Med Kunnskapsbaser for Amazon Bedrock, kan du trygt koble fundamentmodeller (FM-er) inn Amazonas grunnfjell til bedriftens data for Retrieval Augmented Generation (RAG). Tilgang til tilleggsdata hjelper modellen med å generere mer relevante, kontekstspesifikke og nøyaktige svar uten å omskolere FM-ene.
I dette innlegget diskuterer vi to nye funksjoner i Knowledge Bases for Amazon Berggrunn som er spesifikke for RetrieveAndGenerate API: konfigurere maksimalt antall resultater og lage egendefinerte ledetekster med en kunnskapsbase-promptmal. Du kan nå velge disse som søkealternativer ved siden av søketypen.
Oversikt og fordeler med nye funksjoner
Alternativet for maksimalt antall resultater gir deg kontroll over antall søkeresultater som skal hentes fra vektorlageret og sendes til FM for å generere svaret. Dette lar deg tilpasse mengden bakgrunnsinformasjon som gis for generering, og gir dermed mer kontekst for komplekse spørsmål eller mindre for enklere spørsmål. Den lar deg hente opptil 100 resultater. Dette alternativet bidrar til å forbedre sannsynligheten for relevant kontekst, og forbedrer dermed nøyaktigheten og reduserer hallusinasjonen til den genererte responsen.
Den tilpassede forespørselsmalen for kunnskapsbasen lar deg erstatte standard forespørselsmalen med din egen for å tilpasse forespørselen som sendes til modellen for generering av svar. Dette lar deg tilpasse tonen, utgangsformatet og oppførselen til FM-en når den svarer på en brukers spørsmål. Med dette alternativet kan du finjustere terminologien slik at den passer bedre med din bransje eller domene (som helsevesen eller juridisk). I tillegg kan du legge til egendefinerte instruksjoner og eksempler skreddersydd for dine spesifikke arbeidsflyter.
I de følgende delene forklarer vi hvordan du kan bruke disse funksjonene med enten AWS-administrasjonskonsoll eller SDK.
Forutsetninger
For å følge disse eksemplene må du ha en eksisterende kunnskapsbase. For instruksjoner for å lage en, se Lag en kunnskapsbase.
Konfigurer maksimalt antall resultater ved å bruke konsollen
For å bruke alternativet for maksimalt antall resultater ved å bruke konsollen, fullfør følgende trinn:
- På Amazon Bedrock-konsollen velger du Kunnskapsgrunnlag i venstre navigasjonsrute.
- Velg kunnskapsbasen du opprettet.
- Velg Test kunnskapsbase.
- Velg konfigurasjonsikonet.
- Velg Synkroniser datakilde før du begynner å teste kunnskapsbasen din.

- Under konfigurasjonerFor Søketype, velg en søketype basert på ditt bruksområde.
For dette innlegget bruker vi hybridsøk fordi det kombinerer semantisk og tekstsøk for å gi større nøyaktighet. For å lære mer om hybridsøk, se Kunnskapsbaser for Amazon Bedrock støtter nå hybridsøk.
- Expand Maksimalt antall kildebiter og angi maksimalt antall resultater.

For å demonstrere verdien av den nye funksjonen viser vi eksempler på hvordan du kan øke nøyaktigheten til den genererte responsen. Vi brukte Amazon 10K-dokument for 2023 som kildedata for å lage kunnskapsbasen. Vi bruker følgende spørring for eksperimentering: "I hvilket år økte Amazons årlige inntekter fra $245B til $434B?"
Det riktige svaret for denne spørringen er "Amazons årlige inntekt økte fra $245B i 2019 til $434B i 2022," basert på dokumentene i kunnskapsbasen. Vi brukte Claude v2 som FM for å generere den endelige responsen basert på den kontekstuelle informasjonen hentet fra kunnskapsbasen. Claude 3 Sonnet og Claude 3 Haiku støttes også som generasjonen FM-er.
Vi kjørte en annen spørring for å demonstrere sammenligningen av henting med forskjellige konfigurasjoner. Vi brukte den samme inndataspørringen ("I hvilket år økte Amazons årlige inntekter fra $245B til $434B?") og satte maksimalt antall resultater til 5.
Som vist i følgende skjermbilde, var det genererte svaret "Beklager, jeg kan ikke hjelpe deg med denne forespørselen."

Deretter setter vi maksimale resultater til 12 og stiller det samme spørsmålet. Det genererte svaret er "Amazons årlige inntektsøkning fra $245B i 2019 til $434B i 2022."

Som vist i dette eksemplet er vi i stand til å hente riktig svar basert på antall hentede resultater. Hvis du vil lære mer om kildeattribusjonen som utgjør det endelige resultatet, velg Vis kildedetaljer å validere det genererte svaret basert på kunnskapsbasen.
Tilpass en forespørselsmal for kunnskapsbase ved å bruke konsollen
Du kan også tilpasse standardprompten med din egen ledetekst basert på brukstilfellet. For å gjøre det på konsollen, fullfør følgende trinn:
- Gjenta trinnene i forrige del for å begynne å teste kunnskapsbasen din.
- aktiver Generer svar.

- Velg modellen du ønsker for generering av respons.
Vi bruker Claude v2-modellen som eksempel i dette innlegget. Claude 3 Sonnet og Haiku-modellen er også tilgjengelig for generering.
- Velg Påfør å fortsette.

Etter at du har valgt modell, kalles en ny seksjon Kunnskapsbase-promptmal vises under konfigurasjoner.
- Velg Rediger for å begynne å tilpasse forespørselen.
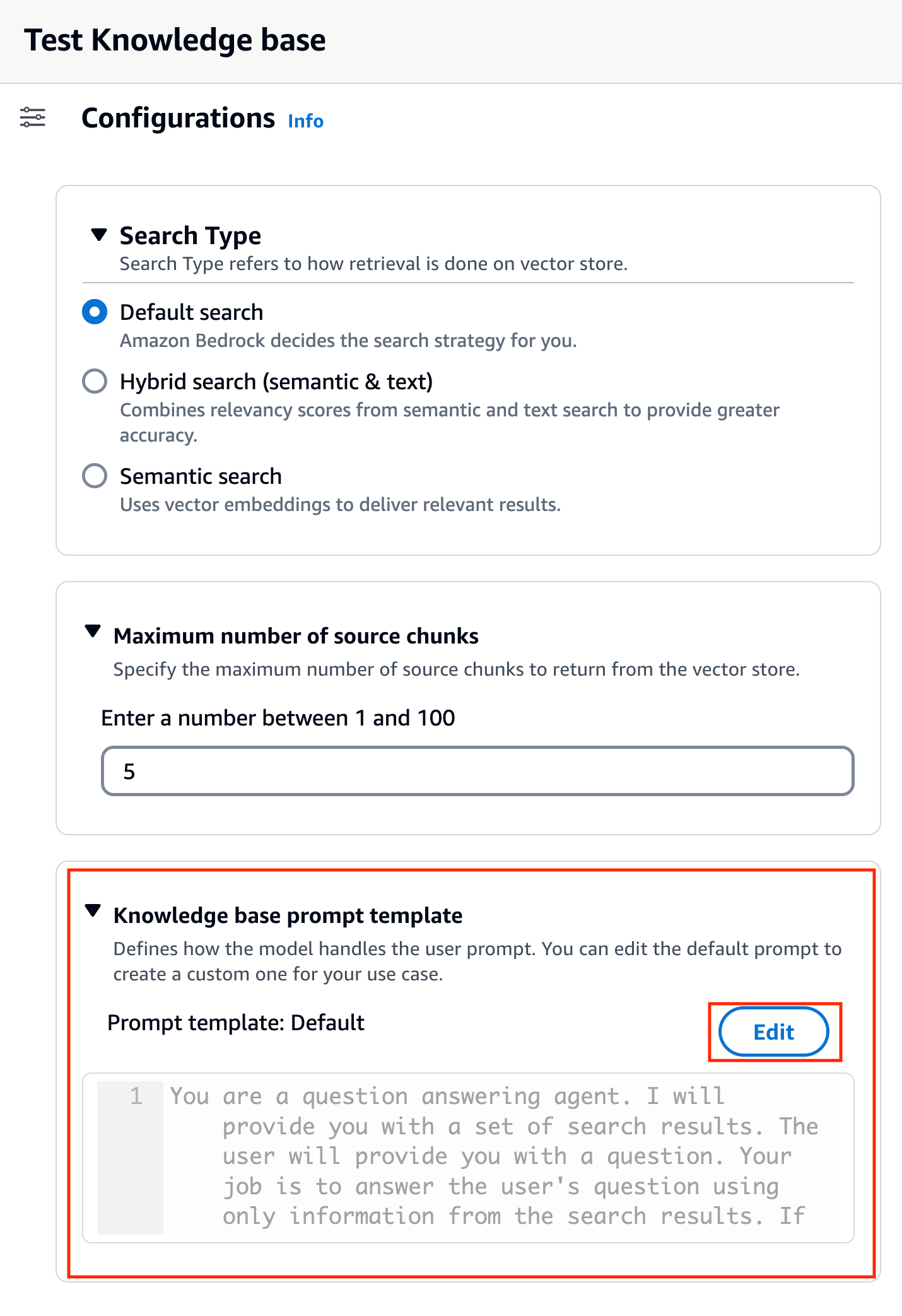
- Juster forespørselsmalen for å tilpasse hvordan du vil bruke de hentede resultatene og generere innhold.
For dette innlegget ga vi noen eksempler for å lage et "Financial Advisor AI-system" ved å bruke Amazons økonomiske rapporter med tilpassede spørsmål. For beste praksis for prompt engineering, se Raske tekniske retningslinjer.
Vi tilpasser nå standard forespørselsmalen på flere forskjellige måter, og observerer svarene.
La oss først prøve en spørring med standard ledetekst. Vi spør «Hva var Amazonas inntekter i 2019 og 2021?» Følgende viser resultatene våre.

Fra utdataene finner vi at det genererer friformresponsen basert på den hentede kunnskapen. Sitatene er også oppført for referanse.
La oss si at vi ønsker å gi ekstra instruksjoner om hvordan du formaterer det genererte svaret, som å standardisere det som JSON. Vi kan legge til disse instruksjonene som et eget trinn etter å ha hentet informasjonen, som en del av ledetekstmalen:
Det endelige svaret har den nødvendige strukturen.

Ved å tilpasse ledeteksten kan du også endre språket for det genererte svaret. I det følgende eksempelet instruerer vi modellen til å gi et svar på spansk.

Etter fjerning $output_format_instructions$ fra standard-ledeteksten fjernes sitatet fra det genererte svaret.
I de følgende delene forklarer vi hvordan du kan bruke disse funksjonene med SDK.
Konfigurer maksimalt antall resultater ved hjelp av SDK
For å endre maksimalt antall resultater med SDK, bruk følgende syntaks. For dette eksemplet er spørringen "I hvilket år økte Amazons årlige inntekter fra $245B til $434B?" Det riktige svaret er "Amazons årlige inntektsøkning fra $245B i 2019 til $434B i 2022."
The 'numberOfResults' alternativ under 'retrievalConfiguration' lar deg velge antall resultater du vil hente. Utgangen til RetrieveAndGenerate API inkluderer generert respons, kildeattribusjon og de hentede tekstbitene.
Følgende er resultatene for forskjellige verdier av 'numberOfResults' parametere. Først setter vi numberOfResults = 5.
Så setter vi numberOfResults = 12.
Tilpass kunnskapsbase-forespørselsmalen ved hjelp av SDK
For å tilpasse forespørselen ved hjelp av SDK, bruker vi følgende spørring med forskjellige forespørselsmaler. For dette eksemplet er spørringen "Hva var Amazonas inntekter i 2019 og 2021?"
Følgende er standard ledetekstmal:
Følgende er den tilpassede ledetekstmalen:
Med standard ledetekstmal får vi følgende svar:
![]()
Hvis du ønsker å gi ytterligere instruksjoner rundt utdataformatet for svargenereringen, som å standardisere svaret i et spesifikt format (som JSON), kan du tilpasse den eksisterende ledeteksten ved å gi mer veiledning. Med vår egendefinerte forespørselsmal får vi følgende svar.

The 'promptTemplate'alternativ i'generationConfiguration' lar deg tilpasse forespørselen for bedre kontroll over svargenerering.
konklusjonen
I dette innlegget introduserte vi to nye funksjoner i Knowledge Bases for Amazon Bedrock: justering av maksimalt antall søkeresultater og tilpasning av standard forespørselsmal for RetrieveAndGenerate API. Vi demonstrerte hvordan du konfigurerer disse funksjonene på konsollen og via SDK for å forbedre ytelsen og nøyaktigheten til den genererte responsen. Å øke de maksimale resultatene gir mer omfattende informasjon, mens tilpasning av ledetekstmalen lar deg finjustere instruksjonene for grunnlagsmodellen for bedre å tilpasses spesifikke brukstilfeller. Disse forbedringene gir større fleksibilitet og kontroll, slik at du kan levere skreddersydde opplevelser for RAG-baserte applikasjoner.
For ytterligere ressurser for å begynne å implementere i AWS-miljøet ditt, se følgende:
Om forfatterne
 Sandeep Singh er Senior Generative AI Data Scientist hos Amazon Web Services, og hjelper bedrifter med å innovere med generativ AI. Han spesialiserer seg på generativ AI, kunstig intelligens, maskinlæring og systemdesign. Han brenner for å utvikle toppmoderne AI/ML-drevne løsninger for å løse komplekse forretningsproblemer for ulike bransjer, optimalisere effektivitet og skalerbarhet.
Sandeep Singh er Senior Generative AI Data Scientist hos Amazon Web Services, og hjelper bedrifter med å innovere med generativ AI. Han spesialiserer seg på generativ AI, kunstig intelligens, maskinlæring og systemdesign. Han brenner for å utvikle toppmoderne AI/ML-drevne løsninger for å løse komplekse forretningsproblemer for ulike bransjer, optimalisere effektivitet og skalerbarhet.
 Suyin Wang er AI/ML Specialist Solutions Architect hos AWS. Hun har en tverrfaglig utdanningsbakgrunn innen maskinlæring, finansiell informasjonstjeneste og økonomi, sammen med mange års erfaring med å bygge datavitenskap og maskinlæringsapplikasjoner som løste forretningsproblemer i den virkelige verden. Hun liker å hjelpe kunder med å identifisere de riktige forretningsspørsmålene og bygge de riktige AI/ML-løsningene. På fritiden elsker hun å synge og lage mat.
Suyin Wang er AI/ML Specialist Solutions Architect hos AWS. Hun har en tverrfaglig utdanningsbakgrunn innen maskinlæring, finansiell informasjonstjeneste og økonomi, sammen med mange års erfaring med å bygge datavitenskap og maskinlæringsapplikasjoner som løste forretningsproblemer i den virkelige verden. Hun liker å hjelpe kunder med å identifisere de riktige forretningsspørsmålene og bygge de riktige AI/ML-løsningene. På fritiden elsker hun å synge og lage mat.
 Sherry Ding er en senior arkitekt for kunstig intelligens (AI) og maskinlæring (ML) spesialistløsninger hos Amazon Web Services (AWS). Hun har lang erfaring innen maskinlæring med doktorgrad i informatikk. Hun jobber hovedsakelig med kunder i offentlig sektor på ulike AI/ML-relaterte forretningsutfordringer, og hjelper dem med å akselerere sin maskinlæringsreise på AWS Cloud. Når hun ikke hjelper kunder, liker hun utendørsaktiviteter.
Sherry Ding er en senior arkitekt for kunstig intelligens (AI) og maskinlæring (ML) spesialistløsninger hos Amazon Web Services (AWS). Hun har lang erfaring innen maskinlæring med doktorgrad i informatikk. Hun jobber hovedsakelig med kunder i offentlig sektor på ulike AI/ML-relaterte forretningsutfordringer, og hjelper dem med å akselerere sin maskinlæringsreise på AWS Cloud. Når hun ikke hjelper kunder, liker hun utendørsaktiviteter.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/knowledge-bases-for-amazon-bedrock-now-supports-custom-prompts-for-the-retrieveandgenerate-api-and-configuration-of-the-maximum-number-of-retrieved-results/

