Introduksjon
Feltet kunstig intelligens har sett bemerkelsesverdige fremskritt de siste årene, spesielt når det gjelder store språkmodeller. LLM-er kan generere menneskelignende tekst, oppsummere dokumenter og skrive programvarekode. Mistral-7B er en av de nyere store språkmodellene som støtter engelsk tekst- og kodegenereringsevne, og den kan brukes til ulike oppgaver som f.eks. tekstoppsummering, klassifisering, tekstfullføring og kodefullføring.

Det som skiller Mistral-7B-Instruct er dens evne til å levere fantastisk ytelse til tross for at den har færre parametere, noe som gjør den til en høyytende og kostnadseffektiv løsning. Modellen ble nylig populær etter at referanseresultater viste at den ikke bare overgår alle 7B-modeller på MT-Bench, men også konkurrerer gunstig med 13B chat-modeller. I denne bloggen vil vi utforske funksjonene og egenskapene til Mistral 7B, inkludert brukstilfeller, ytelse og en praktisk veiledning for finjustering av modellen.
Læringsmål
- Forstå hvordan store språkmodeller og Mistral 7B fungerer
- Arkitektur av Mistral 7B og benchmarks
- Bruk tilfeller av Mistral 7B og hvordan den fungerer
- Dypdykk i kode for slutninger og finjustering
Denne artikkelen ble publisert som en del av Data Science Blogathon.
Innholdsfortegnelse
Hva er store språkmodeller?
Store språkmodeller' arkitektur er dannet med transformatorer, som bruker oppmerksomhetsmekanismer for å fange langdistanseavhengigheter i data, der flere lag med transformatorblokker inneholder multi-head selvoppmerksomhet og feed-forward nevrale nettverk. Disse modellene er forhåndstrent på tekstdata, og lærer å forutsi neste ord i en sekvens, og fanger dermed mønstrene i språk. Førtreningsvektene kan finjusteres på spesifikke oppgaver. Vi vil spesifikt se på arkitekturen til Mistral 7B LLM, og hva som gjør den skiller seg ut.
Mistral 7B arkitektur
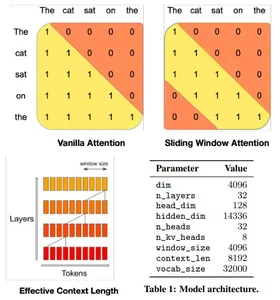
Mistral 7B modelltransformatorarkitekturen balanserer effektivt høy ytelse med minnebruk, ved å bruke oppmerksomhetsmekanismer og cachingstrategier for å utkonkurrere større modeller i hastighet og kvalitet. Den bruker 4096-vindus Sliding Window Attention (SWA), som maksimerer oppmerksomheten over lengre sekvenser ved å la hvert token delta i et undersett av forløper-tokens, og optimalisere oppmerksomheten over lengre sekvenser.
Et gitt skjult lag kan få tilgang til tokens fra inputlag i avstander bestemt av vindusstørrelsen og lagdybden. Modellen integrerer modifikasjoner til Flash Attention og xFormers, og dobler hastigheten i forhold til tradisjonelle oppmerksomhetsmekanismer. I tillegg opprettholder en Rolling Buffer Cache-mekanisme en fast hurtigbufferstørrelse for effektiv minnebruk.
Mistral 7B i Google Colab
La oss dykke dypt ned i koden og se på løpende slutninger med Mistral 7B-modellen i Google Colab. Vi vil bruke gratisversjonen med en enkelt T4 GPU og laste modellen fra Klemende ansikt.
1. Installer og importer ctransformers-biblioteket i Colab.
#intsall ctransformers
pip install ctransformers[cuda] #import
from ctransformers import AutoModelForCausalLM2. Initialiser modellobjektet fra Hugging Face og still inn de nødvendige parameterne. Vi vil bruke en annen versjon av modellen siden den originale modellen fra Mistral AI kan ha problemer med å laste hele modellen inn i minnet på Google Colab.
#load the model from huggingface with 50 gpu layers
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Mistral-7B-Instruct-v0.1-GGUF", model_file="mistral-7b-instruct-v0.1.Q4_K_M.gguf", model_type = "mistral", gpu_layers = 50)3. Definer en funksjon for å skrive ut resultatene vertikalt i Google Colab. Dette trinnet kan hoppes over eller endres hvis det kjøres i et annet miljø.
#function to print the model output in colab in a readable manner
def colab_print(text, max_width = 120): words = text.split() line = "" for word in words: if len(line) + len(word) + 1 > max_width: print(line) line = "" line += word + " " print (line)4. Generer tekst ved hjelp av modellen og se resultatene. Endre parameterne for å endre kvaliteten på den genererte teksten.
#generate text
colab_print(llm('''Give me a well-written paragraph in 5 sentences about a Senior Data Scientist (name - Suvojit) who writes blogs on LLMs on Analytics Vidhya. He studied Masters in AIML in BITS Pilani and works at AZ Company, with a total of 4 years of experience. Start the sentence with - Suvojit is a''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modellrespons: Suvojit er en senior dataforsker som har jobbet i 4 år i AZ-selskapet som en del av teamet deres med fokus på design, implementering og forbedring av prediktive modeller for forbrukeratferd i kundens merkevarer og forretningslinjer ved å bruke teknikker for maskinlæring med begrenset minne. Han skriver om LLM-er på Analytics Vidhya som hjelper ham med å holde seg oppdatert med de siste trendene innen datavitenskap. Han har en mastergrad i AIML fra BITS Pilani, hvor han studerte maskinlæringsalgoritmer og deres applikasjoner. Suvojit er lidenskapelig opptatt av å bruke sin kunnskap om datavitenskap for å hjelpe bedrifter med å ta bedre beslutninger og forbedre ytelsen.
Bruk saker
La oss se på noen av brukstilfellene til Mistral 7B mer detaljert.
Oversettelse
Mistral 7B støtter flere språk for oversettelse. La oss se på engelsk til fransk og spansk oversettelser og sjekke nøyaktigheten.
#translate English to French
colab_print(llm('''Translate this text from English to French: "Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modellrespons: Oversettelsen vil være: "Suvojit est un scientifique des données sénior qui écrit des blogues sur Analytics Vidhya."
#tranlsate English to Spanish
colab_print(llm('''Translate this text from English to Spanish: "Suvojit is a Senior Data Scientist who writes blogs on Analytics Vidhya."''', max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modellrespons: Oversettelsen vil være: "Suvojit es un Senior Data Científico que escribe blogs en Analytics Vidhya."
samandrag
Bruk Mistral 7B til å oppsummere dokumenter til en kortere versjon ved å bruke passende oppsummeringsinstruksjoner.
#Define the prompt with instructions
prompt = '''[INST] You are a helpful code assistant. Your task is to summarize text into exactly two short sentences: Transformers have revolutionized the field of large language models with their ability to capture long-range dependencies and intricate patterns in text. Originating from the paper "Attention Is All You Need" by Vaswani et al. in 2017, transformers introduced the self-attention mechanism, which weighs input tokens differently based on their relevance to a given token. This mechanism enables transformers to process
information more flexibly than traditional RNNs or LSTMs. Consequently, models like GPT, BERT, and their subsequent iterations have been built on the transformer architecture, leading to breakthroughs in numerous natural language processing tasks. Their parallel processing capabilities further make them conducive to training on vast amounts of data. However, as these models grow in size, concerns about their environmental impact and computational demands also emerge. Despite these challenges, the transformative power of transformers in language models remains undeniable. Just summarize the text in exactly 2 short sentences without explanations:
[/INST]''' #Summarize
colab_print(llm(prompt, max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modellrespons: Transformatorer har revolusjonert store språkmodeller ved å fange opp avhengigheter og intrikate mønstre, introdusert en selvoppmerksomhetsmekanisme som gjør at de behandler informasjon fleksibelt, og påfølgende implementeringer inkluderer gjennombrudd som GPT og BERT. Men ettersom disse modellene vokser i størrelse, oppstår bekymringer om deres miljøpåvirkning og beregningsmessige krav, til tross for disse utfordringene forblir de unektelig transformative i språkmodellering.
Egendefinerte instruksjoner
Vi kan bruke [INST]-taggen til å endre brukerinndata for å få et bestemt svar fra modellen. For eksempel kan vi generere en JSON basert på tekstbeskrivelse.
prompt = '''[INST] You are a helpful code assistant. Your task is to generate a valid JSON object based on the given information: My name is Suvojit Hore, working in company AB and my address is AZ Street NY. Just generate the JSON object without explanations:
[/INST] ''' colab_print(llm(prompt, max_new_tokens = 2048, temperature = 0.9, top_k = 55, top_p = 0.93, repetition_penalty = 1.2))Modellrespons: “`json { “name”: “Suvojit Hore”, “company”: “AB”, “address”: “AZ Street NY” } “`
Finjustering av Mistral 7B
La oss se på hvordan vi kan finjustere modellen ved å bruke en enkelt GPU på Google Colab. Vi vil bruke et datasett som konverterer beskrivelser på få ord om bilder til detaljert og svært beskrivende tekst. Disse resultatene kan brukes i Midjourney for å generere det spesifikke bildet. Målet er å trene LLM til å fungere som en rask ingeniør for bildegenerering.
Sett opp miljøet og importer de nødvendige bibliotekene i Google Colab:
# Install the necessary libraries
!pip install pandas autotrain-advanced -q
!autotrain setup --update-torch
!pip install -q peft accelerate bitsandbytes safetensors #import the necesary libraries
import pandas as pd
import torch
from peft import PeftModel
from transformers import AutoModelForCausalLM, AutoTokenizer
import transformers
from huggingface_hub import notebook_loginLogg på Hugging Face fra en nettleser og kopier tilgangstokenet. Bruk dette tokenet til å logge på Hugging Face i notatboken.
notebook_login()
Last opp datasettet til Colab-øktlagring. Vi vil bruke Midjourney-datasettet.
df = pd.read_csv("prompt_engineering.csv")
df.head(5)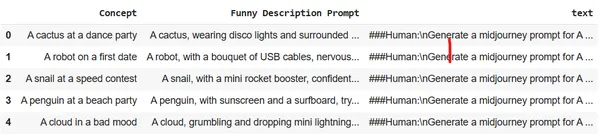
Tren modellen ved hjelp av Autotrain med passende parametere. Endre kommandoen nedenfor for å kjøre den for din egen Huggin Face-repo og brukertilgangstoken.
!autotrain llm --train --project_name mistral-7b-sh-finetuned --model username/Mistral-7B-Instruct-v0.1-sharded --token hf_yiguyfTFtufTFYUTUfuytfuys --data_path . --use_peft --use_int4 --learning_rate 2e-4 --train_batch_size 12 --num_train_epochs 3 --trainer sft --target_modules q_proj,v_proj --push_to_hub --repo_id username/mistral-7b-sh-finetunedLa oss nå bruke den finjusterte modellen til å kjøre inferensmotoren og generere noen detaljerte beskrivelser av bildene.
#adapter and model
adapters_name = "suvz47/mistral-7b-sh-finetuned"
model_name = "bn22/Mistral-7B-Instruct-v0.1-sharded" device = "cuda" #set the config
bnb_config = transformers.BitsAndBytesConfig( load_in_4bit=True, bnb_4bit_use_double_quant=True, bnb_4bit_quant_type="nf4", bnb_4bit_compute_dtype=torch.bfloat16
) #initialize the model
model = AutoModelForCausalLM.from_pretrained( model_name, load_in_4bit=True, torch_dtype=torch.bfloat16, quantization_config=bnb_config, device_map='auto'
)Last inn den finjusterte modellen og tokenizeren.
#load the model and tokenizer
model = PeftModel.from_pretrained(model, adapters_name) tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.bos_token_id = 1 stop_token_ids = [0]Generer en detaljert og beskrivende Midjourney-forespørsel med bare noen få ord.
#prompt
text = "[INST] generate a midjourney prompt in less than 20 words for A computer with an emotional chip [/INST]" #encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('nn')
print(decoded[0])Modellrespons: Når datamaskinen med en emosjonell brikke begynner å behandle følelsene sine, begynner den å stille spørsmål ved dens eksistens og formål, noe som fører til en reise med selvoppdagelse og selvforbedring.
#prompt
text = "[INST] generate a midjourney prompt in less than 20 words for A rainbow chasing its colors [/INST]" #encoder and decoder
encoded = tokenizer(text, return_tensors="pt", add_special_tokens=False)
model_input = encoded
model.to(device)
generated_ids = model.generate(**model_input, max_new_tokens=200, do_sample=True)
decoded = tokenizer.batch_decode(generated_ids)
print('nn')
print(decoded[0])Modellrespons: En regnbue som jager farger befinner seg i en ørken hvor himmelen er et hav av uendelig blått, og regnbuens farger er spredt i sanden.
konklusjonen
Mistral 7B har vist seg å være et betydelig fremskritt innen store språkmodeller. Dens effektive arkitektur, kombinert med dens overlegne ytelse, viser potensialet til å være en stift for ulike NLP-oppgaver i fremtiden. Denne bloggen gir innsikt i modellens arkitektur, dens anvendelse og hvordan man kan utnytte kraften til spesifikke oppgaver som oversettelse, oppsummering og finjustering for andre applikasjoner. Med riktig veiledning og eksperimentering kan Mistral 7B omdefinere grensene for hva som er mulig med LLM-er.
Nøkkelfunksjoner
- Mistral-7B-Instruct utmerker seg i ytelse til tross for færre parametere.
- Den bruker Sliding Window Attention for lang sekvensoptimalisering.
- Funksjoner som Flash Attention og xFormers dobler hastigheten.
- Rolling Buffer Cache sikrer effektiv minneadministrasjon.
- Allsidig: Håndterer oversettelse, oppsummering, generering av strukturert data, tekstgenerering og tekstfullføring.
- Spør Engineering om å legge til tilpassede instruksjoner kan hjelpe modellen å forstå spørringen bedre og utføre flere komplekse språkoppgaver.
- Finjuster Mistral 7B for spesifikke språkoppgaver som å opptre som en rask ingeniør.
Ofte Stilte Spørsmål
A. Mistral-7B er designet for effektivitet og ytelse. Selv om den har færre parametere enn noen andre modeller, lar dens arkitektoniske fremskritt, for eksempel skyvevinduet Attention, levere enestående resultater, til og med utkonkurrere større modeller i spesifikke oppgaver.
A. Ja, Mistral-7B kan finjusteres for ulike oppgaver. Veiledningen gir et eksempel på finjustering av modellen for å konvertere korte tekstbeskrivelser til detaljerte spørsmål for bildegenerering.
A. Sliding Window Attention (SWA) lar modellen håndtere lengre sekvenser effektivt. Med en vindusstørrelse på 4096 optimerer SWA oppmerksomhetsoperasjoner, slik at Mistral-7B kan behandle lange tekster uten å gå på akkord med hastighet eller nøyaktighet.
A. Ja, når du kjører Mistral-7B-slutninger, anbefaler vi å bruke ctransformers-biblioteket, spesielt når du arbeider i Google Colab. Du kan også laste inn modellen fra Hugging Face for ekstra bekvemmelighet
A. Det er avgjørende å lage detaljerte instruksjoner i inndataprompten. Mistral-7Bs allsidighet gjør den i stand til å forstå og følge disse detaljerte instruksjonene, og sikre nøyaktige og ønskede utdata. Riktig rask konstruksjon kan forbedre modellens ytelse betydelig.
Referanser
- Miniatyrbilde – generert ved hjelp av stabil diffusjon
- Arkitektur – Papir
Mediene vist i denne artikkelen eies ikke av Analytics Vidhya og brukes etter forfatterens skjønn.
I slekt
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.analyticsvidhya.com/blog/2023/11/from-gpt-to-mistral-7b-the-exciting-leap-forward-in-ai-conversations/

