I datatiden bruker organisasjoner i økende grad datainnsjøer for å lagre og analysere enorme mengder strukturerte og ustrukturerte data. Datainnsjøer gir et sentralisert depot for data fra ulike kilder, noe som gjør det mulig for organisasjoner å låse opp verdifull innsikt og drive datadrevet beslutningstaking. Men ettersom datavolumene fortsetter å vokse, blir optimalisering av datalayout og organisering avgjørende for effektiv spørring og analyse.
En av hovedutfordringene i datainnsjøer er potensialet for treg søkeytelse, spesielt når man arbeider med store datasett. Dette kan tilskrives faktorer som ineffektiv datalayout, noe som resulterer i overdreven dataskanning og ineffektiv bruk av dataressurser. For å møte denne utfordringen kan vanlige praksiser som partisjonering og bucketing forbedre søkeytelsen betydelig og redusere beregningskostnadene.
Oppdeling er en teknikk som deler et stort datasett i mindre, mer håndterbare deler basert på spesifikke kriterier, for eksempel dato, region eller produktkategori. Ved å partisjonere data kan nedstrøms analytiske spørringer hoppe over irrelevante partisjoner, noe som reduserer mengden data som må skannes og behandles. Du kan bruke partisjonskolonner i WHERE-klausulen i spørringer for å skanne bare de spesifikke partisjonene som spørringen din trenger. Dette kan føre til raskere spørringskjøring og mer effektiv ressursutnyttelse. Det fungerer spesielt bra når kolonner med lav kardinalitet er valgt som nøkkel.
Hva om du har en kolonne med høy kardinalitet som du noen ganger må filtrere etter VIP-kunder? Hver kunde identifiseres vanligvis med en ID, som kan være på millioner. Partisjonering er ikke egnet for kolonner med så høy kardinalitet fordi du ender opp med små filer, treg partisjonsfiltrering og høy Amazon enkel lagringstjeneste (Amazon S3) API-kostnad (ett S3-prefiks opprettes per verdi av partisjonskolonnen). Selv om du kan bruke partisjonering med en naturlig nøkkel som by eller stat for å begrense datasettet til en viss grad, er det fortsatt nødvendig å spørre på tvers av datobaserte partisjoner hvis dataene dine er tidsserier.
Dette er hvor bøtte spiller inn. Bucketing sørger for at alle rader med samme verdier av én eller flere kolonner havner i samme fil. I stedet for én fil per verdi, som partisjonering, brukes en hash-funksjon for å fordele verdier jevnt over et fast antall filer. Ved å organisere data på denne måten kan du utføre effektiv filtrering, fordi bare de relevante bøttene må behandles, noe som reduserer beregningsmessige overhead ytterligere.
Det er flere alternativer for å implementere bucketing på AWS. En tilnærming er å bruke Amazonas Athena CREATE TABLE AS SELECT (CTAS)-setning, som lar deg lage en tabell med boketter direkte fra en spørring. Alternativt kan du bruke AWS Lim for Apache Spark, som gir innebygd støtte for bucketing-konfigurasjoner under datatransformasjonsprosessen. AWS Glue lar deg definere bucketing-parametere, for eksempel antall buckets og kolonnene som skal bucket på, og gir et optimalisert dataoppsett for effektiv spørring med Athena.
I dette innlegget diskuterer vi hvordan du implementerer bucketing på AWS-datainnsjøer, inkludert bruk av Athena CTAS-setning og AWS Glue for Apache Spark. Vi dekker også bøttekjøring for Apache Iceberg-bord.
Eksempel på bruk
I dette innlegget bruker du et offentlig datasett, den NOAA Integrated Surface Database. Dataanalytikere kjører engangsforespørsler etter data i løpet av de siste 5 årene gjennom Athena. De fleste forespørslene er for spesifikke stasjoner med spesifikke rapporttyper. Spørringene må fullføres på 10 sekunder, og kostnadene må optimaliseres nøye. I dette scenariet er du en dataingeniør som er ansvarlig for å optimalisere søkeytelse og kostnader.
For eksempel hvis en analytiker ønsker å hente data for en bestemt stasjon (for eksempel stasjons-ID 123456) med en bestemt rapporttype (f.eks. CRN01), kan spørringen se ut som følgende spørring:
Når det gjelder NOAA Integrated Surface Database, er station_id kolonne har sannsynligvis en høy kardinalitet, med mange unike stasjonsidentifikatorer. På den annen side report_type kolonne kan ha en relativt lav kardinalitet, med et begrenset sett med rapporttyper. Gitt dette scenariet, vil det være en god idé å partisjonere dataene etter report_type og bøtte den forbi station_id.
Med denne partisjonerings- og bucketing-strategien kan Athena først eliminere partisjoner for irrelevante rapporttyper, og deretter skanne bare bøttene innenfor den relevante partisjonen som samsvarer med den spesifiserte stasjons-ID-en, noe som reduserer mengden data som behandles betydelig og akselererer spørringskjøringen. Denne tilnærmingen oppfyller ikke bare ytelseskravet for spørringer, men hjelper også med å optimalisere kostnadene ved å minimere mengden data som skannes og faktureres for hver spørring.
I dette innlegget undersøker vi hvordan søkeytelsen påvirkes av datalayout, spesielt bucketing. Vi sammenligner også tre ulike måter å oppnå bucketing på. Følgende tabell representerer betingelsene for tabellene som skal opprettes.
| . | noaa_remote_original | athena_non_bucketed | athena_bucketed | lim_bøttet | athena_bucketed_iceberg |
| dannet | CSV | parkett | parkett | parkett | parkett |
| Komprimering | n / a | Snappy | Snappy | Snappy | Snappy |
| Laget via | n / a | Athena CTAS | Athena CTAS | Lim ETL | Athena CTAS med isfjell |
| Motor | n / a | Trino | Trino | Apache Spark | Apache isfjell |
| Er partisjonert? | Ja, men på en annen måte | Ja | Ja | Ja | Ja |
| Er bøttet? | Nei | Nei | Ja | Ja | Ja |
noaa_remote_original er partisjonert av year kolonne, men ikke etter report_type kolonne. Denne raden representerer om tabellen er partisjonert av de faktiske kolonnene som brukes i spørringene.
Grunnlinjetabell
For dette innlegget oppretter du flere tabeller med forskjellige betingelser: noen uten bucketing og noen med bucketing, for å vise frem ytelsesegenskapene til bucketing. La oss først lage en original tabell ved å bruke NOAA-dataene. I de påfølgende trinnene inntar du data fra denne tabellen for å lage testtabeller.
Det er flere måter å definere en tabelldefinisjon på: kjører DDL, en AWS Glue-crawler, AWS Glue Data Catalog API, og så videre. I dette trinnet kjører du DDL via Athena-konsollen.
Fullfør følgende trinn for å lage "bucketing_blog"."noaa_remote_original" tabell i datakatalogen:
- Åpne Athena-konsollen.
- I spørringsredigeringsprogrammet, kjør følgende DDL for å opprette en ny AWS Glue-database:
- Til Database etter Data, velg
bucketing_blogfor å angi gjeldende database. - Kjør følgende DDL for å lage den opprinnelige tabellen:
Fordi kildedataene har siterte felt, bruker vi OpenCSVSerde i stedet for standard LazySimpleSerde.
Disse CSV-filene har en overskriftsrad, som vi ber Athena hoppe over ved å legge til skip.header.line.count og sett verdien til 1.
For mer informasjon, se OpenCSVSerDe for behandling av CSV.
- Kjør følgende DDL for å legge til partisjoner. Vi legger til partisjoner kun i 5 år av 124 år basert på brukskravet:
- Kjør følgende DML for å bekrefte om du kan søke etter dataene:
Nå er du klar til å begynne å spørre etter den opprinnelige tabellen for å undersøke grunnlinjeytelsen.
- Kjør en spørring mot den opprinnelige tabellen for å evaluere spørringsytelsen som en grunnlinje. Følgende spørring velger poster for fem spesifikke stasjoner med rapporttype
CRN05: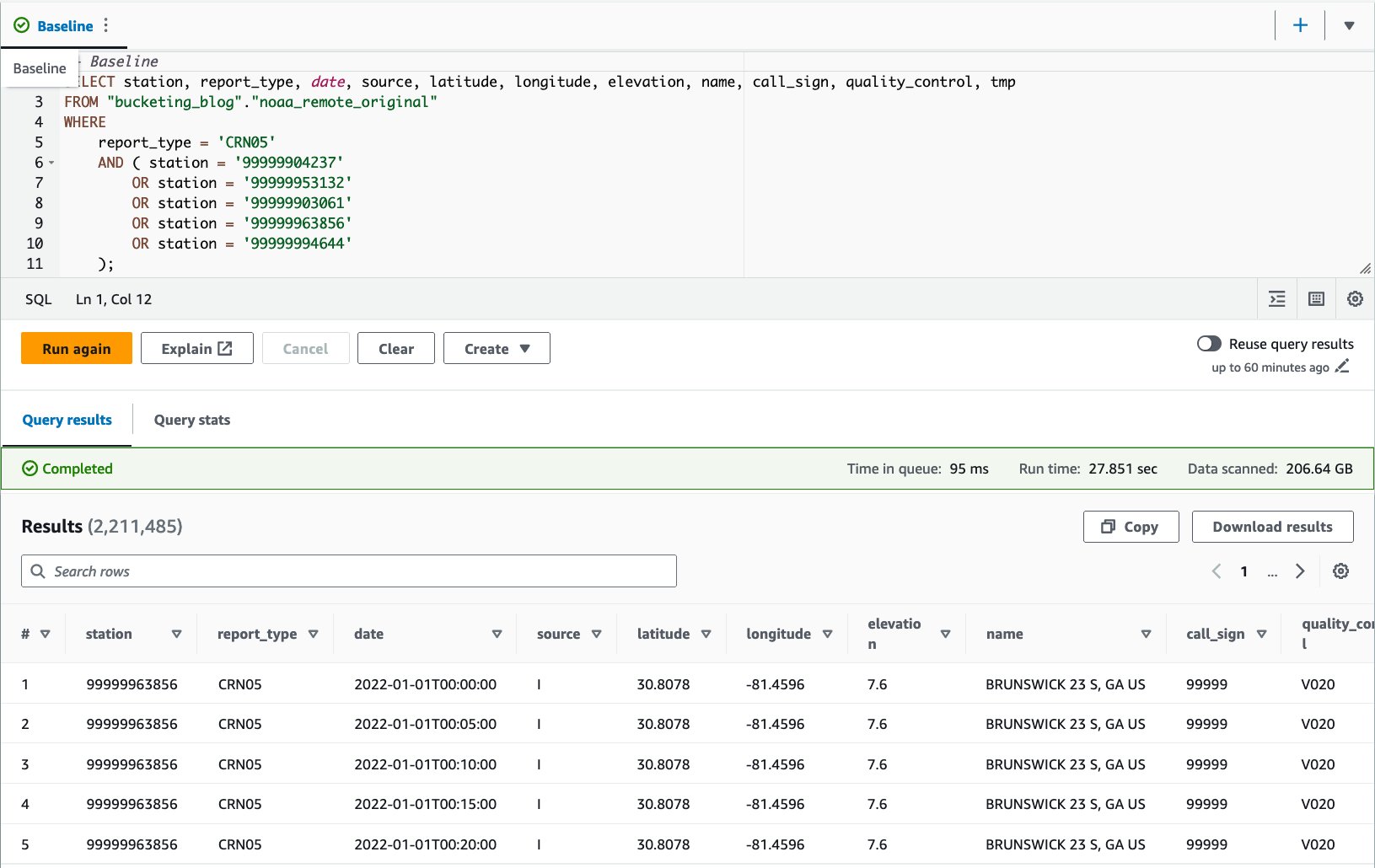
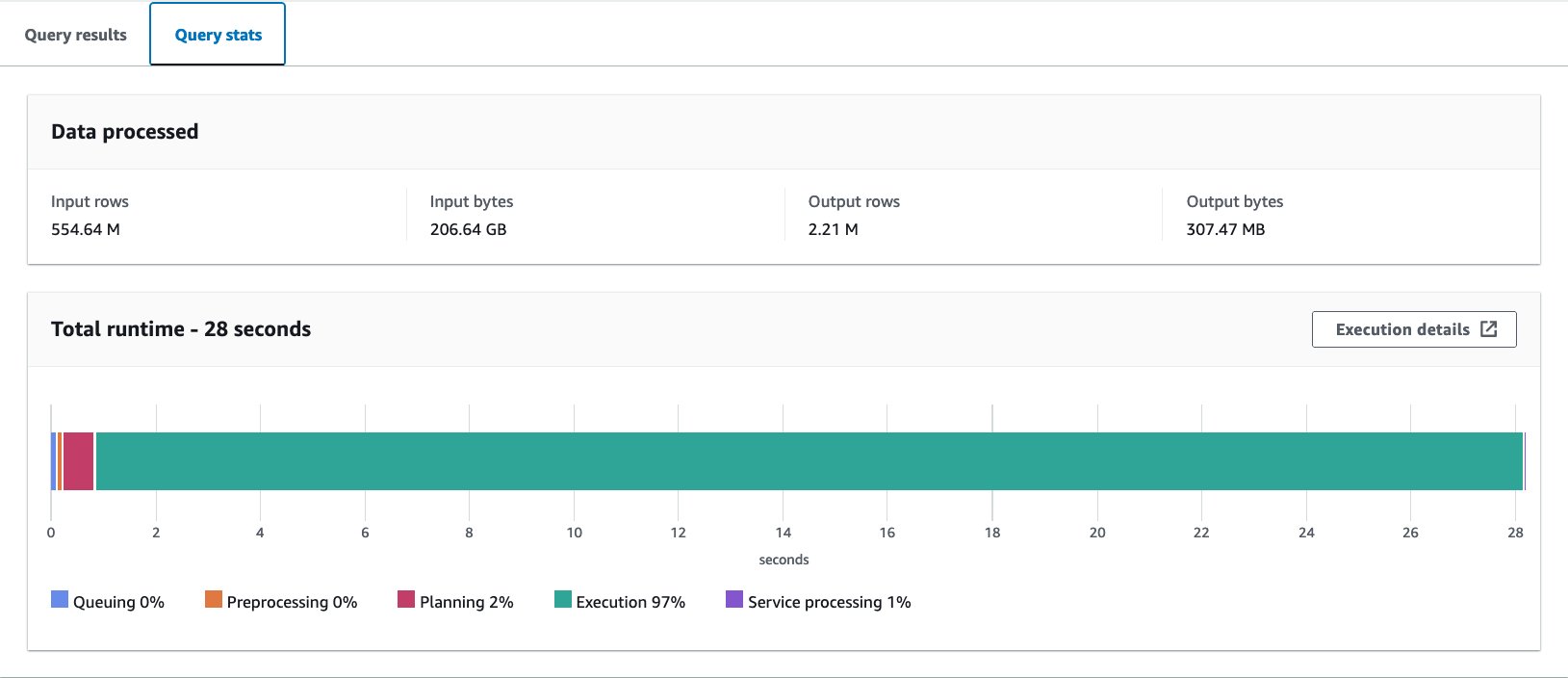
Vi kjørte denne spørringen 10 ganger. Gjennomsnittlig kjøretid for 10 søk er 27.6 sekunder, som er langt lenger enn målet vårt på 10 sekunder, og 155.75 GB data skannes for å returnere 1.65 millioner poster. Dette er grunnlinjeytelsen til den originale råtabellen. Det er på tide å begynne å optimalisere dataoppsettet fra denne grunnlinjen.
Deretter lager du tabeller med andre betingelser enn originalen: en uten bucketing og en med bucketing, og sammenligner dem.
Optimaliser dataoppsettet ved hjelp av Athena CTAS
I denne delen bruker vi en Athena CTAS-spørring for å optimalisere dataoppsettet og dets format.
La oss først lage en tabell med partisjonering, men uten bucketing. Den nye tabellen er partisjonert av kolonnen report_type fordi de fleste forventede spørringer bruker denne kolonnen i WHERE-klausulen, og objekter lagres som parkett med Snappy-komprimering.
- Åpne Athena spørringsredigering.
- Kjør følgende spørring, oppgi din egen S3-bøtte og prefiks:
Dataene dine skal se ut som følgende skjermbilder.
Det er 30 filer under partisjonen.
Deretter lager du en tabell med Hive-stil bucketing. Antall bøtter må justeres nøye gjennom eksperimenter for ditt eget bruk. Generelt sett, jo flere bøtter du har, jo mindre granularitet, noe som kan resultere i bedre ytelse. På den annen side kan for mange små filer føre til ineffektivitet i spørringsplanlegging og -behandling. I tillegg fungerer bucketing bare hvis du spør etter noen få verdier av bucketing-nøkkelen. Jo flere verdier du legger til søket ditt, desto mer sannsynlig er det at du ender opp med å lese alle bøttene.
Følgende er grunnlinjespørringen for å optimalisere:
I dette eksemplet vil tabellen bli delt inn i 16 bøtter av en kolonne med høy kardinalitet (station), som skal brukes for WHERE-klausulen i spørringen. Alle andre forhold forblir de samme. Grunnlinjespørringen har fem verdier i stasjons-IDen, og du forventer at forespørsler på det meste vil ha rundt det tallet, som er mindre nok enn antall bøtter, så 16 burde fungere bra. Det er mulig å spesifisere et større antall bøtter, men CTAS kan ikke brukes hvis det totale antallet partisjoner overstiger 100.
- Kjør følgende spørring:
Spørringen oppretter S3-objekter organisert som vist i følgende skjermbilder.
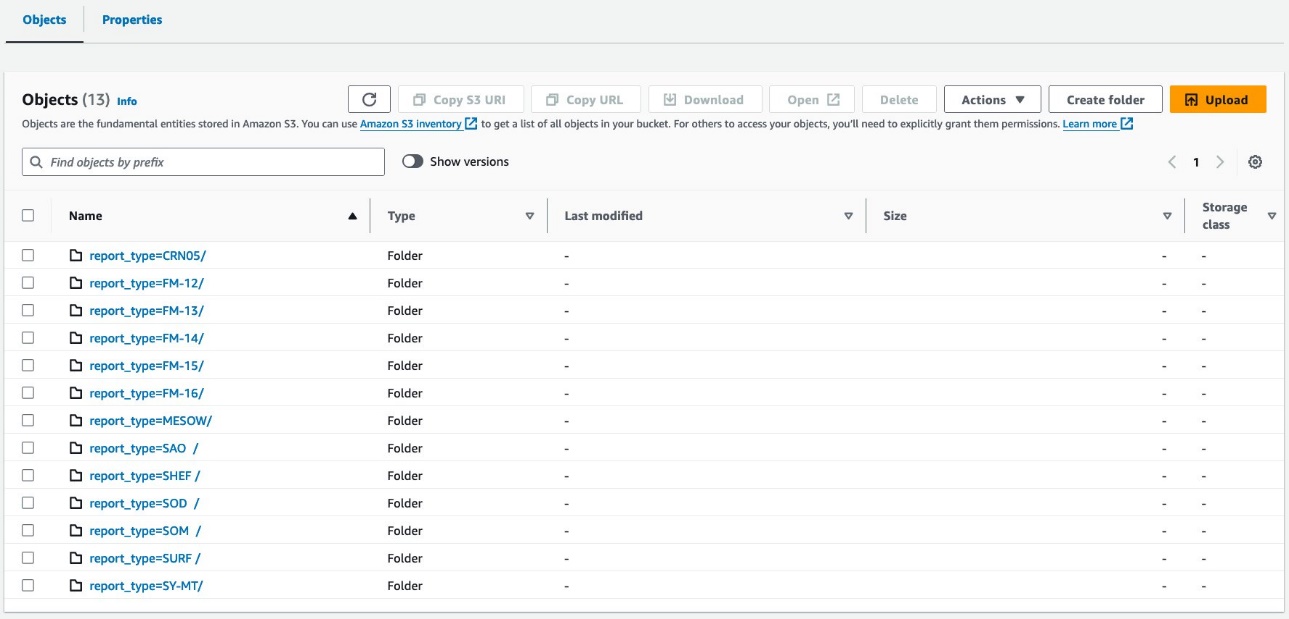

Oppsettet på tabellnivå ser nøyaktig likt ut mellom athena_non_bucketed og athena_bucketed: det er 13 partisjoner i hver tabell. Forskjellen er antall objekter under partisjonene. Det er 16 objekter (bøtter) per partisjon, på omtrent 10–25 MB hver i dette tilfellet. Antall bøtter er konstant på den angitte verdien uavhengig av datamengden, men bøttestørrelsen avhenger av datamengden.
Nå er du klar til å spørre mot hver tabell for å evaluere søkeytelsen. Spørringen vil velge poster med fem spesifikke stasjoner og rapporttype CRN05 de siste 5 årene. Selv om du ikke kan se hvilke data for en spesifikk stasjon som er plassert i hvilken bøtte, har de blitt beregnet og plassert riktig av Athena.
- Spør den ikke-oppdelte tabellen med følgende setning:

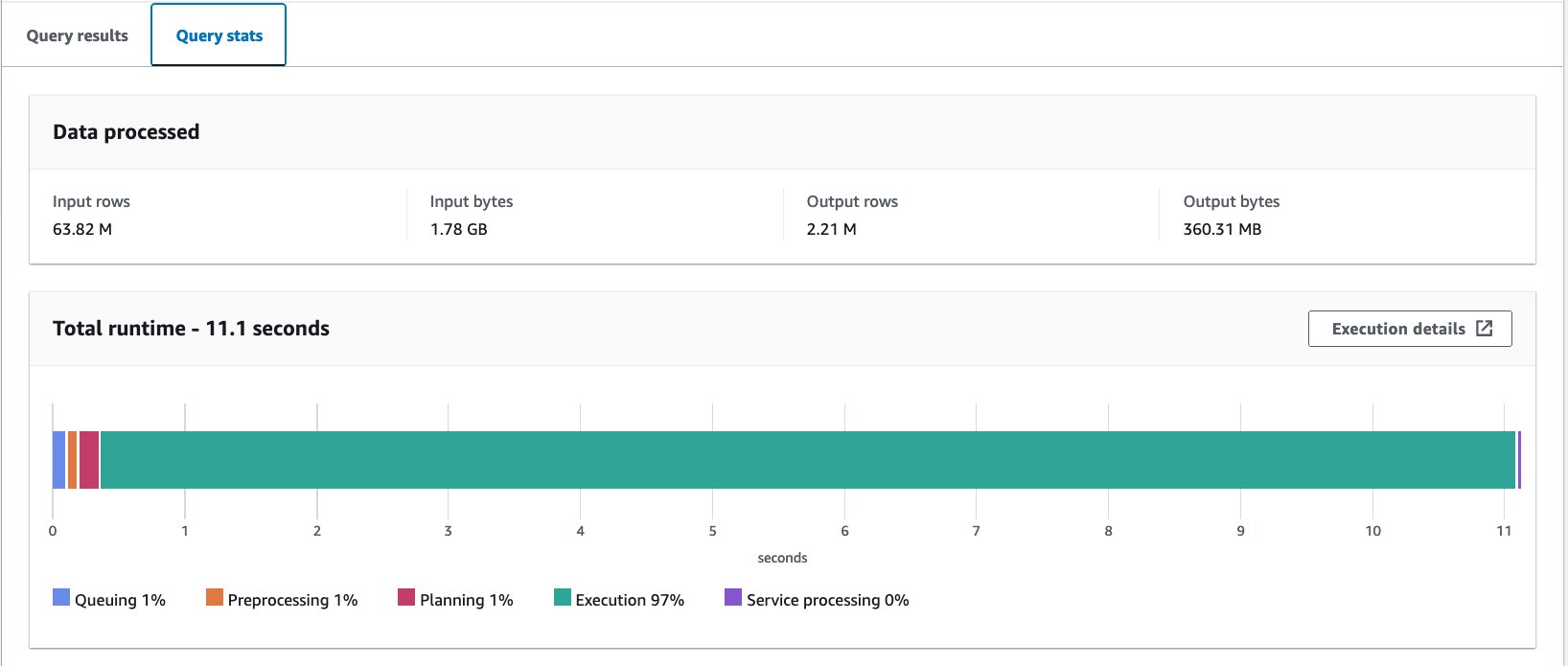
Vi kjørte denne spørringen 10 ganger. Gjennomsnittlig kjøretid for de 10 spørringene er 10.95 sekunder, og 358 MB data skannes for å returnere 2.21 millioner poster. Både kjøretiden og skannestørrelsen har blitt betydelig redusert fordi du har partisjonert dataene, og kan nå bare lese én partisjon der 12 partisjoner av 13 er hoppet over. I tillegg har mengden skannet data gått ned fra 206 GB til 360 MB, som er en reduksjon på 99.8 %. Dette er ikke bare på grunn av partisjoneringen, men også på grunn av endringen av formatet til parkett og komprimering med Snappy.
- Spørr i den inndelte tabellen med følgende setning:
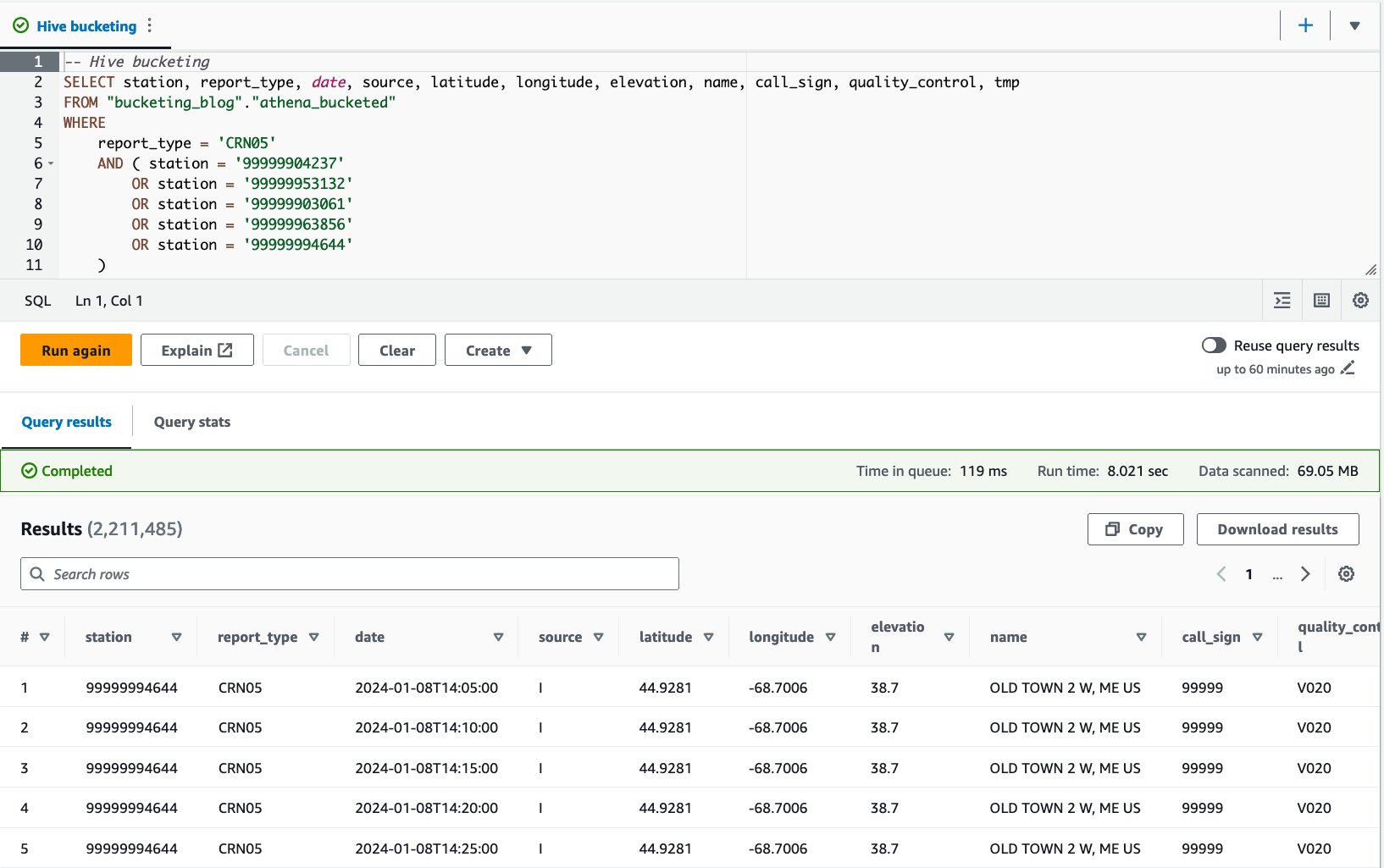
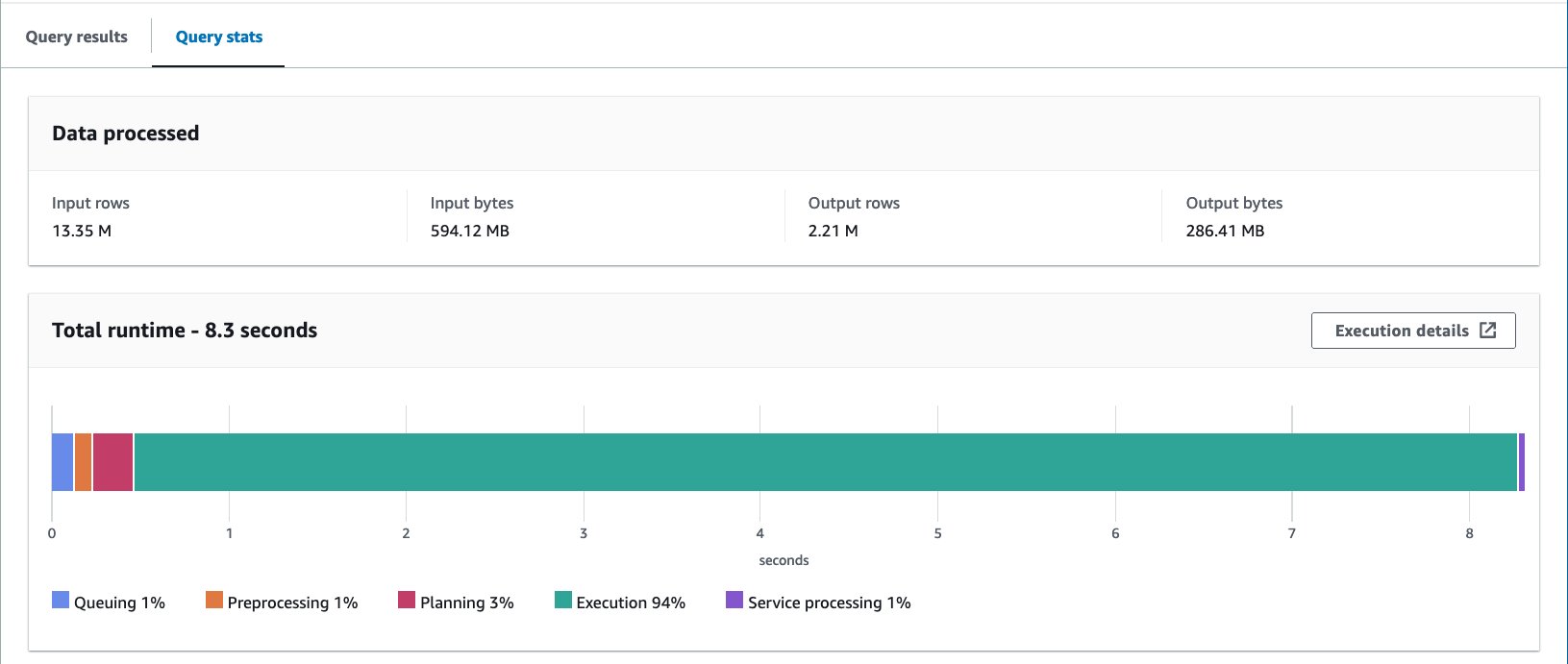
Vi kjørte denne spørringen 10 ganger. Gjennomsnittlig kjøretid for de 10 spørringene er 7.82 sekunder, og 69 MB data skannes for å returnere 2.21 millioner poster. Dette betyr en reduksjon av gjennomsnittlig kjøretid fra 10.95 til 7.82 sekunder (-29 %), og en dramatisk reduksjon av data skannet fra 358 MB til 69 MB (-81 %) for å returnere samme antall poster sammenlignet med den ikke-inndelte tabellen . I dette tilfellet ble både kjøretid og skannet data forbedret ved bucketing. Dette betyr at bucketing ikke bare bidro til ytelse, men også til kostnadsreduksjon.
betraktninger
Som nevnt tidligere, dimensjoner bøtten din nøye for å maksimere ytelsen til søket ditt. Bucketing fungerer bare hvis du spør etter noen få verdier av bucketing-nøkkelen. Vurder å opprette flere verdier enn antallet verdier som forventes i den faktiske spørringen.
I tillegg er en Athena CTAS-spørring begrenset til å opprette opptil 100 partisjoner på en gang. Hvis du trenger et stort antall partisjoner, kan det være lurt å bruke AWS Glue extract, transform and load (ETL), selv om det er en løsning for å dele opp i flere SQL-setninger.
Optimaliser datalayout ved hjelp av AWS Glue ETL
Apache Spark er et distribuert prosesseringsrammeverk med åpen kildekode som muliggjør fleksibel ETL med PySpark, Scala og Spark SQL. Den lar deg partisjonere og samle dataene dine basert på dine behov. Spark har flere innstillingsalternativer for å akselerere jobber. Du kan enkelt automatisere og overvåke Spark-jobber. I denne delen bruker vi AWS Glue ETL-jobber for å kjøre Spark-kode for å optimalisere dataoppsettet.
I motsetning til Athena bucketing, bruker AWS Glue ETL Spark-basert bucketing som en bucketing-algoritme. Alt du trenger å gjøre er å legge til følgende tabellegenskap på tabellen: bucketing_format = 'spark'. For detaljer om denne tabellegenskapen, se Skillevegg og bøtting i Athena.
Fullfør følgende trinn for å lage en tabell med bucketing gjennom AWS Glue ETL:
- Velg på AWS Lim-konsollen ETL jobb i navigasjonsruten.
- Velg Lag jobb Og velg Visuell ETL.
- Under Legg til noder, velg AWS Lim Data Catalog forum Kilder.
- Til Database, velg
bucketing_blog. - Til Bord, velg
noaa_remote_original. - Under Legg til noder, velg Endre skjema forum Transforms.
- Under Legg til noder, velg Egendefinert transformasjon forum Transforms.
- Til Navn, Tast inn
ToS3WithBucketing. - Til Node foreldre, velg Endre skjema.
- Til Kodeblokk, skriv inn følgende kodebit:
Følgende skjermbilde viser jobben opprettet med AWS Glue Studio for å generere en tabell og data.
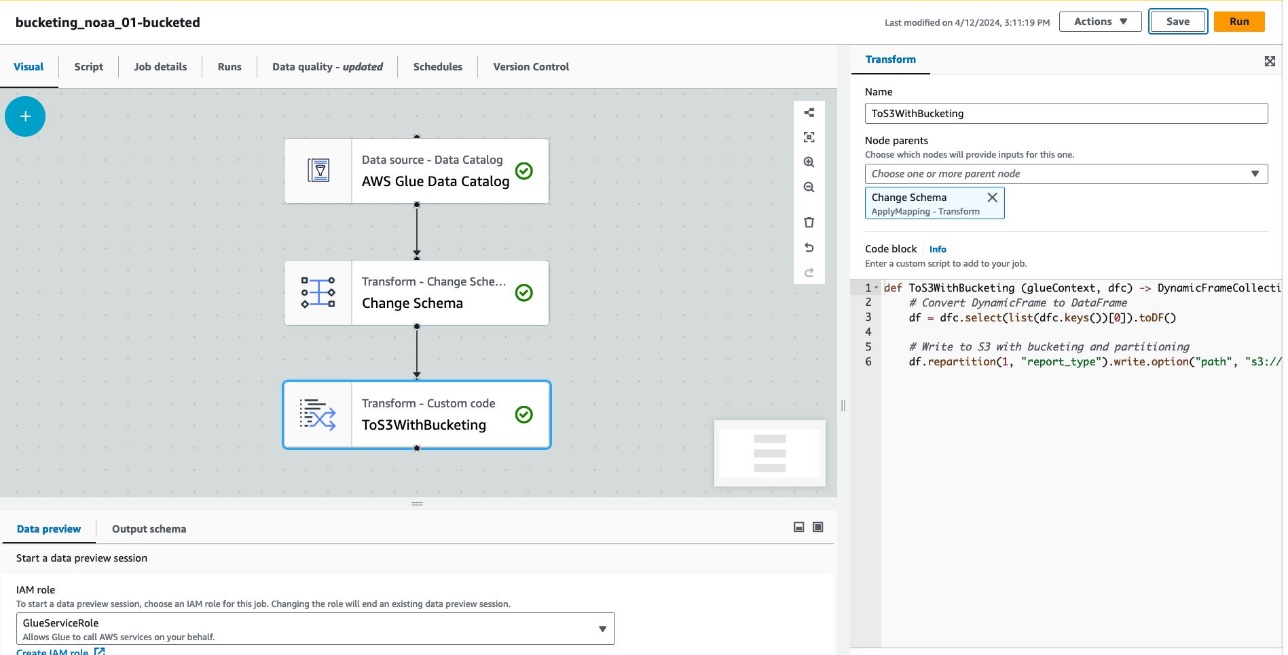
Hver node representerer følgende:
- De AWS Lim Data Catalog noden laster inn
noaa_remote_originaltabell fra datakatalogen - De Endre skjema node sørger for at den laster inn kolonner som er registrert i datakatalogen
- De ToS3WithBucketing node skriver data til Amazon S3 med både partisjonering og Spark-basert bucketing
Jobben har blitt forfattet i den visuelle editoren.
- Under JobbdetaljerFor IAM-rolle, Velg din AWS identitets- og tilgangsadministrasjon (IAM) rolle for denne jobben.
- Til Arbeidstype, velg G.8X.
- Til Ønsket antall arbeidere, skriv inn 5.
- Velg Spar, velg deretter Kjør.
Etter disse trinnene, tabellen glue_bucketed. har blitt skapt.
- Velg tabeller i navigasjonsruten, og velg tabellen
glue_bucketed. - På handlinger meny, velg Rediger tabell etter Administrer.
- på Tabellegenskaper delen velger Legg til.
- Legg til et nøkkelpar med nøkkel
bucketing_formatog verdi gnist.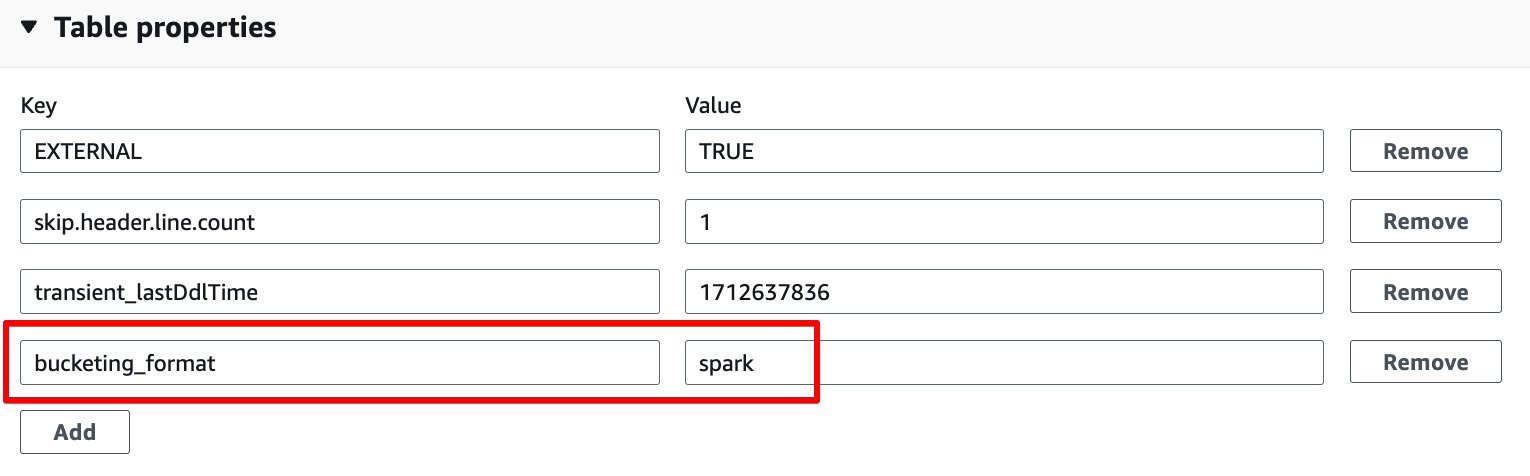
- Velg Spar.
Nå er det på tide å spørre tabellene.
- Spørr i den inndelte tabellen med følgende setning:

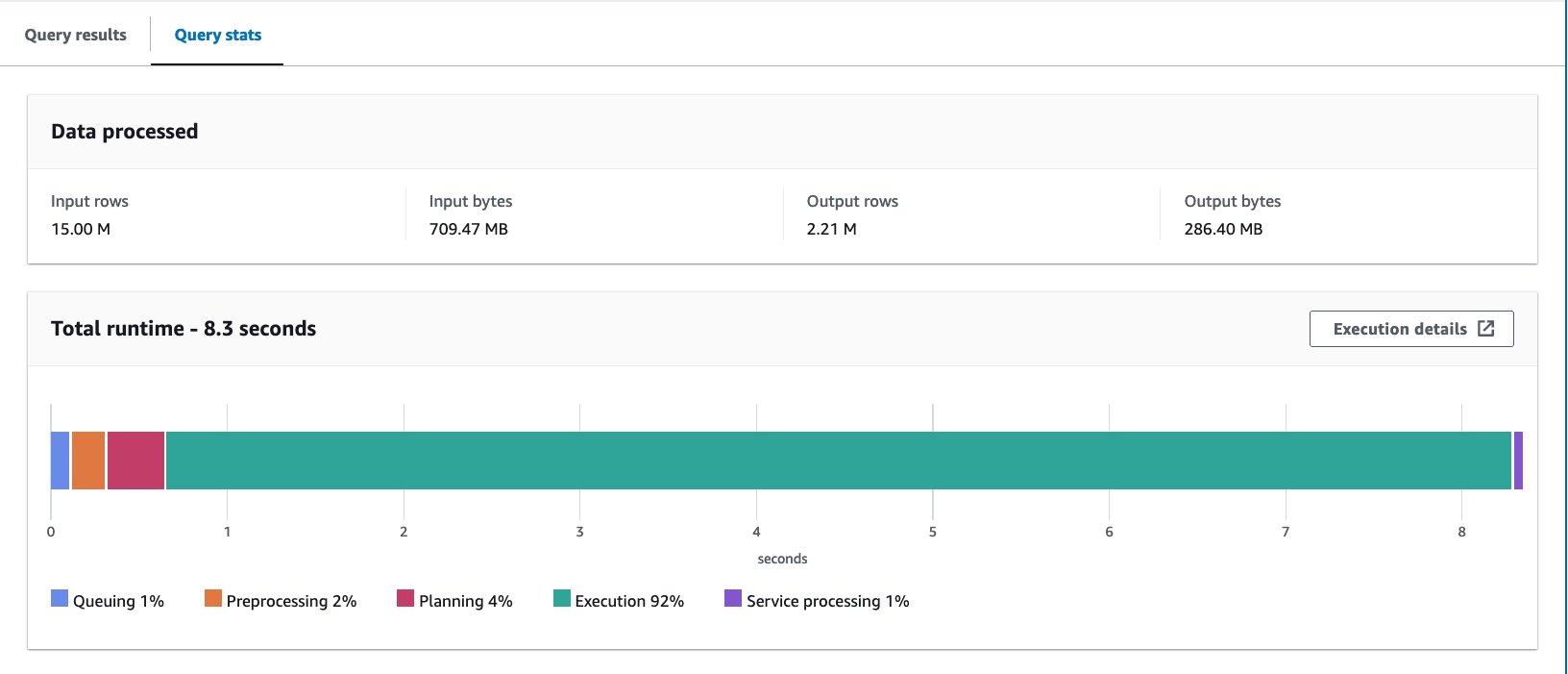
Vi kjørte spørringen 10 ganger. Gjennomsnittlig kjøretid for de 10 spørringene er 7.09 sekunder, og 88 MB data skannes for å returnere 2.21 millioner poster. I dette tilfellet ble både kjøretiden og data som ble skannet forbedret ved bucketing. Dette betyr at bucketing ikke bare bidro til ytelse, men også til kostnadsreduksjon.
Årsaken til de større bytene som ble skannet sammenlignet med Athena CTAS-eksemplet er at verdiene ble fordelt annerledes i denne tabellen. I AWS Glue bucketed-tabellen ble verdiene fordelt på fem filer. I Athena CTAS bucketed-tabellen ble verdiene fordelt over fire filer. Husk at rader er fordelt i bøtter ved hjelp av en hash-funksjon. Spark-bucketing-algoritmen bruker en annen hash-funksjon enn Hive, og i dette tilfellet resulterte det i en annen distribusjon på tvers av filene.
betraktninger
Lim DynamicFrame støtter ikke bucketing native. Du må bruke Spark DataFrame i stedet for DynamicFrame for å samle tabeller.
For informasjon om finjustering av AWS Glue ETL-ytelse, se Beste praksis for ytelsesjustering av AWS Glue for Apache Spark-jobber.
Optimaliser Iceberg-dataoppsettet med skjult partisjonering
Apache Iceberg er et åpent tabellformat med høy ytelse for enorme analytiske tabeller, som bringer påliteligheten og enkelheten til SQL-tabeller til store data. Nylig har det vært en stor etterspørsel etter å bruke Apache Iceberg-tabeller for å oppnå avanserte funksjoner som ACID-transaksjoner, tidsreisespørring og mer.
I Iceberg fungerer bucketing annerledes enn Hive-tabellmetoden vi har sett så langt. I Iceberg er bucketing en undergruppe av partisjonering, og kan brukes ved å bruke bucket-partisjonstransformasjonen. Måten du bruker det på og sluttresultatet ligner på bucketing i Hive-tabeller. For mer informasjon om Iceberg bøttetransformasjoner, se Bøttetransformasjonsdetaljer.
Fullfør følgende trinn:
- Åpne Athena spørringsredigering.
- Kjør følgende spørring for å lage et Iceberg-bord med skjult partisjonering sammen med bucketing:
Dataene dine skal se ut som følgende skjermbilde.

Det er to mapper: data og metadata. Bore ned til data.
Du ser tilfeldige prefikser under data mappe. Velg den første for å se detaljene.
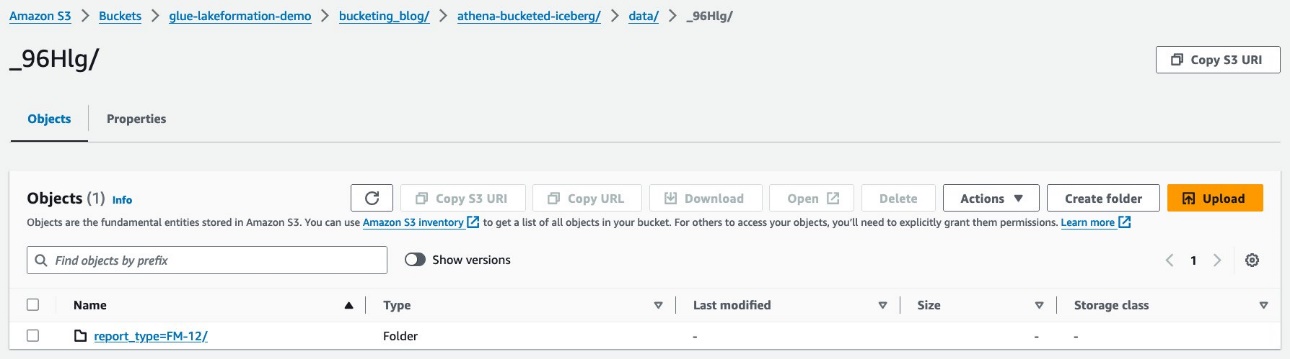
Du ser partisjonen på toppnivå basert på report_type kolonne. Drill ned til neste nivå.

Du ser partisjonen på andre nivå, fylt med station kolonne.
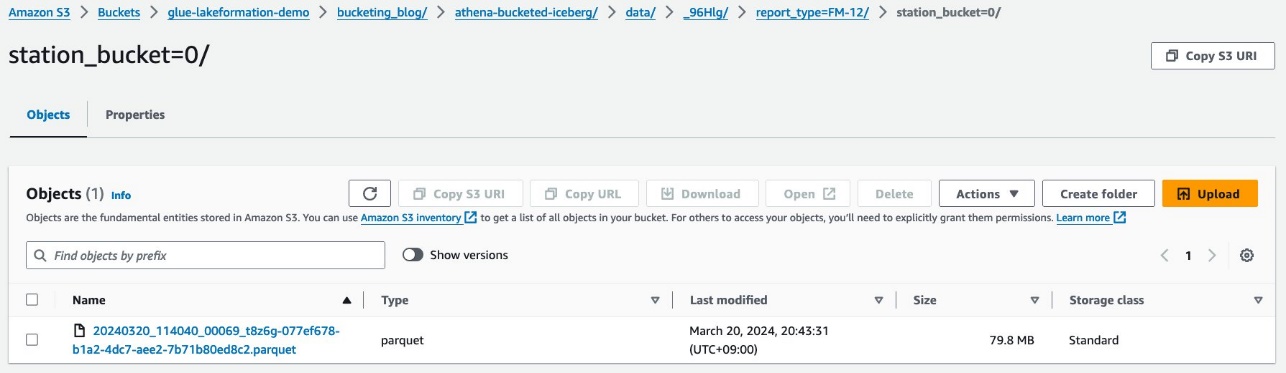
Parkettdatafilene finnes under disse mappene.
- Spørr i den inndelte tabellen med følgende setning:
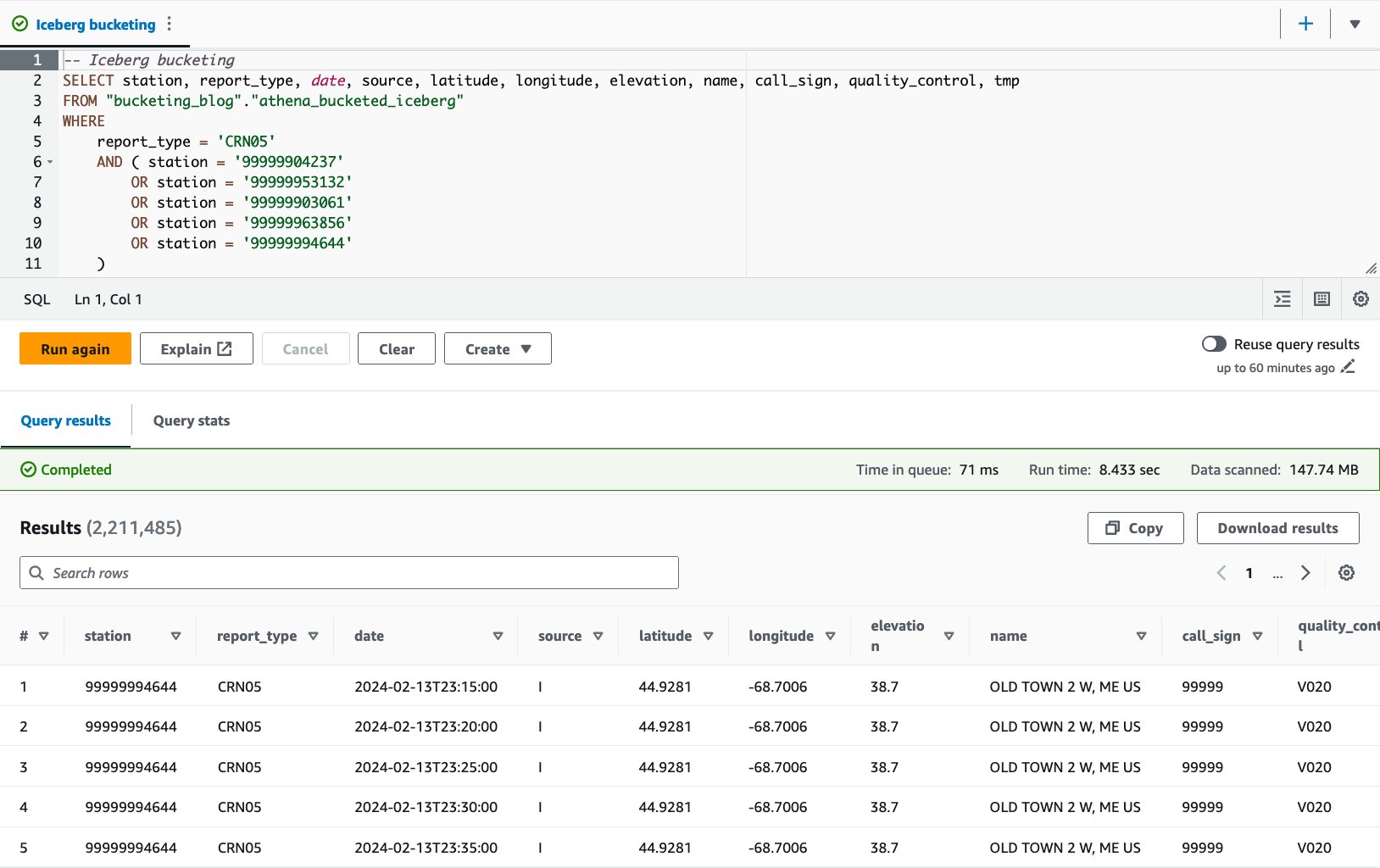
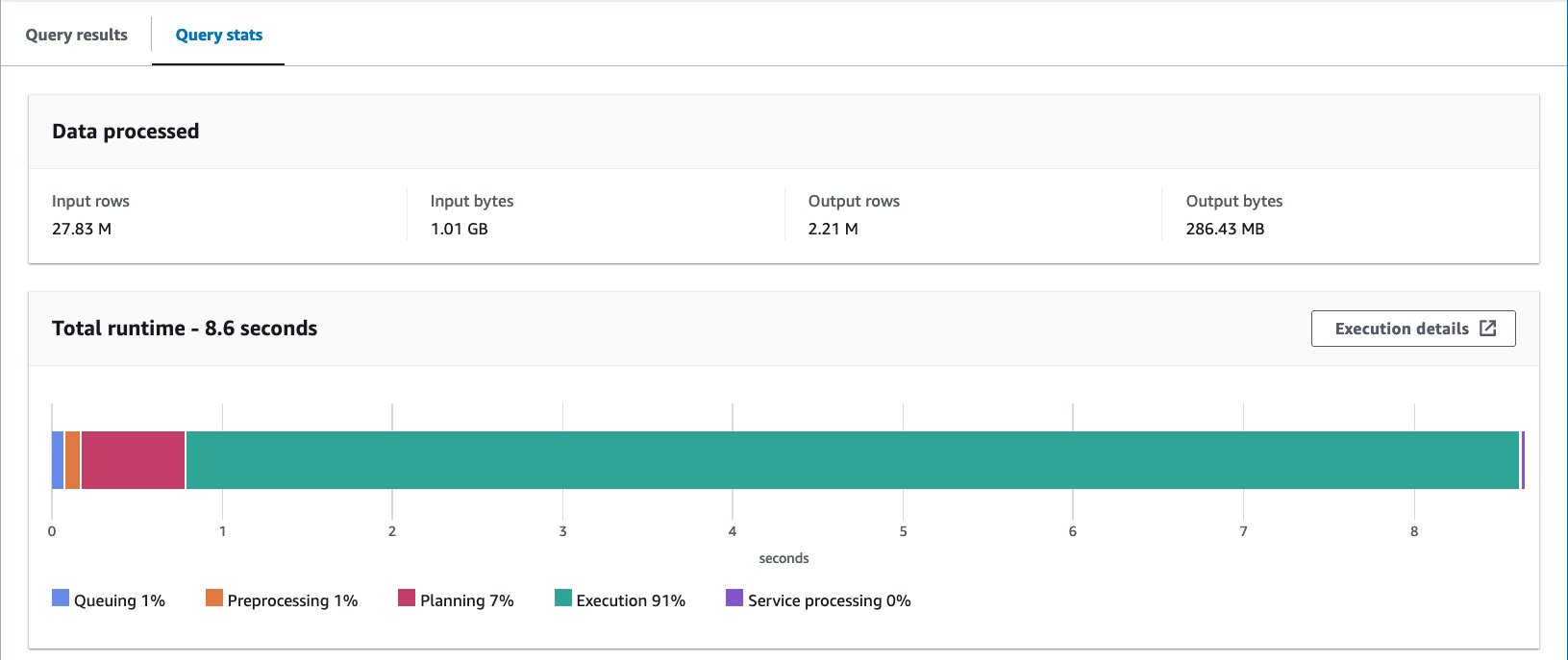
Med Iceberg-bøttetabellen er gjennomsnittlig kjøretid for de 10 spørringene 8.03 sekunder, og 148 MB data skannes for å returnere 2.21 millioner poster. Dette er mindre effektivt enn å bøtte med AWS Glue eller Athena, men med tanke på fordelene med Icebergs ulike funksjoner, er det innenfor et akseptabelt område.
Resultater
Tabellen nedenfor oppsummerer alle resultatene.
| . | noaa_remote_original | athena_non_bucketed | athena_bucketed | lim_bøttet | athena_bucketed_iceberg |
| dannet | CSV | parkett | parkett | parkett | Isfjell (parkett) |
| Komprimering | n / a | Snappy | Snappy | Snappy | Snappy |
| Laget via | n / a | Athena CTAS | Athena CTAS | Lim ETL | Athena CTAS med isfjell |
| Motor | n / a | Trino | Trino | Apache Spark | Apache isfjell |
| Tabellstørrelse (GB) | 155.8 | 5.0 | 5.0 | 5.8 | 5.0 |
| Antall S3-objekter | 53360 | 376 | 192 | 192 | 195 |
| Er partisjonert? | Ja, men på en annen måte | Ja | Ja | Ja | Ja |
| Er bøttet? | Nei | Nei | Ja | Ja | Ja |
| Bucket-format | n / a | n / a | Hive | Spark | Iceberg |
| Antall bøtter | n / a | n / a | 16 | 16 | 16 |
| Gjennomsnittlig kjøretid (sek) | 29.178 | 10.950 | 7.815 | 7.089 | 8.030 |
| Skannet størrelse (MB) | 206640.0 | 358.6 | 69.1 | 87.8 | 147.7 |
Med athena_bucketed, glue_bucketedog athena_bucketed_iceberg, var du i stand til å nå ventetidsmålet på 10 sekunder. Med bucketing fikk du 25–40 % reduksjon i kjøretid og 60–85 % reduksjon i skannestørrelse, noe som kan bidra til både ventetid og kostnadsoptimalisering.
Som du kan se av resultatet, selv om partisjonering bidrar betydelig til å redusere både kjøretid og skannestørrelse, kan bucketing også bidra til å redusere dem ytterligere.
Athena CTAS er grei og rask nok til å fullføre bøtteprosessen. AWS Glue ETL er mer fleksibel og skalerbar for å oppnå avanserte brukstilfeller. Du kan velge hvilken som helst metode basert på dine krav og brukstilfelle, fordi du kan dra nytte av bucketing gjennom begge alternativene.
konklusjonen
I dette innlegget demonstrerte vi hvordan du kan optimalisere tabelldataoppsettet med partisjonering og bucketing gjennom Athena CTAS og AWS Glue ETL. Vi viste at bucketing bidrar til å akselerere søkeforsinkelsen og redusere skannestørrelsen for å optimalisere kostnadene ytterligere. Vi diskuterte også bøtte for Iceberg-bord gjennom skjult partisjonering.
Lagrer kun én teknikk for å optimalisere datalayout ved å redusere dataskanning. For å optimalisere hele dataoppsettet, anbefaler vi å vurdere andre alternativer som partisjonering, bruk av kolonneformet filformat og komprimering i forbindelse med bucketing. Dette kan gjøre det mulig for dataene dine å forbedre søkeytelsen ytterligere.
Lykke til med bøtte!
Om forfatterne
 Takeshi Nakatani er en ledende Big Data-konsulent i Professional Services-teamet i Tokyo. Han har 26 års erfaring i IT-bransjen, med ekspertise innen arkitektur av datainfrastruktur. På fridagene kan han være rocketrommeslager eller motorsyklist.
Takeshi Nakatani er en ledende Big Data-konsulent i Professional Services-teamet i Tokyo. Han har 26 års erfaring i IT-bransjen, med ekspertise innen arkitektur av datainfrastruktur. På fridagene kan han være rocketrommeslager eller motorsyklist.
 Noritaka Sekiyama er en rektor Big Data Architect i AWS Glue-teamet. Han er ansvarlig for å bygge programvareartefakter for å hjelpe kunder. På fritiden liker han å sykle med landeveissykkelen.
Noritaka Sekiyama er en rektor Big Data Architect i AWS Glue-teamet. Han er ansvarlig for å bygge programvareartefakter for å hjelpe kunder. På fritiden liker han å sykle med landeveissykkelen.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/optimize-data-layout-by-bucketing-with-amazon-athena-and-aws-glue-to-accelerate-downstream-queries/

