«Data er i sentrum for enhver søknad, prosess og forretningsbeslutning. Når data brukes til å forbedre kundeopplevelser og drive innovasjon, kan det føre til forretningsvekst.»
- Swami Sivasubramanian, VP for Database, Analytics og Machine Learning hos AWS i Med en null-ETL-tilnærming hjelper AWS utbyggere med å realisere nesten sanntidsanalyse.
Kunder på tvers av bransjer blir mer datadrevne og ønsker å øke inntektene, redusere kostnadene og optimalisere forretningsdriften ved å implementere nesten sanntidsanalyser på transaksjonsdata, og dermed forbedre smidigheten. Basert på kundenes behov og deres tilbakemeldinger, investerer AWS og går stadig videre mot å bringe vår null-ETL-visjon ut i livet, slik at byggherrer kan fokusere mer på å skape verdi fra data, i stedet for å forberede data for analyse.
Vår null-ETL integrasjon med Amazon RedShift letter punkt-til-punkt databevegelse for å gjøre den klar for analyser, kunstig intelligens (AI) og maskinlæring (ML) ved å bruke Amazon Redshift på petabyte med data. Innen sekunder etter at transaksjonsdata er skrevet inn støttes AWS-databaser, zero-ETL gjør dataene sømløst tilgjengelige i Amazon Redshift, og fjerner behovet for å bygge og vedlikeholde komplekse datapipelines som utfører uttrekk, transformasjon og lasting (ETL) operasjoner.
For å hjelpe deg med å fokusere på å skape verdi fra data i stedet for å investere udifferensiert tid og ressurser i å bygge og administrere ETL-pipelines mellom transaksjonsdatabaser og datavarehus, kunngjorde fire AWS-databasenull-ETL-integrasjoner med Amazon Redshift på AWS re:Invent 2023:
I dette innlegget gir vi trinn-for-trinn-veiledning om hvordan du kommer i gang med operasjonelle analyser i nær sanntid ved hjelp av Amazon Aurora PostgreSQL null-ETL-integrasjon med Amazon Redshift.
Løsningsoversikt
For å opprette en null-ETL-integrasjon, spesifiserer du en Amazon Aurora PostgreSQL-kompatibel utgave klynge (kompatibel med PostgreSQL 15.4 og null-ETL-støtte) som kilde, og et Redshift-datavarehus som målet. Integrasjonen replikerer data fra kildedatabasen til måldatavarehuset.
Du må opprette Aurora PostgreSQL DB klargjorte klynger i Amazon RDS Database Preview Environment og en rødforskyvning klargjort forhåndsvisningsklynge or serverløs forhåndsvisningsarbeidsgruppe, i US East (Ohio) AWS-regionen. For Amazon Redshift, sørg for at du velger preview_2023-sporet for å bruke null-ETL-integrasjoner.
Følgende diagram illustrerer arkitekturen implementert i dette innlegget.
Følgende er trinnene som trengs for å sette opp null-ETL-integrasjonen for denne løsningen. For fullstendige startveiledninger, se Arbeider med Aurora zero-ETL-integrasjoner med Amazon Redshift og Arbeider med null-ETL-integrasjoner.
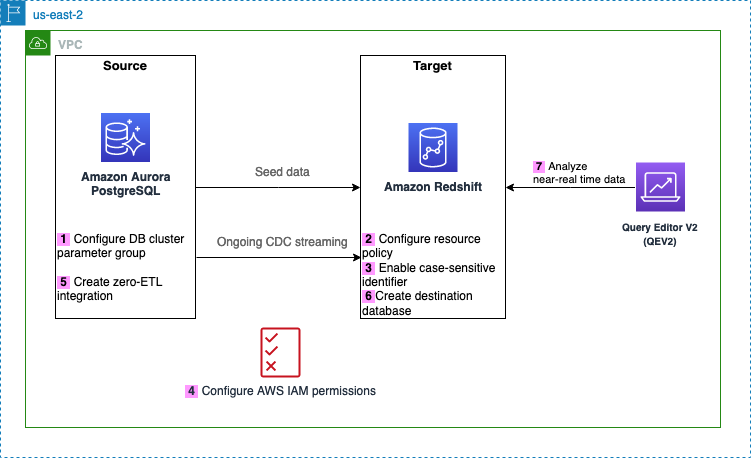
Etter trinn 1 kan du også hoppe over trinn 2–4 og begynne å lage din null-ETL-integrasjon fra trinn 5, i så fall vil Amazon RDS vise en melding om manglende konfigurasjoner, og du kan velge Fiks det for meg for å la Amazon RDS automatisk konfigurere trinnene.
- Konfigurer Aurora PostgreSQL-kilden med en tilpasset DB-klyngeparametergruppe.
- Konfigurer Amazon Redshift Serverløs destinasjon med nødvendig ressurspolicy for navneområdet.
- Oppdater Redshift Serverless-arbeidsgruppen for å aktivere identifikatorer som skiller mellom store og små bokstaver.
- Konfigurer de nødvendige tillatelsene.
- Opprett null-ETL-integrasjonen.
- Lag en database fra integrasjonen i Amazon Redshift.
- Begynn å analysere nær sanntids transaksjonsdata.
Konfigurer Aurora PostgreSQL-kilden med en tilpasset DB-klyngeparametergruppe
For Aurora PostgreSQL DB-klynger må du opprette den egendefinerte parametergruppen i Amazon RDS Database Preview Environment, i USA øst (Ohio)-regionen. Du kan direkte tilgang til Amazon RDS Preview Environment.
For å opprette en Aurora PostgreSQL-database, fullfør følgende trinn:
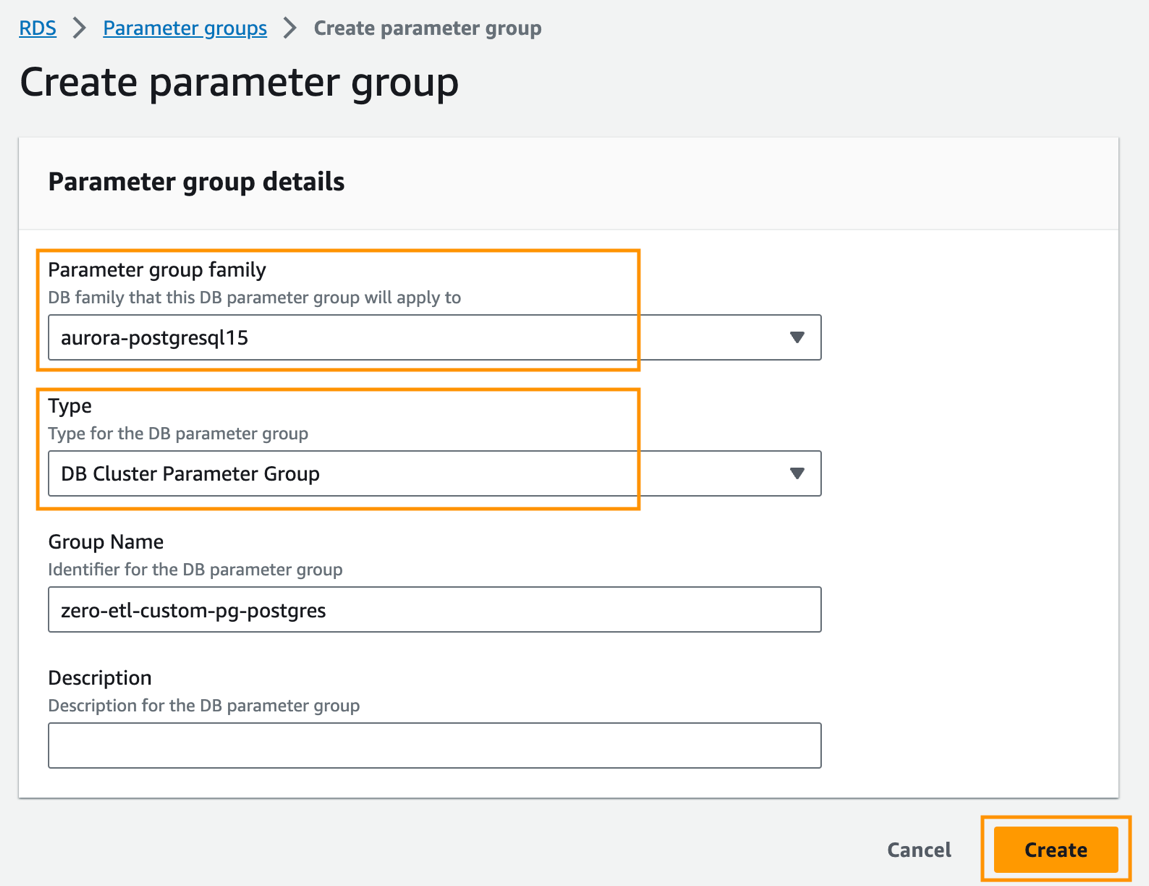
- På Amazon RDS-konsollen velger du Parametergrupper i navigasjonsruten.
- Velg Opprett parametergruppe.
- Til Parametergruppefamilie, velg
aurora-postgresql15. - Til typen, velg
DB Cluster Parameter Group. - Til Gruppenavn, skriv inn et navn (for eksempel,
zero-etl-custom-pg-postgres). - Velg Opprett.
Aurora PostgreSQL null-ETL-integrasjoner med Amazon Redshift krever spesifikke verdier for Aurora DB-klyngeparametere, som krever forbedret logisk replikering (aurora.enhanced_logical_replication).
- På Parametergrupper siden, velg den nyopprettede parametergruppen.
- På handlinger meny, velg Rediger.
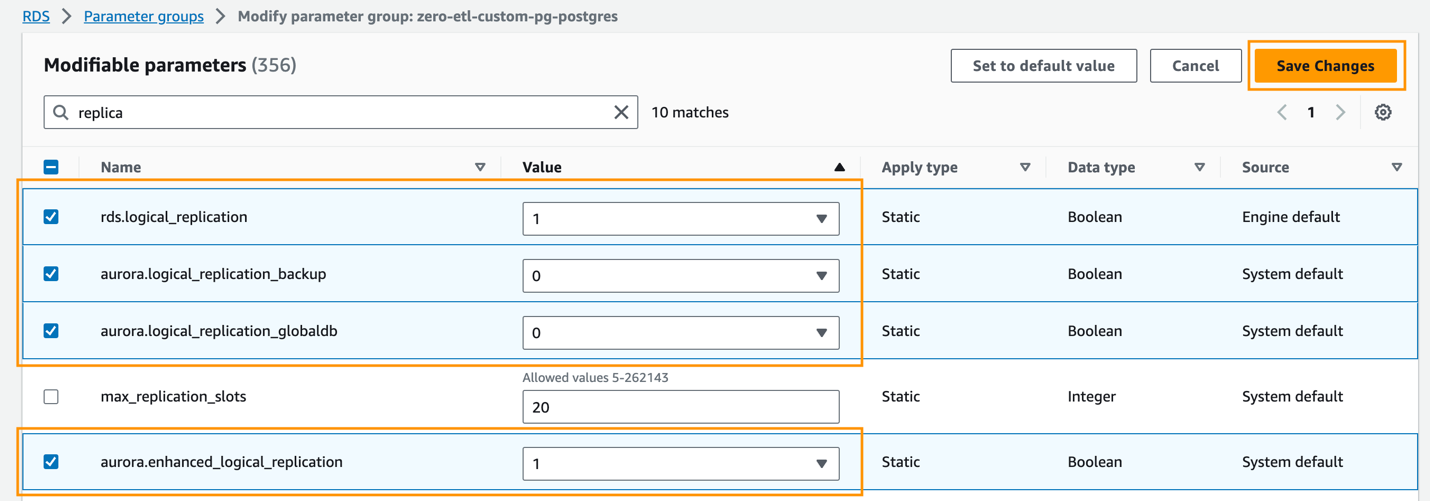
- Sett følgende Aurora PostgreSQL (aurora-postgresql15 familie) klyngeparameterinnstillinger:
rds.logical_replication=1aurora.enhanced_logical_replication=1aurora.logical_replication_backup=0aurora.logical_replication_globaldb=0
Aktivering av forbedret logisk replikering (aurora.enhanced_logical_replication) setter automatisk REPLICA IDENTITY-parameteren til FULL, noe som betyr at alle kolonneverdier skrives til loggen for skriving fremover (WAL).
- Velg Lagre endringer.
- Velg databaser i navigasjonsruten, og velg deretter Lag database.

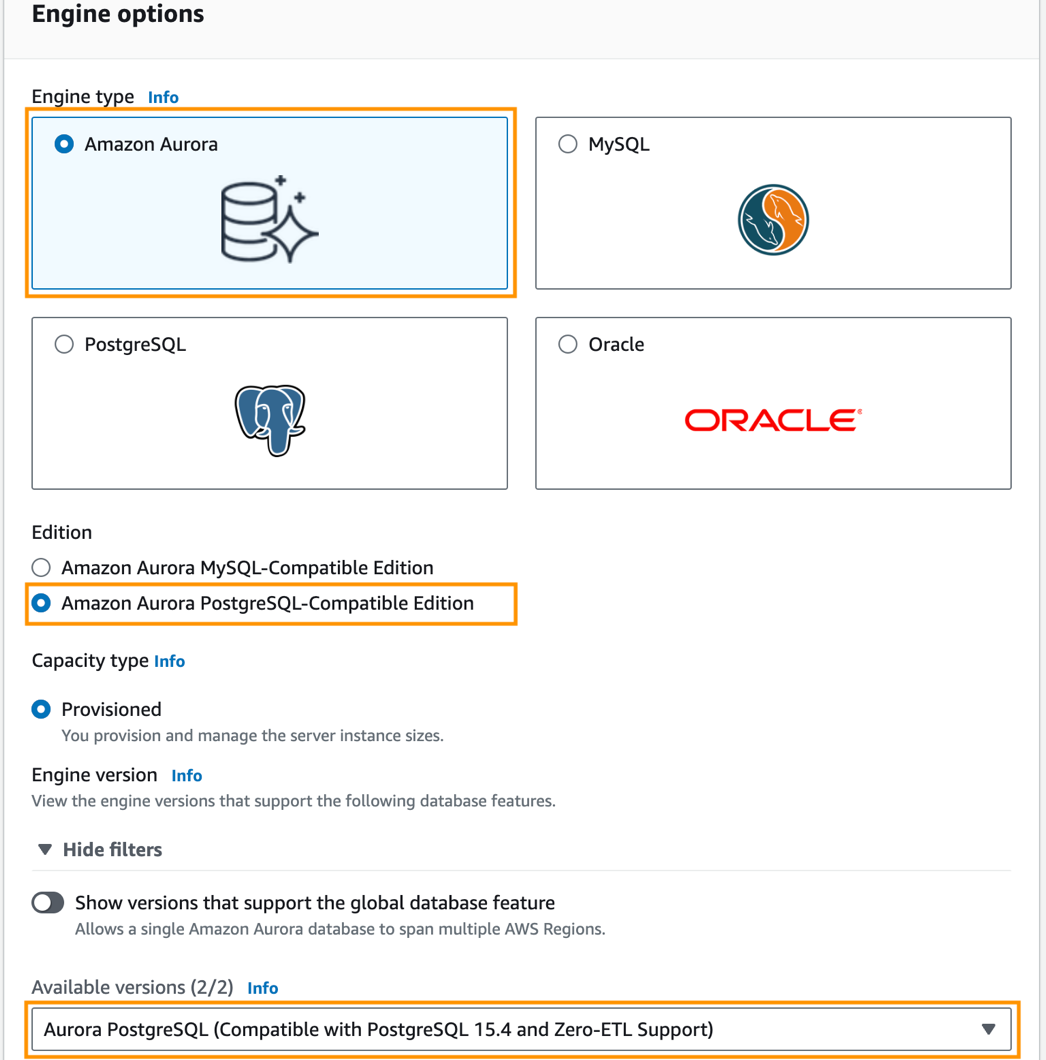
- Til Motortype, plukke ut Amazonas Aurora.
- Til Edition, plukke ut Amazon Aurora PostgreSQL-kompatibel utgave.
- Til Tilgjengelige versjoner, velg Aurora PostgreSQL (kompatibel med PostgreSQL 15.4 og Zero-ETL Support).
- Til maler, plukke ut Produksjon.
- Til DB-klyngeidentifikator, Tast inn
zero-etl-source-pg.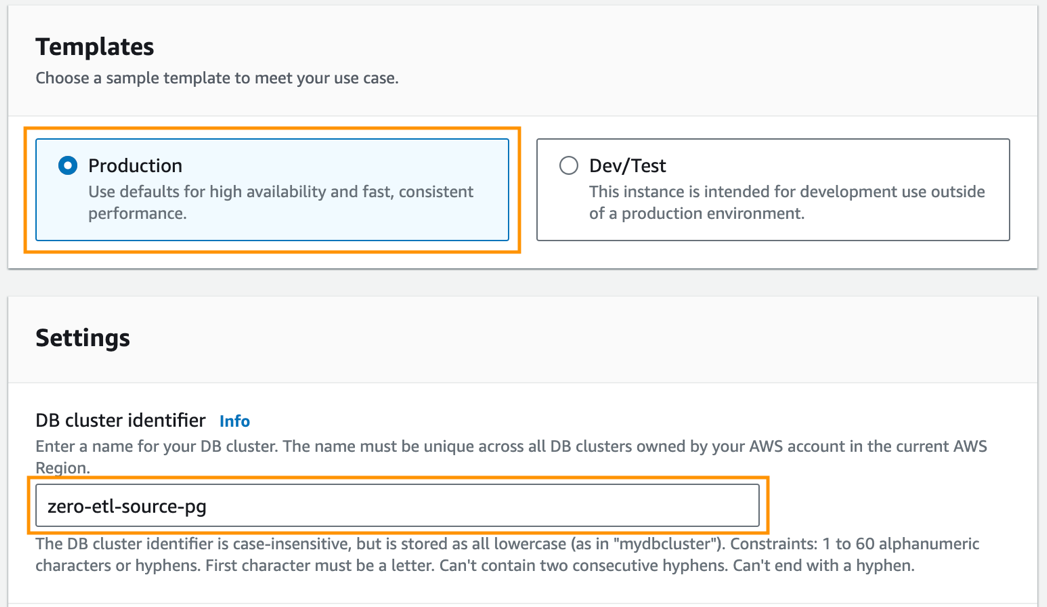
- Under Innstillinger for legitimasjon, skriv inn et passord for Hovedpassord eller bruk alternativet for å automatisk generere et passord for deg.
- på Seksjon for instanskonfigurasjon, plukke ut Minneoptimaliserte klasser.
- Velg en passende forekomststørrelse (standard er
db.r5.2xlarge).
- Under Ekstra konfigurasjonFor DB-klyngeparametergruppe, velg parametergruppen du opprettet tidligere (
zero-etl-custom-pg-postgres).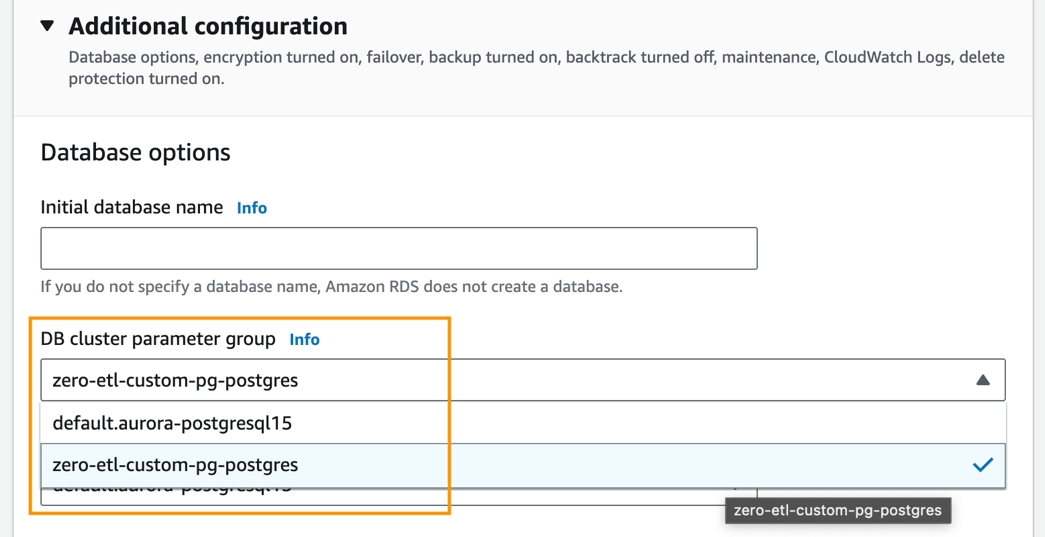
- La standardinnstillingene for de gjenværende konfigurasjonene være igjen.
- Velg Lag database.
I løpet av noen få minutter skulle dette spinne opp en Aurora PostgreSQL-klynge, med én forfatter og én leserforekomst, med statusen endret fra Opprette til Tilgjengelig. Den nyopprettede Aurora PostgreSQL-klyngen vil være kilden for null-ETL-integrasjonen.
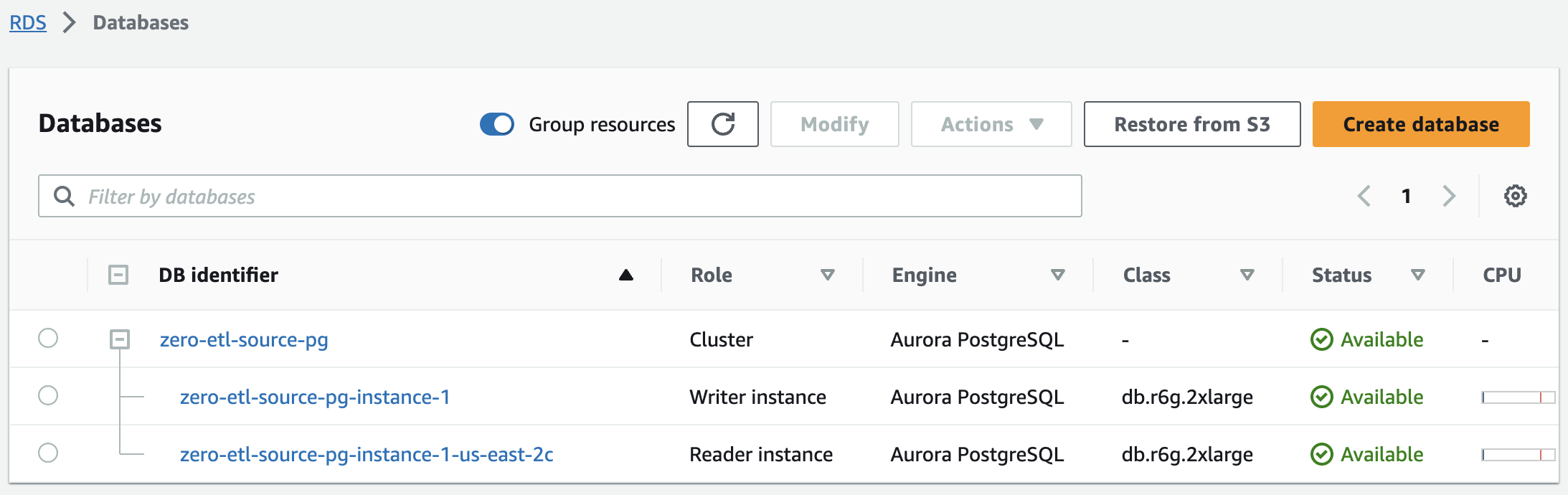
Det neste trinnet er å lage en navngitt database i Amazon Aurora PostgreSQL for null-ETL-integrasjonen.
PostgreSQL-ressursmodellen lar deg lage flere databaser i en klynge. Derfor må du spesifisere hvilken database du vil bruke som kilde for integrasjonen under opprettelsestrinnet med null-ETL-integrasjon.
Når du setter opp PostgreSQL, får du tre standarddatabaser ut av esken: template0, template1 og postgres. Når du oppretter en ny database i PostgreSQL, baserer du den faktisk på en av disse tre databasene i klyngen din. Databasen som ble opprettet under opprettelsen av Aurora PostgreSQL-klynge er basert på template0. De CREATE DATABASE kommandoen fungerer ved å kopiere en eksisterende database, og hvis den ikke er spesifisert, som standard, kopierer den standard systemdatabasemal1. For den navngitte databasen for null-ETL-integrasjon, må databasen opprettes ved hjelp av template1 og ikke template0. Derfor, hvis et første databasenavn legges til under Ekstra konfigurasjon, som vil bli opprettet ved hjelp av template0 og kan ikke brukes for null-ETL-integrasjon.
- For å lage en ny navngitt database ved å bruke
CREATE DATABASEi den nye Aurora PostgreSQL-klyngenzero-etl-source-pg, få først endepunktet til writer-forekomsten av PostgreSQL-klyngen.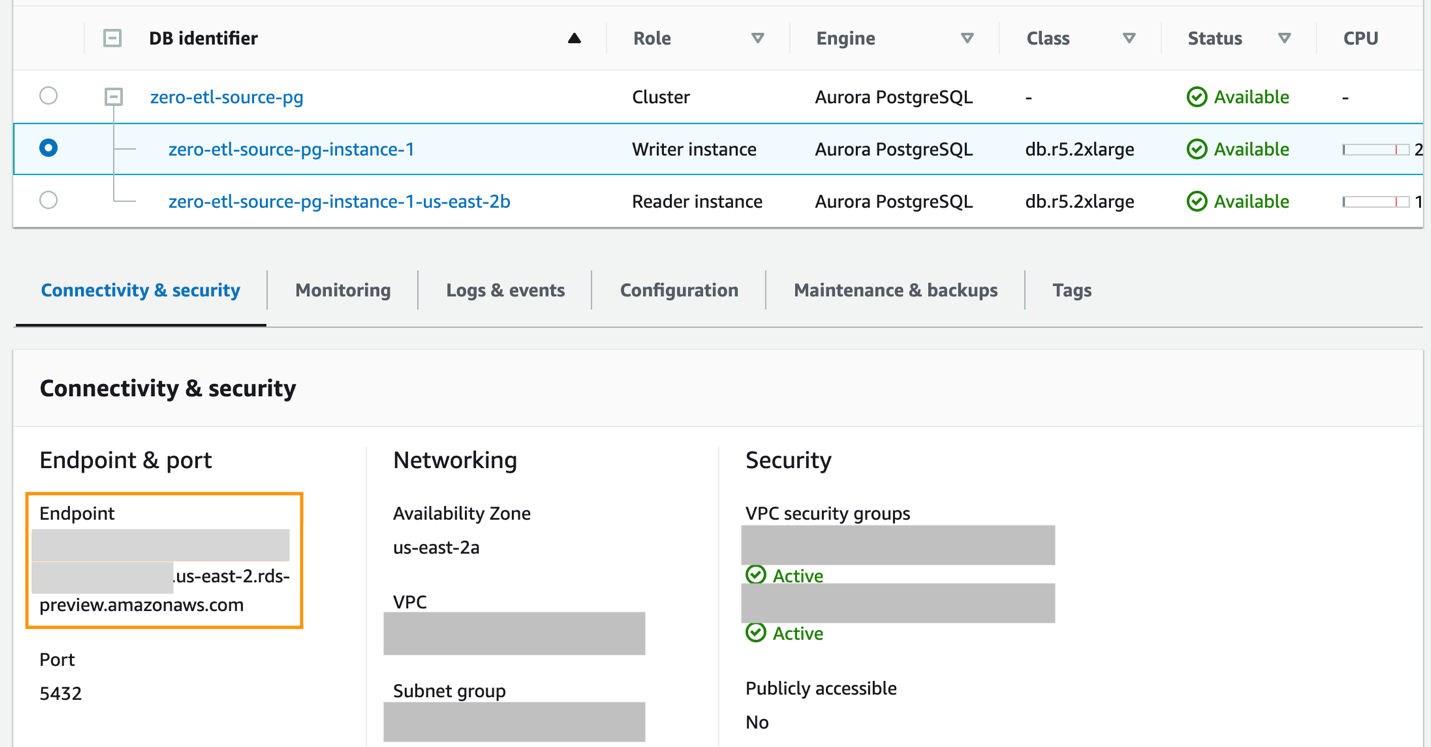
- Fra en terminal eller ved hjelp av AWS CloudShell, SSH inn i PostgreSQL-klyngen og kjør følgende kommandoer for å installere psql og opprette en ny database
zeroetl_db:
Legge template template1 er valgfritt, fordi som standard, hvis ikke nevnt, CREATE DATABASE vil bruke template1.
Du kan også koble til via en klient og opprette databasen. Referere til Koble til en Aurora PostgreSQL DB-klynge for alternativene for å koble til PostgreSQL-klyngen.
Konfigurer Redshift Serverless som destinasjon
Etter at du har opprettet Aurora PostgreSQL-kildedatabaseklyngen, konfigurerer du et Redshift-måldatavarehus. Datavarehuset må oppfylle følgende krav:
- Laget i forhåndsvisning (kun for Aurora PostgreSQL-kilder)
- Bruker en RA3-nodetype (ra3.16xlarge, ra3.4xlarge eller ra3.xlplus) med minst to noder, eller Redshift Serverless
- Kryptert (hvis du bruker en klargjort klynge)
For dette innlegget oppretter og konfigurerer vi en Redshift Serverless-arbeidsgruppe og navneområde som måldatavarehuset, ved å følge disse trinnene:
- På Amazon Redshift-konsollen velger du Serverløst dashbord i navigasjonsruten.
Fordi null-ETL-integrasjonen for Amazon Aurora PostgreSQL til Amazon Redshift har blitt lansert i forhåndsvisning (ikke for produksjonsformål), må du opprette måldatavarehuset i et forhåndsvisningsmiljø.
- Velg Opprett forhåndsvisningsarbeidsgruppe.
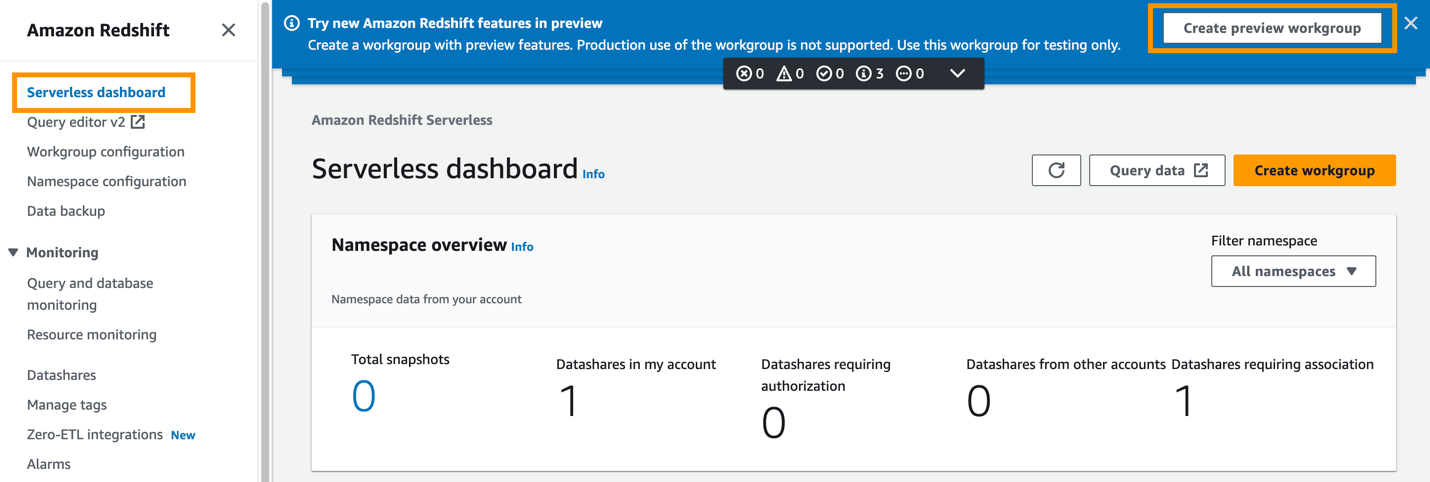
Det første trinnet er å konfigurere Redshift Serverless-arbeidsgruppen.
- Til Arbeidsgruppenavn, skriv inn et navn (for eksempel,
zero-etl-target-rs-wg).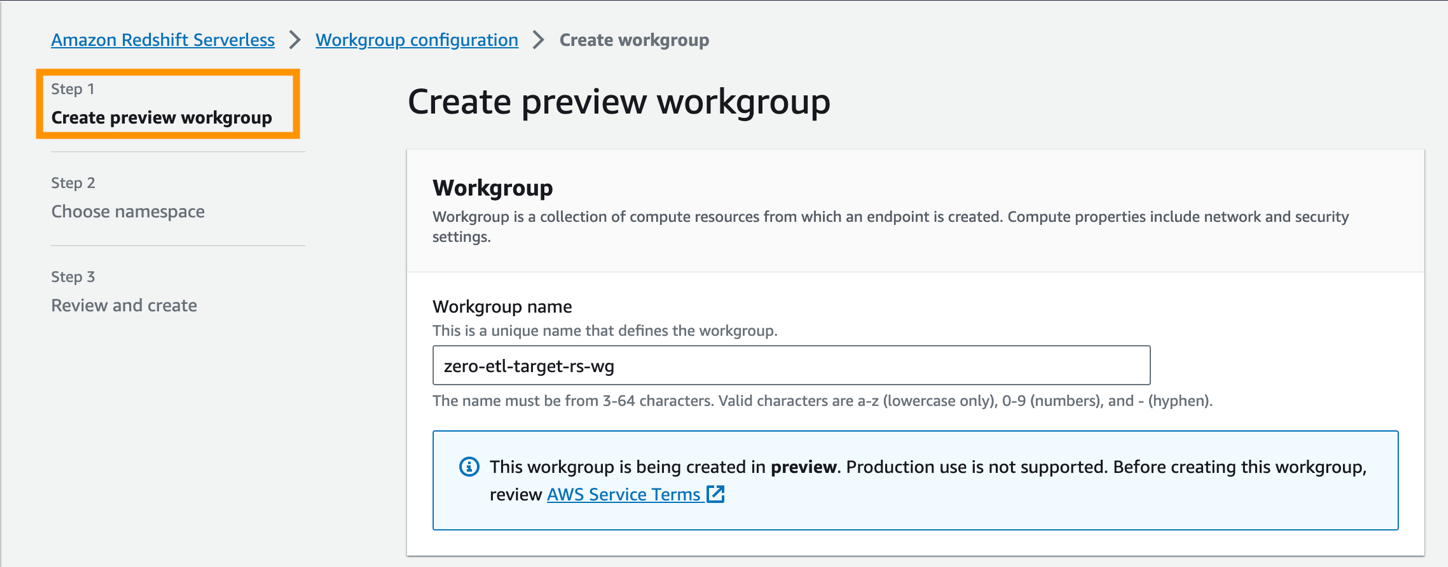
- I tillegg kan du velge kapasiteten for å begrense datavarehusets ressurser. Kapasiteten kan konfigureres i trinn på 8, fra 8–512 RPUer. For dette innlegget, sett dette til
8RPUer. - Velg neste.

Deretter må du konfigurere navneområdet til datavarehuset.
- Plukke ut Opprett et nytt navneområde.
- Til namespace, skriv inn et navn (for eksempel,
zero-etl-target-rs-ns). - Velg neste.
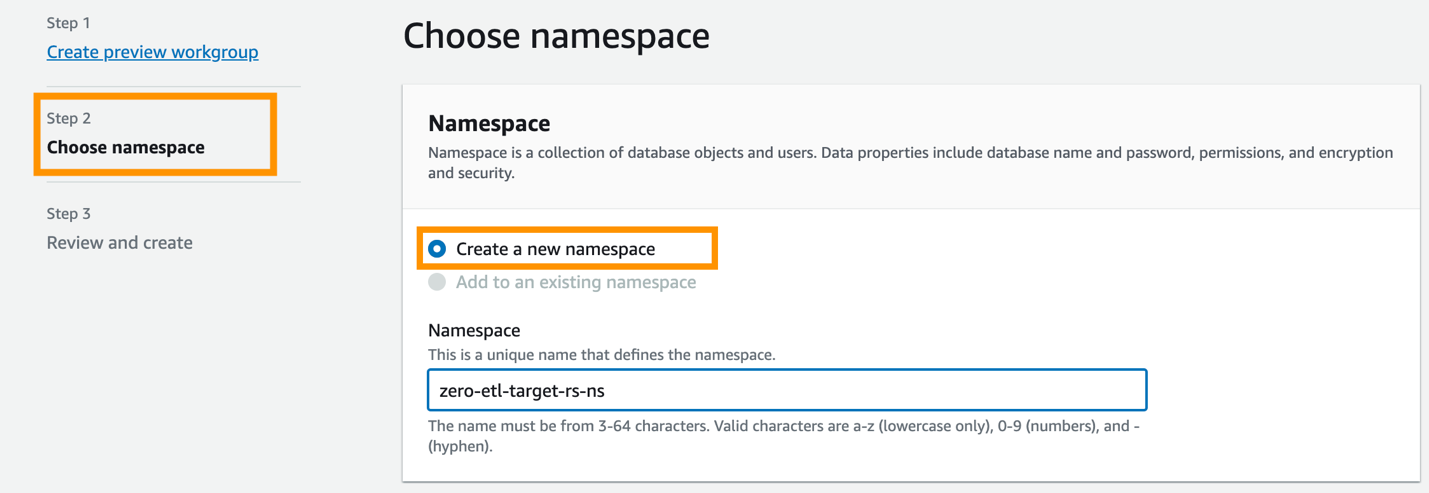
- Velg Opprett arbeidsgruppe.
- Etter at arbeidsgruppen og navneområdet er opprettet, velger du Navneområdekonfigurasjoner i navigasjonsruten og åpne navneområdekonfigurasjonen.
- På Ressurspolitikk kategorien, velg Legg til autoriserte rektorer.
En autorisert rektor identifiserer brukeren eller rollen som kan opprette null-ETL-integrasjoner i datavarehuset.

- Til IAM-rektor ARN- eller AWS-konto-ID, kan du angi enten ARN-en til AWS-brukeren eller -rollen, eller ID-en til AWS-kontoen som du vil gi tilgang for å lage null-ETL-integrasjoner. (En konto-ID lagres som en ARN.)
- Velg lagre endringer.
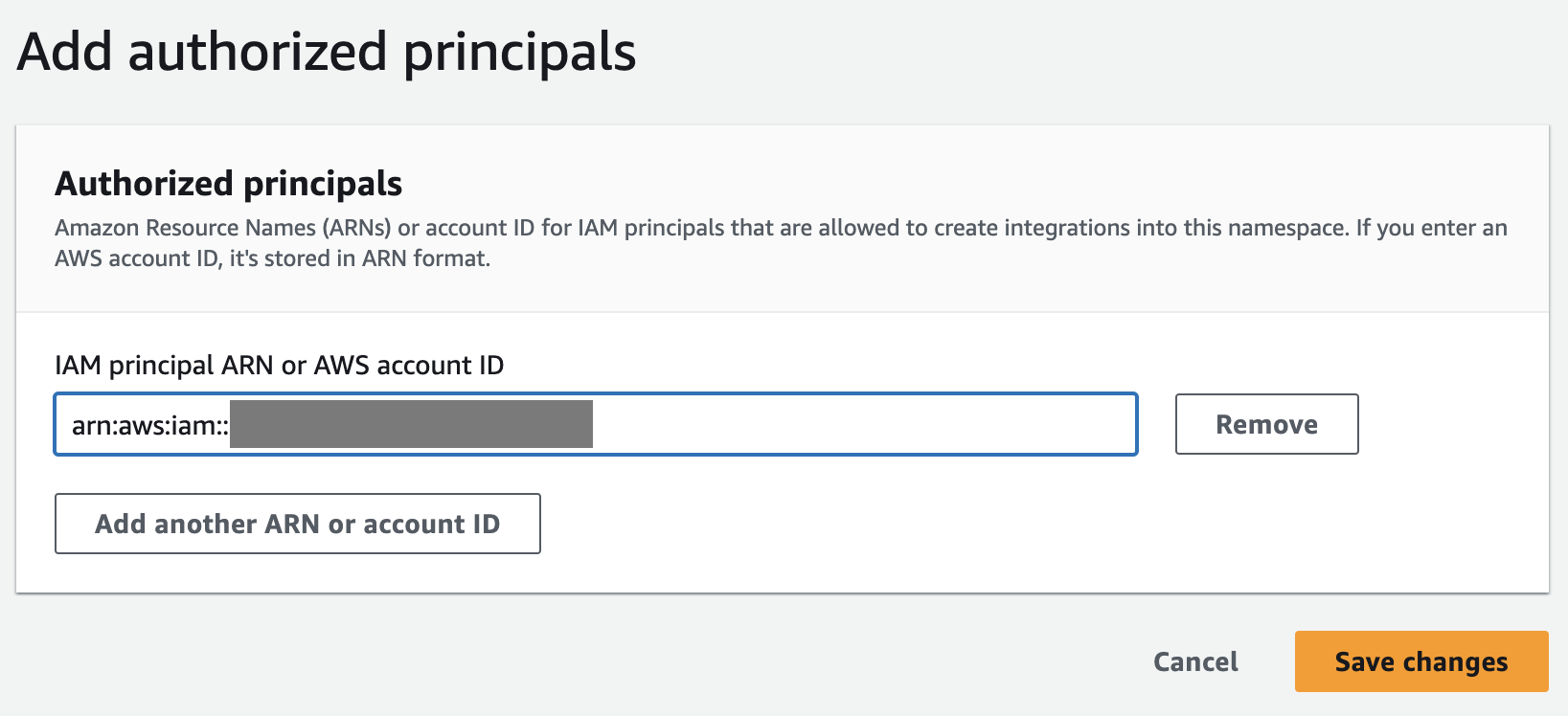
Etter at den autoriserte rektor er konfigurert, må du tillate at kildedatabasen oppdaterer Redshift-datavarehuset. Derfor må du legge til kildedatabasen som en autorisert integrasjonskilde i navneområdet.
- Velg Legg til autorisert integrasjonskilde.
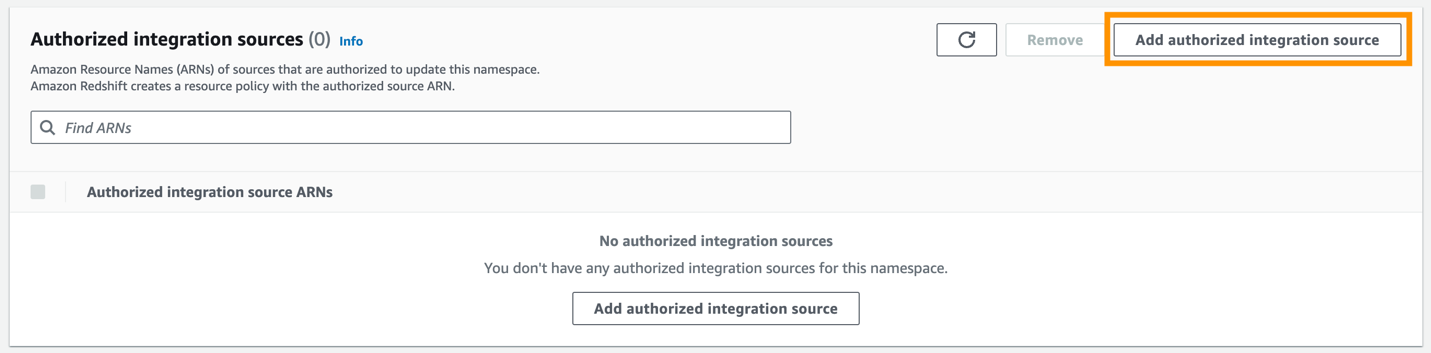
- Til Autorisert kilde ARN, skriv inn ARN for Aurora PostgreSQL-klyngen, fordi det er kilden til null-ETL-integrasjonen.
Du kan få ARN for Aurora PostgreSQL-klyngen på Amazon RDS-konsollen, Konfigurasjon finner du under Amazon ressursnavn.
- Velg lagre endringer.
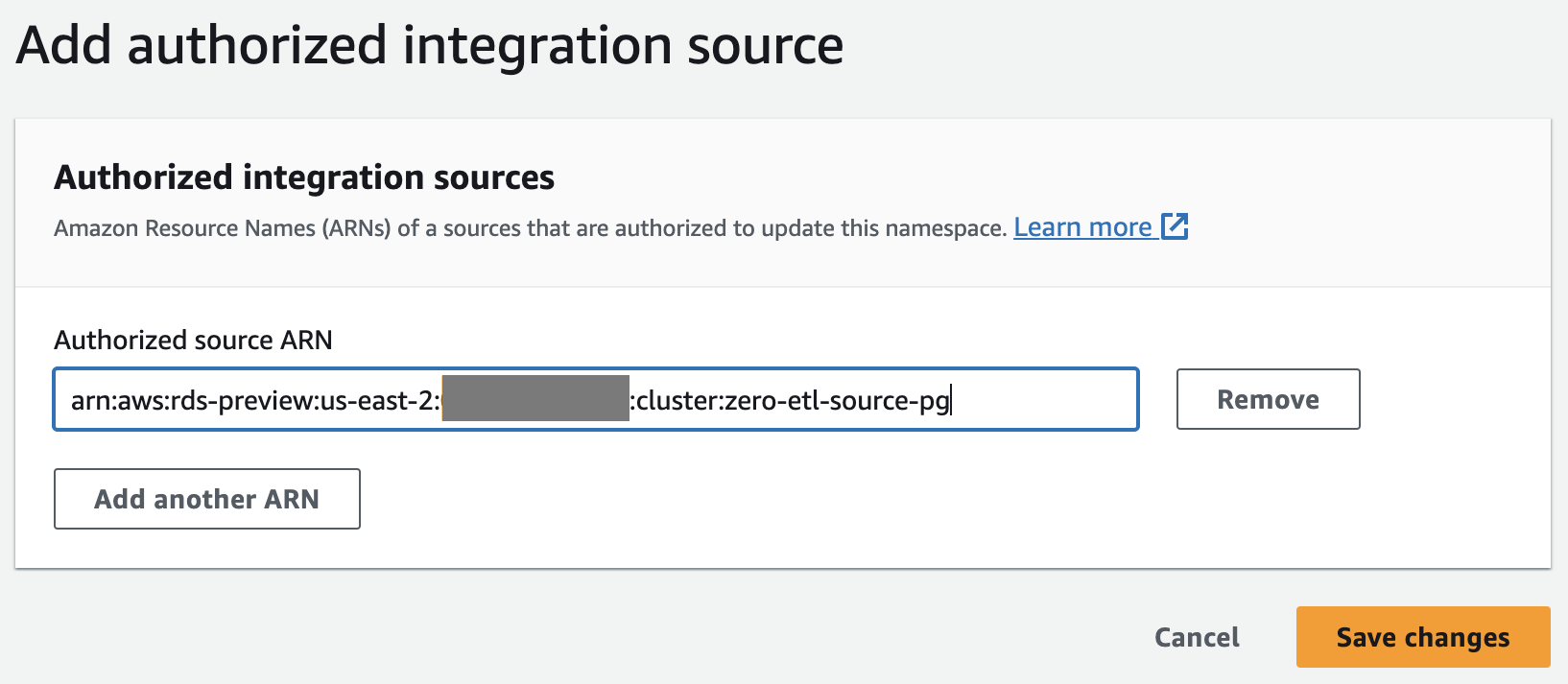
Oppdater Redshift Serverless-arbeidsgruppen for å aktivere identifikatorer som skiller mellom store og små bokstaver
Amazon Aurora PostgreSQL skiller mellom store og små bokstaver som standard, og store og små bokstaver er deaktivert på alle klargjorte klynger og Redshift Serverless-arbeidsgrupper. For at integrasjonen skal lykkes, er parameteren for store og små bokstaver enable_casesensitive_identifier må være aktivert for datavarehuset.
For å endre enable_case_sensitive_identifier parameter i en Redshift Serverless-arbeidsgruppe, må du bruke AWS kommandolinjegrensesnitt (AWS CLI), fordi Amazon Redshift-konsollen for øyeblikket ikke støtter endring av Redshift Serverless-parameterverdier. Kjør følgende kommando for å oppdatere parameteren:
En enkel måte å koble til AWS CLI på er å bruke CloudShell, som er et nettleserbasert skall som gir kommandolinjetilgang til AWS-ressursene og verktøyene direkte fra en nettleser. Følgende skjermbilde illustrerer hvordan du kjører kommandoen i CloudShell.
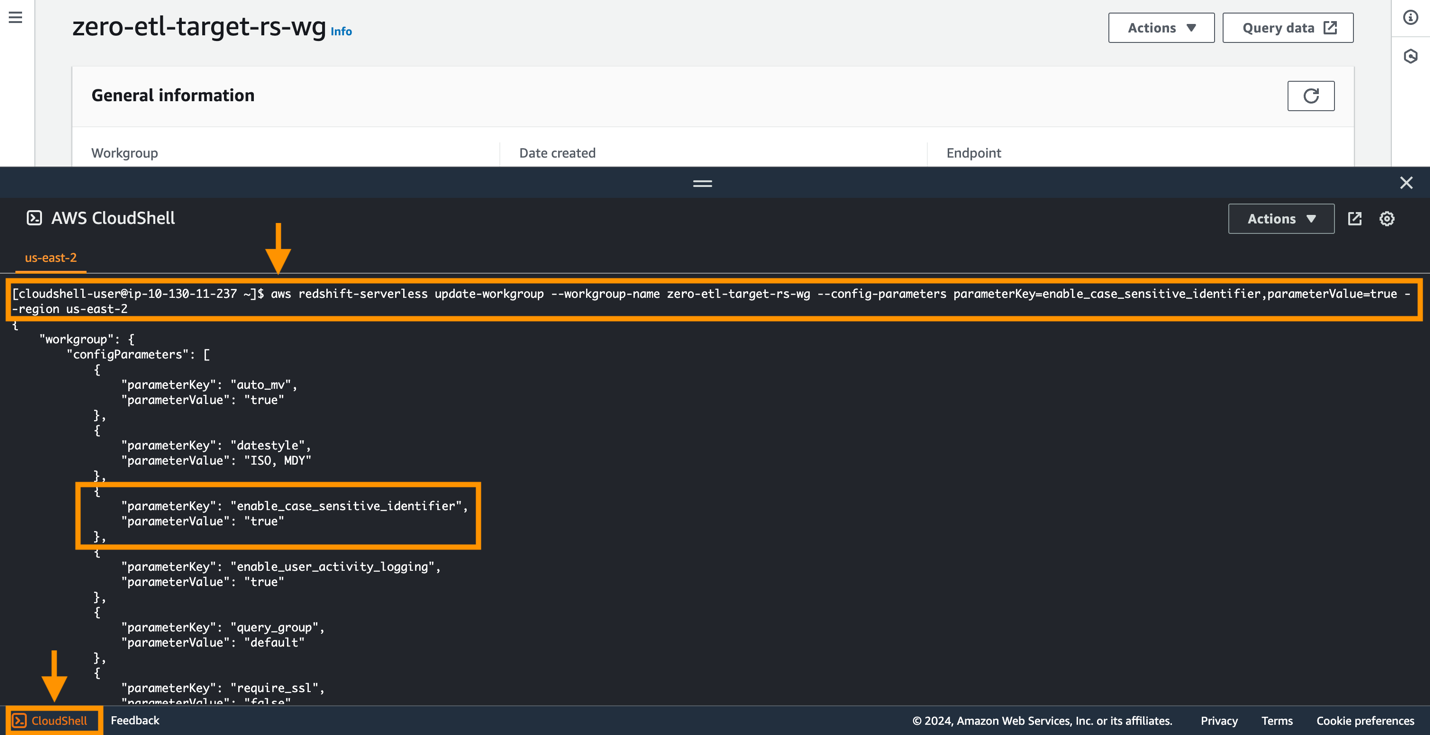
Konfigurer nødvendige tillatelser
For å opprette en null-ETL-integrasjon, må brukeren eller rollen din ha en vedlagt identitetsbasert politikk med det aktuelle AWS identitets- og tilgangsadministrasjon (IAM) tillatelser. En AWS-kontoeier kan konfigurere nødvendige tillatelser for brukere eller roller som kan lage null-ETL-integrasjoner. Eksempelpolicyen lar den tilknyttede rektor utføre følgende handlinger:
- Opprett null-ETL-integrasjoner for kilde Aurora DB-klyngen.
- Se og slett alle null-ETL-integrasjoner.
- Opprett inngående integrasjoner i måldatavarehuset. Amazon Redshift har et annet ARN-format for klargjort og serverløst:
- Forsynt klynge -
arn:aws:redshift:{region}:{account-id}:namespace:namespace-uuid - server~~POS=TRUNC -
arn:aws:redshift-serverless:{region}:{account-id}:namespace/namespace-uuid
Denne tillatelsen er ikke nødvendig hvis den samme kontoen eier Redshift-datavarehuset og denne kontoen er en autorisert rektor for det datavarehuset.
Fullfør følgende trinn for å konfigurere tillatelsene:
- Velg på IAM-konsollen Policy i navigasjonsruten.
- Velg Opprett policy.
- Opprett en ny policy kalt rds-integrasjoner ved å bruke følgende JSON. For forhåndsvisningen av Amazon Aurora PostgreSQL, alle ARN-er og handlinger i Amazon RDS Database Preview Environment har -forhåndsvisning lagt til tjenestenavneområdet. Derfor, i følgende policy, i stedet for rds, må du bruke
rds-preview. For eksempel,rds-preview:CreateIntegration.
- Legg ved policyen du opprettet til IAM-bruker- eller rolletillatelsene dine.
Opprett null-ETL-integrasjonen
For å opprette null-ETL-integrasjonen, fullfør følgende trinn:
- På Amazon RDS-konsollen velger du Null-ETL-integrasjoner i navigasjonsruten.
- Velg Lag null-ETL-integrasjon.
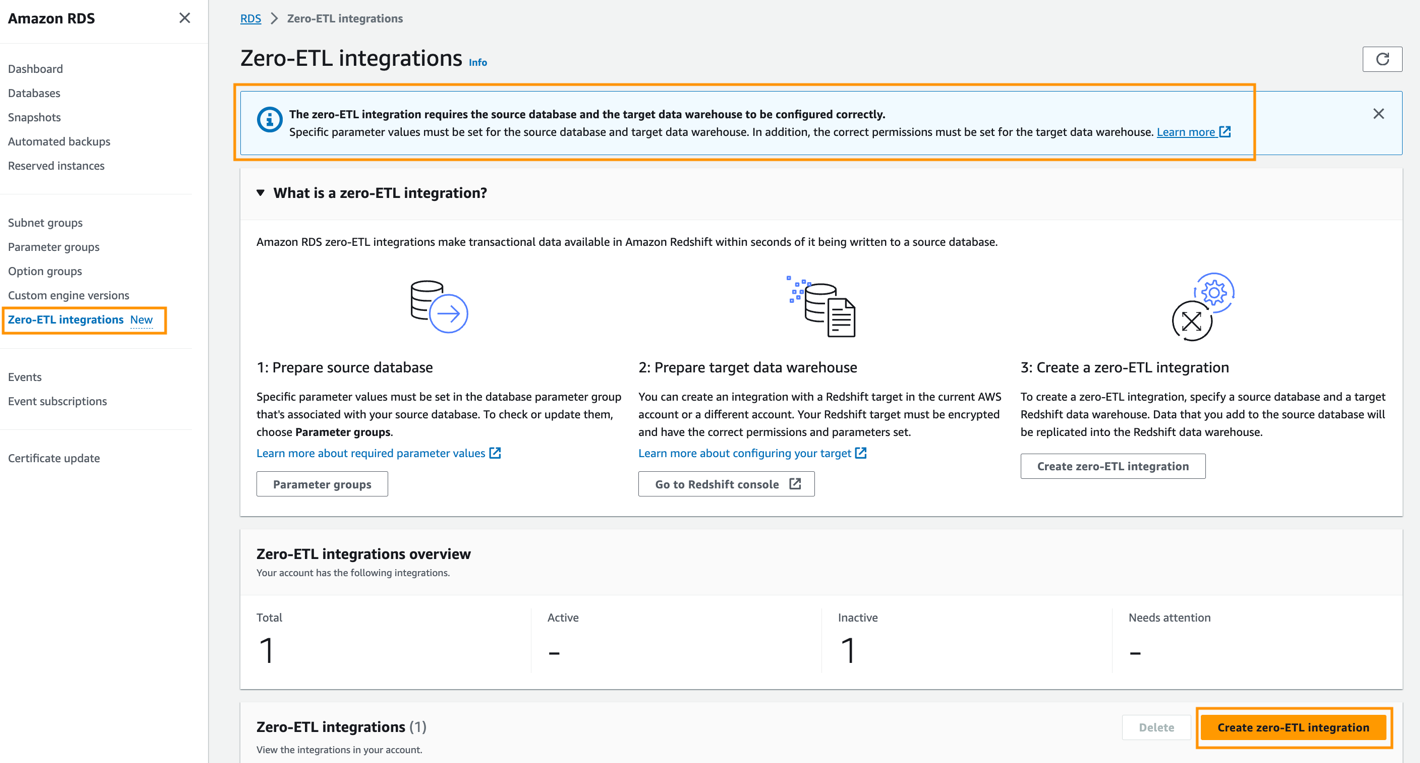
- Til Integrasjonsidentifikator, skriv inn et navn, for eksempel
zero-etl-demo. - Velg neste.

- Til Kildedatabase, velg Bla gjennom RDS-databaser.
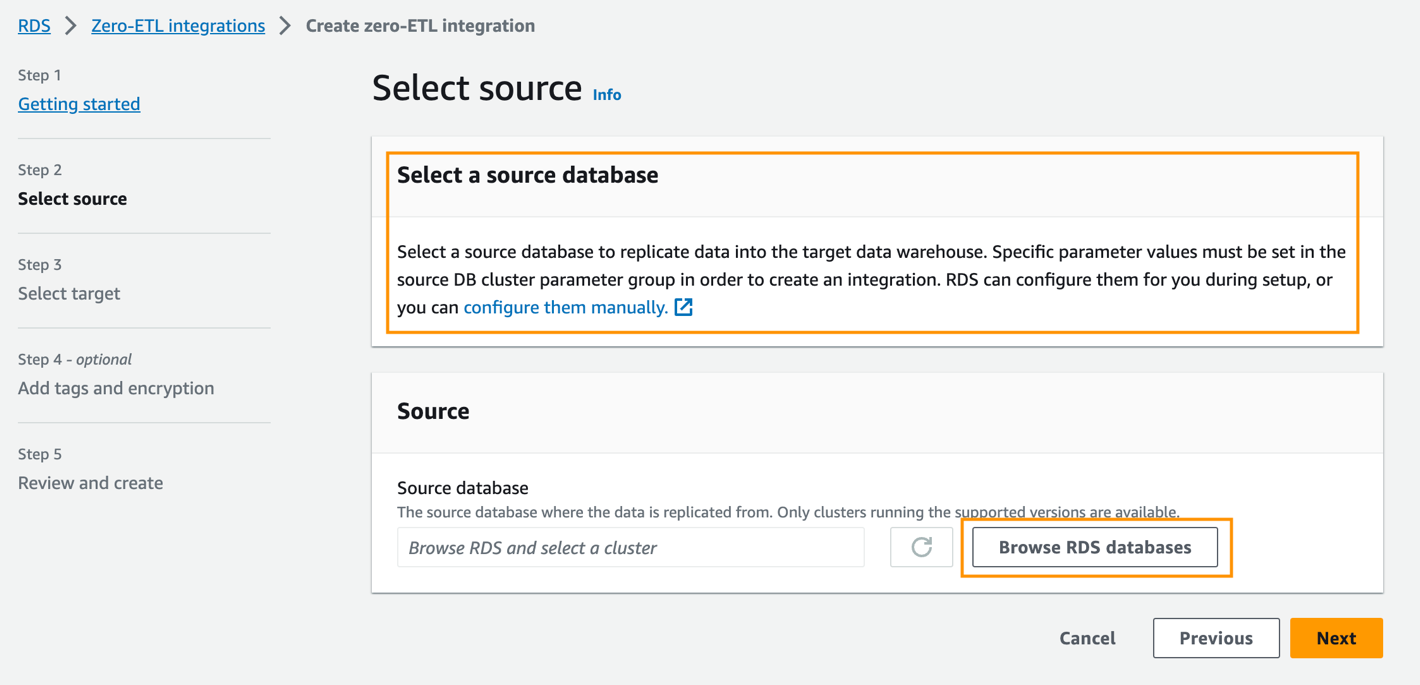
- Velg kildedatabasen
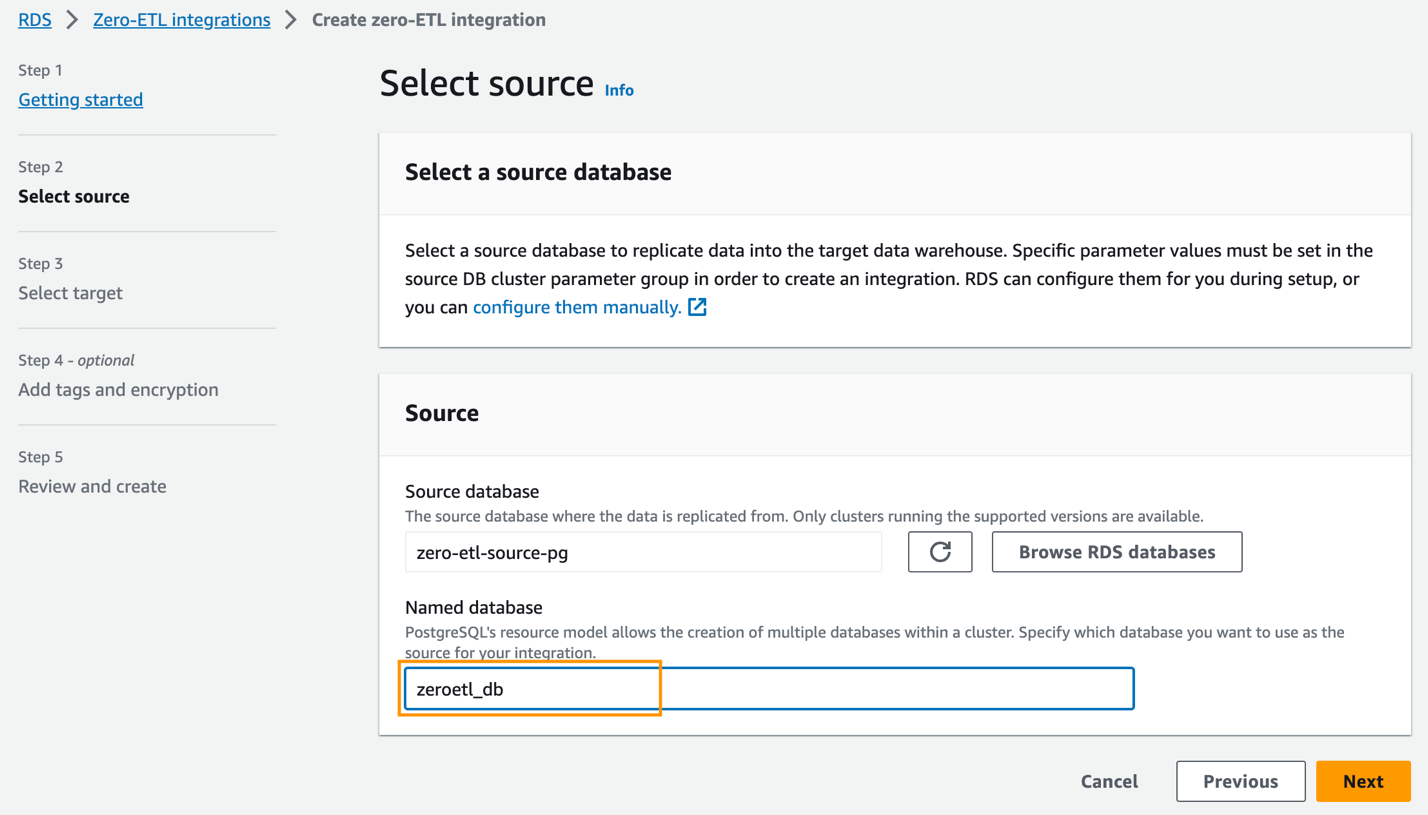
zero-etl-source-pgOg velg Velg. - Til Navngitt database, skriv inn navnet på den nye databasen opprettet i Amazon Aurora PostgreSQL (
zeroetl-db). - Velg neste.
- på MålseksjonFor AWS-konto, plukke ut Bruk gjeldende konto.
- Til Amazon Redshift datavarehus, velg Bla gjennom Redshift-datavarehus.

Vi diskuterer Angi en annen konto alternativet senere i denne delen.
- Velg destinasjonsnavneområdet Redshift Serverless (
zero-etl-target-rs-ns), og velg Velg.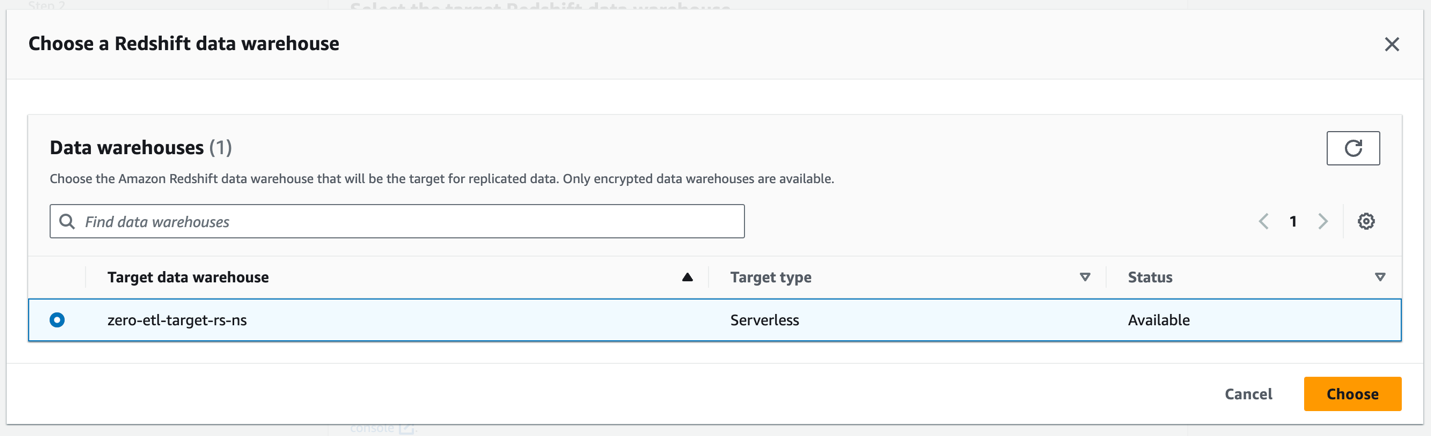
- Legg til tagger og kryptering, hvis aktuelt, og velg Neste.
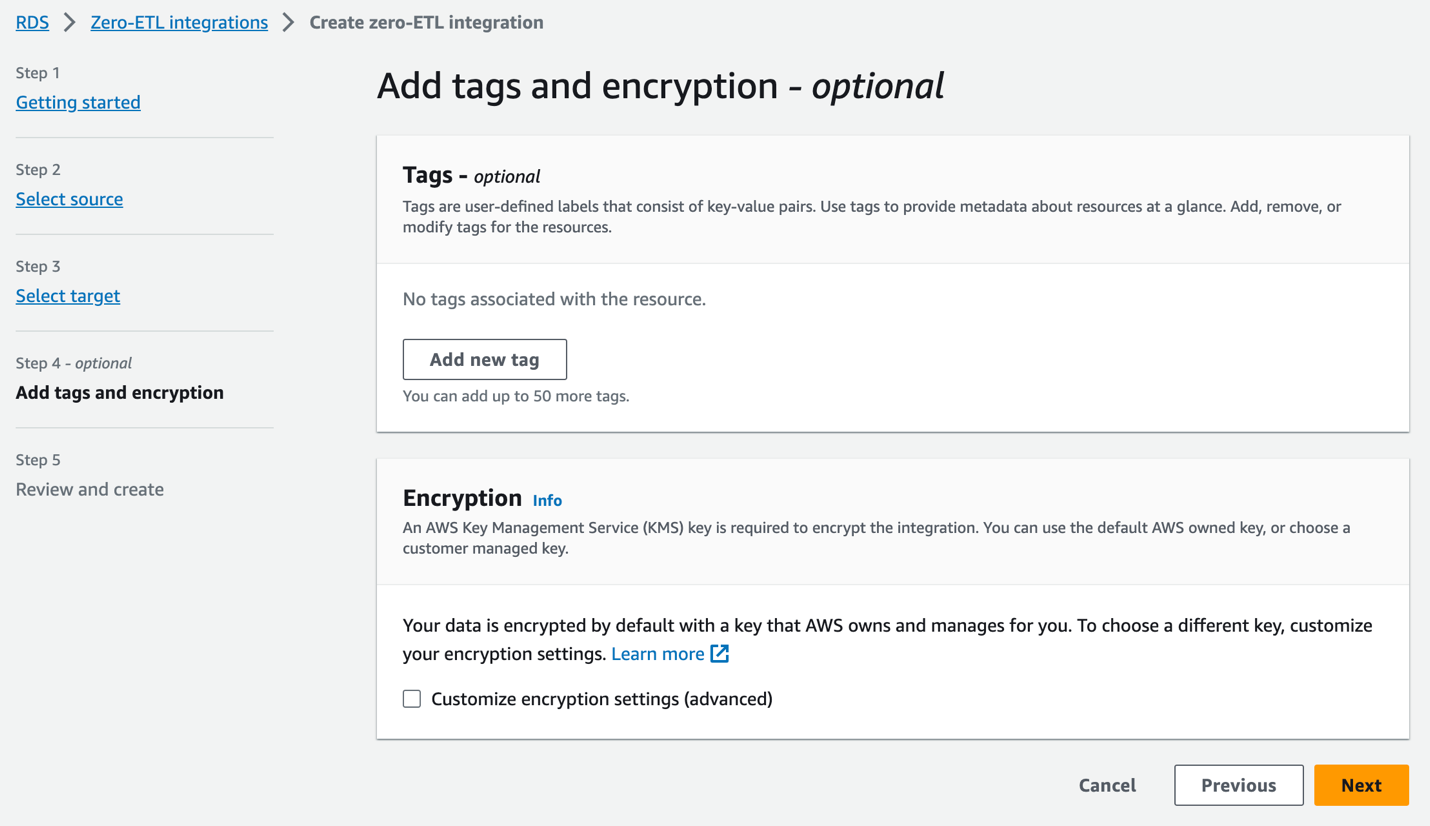
- Bekreft integreringsnavnet, kilden, målet og andre innstillinger, og velg Lag null-ETL-integrasjon.
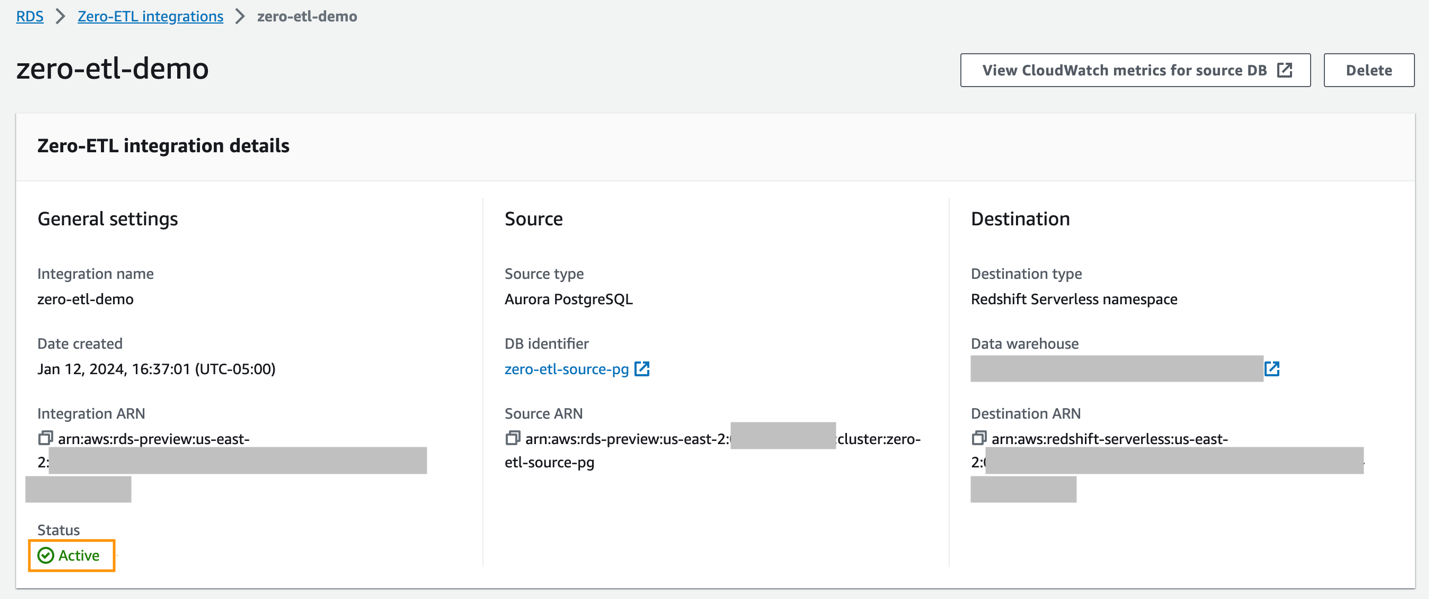
Du kan velge integrasjonen på Amazon RDS-konsollen for å se detaljene og overvåke fremdriften. Det tar omtrent 30 minutter å endre status fra Opprette til Aktiv, avhengig av størrelsen på datasettet som allerede er tilgjengelig i kilden.
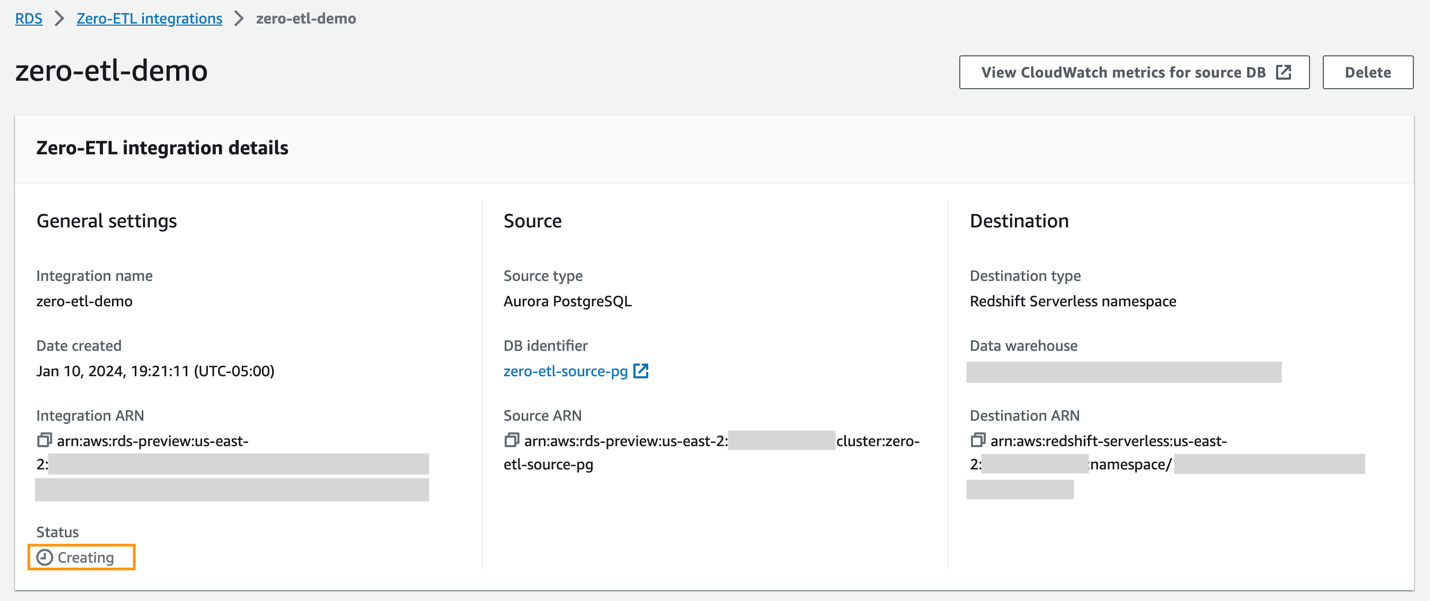
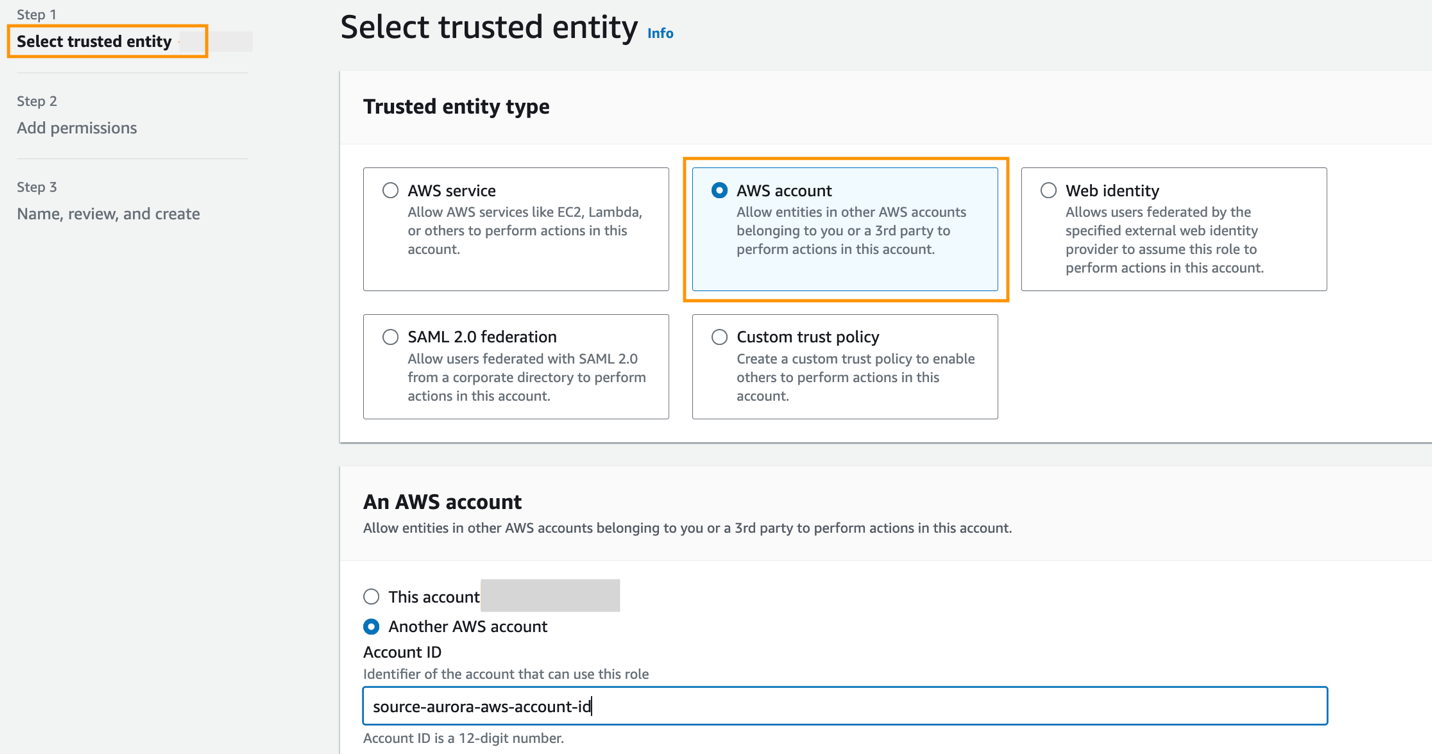
For å spesifisere et mål Redshift-datavarehus som er i en annen AWS-konto, må du opprette en rolle som lar brukere i gjeldende konto få tilgang til ressurser i målkontoen. For mer informasjon, se Gi tilgang til en IAM-bruker i en annen AWS-konto du eier.
Opprett en rolle i målkontoen med følgende tillatelser:
Rollen må ha følgende tillitspolicy, som spesifiserer målkonto-ID. Du kan gjøre dette ved å opprette en rolle med en klarert enhet som en AWS-konto-ID i en annen konto.
Følgende skjermbilde illustrerer å lage dette på IAM-konsollen.
Deretter, mens du oppretter null-ETL-integrasjonen, for Angi en annen konto, velg destinasjonskonto-ID og navnet på rollen du opprettet.
Lag en database fra integrasjonen i Amazon Redshift
For å opprette databasen, fullfør følgende trinn:
- På Redshift Serverless-dashbordet, naviger til
zero-etl-target-rs-nsnavnerom. - Velg Spørr data for å åpne spørringsredigering v2.

- Koble til Redshift Serverless datavarehus ved å velge Opprett forbindelse.
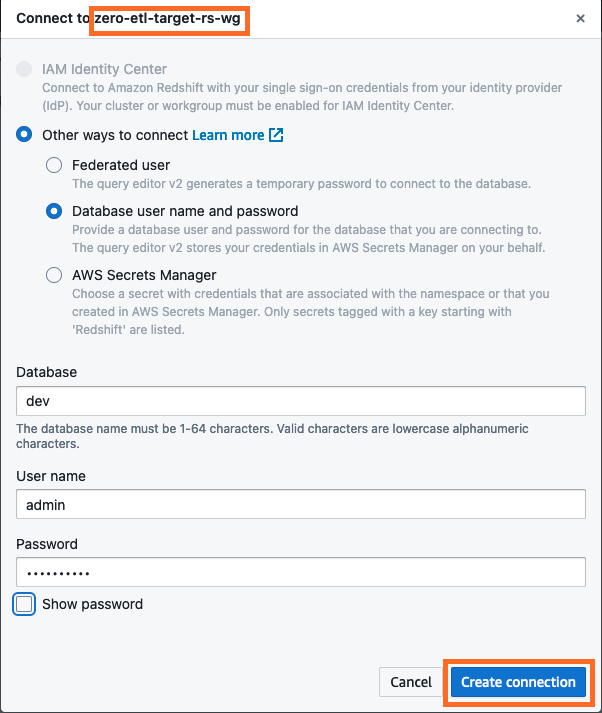
- Få tak i
integration_idfrasvv_integrationsystemtabell: - Bruke
integration_idfra forrige trinn for å opprette en ny database fra integrasjonen. Du må også inkludere en referanse til den navngitte databasen i klyngen du spesifiserte da du opprettet integrasjonen.CREATE DATABASE aurora_pg_zetl FROM INTEGRATION '<result from above>' DATABASE zeroetl_db;
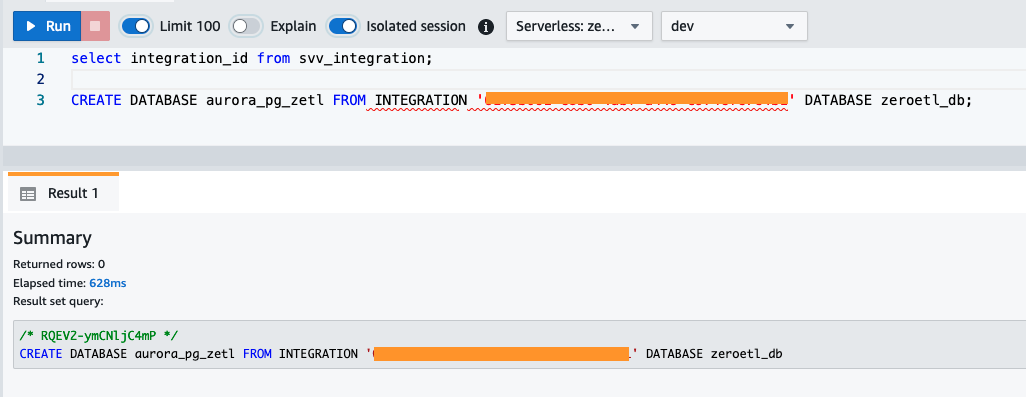
Integrasjonen er nå fullført, og et helt øyeblikksbilde av kilden vil reflektere slik det er i destinasjonen. Pågående endringer vil bli synkronisert i nesten sanntid.
Analyser nær sanntids transaksjonsdata
Nå kan du begynne å analysere nær sanntidsdata fra Amazon Aurora PostgreSQL-kilden til Amazon Redshift-målet:
- Koble til din kilde Aurora PostgreSQL-database. I denne demoen bruker vi psql for å koble til Amazon Aurora PostgreSQL:

- Lag en eksempeltabell med en primærnøkkel. Sørg for at alle tabeller som skal replikeres fra kilde til mål har en primærnøkkel. Tabeller uten primærnøkkel kan ikke replikeres til målet.
- Sett inn dummydata i nasjonstabellen og kontroller om dataene er riktig lastet:

Disse eksempeldataene skal nå replikeres i Amazon Redshift.
Analyser kildedataene i destinasjonen
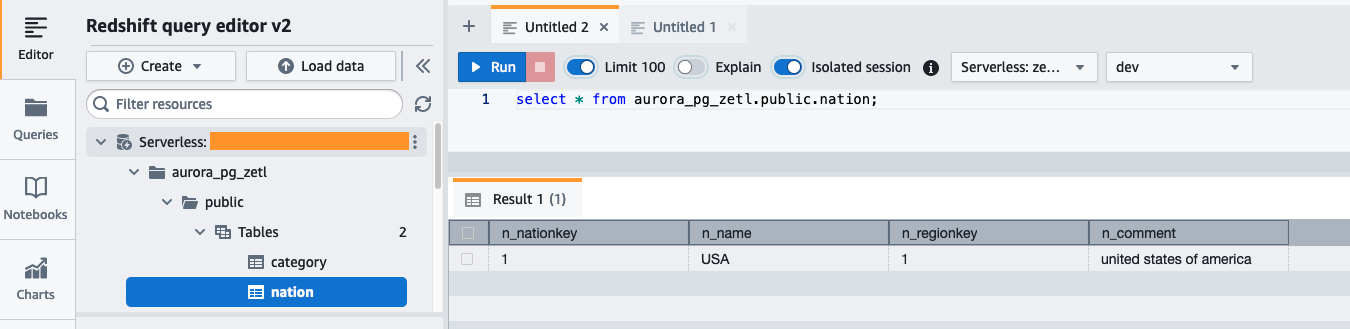
På Redshift Serverless-dashbordet åpner du spørringsredigering v2 og kobler til databasen aurora_pg_zetl du opprettet tidligere.
Kjør følgende spørring for å validere vellykket replikering av kildedataene til Amazon Redshift:
Du kan også bruke følgende spørring for å validere det første øyeblikksbildet eller pågående endringsdatafangst-aktiviteten (CDC):
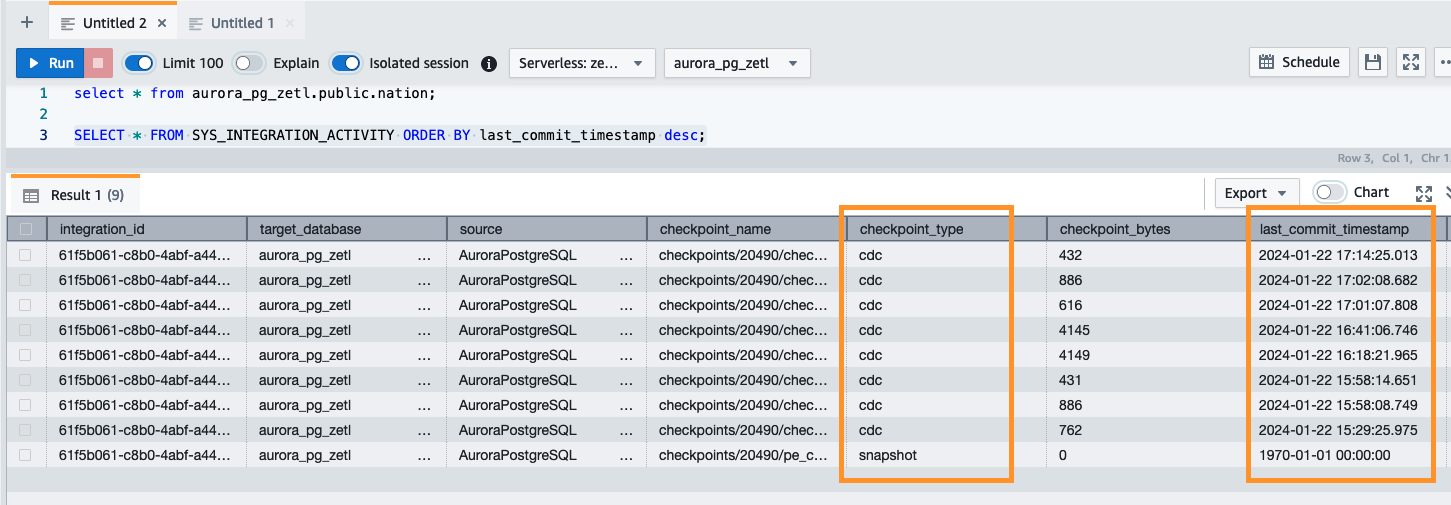
Overvåking
Det er flere alternativer for å få målinger om ytelsen og statusen til Aurora PostgreSQL zero-ETL-integrasjonen med Amazon Redshift.
Hvis du navigerer til Amazon Redshift-konsollen, kan du velge Null-ETL-integrasjoner i navigasjonsruten. Du kan velge null-ETL-integrasjonen du ønsker og vise Amazon CloudWatch målinger knyttet til integrasjonen. Disse beregningene er også direkte tilgjengelige i CloudWatch.
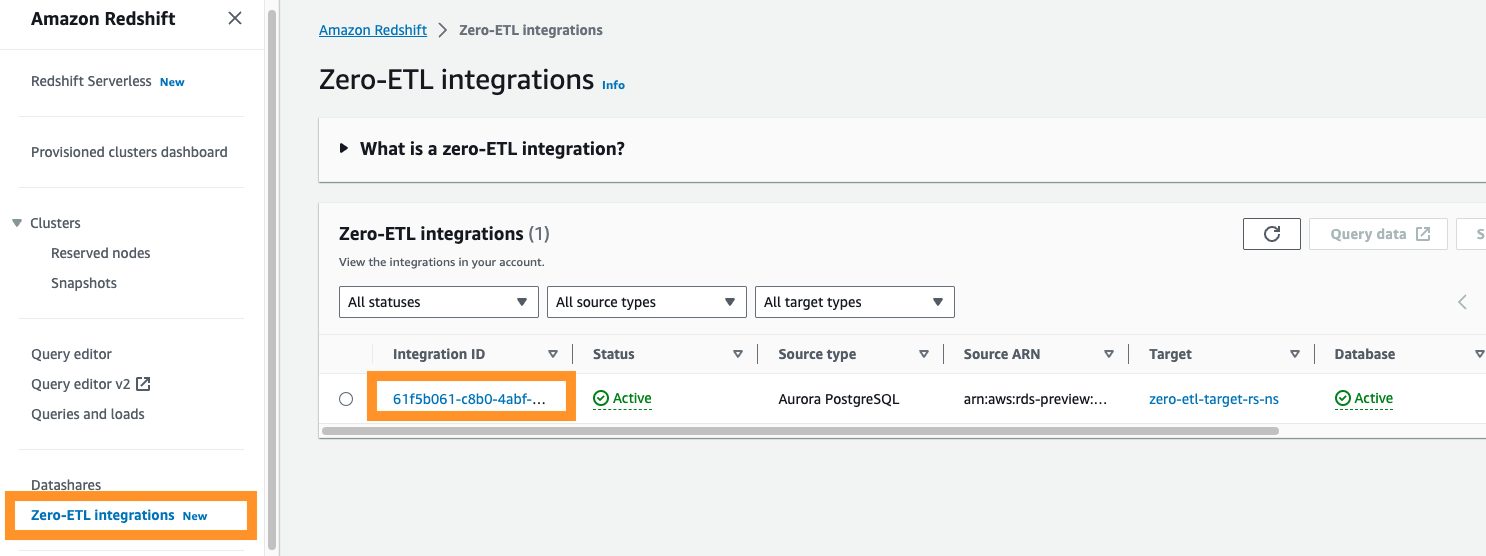
For hver integrasjon er det to faner med informasjon tilgjengelig:
- Integrasjonsberegninger – Viser beregninger som antall tabeller som er vellykket replikert og forsinkelsesdetaljer
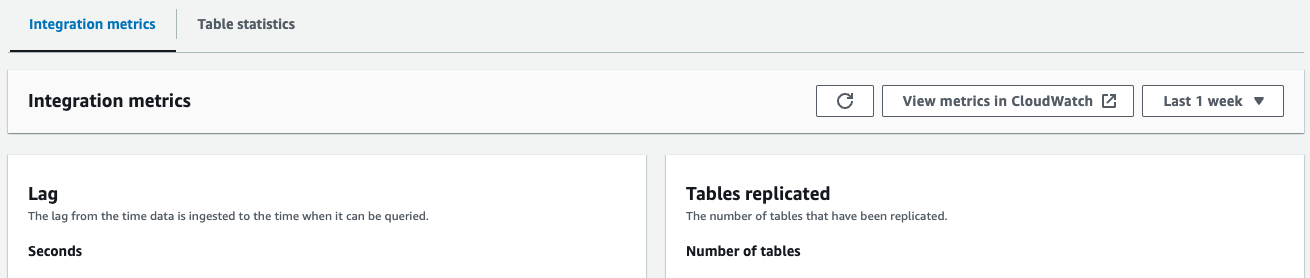
- Tabellstatistikk – Viser detaljer om hver tabell replikert fra Amazon Aurora PostgreSQL til Amazon Redshift
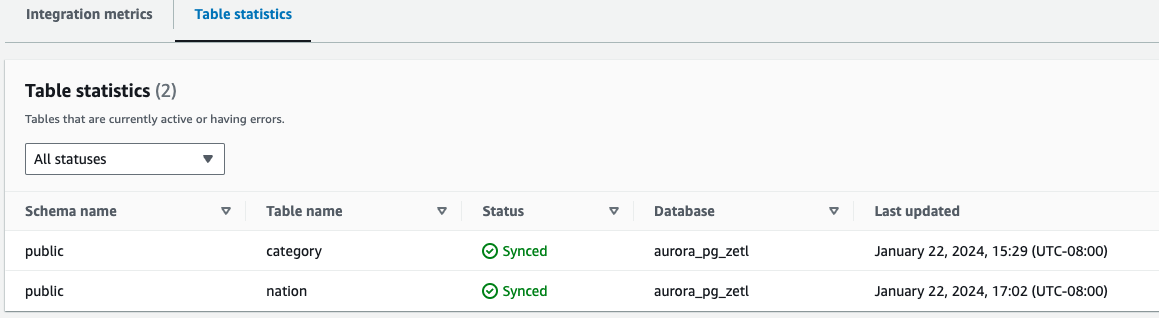
I tillegg til CloudWatch-beregningene kan du spørre etter følgende systemvisninger, som gir informasjon om integrasjonene:
Rydd opp
Når du sletter en null-ETL-integrasjon, slettes ikke transaksjonsdataene dine fra Aurora eller Amazon Redshift, men Aurora sender ikke nye data til Amazon Redshift.
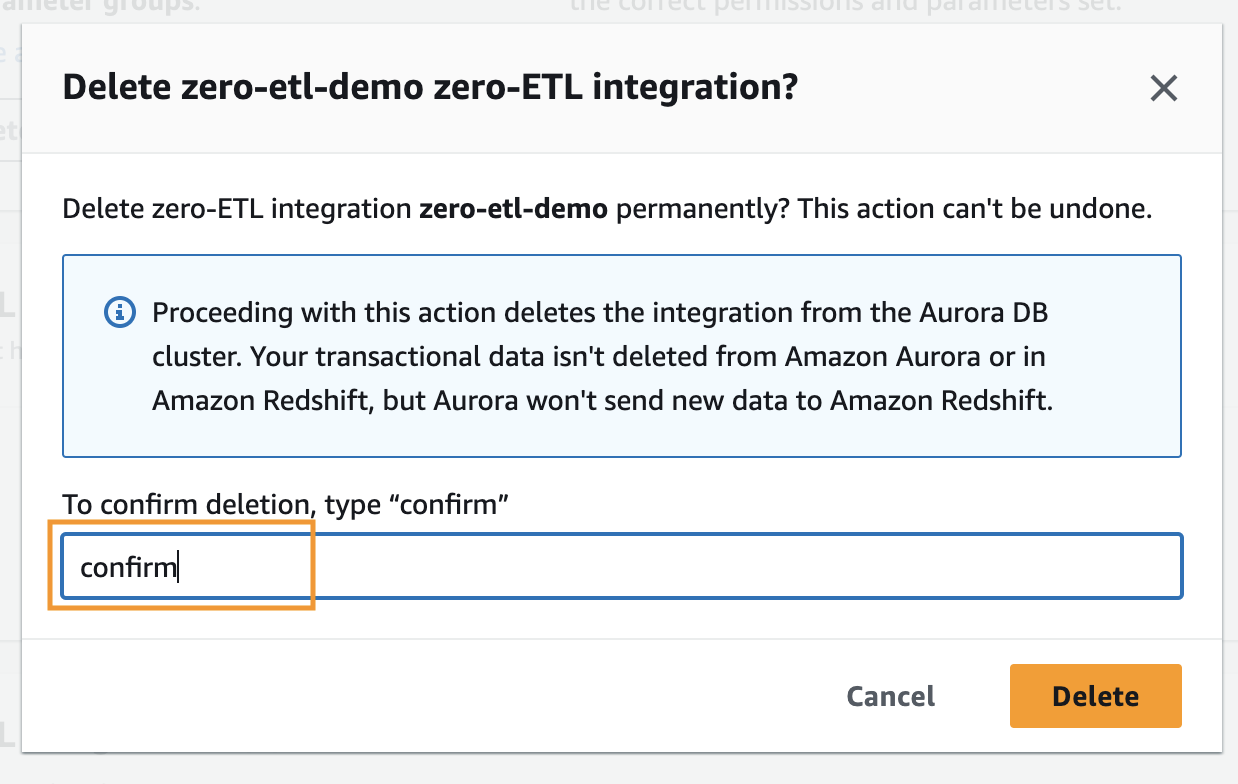
For å slette en null-ETL-integrasjon, fullfør følgende trinn:
- På Amazon RDS-konsollen velger du Null-ETL-integrasjoner i navigasjonsruten.
- Velg null-ETL-integrasjonen du vil slette og velg Delete.

- For å bekrefte slettingen, skriv inn bekreft og velg Delete.
konklusjonen
I dette innlegget forklarte vi hvordan du kan sette opp null-ETL-integrasjonen fra Amazon Aurora PostgreSQL til Amazon Redshift, en funksjon som reduserer innsatsen med å vedlikeholde datapipelines og muliggjør nesten sanntidsanalyse av transaksjons- og driftsdata.
For å lære mer om null-ETL-integrasjon, se Arbeider med Aurora zero-ETL-integrasjoner med Amazon Redshift og Begrensninger.
Om forfatterne
 Raks Khare er en Analytics Specialist Solutions Architect hos AWS basert i Pennsylvania. Han hjelper kunder med å bygge dataanalyseløsninger i stor skala på AWS-plattformen.
Raks Khare er en Analytics Specialist Solutions Architect hos AWS basert i Pennsylvania. Han hjelper kunder med å bygge dataanalyseløsninger i stor skala på AWS-plattformen.
 Juan Luis Polo Garzon er en Associate Specialist Solutions Architect ved AWS, spesialisert i analytiske arbeidsbelastninger. Han har erfaring med å hjelpe kunder med å designe, bygge og modernisere deres skybaserte analyseløsninger. Utenom jobben liker han å reise, utendørs og gå på fotturer, og delta på levende musikkarrangementer.
Juan Luis Polo Garzon er en Associate Specialist Solutions Architect ved AWS, spesialisert i analytiske arbeidsbelastninger. Han har erfaring med å hjelpe kunder med å designe, bygge og modernisere deres skybaserte analyseløsninger. Utenom jobben liker han å reise, utendørs og gå på fotturer, og delta på levende musikkarrangementer.
 Sushmita Barthakur er en Senior Solutions Architect hos Amazon Web Services, og støtter Enterprise-kunder med å bygge arbeidsmengdene deres på AWS. Med en sterk bakgrunn innen Data Analytics og Data Management, har hun lang erfaring med å hjelpe kunder med å bygge og bygge Business Intelligence og Analytics-løsninger, både lokalt og skyen. Sushmita er basert i Tampa, FL og liker å reise, lese og spille tennis.
Sushmita Barthakur er en Senior Solutions Architect hos Amazon Web Services, og støtter Enterprise-kunder med å bygge arbeidsmengdene deres på AWS. Med en sterk bakgrunn innen Data Analytics og Data Management, har hun lang erfaring med å hjelpe kunder med å bygge og bygge Business Intelligence og Analytics-løsninger, både lokalt og skyen. Sushmita er basert i Tampa, FL og liker å reise, lese og spille tennis.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/achieve-near-real-time-operational-analytics-using-amazon-aurora-postgresql-zero-etl-integration-with-amazon-redshift/

