Dette er et gjesteinnlegg skrevet sammen med Scott Gutterman fra PGA TOUR.
Generativ kunstig intelligens (generativ AI) har muliggjort nye muligheter for å bygge intelligente systemer. Nylige forbedringer i generative AI-baserte store språkmodeller (LLM) har muliggjort bruken av dem i en rekke applikasjoner rundt informasjonsinnhenting. Gitt datakildene, ga LLM-er verktøy som ville tillate oss å bygge en Q&A-chatbot på uker, i stedet for det som kan ha tatt år tidligere, og sannsynligvis med dårligere ytelse. Vi formulerte en RAG-løsning (Retrieval-Augmented-Generation) som ville tillate PGA TOUR å lage en prototype for en fremtidig fanengasjementsplattform som kunne gjøre dataene tilgjengelige for fansen på en interaktiv måte i et samtaleformat.
Å bruke strukturerte data for å svare på spørsmål krever en måte å effektivt trekke ut data som er relevante for en brukers forespørsel. Vi formulerte en tekst-til-SQL-tilnærming der en brukers naturlige språkspørring konverteres til en SQL-setning ved hjelp av en LLM. SQL-en drives av Amazonas Athena for å returnere relevante data. Disse dataene blir igjen gitt til en LLM, som blir bedt om å svare på brukerens forespørsel gitt dataene.
Bruk av tekstdata krever en indeks som kan brukes til å søke og gi relevant kontekst til en LLM for å svare på en brukerforespørsel. For å muliggjøre rask informasjonsinnhenting bruker vi Amazon Kendra som indeks for disse dokumentene. Når brukere stiller spørsmål, søker vår virtuelle assistent raskt gjennom Amazon Kendra-indeksen for å finne relevant informasjon. Amazon Kendra bruker naturlig språkbehandling (NLP) for å forstå brukerspørsmål og finne de mest relevante dokumentene. Den relevante informasjonen blir deretter gitt til LLM for endelig responsgenerering. Vår endelige løsning er en kombinasjon av disse tekst-til-SQL- og tekst-RAG-tilnærmingene.
I dette innlegget fremhever vi hvordan AWS Generative AI Innovation Center samarbeidet med AWS profesjonelle tjenester og PGA TOUR å utvikle en prototype virtuell assistent ved hjelp av Amazonas grunnfjell som kan gjøre det mulig for fans å trekke ut informasjon om enhver begivenhet, spiller, hull- eller slagnivådetaljer på en sømløs interaktiv måte. Amazon Bedrock er en fullt administrert tjeneste som tilbyr et utvalg av høyytende fundamentmodeller (FM-er) fra ledende AI-selskaper som AI21 Labs, Anthropic, Cohere, Meta, Stability AI og Amazon via et enkelt API, sammen med et bredt sett av funksjoner du trenger for å bygge generative AI-applikasjoner med sikkerhet, personvern og ansvarlig AI.
Utvikling: Klargjøring av data
Som med alle datadrevne prosjekter, vil ytelsen bare alltid være like god som dataene. Vi behandlet dataene for å gjøre LLM i stand til å effektivt søke etter og hente relevante data.
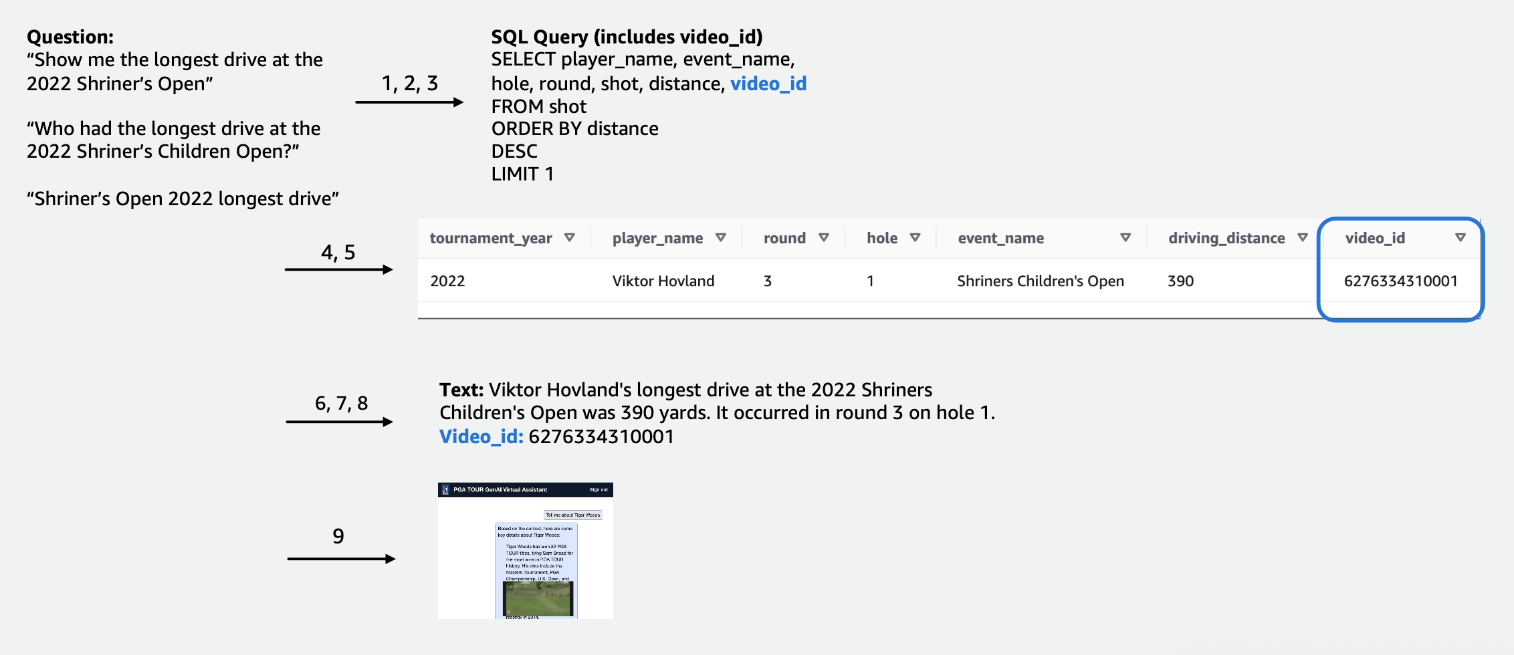
For konkurransedataene i tabellform fokuserte vi på et undersett av data som er relevante for det største antallet brukerforespørsler og merket kolonnene intuitivt, slik at de ville være lettere å forstå for LLM-er. Vi opprettet også noen hjelpekolonner for å hjelpe LLM å forstå konsepter den ellers kunne slite med. For eksempel, hvis en golfspiller skyter ett skudd mindre enn par (som for eksempel gjør det i hullet i 3 skudd på en par 4 eller i 4 skudd på en par 5), kalles det vanligvis en birdie. Hvis en bruker spør «Hvor mange birdies gjorde spiller X i fjor?», er det ikke tilstrekkelig å bare ha poengsum og par i tabellen. Som et resultat la vi til kolonner for å indikere vanlige golfbegreper, som bogey, birdie og eagle. I tillegg koblet vi konkurransedataene med en egen videosamling, ved å bli med i en kolonne for en video_id, som vil tillate appen vår å trekke videoen knyttet til et bestemt skudd i konkurransedataene. Vi har også muliggjort å slå sammen tekstdata til tabelldataene, for eksempel å legge til biografier for hver spiller som en tekstkolonne. De følgende figurene viser trinn-for-trinn-prosedyren for hvordan en spørring behandles for tekst-til-SQL-pipelinen. Tallene angir trinnene for å svare på et spørsmål.
I den følgende figuren viser vi vår ende-til-ende-rørledning. Vi bruker AWS Lambda som vår orkestreringsfunksjon som er ansvarlig for å samhandle med ulike datakilder, LLM-er og feilretting basert på brukerspørringen. Trinn 1-8 ligner på det som er vist i den foregående figuren. Det er små endringer for de ustrukturerte dataene, som vi diskuterer videre.
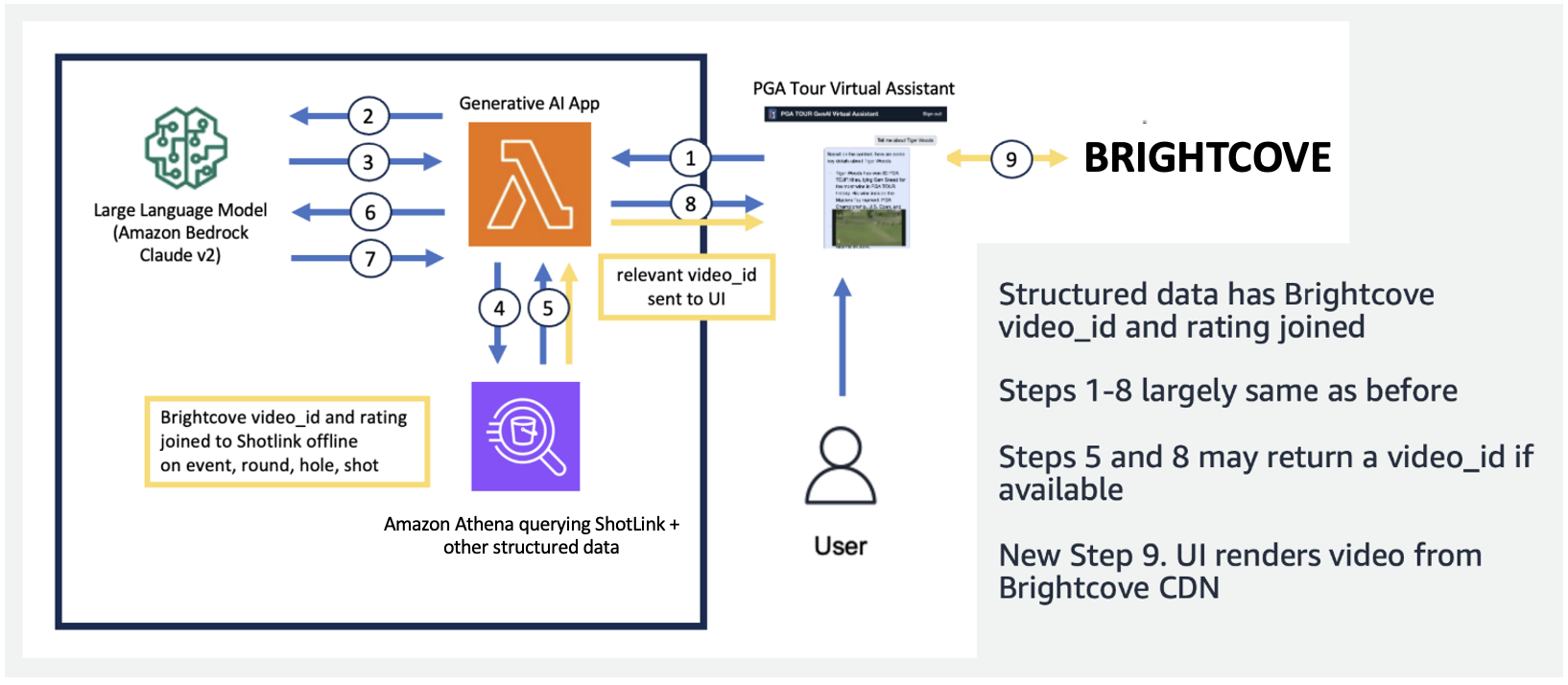
Tekstdata krever unike behandlingstrinn som deler (eller segmenterer) lange dokumenter i deler som kan fordøyes av LLM, samtidig som emnekoherens opprettholdes. Vi eksperimenterte med flere tilnærminger og bestemte oss for et oppdelingsskjema på sidenivå som passet godt med formatet til medieguidene. Vi brukte Amazon Kendra, som er en administrert tjeneste som tar seg av indeksering av dokumenter, uten å kreve spesifikasjon av innbygginger, samtidig som det gir en enkel API for gjenfinning. Følgende figur illustrerer denne arkitekturen.

Den enhetlige, skalerbare rørledningen vi utviklet gjør at PGA TOUR kan skaleres til sin fulle historie med data, hvorav noen går tilbake til 1800-tallet. Den gjør det mulig for fremtidige applikasjoner som kan ta live på kurskonteksten for å skape rike sanntidsopplevelser.
Utvikling: Evaluering av LLM-er og utvikling av generative AI-applikasjoner
Vi har nøye testet og evaluert første- og tredjeparts LLM-ene som er tilgjengelige i Amazon Bedrock for å velge modellen som er best egnet for vår pipeline og brukssituasjon. Vi valgte Anthropics Claude v2 og Claude Instant på Amazon Bedrock. For vår endelige strukturerte og ustrukturerte datapipeline observerer vi at Anthropics Claude 2 på Amazon Bedrock genererte bedre samlede resultater for vår endelige datapipeline.
Spørring er et kritisk aspekt for å få LLM-er til å skrive ut tekst som ønsket. Vi brukte mye tid på å eksperimentere med ulike spørsmål for hver av oppgavene. For eksempel, for tekst-til-SQL-pipelinen, hadde vi flere reservemeldinger, med økende spesifisitet og gradvis forenklede tabellskjemaer. Hvis en SQL-spørring var ugyldig og resulterte i en feil fra Athena, utviklet vi en feilrettingsforespørsel som ville sende feilen og feil SQL til LLM og be den fikse den. Den siste ledeteksten i tekst-til-SQL-pipelinen ber LLM om å ta Athena-utdata, som kan leveres i Markdown- eller CSV-format, og gi et svar til brukeren. For den ustrukturerte teksten utviklet vi generelle spørsmål for å bruke konteksten hentet fra Amazon Kendra for å svare på brukerspørsmålet. Spørsmålet inkluderte instruksjoner om å kun bruke informasjonen hentet fra Amazon Kendra og ikke stole på data fra LLM-foropplæringen.
Latency er ofte et problem med generative AI-applikasjoner, og det er også tilfelle her. Det er spesielt et problem for tekst-til-SQL, som krever en innledende SQL-generering LLM-påkalling, etterfulgt av en responsgenerering LLM-påkalling. Hvis vi bruker en stor LLM, slik som Anthropics Claude V2, dobler dette effektivt latensen til bare én LLM-anrop. Vi eksperimenterte med flere konfigurasjoner av store og mindre LLM-er for å evaluere kjøretid så vel som korrekthet. Følgende tabell viser et eksempel for ett spørsmål er vist nedenfor som viser ventetiden, samt de genererte svarene med Anthropics Claude V2 og Claude Instant på Amazon Bedrock.

Prototype
I applikasjonen vår brukte vi en Lambda-funksjon for å orkestrere de raske valgene og kommunikasjonen mellom Amazon Athena, Amazon Kendra og Amazon Bedrock. Den virtuelle assistenten har et samtalegrensesnitt, bygget med React og Cloudscape Design System, som bruker tekst og videoer for å engasjere seg med brukere.
Vår virtuelle assistent kan stille et bredt spekter av spørsmål om PGA TOUR-arrangementer, spillere, statistikk, historie og mer. For eksempel, når han blir spurt om Tony Finaus lengste kjøreturer på Shriners Children's Open (en av Signature-arrangementene til PGA TOUR), kan assistenten spørre etter strukturerte data for å hente skuddnivådataene hans. Den kan trekke ut den nøyaktige avstanden i yards, det runde tallet og hullet hvor han oppnådde denne rekorden ved å bruke tekst-til-SQL-rørledningen. Assistenten tolker deretter disse numeriske dataene for å generere et endelig svar. Tabellen nedenfor inneholder noen eksempler på svar.
| Spørsmål | Respons |
| Hva var den lengste kjøreturen som ble truffet av Tony Finau i Shriners Children's Open? | Den lengste drive som ble truffet av Tony Finau i Shriners Childrens Open var 382 yards, som han traff under den første runden på hull nummer 4 i 2018. |
| Hva var den lengste kjøreturen truffet av Collin Morikawa i Shriners Children's Open? | Collin Morikawas lengste kjøretur på Shriners Childrens Open var 334 yards. Dette skjedde i 2019 under den første runden på hull nummer 15. |
| Var det noen som gjorde et ess på Shriners Children's Open i 2022? | Ja, Adam Hadwin gjorde en hole-in-one på hull 14 under runde 3 av Shriners Children's Open 2022 |
Følgende forklaringsvideo fremhever noen eksempler på samhandling med den virtuelle assistenten.
I innledende testing har vår virtuelle PGA TOUR-assistent vist store løfter når det gjelder å forbedre fanopplevelsene. Ved å blande AI-teknologier som tekst-til-SQL, semantisk søk og generering av naturlig språk, leverer assistenten informative, engasjerende svar. Fansen får uanstrengt tilgang til data og narrativer som tidligere var vanskelig å finne.
Hva holder fremtiden til?
Etter hvert som vi fortsetter utviklingen, vil vi utvide utvalget av spørsmål vår virtuelle assistent kan håndtere. Dette vil kreve omfattende testing, gjennom samarbeid mellom AWS og PGA TOUR. Over tid tar vi sikte på å utvikle assistenten til en personlig, omni-channel opplevelse tilgjengelig på tvers av nett-, mobil- og talegrensesnitt.
Etableringen av en skybasert generativ AI-assistent lar PGA TOUR presentere sin enorme datakilde for flere interne og eksterne interessenter. Etter hvert som det sportsgenerative AI-landskapet utvikler seg, muliggjør det å lage nytt innhold. Du kan for eksempel bruke AI og maskinlæring (ML) for å synliggjøre innhold som fans vil se når de ser på en begivenhet, eller når produksjonsteam ser etter bilder fra tidligere turneringer som matcher en aktuell begivenhet. For eksempel, hvis Max Homa gjør seg klar til å ta sitt siste skudd på PGA TOUR Championship fra et sted 20 fot fra pinnen, kan PGA TOUR bruke AI og ML til å identifisere og presentere klipp, med AI-generert kommentarer, av ham forsøkte et lignende skudd fem ganger tidligere. Denne typen tilgang og data lar et produksjonsteam umiddelbart legge til verdi til sendingen eller tillate en fan å tilpasse typen data de vil se.
"PGA TOUR er bransjeledende når det gjelder å bruke banebrytende teknologi for å forbedre fanopplevelsen. AI er i forkant av teknologistabelen vår, der den gjør det mulig for oss å skape et mer engasjerende og interaktivt miljø for fans. Dette er begynnelsen på vår generative AI-reise i samarbeid med AWS Generative AI Innovation Center for en transformerende ende-til-ende kundeopplevelse. Vi jobber med å utnytte Amazon Bedrock og våre anstendighetsdata for å skape en interaktiv opplevelse for PGA TOUR-fans for å finne informasjon av interesse om en begivenhet, spiller, statistikk eller annet innhold på en interaktiv måte.»
– Scott Gutterman, SVP for Broadcast and Digital Properties på PGA TOUR.
konklusjonen
Prosjektet vi diskuterte i dette innlegget eksemplifiserer hvordan strukturerte og ustrukturerte datakilder kan smeltes sammen ved hjelp av AI for å lage neste generasjons virtuelle assistenter. For sportsorganisasjoner muliggjør denne teknologien mer engasjerende fansengasjement og låser opp intern effektivitet. Dataintelligensen vi får frem hjelper PGA TOUR-interessenter som spillere, trenere, funksjonærer, partnere og media til å ta informerte beslutninger raskere. Utover sport kan metodikken vår replikeres på tvers av alle bransjer. De samme prinsippene gjelder for bygningsassistenter som engasjerer kunder, ansatte, studenter, pasienter og andre sluttbrukere. Med gjennomtenkt design og testing kan praktisk talt enhver organisasjon dra nytte av et AI-system som kontekstualiserer deres strukturerte databaser, dokumenter, bilder, videoer og annet innhold.
Hvis du er interessert i å implementere lignende funksjoner, bør du vurdere å bruke Agenter for Amazon Bedrock og Kunnskapsbaser for Amazon Bedrock som en alternativ, fullstendig AWS-administrert løsning. Denne tilnærmingen kan videre undersøke å tilby intelligent automatisering og datasøkeevner gjennom tilpassbare agenter. Disse agentene kan potensielt transformere brukerapplikasjonsinteraksjoner til å bli mer naturlige, effektive og effektive.
Om forfatterne
 Scott Gutterman er SVP for Digital Operations for PGA TOUR. Han er ansvarlig for TOURs overordnede digitale drift, produktutvikling og driver deres GenAI-strategi.
Scott Gutterman er SVP for Digital Operations for PGA TOUR. Han er ansvarlig for TOURs overordnede digitale drift, produktutvikling og driver deres GenAI-strategi.
 Ahsan Ali er en Applied Scientist ved Amazon Generative AI Innovation Center, hvor han jobber med kunder fra forskjellige domener for å løse deres presserende og kostbare problemer ved å bruke Generative AI.
Ahsan Ali er en Applied Scientist ved Amazon Generative AI Innovation Center, hvor han jobber med kunder fra forskjellige domener for å løse deres presserende og kostbare problemer ved å bruke Generative AI.
 Tahin Syed er en Applied Scientist ved Amazon Generative AI Innovation Center, hvor han jobber med kunder for å hjelpe med å realisere forretningsresultater med generative AI-løsninger. Utenom jobben liker han å prøve ny mat, reise og undervise i taekwondo.
Tahin Syed er en Applied Scientist ved Amazon Generative AI Innovation Center, hvor han jobber med kunder for å hjelpe med å realisere forretningsresultater med generative AI-løsninger. Utenom jobben liker han å prøve ny mat, reise og undervise i taekwondo.
 Grace Lang er en Associate Data & ML-ingeniør med AWS Professional Services. Drevet av en lidenskap for å overvinne tøffe utfordringer, hjelper Grace kundene med å nå sine mål ved å utvikle maskinlæringsdrevne løsninger.
Grace Lang er en Associate Data & ML-ingeniør med AWS Professional Services. Drevet av en lidenskap for å overvinne tøffe utfordringer, hjelper Grace kundene med å nå sine mål ved å utvikle maskinlæringsdrevne løsninger.
 Jae Lee er Senior Engagement Manager i ProServes M&E-vertikal. Hun leder og leverer komplekse engasjementer, viser sterke problemløsningskompetanse, administrerer interessentenes forventninger og kuraterer presentasjoner på ledernivå. Hun liker å jobbe med prosjekter fokusert på sport, generativ AI og kundeopplevelse.
Jae Lee er Senior Engagement Manager i ProServes M&E-vertikal. Hun leder og leverer komplekse engasjementer, viser sterke problemløsningskompetanse, administrerer interessentenes forventninger og kuraterer presentasjoner på ledernivå. Hun liker å jobbe med prosjekter fokusert på sport, generativ AI og kundeopplevelse.
 Karn Chahar er sikkerhetskonsulent med delt leveringsteamet hos AWS. Han er en teknologientusiast som liker å jobbe med kunder for å løse sikkerhetsutfordringene deres og forbedre deres sikkerhetsposisjon i skyen.
Karn Chahar er sikkerhetskonsulent med delt leveringsteamet hos AWS. Han er en teknologientusiast som liker å jobbe med kunder for å løse sikkerhetsutfordringene deres og forbedre deres sikkerhetsposisjon i skyen.
 Mike Amjadi er en Data & ML Engineer med AWS ProServe fokusert på å gjøre det mulig for kunder å maksimere verdien fra data. Han spesialiserer seg på å designe, bygge og optimalisere datarørledninger etter godt utformede prinsipper. Mike er lidenskapelig opptatt av å bruke teknologi for å løse problemer og er forpliktet til å levere de beste resultatene for kundene våre.
Mike Amjadi er en Data & ML Engineer med AWS ProServe fokusert på å gjøre det mulig for kunder å maksimere verdien fra data. Han spesialiserer seg på å designe, bygge og optimalisere datarørledninger etter godt utformede prinsipper. Mike er lidenskapelig opptatt av å bruke teknologi for å løse problemer og er forpliktet til å levere de beste resultatene for kundene våre.
 Vrushali Sawant er en Front End Engineer med Proserve. Hun er svært dyktig i å lage responsive nettsider. Hun elsker å jobbe med kunder, forstå deres krav og gi dem skalerbare UI/UX-løsninger som er enkle å ta i bruk.
Vrushali Sawant er en Front End Engineer med Proserve. Hun er svært dyktig i å lage responsive nettsider. Hun elsker å jobbe med kunder, forstå deres krav og gi dem skalerbare UI/UX-løsninger som er enkle å ta i bruk.
 Neelam Patel er en Customer Solutions Manager hos AWS, og leder viktige initiativer for generativ kunstig intelligens og skymodernisering. Neelam samarbeider med sentrale ledere og teknologieiere for å møte deres skytransformasjonsutfordringer og hjelper kunder med å maksimere fordelene ved skyadopsjon. Hun har en MBA fra Warwick Business School, Storbritannia og en bachelorgrad i datateknikk, India.
Neelam Patel er en Customer Solutions Manager hos AWS, og leder viktige initiativer for generativ kunstig intelligens og skymodernisering. Neelam samarbeider med sentrale ledere og teknologieiere for å møte deres skytransformasjonsutfordringer og hjelper kunder med å maksimere fordelene ved skyadopsjon. Hun har en MBA fra Warwick Business School, Storbritannia og en bachelorgrad i datateknikk, India.
 Dr. Murali Baktha er Global Golf Solution Architect hos AWS, og går i spissen for sentrale initiativer som involverer Generativ AI, dataanalyse og banebrytende skyteknologier. Murali jobber med sentrale ledere og teknologieiere for å forstå kundens forretningsutfordringer og designer løsninger for å møte disse utfordringene. Han har en MBA i finans fra UConn og en doktorgrad fra Iowa State University.
Dr. Murali Baktha er Global Golf Solution Architect hos AWS, og går i spissen for sentrale initiativer som involverer Generativ AI, dataanalyse og banebrytende skyteknologier. Murali jobber med sentrale ledere og teknologieiere for å forstå kundens forretningsutfordringer og designer løsninger for å møte disse utfordringene. Han har en MBA i finans fra UConn og en doktorgrad fra Iowa State University.
 Mehdi Noor er en Applied Science Manager ved Generative Ai Innovation Center. Med en lidenskap for å bygge bro mellom teknologi og innovasjon, hjelper han AWS-kunder med å frigjøre potensialet til Generativ AI, gjøre potensielle utfordringer til muligheter for rask eksperimentering og innovasjon ved å fokusere på skalerbar, målbar og effektfull bruk av avanserte AI-teknologier, og strømlinjeforme veien til produksjon.
Mehdi Noor er en Applied Science Manager ved Generative Ai Innovation Center. Med en lidenskap for å bygge bro mellom teknologi og innovasjon, hjelper han AWS-kunder med å frigjøre potensialet til Generativ AI, gjøre potensielle utfordringer til muligheter for rask eksperimentering og innovasjon ved å fokusere på skalerbar, målbar og effektfull bruk av avanserte AI-teknologier, og strømlinjeforme veien til produksjon.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/the-journey-of-pga-tours-generative-ai-virtual-assistant-from-concept-to-development-to-prototype/

