
Bilde av forfatter
Praktiske prosjekter er den beste måten å lære om datavitenskap og maskinlæring. Data Science-oppgaver vil eksponere deg for alle fasetter av denne disiplinen og hjelpe deg å finpusse ferdighetene dine med praktisk SQL-, R- eller Python-erfaring. Det vil ikke bare hjelpe deg med å forbedre dine datavitenskapelige ferdigheter og få selvtillit, men det vil også gjøre det mulig for deg å lage overbevisende CV. I denne artikkelen vil vi diskutere ulike datavitenskapsprosjektideer for nybegynnere som vil hjelpe deg med å bygge en sterk datavitenskapelig portefølje.
Med en eksponentiell økning i dataene i dagens verden, har datavitenskap blitt det mest ettertraktede feltet. Alle selskapene i dagens verden får et konkurransefortrinn hvis de utnytter datavitenskap på en effektiv måte. Dette har ført til en økning i antall ledige stillinger i alle selskapene for dataanalytikere og dataforskere. For å få jobb på dette feltet er det en god idé å vise frem ferdighetene dine ved å bygge dataanalyseprosjekter å løse problemer i den virkelige verden. Før vi begynner å diskutere prosjektene, la oss se hvorfor et Data Science-prosjekt vil hjelpe deg med å få en jobb og hvorfor du bør ha en imponerende datavitenskapelig prosjektportefølje.
Hvis du virkelig er interessert i Data Science-feltet, bør du ha en grunnleggende forståelse av hva slags problemer som løses ved hjelp av datavitenskap og hvordan du kan nærme deg dem. Hvis du ønsker å komme inn på dette feltet, trenger du en forståelse av ferdighetene som kreves for å løse spesifikke datavitenskapelige problemer. Online kurs og bøker kan bare ta deg til et visst nivå, men hvis du virkelig ønsker å komme inn på dette feltet, bør du vite hvordan data brukes til å løse problemer i den virkelige verden. For å forstå dette er det å jobbe med prosjekter den eneste måten å hjelpe deg med å få alle ferdighetene som kreves for å gå inn i Data Science.
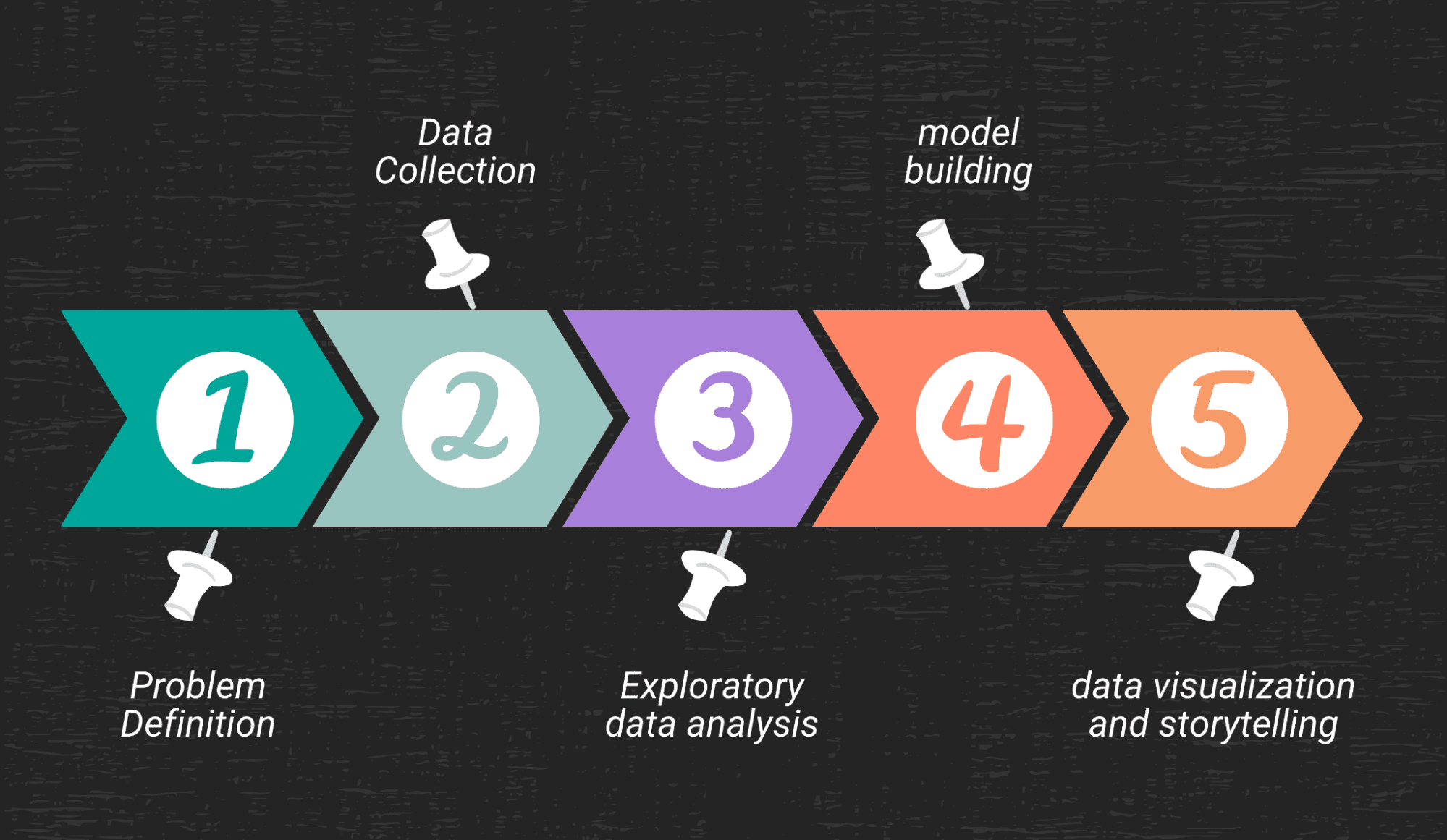
Data Science-prosjekter vil hjelpe deg med å forstå de ulike trinnene som kreves for å løse et problem:
- Definere problemet og dele det ned i mindre trinn
- Datainnsamling
- Utforskende dataanalyse
- Modellbygging
- Datavisualisering og historiefortelling
Bilde av forfatter
Problem Definisjon
Dette er det første trinnet i et datavitenskapelig prosjekt. Ethvert datavitenskapelig prosjekt begynner med dette trinnet der du må forstå og definere problemet tydelig. Dette er en av de viktigste aspektene ved livssyklusen for et datavitenskapelig prosjekt. For eksempel, hvis du vil investere pengene dine i Tesla-aksjer, men du vil forstå hvordan detaljinvestorer ser på selskapet, og hva er de generelle følelsene? Da må du definere dette problemet klart. I dette eksemplet vil problemformuleringen din være: "Forstå hvordan Tesla blir oppfattet av detaljinvestorene?"
Når du har identifisert problemet, må du forstå hva slags data som trengs for å løse problemet.
Datainnsamling
Når du har identifisert problemet, er neste trinn datainnsamling. Du må identifisere datakildene som du vil være i stand til å løse problemet du har definert i det første trinnet. Du må kanskje hente data fra én kilde eller flere kilder ved å bruke API.
For eksempelet som ble diskutert i det første punktet, la oss si at du planlegger å investere i Tesla-aksjer, men prøver å forstå den generelle følelsen av detaljinvestorer overfor dette selskapet. For å løse dette problemet, må du samle informasjonen som vil ha kommentarer om dette selskapet fra detaljinvestorer. Du bestemmer deg for å gå på Twitter og se hvordan folk reagerer på forskjellige kunngjøringer fra disse selskapene. Du kan gå gjennom individuelle tweets og forstå følelsene siden det vil være millioner av tweets tilgjengelig.
I slike scenarier må du få dataene om tweets som snakker om Tesla. For å få dataene, vil du opprette en utviklerkonto på Twitter og bruke Python til å trekke ut tweetene ved hjelp av Twitter API. Dette vil være datainnsamlingstrinnene som kreves for å løse ethvert prosjekt. I de fleste selskaper er det dedikerte dataingeniører som er ansvarlige for å samle inn data, men noen ganger vil en dataforsker også trenge disse ferdighetene for å samle informasjon ved hjelp av en API.
Utforskende dataanalyse
Dette er nok et viktig skritt i Data Science-prosjektets livssyklus. Utforskende dataanalyse handler om å forstå dataene, identifisere kolonnene som kreves, fjerne kolonnene som er overflødige, manglende verdibehandling, avviksdeteksjon og identifisere mønstre i dataene.
I Twitter-eksemplet diskutert ovenfor, må du rense tweets, fjerne overflødig informasjon og bare beholde relevante tweets som kreves for analysen, forstå volumet av tweets over tid for å finne sesongvariasjoner, osv. Dette trinnet brukes til å forstå og utforske dataene og gjøre endringer i dataene hvis det ikke passer dine behov.
Modellbygging
Når du har definert problemet, samlet inn data og gjort den foreløpige analysen ved hjelp av EDA-teknikkene, starter du med modellbyggingsfasen. Når du definerer et problem, vil du innse om problemet kan løses ved hjelp av overvåket eller uovervåket maskinlæringsalgoritmer. Basert på hva problemet ditt krever, må du forstå hvilken modell du skal bruke.
Denne fasen tar litt tid å forstå hvilken modell som vil være relevant for problemet ditt. Det er mange modeller tilgjengelig på markedet som kan brukes til å løse det samme problemet, og derfor må du vurdere disse modellene basert på nøyaktigheten. Evaluering er en tidkrevende prosess siden det er mye prøving og feiling involvert i dette trinnet. Når modellen din er bygget og fungerer godt nok, kan du begynne å jobbe med datavisualisering og historiefortelling.
I Twitter-eksemplet diskutert ovenfor, kan du trene en maskinlæringsmodell ved å bruke et merket datasett (Informasjon om hver tweet som er merket som enten positiv/negativ/nøytral). Når modellen er opplært, må du legge inn en ny tweet for å teste ytelsen til den modellen. Når du har testet flere prøver, kan du sjekke antall falske positive og falske negative for å forstå hvordan modellen presterer. Du må prøve ut andre modeller for å sammenligne nøyaktigheten til forskjellige klassifiseringsalgoritmer.
Datavisualisering og historiefortelling
Hvis du gjør analysen flittig, men du ikke er i stand til å formidle historien ordentlig, nytter det ikke. Å formidle innsikten du finner fra dataene til et ikke-teknisk publikum er en av de viktigste ferdigheter som kreves for en dataforsker. Det er mange verktøy og teknikker tilgjengelig for historiefortelling. Du kan bruke Tableau eller Power BI for å hjelpe deg med å bygge bedre visualiseringer.
Nå som vi har diskutert trinnene du må ta i et datavitenskapsprosjekt, la oss fokusere på noen av de virkelige datavitenskapsprosjektene du kan jobbe med.
Det er mange ressurser tilgjengelig på nettet for å komme i gang med dataanalyse og datavitenskapelige prosjekter. I denne delen vil vi diskutere noen av prosjektideene du kan jobbe med for å løse problemer i den virkelige verden. Det første trinnet vil være å identifisere kilden til data, og vi vil diskutere det også.

Bilde av forfatter
Tilbøyelighetsmodellering
En tilnærming kalt "tilbøyelighetsmodellering" tar sikte på å forutsi sannsynligheten for at nettstedbrukere, potensielle kunder eller kunder vil foreta bestemte handlinger. Det er en statistisk metode som identifiserer sannsynligheten for at en kunde ville gjøre en bestemt handling ved å ta hensyn til alle uavhengige så vel som forvirrende faktorer som kan påvirke kundeadferd.

Bilde av forfatter
For eksempel kan en tilbøyelighetsmodell brukes av et markedsføringsteam for å forstå og bestemme sannsynligheten eller sannsynligheten for at et kundeemne kan konvertere og bli en betalende kunde. Eller det kan også brukes til å forstå sannsynligheten for at eksisterende kunder kommer fra plattformen. Dermed kan tilbøyelighetsmodellering hjelpe selskapene til å allokere ressurser klokt og få bedre resultater og dermed redusere kostnadene. For eksempel, i stedet for å sende en markedsføringskampanje til alle 10 XNUMX kunder, kan et selskap kjøre tilbøyelighetsmodellering for å identifisere hvilke kunder som er mer sannsynlig å svare på e-poster og dermed sende e-poster til kun de spesifikke kundene som vil resultere i tids- og ressursbesparelser. Det er et godt datasett på kaggle for tilbøyelighetsmodellering å forstå kundenes tilbøyelighet til å kjøpe et bestemt produkt.
Eksempler fra den virkelige verden
Det er mange selskaper som bruker tilbøyelighetsmodellering. Tilbøyelighetsmodellering kan brukes i mange applikasjoner som å bestemme tilbøyelighet til å kjøpe, tilbøyelighet til å avbryte, tilbøyelighet til å engasjere eller forutsi kundens levetidsverdi.
Dette brukes hovedsakelig av markedsføringsteam fra selskaper som Facebook/Meta, Google, Amazon, osv. Markedsføringsteam er avhengige av kundenes tilbøyelighetsscore for å avgjøre om de skal investere i en spesifikk kundegruppe eller ikke. Derfor er det et must å ha et tilbøyelighetsmodelleringsprosjekt i porteføljen din. Det er et flott modelleksempel på kaggle for å forstå hvilke kunder de skal målrette mot markedsføringskampanjer.
Tekstanalyse
Med teknologiske fremskritt og digitalisering er det en enorm mengde informasjon tilgjengelig. Ut av all denne informasjonen er det mye tekstdata på internett. Bedrifter utnytter disse tekstdataene for å forstå hva kundene sier om selskapene sine, og hva de sier om produktene sine, og dermed gjøre endringer i strategien. Det er et godt prosjekt på kaggle for å utføre sentiment analyse fra datasettet for filmanmeldelser.
Bilde av forfatter
Det er mange felt innen tekstanalyse og ett av dem er Natural Language Processing (NLP). NLP brukes til å bryte ned tekstdataene i maskinlesbart format, tokenisere tekstdataene, trekke ut meninger fra dataene og deretter identifisere innsikt. Det er mange bruksområder for naturlig språkbehandling; forstå følelsene til kundene dine, bygge samtaleagenter eller chatbots, bygge tjenester som Alexa eller Siri, bygge språkoversettelsesmotorer og mye mer. Derfor er det en god idé å ha prosjekter knyttet til naturlig språkbehandling i porteføljen.
Eksempler fra den virkelige verden
Nesten alle bedrifter i dagens verden bruker tekstanalyse eller naturlig språkbehandling for å forstå kundene sine og bygge innovative produkter. For eksempel, Facebook/Meta bruker tekstanalyse tungt. I motsetning til Instagram som har mesteparten av data i form av videoer og bilder, har Facebook stort sett tekstdata. De bruker disse tekstdataene til å automatisk kategorisere innlegg i forskjellige kategorier og automatisk fjerne innlegg som er støtende. Faktisk har Facebook utviklet et internt verktøy kalt Deep Text som brukes til å analysere og trekke ut betydningen av innlegg og dermed automatisk identifisere støtende innlegg og fjerne dem fra plattformen.
Bortsett fra Facebook er det mange selskaper som bruker tekstanalyse og maskinlæring for å bygge innovative løsninger for kundene sine. For eksempel, Amazon bygde Alexa som er en smart virtuell assistent. Alexa svarer på kundeforespørsler med nøyaktighet fordi den bruker tunge maskinlæringsalgoritmer under for først å oversette tale til tekst, deretter identifisere betydningen av teksten ved hjelp av NLP, deretter bruke maskinlæringsmodeller for å forutsi den nest beste responsen og deretter konvertere den responsen til en lydutgang.
Dermed blir Text Analytics eller Natural Language Processing brukt av de fleste av de innovative selskapene i dagens verden, og det vil være bra å ha et NLP-prosjekt i porteføljen for å utmerke seg i ditt neste intervju.
Anbefaling Motor
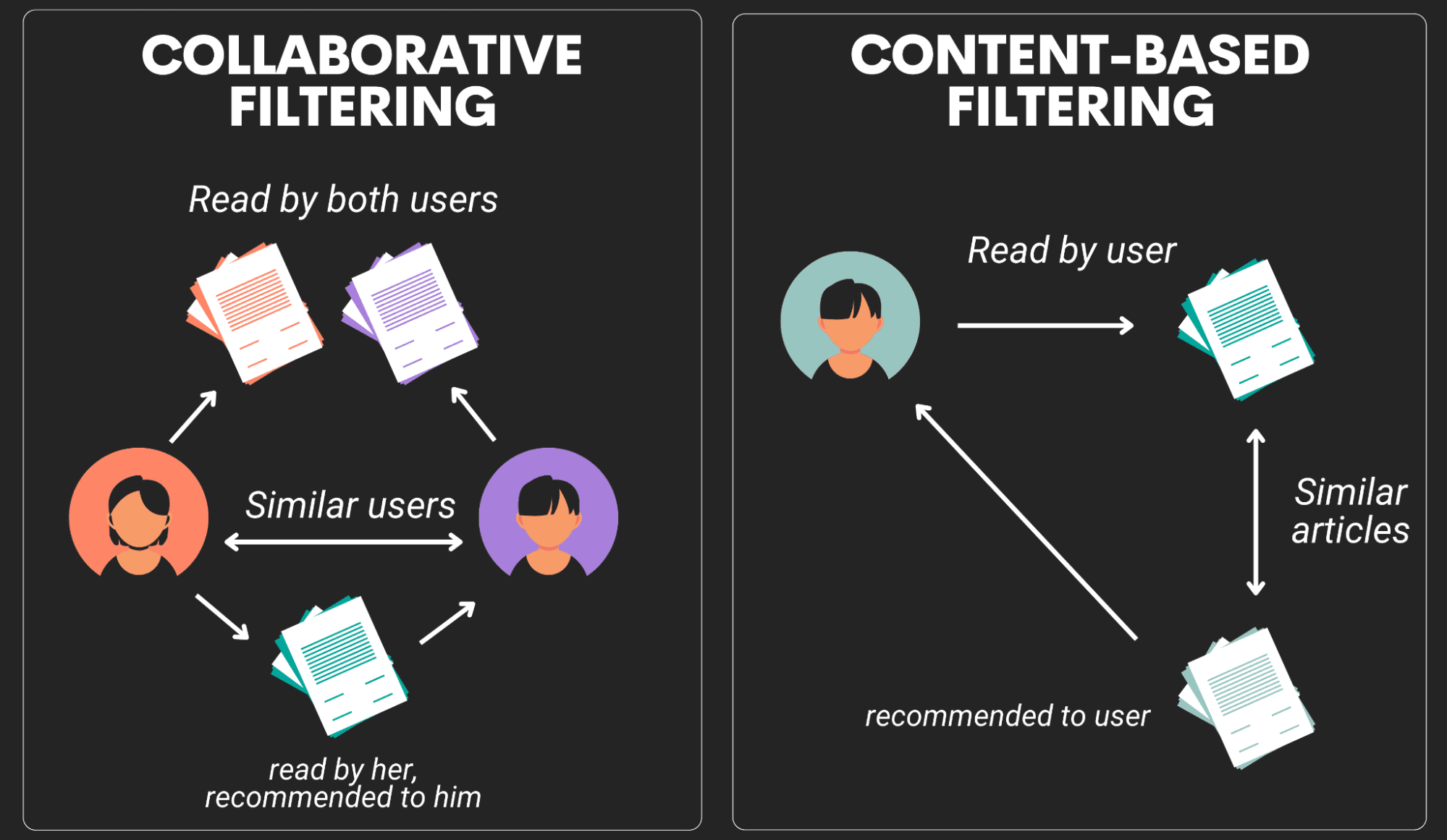
Anbefalingssystemer er en utvidet klasse av nettapplikasjoner som prøver å identifisere brukerresponsen basert på brukerens historiske data og anbefaler et nytt produkt eller en ny handling som brukeren mest sannsynlig vil ta. Anbefalingsmotorer kan klassifiseres i to hovedgrupper; Innholdsbaserte systemer og Collaborative filtreringssystemer.
Bilde av forfatter
Innholdsbaserte systemer: I disse motorene er anbefalingen basert på innholdet i en vare. Hvis du for eksempel har sett mange sci-fi-filmer på Netflix, vil Netflix anbefale deg nye filmer som er fra thrillerkategoriene og som kan ha lignende kategorier.
Samarbeidsfiltreringssystemer: I disse motorene er anbefalingen basert på likheten mellom de to brukerne, og hvis to brukere er like, kan de få en lignende anbefaling. For eksempel, basert på de historiske dataene, hvis bruker 1 og bruker 2 har sett lignende filmer, vil anbefalingssystemet anbefale en ny film til bruker 1 som kan ha blitt sett av bruker 2. Dermed vil elementene som anbefales til en bruker er de som foretrekkes av lignende brukere.
Den beste måten å lære et konsept på er å gjøre et prosjekt, og det er et veldig godt å bygge et moteanbefaler motor i python.
Eksempler fra den virkelige verden
Et av de vanligste eksemplene på anbefalingssystem er Netflix som anbefaler nye filmer, serier, dokumentarer basert på kundens historiske bruk. Amazon bruker også et anbefalingssystem for å anbefale lignende produkter til sine kunder basert på deres kjøps- eller nettleserhistorikk.
Ved å bruke den enorme mengden data den samler inn, Netflix har laget en anbefalingsmotor for sine brukere som opererer i nær sanntid. Hver brukers informasjon samles inn av Netflix, som deretter rangerer brukerne etter hva slags innhold de ser på, søker etter, legger til i overvåkningslister osv. Denne typen data er inkludert i Big Data, og alt lagres i databaser der maskinen læringsalgoritmer kan bruke det til å lage mønstre som avslører seerens preferanser. Siden hver bruker kan ha forskjellig smak, kan dette mønsteret matche en annen bruker eller ikke. Anbefalingssystemet presenterer TV-serier eller filmer som brukeren sannsynligvis vil se basert på disse vurderingene for hver klient.
Chatbots
Programvarene kjent som chatbots, også referert til som chatter-bots eller samtaleagenter, brukes ofte i stedet for live-agenter for å hjelpe klienter. Har du noen gang besøkt et nettsted for kundeservice, chattet med en representant og så lært at du faktisk snakket med en "robot"? Så du er klar over hva chatboter er!

Bilde av forfatter
Chatbots er vanligvis tilgjengelig for brukere gjennom frittstående apper eller nettbaserte apper. I disse dager er kundeservice der chatbots er mest brukt i den virkelige verden. Chatbots tar vanligvis over jobber som tidligere ble utført av faktiske mennesker, for eksempel kundeservicerepresentanter eller støtteagenter.
Chatbots er sofistikerte dataprogrammer som analyserer kundetekstchatter for å finne det riktige svaret. Alle disse robotene bruker naturlig språkbehandling (NLP), som vanligvis innebærer to trinn: naturlig språkforståelse, som transformerer og dekonstruerer teksten gitt av klienten; og maskinlæringsmodeller, som hjelper robotene å forstå og trekke ut meningen med setningen. Responsen på kundens tekst dannes i det andre trinnet, kjent som naturlig språkgenerering, ved å bruke betydningen skapt i det første. Grunnlaget for å lage en chatbot er generelt NLP.
Eksempler fra den virkelige verden
De siste årene har kunstig intelligens (AI) utløst en bølge av transformasjon. Det har blitt standardteknologien for alle sektorer du kan tenke deg. Kunder er villige til å samhandle med roboter hvis de implementeres riktig, noe som demonstreres av noen av de vellykkede chatbot-eksemplene og casestudiene som brukes av store bedrifter. På grunn av dette er det avgjørende for hele klientopplevelsen å implementere den riktige bot-strategien og tilpasse chatboten til å passe til din brukssituasjon.
Mange selskaper har implementert en vellykket chatbot for grunnleggende spørsmål:
Det er mange andre selskaper som har bygget chatbot, og derfor er det en god idé å ha dette prosjektet i porteføljen din.
For å komme inn på feltet Data Analytics og Data Science, er det veldig viktig å bygge en portefølje av prosjekter som vil hjelpe deg med å forstå problemløsningsprosessen og bygge en sterk sak i ditt neste intervju. I denne artikkelen diskuterte vi hvordan det å bygge et prosjekt er avgjørende for å få relevante ferdigheter som kreves av en dataforsker. Vi diskuterte trinnene involvert i å løse et datavitenskapelig problem; Problemdefinisjon, datainnsamling, utforskende dataanalyse, modellbygging og datavisualisering og historiefortelling.
Du kan bli utstyrt med alle disse ferdighetene bare ved praktisk erfaring ved å jobbe med prosjekter. Vi har også diskutert noen virkelige prosjektideer som du kan jobbe med og hvordan bedrifter utnytter det i dagens verden. På StrataScratch, kan du jobbe med små prosjekter som ble gitt av mange selskaper som ta hjemmeoppgaver. Så med det, start praksisen med et smell og gjør porteføljen klar før neste intervju.
Nate Rosidi er dataviter og innen produktstrategi. Han er også adjungert professor som underviser i analyse, og er grunnleggeren av StrataScratch, en plattform som hjelper dataforskere med å forberede seg til intervjuene sine med ekte intervjuspørsmål fra toppbedrifter. Ta kontakt med ham Twitter: StrataScratch or Linkedin.
- Myntsmart. Europas beste Bitcoin og Crypto Exchange.Klikk her
- Platoblokkkjede. Web3 Metaverse Intelligence. Kunnskap forsterket. Tilgang her.
- kilde: https://www.kdnuggets.com/2022/11/data-science-projects-help-solve-real-world-problems.html?utm_source=rss&utm_medium=rss&utm_campaign=data-science-projects-that-can-help-you-solve-real-world-problems

