For å bygge en generativ AI-applikasjon er det avgjørende å berike de store språkmodellene (LLM) med nye data. Det er her Retrieval Augmented Generation (RAG)-teknikken kommer inn. RAG er en maskinlæringsarkitektur (ML) som bruker eksterne dokumenter (som Wikipedia) for å øke kunnskapen og oppnå toppmoderne resultater på kunnskapsintensive oppgaver . For inntak av disse eksterne datakildene har Vector-databaser utviklet seg, som kan lagre vektorinnbygginger av datakilden og tillate likhetssøk.
I dette innlegget viser vi hvordan du bygger en RAG-ekstrakt, transformerer og laster (ETL) inntakspipeline for å innta store mengder data til en Amazon OpenSearch-tjeneste klynge og bruk Amazon Relational Database Service (Amazon RDS) for PostgreSQL med pgvector-utvidelsen som et vektordatalager. Hver tjeneste implementerer k-nærmeste nabo (k-NN) eller tilnærmet nærmeste nabo (ANN) algoritmer og avstandsmålinger for å beregne likhet. Vi introduserer integrering av Ray inn i RAG kontekstuelle dokumentinnhentingsmekanisme. Ray er et distribuert databibliotek med åpen kildekode, Python, generellt formål. Den tillater distribuert databehandling å generere og lagre innebygginger for en stor mengde data, parallelt på tvers av flere GPUer. Vi bruker en Ray-klynge med disse GPU-ene for å kjøre parallell inntak og spørring for hver tjeneste.
I dette eksperimentet prøver vi å analysere følgende aspekter for OpenSearch Service og pgvector-utvidelsen på Amazon RDS:
- Som en vektorbutikk, muligheten til å skalere og håndtere et stort datasett med titalls millioner poster for RAG
- Mulige flaskehalser i inntaksrørledningen for RAG
- Hvordan oppnå optimal ytelse i inntak og henting av spørringer for OpenSearch Service og Amazon RDS
For å forstå mer om vektordatalagre og deres rolle i å bygge generative AI-applikasjoner, se Rollen til vektordatalagre i generative AI-applikasjoner.
Oversikt over OpenSearch Service
OpenSearch Service er en administrert tjeneste for sikker analyse, søk og indeksering av forretnings- og driftsdata. OpenSearch Service støtter petabyte-skaladata med muligheten til å lage flere indekser på tekst- og vektordata. Med optimalisert konfigurasjon tar den sikte på høy tilbakekalling for spørringene. OpenSearch Service støtter ANN så vel som eksakt k-NN-søk. OpenSearch Service støtter et utvalg av algoritmer fra NMSLIB, FAISSog Lucene biblioteker for å drive k-NN-søket. Vi opprettet ANN-indeksen for OpenSearch med algoritmen Hierarchical Navigable Small World (HNSW) fordi den anses som en bedre søkemetode for store datasett. For mer informasjon om valg av indeksalgoritme, se Velg k-NN-algoritmen for milliardskalaen din med OpenSearch.
Oversikt over Amazon RDS for PostgreSQL med pgvector
Pgvector-utvidelsen legger til et åpen kildekode-vektorlikhetssøk til PostgreSQL. Ved å bruke pgvector-utvidelsen kan PostgreSQL utføre likhetssøk på vektorinnbygginger, noe som gir bedrifter en rask og dyktig løsning. pgvector gir to typer vektorlikhetssøk: eksakt nærmeste nabo, som resulterer med 100 % tilbakekalling, og omtrentlig nærmeste nabo (ANN), som gir bedre ytelse enn eksakt søk med en avveining ved tilbakekalling. For søk over en indeks kan du velge hvor mange sentre som skal brukes i søket, med flere sentre som gir bedre tilbakekalling med en avveining av ytelse.
Løsningsoversikt
Følgende diagram illustrerer løsningsarkitekturen.

La oss se på nøkkelkomponentene mer detaljert.
datasett
Vi bruker OSCAR-data som vårt korpus og SQUAD-datasettet for å gi eksempler på spørsmål. Disse datasettene konverteres først til Parkett-filer. Deretter bruker vi en Ray-klynge for å konvertere Parkett-dataene til innbygginger. De opprettede innebyggingene tas inn til OpenSearch Service og Amazon RDS med pgvector.
OSCAR (Open Super-large Crawled Aggregated corpus) er et stort flerspråklig korpus oppnådd ved språkklassifisering og filtrering av Vanlig gjennomgang korpus ved hjelp av ugudelig arkitektur. Data distribueres etter språk i både original og deduplisert form. Oscar Corpus-datasettet er på omtrent 609 millioner poster og tar opp omtrent 4.5 TB som rå JSONL-filer. JSONL-filene konverteres deretter til parkettformat, som minimerer den totale størrelsen til 1.8 TB. Vi skalert datasettet ytterligere ned til 25 millioner poster for å spare tid under inntak.
SQuAD (Stanford Question Answering Dataset) er et leseforståelsesdatasett som består av spørsmål stilt av publikumsarbeidere på et sett med Wikipedia-artikler, der svaret på hvert spørsmål er et tekstsegment, eller span, fra tilsvarende lesepassasje, eller spørsmålet kan være ubesvart. Vi bruker SQUAD, lisensiert som CC-BY-SA 4.0, for å gi eksempler på spørsmål. Den har omtrent 100,000 50,000 spørsmål med over XNUMX XNUMX ubesvarbare spørsmål skrevet av publikumsarbeidere for å se ut som svarbare.
Stråleklynge for inntak og oppretting av vektorinnbygginger
I vår testing fant vi ut at GPU-ene har størst innvirkning på ytelsen når de lager innebyggingene. Derfor bestemte vi oss for å bruke en Ray-klynge for å konvertere råteksten vår og lage innbyggingene. Ray er et enhetlig datarammeverk med åpen kildekode som gjør det mulig for ML-ingeniører og Python-utviklere å skalere Python-applikasjoner og akselerere ML-arbeidsbelastninger. Vår klynge besto av 5 g4dn.12xlarge Amazon Elastic Compute Cloud (Amazon EC2) forekomster. Hver forekomst ble konfigurert med 4 NVIDIA T4 Tensor Core GPUer, 48 vCPU og 192 GiB minne. For tekstpostene våre endte vi opp med å dele hver i 1,000 stykker med en overlapping på 100 stykker. Dette bryter ut til omtrent 200 per rekord. For modellen som ble brukt til å lage embeddings, slo vi oss til ro all-mpnet-base-v2 for å lage et 768-dimensjonalt vektorrom.
Oppsett av infrastruktur
Vi brukte følgende RDS-forekomsttyper og OpenSearch-tjenesteklyngekonfigurasjoner for å konfigurere infrastrukturen vår.
Følgende er egenskapene våre for RDS-forekomsttype:
- Forekomsttype: db.r7g.12xlarge
- Tildelt lagringsplass: 20 TB
- Multi-AZ: Sant
- Lagring kryptert: Sant
- Aktiver ytelsesinnsikt: Sant
- Performance Insight-oppbevaring: 7 dager
- Lagringstype: gp3
- Avsatt IOPS: 64,000 XNUMX
- Indekstype: IVF
- Antall lister: 5,000
- Avstandsfunksjon: L2
Følgende er våre OpenSearch Service-klyngeegenskaper:
- Versjon: 2.5
- Datanoder: 10
- Datanode-forekomsttype: r6g.4xlarge
- Primære noder: 3
- Primær nodeforekomsttype: r6g.xlarge
- Indeks: HNSW-motor:
nmslib - Oppdateringsintervall: 30 sekunder
ef_construction: 256- m: 16
- Avstandsfunksjon: L2
Vi brukte store konfigurasjoner for både OpenSearch Service-klyngen og RDS-forekomster for å unngå flaskehalser i ytelsen.
Vi distribuerer løsningen ved hjelp av en AWS skyutviklingssett (AWS CDK) stable, som skissert i den følgende delen.
Distribuer AWS CDK-stakken
AWS CDK-stakken lar oss velge OpenSearch Service eller Amazon RDS for inntak av data.
Forhåndskrav
Før du fortsetter med installasjonen, under cdk, bin, src.tc, endre de boolske verdiene for Amazon RDS og OpenSearch Service til enten sant eller usant, avhengig av dine preferanser.
Du trenger også en service-linked AWS identitets- og tilgangsadministrasjon (IAM)-rolle for OpenSearch Service-domenet. For flere detaljer, se Amazon OpenSearch Service Construct Library. Du kan også kjøre følgende kommando for å opprette rollen:
Denne AWS CDK-stakken vil distribuere følgende infrastruktur:
- En VPC
- En hoppvert (inne i VPC)
- En OpenSearch-tjenesteklynge (hvis du bruker OpenSearch-tjenesten for inntak)
- En RDS-forekomst (hvis du bruker Amazon RDS for inntak)
- An AWS systemansvarlig dokument for distribusjon av Ray-klyngen
- An Amazon enkel lagringstjeneste (Amazon S3) bøtte
- An AWS Lim jobb for å konvertere OSCAR-datasettet JSONL-filer til Parkett-filer
- Amazon CloudWatch oversikter
Last ned dataene
Kjør følgende kommandoer fra hoppverten:
Før du kloner git-repoen, sørg for at du har en Hugging Face-profil og tilgang til OSCAR-datakorpuset. Du må bruke brukernavnet og passordet for å klone OSCAR-dataene:
Konverter JSONL-filer til Parkett
AWS CDK-stakken opprettet AWS Glue ETL-jobben oscar-jsonl-parquet for å konvertere OSCAR-dataene fra JSONL til Parkett-format.
Etter at du har kjørt oscar-jsonl-parquet jobb, skal filene i Parkett-format være tilgjengelig under parkettmappen i S3-bøtta.
Last ned spørsmålene
Last ned spørsmålsdataene fra hoppeverten din og last den opp til S3-bøtten din:
Sett opp Ray-klyngen
Som en del av AWS CDK-stackdistribusjonen opprettet vi et Systems Manager-dokument kalt CreateRayCluster.
For å kjøre dokumentet, fullfør følgende trinn:
- På Systems Manager-konsollen, under dokumenter Velg navigasjonsruten Eies av meg.
- Åpne
CreateRayClusterdokument. - Velg Kjør.
Kjør-kommandosiden vil ha standardverdiene fylt ut for klyngen.
Standardkonfigurasjonen ber om 5 g4dn.12xlarge. Sørg for at kontoen din har grenser for å støtte dette. Den relevante tjenestegrensen er Running On-Demand G- og VT-forekomster. Standard for dette er 64, men denne konfigurasjonen krever 240 CPUer.
- Etter at du har gått gjennom klyngekonfigurasjonen, velger du hoppverten som mål for kjørekommandoen.
Denne kommandoen vil utføre følgende trinn:
- Kopier Ray-klyngefilene
- Sett opp Ray-klyngen
- Sett opp OpenSearch Service-indeksene
- Sett opp RDS-tabellene
Du kan overvåke utdataene fra kommandoene på Systems Manager-konsollen. Denne prosessen vil ta 10–15 minutter for den første lanseringen.
Kjør inntak
Fra hoppverten kobler du til Ray-klyngen:
Første gang du kobler til verten, installer kravene. Disse filene skal allerede være til stede på hodenoden.
For en av inntaksmetodene, hvis du får en feil som følgende, er det relatert til utløpt legitimasjon. Den nåværende løsningen (i skrivende stund) er å plassere legitimasjonsfiler i Ray-hodenoden. For å unngå sikkerhetsrisikoer, ikke bruk IAM-brukere til autentisering når du utvikler spesialbygd programvare eller arbeider med ekte data. Bruk heller føderasjon med en identitetsleverandør som f.eks AWS IAM Identity Center (etterfølger til AWS Single Sign-On).
Vanligvis lagres legitimasjonen i filen ~/.aws/credentials på Linux- og macOS-systemer, og %USERPROFILE%.awscredentials på Windows, men dette er kortsiktig legitimasjon med et økttoken. Du kan heller ikke overstyre standard påloggingsfilen, og derfor må du opprette langsiktig legitimasjon uten økttoken ved å bruke en ny IAM-bruker.
For å opprette langsiktig legitimasjon, må du generere en AWS-tilgangsnøkkel og AWS-hemmelig tilgangsnøkkel. Du kan gjøre det fra IAM-konsollen. For instruksjoner, se Autentiser med IAM-brukerlegitimasjon.
Etter at du har opprettet nøklene, kobler du til hoppverten med Session Manager, en funksjon av Systems Manager, og kjør følgende kommando:
Nå kan du kjøre inntakstrinnene på nytt.
Ta inn data i OpenSearch Service
Hvis du bruker OpenSearch-tjenesten, kjør følgende skript for å innta filene:
Når det er fullført, kjør skriptet som kjører simulerte spørringer:
Ta inn data i Amazon RDS
Hvis du bruker Amazon RDS, kjør følgende skript for å innta filene:
Når den er fullført, sørg for å kjøre et fullt vakuum på RDS-forekomsten.
Kjør deretter følgende skript for å kjøre simulerte spørringer:
Sett opp Ray-dashbordet
Før du setter opp Ray-dashbordet, bør du installere AWS kommandolinjegrensesnitt (AWS CLI) på din lokale maskin. For instruksjoner, se Installer eller oppdater den nyeste versjonen av AWS CLI.
Fullfør følgende trinn for å sette opp dashbordet:
- Installer Session Manager-plugin for AWS CLI.
- I Isengard-kontoen, kopier den midlertidige legitimasjonen for bash/zsh og kjør i din lokale terminal.
- Opprett en session.sh-fil på maskinen din og kopier følgende innhold til filen:
- Endre katalogen til der denne session.sh-filen er lagret.
- Kjør kommandoen
Chmod +xfor å gi kjørbar tillatelse til filen. - Kjør følgende kommando:
For eksempel:
Du vil se en melding som følgende:
Åpne en ny fane i nettleseren din og skriv inn localhost:8265.
Du vil se Ray-dashbordet og statistikk over jobbene og klyngen som kjører. Du kan spore beregninger herfra.
Du kan for eksempel bruke Ray-dashbordet til å observere belastningen på klyngen. Som vist i følgende skjermbilde, under inntak, kjører GPU-ene nær 100 % utnyttelse.
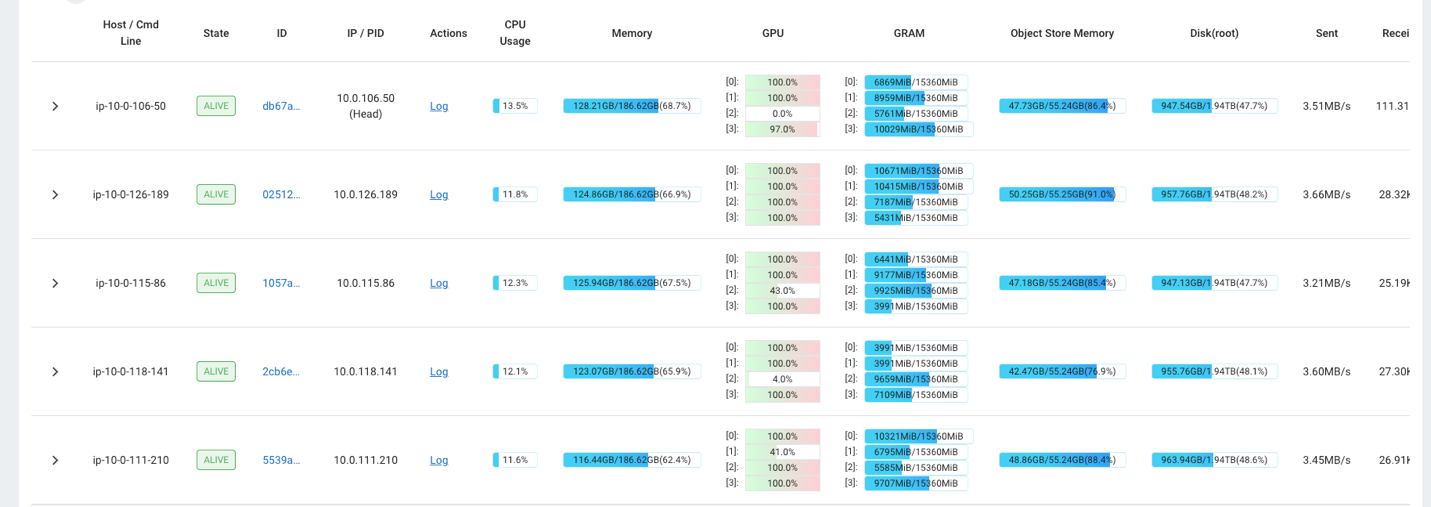
Du kan også bruke RAG_Benchmarks CloudWatch-dashbordet for å se inntaksfrekvensen og responstidene for spørringene.
Utvidbarhet av løsningen
Du kan utvide denne løsningen til å koble til andre AWS eller tredjeparts vektorbutikker. For hvert nytt vektorlager må du lage skript for å konfigurere datalageret samt inntak av data. Resten av rørledningen kan gjenbrukes etter behov.
konklusjonen
I dette innlegget delte vi en ETL-pipeline som du kan bruke til å legge vektoriserte RAG-data i både OpenSearch Service så vel som Amazon RDS med pgvector-utvidelsen som vektordatalagre. Løsningen brukte en Ray-klynge for å gi den nødvendige parallelliteten for å innta et stort datakorpus. Du kan bruke denne metodikken til å integrere hvilken som helst vektordatabase for å bygge RAG-rørledninger.
Om forfatterne
 Randy DeFauw er Senior Principal Solutions Architect hos AWS. Han har en MSEE fra University of Michigan, hvor han jobbet med datasyn for autonome kjøretøy. Han har også en MBA fra Colorado State University. Randy har hatt en rekke stillinger innen teknologiområdet, alt fra programvareutvikling til produktadministrasjon. Han gikk inn i big data-området i 2013 og fortsetter å utforske det området. Han jobber aktivt med prosjekter i ML-området og har presentert på en rekke konferanser, inkludert Strata og GlueCon.
Randy DeFauw er Senior Principal Solutions Architect hos AWS. Han har en MSEE fra University of Michigan, hvor han jobbet med datasyn for autonome kjøretøy. Han har også en MBA fra Colorado State University. Randy har hatt en rekke stillinger innen teknologiområdet, alt fra programvareutvikling til produktadministrasjon. Han gikk inn i big data-området i 2013 og fortsetter å utforske det området. Han jobber aktivt med prosjekter i ML-området og har presentert på en rekke konferanser, inkludert Strata og GlueCon.
 David Christian er en hovedløsningsarkitekt basert i Sør-California. Han har sin bachelor i informasjonssikkerhet og en lidenskap for automatisering. Fokusområdene hans er DevOps-kultur og transformasjon, infrastruktur som kode og robusthet. Før han begynte i AWS, hadde han roller innen sikkerhet, DevOps og systemutvikling, og administrerte store private og offentlige skymiljøer.
David Christian er en hovedløsningsarkitekt basert i Sør-California. Han har sin bachelor i informasjonssikkerhet og en lidenskap for automatisering. Fokusområdene hans er DevOps-kultur og transformasjon, infrastruktur som kode og robusthet. Før han begynte i AWS, hadde han roller innen sikkerhet, DevOps og systemutvikling, og administrerte store private og offentlige skymiljøer.
 Prachi Kulkarni er Senior Solutions Architect hos AWS. Spesialiseringen hennes er maskinlæring, og hun jobber aktivt med å designe løsninger ved hjelp av ulike AWS ML-, big data- og analysetilbud. Prachi har erfaring innen flere domener, inkludert helsetjenester, fordeler, detaljhandel og utdanning, og har jobbet i en rekke stillinger innen produktteknikk og arkitektur, ledelse og kundesuksess.
Prachi Kulkarni er Senior Solutions Architect hos AWS. Spesialiseringen hennes er maskinlæring, og hun jobber aktivt med å designe løsninger ved hjelp av ulike AWS ML-, big data- og analysetilbud. Prachi har erfaring innen flere domener, inkludert helsetjenester, fordeler, detaljhandel og utdanning, og har jobbet i en rekke stillinger innen produktteknikk og arkitektur, ledelse og kundesuksess.
 Richa Gupta er løsningsarkitekt hos AWS. Hun brenner for å bygge ende-til-ende-løsninger for kunder. Hennes spesialisering er maskinlæring og hvordan den kan brukes til å bygge nye løsninger som fører til operasjonell fortreffelighet og genererer forretningsinntekter. Før hun begynte i AWS, jobbet hun i egenskap av programvareingeniør og løsningsarkitekt, og bygde løsninger for store teleoperatører. Utenom jobben liker hun å utforske nye steder og elsker eventyrlige aktiviteter.
Richa Gupta er løsningsarkitekt hos AWS. Hun brenner for å bygge ende-til-ende-løsninger for kunder. Hennes spesialisering er maskinlæring og hvordan den kan brukes til å bygge nye løsninger som fører til operasjonell fortreffelighet og genererer forretningsinntekter. Før hun begynte i AWS, jobbet hun i egenskap av programvareingeniør og løsningsarkitekt, og bygde løsninger for store teleoperatører. Utenom jobben liker hun å utforske nye steder og elsker eventyrlige aktiviteter.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/build-a-rag-data-ingestion-pipeline-for-large-scale-ml-workloads/

