Introduksjon
Retrieval Augmented-Generation (RAG) har tatt verden av Storm helt siden starten. RAG er det som er nødvendig for at de store språkmodellene (LLMs) skal kunne gi eller generere nøyaktige og saklige svar. Vi løser fakta om LLM-er av RAG, hvor vi prøver å gi LLM en kontekst som er kontekstuelt lik brukerspørringen, slik at LLM-en vil jobbe med denne konteksten og generere et faktisk korrekt svar. Vi gjør dette ved å representere våre data og brukersøk i form av vektorinnbygginger og utføre en cosinuslikhet. Men problemet er at alle de tradisjonelle tilnærmingene representerer dataene i en enkelt innebygging, noe som kanskje ikke er ideelt for godt gjenfinningssystemer. I denne guiden skal vi se nærmere på ColBERT som utfører gjenfinning med bedre nøyaktighet enn tradisjonelle bi-encoder-modeller.
Læringsmål
- Forstå hvordan henting i RAG fungerer på et høyt nivå.
- Forstå begrensninger for enkeltinnbygging ved henting.
- Forbedre gjenfinningskonteksten med ColBERTs token-innbygginger.
- Finn ut hvordan ColBERTs sene interaksjon forbedrer henting.
- Bli kjent med hvordan du jobber med ColBERT for nøyaktig henting.
Denne artikkelen ble publisert som en del av Data Science Blogathon.
Innholdsfortegnelse
Hva er RAG?
LLM-er, selv om de er i stand til å generere tekst som er både meningsfulle og grammatisk korrekte, lider av et problem som kalles hallusinasjoner. Hallusinasjoner i LLM-er er konseptet der LLM-ene selvsikkert genererer feil svar, det vil si at de lager feil svar på en måte som får oss til å tro at det er sant. Dette har vært et stort problem siden introduksjonen av LLM-ene. Disse hallusinasjonene fører til feil og faktisk feil svar. Derfor ble Retrieval Augmented Generation introdusert.
I RAG tar vi en liste over dokumenter/biter av dokumenter og koder disse tekstdokumentene til en numerisk representasjon kalt vektorinnbygging, der en enkelt vektorinnbygging representerer en enkelt del av dokumentet og lagrer dem i en database kalt vektor butikk. Modellene som kreves for å kode disse bitene til innbygginger kalles kodingsmodeller eller bi-kodere. Disse koderne er trent på et stort datakorpus, og gjør dem dermed kraftige nok til å kode bitene av dokumenter i en enkelt vektorinnbyggingsrepresentasjon.
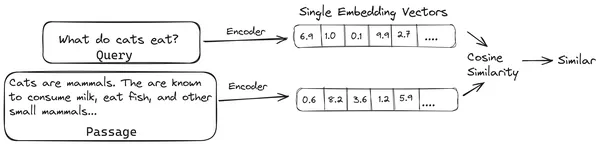
Nå når en bruker spør en spørring til LLM, så gir vi denne spørringen til den samme koderen for å produsere en enkelt vektorinnbygging. Denne innebyggingen brukes deretter til å beregne likhetspoeng med forskjellige andre vektorinnbygginger av dokumentbitene for å få den mest relevante delen av dokumentet. Den mest relevante delen eller en liste over de mest relevante delene sammen med brukerforespørselen blir gitt til LLM. LLM mottar deretter denne ekstra kontekstuelle informasjonen og genererer deretter et svar som er på linje med konteksten mottatt fra brukerspørringen. Dette sikrer at det genererte innholdet av LLM er saklig og noe som kan spores tilbake om nødvendig.
Problemet med tradisjonelle bi-kodere
Problemet med tradisjonelle Encoder-modeller som all-miniLM, OpenAI innebyggingsmodell og andre kodermodeller er at de komprimerer hele teksten til en enkelt vektorinnbyggingsrepresentasjon. Disse enkeltvektorrepresentasjonene er nyttige fordi de hjelper til med effektiv og rask henting av lignende dokumenter. Problemet ligger imidlertid i kontekstualiteten mellom spørringen og dokumentet. Enkeltvektorinnbyggingen er kanskje ikke tilstrekkelig til å lagre den kontekstuelle informasjonen til en dokumentdel, og skaper dermed en informasjonsflaskehals.
Tenk deg at 500 ord blir komprimert til en enkelt vektor med størrelse 782. Det er kanskje ikke tilstrekkelig å representere en slik del med en enkelt vektorinnbygging, og dermed gi subpar resultater i gjenfinning i de fleste tilfellene. Enkeltvektorrepresentasjonen kan også mislykkes i tilfeller med komplekse spørringer eller dokumenter. En slik løsning ville være å representere dokumentbiten eller en spørring som en liste over innebygde vektorer i stedet for en enkelt innebyggingsvektor, det er her ColBERT kommer inn.
Hva er ColBERT?
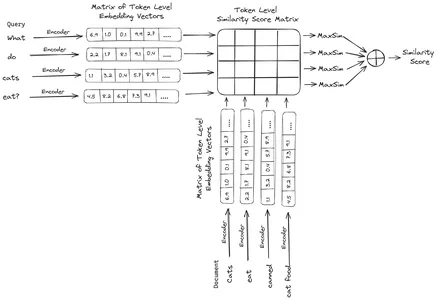
ColBERT (Contextual Late Interactions BERT) er en bi-koder som representerer tekst i en multi-vektor innebygd representasjon. Den tar inn en spørring eller en del av et dokument / et lite dokument og lager vektorinnbygginger på tokennivå. Det vil si at hvert token får sin egen vektorinnbygging, og spørringen/dokumentet er kodet til en liste over vektorinnbygginger på tokennivå. Embeddings på tokennivå er generert fra en forhåndstrent BERTI modell derav navnet BERT.
Disse lagres så i vektordatabasen. Nå, når en spørring kommer inn, opprettes en liste over innebygginger på tokennivå for den, og deretter utføres en matrisemultiplikasjon mellom brukerspørringen og hvert dokument, noe som resulterer i en matrise som inneholder likhetspoeng. Den generelle likheten oppnås ved å ta summen av maksimal likhet på tvers av dokumenttokenene for hvert spørringstoken. Formelen for dette kan sees på bildet nedenfor:
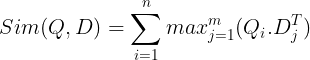
Her i ligningen ovenfor ser vi at vi gjør et punktprodukt mellom Query Tokens-matrisen (som inneholder N token-nivå-vektor-innbygginger) og Transpose of Document Tokens-matrisen (som inneholder M-token-nivå vektor-innbygginger), og så tar vi den maksimale likheten kryss dokumentsymbolene for hvert spørringstoken. Deretter tar vi summen av alle disse maksimale likhetene, som gir oss den endelige likhetspoengsummen mellom dokumentet og spørringen. Grunnen til at dette gir effektiv og nøyaktig gjenfinning er at vi her har en token-nivå interaksjon, som gir rom for mer kontekstuell forståelse mellom spørringen og dokumentet.
Hvorfor navnet ColBERT?
Ettersom vi beregner listen over innebygde vektorer før seg selv og bare utfører denne MaxSim-operasjonen (maksimal likhet) under modellslutningen, og dermed kaller det et sent interaksjonstrinn, og ettersom vi får mer kontekstuell informasjon gjennom interaksjoner på tokennivå, kalles det kontekstuelt. sene interaksjoner. Dermed navnet Contextual Late Interactions BERTI eller ColBERT. Disse beregningene kan utføres parallelt, og derfor kan de beregnes effektivt. Til slutt er en bekymring plassen, det vil si at det krever mye plass å lagre denne listen over vektorinnbygginger på symbolnivå. Dette problemet ble løst i ColBERTv2, der innebyggingene komprimeres gjennom teknikken som kalles restkompresjon, og dermed optimalisere plassen som brukes.
Hands-On ColBERT med eksempel
I denne delen vil vi komme i gang med ColBERT og til og med sjekke hvordan den presterer mot en vanlig innebyggingsmodell.
Trinn 1: Last ned biblioteker
Vi starter med å laste ned følgende bibliotek:
!pip install ragatouille langchain langchain_openai chromadb einops sentence-transformers tiktoken- RAGatouille: Dette biblioteket lar oss jobbe med avanserte (SOTA) gjenfinningsmetoder som ColBERT på en brukervennlig måte. Det gir muligheter for å lage indekser over datasettene, spørre etter dem, og til og med tillate oss å trene en ColBERT-modell på dataene våre.
- Langkjede: Dette biblioteket lar oss jobbe med open source-innbyggingsmodellene slik at vi kan teste hvor godt de andre innbyggingsmodellene fungerer sammenlignet med ColBERT.
- langchain_openai: Installerer Langkjede avhengigheter for OpenAI. Vi vil til og med jobbe med OpenAI Embedding-modellen for å sjekke ytelsen mot ColBERT.
- ChromaDB: Dette biblioteket lar oss lage et vektorlager i miljøet vårt slik at vi kan lagre innebyggingene vi har laget på dataene våre og senere utføre et semantisk søk mellom spørringen og de lagrede innebyggingene.
- einops: Dette biblioteket er nødvendig for effektive tensormatrisemultiplikasjoner.
- setningstransformatorer og tiktoken bibliotek er nødvendig for at open source-innbyggingsmodellene skal fungere skikkelig.
Trinn 2: Last ned forhåndsopplært modell
I neste trinn skal vi laste ned den ferdigtrente ColBERT-modellen. For dette vil koden være
from ragatouille import RAGPretrainedModel
RAG = RAGPretrainedModel.from_pretrained("colbert-ir/colbertv2.0")- Vi importerer først RAGPretrainedModel-klassen fra RAGatouille-biblioteket.
- Deretter kaller vi .from_pretrained() og gir modellnavnet, dvs. "colbert-ir/colbertv2.0".
Å kjøre koden ovenfor vil instansiere en ColBERT RAG-modell. La oss nå laste ned en Wikipedia-side og utføre henting fra den. For dette vil koden være:
from ragatouille.utils import get_wikipedia_page
document = get_wikipedia_page("Elon_Musk")
print("Word Count:",len(document))
print(document[:1000])RAGatouille kommer med en hendig funksjon kalt get_wikipedia_page som tar inn en streng og får den tilsvarende Wikipedia-siden. Her laster vi ned Wikipedia-innholdet på Elon Musk og lagrer det i variabeldokumentet. La oss skrive ut antall ord i dokumentet og de første linjene i dokumentet.
Her kan vi se resultatet på bildet. Vi kan se at det er totalt 64,668 XNUMX ord på Wikipedia-siden til Elon Musk.
Trinn 3: Indeksering
Nå skal vi lage en indeks på dette dokumentet.
RAG.index(
# List of Documents
collection=[document],
# List of IDs for the above Documents
document_ids=['elon_musk'],
# List of Dictionaries for the metadata for the above Documents
document_metadatas=[{"entity": "person", "source": "wikipedia"}],
# Name of the index
index_name="Elon2",
# Chunk Size of the Document Chunks
max_document_length=256,
# Wether to Split Document or Not
split_documents=True
)Her kaller vi .index() til RAG for å indeksere dokumentet vårt. Til dette sender vi følgende:
- samling: Dette er en liste over dokumenter som vi ønsker å indeksere. Her har vi bare ett dokument, derav en liste over et enkelt dokument.
- document_ID: Hvert dokument forventer en unik dokument-ID. Her gir vi det navnet elon_musk fordi dokumentet handler om Elon Musk.
- document_metadatas: Hvert dokument har sine metadata. Dette er igjen en liste over ordbøker, der hver ordbok inneholder et nøkkelverdi-par metadata for et bestemt dokument.
- indeksnavn: Navnet på indeksen vi oppretter. La oss gi den navnet Elon2.
- max_document_size: Dette ligner på chunk-størrelsen. Vi spesifiserer hvor mye hver dokumentdel skal være. Her gir vi den en verdi på 256. Hvis vi ikke spesifiserer noen verdi, vil 256 bli tatt som standard chunk-størrelse.
- split_documents: Det er en boolsk verdi, der True indikerer at vi ønsker å dele opp dokumentet vårt i henhold til den gitte delstørrelsen, og False indikerer at vi ønsker å lagre hele dokumentet som en enkelt del.
Å kjøre koden ovenfor vil dele opp dokumentet vårt i størrelser på 256 per del, og deretter bygge dem inn gjennom ColBERT-modellen, som vil produsere en liste over token-nivå vektorinnbygginger for hver del og til slutt lagre dem i en indeks. Dette trinnet vil ta litt tid å kjøre og kan akselereres hvis du har en GPU. Til slutt oppretter den en katalog der indeksen vår er lagret. Her vil katalogen være ".ragatouille/colbert/indexes/Elon2"
Trinn 4: Generell spørring
Nå starter vi søket. For dette vil koden være
results = RAG.search(query="What companies did Elon Musk find?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc["content"])- Her kaller vi først .search()-metoden til RAG-objektet
- Til dette gir vi variablene som inkluderer søkenavnet, k (antall dokumenter som skal hentes) og indeksnavnet som skal søkes
- Her gir vi spørringen "Hvilke selskaper fant Elon Musk?". Resultatet som oppnås vil være i en liste med ordbokformat, som inneholder nøklene som innhold, poengsum, rangering, document_id, passage_id og document_metadata
- Derfor jobber vi med koden nedenfor for å skrive ut de hentede dokumentene på en ryddig måte
- Her går vi gjennom listen over ordbøker og skriver ut innholdet i dokumentene
Å kjøre koden vil gi følgende resultater:
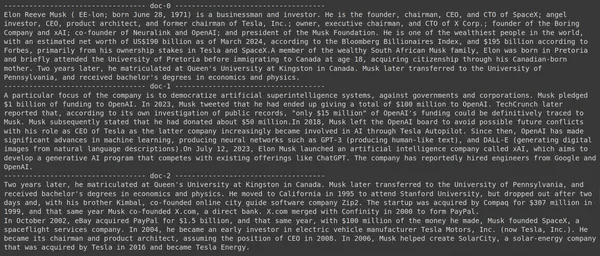
På bildet kan vi se at det første og siste dokumentet i sin helhet dekker de forskjellige selskapene grunnlagt av Elon Musk. ColBERT var i stand til å hente de relevante delene som var nødvendige for å svare på spørringen.
Trinn 5: Spesifikk spørring
La oss nå gå et skritt videre og stille et spesifikt spørsmål.
results = RAG.search(query="How much Tesla stocks did Elon sold in
Decemeber 2022?", k=3, index_name='Elon2')
for i, doc, in enumerate(results):
print(f"---------------
------------------- doc-{i} ------------------------------------")
print(doc["content"])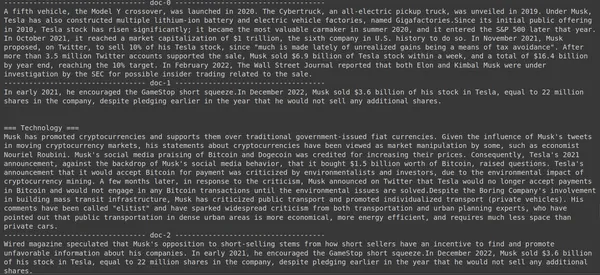
Her i koden ovenfor stiller vi et veldig spesifikt spørsmål om hvor mange aksjer verdt av Tesla Elon solgt i desember 2022. Vi kan se resultatet her. Dok-1 inneholder svaret på spørsmålet. Elon har solgt for 3.6 milliarder dollar av aksjene sine i Tesla. Igjen var ColBERT i stand til å hente den relevante delen for den gitte spørringen.
Trinn 6: Testing av andre modeller
La oss nå prøve det samme spørsmålet med de andre innebyggingsmodellene både åpen kildekode og lukket her:
from langchain_community.embeddings import HuggingFaceEmbeddings
from transformers import AutoModel
model = AutoModel.from_pretrained('jinaai/jina-embeddings-v2-base-en', trust_remote_code=True)
model_name = "jinaai/jina-embeddings-v2-base-en"
model_kwargs = {'device': 'cpu'}
embeddings = HuggingFaceEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
)
- Vi starter med å laste ned modellen først gjennom AutoModel-klassen fra Transformers-biblioteket.
- Deretter lagrer vi model_name og model_kwargs i deres respektive variabler.
- Nå for å jobbe med denne modellen i LangChain, importerer vi HuggingFaceEmbeddings fra Langkjede og gi den modellnavnet og model_kwargs.
Å kjøre denne koden vil laste ned og laste inn Jina-innbyggingsmodellen slik at vi kan jobbe med den
Trinn 7: Opprett innebygginger
Nå må vi begynne å dele opp dokumentet vårt og deretter lage embeddings ut av det og lagre dem i Chroma vektorlageret. For dette jobber vi med følgende kode:
from langchain_community.vectorstores import Chroma
from langchain_text_splitters import RecursiveCharacterTextSplitter
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
chunk_size=256,
chunk_overlap=0)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})- Vi starter med å importere Chroma og RecursiveCharacterTextSplitter fra LangChain-biblioteket
- Deretter instansierer vi en text_splitter ved å kalle .from_tiktoken_encoder til RecursiveCharacterTextSplitter og gi den chunk_size og chunk_overlap
- Her vil vi bruke samme chunk_size som vi har gitt til ColBERT
- Deretter kaller vi .split_text()-metoden til denne text_splitteren og gir den dokumentet som inneholder Wikipedia-informasjon om Elon Musk. Deretter deler den opp dokumentet basert på den gitte delstørrelsen, og til slutt lagres listen over dokumentbiter i variabeldelingene
- Til slutt kaller vi funksjonen .from_texts() til Chroma-klassen for å lage et vektorlager. Til denne funksjonen gir vi delingene, innebyggingsmodellen og samlingsnavnet
- Nå lager vi en retriever ut av den ved å kalle .as_retriever()-funksjonen til vektorlagerobjektet. Vi gir 3 for k-verdien
Å kjøre denne koden vil ta dokumentet vårt, dele det opp i mindre dokumenter med størrelse 256 per del, og deretter bygge inn disse mindre delene med Jina-innbyggingsmodellen og lagre disse innbyggingsvektorene i chroma-vektorlageret.
Trinn 8: Opprette en Retriever
Til slutt lager vi en retriever fra den. Nå skal vi utføre et vektorsøk og sjekke resultatene.
docs = retriever.get_relevant_documents("What companies did Elon Musk find?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)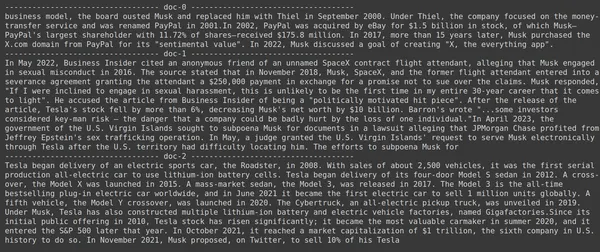
- Vi kaller funksjonen .get_relevent_documents() til retrieverobjektet og gir det samme spørring.
- Deretter skriver vi pent ut de 3 beste hentede dokumentene.
- På bildet kan vi se at Jina Embedder til tross for at den er en populær innebyggingsmodell, er gjenfinningen for søket vårt dårlig. Det lyktes ikke å få de riktige dokumentbitene.
Vi kan tydelig se forskjellen mellom Jina, embedding-modellen som representerer hver del som en enkelt vektor-innbygging, og ColBERT-modellen som representerer hver del som en liste over token-nivå innebyggingsvektorer. ColBERT overgår klart i dette tilfellet.
Trinn 9: Testing av OpenAIs innebyggingsmodell
La oss nå prøve å bruke en innebygd modell med lukket kilde, som OpenAI Embedding-modellen.
import os
os.environ["OPENAI_API_KEY"] = "Your API Key"
from langchain_openai import OpenAIEmbeddings
embeddings = OpenAIEmbeddings()
text_splitter = RecursiveCharacterTextSplitter.from_tiktoken_encoder(
model_name = "gpt-4",
chunk_size = 256,
chunk_overlap = 0,
)
splits = text_splitter.split_text(document)
vectorstore = Chroma.from_texts(texts=splits,
embedding=embeddings,
collection_name="elon_collection")
retriever = vectorstore.as_retriever(search_kwargs = {'k':3})Her er koden veldig lik den vi nettopp har skrevet
- Den eneste forskjellen er at vi sender inn OpenAI API-nøkkelen for å angi miljøvariabelen.
- Vi lager deretter en forekomst av OpenAI Embedding-modellen ved å importere den fra LangChain.
- Og mens vi lager samlingsnavnet, gir vi et annet samlingsnavn, slik at innbyggingene fra OpenAI Embedding-modellen lagres i en annen samling.
Å kjøre denne koden vil igjen ta dokumentene våre, dele dem inn i mindre dokumenter av størrelse 256, og deretter bygge dem inn i enkeltvektor-innbyggingsrepresentasjon med OpenAI-innbyggingsmodellen og til slutt lagre disse innebyggingene i Chroma Vector Store. La oss nå prøve å hente de relevante dokumentene til det andre spørsmålet.
docs = retriever.get_relevant_documents("How much Tesla stocks did Elon sold in Decemeber 2022?",)
for i, doc in enumerate(docs):
print(f"---------------------------------- doc-{i} ------------------------------------")
print(doc.page_content)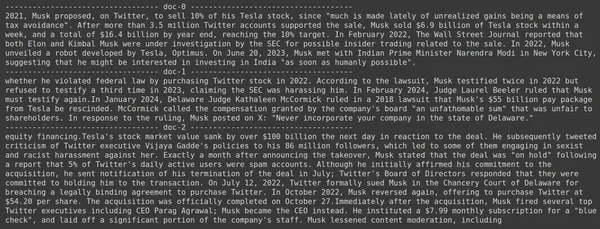
- Vi ser at svaret vi forventer ikke finnes innenfor de hentede delene.
- Den delen inneholder informasjon om Tesla-aksjer i 2022, men snakker ikke om at Elon skal selge dem.
- Det samme kan sees med de resterende to dokumentbitene, der informasjonen de inneholder handler om Tesla og dens aksjer, men dette er ikke informasjonen vi forventer.
- De ovennevnte delene vil ikke gi konteksten for LLM for å svare på spørsmålet vi har gitt.
Selv her kan vi se en klar forskjell mellom en-vektor-innbyggingsrepresentasjonen vs multi-vektor-innbyggingsrepresentasjonen. Multi-embedding-representasjonene fanger tydelig opp de komplekse spørringene som resulterer i mer nøyaktige henting.
konklusjonen
Avslutningsvis demonstrerer ColBERT et betydelig fremskritt i gjenfinningsytelse i forhold til tradisjonelle bi-encoder-modeller ved å representere tekst som multi-vektor-innbygging på token-nivå. Denne tilnærmingen tillater mer nyansert kontekstuell forståelse mellom spørsmål og dokumenter, noe som fører til mer nøyaktige gjenfinningsresultater og reduserer problemet med hallusinasjoner som ofte observeres i LLM-er.
Nøkkelfunksjoner
- RAG adresserer problemet med hallusinasjoner i LLM-er ved å gi kontekstuell informasjon for generering av faktiske svar.
- Tradisjonelle bi-kodere lider av en informasjonsflaskehals på grunn av komprimering av hele tekster til enkeltvektor-innbygginger, noe som resulterer i subpar innhentingsnøyaktighet.
- ColBERT, med sin innebygde representasjon på tokennivå, letter bedre kontekstuell forståelse mellom spørringer og dokumenter, noe som fører til forbedret gjenfinningsytelse.
- Det sene interaksjonstrinnet i ColBERT, kombinert med token-nivå interaksjoner, forbedrer gjenfinningsnøyaktigheten ved å vurdere kontekstuelle nyanser.
- ColBERTv2 optimerer lagringsplass gjennom gjenværende komprimering samtidig som hentingseffektiviteten opprettholdes.
- Praktiske eksperimenter demonstrerer ColBERTs overlegenhet i gjenfinningsytelse sammenlignet med tradisjonelle og åpen kildekode-innbyggingsmodeller som Jina og OpenAI Embedding.
Ofte Stilte Spørsmål
A. Tradisjonelle bi-kodere komprimerer hele tekster til enkeltvektorinnbygginger, og mister potensielt kontekstuell informasjon. Dette begrenser deres effektivitet i gjenfinningsoppgaver, spesielt med komplekse forespørsler eller dokumenter.
A. ColBERT (Contextual Late Interactions BERT) er en bi-koder-modell som representerer tekst ved bruk av token-nivå vektorinnbygginger. Det gir mulighet for mer nyansert kontekstuell forståelse mellom spørringer og dokumenter, og forbedrer gjenfinningsnøyaktigheten.
A. ColBERT genererer embeddings på tokennivå for spørringer og dokumenter, utfører matrisemultiplikasjon for å beregne likhetspoeng, og velger deretter den mest relevante informasjonen basert på maksimal likhet på tvers av tokens. Dette gir mulighet for effektiv gjenfinning med kontekstuell forståelse.
A. ColBERTv2 optimerer plass gjennom restkompresjonsmetoden, og reduserer lagringskravene for embeddings på token-nivå samtidig som gjenfinningsnøyaktigheten opprettholdes.
A. Du kan bruke biblioteker som RAGatouille for å jobbe med ColBERT enkelt. Ved å indeksere dokumenter og spørringer kan du utføre effektive gjenfinningsoppgaver og generere nøyaktige svar tilpasset konteksten.
Mediene vist i denne artikkelen eies ikke av Analytics Vidhya og brukes etter forfatterens skjønn.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.analyticsvidhya.com/blog/2024/04/colbert-improve-retrieval-performance-with-token-level-vector-embeddings/

