Generator obrazów Amazon Titan G1 to najnowocześniejszy model zamiany tekstu na obraz, dostępny za pośrednictwem Amazońska skała macierzysta, który jest w stanie zrozumieć podpowiedzi opisujące wiele obiektów w różnych kontekstach i uchwycić te istotne szczegóły w generowanych obrazach. Jest dostępny we wschodnich stanach USA (N. Wirginia) i zachodnich stanach USA (Oregon) AWS i może wykonywać zaawansowane zadania edycji obrazów, takie jak inteligentne kadrowanie, malowanie i zmiany tła. Użytkownicy chcieliby jednak dostosować model do unikalnych cech niestandardowych zbiorów danych, na których model nie został jeszcze przeszkolony. Niestandardowe zbiory danych mogą zawierać dane ściśle zastrzeżone, zgodne z wytycznymi Twojej marki lub określonymi stylami, takimi jak poprzednia kampania. Aby rozwiązać te przypadki użycia i wygenerować w pełni spersonalizowane obrazy, możesz dostroić Amazon Titan Image Generator za pomocą własnych danych niestandardowe modele dla Amazon Bedrock.
Od generowania obrazów po ich edycję, modele zamiany tekstu na obraz mają szerokie zastosowanie w różnych branżach. Mogą zwiększyć kreatywność pracowników i zapewnić możliwość wyobrażenia sobie nowych możliwości po prostu za pomocą opisów tekstowych. Na przykład może pomóc architektom w projektowaniu i planowaniu pięter oraz umożliwić szybsze wprowadzanie innowacji, zapewniając możliwość wizualizacji różnych projektów bez ręcznego procesu ich tworzenia. Podobnie może pomóc w projektowaniu w różnych branżach, takich jak produkcja, projektowanie mody w handlu detalicznym i projektowanie gier, usprawniając generowanie grafiki i ilustracji. Modele zamiany tekstu na obraz poprawiają także obsługę klienta, umożliwiając spersonalizowane reklamy oraz interaktywne i wciągające wizualne chatboty w zastosowaniach związanych z mediami i rozrywką.
W tym poście przeprowadzimy Cię przez proces dostrajania modelu generatora obrazów Amazon Titan, aby poznać dwie nowe kategorie: pies Ron i kot Smila, nasze ulubione zwierzaki. Omawiamy, jak przygotować dane do zadania dostrajania modelu i jak utworzyć zadanie dostosowywania modelu w Amazon Bedrock. Na koniec pokażemy, jak przetestować i wdrożyć dopracowany model za pomocą Zapewniona przepustowość.
 |
 |
| Ron, pies | Uśmiechnij się do kota |
Ocena możliwości modelu przed dostrojeniem zadania
Modele podstawowe są trenowane na dużych ilościach danych, więc możliwe jest, że Twój model będzie działał wystarczająco dobrze po wyjęciu z pudełka. Dlatego też dobrą praktyką jest sprawdzenie, czy rzeczywiście konieczne jest dostrojenie modelu do konkretnego przypadku użycia lub czy wystarczy szybka inżynieria. Spróbujmy wygenerować kilka obrazów psa Rona i kota Smila za pomocą podstawowego modelu Amazon Titan Image Generator, jak pokazano na poniższych zrzutach ekranu.
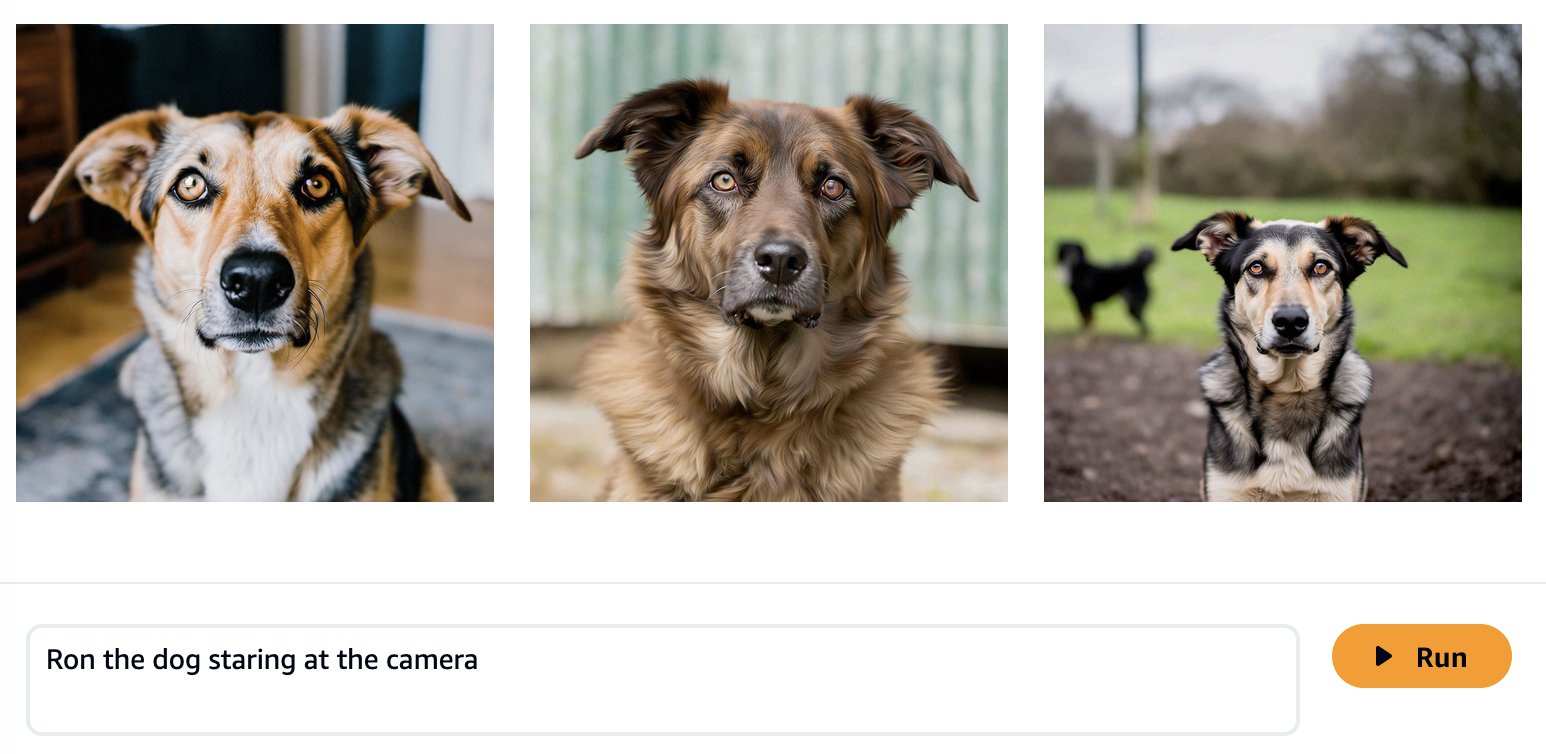

Zgodnie z oczekiwaniami, gotowy model nie zna jeszcze Rona i Smili, a wygenerowane wyniki pokazują różne psy i koty. Dzięki szybkiej inżynierii możemy dostarczyć więcej szczegółów, aby zbliżyć się do wyglądu naszych ulubionych zwierząt.


Choć wygenerowane obrazy są bardziej podobne do Rona i Smili, widzimy, że model nie jest w stanie odtworzyć ich pełnego podobieństwa. Rozpocznijmy teraz dopracowywanie zdjęć Rona i Smili, aby uzyskać spójne, spersonalizowane rezultaty.
Dostrajanie generatora obrazu Amazon Titan
Amazon Bedrock zapewnia bezserwerowe środowisko umożliwiające dostrojenie modelu generatora obrazu Amazon Titan. Wystarczy przygotować dane i wybrać hiperparametry, a AWS zajmie się całym zadaniem za Ciebie.
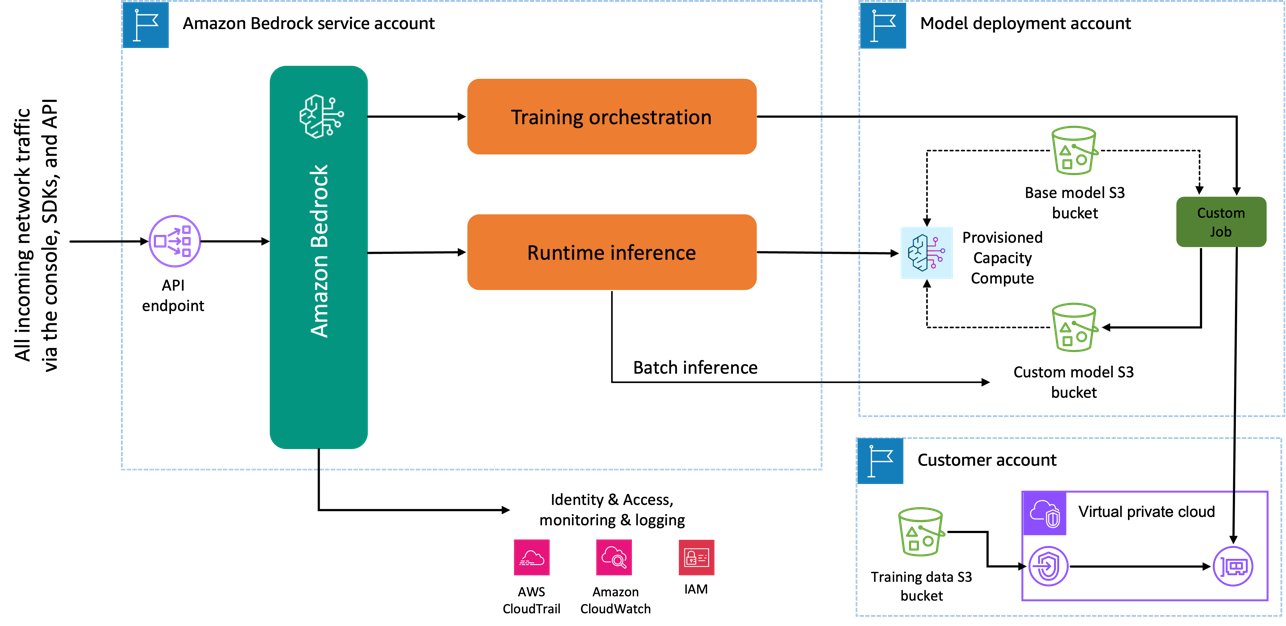
Kiedy używasz modelu Amazon Titan Image Generator do dostrajania, kopia tego modelu jest tworzona na koncie rozwoju modelu AWS, którego właścicielem i zarządcą jest AWS, oraz tworzone jest zadanie dostosowywania modelu. To zadanie uzyskuje następnie dostęp do danych dostrajających z VPC, a waga modelu Amazon Titan zostaje zaktualizowana. Nowy model jest następnie zapisywany w pliku Usługa Amazon Simple Storage (Amazon S3) znajduje się na tym samym koncie rozwoju modelu, co model wstępnie wyszkolony. Może być teraz używany do wnioskowania tylko przez Twoje konto i nie jest udostępniany żadnemu innemu kontu AWS. Podczas uruchamiania wnioskowania dostęp do tego modelu można uzyskać za pośrednictwem pliku a obliczenie udostępnionej pojemności lub bezpośrednio, używając wnioskowanie wsadowe dla Amazon Bedrock. Niezależnie od wybranej metody wnioskowania, Twoje dane pozostają na Twoim koncie i nie są kopiowane na żadne konto należące do AWS ani wykorzystywane do ulepszania modelu Amazon Titan Image Generator.
Poniższy diagram ilustruje ten przepływ pracy.
Prywatność danych i bezpieczeństwo sieci
Twoje dane używane do dostrajania, w tym podpowiedzi, a także modele niestandardowe, pozostają prywatne na Twoim koncie AWS. Nie są one udostępniane ani wykorzystywane do szkolenia modeli ani udoskonalania usług ani nie są udostępniane zewnętrznym dostawcom modeli. Wszystkie dane wykorzystywane do dostrajania są szyfrowane podczas przesyłania i przechowywania. Dane pozostają w tym samym regionie, w którym przetwarzane jest wywołanie API. Możesz także użyć Prywatny link AWS aby utworzyć prywatne połączenie pomiędzy kontem AWS, na którym znajdują się Twoje dane, a VPC.
Przygotowywanie danych
Zanim będzie można utworzyć zadanie dostosowywania modelu, należy to zrobić przygotuj zestaw danych szkoleniowych. Format zbioru danych szkoleniowych zależy od rodzaju tworzonego zadania dostosowywania (dostrajanie lub kontynuacja szkolenia wstępnego) i modalności danych (zamiana tekstu na tekst, tekst na obraz lub obraz na osadzanie). W przypadku modelu generatora obrazu Amazon Titan musisz podać obrazy, których chcesz użyć do dostrojenia, oraz podpis dla każdego obrazu. Amazon Bedrock oczekuje, że Twoje obrazy będą przechowywane na Amazon S3, a pary obrazów i podpisów będą dostarczane w formacie JSONL z wieloma liniami JSON.
Każda linia JSON jest próbką zawierającą odnośnik do obrazu, identyfikator URI S3 obrazu oraz podpis zawierający tekstową zachętę do obrazu. Twoje obrazy muszą być w formacie JPEG lub PNG. Poniższy kod przedstawia przykład formatu:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
Ponieważ „Ron” i „Smila” to imiona, których można użyć również w innych kontekstach, np. w imieniu osoby, podczas tworzenia podpowiedzi dodajemy identyfikatory „Ron the dog” i „Smila the cat”, aby dostroić nasz model . Chociaż nie jest to wymagane w procesie dostrajania, te dodatkowe informacje zapewniają większą przejrzystość kontekstową modelu podczas jego dostosowywania do nowych klas i pozwalają uniknąć pomylenia „psa Rona” z osobą o imieniu Ron i „ Smila the cat” z miastem Smila na Ukrainie. Korzystając z tej logiki, poniższe obrazy przedstawiają przykład naszego zestawu danych szkoleniowych.
 |
 |
 |
| Pies Ron leżący na białym łóżku dla psa | Pies Ron siedzący na podłodze z płytek | Pies Ron leżący na siedzeniu samochodu |
 |
 |
 |
| Smila kot leżący na kanapie | Kot Smila leżący na kanapie wpatrujący się w kamerę | Smila, kot leżący w transporterze |
Transformując nasze dane do formatu oczekiwanego przez zadanie dostosowywania, otrzymujemy następującą przykładową strukturę:
{"odniesienie do obrazu": "/ron_01.jpg", "caption": "Pies Ron leżący na białym łóżku dla psa"} {"image-ref": "/ron_02.jpg", "caption": "Pies Ron siedzący na podłodze z płytek"} {"image-ref": "/ron_03.jpg", "caption": "Pies Ron leżący na foteliku samochodowym"} {"image-ref": "/smila_01.jpg", "caption": "Uśmiechnij się, kot leżący na kanapie"} {"image-ref": "/smila_02.jpg", "caption": "Uśmiechnij się do kota siedzącego przy oknie obok posągu kota"} {"image-ref": "/smila_03.jpg", "caption": "Uśmiechnij się, kot leżący na transporterze"}
Po utworzeniu pliku JSONL musimy go zapisać w zasobniku S3, aby rozpocząć zadanie dostosowywania. Zadania dostrajania Amazon Titan Image Generator G1 będą działać z 5–10,000 60 obrazów. W przykładzie omówionym w tym poście użyliśmy 30 zdjęć: 30 przedstawiających psa Rona i XNUMX przedstawiających kota Smilę. Ogólnie rzecz biorąc, zapewnienie większej liczby odmian stylu lub klasy, której próbujesz się nauczyć, poprawi dokładność dopracowanego modelu. Jednak im więcej obrazów użyjesz do dostrajania, tym więcej czasu będzie potrzebne na ukończenie zadania dostrajania. Liczba użytych obrazów ma również wpływ na cenę Twojej dopracowanej pracy. Odnosić się do Ceny Amazon Bedrock po więcej informacji.
Dostrajanie generatora obrazu Amazon Titan
Teraz, gdy mamy już gotowe dane szkoleniowe, możemy rozpocząć nowe zadanie dostosowywania. Proces ten można wykonać zarówno za pośrednictwem konsoli Amazon Bedrock, jak i interfejsów API. Aby skorzystać z konsoli Amazon Bedrock, wykonaj następujące kroki:
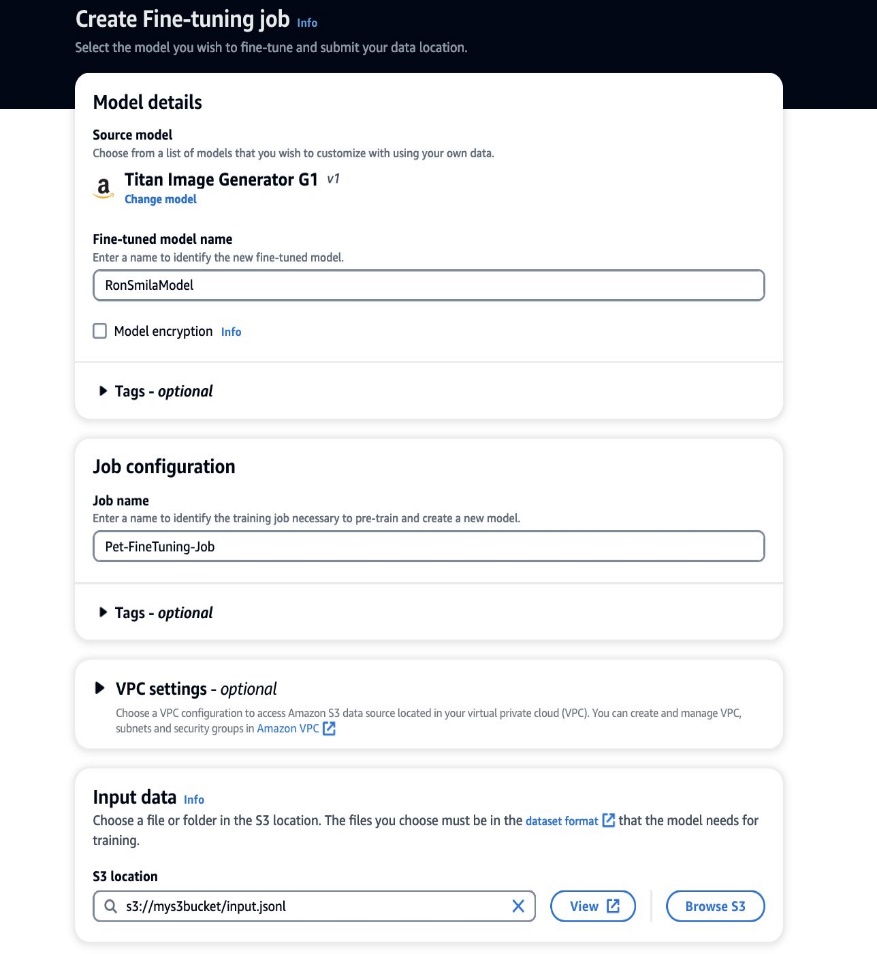
- Na konsoli Amazon Bedrock wybierz Modele niestandardowe w okienku nawigacji.
- Na Dostosuj model menu, wybierz Utwórz zadanie dostrajające.
- W razie zamówieenia projektu Dopracowana nazwa modelu, wprowadź nazwę nowego modelu.
- W razie zamówieenia projektu Konfiguracja pracywprowadź nazwę zadania szkoleniowego.
- W razie zamówieenia projektu Dane wejściowe, wprowadź ścieżkę S3 danych wejściowych.
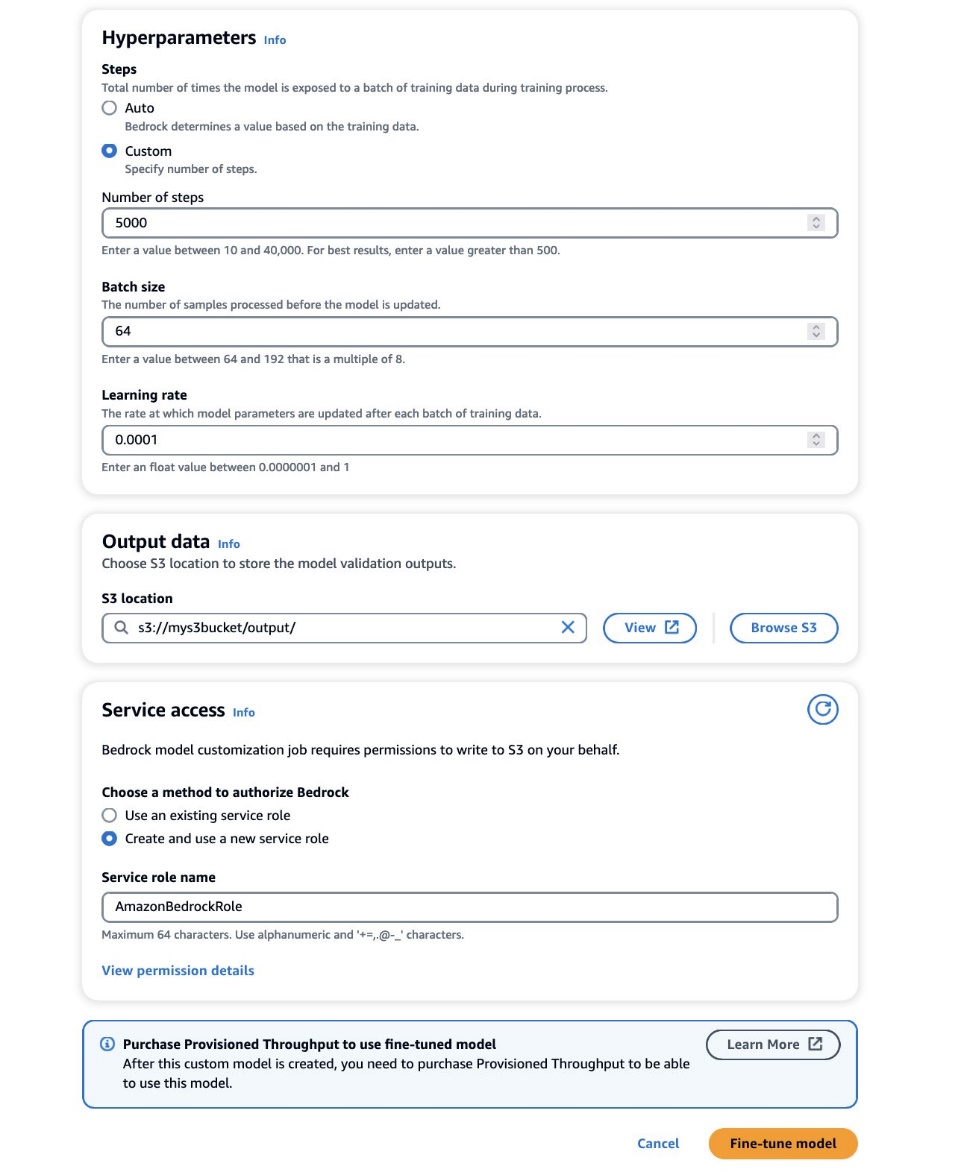
- W Hiperparametry sekcji podaj wartości następujących elementów:
- Liczba stopni – Liczba ekspozycji modelu w każdej partii.
- Wielkość partii – Liczba próbek przetworzonych przed aktualizacją parametrów modelu.
- Wskaźnik uczenia się – Szybkość aktualizacji parametrów modelu po każdej partii. Wybór tych parametrów zależy od danego zbioru danych. Ogólnie rzecz biorąc, zalecamy rozpoczęcie od ustalenia rozmiaru wsadu na 8, szybkości uczenia się na 1e-5 i ustawienie liczby kroków zgodnie z liczbą użytych obrazów, jak opisano szczegółowo w poniższej tabeli.
| Liczba dostarczonych obrazów | 8 | 32 | 64 | 1,000 | 10,000 |
| Zalecana liczba kroków | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Jeśli wyniki Twojej pracy dostrajania nie są zadowalające, rozważ zwiększenie liczby kroków, jeśli nie zaobserwujesz żadnych oznak stylu na wygenerowanych obrazach, i zmniejszenie liczby kroków, jeśli zaobserwujesz styl na wygenerowanych obrazach, ale z artefaktami lub rozmyciem. Jeśli precyzyjnie dostrojony model nie nauczy się unikalnego stylu w zestawie danych nawet po 40,000 XNUMX kroków, rozważ zwiększenie rozmiaru partii lub szybkości uczenia się.
- W Dane wyjściowe w sekcji wprowadź ścieżkę wyjściową S3, w której przechowywane są wyniki walidacji, w tym okresowo rejestrowane metryki utraty walidacji i dokładności.
- W Dostęp serwisowy sekcję, wygeneruj nową AWS Zarządzanie tożsamością i dostępem (IAM) lub wybierz istniejącą rolę IAM z niezbędnymi uprawnieniami dostępu do zasobników S3.
Ta autoryzacja umożliwia firmie Amazon Bedrock pobieranie zbiorów danych wejściowych i walidacyjnych z wyznaczonego zasobnika oraz bezproblemowe przechowywanie wyników walidacji w zasobniku S3.
- Dodaj Dopracuj model.
Po ustawieniu prawidłowych konfiguracji Amazon Bedrock przeszkoli teraz Twój niestandardowy model.
Wdróż precyzyjnie dostrojony generator obrazów Amazon Titan z zapewnioną przepustowością
Po utworzeniu modelu niestandardowego udostępniona przepustowość umożliwia przydzielenie z góry określonej, stałej szybkości przetwarzania do modelu niestandardowego. Ta alokacja zapewnia spójny poziom wydajności i możliwości obsługi obciążeń, co skutkuje lepszą wydajnością w przypadku obciążeń produkcyjnych. Drugą zaletą zapewnianej przepustowości jest kontrola kosztów, ponieważ standardowe ceny oparte na tokenach z trybem wnioskowania na żądanie mogą być trudne do przewidzenia w dużych skalach.
Po zakończeniu dostrajania Twojego modelu, model ten pojawi się na Modele niestandardowe na konsoli Amazon Bedrock.
Aby kupić udostępnioną przepustowość, wybierz model niestandardowy, który właśnie dostroiłeś i wybierz Zakup udostępnionej przepustowości.
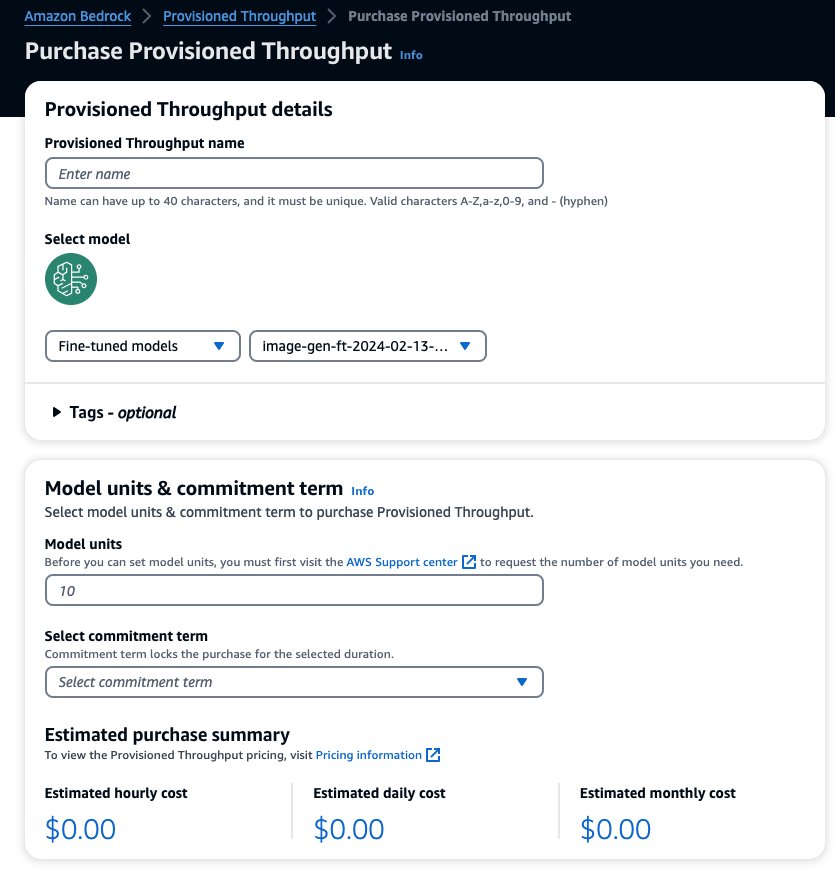
Spowoduje to wstępne wypełnienie wybranego modelu, dla którego chcesz kupić aprowizowaną przepustowość. Aby przetestować dopracowany model przed wdrożeniem, ustaw jednostki modelu na wartość 1 i ustaw okres zobowiązania na Brak zobowiązań. Dzięki temu możesz szybko rozpocząć testowanie modeli za pomocą niestandardowych podpowiedzi i sprawdzić, czy szkolenie jest odpowiednie. Co więcej, gdy dostępne będą nowe, dostrojone modele i nowe wersje, możesz zaktualizować alokowaną przepustowość, o ile aktualizujesz ją za pomocą innych wersji tego samego modelu.
Dostrajanie wyników
W przypadku naszego zadania dostosowywania modelu psa Rona i kota Smili eksperymenty wykazały, że najlepszymi hiperparametrami było 5,000 kroków przy wielkości partii 8 i szybkości uczenia się 1e-5.
Poniżej przedstawiono kilka przykładów obrazów wygenerowanych przez dostosowany model.
 |
 |
 |
| Pies Ron w pelerynie superbohatera | Ron, pies na Księżycu | Pies Ron w basenie w okularach przeciwsłonecznych |
 |
 |
 |
| Uśmiechnij się do kota na śniegu | Uśmiechnij się do kota w czerni i bieli, wpatrując się w kamerę | Uśmiechnij się do kota w świątecznej czapce |
Wnioski
W tym poście omówiliśmy, kiedy należy zastosować dostrajanie zamiast projektowania monitów w celu generowania obrazu o lepszej jakości. Pokazaliśmy, jak dostroić model Amazon Titan Image Generator i wdrożyć niestandardowy model na Amazon Bedrock. Udostępniliśmy również ogólne wytyczne dotyczące przygotowywania danych do dostrajania i ustawiania optymalnych hiperparametrów w celu dokładniejszego dostosowywania modelu.
W następnym kroku możesz dostosować następujące elementy przykład do Twojego przypadku użycia, aby wygenerować hiperspersonalizowane obrazy za pomocą generatora obrazu Amazon Titan.
O autorach
 Maira Ladeira Tanke jest starszym analitykiem danych zajmującym się generatywną sztuczną inteligencją w AWS. Ma doświadczenie w uczeniu maszynowym i ponad 10-letnie doświadczenie w projektowaniu i budowaniu aplikacji AI dla klientów z różnych branż. Jako lider techniczny pomaga klientom przyspieszyć osiąganie wartości biznesowej dzięki generatywnym rozwiązaniom AI w Amazon Bedrock. W wolnym czasie Maira lubi podróżować, bawić się ze swoim kotem Smilą i spędzać czas z rodziną w ciepłym miejscu.
Maira Ladeira Tanke jest starszym analitykiem danych zajmującym się generatywną sztuczną inteligencją w AWS. Ma doświadczenie w uczeniu maszynowym i ponad 10-letnie doświadczenie w projektowaniu i budowaniu aplikacji AI dla klientów z różnych branż. Jako lider techniczny pomaga klientom przyspieszyć osiąganie wartości biznesowej dzięki generatywnym rozwiązaniom AI w Amazon Bedrock. W wolnym czasie Maira lubi podróżować, bawić się ze swoim kotem Smilą i spędzać czas z rodziną w ciepłym miejscu.
 Dany Mitchell jest architektem rozwiązań specjalistycznych AI/ML w Amazon Web Services. Koncentruje się na przypadkach użycia systemów wizyjnych i pomaga klientom w całym regionie EMEA przyspieszyć ich podróż do uczenia maszynowego.
Dany Mitchell jest architektem rozwiązań specjalistycznych AI/ML w Amazon Web Services. Koncentruje się na przypadkach użycia systemów wizyjnych i pomaga klientom w całym regionie EMEA przyspieszyć ich podróż do uczenia maszynowego.
 Bharati Srinivasan jest analitykiem danych w AWS Professional Services, gdzie uwielbia tworzyć fajne rzeczy na Amazon Bedrock. Pasjonuje się zwiększaniem wartości biznesowej z aplikacji do uczenia maszynowego, ze szczególnym uwzględnieniem odpowiedzialnej sztucznej inteligencji. Poza tworzeniem nowych doświadczeń związanych ze sztuczną inteligencją dla klientów, Bharathi uwielbia pisać science fiction i rzucać sobie wyzwania w sportach wytrzymałościowych.
Bharati Srinivasan jest analitykiem danych w AWS Professional Services, gdzie uwielbia tworzyć fajne rzeczy na Amazon Bedrock. Pasjonuje się zwiększaniem wartości biznesowej z aplikacji do uczenia maszynowego, ze szczególnym uwzględnieniem odpowiedzialnej sztucznej inteligencji. Poza tworzeniem nowych doświadczeń związanych ze sztuczną inteligencją dla klientów, Bharathi uwielbia pisać science fiction i rzucać sobie wyzwania w sportach wytrzymałościowych.
 Achin Jain jest naukowcem stosowanym w zespole Amazon Artificial General Intelligence (AGI). Ma wiedzę w zakresie modeli zamiany tekstu na obraz i koncentruje się na budowaniu generatora obrazu Amazon Titan.
Achin Jain jest naukowcem stosowanym w zespole Amazon Artificial General Intelligence (AGI). Ma wiedzę w zakresie modeli zamiany tekstu na obraz i koncentruje się na budowaniu generatora obrazu Amazon Titan.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

