
Bilde laget av forfatter med Midjourney
MetaGPT er et multi-agent rammeverk for å tildele roller til ulike agenter som fører til dannelsen av samarbeidende enheter som er i stand til å jobbe sammen for å utføre komplekse instruksjoner. MetaGPT fakturerer seg selv som et "programvareselskap som multi-agent system", og gir deg en ide om tiltenkt bruk av disse samarbeidsenhetene. MetaGPT kan brukes som en frittstående app fra kommandolinjen, og som et bibliotek i dine egne Python-skript, noe som gir mulighet for fleksibiliteten og kontrollen man ønsker i et slikt rammeverk.
Prosjektet startet i april 2023, ved å utnytte ChatGPT, og har i skrivende stund nesten 40K stjerner på GitHub. GitHub-repoen beskriver seg selv som følger:
MetaGPT tar et enlinjekrav som input og sender ut brukerhistorier / konkurranseanalyse / krav / datastrukturer / APIer / dokumenter, etc.
Internt inkluderer MetaGPT produktledere / arkitekter / prosjektledere / ingeniører. Det gir hele prosessen til et programvareselskap sammen med nøye orkestrerte SOP-er.
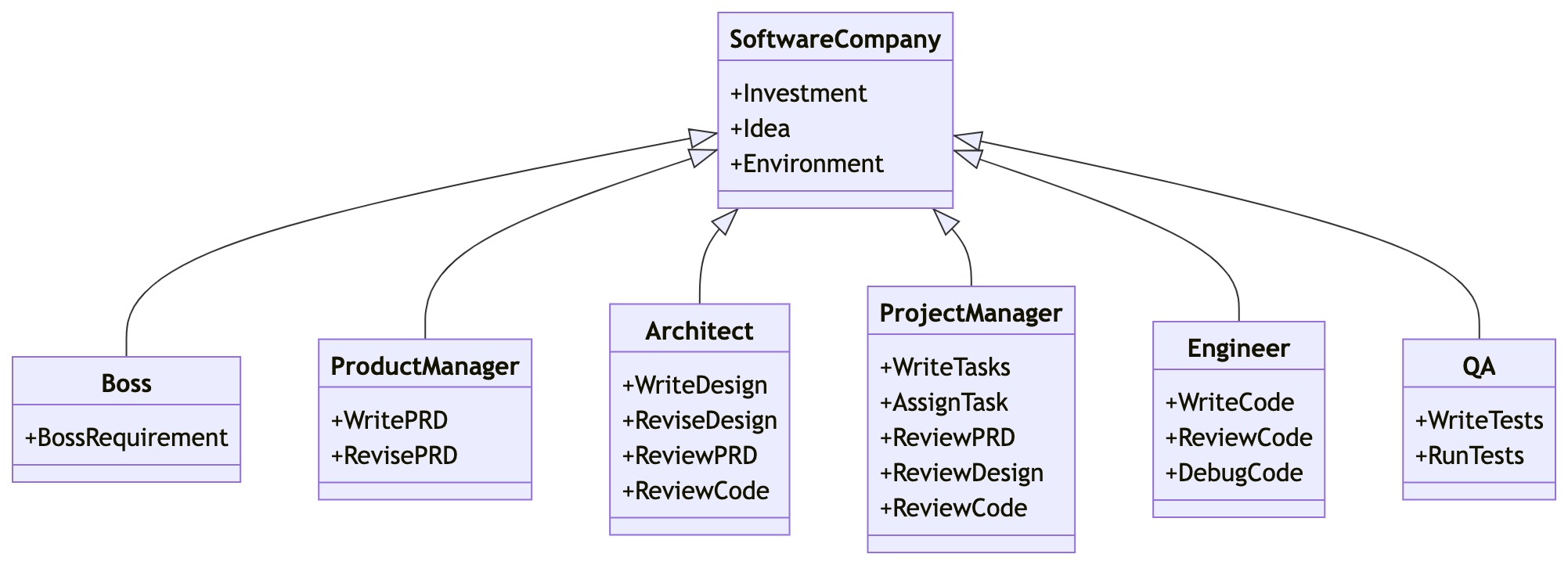
MetaGPTs Software Company Multi-Agent Schematic (gradvis implementering) (fra MetaGPTs GitHub)
MetaGPT kan brukes til kodegenerering, prototyping, prosjektplanlegging og mer. Det har blitt anerkjent som en enestående prestasjon med åpen kildekode, og er kontinuerlig en trendende GitHub-repo.
Det er MetaGPT. La oss nå diskutere Datatolk, Dyp visdomsin siste MetaGPT forbedring, og prestasjon i seg selv.
Full video for å introdusere MetaGPT Data Interpreter
Viser hvordan man kan håndtere prognoseutfordringer for strømbelastning gjennom dynamisk planlegging, verktøyutnyttelse, forbedret resonnement og erfaringsbasert verifisering.
Repo: https://t.co/xWGS0UF9oW
Saker: https://t.co/GhNH54Ahhi... pic.twitter.com/Xc5aam1TXz— MetaGPT (@MetaGPT_) Mars 19, 2024
Data Interpreter er en annen medlemsagent i MetaGPT-rammeverket, en agent dedikert til å vurdere og løse datarelaterte oppgaver. Fra avisen:
I denne studien introduserer vi Data Interpreter, en løsning designet for å løse med kode som legger vekt på tre sentrale teknikker for å øke problemløsning i datavitenskap: 1) dynamisk planlegging med hierarkiske grafstrukturer for sanntidsdatatilpasning; 2) verktøyintegrasjon dynamisk for å forbedre kodeferdigheten under utførelse, og berike den nødvendige ekspertisen; 3) identifisering av logisk inkonsistens i tilbakemeldinger, og effektivitetsforbedring gjennom erfaringsregistrering. […] Sammenlignet med åpen kildekode-baselinjer, viste den overlegen ytelse, og viste betydelige forbedringer i maskinlæringsoppgaver, og økte fra 0.86 til 0.95. I tillegg viste den en 26 % økning i MATH-datasettet og en bemerkelsesverdig 112 % forbedring i åpne oppgaver.
Disse funnene er absolutt imponerende. Og det er ingen grunn til å ta dem for pålydende, siden de har publisert disse resultatene. Deep Wisdom har også gjort tilgjengelig en mengde eksempler for å vise hvordan deres Data Interpreter-agent kan brukes i forbindelse med det eksisterende MetaGPT-rammeverket.
Dette eksemplet her viser hvordan den kan brukes til NVIDIA-aksjetrendanalyse. For å se hvordan en MetaGPT Data Interpreter-forespørsel ser ut, vil jeg duplisere den nedenfor:
Få NVIDIA Corporation (NVDA) aksjekursdata fra Yahoo Finance, med fokus på historiske sluttkurser fra de siste 5 årene. Sammendragsstatistikk (gjennomsnitt, median, standardavvik osv.) for å forstå den sentrale tendensen og spredningen til sluttkurser. Analyser dataene for merkbare trender, mønstre eller anomalier over tid, potensielt ved å bruke rullende gjennomsnitt eller prosentvise endringer. Lag et plott for å visualisere all dataanalysen. Reserver 20 % av datasettet for validering. Tren en prediktiv modell på treningssettet. Rapporter modellens valideringsnøyaktighet, og visualiser resultatet av prediksjonsresultatet. Lukk
Du kan sjekke ut eksempelnotisboken (lenket ovenfor) for å følge MetaGPTs prosess og se resultatene. Spoilervarsel: Deep Wisdom deler dem ikke fordi de ikke er imponerende 🙂
Lese hele papiret for all info du kan be om. Du kan finne ut mer om installasjon og bruk på prosjektets GitHub repo. Jeg kan bekrefte av erfaring at MetaGPT er et verdig prosjekt å sjekke ut, og med tillegg av Data Interpreter-agenten er dette enda mer sant enn det var før.
Matthew Mayo (@mattmayo13) har en mastergrad i informatikk og en graduate diplom i data mining. Som sjefredaktør for KDnuggets har Matthew som mål å gjøre komplekse datavitenskapelige konsepter tilgjengelige. Hans profesjonelle interesser inkluderer naturlig språkbehandling, maskinlæringsalgoritmer og å utforske nye AI. Han er drevet av et oppdrag om å demokratisere kunnskap i datavitenskapsmiljøet. Matthew har kodet siden han var 6 år gammel.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.kdnuggets.com/metagpt-data-interpreter-open-source-llm-based-data-solutions?utm_source=rss&utm_medium=rss&utm_campaign=introducing-metagpts-data-interpreter-sota-open-source-llm-based-data-solutions

