koron zaopatruje browary, rozlewnie napojów i producentów żywności na całym świecie w indywidualne maszyny i kompletne linie produkcyjne. Każdego dnia miliony szklanych butelek, puszek i pojemników PET przepływają przez linię Krones. Linie produkcyjne to złożone systemy, w których występuje wiele możliwych błędów, które mogą zablokować linię i zmniejszyć wydajność produkcji. Krones chce wykryć awarię tak wcześnie, jak to możliwe (czasami nawet zanim ona nastąpi) i powiadomić operatorów linii produkcyjnych, aby zwiększyć niezawodność i wydajność. Jak zatem wykryć awarię? Krones wyposaża swoje linie w czujniki do gromadzenia danych, które można następnie oceniać pod kątem zasad. Krones, jako producent linii, jak i operator linii, ma możliwość tworzenia reguł monitorowania maszyn. Dlatego rozlewnie napojów i inni operatorzy mogą zdefiniować własny margines błędu dla linii. W przeszłości Krones korzystał z systemu opartego na bazie danych szeregów czasowych. Główne wyzwania polegały na tym, że system był trudny do debugowania, a zapytania reprezentowały bieżący stan maszyn, ale nie zmiany stanów.
W tym poście pokazano, jak firma Krones zbudowała rozwiązanie do przesyłania strumieniowego do monitorowania swoich linii Amazonka Kinesis i Usługa zarządzana przez Amazon dla Apache Flink. Te w pełni zarządzane usługi zmniejszają złożoność tworzenia aplikacji do przesyłania strumieniowego za pomocą Apache Flink. Usługa zarządzana dla Apache Flink zarządza podstawowymi komponentami Apache Flink, które zapewniają trwały stan aplikacji, metryki, dzienniki i nie tylko, a Kinesis umożliwia ekonomiczne przetwarzanie danych przesyłanych strumieniowo w dowolnej skali. Jeśli chcesz rozpocząć pracę z własną aplikacją Apache Flink, zapoznaj się z Repozytorium GitHub dla przykładów korzystających z interfejsów API Java, Python lub SQL firmy Flink.
Przegląd rozwiązania
Monitorowanie linii Krones jest częścią Wytyczne Krones dotyczące hali produkcyjnej system. Zapewnia wsparcie w organizacji, ustalaniu priorytetów, zarządzaniu i dokumentowaniu wszelkich działań w firmie. Umożliwia powiadomienie operatora, jeśli maszyna jest zatrzymana lub potrzebne są materiały, niezależnie od tego, gdzie operator znajduje się na linii. Sprawdzone reguły monitorowania stanu są już wbudowane, ale można je również zdefiniować za pomocą interfejsu użytkownika. Na przykład, jeśli określony monitorowany punkt danych przekracza próg, na linii może pojawić się wiadomość tekstowa lub sygnał wyzwalający zlecenie konserwacji.
System monitorowania stanu i oceny reguł zbudowany jest na platformie AWS, wykorzystując usługi analityczne AWS. Poniższy diagram ilustruje architekturę.
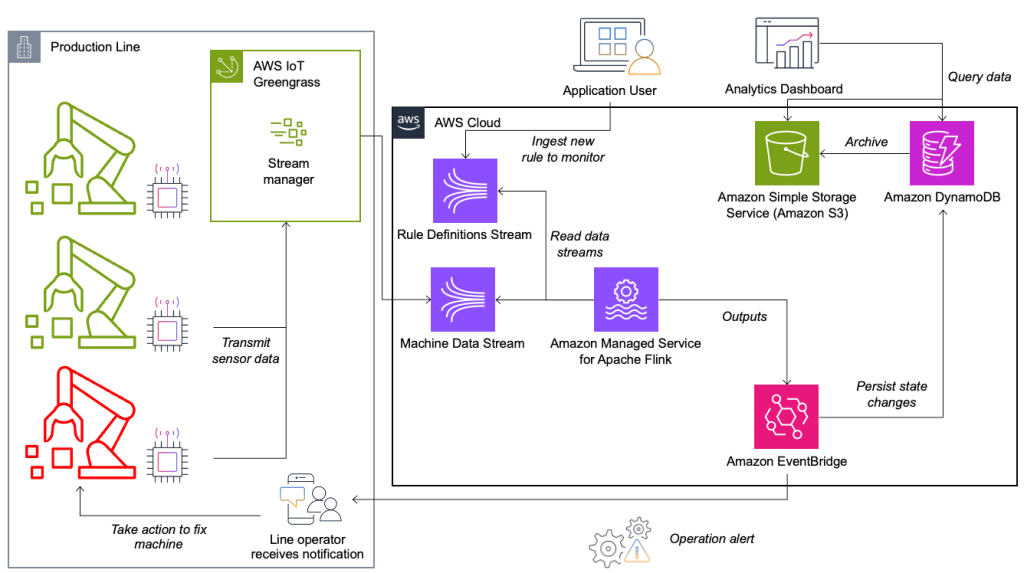
Prawie każda aplikacja do przesyłania strumieniowego danych składa się z pięciu warstw: źródła danych, pozyskiwania strumieni, przechowywania strumieni, przetwarzania strumieni i co najmniej jednego miejsca docelowego. W kolejnych sekcjach szczegółowo przyjrzymy się każdej warstwie i szczegółowo omówimy działanie rozwiązania do monitorowania linii, stworzonego przez Krones.
Źródło danych
Dane są zbierane przez usługę działającą na urządzeniu brzegowym, czytającą kilka protokołów, takich jak Siemens S7 lub OPC/UA. Surowe dane są wstępnie przetwarzane w celu utworzenia ujednoliconej struktury JSON, co ułatwia ich późniejsze przetwarzanie w silniku reguł. Przykładowy ładunek przekonwertowany do formatu JSON może wyglądać następująco:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Przetwarzanie strumieniowe
Zielona trawa AWS IoT to środowisko wykonawcze i usługa w chmurze typu open source Internetu rzeczy (IoT). Dzięki temu możesz działać lokalnie na danych oraz agregować i filtrować dane dotyczące urządzeń. AWS IoT Greengrass udostępnia gotowe komponenty, które można wdrożyć na urządzeniach brzegowych. Rozwiązanie linii produkcyjnej wykorzystuje komponent stream managera, który może przetwarzać dane i przesyłać je do miejsc docelowych AWS takich jak Analityka AWS IoT, Usługa Amazon Simple Storage (Amazon S3) i Kinesis. Menedżer strumienia buforuje i agreguje rekordy, a następnie wysyła je do strumienia danych Kinesis.
Przechowywanie strumieniowe
Zadaniem magazynu strumieniowego jest buforowanie komunikatów w sposób odporny na błędy i udostępnianie ich do wykorzystania przez jedną lub więcej aplikacji konsumenckich. Aby to osiągnąć w AWS, najpopularniejszymi technologiami są Kinesis i Przesyłanie strumieniowe zarządzane przez Amazon dla Apache Kafka (Amazon MSK). Do przechowywania danych z czujników z linii produkcyjnych Krones wybiera Kinesis. Kinesis to bezserwerowa usługa przesyłania strumieniowego danych, która działa w dowolnej skali i charakteryzuje się niskimi opóźnieniami. Fragmenty w strumieniu danych Kinesis to jednoznacznie zidentyfikowana sekwencja rekordów danych, gdzie strumień składa się z jednego lub większej liczby fragmentów. Każdy fragment ma pojemność odczytu 2 MB/s i pojemność zapisu 1 MB/s (przy maksymalnie 1,000 rekordów/s). Aby uniknąć przekroczenia tych limitów, dane powinny być dystrybuowane pomiędzy fragmentami możliwie równomiernie. Każdy rekord wysyłany do Kinesis ma klucz partycji, który służy do grupowania danych w fragment. Dlatego chcesz mieć dużą liczbę kluczy partycji, aby równomiernie rozłożyć obciążenie. Menedżer strumieni działający na platformie AWS IoT Greengrass obsługuje losowe przypisania kluczy partycji, co oznacza, że wszystkie rekordy trafiają do losowego fragmentu, a obciążenie jest rozkładane równomiernie. Wadą losowego przypisania kluczy partycji jest to, że rekordy nie są przechowywane w kolejności w Kinesis. Wyjaśnimy, jak rozwiązać ten problem w następnej sekcji, gdzie mówimy o znakach wodnych.
Znaki wodne
A watermark to mechanizm używany do śledzenia i pomiaru postępu czasu zdarzenia w strumieniu danych. Czas zdarzenia to sygnatura czasowa od momentu utworzenia zdarzenia w źródle. Znak wodny wskazuje aktualny postęp aplikacji przetwarzającej strumień, więc wszystkie zdarzenia z wcześniejszym lub równym znacznikiem czasu są uznawane za przetworzone. Informacje te są niezbędne dla Flink do przyspieszenia czasu zdarzenia i uruchomienia odpowiednich obliczeń, takich jak ocena okien. Dozwolone opóźnienie między czasem zdarzenia a znakiem wodnym można skonfigurować w celu określenia czasu oczekiwania na spóźnione dane przed uznaniem okna za ukończone i przesunięciem znaku wodnego.
Krones posiada systemy na całym świecie i musi obsługiwać spóźnienia spowodowane utratą połączenia lub innymi ograniczeniami sieci. Zaczęli od monitorowania spóźnień i ustawienia domyślnej obsługi opóźnień Flink na maksymalną wartość, jaką widzieli w tej metryce. Doświadczyli problemów z synchronizacją czasu z urządzeń brzegowych, co doprowadziło ich do bardziej wyrafinowanego sposobu znakowania wodnego. Zbudowali globalny znak wodny dla wszystkich nadawców i użyli najniższej wartości jako znaku wodnego. Sygnatury czasowe są przechowywane w HashMap dla wszystkich przychodzących zdarzeń. Kiedy znaki wodne są emitowane okresowo, używana jest najmniejsza wartość tej HashMap. Aby uniknąć blokowania znaków wodnych z powodu brakujących danych, skonfigurowano moduł idleTimeOut parametr, który ignoruje znaczniki czasu starsze niż określony próg. Zwiększa to opóźnienia, ale zapewnia dużą spójność danych.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Przetwarzanie strumienia
Po zebraniu danych z czujników i wchłonięciu ich do Kinesis, muszą one zostać ocenione przez silnik reguł. Reguła w tym systemie reprezentuje stan pojedynczej metryki (takiej jak temperatura) lub zbiór metryk. Do interpretacji metryki używany jest więcej niż jeden punkt danych, co jest obliczeniem stanowym. W tej sekcji zagłębiamy się w stan klucza i stan rozgłaszania w Apache Flink oraz w jaki sposób są one wykorzystywane do tworzenia silnika reguł Krones.
Sterowanie strumieniem i wzorcem stanu rozgłaszania
W Apache Flink, były odnosi się do zdolności systemu do trwałego przechowywania informacji i zarządzania nimi w czasie i operacjach, umożliwiając przetwarzanie danych przesyłanych strumieniowo z obsługą obliczeń stanowych.
Połączenia wzorzec stanu rozgłoszeniowego umożliwia dystrybucję stanu na wszystkie równoległe instancje operatora. Dlatego wszyscy operatorzy mają ten sam stan i dane mogą być przetwarzane przy użyciu tego samego stanu. Te dane tylko do odczytu można pozyskać przy użyciu strumienia sterującego. Strumień kontrolny to zwykły strumień danych, ale zwykle o znacznie niższej szybkości transmisji danych. Ten wzorzec umożliwia dynamiczną aktualizację stanu wszystkich operatorów, umożliwiając użytkownikowi zmianę stanu i zachowania aplikacji bez konieczności ponownego wdrażania. Dokładniej, dystrybucja stanu odbywa się za pomocą strumienia kontrolnego. Dodając nowy rekord do strumienia kontrolnego, wszyscy operatorzy otrzymują tę aktualizację i wykorzystują nowy stan do przetwarzania nowych komunikatów.
Dzięki temu użytkownicy aplikacji Krones mogą przyjmować nowe reguły do aplikacji Flink bez konieczności jej ponownego uruchamiania. Pozwala to uniknąć przestojów i zapewnia użytkownikom doskonałe wrażenia, gdy zmiany zachodzą w czasie rzeczywistym. Reguła obejmuje scenariusz w celu wykrycia odchylenia od procesu. Czasami dane maszynowe nie są tak łatwe do interpretacji, jak mogłoby się wydawać na pierwszy rzut oka. Jeśli czujnik temperatury wysyła wysokie wartości, może to wskazywać na błąd, ale może być również skutkiem trwającej procedury konserwacyjnej. Ważne jest, aby umieścić dane w kontekście i przefiltrować niektóre wartości. Osiąga się to dzięki koncepcji tzw grupowanie.
Grupowanie metryk
Grupowanie danych i metryk umożliwia zdefiniowanie istotności przychodzących danych i uzyskanie dokładnych wyników. Przeanalizujmy przykład na poniższym rysunku.
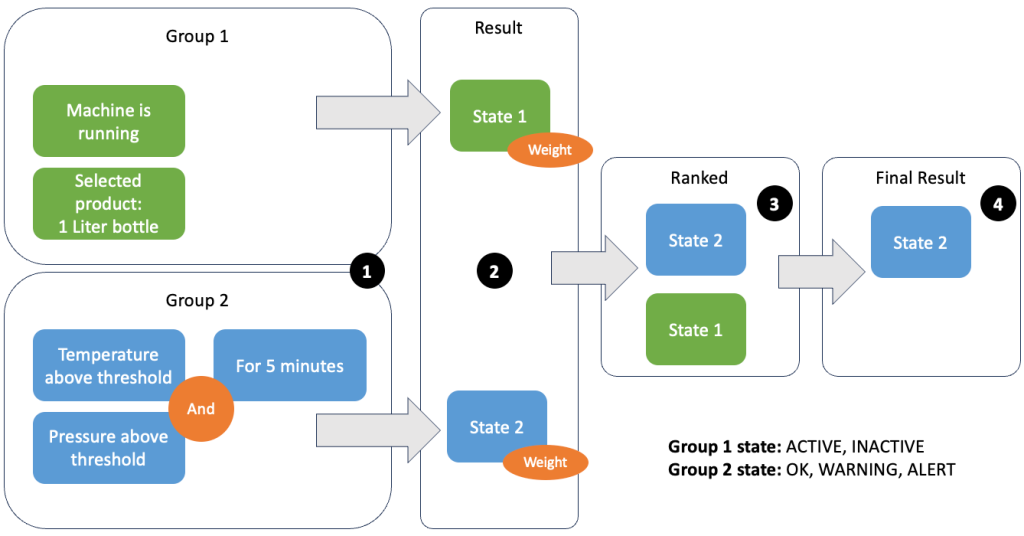
W kroku 1 definiujemy dwie grupy warunków. Grupa 1 zbiera stan maszyny i jaki produkt przechodzi przez linię. Grupa 2 korzysta z wartości czujników temperatury i ciśnienia. Grupa warunków może mieć różne stany w zależności od otrzymywanych wartości. W tym przykładzie grupa 1 otrzymuje dane, że maszyna pracuje, a jako produkt wybierana jest butelka o pojemności jednego litra; to daje tej grupie stan ACTIVE. Grupa 2 zawiera wskaźniki temperatury i ciśnienia; oba wskaźniki są powyżej swoich progów przez ponad 5 minut. Powoduje to, że grupa 2 znajduje się w a WARNING państwo. Oznacza to, że grupa 1 zgłasza, że wszystko jest w porządku, a grupa 2 – nie. W kroku 2 do grup dodawane są wagi. Jest to potrzebne w niektórych sytuacjach, ponieważ grupy mogą zgłaszać sprzeczne informacje. W tym scenariuszu raporty grupy 1 ACTIVE i raporty grupy 2 WARNING, więc dla systemu nie jest jasne, jaki jest stan linii. Po dodaniu wag stany można uszeregować, jak pokazano w kroku 3. Na koniec, jako zwycięski zostaje wybrany stan o najwyższej randze, jak pokazano w kroku 4.
Po ocenie reguł i określeniu ostatecznego stanu maszyny wyniki zostaną poddane dalszej obróbce. Podjęte działanie zależy od konfiguracji reguły; może to być powiadomienie operatora linii o konieczności uzupełnienia materiałów, przeprowadzenia konserwacji lub po prostu wizualna aktualizacja na desce rozdzielczej. Ta część systemu, która ocenia wskaźniki i reguły oraz podejmuje działania w oparciu o wyniki, nazywana jest: silnik reguł.
Skalowanie silnika reguł
Umożliwiając użytkownikom tworzenie własnych reguł, silnik reguł może zawierać dużą liczbę reguł, które musi ocenić, a niektóre reguły mogą korzystać z tych samych danych z czujnika, co inne reguły. Flink to system rozproszony, który bardzo dobrze skaluje się w poziomie. Aby rozdzielić strumień danych na kilka zadań, możesz użyć metody keyBy() metoda. Umożliwia to logiczny podział strumienia danych i wysyłanie części danych do różnych menedżerów zadań. Często odbywa się to poprzez wybranie dowolnego klucza, aby uzyskać równomiernie rozłożone obciążenie. W tym przypadku Krones dodał ruleId do punktu danych i użył go jako klucza. W przeciwnym razie potrzebne punkty danych są przetwarzane przez inne zadanie. Kluczowy strumień danych można stosować we wszystkich regułach, tak jak zwykłą zmienną.
Kierunki
Kiedy reguła zmienia swój stan, informacja jest wysyłana do strumienia Kinesis, a następnie przez Most zdarzeń Amazona konsumentom. Jeden z odbiorców tworzy powiadomienie o zdarzeniu, które przekazywane jest na linię produkcyjną i powiadamia personel o konieczności działania. Aby móc analizować zmiany stanu reguły, inna usługa zapisuje dane do pliku Amazon DynamoDB tabela zapewniająca szybki dostęp, a także TTL, który umożliwia przesyłanie długoterminowej historii do Amazon S3 w celu dalszego raportowania.
Wnioski
W tym poście pokazaliśmy, jak Krones zbudował system monitorowania linii produkcyjnej w czasie rzeczywistym na AWS. Usługa zarządzana dla Apache Flink umożliwiła zespołowi Krones szybkie rozpoczęcie pracy, koncentrując się na rozwoju aplikacji, a nie na infrastrukturze. Możliwości Flink działające w czasie rzeczywistym umożliwiły firmie Krones skrócenie przestojów maszyn o 10% i zwiększenie wydajności aż do 5%.
Jeśli chcesz zbudować własne aplikacje do przesyłania strumieniowego, sprawdź dostępne próbki na stronie Repozytorium GitHub. Jeśli chcesz rozszerzyć swoją aplikację Flink o niestandardowe konektory, zobacz Ułatwianie tworzenia łączników za pomocą Apache Flink: Przedstawiamy zlew asynchroniczny. Async Sink jest dostępny w Apache Flink w wersji 1.15.1 i nowszych.
O autorach
 Floriana Maira jest starszym architektem rozwiązań i ekspertem ds. strumieniowania danych w AWS. Jest technologiem, który pomaga klientom w Europie odnosić sukcesy i wprowadzać innowacje, rozwiązując wyzwania biznesowe za pomocą usług AWS Cloud. Oprócz pracy jako architekt rozwiązań Florian jest zapalonym alpinistą i wspiął się na jedne z najwyższych gór w Europie.
Floriana Maira jest starszym architektem rozwiązań i ekspertem ds. strumieniowania danych w AWS. Jest technologiem, który pomaga klientom w Europie odnosić sukcesy i wprowadzać innowacje, rozwiązując wyzwania biznesowe za pomocą usług AWS Cloud. Oprócz pracy jako architekt rozwiązań Florian jest zapalonym alpinistą i wspiął się na jedne z najwyższych gór w Europie.
 Emil Dietl jest starszym liderem technicznym w Krones, specjalizującym się w inżynierii danych, z kluczowym obszarem w Apache Flink i mikrousługach. Jego praca często wiąże się z rozwojem i utrzymaniem oprogramowania o znaczeniu krytycznym. Poza życiem zawodowym bardzo ceni sobie spędzanie czasu z rodziną.
Emil Dietl jest starszym liderem technicznym w Krones, specjalizującym się w inżynierii danych, z kluczowym obszarem w Apache Flink i mikrousługach. Jego praca często wiąże się z rozwojem i utrzymaniem oprogramowania o znaczeniu krytycznym. Poza życiem zawodowym bardzo ceni sobie spędzanie czasu z rodziną.
 Szymon Peyer jest architektem rozwiązań w AWS z siedzibą w Szwajcarii. Jest praktycznym wykonawcą i pasjonuje się łączeniem technologii i ludzi korzystających z usług AWS Cloud. Szczególną uwagę skupia na strumieniowaniu danych i automatyzacji. Oprócz pracy Simon lubi rodzinę, spędzać czas na świeżym powietrzu i wędrować po górach.
Szymon Peyer jest architektem rozwiązań w AWS z siedzibą w Szwajcarii. Jest praktycznym wykonawcą i pasjonuje się łączeniem technologii i ludzi korzystających z usług AWS Cloud. Szczególną uwagę skupia na strumieniowaniu danych i automatyzacji. Oprócz pracy Simon lubi rodzinę, spędzać czas na świeżym powietrzu i wędrować po górach.
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

