Amazon Titan lmage Generator G1 er en banebrytende tekst-til-bilde-modell, tilgjengelig via Amazonas grunnfjell, som er i stand til å forstå spørsmål som beskriver flere objekter i ulike sammenhenger og fanger opp disse relevante detaljene i bildene den genererer. Den er tilgjengelig i US East (N. Virginia) og US West (Oregon) AWS-regioner og kan utføre avanserte bilderedigeringsoppgaver som smart beskjæring, in-painting og bakgrunnsendringer. Brukere vil imidlertid gjerne tilpasse modellen til unike egenskaper i tilpassede datasett som modellen ikke allerede er trent på. Egendefinerte datasett kan inkludere svært proprietære data som er i samsvar med retningslinjene for merkevaren din eller spesifikke stiler, for eksempel en tidligere kampanje. For å løse disse brukstilfellene og generere fullstendig personlige bilder, kan du finjustere Amazon Titan Image Generator med dine egne data ved å bruke tilpassede modeller for Amazon Bedrock.
Fra å generere bilder til å redigere dem, tekst-til-bilde-modeller har brede bruksområder på tvers av bransjer. De kan øke medarbeidernes kreativitet og gi muligheten til å forestille seg nye muligheter ganske enkelt med tekstlige beskrivelser. For eksempel kan det hjelpe design og gulvplanlegging for arkitekter og tillate raskere innovasjon ved å gi muligheten til å visualisere ulike design uten den manuelle prosessen med å lage dem. På samme måte kan det hjelpe til med design på tvers av ulike bransjer som produksjon, motedesign i detaljhandel og spilldesign ved å strømlinjeforme genereringen av grafikk og illustrasjoner. Tekst-til-bilde-modeller forbedrer også kundeopplevelsen din ved å tillate personlig tilpasset annonsering samt interaktive og oppslukende visuelle chatbots i brukssaker med media og underholdning.
I dette innlegget guider vi deg gjennom prosessen med å finjustere Amazon Titan Image Generator-modellen for å lære deg to nye kategorier: Hunden Ron og katten Smila, våre favoritt kjæledyr. Vi diskuterer hvordan du forbereder dataene dine for modellfinjusteringsoppgaven og hvordan du oppretter en modelltilpasningsjobb i Amazon Bedrock. Til slutt viser vi deg hvordan du tester og distribuerer din finjusterte modell med Provisioned Throughput.
 |
 |
| Hunden Ron | Smil katten |
Evaluering av modellegenskaper før du finjusterer en jobb
Grunnmodeller er trent på store datamengder, så det er mulig at modellen din vil fungere godt nok ut av boksen. Det er derfor det er god praksis å sjekke om du faktisk trenger å finjustere modellen din for bruksområdet ditt, eller om rask utvikling er tilstrekkelig. La oss prøve å generere noen bilder av hunden Ron og katten Smila med basismodellen Amazon Titan Image Generator, som vist i de følgende skjermbildene.

Som forventet kjenner ikke den ut-av-boksen-modellen Ron og Smila ennå, og de genererte resultatene viser forskjellige hunder og katter. Med litt rask ingeniørarbeid kan vi gi flere detaljer for å komme nærmere utseendet til favorittdyrene våre.


Selv om de genererte bildene ligner mer på Ron og Smila, ser vi at modellen ikke er i stand til å gjengi den fulle likheten til dem. La oss nå starte en finjusteringsjobb med bildene fra Ron og Smila for å få konsistente, personlige utdata.
Finjustering av Amazon Titan Image Generator
Amazon Bedrock gir deg en serverløs opplevelse for finjustering av Amazon Titan Image Generator-modellen. Du trenger bare å forberede dataene dine og velge hyperparametrene dine, så vil AWS håndtere de tunge løftene for deg.
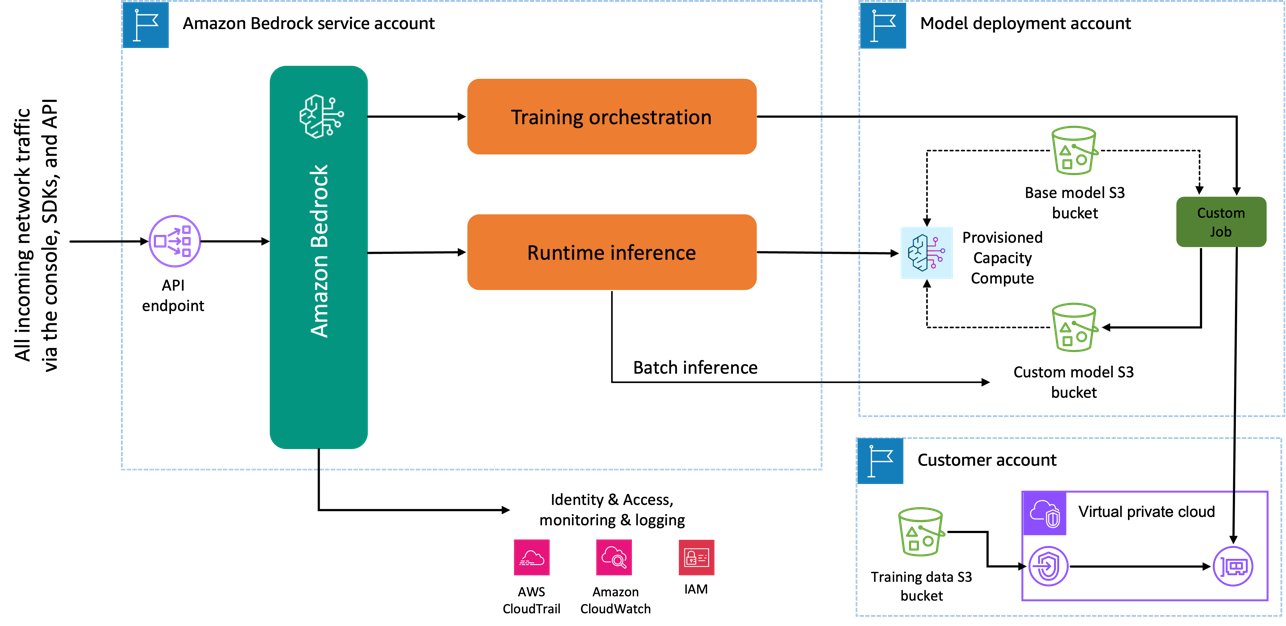
Når du bruker Amazon Titan Image Generator-modellen til å finjustere, opprettes en kopi av denne modellen i AWS-modellutviklingskontoen, eid og administrert av AWS, og en modelltilpasningsjobb opprettes. Denne jobben får deretter tilgang til finjusteringsdataene fra en VPC, og Amazon Titan-modellen har sine vekter oppdatert. Den nye modellen lagres deretter i en Amazon enkel lagringstjeneste (Amazon S3) plassert i samme modellutviklingskonto som den ferdigtrente modellen. Den kan nå kun brukes til slutninger av kontoen din og deles ikke med noen annen AWS-konto. Når du kjører inferens, får du tilgang til denne modellen via en beregnet kapasitetsberegning eller direkte ved å bruke batch-slutning for Amazon Bedrock. Uavhengig av slutningsmetoden som er valgt, forblir dataene dine på kontoen din og blir ikke kopiert til noen AWS-eid konto eller brukt til å forbedre Amazon Titan Image Generator-modellen.
Følgende diagram illustrerer denne arbeidsflyten.
Datavern og nettverkssikkerhet
Dataene dine som brukes til finjustering, inkludert forespørsler, så vel som de tilpassede modellene, forblir private i AWS-kontoen din. De deles ikke eller brukes til modellopplæring eller tjenesteforbedringer, og deles ikke med tredjeparts modellleverandører. Alle dataene som brukes til finjustering er kryptert under overføring og hvile. Dataene forblir i samme region der API-kallet behandles. Du kan også bruke AWS PrivateLink for å opprette en privat forbindelse mellom AWS-kontoen der dataene dine ligger og VPC.
Dataforberedelse
Før du kan opprette en modelltilpasningsjobb, må du klargjør treningsdatasettet ditt. Formatet på opplæringsdatasettet ditt avhenger av typen tilpasningsjobb du oppretter (finjustering eller fortsatt forhåndstrening) og modaliteten til dataene dine (tekst-til-tekst, tekst-til-bilde eller bilde-til- innebygging). For Amazon Titan Image Generator-modellen må du oppgi bildene du vil bruke for finjusteringen og en bildetekst for hvert bilde. Amazon Bedrock forventer at bildene dine lagres på Amazon S3 og at parene med bilder og bildetekster leveres i et JSONL-format med flere JSON-linjer.
Hver JSON-linje er et eksempel som inneholder en bilderefer, S3 URI for et bilde og en bildetekst som inkluderer en tekstmelding for bildet. Bildene dine må være i JPEG- eller PNG-format. Følgende kode viser et eksempel på formatet:
{"image-ref": "s3://bucket/path/to/image001.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image002.png", "caption": ""} {"image-ref": "s3://bucket/path/to/image003.png", "caption": ""}
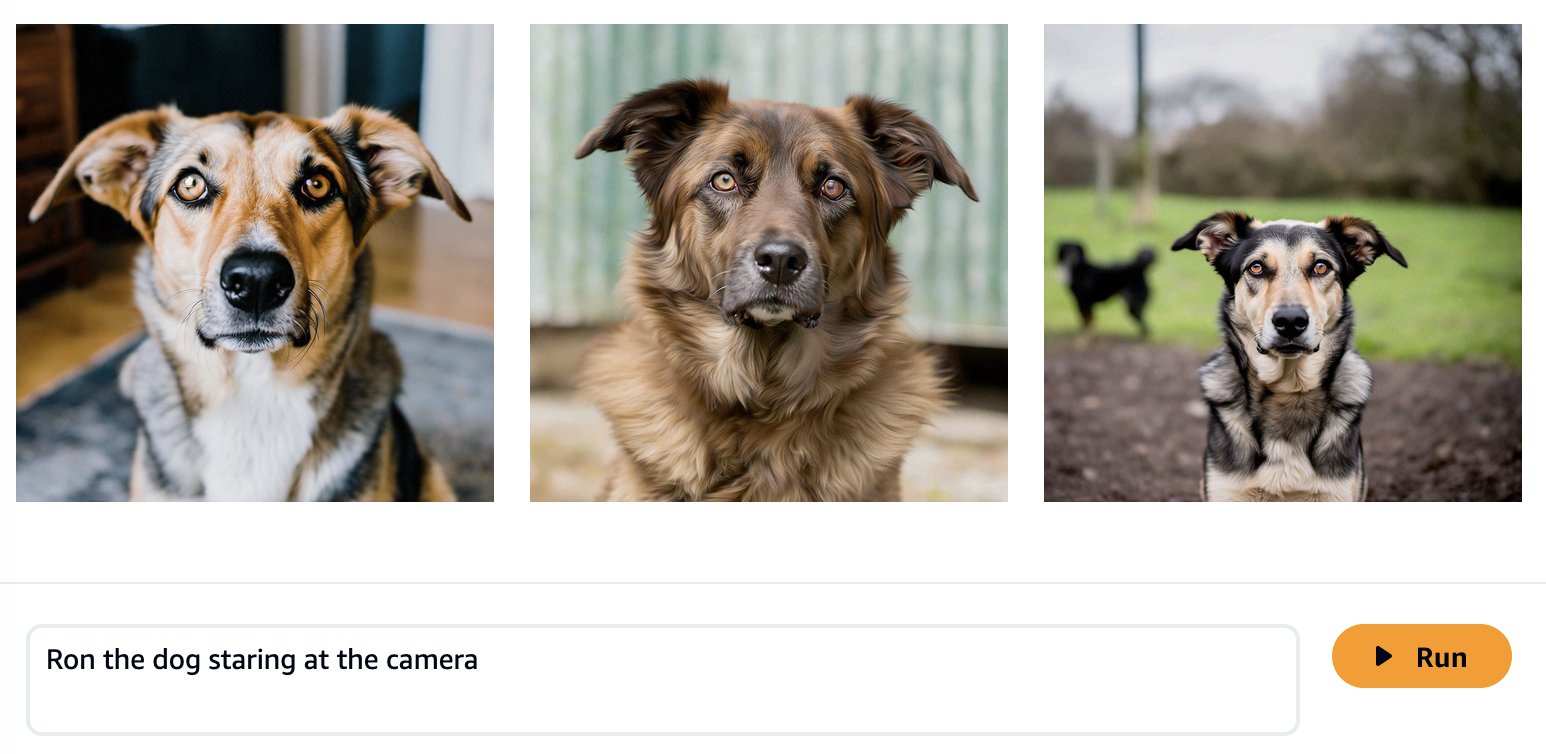
Fordi "Ron" og "Smila" er navn som også kan brukes i andre sammenhenger, for eksempel en persons navn, legger vi til identifikatorene "Ron the dog" og "Smila the cat" når vi lager ledeteksten for å finjustere modellen vår . Selv om det ikke er et krav for finjustering av arbeidsflyten, gir denne tilleggsinformasjonen mer kontekstuell klarhet for modellen når den tilpasses for de nye klassene, og vil unngå forvirringen av "Ron hunden" med en person som heter Ron og " Smila the cat» med byen Smila i Ukraina. Ved å bruke denne logikken viser følgende bilder et eksempel på opplæringsdatasettet vårt.
 |
 |
 |
| Hunden Ron ligger på en hvit hundeseng | Hunden Ron sitter på et flisgulv | Hunden Ron ligger på et bilsete |
 |
 |
 |
| Smila katten liggende på en sofa | Katten Smila stirrer på kameraet som ligger på en sofa | Smila katten legger i en dyrebærer |
Når vi transformerer dataene våre til formatet forventet av tilpasningsjobben, får vi følgende eksempelstruktur:
{"image-ref": "/ron_01.jpg", "caption": "Hunden Ron ligger på en hvit hundeseng"} {"image-ref": "/ron_02.jpg", "caption": "Ron hunden sitter på et flisgulv"} {"image-ref": "/ron_03.jpg", "caption": "Ron hunden som ligger på et bilsete"} {"image-ref": "/smila_01.jpg", "caption": "Smila katten som ligger på en sofa"} {"image-ref": "/smila_02.jpg", "caption": "Smila katten som sitter ved siden av vinduet ved siden av en statuekatt"} {"image-ref": "/smila_03.jpg", "caption": "Smila katten som ligger på en dyrebærer"}
Etter at vi har opprettet JSONL-filen vår, må vi lagre den på en S3-bøtte for å starte vår tilpasningsjobb. Finjusteringsjobber for Amazon Titan Image Generator G1 vil fungere med 5–10,000 60 bilder. For eksempelet som er omtalt i dette innlegget, bruker vi 30 bilder: 30 av hunden Ron og XNUMX av katten Smila. Generelt vil det å gi flere varianter av stilen eller klassen du prøver å lære, forbedre nøyaktigheten til den finjusterte modellen. Men jo flere bilder du bruker for finjustering, jo mer tid vil det ta før finjusteringsjobben er ferdig. Antall bilder som brukes påvirker også prisen på den finjusterte jobben din. Referere til Priser for Amazons grunnfjell for mer informasjon.
Finjustering av Amazon Titan Image Generator
Nå som vi har treningsdataene våre klare, kan vi begynne på en ny tilpasningsjobb. Denne prosessen kan gjøres både via Amazon Bedrock-konsollen eller APIer. For å bruke Amazon Bedrock-konsollen, fullfør følgende trinn:
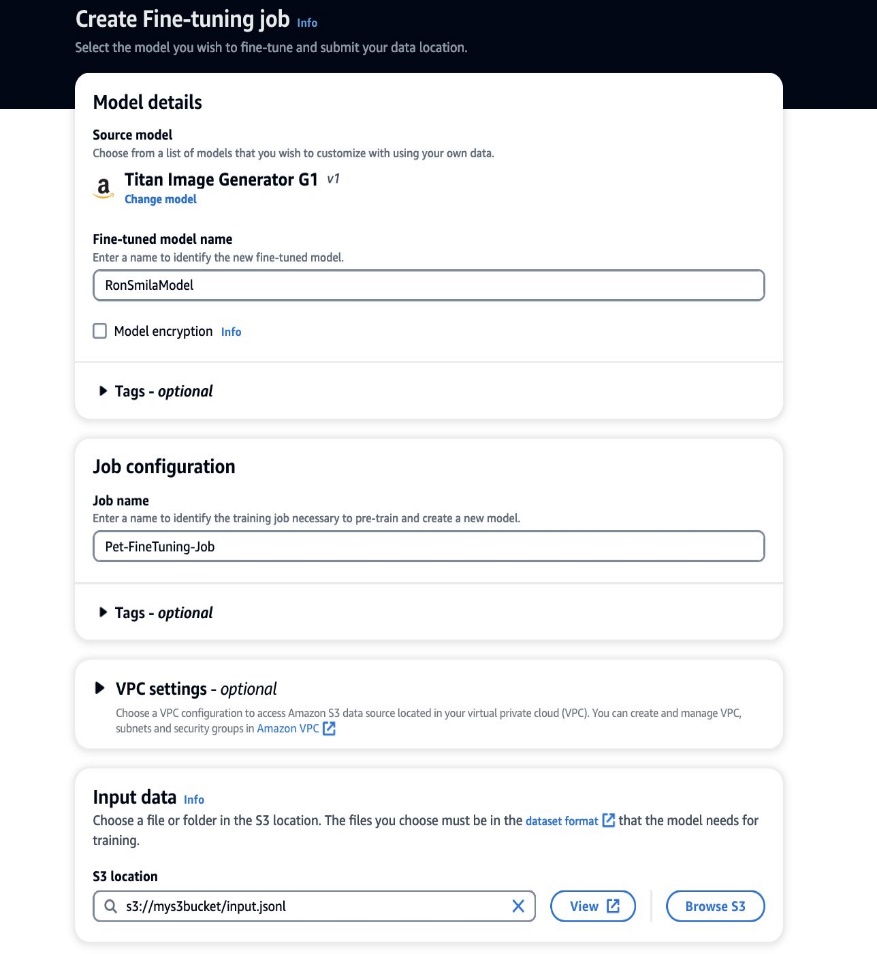
- På Amazon Bedrock-konsollen velger du Tilpassede modeller i navigasjonsruten.
- På Tilpass modellen meny, velg Lag finjusteringsjobb.
- Til Finjustert modellnavn, skriv inn et navn for den nye modellen.
- Til Jobbkonfigurasjon, skriv inn et navn for opplæringsjobben.
- Til Inndata, skriv inn S3-banen til inndataene.
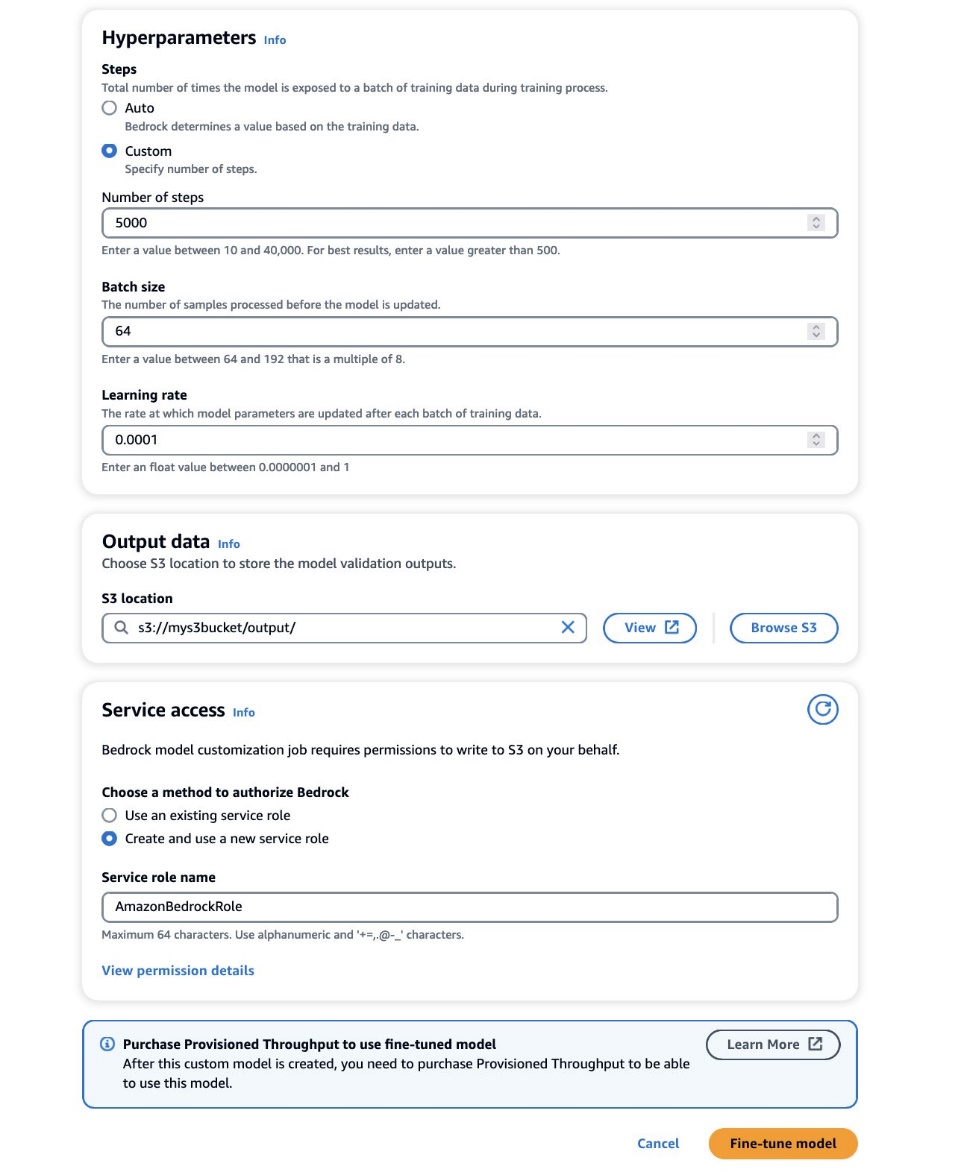
- på Hyperparametere oppgi verdier for følgende:
- Antall trinn – Antall ganger modellen er eksponert for hver batch.
- Partistørrelse, Gruppestørrelse – Antall prøver behandlet før oppdatering av modellparametrene.
- Læringsfrekvens – Hastigheten som modellparametrene oppdateres med etter hver batch. Valget av disse parameterne avhenger av et gitt datasett. Som en generell retningslinje anbefaler vi at du starter med å fikse batchstørrelsen til 8, læringshastigheten til 1e-5, og setter antall trinn i henhold til antall bilder som brukes, som beskrevet i følgende tabell.
| Antall bilder oppgitt | 8 | 32 | 64 | 1,000 | 10,000 |
| Antall trinn anbefales | 1,000 | 4,000 | 8,000 | 10,000 | 12,000 |
Hvis resultatene av finjusteringsjobben ikke er tilfredsstillende, bør du vurdere å øke antall trinn hvis du ikke ser noen tegn på stilen i genererte bilder, og redusere antall trinn hvis du observerer stilen i de genererte bildene, men med artefakter eller uskarphet. Hvis den finjusterte modellen ikke klarer å lære den unike stilen i datasettet ditt selv etter 40,000 XNUMX trinn, bør du vurdere å øke batchstørrelsen eller lærehastigheten.
- på Utdata seksjon, skriv inn S3-utgangsbanen der valideringsutdataene, inkludert periodisk registrerte valideringstap og nøyaktighetsmålinger, er lagret.
- på Tjenestetilgang seksjon, generere en ny AWS identitets- og tilgangsadministrasjon (IAM)-rolle eller velg en eksisterende IAM-rolle med de nødvendige tillatelsene for å få tilgang til S3-bøttene dine.
Denne autorisasjonen gjør det mulig for Amazon Bedrock å hente inn- og valideringsdatasett fra den angitte bøtten og lagre valideringsutdata sømløst i S3-bøtten din.
- Velg Finjuster modellen.
Med de riktige konfigurasjonene satt, vil Amazon Bedrock nå trene din egendefinerte modell.
Distribuer den finjusterte Amazon Titan Image Generator med Provisioned Throughput
Etter at du har opprettet en egendefinert modell, lar Provisioned Throughput deg tildele en forhåndsbestemt, fast prosesskapasitet til den tilpassede modellen. Denne tildelingen gir et konsistent nivå av ytelse og kapasitet for håndtering av arbeidsbelastninger, noe som resulterer i bedre ytelse i produksjonsarbeidsmengder. Den andre fordelen med Provisioned Throughput er kostnadskontroll, fordi standard token-basert prissetting med on-demand slutningsmodus kan være vanskelig å forutsi i stor skala.
Når finjusteringen av modellen din er fullført, vil denne modellen vises på Egendefinerte modeller side på Amazon Bedrock-konsollen.
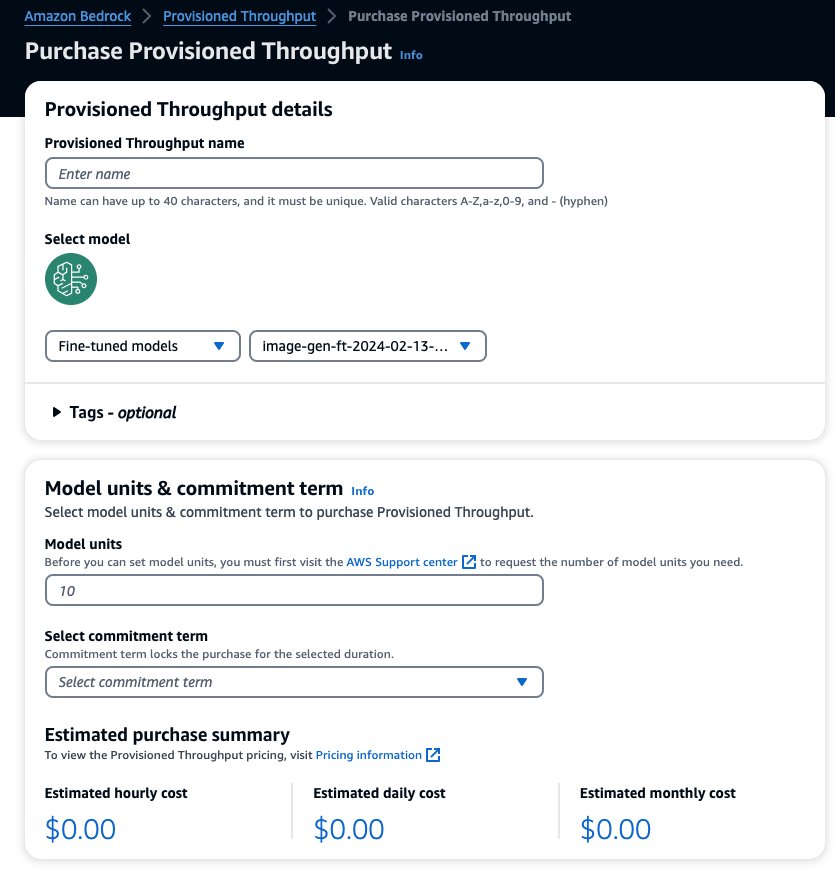
For å kjøpe Provisioned Throughput, velg den tilpassede modellen du nettopp har finjustert og velg Kjøp Provisioned Throughput.
Dette forhåndsutfyller den valgte modellen du ønsker å kjøpe Provisioned Throughput for. For å teste den finjusterte modellen før distribusjon, sett modellenheter til en verdi på 1 og sett forpliktelsestiden til Ingen binding. Dette lar deg raskt begynne å teste modellene dine med dine tilpassede meldinger og sjekke om opplæringen er tilstrekkelig. Når nye finjusterte modeller og nye versjoner er tilgjengelige, kan du dessuten oppdatere Provisioned Throughput så lenge du oppdaterer den med andre versjoner av samme modell.
Finjustere resultater
For vår oppgave med å tilpasse modellen på hunden Ron og katten Smila, viste eksperimenter at de beste hyperparametrene var 5,000 trinn med en batchstørrelse på 8 og en læringsrate på 1e-5.
Følgende er noen eksempler på bildene generert av den tilpassede modellen.
 |
 |
 |
| Hunden Ron iført en superheltkappe | Ron hunden på månen | Ron hunden i et svømmebasseng med solbriller |
 |
 |
 |
| Smila katten på snøen | Katten Smila i svart-hvitt stirrer på kameraet | Katten Smila med julelue |
konklusjonen
I dette innlegget diskuterte vi når du skal bruke finjustering i stedet for å konstruere spørsmålene dine for å generere bilder av bedre kvalitet. Vi viste hvordan du finjusterer Amazon Titan Image Generator-modellen og distribuerer den tilpassede modellen på Amazon Bedrock. Vi ga også generelle retningslinjer for hvordan du klargjør dataene dine for finjustering og angir optimale hyperparametre for mer nøyaktig modelltilpasning.
Som et neste trinn kan du tilpasse følgende eksempel til ditt bruksområde for å generere hyper-personlige bilder ved hjelp av Amazon Titan Image Generator.
Om forfatterne
 Maira Ladeira Tanke er Senior Generative AI Data Scientist ved AWS. Med bakgrunn fra maskinlæring har hun over 10 års erfaring med å bygge og bygge AI-applikasjoner med kunder på tvers av bransjer. Som teknisk leder hjelper hun kunder med å akselerere deres oppnåelse av forretningsverdi gjennom generative AI-løsninger på Amazon Bedrock. På fritiden liker Maira å reise, leke med katten Smila og tilbringe tid med familien et varmt sted.
Maira Ladeira Tanke er Senior Generative AI Data Scientist ved AWS. Med bakgrunn fra maskinlæring har hun over 10 års erfaring med å bygge og bygge AI-applikasjoner med kunder på tvers av bransjer. Som teknisk leder hjelper hun kunder med å akselerere deres oppnåelse av forretningsverdi gjennom generative AI-løsninger på Amazon Bedrock. På fritiden liker Maira å reise, leke med katten Smila og tilbringe tid med familien et varmt sted.
 Dani Mitchell er en AI/ML-spesialistløsningsarkitekt hos Amazon Web Services. Han er fokusert på bruk av datasyn og å hjelpe kunder over hele EMEA med å akselerere deres ML-reise.
Dani Mitchell er en AI/ML-spesialistløsningsarkitekt hos Amazon Web Services. Han er fokusert på bruk av datasyn og å hjelpe kunder over hele EMEA med å akselerere deres ML-reise.
 Bharathi Srinivasan er dataforsker ved AWS Professional Services, hvor hun elsker å bygge kule ting på Amazons grunnfjell. Hun brenner for å drive forretningsverdi fra maskinlæringsapplikasjoner, med fokus på ansvarlig AI. Utenom å bygge nye AI-opplevelser for kunder, elsker Bharathi å skrive science fiction og utfordre seg selv med utholdenhetsidretter.
Bharathi Srinivasan er dataforsker ved AWS Professional Services, hvor hun elsker å bygge kule ting på Amazons grunnfjell. Hun brenner for å drive forretningsverdi fra maskinlæringsapplikasjoner, med fokus på ansvarlig AI. Utenom å bygge nye AI-opplevelser for kunder, elsker Bharathi å skrive science fiction og utfordre seg selv med utholdenhetsidretter.
 Achin Jain er en Applied Scientist med Amazon Artificial General Intelligence (AGI)-teamet. Han har ekspertise på tekst-til-bilde-modeller og er fokusert på å bygge Amazon Titan Image Generator.
Achin Jain er en Applied Scientist med Amazon Artificial General Intelligence (AGI)-teamet. Han har ekspertise på tekst-til-bilde-modeller og er fokusert på å bygge Amazon Titan Image Generator.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/machine-learning/fine-tune-your-amazon-titan-image-generator-g1-model-using-amazon-bedrock-model-customization/

