Trino er en distribuert SQL-spørringsmotor med åpen kildekode designet for interaktive analytiske arbeidsbelastninger. På AWS kan du kjøre Trino på Amazon EMR, hvor du har fleksibiliteten til å kjøre din foretrukne versjon av åpen kildekode Trino på Amazon Elastic Compute Cloud (Amazon EC2)-forekomster som du administrerer, eller på Amazonas Athena for en serverløs opplevelse. Når du bruker Trino på Amazon EMR eller Athena, får du de nyeste open source-samfunnsinnovasjonene sammen med proprietære, AWS-utviklede optimaliseringer.
Fra Amazon EMR 6.8.0 og Athena-motorversjon 2 har AWS utviklet spørringsplaner og motoratferdsoptimaliseringer som forbedrer søkeytelsen på Trino. I dette innlegget sammenligner vi Amazon EMR 6.15.0 med åpen kildekode Trino 426 og viser at TPC-DS-spørringer kjørte opptil 2.7 ganger raskere på Amazon EMR 6.15.0 Trino 426 sammenlignet med åpen kildekode Trino 426. Senere forklarer vi noen av AWS-utviklede ytelsesoptimaliseringer som bidrar til disse resultatene.
Benchmark-oppsett
I vår testing brukte vi 3 TB datasettet lagret i Amazon S3 i komprimert parkettformat og metadata for databaser og tabeller er lagret i AWS Lim Datakatalog. Denne benchmarken bruker umodifisert TPC-DS-dataskjema og tabellrelasjoner. Faktatabeller er partisjonert på datokolonnen og inneholdt 200-2100 partisjoner. Tabell- og kolonnestatistikk var ikke til stede for noen av tabellene. Vi brukte TPC-DS-spørringer fra åpen kildekode Trino Github depot uten modifikasjoner. Benchmark-spørringer ble kjørt sekvensielt på to forskjellige Amazon EMR 6.15.0-klynger: en med Amazon EMR Trino 426 og den andre med åpen kildekode Trino 426. Begge klynger brukte 1 r5.4xlarge-koordinator og 20 r5.4xlarge-arbeiderforekomster.
Resultater observert
Våre benchmarks viser konsekvent bedre ytelse med Trino på Amazon EMR 6.15.0 sammenlignet med åpen kildekode Trino. Den totale spørringskjøringen til Trino på Amazon EMR var 2.7 ganger raskere sammenlignet med åpen kildekode. Følgende graf viser ytelsesforbedringer målt ved den totale spørringens kjøretid (i sekunder) for benchmark-søkene.
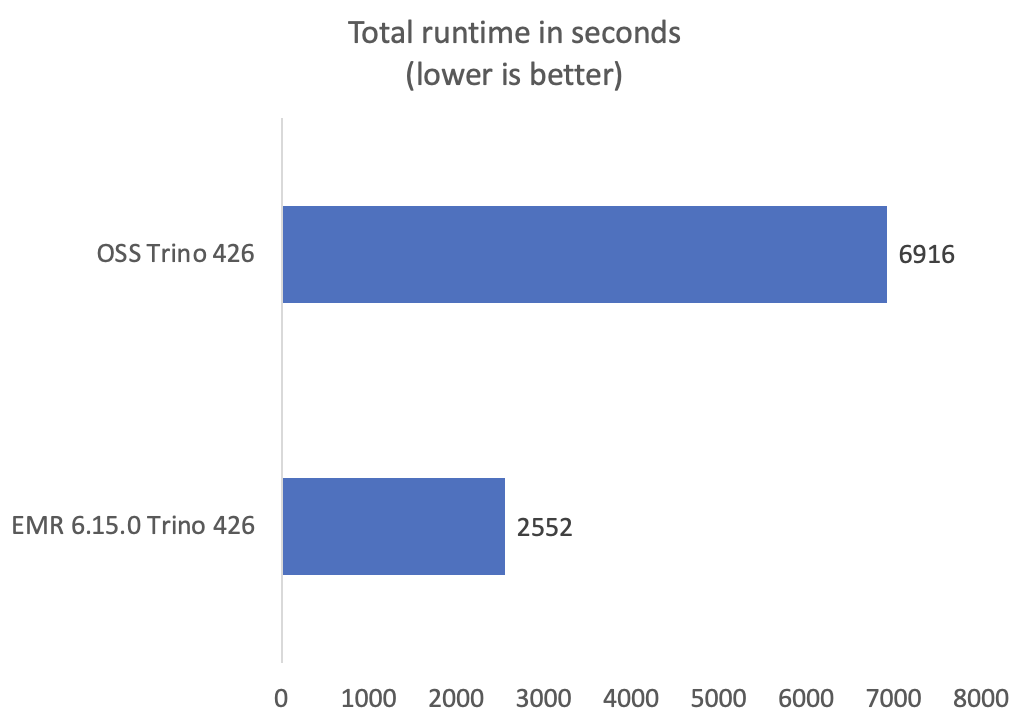
Mange av TPC-DS-spørringene viste ytelsesgevinster over fem ganger raskere sammenlignet med åpen kildekode Trino. Noen søk viste enda bedre ytelse, som søk 72 som ble forbedret med 160 ganger. Følgende graf viser de 10 beste TPC-DS-søkene med den største forbedringen i kjøretid. For en kortfattet fremstilling og for å unngå skjevheter i ytelsesforbedringer i grafen, har vi ekskludert q72.

Ytelsesforbedringer
Nå som vi forstår ytelsesgevinstene med Trino på Amazon EMR, la oss gå dypere inn i noen av nøkkelinnovasjonene utviklet av AWS engineering som bidrar til disse forbedringene.
Å velge en bedre sammenføyningsrekkefølge og sammenføyningstype er avgjørende for bedre søkeytelse fordi det kan påvirke hvor mye data som leses fra en bestemt tabell, hvor mye data som overføres til mellomstadiene gjennom nettverket, og hvor mye minne som trengs for å bygge opp en hash-tabell for å lette en sammenføyning. Beslutninger om å slå sammen rekkefølge og sammenføyning er vanligvis en funksjon som utføres av kostnadsbaserte optimerere, som bruker statistikk for å forbedre spørringsplaner ved å bestemme hvordan tabeller og underspørringer skal slås sammen.
Tabellstatistikk er imidlertid ofte ikke tilgjengelig, utdatert eller for dyr å samle inn på store tabeller. Når statistikk ikke er tilgjengelig, bruker Amazon EMR og Athena S3-filmetadata for å optimalisere spørringsplaner. S3-filmetadata brukes til å utlede små underspørringer og tabeller i spørringen mens sammenføyningsrekkefølgen eller sammenføyningstypen bestemmes. Tenk for eksempel på følgende spørring:
Den syntaktiske sammenføyningsrekkefølgen er store_sales tiltrer store_returns tiltrer call_center. Med Amazon EMR sammenføyningstype og optimaliseringsregler for valg av ordre, bestemmes optimal sammenføyningsrekkefølge selv om disse tabellene ikke har statistikk. For det foregående spørringen if call_center regnes som en liten tabell etter å ha estimert den omtrentlige størrelsen gjennom S3-filmetadata, vil EMRs sammenføyningsoptimaliseringsregler bli med store_sales med call_center først og konverter sammenføyningen til en kringkastingssammenføyning, øke hastigheten på spørringen og redusere minneforbruket. Omorganisering av sammenføyning minimerer mellomresultatstørrelsen, noe som bidrar til å redusere den totale spørringens kjøretid ytterligere.
Med Amazon EMR 6.10.0 og nyere er S3-filmetadatabaserte sammenføyningsoptimaliseringer slått på som standard. Hvis du bruker Amazon EMR 6.8.0 eller 6.9.0, kan du slå på disse optimaliseringene ved å angi øktegenskapene fra Trino-klienter eller legge til følgende egenskaper til trino-config-klassifiseringen når du oppretter klyngen din. Referere til Konfigurer applikasjoner for detaljer om hvordan du overstyrer standardkonfigurasjonene for en applikasjon.
Konfigurasjon for valg av sammenføyningstype:
Konfigurasjon for å bli med på nytt:
konklusjonen
Med Amazon EMR 6.8.0 og nyere kan du kjøre spørringer på Trino betydelig raskere enn åpen kildekode Trino. Som vist i dette blogginnlegget, viste vår TPC-DS-benchmark en 2.7 ganger forbedring i total spørringstid med Trino på Amazon EMR 6.15.0. Optimaliseringene diskutert i dette innlegget, og mange andre, er også tilgjengelige når du kjører Trino-spørringer på Athena der lignende ytelsesforbedringer observeres. For å lære mer, se Kjør spørringer 3 ganger raskere med opptil 70 % kostnadsbesparelser på den nyeste Amazon Athena-motoren.
I vårt oppdrag om å innovere på vegne av kunder, lanserer Amazon EMR og Athena ofte ytelses- og pålitelighetsforbedringer på sine nyeste versjoner. Undersøk Amazon EMR og Amazonas Athena utgivelsessider for å lære om nye funksjoner og forbedringer.
Om forfatterne
 Bhargavi Sagi er en programvareutviklingsingeniør på Amazon Athena. Hun begynte i AWS i 2020 og har jobbet med forskjellige områder av Amazon EMR og Athena motor V3, inkludert motoroppgradering, motorpålitelighet og motorytelse.
Bhargavi Sagi er en programvareutviklingsingeniør på Amazon Athena. Hun begynte i AWS i 2020 og har jobbet med forskjellige områder av Amazon EMR og Athena motor V3, inkludert motoroppgradering, motorpålitelighet og motorytelse.
 Sushil Kumar Shivashankar er ingeniørsjef for EMR Trino og Athena Query Engine-teamet. Han har fokusert på analyseområdet for store data siden 2014.
Sushil Kumar Shivashankar er ingeniørsjef for EMR Trino og Athena Query Engine-teamet. Han har fokusert på analyseområdet for store data siden 2014.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/run-trino-queries-2-7-times-faster-with-amazon-emr-6-15-0/

