Wprowadzenie
Sercem nauka danych kryje się statystyka, która istnieje od wieków, a mimo to pozostaje niezwykle istotna w dzisiejszej epoce cyfrowej. Dlaczego? Ponieważ podstawowe pojęcia statystyczne są podstawą analiza danych, co pozwala nam zrozumieć ogromne ilości danych generowanych codziennie. To jak rozmowa z danymi, gdzie statystyki pomagają nam zadawać właściwe pytania i rozumieć historie, które dane próbują opowiedzieć.
Od przewidywania przyszłych trendów i podejmowania decyzji na podstawie danych po testowanie hipotez i mierzenie wydajności – statystyka to narzędzie, które pozwala wyciągać wnioski i podejmować decyzje oparte na danych. Stanowi pomost pomiędzy surowymi danymi a praktycznymi spostrzeżeniami, co czyni go nieodzowną częścią nauki o danych.
W tym artykule zebrałem 15 najważniejszych podstawowych pojęć statystycznych, które powinien znać każdy początkujący analityk danych!

Spis treści
1. Próbkowanie statystyczne i gromadzenie danych
Nauczymy się kilku podstawowych pojęć związanych ze statystyką, ale zrozumienie, skąd pochodzą nasze dane i w jaki sposób je gromadzimy, jest niezbędne, zanim zagłębimy się w ocean danych. W tym miejscu w grę wchodzą populacje, próbki i różne techniki pobierania próbek.
Wyobraź sobie, że chcemy poznać średni wzrost ludzi w mieście. Pomiar wszystkich jest praktyczny, dlatego bierzemy mniejszą grupę (próbkę) reprezentującą większą populację. Sztuka polega na tym, jak wybrać tę próbkę. Techniki takie jak próbkowanie losowe, warstwowe lub klastrowe zapewniają dobrą reprezentację naszej próby, minimalizując stronniczość i zwiększając wiarygodność naszych wyników.
Rozumiejąc populacje i próbki, możemy z całą pewnością rozszerzyć nasze spostrzeżenia z próbki na całą populację, podejmując świadome decyzje bez konieczności przeprowadzania ankiety u wszystkich.
2. Rodzaje danych i skale pomiarowe
Dane mają różną postać, a znajomość rodzaju danych, z którymi masz do czynienia, ma kluczowe znaczenie przy wyborze odpowiednich narzędzi i technik statystycznych.
Dane ilościowe i jakościowe
- Dane ilościowe: Tego typu dane dotyczą przede wszystkim liczb. Jest mierzalny i można go wykorzystać do obliczeń matematycznych. Dane ilościowe mówią nam „ile” lub „ile”, np. liczba użytkowników odwiedzających witrynę lub temperatura w mieście. Jest prosty i obiektywny, zapewnia jasny obraz za pomocą wartości liczbowych.
- Dane jakościowe: I odwrotnie, dane jakościowe dotyczą cech i opisów. Chodzi o „jaki typ” lub „jaka kategoria”. Pomyśl o tym jak o danych opisujących cechy lub atrybuty, takie jak kolor samochodu lub gatunek książki. Dane te są subiektywne i opierają się na obserwacjach, a nie na pomiarach.
Cztery skale pomiaru
- Nominalna skala: Jest to najprostsza forma pomiaru służąca do kategoryzowania danych bez określonej kolejności. Przykładami mogą tu być: rodzaj kuchni, grupy krwi lub narodowość. Chodzi o etykietowanie bez wartości ilościowej.
- Skala porządkowa: Dane można tutaj uporządkować lub uszeregować, ale odstępy między wartościami nie są zdefiniowane. Pomyśl o ankiecie satysfakcji z opcjami takimi jak zadowolony, neutralny i niezadowolony. Informuje nas o kolejności, ale nie o odległości pomiędzy rankingami.
- Skala interwałowa: Skalowanie interwałowe porządkuje dane i określa ilościowo różnicę między wpisami. Jednak nie ma rzeczywistego punktu zerowego. Dobrym przykładem jest temperatura w stopniach Celsjusza; różnica między 10°C a 20°C jest taka sama jak między 20°C a 30°C, ale 0°C nie oznacza braku temperatury.
- Skala proporcji: Najbardziej pouczająca skala ma wszystkie właściwości skali interwałowej plus znaczący punkt zerowy, pozwalający na dokładne porównanie wielkości. Przykładami mogą być waga, wzrost i dochód. Tutaj możemy powiedzieć, że coś jest dwa razy większe od drugiego.
3. Opisowe statystyki
Imagine opisowe statystyki jako pierwsza randka z Twoimi danymi. Chodzi o poznanie podstaw, ogólnych pociągnięć opisujących to, co jest przed tobą. Statystyka opisowa ma dwa główne typy: miary tendencji centralnej i miary zmienności.
Miary tendencji centralnej: Są jak środek ciężkości danych. Dają nam pojedynczą wartość typową lub reprezentatywną dla naszego zbioru danych.
Oznaczać: Średnią oblicza się, dodając wszystkie wartości i dzieląc przez liczbę wartości. To jak ogólna ocena restauracji na podstawie wszystkich recenzji. Poniżej podano wzór matematyczny na średnią:

Mediana: Wartość środkowa, gdy dane są uporządkowane od najmniejszej do największej. Jeśli liczba obserwacji jest parzysta, jest to średnia z dwóch środkowych liczb. Służy do znajdowania środkowego punktu mostu.
Jeśli n jest parzyste, mediana jest średnią dwóch liczb środkowych.
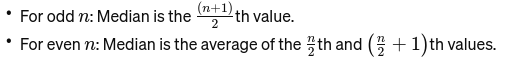
Tryb: To jest najczęściej występująca wartość w zbiorze danych. Pomyśl o tym jak o najpopularniejszym daniu w restauracji.
Miary zmienności: Podczas gdy miary tendencji centralnej prowadzą nas do centrum, miary zmienności mówią nam o rozproszeniu lub rozproszeniu.
Zakres: Różnica pomiędzy najwyższą i najniższą wartością. Daje podstawowe pojęcie o rozprzestrzenianiu się.
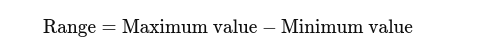
Zmienność: Mierzy, jak daleko każda liczba w zestawie znajduje się od średniej, a tym samym od każdej innej liczby w zestawie. Dla próbki jest to obliczane jako:
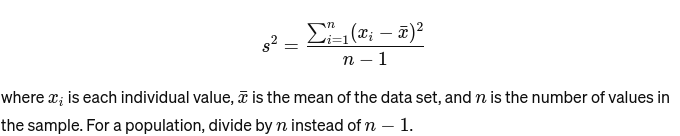
Odchylenie standardowe: Pierwiastek kwadratowy wariancji stanowi miarę średniej odległości od średniej. To jak ocenianie konsystencji ciasta piekarza. Jest reprezentowany jako:
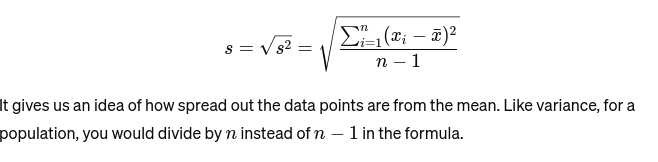
Zanim przejdziemy do kolejnego podstawowego pojęcia statystyki, oto: Przewodnik dla początkujących po analizie statystycznej dla Ciebie!
4. Wizualizacja danych
Wizualizacja danych to sztuka i nauka opowiadania historii za pomocą danych. Zamienia złożone wyniki naszej analizy w coś namacalnego i zrozumiałego. Ma to kluczowe znaczenie w przypadku eksploracyjnej analizy danych, której celem jest odkrycie wzorców, korelacji i wniosków z danych bez wyciągania jeszcze formalnych wniosków.
- Wykresy i wykresy: Zaczynając od podstaw, wykresy słupkowe, wykresy liniowe i wykresy kołowe zapewniają podstawowy wgląd w dane. Stanowią one ABC wizualizacji danych, niezbędne każdemu opowiadaczowi danych.
Poniżej mamy przykład wykresu słupkowego (po lewej) i wykresu liniowego (po prawej).
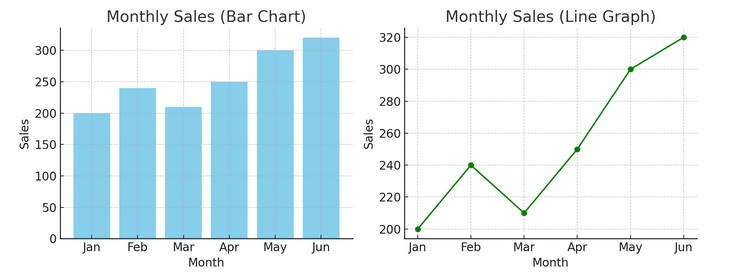
- Zaawansowane wizualizacje: Gdy nurkujemy głębiej, mapy cieplne, wykresy punktowe i histogramy pozwalają na bardziej zniuansowaną analizę. Narzędzia te pomagają identyfikować trendy, rozkłady i wartości odstające.
Poniżej znajduje się przykład wykresu punktowego i histogramu

Wizualizacje łączą surowe dane i ludzkie funkcje poznawcze, umożliwiając nam szybką interpretację i nadanie sensu złożonym zbiorom danych.
5. Podstawy prawdopodobieństwa
Prawdopodobieństwo jest gramatyką języka statystyki. Chodzi o prawdopodobieństwo lub prawdopodobieństwo wystąpienia zdarzeń. Zrozumienie pojęć prawdopodobieństwa jest niezbędne do interpretacji wyników statystycznych i formułowania prognoz.
- Zdarzenia niezależne i zależne:
- Niezależne wydarzenia: Wynik jednego zdarzenia nie wpływa na wynik innego. Podobnie jak w rzucie monetą, wyrzucenie orła w jednym rzucie nie zmienia szans na następny rzut.
- Zdarzenia zależne: Wynik jednego zdarzenia wpływa na wynik innego. Na przykład, jeśli dobierzesz kartę z talii i jej nie zastąpisz, Twoje szanse na wylosowanie innej konkretnej karty zmienią się.
Prawdopodobieństwo stanowi podstawę do wyciągania wniosków na temat danych i ma kluczowe znaczenie dla zrozumienia istotności statystycznej i testowania hipotez.
6. Wspólne rozkłady prawdopodobieństwa
Rozkłady prawdopodobieństwa są jak różne gatunki w ekosystemie statystycznym, każdy dostosowany do swojej niszy zastosowań.
- Normalna dystrybucja: Często nazywany krzywą dzwonową ze względu na swój kształt, rozkład ten charakteryzuje się średnią i odchyleniem standardowym. Jest to powszechne założenie w wielu testach statystycznych, ponieważ wiele zmiennych ma naturalny rozkład w świecie rzeczywistym.
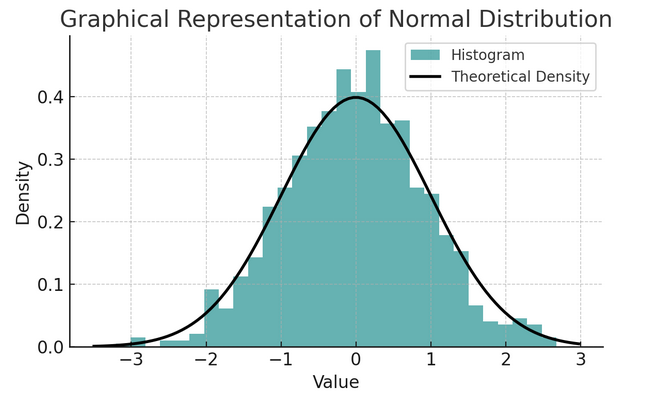
Zestaw reguł znany jako reguła empiryczna lub reguła 68-95-99.7 podsumowuje cechy rozkładu normalnego, który opisuje, w jaki sposób dane są rozłożone wokół średniej.
Reguła 68-95-99.7 (Reguła empiryczna)
Zasada ta ma zastosowanie do rozkładu całkowicie normalnego i opisuje co następuje:
- 68% danych mieści się w jednym odchyleniu standardowym (σ) średniej (μ).
- 95% danych mieści się w granicach dwóch odchyleń standardowych od średniej.
- W przybliżeniu 99.7% danych mieści się w granicach trzech odchyleń standardowych od średniej.
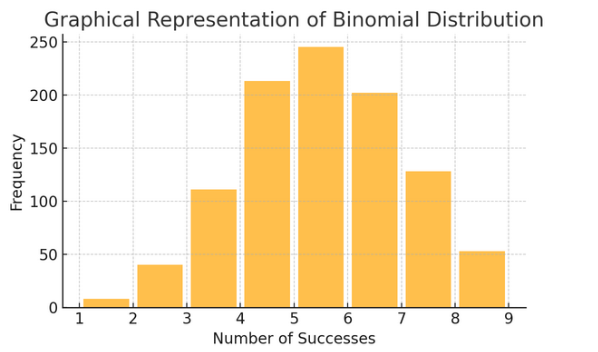
Rozkład dwumianowy: Rozkład ten dotyczy sytuacji, w których dwa wyniki (takie jak sukces lub porażka) powtarzają się kilka razy. Pomaga modelować zdarzenia, takie jak rzut monetą lub wykonanie testu prawda/fałsz.
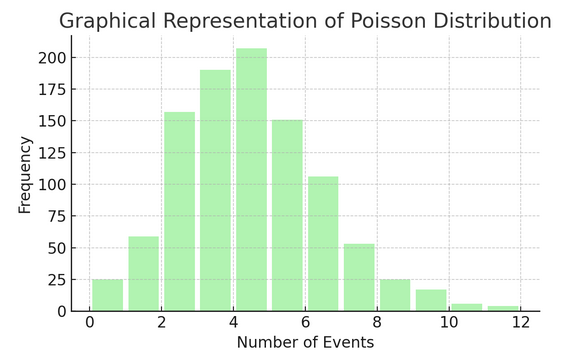
Dystrybucja Poissona liczy, ile razy coś dzieje się w określonym przedziale lub przestrzeni. Jest to idealne rozwiązanie w sytuacjach, w których zdarzenia dzieją się niezależnie i stale, jak np. codzienne otrzymywane e-maile.
Każda dystrybucja ma swój własny zestaw formuł i cech, a wybór właściwego zależy od charakteru danych i tego, czego próbujesz się dowiedzieć. Zrozumienie tych rozkładów pozwala statystykom i badaczom danych modelować zjawiska w świecie rzeczywistym i dokładnie przewidywać przyszłe zdarzenia.
7. Testowanie hipotez
Myśleć testowanie hipotez jako praca detektywistyczna w statystyce. Jest to metoda sprawdzania, czy dana teoria dotycząca naszych danych może być prawdziwa. Proces ten rozpoczyna się od dwóch przeciwstawnych hipotez:
- Hipoteza zerowa (H0): Jest to założenie domyślne, sugerujące istnienie efektu lub różnicy. To znaczy: „Nie” tu jesteśmy nowi.
- Al „alternatywna hipoteza (H1 lub Ha): Podważa to status quo, proponując efekt lub różnicę. Twierdzi, że „dzieje się coś interesującego”.
Przykład: Badanie, czy nowy program diety prowadzi do utraty wagi w porównaniu z niestosowaniem żadnej diety.
- Hipoteza zerowa (H0): Nowy program dietetyczny nie prowadzi do utraty wagi (nie ma różnicy w utracie wagi pomiędzy osobami stosującymi nowy program dietetyczny i tymi, którzy go nie stosują).
- Hipoteza alternatywna (H1): Nowy program dietetyczny prowadzi do utraty wagi (różnica w utracie wagi pomiędzy tymi, którzy go przestrzegają, a tymi, którzy tego nie robią).
Testowanie hipotez polega na wyborze między nimi w oparciu o dowody (nasze dane).
Błędy typu I i II oraz poziomy istotności:
- Błąd typu I: Dzieje się tak, gdy błędnie odrzucimy hipotezę zerową. Skazuje niewinną osobę.
- Błąd typu II: Dzieje się tak, gdy nie odrzucimy fałszywej hipotezy zerowej. Pozwala winnemu wyjść na wolność.
- Poziom istotności (α): To jest próg decydujący o tym, ile dowodów wystarczy do odrzucenia hipotezy zerowej. Często ustawia się go na 5% (0.05), co wskazuje na 5% ryzyko błędu typu I.
8. Przedziały ufności
Przedziały ufności Podaj nam zakres wartości, w obrębie którego spodziewamy się, że prawidłowy parametr populacji (taki jak średnia lub proporcja) będzie się mieścić w określonym poziomie ufności (zwykle 95%). To jak przewidywanie końcowego wyniku drużyny sportowej z marginesem błędu; mówimy: „Jesteśmy w 95% pewni, że prawdziwy wynik będzie mieścić się w tym zakresie”.
Konstruowanie i interpretowanie przedziałów ufności pomaga nam zrozumieć precyzję naszych szacunków. Im szerszy przedział, tym mniej dokładne jest nasze oszacowanie i odwrotnie.
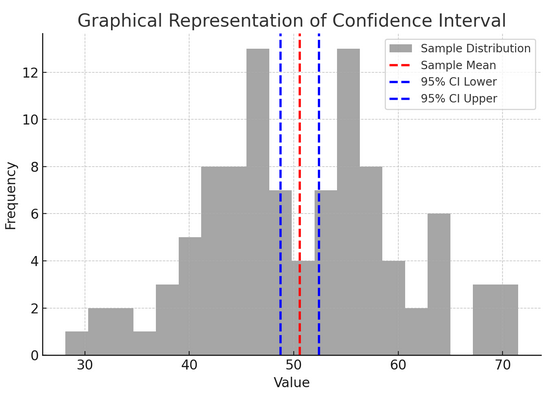
Powyższy rysunek ilustruje koncepcję przedziału ufności (CI) w statystyce, wykorzystując rozkład próbki i jego 95% przedział ufności wokół średniej próbki.
Oto zestawienie najważniejszych elementów na rysunku:
- Rozkład próbek (szary histogram): Przedstawia to rozkład 100 punktów danych wygenerowanych losowo z rozkładu normalnego ze średnią 50 i odchyleniem standardowym 10. Histogram wizualnie przedstawia rozkład punktów danych wokół średniej.
- Średnia próbki (czerwona linia przerywana): Ta linia wskazuje średnią (średnią) wartość danych próbki. Służy jako oszacowanie punktowe, wokół którego konstruujemy przedział ufności. W tym przypadku reprezentuje średnią wszystkich wartości próbek.
- 95% przedział ufności (niebieskie linie przerywane): Te dwie linie wyznaczają dolną i górną granicę 95% przedziału ufności wokół średniej próbki. Przedział oblicza się przy użyciu błędu standardowego średniej (SEM) i wyniku Z odpowiadającego pożądanemu poziomowi ufności (1.96 dla 95% ufności). Przedział ufności sugeruje, że mamy 95% pewności, że średnia populacji mieści się w tym zakresie.
9. Korelacja i przyczynowość
Korelacja i przyczynowość często się mylą, ale są różne:
- Korelacja: Wskazuje związek lub powiązanie między dwiema zmiennymi. Kiedy jedno się zmienia, drugie też się zmienia. Korelację mierzy się współczynnikiem korelacji w zakresie od -1 do 1. Wartość bliższa 1 lub -1 oznacza silny związek, natomiast 0 oznacza brak powiązania.
- Związek przyczynowy: Oznacza to, że zmiany jednej zmiennej bezpośrednio powodują zmiany w innej. Jest to stwierdzenie solidniejsze niż korelacja i wymaga rygorystycznych testów.
To, że dwie zmienne są ze sobą skorelowane, nie oznacza, że jedna powoduje drugą. Jest to klasyczny przypadek niemylenia „korelacji” z „przyczynowością”.
10. Prosta regresja liniowa
Prosty regresji liniowej to sposób modelowania zależności między dwiema zmiennymi poprzez dopasowanie równania liniowego do obserwowanych danych. Jedna zmienna jest uważana za zmienną objaśniającą (niezależną), a druga za zmienną zależną.
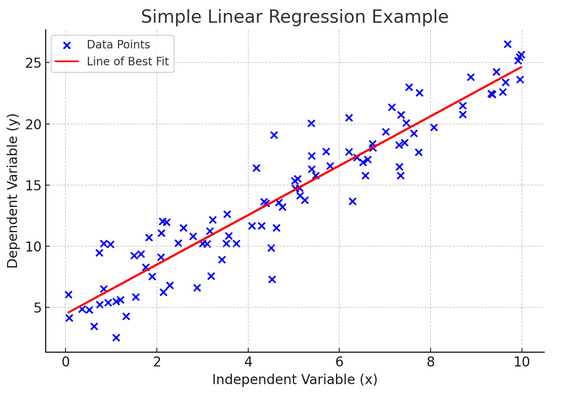
Prosta regresja liniowa pomaga nam zrozumieć, jak zmiany zmiennej niezależnej wpływają na zmienną zależną. Jest to potężne narzędzie do przewidywania i stanowi podstawę wielu innych złożonych modeli statystycznych. Analizując związek między dwiema zmiennymi, możemy dokonać świadomych przewidywań dotyczących ich interakcji.
Prosta regresja liniowa zakłada liniową zależność pomiędzy zmienną niezależną (zmienną objaśniającą) a zmienną zależną. Jeżeli związek między tymi dwiema zmiennymi nie jest liniowy, wówczas założenia prostej regresji liniowej mogą zostać naruszone, co może prowadzić do niedokładnych przewidywań lub interpretacji. Dlatego przed zastosowaniem prostej regresji liniowej niezbędna jest weryfikacja liniowej zależności w danych.
11. Wielokrotna regresja liniowa
Pomyśl o wielokrotnej regresji liniowej jako o przedłużeniu prostej regresji liniowej. Mimo to, zamiast próbować przewidzieć wynik za pomocą jednego rycerza w lśniącej zbroi (predyktor), masz całą drużynę. To jak przejście od gry w koszykówkę jeden na jednego do gry rozgrywanej przez cały zespół, w której każdy gracz (predyktor) wnosi unikalne umiejętności. Chodzi o to, aby zobaczyć, jak kilka zmiennych łącznie wpływa na pojedynczy wynik.
Jednak w przypadku większego zespołu pojawia się wyzwanie związane z zarządzaniem relacjami, znane jako wieloliniowość. Występuje, gdy predyktory są zbyt blisko siebie i dzielą się podobnymi informacjami. Wyobraź sobie dwóch koszykarzy ciągle próbujących oddać ten sam strzał; mogą sobie przeszkadzać. Regresja może utrudniać dostrzeżenie unikalnego wkładu każdego predyktora, potencjalnie wypaczając nasze zrozumienie, które zmienne są istotne.
12. Regresja logistyczna
Podczas gdy regresja liniowa przewiduje ciągłe wyniki (takie jak temperatura lub ceny), regresja logistyczna jest używane, gdy wynik jest określony (np. tak/nie, wygrana/przegrana). Wyobraź sobie, że próbujesz przewidzieć, czy zespół wygra, czy przegra na podstawie różnych czynników; regresja logistyczna to Twoja strategia.
Przekształca równanie liniowe w taki sposób, że jego wynik mieści się w przedziale od 0 do 1, co reprezentuje prawdopodobieństwo przynależności do określonej kategorii. To jak posiadanie magicznej soczewki, która przekształca ciągłe wyniki w jasny obraz „to czy tamto”, pozwalając nam przewidzieć kategoryczne wyniki.
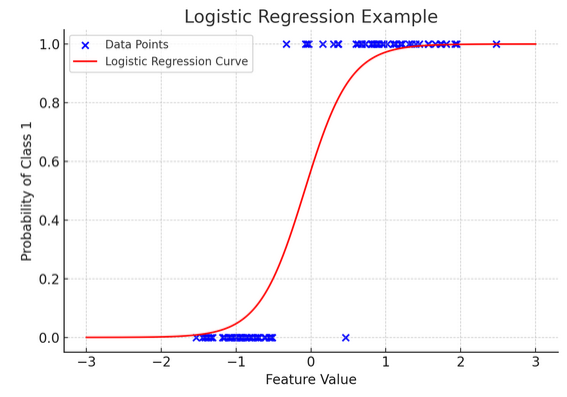
Graficzna reprezentacja ilustruje przykład regresji logistycznej zastosowanej do syntetycznego zbioru danych klasyfikacji binarnej. Niebieskie kropki reprezentują punkty danych, ich położenie wzdłuż osi x wskazuje wartość cechy, a oś y wskazuje kategorię (0 lub 1). Czerwona krzywa przedstawia prognozę modelu regresji logistycznej dotyczącą prawdopodobieństwa przynależności do klasy 1 (np. „wygrana”) dla różnych wartości cech. Jak widać, krzywa płynnie przechodzi od prawdopodobieństwa klasy 0 do klasy 1, co pokazuje zdolność modelu do przewidywania wyników kategorycznych w oparciu o podstawową cechę ciągłą.
Wzór na regresję logistyczną podaje wzór:

Formuła ta wykorzystuje funkcję logistyczną do przekształcenia wyniku równania liniowego na prawdopodobieństwo z zakresu od 0 do 1. Transformacja ta pozwala nam zinterpretować wyniki jako prawdopodobieństwa przynależności do określonej kategorii w oparciu o wartość zmiennej niezależnej xx.
13. Testy ANOVA i Chi-kwadrat
ANOVA (Analiza wariancji) i Testy chi-kwadrat są jak detektywi w świecie statystyk, pomagając nam rozwiązywać różne zagadki. It pozwala nam porównać średnie w wielu grupach, aby sprawdzić, czy przynajmniej jedna jest statystycznie różna. Pomyśl o tym jak o degustacji próbek z kilku partii ciasteczek w celu ustalenia, czy któraś partia smakuje znacząco inaczej.
Z drugiej strony test Chi-Square jest używany do danych kategorycznych. Pomaga nam zrozumieć, czy istnieje znaczący związek między dwiema zmiennymi kategorycznymi. Na przykład, czy istnieje związek pomiędzy ulubionym gatunkiem muzyki a grupą wiekową danej osoby? Test Chi-Square pomaga odpowiedzieć na takie pytania.
14. Centralne twierdzenie graniczne i jego znaczenie w nauce danych
Połączenia Centralne twierdzenie graniczne (CLT) to podstawowa zasada statystyczna, która wydaje się niemal magiczna. Mówi nam, że jeśli pobierzesz wystarczającą liczbę próbek z populacji i obliczysz ich średnie, te średnie utworzą rozkład normalny (krzywą dzwonową), niezależnie od pierwotnego rozkładu populacji. Jest to niezwykle przydatne, ponieważ pozwala nam wyciągać wnioski na temat populacji, nawet jeśli nie znamy ich dokładnego rozmieszczenia.
W nauce danych CLT stanowi podstawę wielu technik, umożliwiając nam korzystanie z narzędzi zaprojektowanych dla danych o rozkładzie normalnym, nawet jeśli nasze dane początkowo nie spełniają tych kryteriów. To jak znalezienie uniwersalnego adaptera dla metod statystycznych, dzięki któremu wiele potężnych narzędzi będzie można zastosować w większej liczbie sytuacji.
15. Kompromis odchylenia i wariancji
In modelowanie predykcyjne i uczenie maszynoweThe kompromis między stronniczością a wariancją to kluczowa koncepcja, która podkreśla napięcie między dwoma głównymi rodzajami błędów, które mogą spowodować, że nasze modele zawiodą. Odchylenie odnosi się do błędów ze zbyt uproszczonych modeli, które nie odzwierciedlają dobrze podstawowych trendów. Wyobraź sobie, że próbujesz dopasować linię prostą do zakrzywionej drogi; przegapisz znak. I odwrotnie, odchylenia od zbyt złożonych modeli wychwytują szum w danych tak, jakby był rzeczywistym wzorcem — jak śledzenie każdego zakrętu i skręcanie na wyboistej ścieżce, myśląc, że to droga do przodu.
Sztuka polega na zrównoważeniu tych dwóch elementów, aby zminimalizować całkowity błąd i znaleźć idealny punkt, w którym model jest w sam raz – na tyle złożony, aby uchwycić dokładne wzorce, ale wystarczająco prosty, aby zignorować losowy szum. To jak strojenie gitary; nie będzie brzmiało dobrze, jeśli będzie zbyt ciasne lub luźne. Kompromis odchylenia i wariancji polega na znalezieniu idealnej równowagi pomiędzy tymi dwoma elementami. Kompromis błędu systematycznego i wariancji jest istotą dostrajania naszych modeli statystycznych, aby jak najlepiej i dokładnie przewidywać wyniki.
Wnioski
Od próbkowania statystycznego po kompromis między odchyleniami a wariancją — zasady te nie są jedynie pojęciami akademickimi, ale niezbędnymi narzędziami do wnikliwej analizy danych. Wyposażają aspirujących badaczy danych w umiejętności przekształcania ogromnych danych w przydatne spostrzeżenia, kładąc nacisk na statystyki jako podstawę podejmowania decyzji w oparciu o dane i innowacji w epoce cyfrowej.
Czy przegapiliśmy jakieś podstawowe pojęcie statystyki? Daj nam znać w sekcji komentarzy poniżej.
Poznaj nasze kompleksowy przewodnik statystyczny dla analityki danych, aby dowiedzieć się na ten temat!
- Dystrybucja treści i PR oparta na SEO. Uzyskaj wzmocnienie już dziś.
- PlatoData.Network Pionowe generatywne AI. Wzmocnij się. Dostęp tutaj.
- PlatoAiStream. Inteligencja Web3. Wiedza wzmocniona. Dostęp tutaj.
- PlatonESG. Węgiel Czysta technologia, Energia, Środowisko, Słoneczny, Gospodarowanie odpadami. Dostęp tutaj.
- Platon Zdrowie. Inteligencja w zakresie biotechnologii i badań klinicznych. Dostęp tutaj.
- Źródło: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

