Kroner gir bryggerier, drikkevaretappere og matprodusenter over hele verden individuelle maskiner og komplette produksjonslinjer. Hver dag går millioner av glassflasker, bokser og PET-beholdere gjennom en Krones-linje. Produksjonslinjer er komplekse systemer med mange mulige feil som kan stoppe linjen og redusere produksjonsutbyttet. Krones ønsker å oppdage feilen så tidlig som mulig (noen ganger også før den skjer) og varsle produksjonslinjeoperatører for å øke påliteligheten og produksjonen. Så hvordan oppdage en feil? Krones utstyrer sine linjer med sensorer for datainnsamling, som deretter kan evalueres opp mot regler. Krones, som linjeprodusent, samt linjeoperatør har mulighet til å lage overvåkingsregler for maskiner. Derfor kan drikkevaretappere og andre operatører definere sin egen feilmargin for linjen. Tidligere brukte Krones et system basert på en tidsseriedatabase. Hovedutfordringene var at dette systemet var vanskelig å feilsøke og også spørringer representerte maskinens nåværende tilstand, men ikke tilstandsovergangene.
Dette innlegget viser hvordan Krones bygde en strømmeløsning for å overvåke linjene deres, basert på Amazon Kinesis og Amazon Managed Service for Apache Flink. Disse fullt administrerte tjenestene reduserer kompleksiteten ved å bygge strømmeapplikasjoner med Apache Flink. Administrert tjeneste for Apache Flink administrerer de underliggende Apache Flink-komponentene som gir holdbar applikasjonstilstand, beregninger, logger og mer, og Kinesis lar deg behandle strømmedata på en kostnadseffektiv måte i alle skalaer. Hvis du vil komme i gang med din egen Apache Flink-applikasjon, sjekk ut GitHub repository for prøver som bruker Java-, Python- eller SQL-API-ene til Flink.
Oversikt over løsning
Krones sin linjeovervåking er en del av Krones butikkgulvveiledning system. Det gir støtte i organisering, prioritering, ledelse og dokumentasjon av alle aktiviteter i selskapet. Den lar dem varsle en operatør hvis maskinen er stoppet eller det kreves materialer, uansett hvor operatøren er i køen. Påviste regler for tilstandsovervåking er allerede innebygd, men kan også brukerdefineres via brukergrensesnittet. For eksempel, hvis et bestemt datapunkt som overvåkes bryter en terskel, kan det være en tekstmelding eller trigger for en vedlikeholdsordre på linjen.
Tilstandsovervåkings- og regelevalueringssystemet er bygget på AWS, ved å bruke AWS-analysetjenester. Følgende diagram illustrerer arkitekturen.
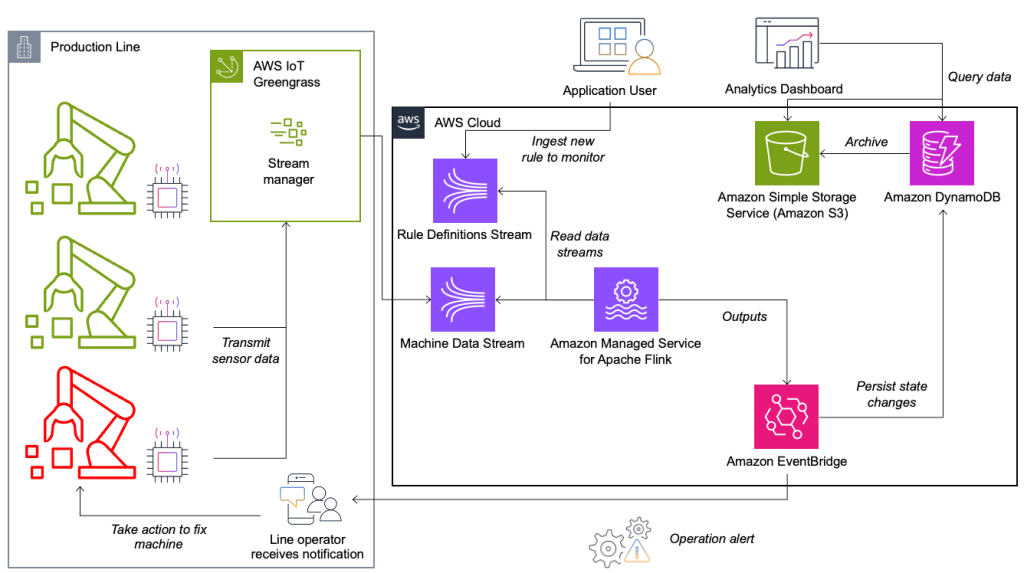
Nesten alle datastrømmeapplikasjoner består av fem lag: datakilde, strøminntak, strømlagring, strømbehandling og en eller flere destinasjoner. I de følgende avsnittene dykker vi dypere ned i hvert lag og hvordan linjeovervåkingsløsningen, bygget av Krones, fungerer i detalj.
Datakilde
Dataene samles inn av en tjeneste som kjører på en kantenhet som leser flere protokoller som Siemens S7 eller OPC/UA. Rådata er forhåndsbehandlet for å lage en enhetlig JSON-struktur, som gjør det enklere å behandle senere i regelmotoren. Et eksempel på nyttelast konvertert til JSON kan se slik ut:
{
"version": 1,
"timestamp": 1234,
"equipmentId": "84068f2f-3f39-4b9c-a995-d2a84d878689",
"tag": "water_temperature",
"value": 13.45,
"quality": "Ok",
"meta": {
"sequenceNumber": 123,
"flags": ["Fst", "Lst", "Wmk", "Syn", "Ats"],
"createdAt": 12345690,
"sourceId": "filling_machine"
}
}Strøminntak
AWS IoT Greengrass er en åpen kildekode Internet of Things (IoT) edge runtime og skytjeneste. Dette lar deg handle på data lokalt og samle og filtrere enhetsdata. AWS IoT Greengrass gir forhåndsbygde komponenter som kan distribueres til kanten. Produksjonslinjeløsningen bruker stream manager-komponenten, som kan behandle data og overføre dem til AWS-destinasjoner som f.eks AWS IoT Analytics, Amazon enkel lagringstjeneste (Amazon S3), og Kinesis. Strømbehandleren bufrer og samler poster, og sender dem deretter til en Kinesis-datastrøm.
Strømlagring
Jobben til strømlagringen er å bufre meldinger på en feiltolerant måte og gjøre den tilgjengelig for forbruk til en eller flere forbrukerapplikasjoner. For å oppnå dette på AWS er de vanligste teknologiene Kinesis og Amazon administrerte strømming for Apache Kafka (Amazon MSK). For lagring av sensordata fra produksjonslinjer velger Krones Kinesis. Kinesis er en serverløs strømmedatatjeneste som fungerer i alle skalaer med lav ventetid. Shards i en Kinesis-datastrøm er en unikt identifisert sekvens av dataposter, der en strøm er sammensatt av ett eller flere shards. Hvert shard har 2 MB/s lesekapasitet og 1 MB/s skrivekapasitet (med maks 1,000 poster/s). For å unngå å nå disse grensene, bør data fordeles mellom shards så jevnt som mulig. Hver post som sendes til Kinesis har en partisjonsnøkkel, som brukes til å gruppere data i et shard. Derfor vil du ha et stort antall partisjonsnøkler for å fordele belastningen jevnt. Strømbehandleren som kjører på AWS IoT Greengrass støtter tilfeldige partisjonsnøkkeltilordninger, noe som betyr at alle poster havner i et tilfeldig skjær og belastningen fordeles jevnt. En ulempe med tilfeldige partisjonsnøkkeltilordninger er at poster ikke lagres i rekkefølge i Kinesis. Vi forklarer hvordan du løser dette i neste avsnitt, hvor vi snakker om vannmerker.
Vannmerker
A vannmerke er en mekanisme som brukes til å spore og måle fremdriften til hendelsestid i en datastrøm. Hendelsestidspunktet er tidsstemplet fra da hendelsen ble opprettet ved kilden. Vannmerket indikerer rettidig fremdrift av strømbehandlingsapplikasjonen, så alle hendelser med et tidligere eller likt tidsstempel anses som behandlet. Denne informasjonen er viktig for Flink for å fremme hendelsestid og utløse relevante beregninger, for eksempel vindusevalueringer. Den tillatte forsinkelsen mellom hendelsestid og vannmerke kan konfigureres for å bestemme hvor lenge man skal vente på sene data før man vurderer et vindu som fullført og fremmer vannmerket.
Krones har systemer over hele kloden, og trengte for å håndtere sene ankomster på grunn av tilkoblingstap eller andre nettverksbegrensninger. De startet med å overvåke sene ankomster og sette standard Flink sen håndtering til den maksimale verdien de så i denne beregningen. De opplevde problemer med tidssynkronisering fra kantenhetene, noe som førte dem til en mer sofistikert måte for vannmerking. De bygde et globalt vannmerke for alle avsendere og brukte den laveste verdien som vannmerke. Tidsstemplene lagres i et HashMap for alle innkommende hendelser. Når vannmerkene sendes ut med jevne mellomrom, brukes den minste verdien av dette HashMap. For å unngå stopp av vannmerker på grunn av manglende data, konfigurerte de en idleTimeOut parameter, som ignorerer tidsstempler som er eldre enn en viss terskel. Dette øker latensen, men gir sterk datakonsistens.
public class BucketWatermarkGenerator implements WatermarkGenerator<DataPointEvent> {
private HashMap <String, WatermarkAndTimestamp> lastTimestamps;
private Long idleTimeOut;
private long maxOutOfOrderness;
}
Stream behandling
Etter at dataene er samlet inn fra sensorer og tatt inn i Kinesis, må de evalueres av en regelmotor. En regel i dette systemet representerer tilstanden til en enkelt metrikk (som temperatur) eller en samling av beregninger. For å tolke en beregning brukes mer enn ett datapunkt, som er en statistisk beregning. I denne delen dykker vi dypere inn i nøkkeltilstanden og kringkastingstilstanden i Apache Flink og hvordan de brukes til å bygge Krones-regelmotoren.
Kontroller strøm- og kringkastingstilstandsmønster
I Apache Flink, stat refererer til systemets evne til å lagre og administrere informasjon vedvarende på tvers av tid og operasjoner, noe som muliggjør behandling av strømmedata med støtte for statistiske beregninger.
De kringkastingstilstandsmønster tillater distribusjon av en stat til alle parallelle forekomster av en operatør. Derfor har alle operatører samme tilstand, og data kan behandles med samme tilstand. Disse skrivebeskyttede dataene kan tas inn ved å bruke en kontrollstrøm. En kontrollstrøm er en vanlig datastrøm, men vanligvis med mye lavere datahastighet. Dette mønsteret lar deg dynamisk oppdatere tilstanden på alle operatører, slik at brukeren kan endre tilstanden og oppførselen til applikasjonen uten behov for en omdistribuering. Mer presist gjøres fordelingen av staten ved bruk av en kontrollstrøm. Ved å legge til en ny post i kontrollstrømmen, mottar alle operatører denne oppdateringen og bruker den nye tilstanden for behandling av nye meldinger.
Dette lar brukere av Krones-applikasjonen ta inn nye regler i Flink-applikasjonen uten å starte den på nytt. Dette unngår nedetid og gir en god brukeropplevelse når endringer skjer i sanntid. En regel dekker et scenario for å oppdage et prosessavvik. Noen ganger er maskindataene ikke så enkle å tolke som de kan se ut ved første øyekast. Hvis en temperatursensor sender høye verdier, kan dette indikere en feil, men også være effekten av en pågående vedlikeholdsprosedyre. Det er viktig å sette beregninger i kontekst og filtrere noen verdier. Dette oppnås ved et konsept kalt gruppering.
Gruppering av beregninger
Grupperingen av data og beregninger lar deg definere relevansen til innkommende data og produsere nøyaktige resultater. La oss gå gjennom eksemplet i den følgende figuren.
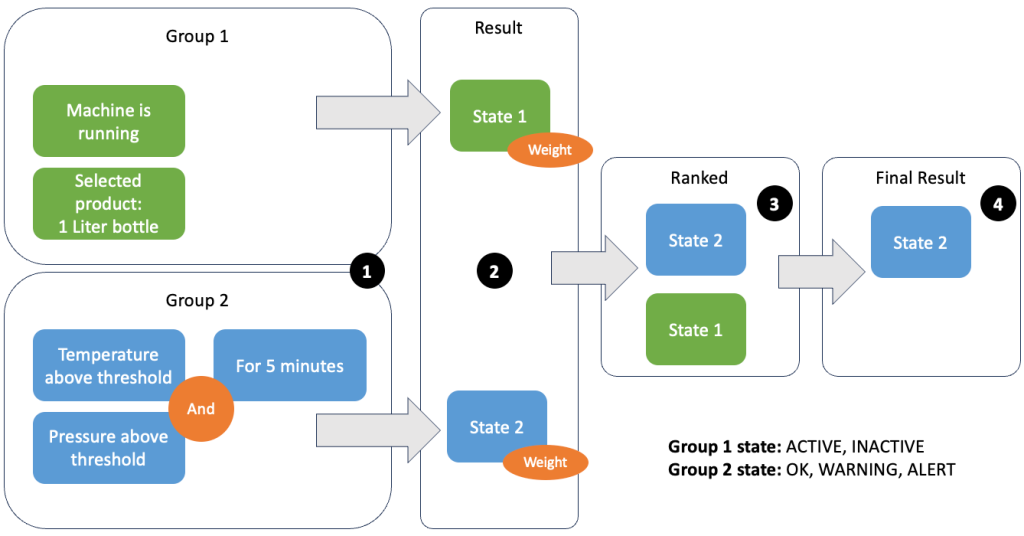
I trinn 1 definerer vi to tilstandsgrupper. Gruppe 1 samler maskinstatus og hvilket produkt som går gjennom linjen. Gruppe 2 bruker verdien til temperatur- og trykksensorene. En tilstandsgruppe kan ha forskjellige tilstander avhengig av verdiene den mottar. I dette eksemplet mottar gruppe 1 data om at maskinen kjører, og én-liters flasken er valgt som produkt; dette gir denne gruppen staten ACTIVE. Gruppe 2 har metrikk for temperatur og trykk; begge beregningene er over terskelverdiene i mer enn 5 minutter. Dette resulterer i at gruppe 2 er i a WARNING stat. Dette betyr at gruppe 1 rapporterer at alt er bra og gruppe 2 ikke. I trinn 2 legges vekter til gruppene. Dette er nødvendig i enkelte situasjoner, fordi grupper kan rapportere motstridende informasjon. I dette scenariet rapporterer gruppe 1 ACTIVE og gruppe 2 rapporter WARNING, så det er ikke klart for systemet hvordan linjens tilstand er. Etter å ha lagt til vektene, kan statene rangeres, som vist i trinn 3. Til slutt blir den høyest rangerte staten valgt som den vinnende, som vist i trinn 4.
Etter at reglene er evaluert og den endelige maskintilstanden er definert, vil resultatene bli behandlet videre. Handlingen som tas avhenger av regelkonfigurasjonen; dette kan være en melding til linjeoperatøren om å fylle på materialer, gjøre noe vedlikehold eller bare en visuell oppdatering på dashbordet. Denne delen av systemet, som evaluerer beregninger og regler og iverksetter handlinger basert på resultatene, omtales som en regel motor.
Skalering av regelmotoren
Ved å la brukere bygge sine egne regler, kan regelmotoren ha et stort antall regler som den må evaluere, og noen regler kan bruke samme sensordata som andre regler. Flink er et distribuert system som skalerer veldig godt horisontalt. For å distribuere en datastrøm til flere oppgaver, kan du bruke keyBy() metode. Dette lar deg partisjonere en datastrøm på en logisk måte og sende deler av dataene til forskjellige oppgavebehandlere. Dette gjøres ofte ved å velge en vilkårlig nøkkel slik at du får en jevnt fordelt belastning. I dette tilfellet la Krones til en ruleId til datapunktet og brukte det som en nøkkel. Ellers behandles datapunkter som trengs av en annen oppgave. Den tastede datastrømmen kan brukes på tvers av alle regler akkurat som en vanlig variabel.
Destinasjoner
Når en regel endrer tilstand, sendes informasjonen til en Kinesis-strøm og deretter via Amazon EventBridge til forbrukerne. En av forbrukerne oppretter et varsel fra hendelsen som overføres til produksjonslinjen og varsler personellet om å handle. For å kunne analysere regeltilstandsendringene, skriver en annen tjeneste dataene til en Amazon DynamoDB tabell for rask tilgang og en TTL er på plass for å laste ned langtidshistorikk til Amazon S3 for videre rapportering.
konklusjonen
I dette innlegget viste vi deg hvordan Krones bygde et produksjonslinjeovervåkingssystem i sanntid på AWS. Managed Service for Apache Flink gjorde det mulig for Krones-teamet å komme raskt i gang ved å fokusere på applikasjonsutvikling i stedet for infrastruktur. Sanntidsfunksjonene til Flink gjorde det mulig for Krones å redusere maskinstans med 10 % og øke effektiviteten med opptil 5 %.
Hvis du vil bygge dine egne strømmeapplikasjoner, sjekk ut de tilgjengelige eksemplene på GitHub repository. Hvis du vil utvide Flink-applikasjonen din med tilpassede kontakter, se Gjør det enklere å bygge koblinger med Apache Flink: Vi introduserer Async Sink. Async Sink er tilgjengelig i Apache Flink versjon 1.15.1 og nyere.
Om forfatterne
 Florian Mair er senior løsningsarkitekt og datastrømmeekspert hos AWS. Han er en teknolog som hjelper kunder i Europa med å lykkes og innovere ved å løse forretningsutfordringer ved å bruke AWS Cloud-tjenester. I tillegg til å jobbe som Solutions Architect, er Florian en lidenskapelig fjellklatrer, og har besteget noen av de høyeste fjellene i Europa.
Florian Mair er senior løsningsarkitekt og datastrømmeekspert hos AWS. Han er en teknolog som hjelper kunder i Europa med å lykkes og innovere ved å løse forretningsutfordringer ved å bruke AWS Cloud-tjenester. I tillegg til å jobbe som Solutions Architect, er Florian en lidenskapelig fjellklatrer, og har besteget noen av de høyeste fjellene i Europa.
 Emil Dietl er en Senior Tech Lead hos Krones som spesialiserer seg på datateknikk, med et nøkkelfelt innen Apache Flink og mikrotjenester. Arbeidet hans involverer ofte utvikling og vedlikehold av virksomhetskritisk programvare. Utenom yrkeslivet setter han stor pris på å tilbringe kvalitetstid med familien.
Emil Dietl er en Senior Tech Lead hos Krones som spesialiserer seg på datateknikk, med et nøkkelfelt innen Apache Flink og mikrotjenester. Arbeidet hans involverer ofte utvikling og vedlikehold av virksomhetskritisk programvare. Utenom yrkeslivet setter han stor pris på å tilbringe kvalitetstid med familien.
 Simon Peyer er løsningsarkitekt hos AWS med base i Sveits. Han er en praktisk gjører og brenner for å koble sammen teknologi og mennesker som bruker AWS Cloud-tjenester. Et spesielt fokus for ham er datastrømming og automatisering. Ved siden av jobben liker Simon familien sin, friluftsliv og fotturer i fjellet.
Simon Peyer er løsningsarkitekt hos AWS med base i Sveits. Han er en praktisk gjører og brenner for å koble sammen teknologi og mennesker som bruker AWS Cloud-tjenester. Et spesielt fokus for ham er datastrømming og automatisering. Ved siden av jobben liker Simon familien sin, friluftsliv og fotturer i fjellet.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/krones-real-time-production-line-monitoring-with-amazon-managed-service-for-apache-flink/

