Dzisiaj z radością ogłaszamy możliwość dostrojenia modeli Code Llama za pomocą Meta Amazon SageMaker JumpStart. Rodzina dużych modeli językowych (LLM) Code Llama to zbiór wstępnie wyszkolonych i dostrojonych modeli generowania kodu o skali od 7 miliardów do 70 miliardów parametrów. Dopracowane modele Code Lamy zapewniają większą dokładność i wyjaśnialność w porównaniu z podstawowymi modelami Code Lamy, co widać w testach HumanEval i zbiory danych MBPP. Możesz dostroić i wdrożyć modele Code Llama za pomocą SageMaker JumpStart, korzystając z Studio Amazon SageMaker Interfejs użytkownika za pomocą kilku kliknięć lub przy użyciu pakietu SageMaker Python SDK. Dostrajanie modeli Lamy opiera się na skryptach dostarczonych w pliku repo llama-recipes w GitHubie z Meta przy użyciu technik kwantyzacji PyTorch FSDP, PEFT/LoRA i Int8.
W tym poście opisujemy, jak dostroić wstępnie wytrenowane modele Code Llama za pomocą SageMaker JumpStart za pomocą interfejsu użytkownika i zestawu SDK dostępnego za pomocą jednego kliknięcia: Repozytorium GitHub.
Co to jest SageMaker JumpStart
Dzięki SageMaker JumpStart praktycy uczenia maszynowego (ML) mogą wybierać spośród szerokiej gamy publicznie dostępnych modeli podstawowych. Praktycy ML mogą wdrażać modele podstawowe w dedykowanych Amazon Sage Maker instancje z izolowanego środowiska sieciowego i dostosowywać modele za pomocą SageMaker do trenowania i wdrażania modeli.
Co to jest Kod Lama
Code Llama jest wersją specjalizującą się w kodzie Lama 2 który powstał w wyniku dalszego szkolenia Lamy 2 na zbiorach danych specyficznych dla kodu i próbkowania większej ilości danych z tego samego zbioru danych przez dłuższy czas. Code Llama oferuje ulepszone możliwości kodowania. Może generować kod i język naturalny dotyczący kodu, zarówno na podstawie podpowiedzi w kodzie, jak i w języku naturalnym (na przykład „Napisz mi funkcję, która wyprowadza ciąg Fibonacciego”). Można go także używać do uzupełniania kodu i debugowania. Obsługuje wiele najpopularniejszych obecnie języków programowania, w tym Python, C++, Java, PHP, TypeScript (JavaScript), C#, Bash i inne.
Po co dostrajać modele Code Lamy
Meta opublikowała testy wydajności Code Llama w serwisie HumanEval i MBPP dla popularnych języków kodowania, takich jak Python, Java i JavaScript. Wydajność modeli Code Llama Python w HumanEval wykazała różną wydajność w różnych językach kodowania i zadaniach, wahającą się od 38% w modelu Pythona 7B do 57% w modelach Pythona 70B. Ponadto dostrojone modele Code Lama w języku programowania SQL dały lepsze wyniki, co widać w testach porównawczych oceny SQL. Te opublikowane testy porównawcze podkreślają potencjalne korzyści z dostrajania modeli Code Lama, umożliwiając lepszą wydajność, dostosowywanie i dostosowywanie do określonych dziedzin i zadań kodowania.
Dostrajanie bez użycia kodu za pomocą interfejsu użytkownika SageMaker Studio
Aby rozpocząć dostrajanie modeli lamy przy użyciu SageMaker Studio, wykonaj następujące kroki:
- W konsoli SageMaker Studio wybierz Szybki start w okienku nawigacji.
Znajdziesz listę ponad 350 modeli, od modeli open source po modele zastrzeżone.
- Wyszukaj modele Code Lamy.

Jeśli nie widzisz modeli Code Lamy, możesz zaktualizować wersję SageMaker Studio, zamykając i uruchamiając ponownie. Aby uzyskać więcej informacji na temat aktualizacji wersji, zobacz Zamknij i zaktualizuj aplikacje Studio. Wybierając, możesz znaleźć także inne warianty modelu Poznaj wszystkie modele generowania kodu lub wyszukaj Code Lama w polu wyszukiwania.
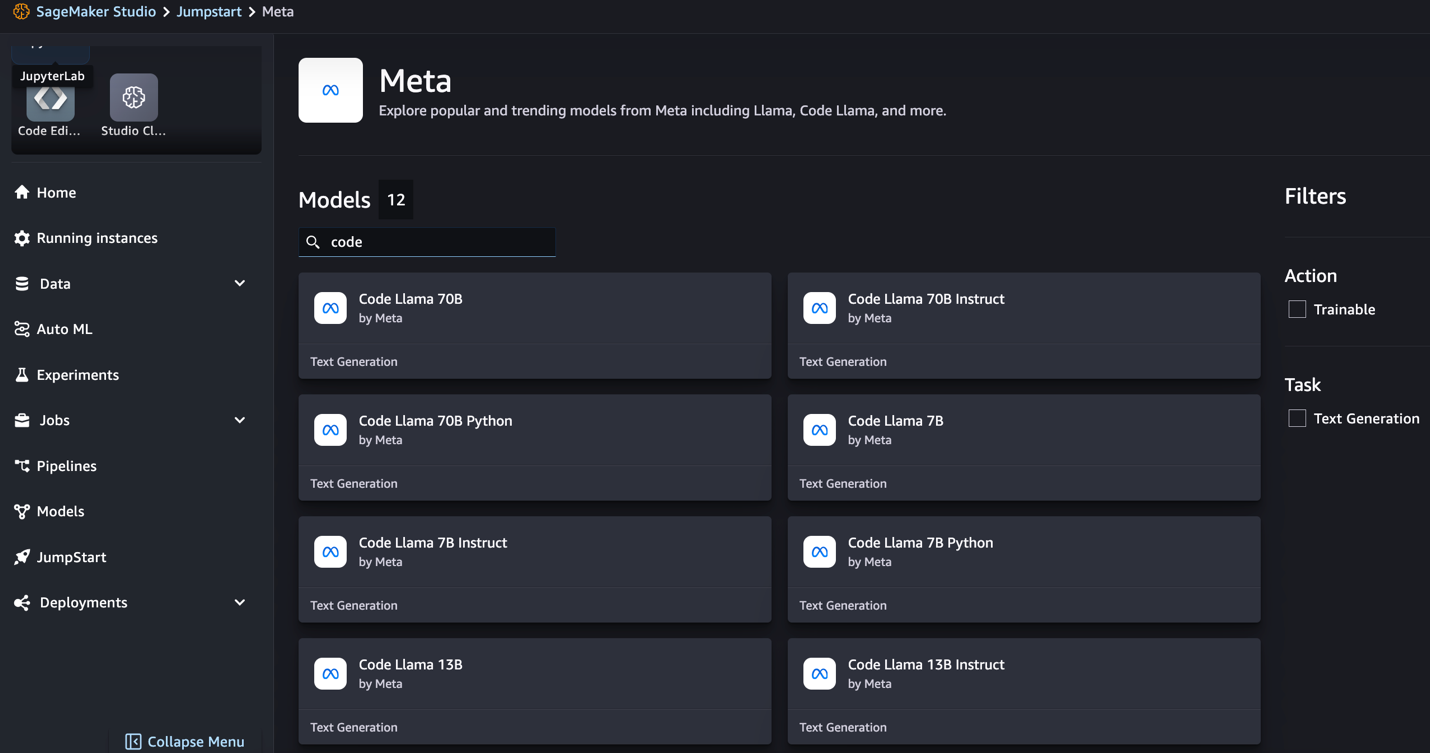
SageMaker JumpStart obsługuje obecnie dostrajanie instrukcji dla modeli Code Lama. Poniższy zrzut ekranu przedstawia stronę dostrajania modelu Code Llama 2 70B.
- W razie zamówieenia projektu Lokalizacja zbioru danych treningowych, możesz wskazać Usługa Amazon Simple Storage Wiadro (Amazon S3) zawierające zbiory danych szkoleniowych i walidacyjnych do dostrajania.
- Ustaw konfigurację wdrożenia, hiperparametry i ustawienia zabezpieczeń w celu dostrajania.
- Dodaj Pociąg aby rozpocząć zadanie dostrajania w instancji SageMaker ML.
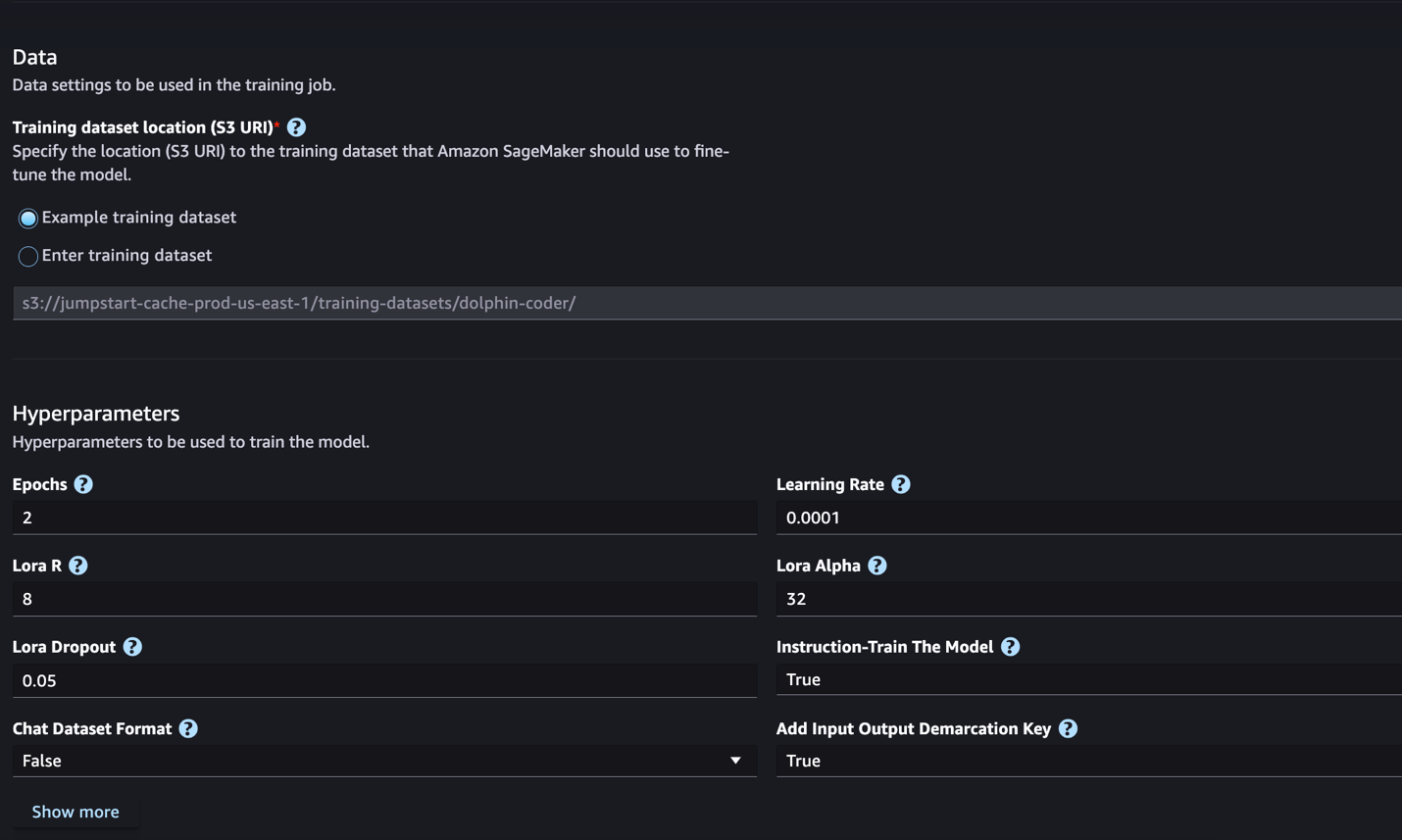
W następnej sekcji omówimy format zbioru danych, który należy przygotować do dostrajania instrukcji.
- Po dopracowaniu modelu możesz go wdrożyć, korzystając ze strony modelu w SageMaker JumpStart.
Opcja wdrożenia dopracowanego modelu pojawi się po zakończeniu dostrajania, jak pokazano na poniższym zrzucie ekranu.

Dostosuj za pomocą pakietu SageMaker Python SDK
W tej sekcji pokazujemy, jak dostroić modele Code LIama przy użyciu pakietu SageMaker Python SDK na zestawie danych w formacie instrukcji. W szczególności model jest dostrojony pod kątem zestawu zadań przetwarzania języka naturalnego (NLP) opisanych za pomocą instrukcji. Pomaga to poprawić wydajność modelu w przypadku niewidocznych zadań dzięki monitom o zerowym zasięgu.
Wykonaj poniższe kroki, aby ukończyć zadanie dostrajania. Cały kod dostrajający można uzyskać z pliku Repozytorium GitHub.
Najpierw przyjrzyjmy się formatowi zbioru danych wymaganemu do dostrojenia instrukcji. Dane szkoleniowe powinny być sformatowane w formacie linii JSON (.jsonl), gdzie każda linia jest słownikiem reprezentującym próbkę danych. Wszystkie dane treningowe muszą znajdować się w jednym folderze. Można go jednak zapisać w wielu plikach .jsonl. Poniżej znajduje się przykład w formacie linii JSON:
Folder szkoleniowy może zawierać plik template.json plik opisujący formaty wejściowe i wyjściowe. Poniżej znajduje się przykładowy szablon:
Aby dopasować szablon, każda próbka w plikach wierszy JSON musi zawierać system_prompt, question, response pola. W tej demonstracji używamy Zbiór danych Dolphin Coder z Przytulonej Twarzy.
Po przygotowaniu zbioru danych i przesłaniu go do segmentu S3 możesz rozpocząć dostrajanie, używając następującego kodu:
Dostrojony model można wdrożyć bezpośrednio z narzędzia szacowania, jak pokazano w poniższym kodzie. Szczegóły w notatniku w Repozytorium GitHub.
Techniki dostrajania
Modele językowe, takie jak Llama, mają rozmiar większy niż 10 GB, a nawet 100 GB. Dostrajanie tak dużych modeli wymaga instancji ze znacznie dużą pamięcią CUDA. Ponadto uczenie tych modeli może być bardzo powolne ze względu na rozmiar modelu. Dlatego w celu wydajnego dostrajania stosujemy następujące optymalizacje:
- Adaptacja niskiej rangi (LoRA) – Jest to rodzaj efektywnego dostrajania parametrów (PEFT) służącego do wydajnego dostrajania dużych modeli. Dzięki tej metodzie zamrażasz cały model i dodajesz do modelu jedynie niewielki zestaw regulowanych parametrów lub warstw. Na przykład zamiast trenować wszystkie 7 miliardów parametrów Lamy 2 7B, możesz dostroić mniej niż 1% parametrów. Pomaga to w znacznym zmniejszeniu zapotrzebowania na pamięć, ponieważ wystarczy przechowywać gradienty, stany optymalizatora i inne informacje związane ze szkoleniem tylko dla 1% parametrów. Co więcej, pomaga to w skróceniu czasu i kosztów szkolenia. Więcej szczegółów na temat tej metody można znaleźć w artykule LoRA: Adaptacja niskiego poziomu dużych modeli językowych.
- Kwantyzacja Int8 – Nawet przy optymalizacjach takich jak LoRA modele takie jak Llama 70B są nadal zbyt duże, aby można je było trenować. Aby zmniejszyć zużycie pamięci podczas treningu, możesz podczas treningu użyć kwantyzacji Int8. Kwantyzacja zazwyczaj zmniejsza precyzję typów danych zmiennoprzecinkowych. Chociaż zmniejsza to pamięć wymaganą do przechowywania ciężarów modeli, pogarsza to wydajność z powodu utraty informacji. Kwantyzacja Int8 wykorzystuje tylko jedną czwartą precyzji, ale nie powoduje pogorszenia wydajności, ponieważ nie powoduje po prostu utraty bitów. Zaokrągla dane z jednego typu do drugiego. Aby dowiedzieć się więcej o kwantyzacji Int8, zobacz LLM.int8(): 8-bitowe mnożenie macierzy dla transformatorów w dużej skali.
- W pełni podzielone na dane równoległe (FSDP) – Jest to rodzaj algorytmu uczenia równoległego do danych, który dzieli parametry modelu na procesy równoległe danych i opcjonalnie może przenieść część obliczeń szkoleniowych do procesorów. Chociaż parametry są podzielone na różne procesory graficzne, obliczenia każdej mikropartii są lokalne dla procesu roboczego GPU. Umożliwia bardziej równomierne rozbicie parametrów i osiągnięcie zoptymalizowanej wydajności dzięki nakładaniu się komunikacji i obliczeń podczas szkolenia.
Poniższa tabela podsumowuje szczegóły każdego modelu z różnymi ustawieniami.
| Model | Ustawienia domyślne | LORA + FSDP | LORA + Brak FSDP | Kwantyzacja Int8 + LORA + Brak FSDP |
| Kod Lama 2 7B | LORA + FSDP | Tak | Tak | Tak |
| Kod Lama 2 13B | LORA + FSDP | Tak | Tak | Tak |
| Kod Lama 2 34B | INT8 + LORA + BEZ FSDP | Nie | Nie | Tak |
| Kod Lama 2 70B | INT8 + LORA + BEZ FSDP | Nie | Nie | Tak |
Dostrajanie modeli Lamy opiera się na skryptach dostarczonych przez poniższe osoby GitHub repo.
Obsługiwane hiperparametry do szkolenia
Dostrajanie Code Llama 2 obsługuje wiele hiperparametrów, z których każdy może mieć wpływ na wymagania dotyczące pamięci, szybkość uczenia i wydajność dostrojonego modelu:
- epoka – Liczba przejść, jakie algorytm dostrajający wykonuje przez zbiór danych szkoleniowych. Musi być liczbą całkowitą większą niż 1. Wartość domyślna to 5.
- wskaźnik_nauczenia – Szybkość aktualizacji wag modeli po przepracowaniu każdej partii przykładów szkoleniowych. Musi to być dodatnia liczba zmiennoprzecinkowa większa niż 0. Wartość domyślna to 1e-4.
- instrukcja_dostrojona – Czy szkolić model, czy nie. Musi być
TrueorFalse. Domyślnie jestFalse. - per_device_train_batch_size – Rozmiar partii na rdzeń GPU/procesor do celów szkoleniowych. Musi być dodatnią liczbą całkowitą. Wartość domyślna to 4.
- per_device_eval_batch_size – Rozmiar partii na rdzeń GPU/procesor do oceny. Musi być dodatnią liczbą całkowitą. Wartość domyślna to 1.
- max_train_samples – W celu debugowania lub szybszego szkolenia skróć liczbę przykładów szkoleniowych do tej wartości. Wartość -1 oznacza wykorzystanie wszystkich próbek szkoleniowych. Musi to być dodatnia liczba całkowita lub -1. Wartość domyślna to -1.
- max_val_samples – W celu debugowania lub szybszego szkolenia skróć liczbę przykładów walidacji do tej wartości. Wartość -1 oznacza wykorzystanie wszystkich próbek walidacyjnych. Musi to być dodatnia liczba całkowita lub -1. Wartość domyślna to -1.
- maksymalna_długość_wejściowa – Maksymalna całkowita długość sekwencji wejściowej po tokenizacji. Sekwencje dłuższe niż ta zostaną obcięte. Jeśli -1,
max_input_lengthjest ustawiona na minimum 1024 i maksymalną długość modelu zdefiniowaną przez tokenizer. Jeśli zostanie ustawiony na wartość dodatnią,max_input_lengthjest ustawiony na minimum podanej wartości imodel_max_lengthzdefiniowany przez tokenizer. Musi to być dodatnia liczba całkowita lub -1. Wartość domyślna to -1. - validation_split_ratio – Jeśli kanał walidacji to
none, stosunek podziału walidacji pociągu do danych pociągu musi mieścić się w przedziale 0–1. Wartość domyślna to 0.2. - train_data_split_seed – Jeśli nie ma danych walidacyjnych, naprawia to losowy podział wejściowych danych szkoleniowych na dane szkoleniowe i walidacyjne wykorzystywane przez algorytm. Musi być liczbą całkowitą. Wartość domyślna to 0.
- preprocessing_num_workers – Liczba procesów, które należy zastosować do przetwarzania wstępnego. Jeśli
None, główny proces służy do wstępnego przetwarzania. Domyślnie jestNone. - lora_r – Lora R. Musi być dodatnią liczbą całkowitą. Wartość domyślna to 8.
- lora_alfa – Lora Alfa. Musi być dodatnią liczbą całkowitą. Wartość domyślna to 32
- lora_dropout – Lora odpada. musi być dodatnią liczbą zmiennoprzecinkową z zakresu od 0 do 1. Wartość domyślna to 0.05.
- int8_kwantyzacja - Jeśli
True, model jest ładowany z 8-bitową precyzją na potrzeby szkolenia. Wartość domyślna dla 7B i 13B toFalse. Domyślnie dla 70B jestTrue. - włącz_fsdp – Jeśli ma wartość True, szkolenie korzysta z FSDP. Wartość domyślna dla 7B i 13B to True. Wartość domyślna dla 70B to Fałsz. Zauważ to
int8_quantizationnie jest obsługiwany przez FSDP.
Wybierając hiperparametry, należy wziąć pod uwagę następujące kwestie:
- Oprawa
int8_quantization=Truezmniejsza zapotrzebowanie na pamięć i prowadzi do szybszego treningu. - Zmniejszenie
per_device_train_batch_sizeimax_input_lengthzmniejsza zapotrzebowanie na pamięć i dlatego można go uruchomić na mniejszych instancjach. Jednakże ustawienie bardzo niskich wartości może wydłużyć czas uczenia. - Jeśli nie używasz kwantyzacji Int8 (
int8_quantization=False), użyj FSDP (enable_fsdp=True) dla szybszego i efektywniejszego treningu.
Obsługiwane typy instancji na potrzeby szkolenia
W poniższej tabeli podsumowano obsługiwane typy wystąpień na potrzeby uczenia różnych modeli.
| Model | Domyślny typ instancji | Obsługiwane typy instancji |
| Kod Lama 2 7B | ml.g5.12xduży |
ml.g5.12xlarge, ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xduże |
| Kod Lama 2 13B | ml.g5.12xduży |
ml.g5.24xlarge, ml.g5.48xlarge, ml.p3dn.24xlarge, ml.g4dn.12xduże |
| Kod Lama 2 70B | ml.g5.48xduży |
ml.g5.48xduży ml.p4d.24xduży |
Wybierając typ instancji, należy wziąć pod uwagę następujące kwestie:
- Instancje G5 zapewniają najbardziej efektywne szkolenie spośród obsługiwanych typów instancji. Dlatego jeśli masz dostępne instancje G5, powinieneś z nich skorzystać.
- Czas treningu w dużej mierze zależy od ilości procesorów graficznych i dostępnej pamięci CUDA. Dlatego szkolenie na instancjach z tą samą liczbą procesorów graficznych (na przykład ml.g5.2xlarge i ml.g5.4xlarge) jest mniej więcej takie samo. Dlatego do treningu możesz wykorzystać tańszą instancję (ml.g5.2xlarge).
- Podczas korzystania z instancji p3 uczenie będzie wykonywane z 32-bitową precyzją, ponieważ bfloat16 nie jest obsługiwany w tych instancjach. Dlatego zadanie szkoleniowe zużyje dwukrotnie więcej pamięci CUDA podczas szkolenia na instancjach p3 w porównaniu z instancjami g5.
Aby poznać koszt szkolenia w przeliczeniu na instancję, zob Instancje Amazon EC2 G5.
Ocena
Ocena jest ważnym krokiem w ocenie wydajności precyzyjnie dostrojonych modeli. Przedstawiamy zarówno oceny jakościowe, jak i ilościowe, aby wykazać poprawę modeli precyzyjnie dostrojonych w porównaniu z modelami niedostrojonymi. W ocenie jakościowej pokazujemy przykładową odpowiedź zarówno z modeli dostrojonych, jak i niedostrojonych. W ocenie ilościowej używamy HumanEval, zestaw testów opracowany przez OpenAI do generowania kodu w języku Python w celu testowania możliwości tworzenia poprawnych i dokładnych wyników. Repozytorium HumanEval jest objęte licencją MIT. Dopracowaliśmy warianty Pythona wszystkich modeli Code LIama w różnych rozmiarach (Code LIama Python 7B, 13B, 34B i 70B na Zbiór danych Dolphin Coder), a wyniki ewaluacji zaprezentujemy w kolejnych rozdziałach.
Ocena jakościowa
Po wdrożeniu dopracowanego modelu możesz zacząć używać punktu końcowego do generowania kodu. W poniższym przykładzie prezentujemy odpowiedzi zarówno z podstawowego, jak i dopracowanego wariantu Code LIama 34B Python na próbce testowej w Zbiór danych Dolphin Coder:
Dopracowany model Code Llama oprócz udostępnienia kodu dla poprzedniego zapytania generuje szczegółowe wyjaśnienie podejścia i pseudokod.
Kod Lamy 34b Niedostrojona odpowiedź Pythona:
Code Lama 34B Dostrojona odpowiedź Pythona
Podstawowa prawda
Co ciekawe, nasza dopracowana wersja Code Llama 34B Python zapewnia dynamiczne rozwiązanie oparte na programowaniu dla najdłuższego podciągu palindromowego, które różni się od rozwiązania dostarczonego w zasadzie z wybranego przykładu testowego. Nasz dopracowany model szczegółowo wyjaśnia i wyjaśnia rozwiązanie oparte na programowaniu dynamicznym. Z drugiej strony, niedostrojony model powoduje halucynacje potencjalnych wyników zaraz po print instrukcja (pokazana w lewej komórce), ponieważ wynik axyzzyx nie jest najdłuższym palindromem w danym ciągu. Pod względem złożoności czasowej rozwiązanie programowania dynamicznego jest generalnie lepsze niż podejście początkowe. Rozwiązanie do programowania dynamicznego ma złożoność czasową O(n^2), gdzie n jest długością ciągu wejściowego. Jest to bardziej wydajne niż początkowe rozwiązanie z niedostrojonego modelu, które również miało kwadratową złożoność czasową O(n^2), ale przy mniej zoptymalizowanym podejściu.
To wygląda obiecująco! Pamiętaj, że udoskonaliliśmy wariant Code LIama Python tylko w 10% przypadków Zbiór danych Dolphin Coder. Jest o wiele więcej do odkrycia!
Pomimo dokładnych instrukcji w odpowiedzi nadal musimy sprawdzić poprawność kodu Pythona dostarczonego w rozwiązaniu. Następnie używamy struktury oceny zwanej Ocena człowieka przeprowadzanie testów integracyjnych na wygenerowanej odpowiedzi z Code LIama w celu systematycznego sprawdzania jej jakości.
Ocena ilościowa za pomocą HumanEval
HumanEval to narzędzie ewaluacyjne służące do oceny możliwości rozwiązywania problemów LLM w przypadku problemów z kodowaniem opartym na Pythonie, jak opisano w artykule Ocena modeli dużego języka wyszkolonych w kodzie. W szczególności składa się ze 164 oryginalnych problemów programistycznych opartych na języku Python, które oceniają zdolność modelu językowego do generowania kodu na podstawie dostarczonych informacji, takich jak sygnatura funkcji, dokumentacja, treść i testy jednostkowe.
Każde pytanie dotyczące programowania w Pythonie wysyłamy do modelu Code LIama wdrożonego na punkcie końcowym SageMaker, aby uzyskać k odpowiedzi. Następnie każdą z k odpowiedzi uruchamiamy w testach integracyjnych w repozytorium HumanEval. Jeśli jakakolwiek odpowiedź spośród k odpowiedzi przejdzie testy integracyjne, uznajemy, że przypadek testowy zakończył się sukcesem; w przeciwnym razie nie powiodło się. Następnie powtarzamy proces, aby obliczyć współczynnik pomyślnych przypadków jako ostateczny wynik oceny pass@k. Zgodnie ze standardową praktyką w naszej ocenie ustalamy k jako 1, aby wygenerować tylko jedną odpowiedź na pytanie i sprawdzić, czy przechodzi ona test integracji.
Poniżej znajduje się przykładowy kod umożliwiający korzystanie z repozytorium HumanEval. Można uzyskać dostęp do zbioru danych i wygenerować pojedynczą odpowiedź, korzystając z punktu końcowego SageMaker. Szczegóły w notatniku w Repozytorium GitHub.
W poniższej tabeli przedstawiono ulepszenia precyzyjnie dostrojonych modeli Code LIama Python w porównaniu z niedostrojonymi modelami w różnych rozmiarach modeli. Aby zapewnić poprawność, wdrażamy również niedostrojone modele Code LIama w punktach końcowych SageMaker i poddajemy je ocenom Human Eval. The przepustka@1 liczby (pierwszy wiersz poniższej tabeli) odpowiadają liczbom podanym w Artykuł badawczy Code Lama. Parametry wnioskowania są konsekwentnie ustawione jako "parameters": {"max_new_tokens": 384, "temperature": 0.2}.
Jak widać z wyników, wszystkie dostrojone warianty Code LIama Python wykazują znaczną poprawę w stosunku do niedostrojonych modeli. W szczególności Code LIama Python 70B przewyższa niedostrojony model o około 12%.
| . | 7B Pythona | 13B Pythona | 34B | 34B Pythona | 70B Pythona |
| Wydajność wstępnie wyszkolonego modelu (przebieg @ 1) | 38.4 | 43.3 | 48.8 | 53.7 | 57.3 |
| Dostrojona wydajność modelu (przejście @ 1) | 45.12 | 45.12 | 59.1 | 61.5 | 69.5 |
Teraz możesz spróbować dostroić modele Code LIama na własnym zestawie danych.
Sprzątać
Jeśli zdecydujesz, że nie chcesz już uruchamiać punktu końcowego SageMaker, możesz go usunąć za pomocą AWS SDK dla Pythona (Boto3), Interfejs wiersza poleceń AWS (AWS CLI) lub konsola SageMaker. Aby uzyskać więcej informacji, zobacz Usuń punkty końcowe i zasoby. Dodatkowo możesz zamknij zasoby SageMaker Studio które nie są już potrzebne.
Wnioski
W tym poście omówiliśmy dostrajanie modeli Meta Code Llama 2 za pomocą SageMaker JumpStart. Pokazaliśmy, że można używać konsoli SageMaker JumpStart w SageMaker Studio lub pakietu SageMaker Python SDK do dostrajania i wdrażania tych modeli. Omówiliśmy także technikę dostrajania, typy instancji i obsługiwane hiperparametry. Dodatkowo przedstawiliśmy rekomendacje dotyczące zoptymalizowanego szkolenia na podstawie różnych przeprowadzonych przez nas testów. Jak widać z wyników dostrajania trzech modeli na dwóch zbiorach danych, dostrajanie poprawia podsumowanie w porównaniu z modelami niedostrojonymi. W następnym kroku możesz spróbować dostroić te modele na własnym zestawie danych, korzystając z kodu dostarczonego w repozytorium GitHub, aby przetestować i porównać wyniki dla swoich przypadków użycia.
O autorach
 Dr Xin Huang jest starszym naukowcem zajmującym się wbudowanymi algorytmami Amazon SageMaker JumpStart i Amazon SageMaker. Koncentruje się na rozwijaniu skalowalnych algorytmów uczenia maszynowego. Jego zainteresowania badawcze obejmują obszar przetwarzania języka naturalnego, wyjaśnialne głębokie uczenie się na danych tabelarycznych oraz solidną analizę nieparametrycznego grupowania czasoprzestrzennego. Opublikował wiele artykułów na konferencjach ACL, ICDM, KDD i Royal Statistical Society: Series A.
Dr Xin Huang jest starszym naukowcem zajmującym się wbudowanymi algorytmami Amazon SageMaker JumpStart i Amazon SageMaker. Koncentruje się na rozwijaniu skalowalnych algorytmów uczenia maszynowego. Jego zainteresowania badawcze obejmują obszar przetwarzania języka naturalnego, wyjaśnialne głębokie uczenie się na danych tabelarycznych oraz solidną analizę nieparametrycznego grupowania czasoprzestrzennego. Opublikował wiele artykułów na konferencjach ACL, ICDM, KDD i Royal Statistical Society: Series A.
 Vishaala Yalamanchali jest architektem rozwiązań start-upowych współpracującym z firmami zajmującymi się generatywną sztuczną inteligencją, robotyką i pojazdami autonomicznymi na wczesnym etapie rozwoju. Vishaal współpracuje ze swoimi klientami w celu dostarczania najnowocześniejszych rozwiązań ML i osobiście jest zainteresowany uczeniem się przez wzmacnianie, oceną LLM i generowaniem kodu. Przed pracą w AWS Vishaal był studentem UCI, specjalizującym się w bioinformatyce i inteligentnych systemach.
Vishaala Yalamanchali jest architektem rozwiązań start-upowych współpracującym z firmami zajmującymi się generatywną sztuczną inteligencją, robotyką i pojazdami autonomicznymi na wczesnym etapie rozwoju. Vishaal współpracuje ze swoimi klientami w celu dostarczania najnowocześniejszych rozwiązań ML i osobiście jest zainteresowany uczeniem się przez wzmacnianie, oceną LLM i generowaniem kodu. Przed pracą w AWS Vishaal był studentem UCI, specjalizującym się w bioinformatyce i inteligentnych systemach.
 Meenakshisundaram Tandavarayan pracuje w AWS jako Specjalista AI/ML. Jego pasją jest projektowanie, tworzenie i promowanie danych i rozwiązań analitycznych skupionych na człowieku. Meena koncentruje się na rozwoju zrównoważonych systemów, które zapewniają wymierne, konkurencyjne przewagi dla strategicznych klientów AWS. Meena jest łącznikiem i myślicielem projektowym, stara się kierować firmy na nowe sposoby pracy poprzez innowacje, inkubację i demokratyzację.
Meenakshisundaram Tandavarayan pracuje w AWS jako Specjalista AI/ML. Jego pasją jest projektowanie, tworzenie i promowanie danych i rozwiązań analitycznych skupionych na człowieku. Meena koncentruje się na rozwoju zrównoważonych systemów, które zapewniają wymierne, konkurencyjne przewagi dla strategicznych klientów AWS. Meena jest łącznikiem i myślicielem projektowym, stara się kierować firmy na nowe sposoby pracy poprzez innowacje, inkubację i demokratyzację.
 Dr Ashish Khetan jest starszym naukowcem z wbudowanymi algorytmami Amazon SageMaker i pomaga rozwijać algorytmy uczenia maszynowego. Doktoryzował się na University of Illinois Urbana-Champaign. Jest aktywnym badaczem uczenia maszynowego i wnioskowania statystycznego oraz opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
Dr Ashish Khetan jest starszym naukowcem z wbudowanymi algorytmami Amazon SageMaker i pomaga rozwijać algorytmy uczenia maszynowego. Doktoryzował się na University of Illinois Urbana-Champaign. Jest aktywnym badaczem uczenia maszynowego i wnioskowania statystycznego oraz opublikował wiele artykułów na konferencjach NeurIPS, ICML, ICLR, JMLR, ACL i EMNLP.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/machine-learning/fine-tune-code-llama-on-amazon-sagemaker-jumpstart/

