De siste årene har det vært en økende vekt på pristransparens i helsesektoren. Under Regel for åpenhet i dekning (TCR)., sykehus og betalere til å publisere sine prisdata i et maskinlesbart format. Med dette trekket kan pasienter sammenligne priser mellom ulike sykehus og ta informerte helsebeslutninger. For mer informasjon, se Leverer forbrukervennlig åpenhet om helsetjenester i dekning på AWS.
Dataene i de maskinlesbare filene kan gi verdifull innsikt for å forstå de sanne kostnadene ved helsetjenester og sammenligne priser og kvalitet på tvers av sykehus. Tilgjengeligheten av maskinlesbare filer åpner for nye muligheter for dataanalyse, og lar organisasjoner analysere store mengder prisdata. Ved å bruke maskinlæring (ML) og datavisualiseringsverktøy kan disse datasettene transformeres til handlingskraftig innsikt som kan informere beslutningstaking.
I dette innlegget forklarer vi hvordan helseorganisasjoner kan bruke AWS-tjenester til å innta, analysere og generere innsikt fra pristransparensdataene opprettet av sykehus. Vi bruker prøvedata fra tre ulike sykehus, analyserer dataene og skaper komparative trender og innsikter fra dataene.
Løsningsoversikt
Som en del av Sentre for Medicare og Medicaid Services (CMS) mandat har alle sykehus nå sin maskinlesbare fil som inneholder prisdataene. Når sykehusene genererer disse dataene, kan de bruke organisasjonsdataene sine eller innta data fra andre sykehus for å utlede analyser og konkurransemessige sammenligninger. Denne sammenligningen kan hjelpe sykehus med å gjøre følgende:
- Utled en prisgrunnlinje for alle medisinske tjenester og utfør gapanalyse
- Analyser pristrender og identifiser tjenester der konkurrenter ikke deltar
- Evaluer og identifiser tjenestene der kostnadsforskjellen er over en bestemt terskel
Størrelsen på de maskinlesbare filene fra sykehus er mindre enn de som genereres av betalerne. Dette skyldes kompleksiteten til JSON-strukturen, kontraktene og risikoevalueringsprosessen på betalersiden. På grunn av denne lave kompleksiteten bruker løsningen AWS-serverløse tjenester for å innta dataene, transformere dem og gjøre dem tilgjengelige for analyser. Analysen av de maskinlesbare filene fra betalere krever avanserte beregningsevner på grunn av kompleksiteten og sammenhengen i JSON-filen.
Forutsetninger
Som en forutsetning, evaluer sykehusene som prisanalysen skal utføres for og identifiser de maskinlesbare filene for analyse. Amazon enkel lagringstjeneste (Amazon S3) er en objektlagringstjeneste som tilbyr bransjeledende skalerbarhet, datatilgjengelighet, sikkerhet og ytelse. Lag separate mapper for hvert sykehus inne i S3-bøtta.
Arkitekturoversikt
Arkitekturen bruker AWS serverløs teknologi for implementeringen. Den serverløse arkitekturen har automatisk skalering, høy tilgjengelighet og en pay-as-you-go-faktureringsmodell for å øke smidigheten og optimalisere kostnadene. Arkitekturtilnærmingen er delt inn i et datainntakslag, et dataanalyselag og et datavisualiseringslag.
Arkitekturen inneholder tre uavhengige stadier:
- Filinntak – Sykehusene forhandler kontrakten og prisene med betalerne en gang i året med periodiske revisjoner på kvartals- eller månedsbasis. Datainntaksprosessen kopierer de maskinlesbare filene fra sykehusene, validerer dataene og holder de validerte filene tilgjengelige for analyse.
- Dataanalyse – I dette stadiet transformeres filene ved hjelp av AWS Lim og lagret i AWS Glue Data Catalog. AWS Glue er en serverløs dataintegrasjonstjeneste som gjør det enklere å oppdage, forberede, flytte og integrere data fra flere kilder for analyse, ML og applikasjonsutvikling. Da kan du bruke Amazonas Athena V3 for å spørre tabellene i datakatalogen.
- Datavisualisering - Amazon QuickSight er en skydrevet forretningsanalysetjeneste som gjør det enkelt å bygge visualiseringer, utføre ad hoc-analyser og raskt få forretningsinnsikt fra prisdataene. Dette stadiet bruker QuickSight til å visuelt analysere dataene i den maskinlesbare filen ved hjelp av Athena-spørringer.
Filinntak
Filinntaksprosessen fungerer som definert i følgende figur. Arkitekturen bruker AWS Lambda, en serverløs, hendelsesdrevet databehandlingstjeneste som lar deg kjøre kode uten å klargjøre eller administrere servere.
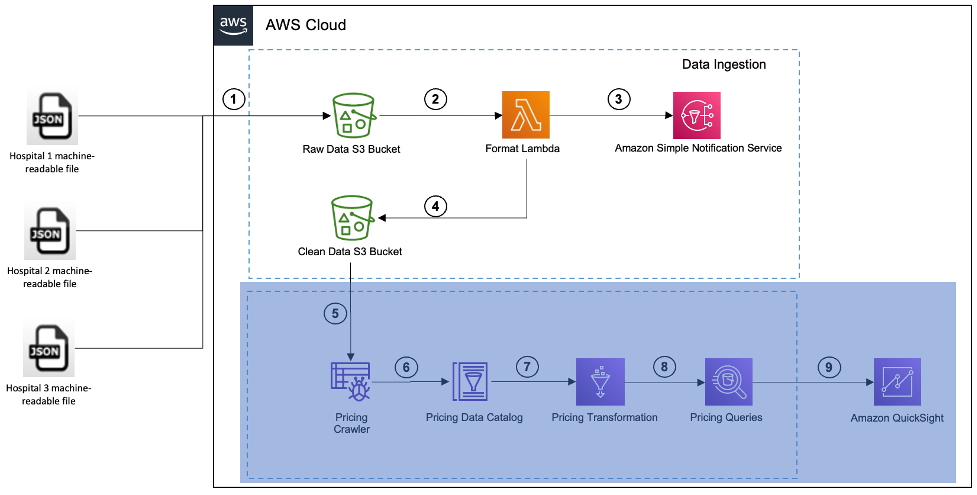
Følgende flyt definerer prosessen for å innta og analysere dataene:
- Kopier de maskinlesbare filene fra sykehusene inn i den respektive rådata S3-bøtten.
- Filopplastingen til S3-bøtten utløser en S3-hendelse, som påkaller en format Lambda-funksjon.
- Lambda-funksjonen utløser et varsel når den identifiserer problemer i filen.
- Lambda-funksjonen inntar filen, transformerer dataene og lagrer den rene filen i en ny rene data S3-bøtte.
Organisasjoner kan lage nye Lambda-funksjoner avhengig av forskjellen i filformatene.
Dataanalyse
Filinntaket og dataanalyseprosessene er uavhengige av hverandre. Mens filinntaket skjer på en planlagt eller periodisk basis, skjer dataanalysen regelmessig basert på forretningsdriftens behov. Arkitekturen for dataanalysen er vist i følgende figur.
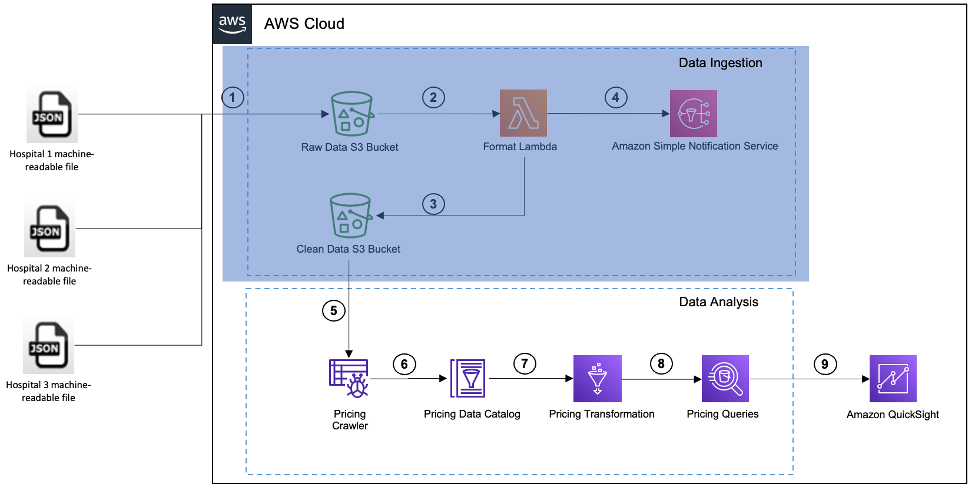
Dette stadiet bruker en AWS Glue-crawler, AWS Glue Data Catalog og Athena v3 for å analysere dataene fra de maskinlesbare filene.
- Et AWS-lim crawler skanner de rene dataene i S3-bøtten og oppretter eller oppdaterer tabellene i AWS Lim Data Catalog. Søkeroboten kan kjøre på forespørsel eller etter en tidsplan, og kan gjennomsøke flere maskinlesbare filer i en enkelt kjøring.
- Datakatalogen inneholder nå referanser til maskinlesbare data. Datakatalogen inneholder tabelldefinisjonen, som inneholder metadata om dataene i den maskinlesbare filen. Tabellene skrives til en database, som fungerer som en beholder.
- Bruk datakatalogen og transformer sykehuspristransparensdataene.
- Når dataene er tilgjengelige i datakatalogen, kan du utvikle analysespørringen ved hjelp av Athena. Athena er en serverløs, interaktiv analysetjeneste som gir en forenklet, fleksibel måte å analysere petabyte med data ved hjelp av SQL-spørringer.
- Enhver feil under prosessen vil bli fanget opp i Amazon CloudWatch logger, som kan brukes til feilsøking og analyse. Datakatalogen må bare oppdateres når det er en endring i den maskinlesbare filstrukturen eller en ny maskinlesbar fil lastes opp til den rene S3-bøtten. Når robotsøkeprogrammet kjører med jevne mellomrom, identifiserer det automatisk endringene og oppdaterer datakatalogen.
Datavisualisering
Når dataanalysen er fullført og spørringer er utviklet ved hjelp av Athena, kan vi visuelt analysere resultatene og få innsikt ved hjelp av QuickSight. Som vist i følgende figur, når datainntaket og dataanalysen er fullført, bygges spørringene ved hjelp av Athena.
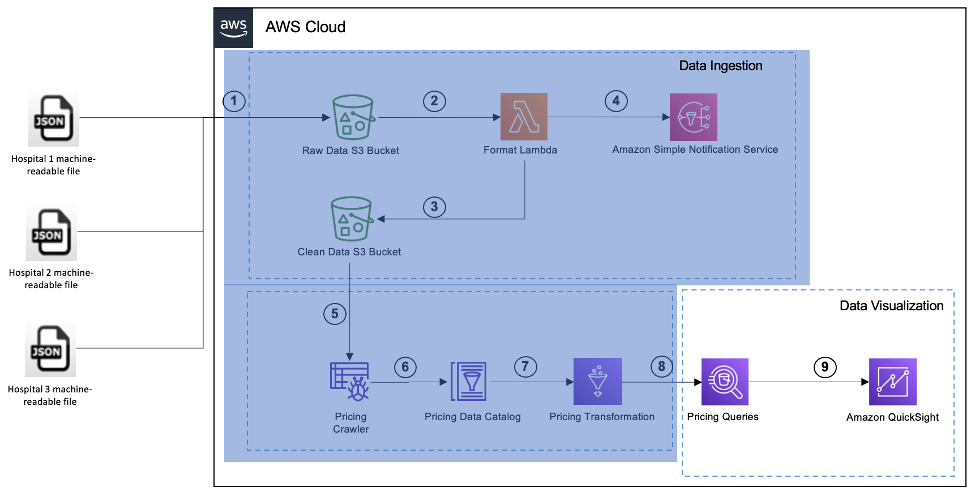
På dette stadiet bruker vi QuickSight til å lage datasett ved å bruke Athena-spørringene, bygge visualiseringer og distribuere dashboards for visuell analyse og innsikt.
Lag et QuickSight-datasett
Fullfør følgende trinn for å lage et QuickSight-datasett:
- Velg på QuickSight-konsollen Administrer data.
- På datasett side, velg Nytt datasett.
- på Lag et datasett siden, velg tilkoblingsprofilikonet for den eksisterende Athena-datakilden du vil bruke.
- Velg Lag datasett.
- På Velg ditt bord side, velg Bruk tilpasset SQL og skriv inn Athena-søket.
Etter at datasettet er opprettet, kan du legge til visualiseringer og analysere dataene fra den maskinlesbare filen. Med QuickSight-dashbordet kan organisasjoner enkelt utføre prissammenligninger på tvers av forskjellige sykehus, identifisere høykosttjenester og finne andre prisavvikere. I tillegg kan du bruke ML i QuickSight for å få ML-drevet innsikt, oppdage prisanomalier og lage prognoser basert på historiske filer.
Følgende figur viser et illustrativt QuickSight-dashbord med innsikt som sammenligner de maskinlesbare filene fra tre forskjellige sykehus. Med disse bildene sammenligner du prisdataene på tvers av sykehus, lager prisreferanser, bestemmer kostnadseffektive sykehus og identifiserer muligheter for konkurransefortrinn.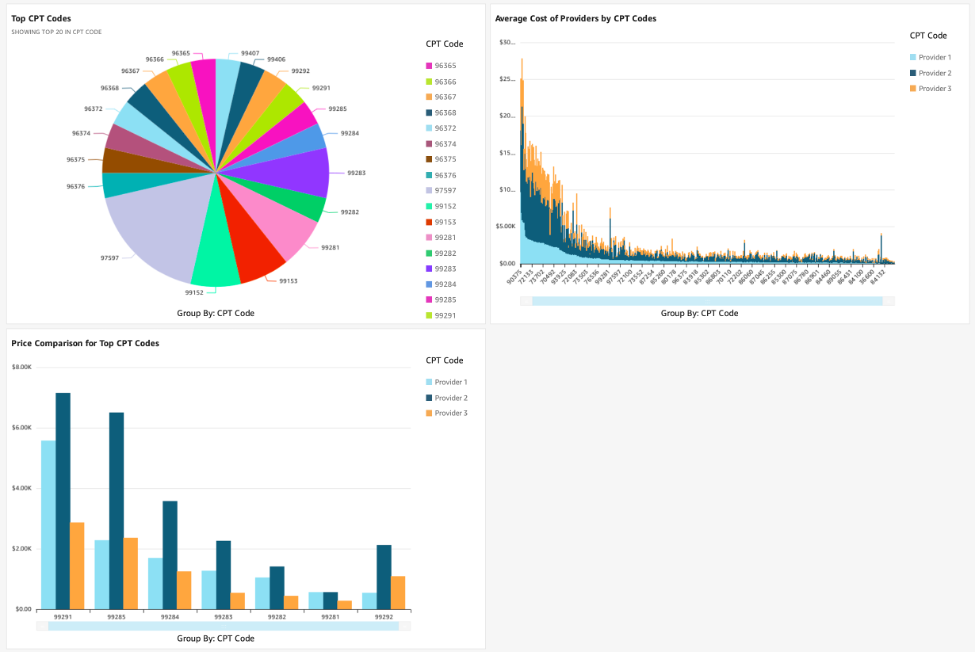
Ytelses-, drifts- og kostnadshensyn
Løsningen anbefaler QuickSight Enterprise for visualisering og innsikt. For QuickSight-dashboards kan Athena-spørringsresultatene lagres i SPICE-databasen for bedre ytelse.
Tilnærmingen bruker Athena V3, som tilbyr ytelsesforbedringer, pålitelighetsforbedringer og nyere funksjoner. Bruker Athena søkeresultat gjenbruk funksjon muliggjør hurtigbufring og gjenbruk av spørringsresultater. Når flere identiske spørringer kjøres med gjenbruksalternativet for søkeresultater, kjøres gjentatte spørringer opptil fem ganger raskere, noe som gir deg økt produktivitet for interaktiv dataanalyse. Fordi du ikke skanner dataene, får du forbedret ytelse til en lavere kostnad.
Kostnad
Sykehus oppretter de maskinlesbare filene på månedlig basis. Denne tilnærmingen bruker en serverløs arkitektur som holder kostnadene lave og tar unna utfordringen med vedlikeholdskostnader. Analysen kan begynne med de maskinlesbare filene for noen få sykehus, og de kan legge til nye sykehus etter hvert som de skaleres. Følgende eksempel hjelper deg med å forstå kostnadene for forskjellige sykehus basert på datastørrelsen:
- A typisk sykehus med 100 GB lagringsplass/måned, spørring av 20 GB data med 2 forfattere og 5 lesere, koster rundt $2,500/år
AWS tilbyr deg en betal-etter-du-gå-tilnærming for priser for de aller fleste av våre skytjenester. Med AWS betaler du kun for de individuelle tjenestene du trenger, så lenge du bruker dem, og uten å kreve langsiktige kontrakter eller komplisert lisensiering.

konklusjonen
Dette innlegget illustrerte hvordan man samler inn og analyserer sykehusskapte pristransparensdata og genererer innsikt ved hjelp av AWS-tjenester. Denne typen analyse og visualiseringene gir rammeverket for å analysere de maskinlesbare filene. Sykehus, betalere, meglere, underwriters og andre interessenter i helsevesenet kan bruke denne arkitekturen til å analysere og hente innsikt fra prisdata publisert av sykehus etter eget valg. Våre AWS-team kan hjelpe deg med å identifisere den riktige strategien ved å tilby tankelederskap og foreskrivende teknisk støtte for analyse av pristransparens.
Kontakt AWS-kontoteamet ditt for mer hjelp med design og for å utforske private priser. Hvis du ikke har kontakt med AWS ennå, vær så snill å nå ut å bli koblet til en AWS-representant.
Om forfatterne
![]() Gokhul Srinivasan er en Senior Partner Solutions Architect som leder AWS Healthcare and Life Sciences (HCLS) Global Startup Partners. Gokhul har over 19 års helseerfaring med å hjelpe organisasjoner med digital transformasjon, modernisering av plattformer og levere forretningsresultater.
Gokhul Srinivasan er en Senior Partner Solutions Architect som leder AWS Healthcare and Life Sciences (HCLS) Global Startup Partners. Gokhul har over 19 års helseerfaring med å hjelpe organisasjoner med digital transformasjon, modernisering av plattformer og levere forretningsresultater.
![]() Laks Sundararajan er en erfaren Enterprise Architect som hjelper bedrifter med å tilbakestille, transformere og modernisere IT-, digital-, sky-, data- og innsiktsstrategiene sine. En velprøvd leder med betydelig ekspertise rundt Generativ AI, Digital, Cloud og Data/Analytics Transformation, Laks er en senior løsningsarkitekt med Healthcare and Life Sciences (HCLS).
Laks Sundararajan er en erfaren Enterprise Architect som hjelper bedrifter med å tilbakestille, transformere og modernisere IT-, digital-, sky-, data- og innsiktsstrategiene sine. En velprøvd leder med betydelig ekspertise rundt Generativ AI, Digital, Cloud og Data/Analytics Transformation, Laks er en senior løsningsarkitekt med Healthcare and Life Sciences (HCLS).
 Anil Chinnam er en løsningsarkitekt i Digital Native Business Segment hos Amazon Web Services(AWS). Han liker å jobbe med kunder for å forstå deres utfordringer og løse dem ved å lage innovative løsninger ved å bruke AWS-tjenester. Utenom jobben liker Anil å være far, svømme og reise.
Anil Chinnam er en løsningsarkitekt i Digital Native Business Segment hos Amazon Web Services(AWS). Han liker å jobbe med kunder for å forstå deres utfordringer og løse dem ved å lage innovative løsninger ved å bruke AWS-tjenester. Utenom jobben liker Anil å være far, svømme og reise.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/how-healthcare-organizations-can-analyze-and-create-insights-using-price-transparency-data/

