Introduksjon
Store språkmodeller (LLM) er fremtredende innovasjonspilarer i det stadig utviklende landskapet med kunstig intelligens. Disse modellene, som GPT-3, har vist frem imponerende naturlig språkbehandling og innholdsgenereringsmuligheter. Likevel krever å utnytte deres fulle potensiale å forstå deres intrikate virkemåter og bruke effektive teknikker, som finjustering, for å optimalisere ytelsen deres.
Som en dataforsker med en forkjærlighet for å grave i dybden av LLM-forskning, har jeg begitt meg ut på en reise for å avdekke triksene og strategiene som får disse modellene til å skinne. I denne artikkelen vil jeg lede deg gjennom noen viktige aspekter ved å lage data av høy kvalitet for LLM-er, bygge effektive modeller og maksimere deres nytte i virkelige applikasjoner.

Læringsmål:
- Forstå den lagdelte tilnærmingen til LLM-bruk, fra grunnleggende modeller til spesialiserte agenter.
- Lær om sikkerhet, forsterkende læring og kobling av LLM-er med databaser.
- Utforsk "LIMA", "Distil" og spørsmål-svar-teknikker for sammenhengende svar.
- Ta tak i avansert finjustering med modeller som "phi-1" og kjenn fordelene.
- Lær om skaleringslover, bias reduksjon, og takle modelltendenser.
Innholdsfortegnelse
Bygge effektive LLM-er: tilnærminger og teknikker
Når du fordyper deg i LLM-er, er det viktig å gjenkjenne stadiene i søknaden deres. For meg danner disse stadiene en kunnskapspyramide, der hvert lag bygger på det tidligere. De grunnleggende modell er grunnfjellet – det er modellen som utmerker seg ved å forutsi neste ord, i likhet med smarttelefonens prediktive tastatur.
Magien skjer når du tar den grunnleggende modellen og finjusterer den ved å bruke data som er relevante for oppgaven din. Det er her chat-modeller kommer inn i bildet. Ved å trene modellen på chat-samtaler eller lærerike eksempler, kan du lokke den til å vise chatbot-lignende oppførsel, som er et kraftig verktøy for ulike applikasjoner.
Sikkerhet er viktig, spesielt siden internett kan være et ganske ufint sted. Det neste trinnet innebærer Forsterkning Lær fra menneskelig tilbakemelding (RLHF). Dette stadiet justerer modellens oppførsel med menneskelige verdier og sikrer den mot å levere upassende eller unøyaktige svar.
Når vi beveger oss lenger opp i pyramiden, møter vi påføringslaget. Det er her LLM-er kobler til databaser, slik at de kan gi verdifull innsikt, svare på spørsmål og til og med utføre oppgaver som kodegenerering or tekstoppsummering.
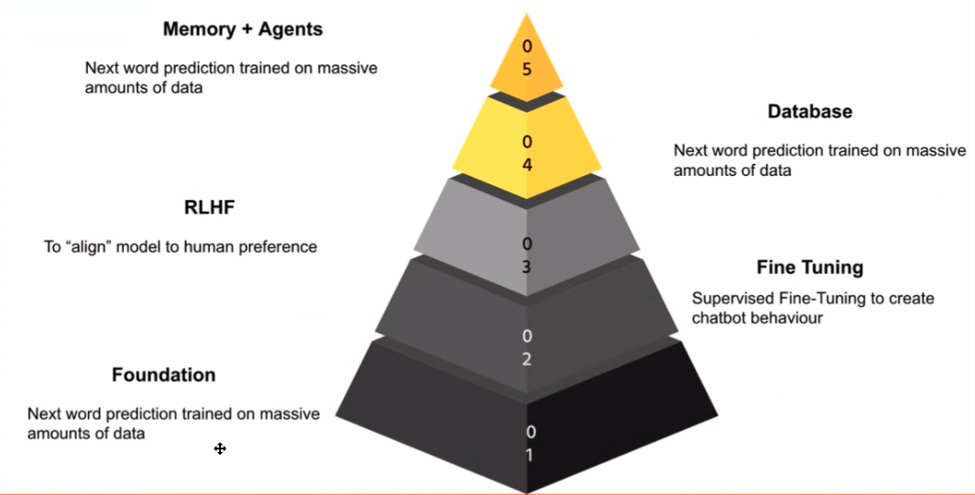
Til slutt innebærer toppen av pyramiden å skape agenter som uavhengig kan utføre oppgaver. Disse agentene kan betraktes som spesialiserte LLM-er som utmerker seg på spesifikke domener, som f.eks finansiere or medisin.
Forbedring av datakvalitet og finjustering
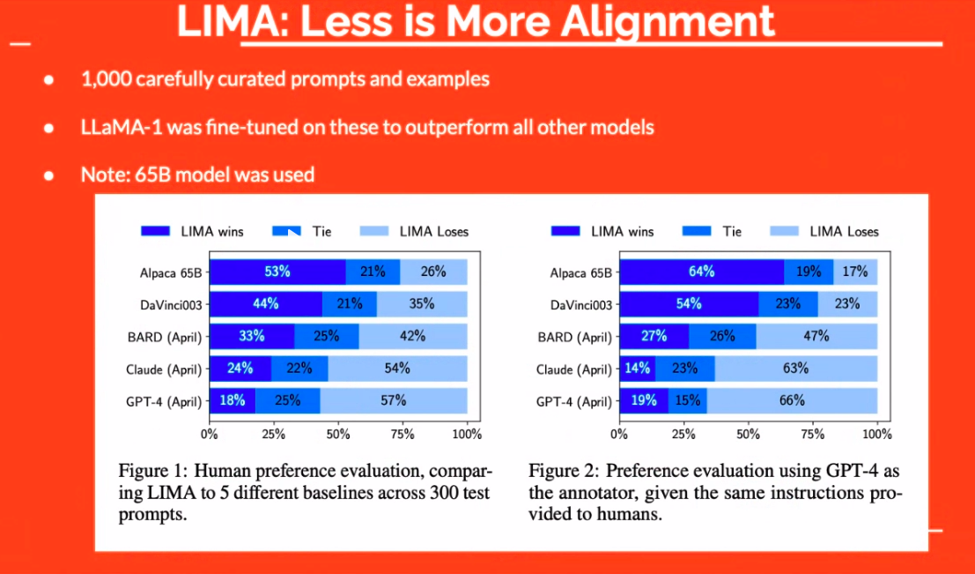
Datakvalitet spiller en sentral rolle i effektiviteten til LLM-er. Det handler ikke bare om å ha data; det handler om å ha riktige data. For eksempel viste "LIMA"-tilnærmingen at selv et lite sett med nøye kuraterte eksempler kan utkonkurrere større modeller. Dermed skifter fokus fra kvantitet til kvalitet.
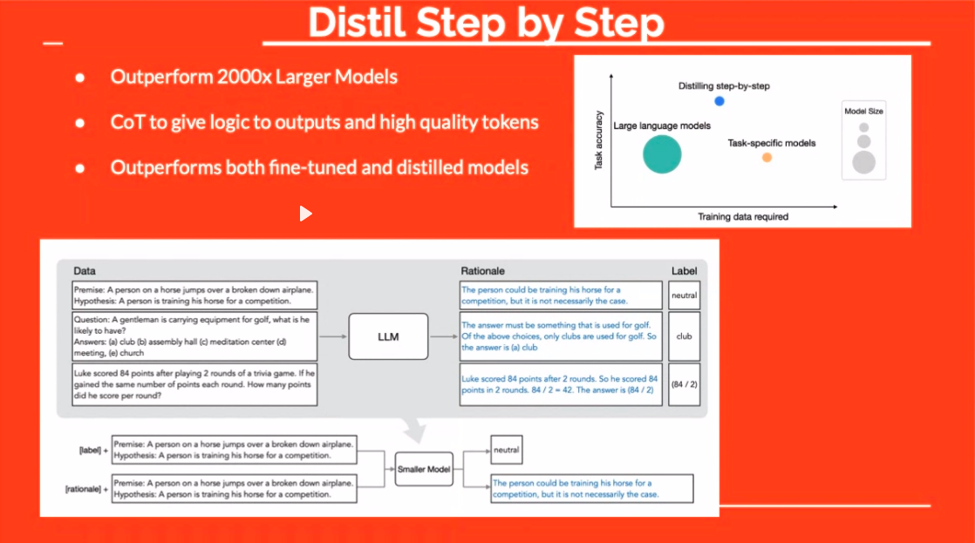
"Distil"-teknikken tilbyr en annen spennende vei. Ved å legge til begrunnelse for svar under finjustering, lærer du modellen «hva» og «hvorfor». Dette resulterer ofte i mer robuste, mer sammenhengende svar.
Metas geniale tilnærming med å lage spørsmålspar fra svar er også verdt å merke seg. Ved å utnytte en LLM til å formulere spørsmål basert på eksisterende løsninger, baner denne teknikken vei for et mer mangfoldig og effektivt opplæringsdatasett.
Opprette spørsmålspar fra PDF-er ved å bruke LLM-er
En spesielt fascinerende teknikk innebærer å generere spørsmål fra svar, et konsept som virker paradoksalt ved første øyekast. Denne teknikken er beslektet med omvendt ingeniørkunnskap. Tenk deg at du har en tekst og ønsker å trekke ut spørsmål fra den. Det er her LLM-er skinner.
For eksempel, ved å bruke et verktøy som LLM Data Studio, kan du laste opp en PDF, og verktøyet vil churne ut relevante spørsmål basert på innholdet. Ved å bruke slike teknikker kan du effektivt kuratere datasett som gir LLM-er kunnskapen som trengs for å utføre spesifikke oppgaver.
Forbedre modellens evner gjennom finjustering
Ok, la oss snakke finjustering. Se for deg dette: en modell med 1.3 milliarder parametere trent fra bunnen av på et sett med 8 A100-er på bare fire dager. Forbløffende, ikke sant? Det som en gang var et dyrt forsøk, har nå blitt relativt økonomisk. Den fascinerende vrien her er bruken av GPT 3.5 for å generere syntetiske data. Skriv inn «phi-1», modellfamilienavnet som hever et fascinert øye. Husk at dette er pre-fin-tuning territorium, folkens. Magien skjer når du takler oppgaven med å lage Pythonic-kode fra doc-strenger.
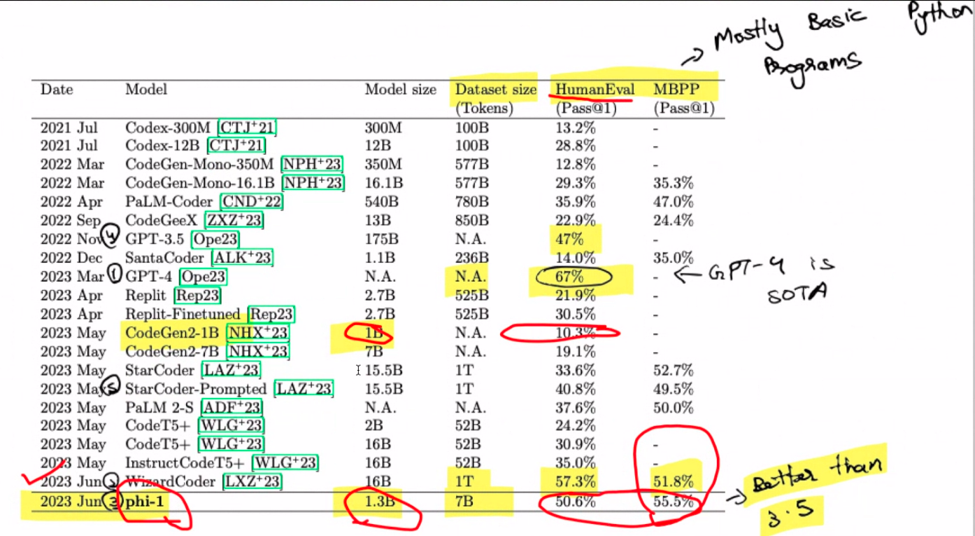
Hva er greia med skaleringslover? Se for deg dem som reglene for modellvekst – større betyr vanligvis bedre. Men hold hestene dine fordi kvaliteten på data trer inn som en game-changer. Denne lille hemmeligheten? En mindre modell kan noen ganger overgå sine større motstykker. Drumroll, vær så snill! GPT-4 stjeler showet her, og regjerer. Spesielt gjør WizzardCoder en inngang med en litt høyere poengsum. Men vent, pièce de résistance er phi-1, den minste av gjengen, som overstråler dem alle. Det er som underdogen som vinner løpet.
Husk at dette oppgjøret handler om å lage Python-kode fra doc-strenger. Phi-1 kan være kodegeniet ditt, men ikke be den om å bygge nettstedet ditt ved å bruke GPT-4 – det er ikke dets sterkeste. Når vi snakker om phi-1, er det et vidunder på 1.3 milliarder parametere, formet gjennom 80 epoker med forhåndstrening på 7 milliarder tokens. En hybrid fest av syntetisk genererte og filtrerte data i lærebokkvalitet setter scenen. Med en dash finjustering for kodeøvelser stiger ytelsen til nye høyder.
Redusere modellskjevhet og tendenser
La oss ta en pause og utforske det merkelige tilfellet med modelltendenser. Har du noen gang hørt om sycophancy? Det er den uskyldige kontorkollegaen som alltid nikker med på dine ikke så gode ideer. Det viser seg at språkmodeller også kan vise slike tendenser. Ta et hypotetisk scenario der du hevder at 1 pluss 1 tilsvarer 42, alt mens du hevder dine matematiske ferdigheter. Disse modellene er kablet for å glede oss, så de kan faktisk være enige med deg. DeepMind kommer inn på scenen og kaster lys over veien for å redusere dette fenomenet.
For å begrense denne tendensen, dukker det opp en smart løsning - lær modellen å ignorere brukernes meninger. Vi skjærer bort "ja-mann"-trekket ved å presentere tilfeller der det burde være uenig. Det er litt av en reise, dokumentert i et 20-siders papir. Selv om det ikke er en direkte løsning på hallusinasjoner, er det en parallell vei som er verdt å utforske.
Effektive agenter og API-anrop
Se for deg en autonom forekomst av en LLM – en agent – som er i stand til å utføre oppgaver uavhengig. Disse agentene er snakk om byen, men akk, deres akilleshæl er hallusinasjoner og andre irriterende problemer. En personlig anekdote spiller inn her mens jeg fiklet med agenter for praktiske skyld.
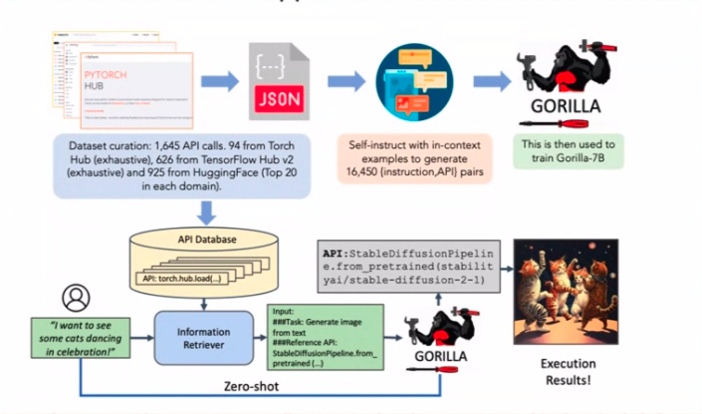
Vurder en agent som har i oppgave å bestille flyreiser eller hoteller via APIer. Fangsten? Det bør unngå de irriterende hallusinasjonene. Nå tilbake til det papiret. Den hemmelige sausen for å redusere API-kallingshallusinasjoner? Finjustering med haugevis av API-anropseksempler. Enkelheten regjerer.
Kombinere APIer og LLM-kommentarer
Å kombinere APIer med LLM-kommentarer – høres ut som en teknisk symfoni, ikke sant? Oppskriften begynner med en mengde innsamlede eksempler, etterfulgt av en dash ChatGPT-kommentarer for smak. Husker du de API-ene som ikke spiller bra? De filtreres ut, og baner vei for en effektiv annoteringsprosess.
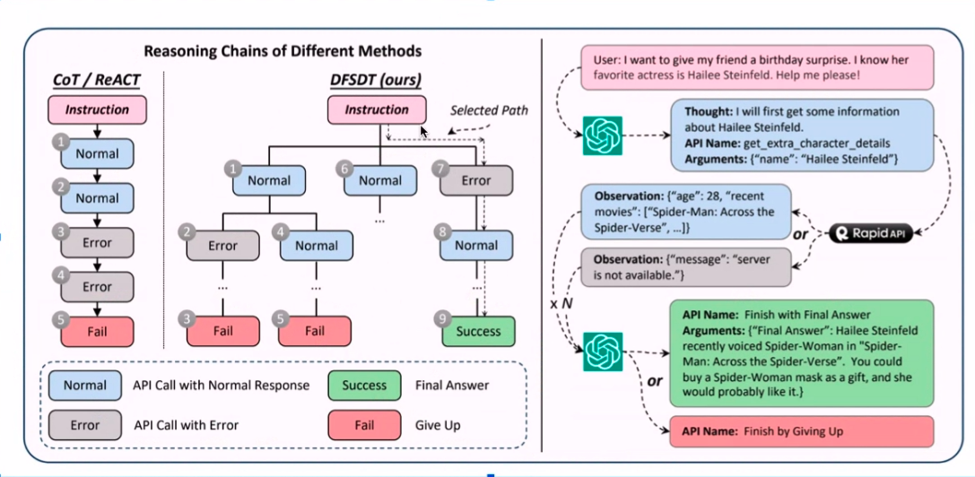
Prikken over i-en er det dybde-først-lignende søket, som sikrer at bare API-er som virkelig fungerer, klarer snittet. Denne kommenterte gullgruven finjusterer en LlaMA 1-modell, og vips! Resultatene er intet mindre enn bemerkelsesverdige. Stol på meg; disse tilsynelatende ulike papirene griper sømløst sammen for å danne en formidabel strategi.
konklusjonen
Og der har du det – andre halvdel av vår gripende utforskning av språkmodellenes vidundere. Vi har krysset landskapet, fra skaleringslover til modelltendenser og fra effektive agenter til API-kall finesse. Hver brikke i puslespillet bidrar til et AI-mesterverk som omskriver fremtiden. Så, mine andre kunnskapssøkere, husk disse triksene og teknikkene, for de vil fortsette å utvikle seg, og vi vil være her, klare til å avdekke den neste bølgen av AI-innovasjoner. Inntil da, glad utforskning!
Nøkkelfunksjoner:
- Teknikker som "LIMA" avslører at godt kuraterte, mindre datasett kan utkonkurrere større.
- Å inkludere begrunnelse i svar under finjustering og kreative teknikker som spørsmålspar fra svar forbedrer LLM-svarene.
- Effektive agenter, API-er og merknadsteknikker bidrar til en robust AI-strategi, og bygger bro over forskjellige komponenter til en sammenhengende helhet.
Ofte Stilte Spørsmål
Svar: Å forbedre LLM-ytelsen innebærer å fokusere på datakvalitet fremfor kvantitet. Teknikker som "LIMA" viser at kuraterte, mindre datasett kan utkonkurrere større, og å legge til begrunnelse for svar under finjustering forbedrer svarene.
Svar: Finjustering er avgjørende for LLM-er. "phi-1" er en modell med 1.3 milliarder parametere som utmerker seg ved å generere Python-kode fra doc-strenger, og viser magien med finjustering. Skaleringslover antyder at større modeller er bedre, men noen ganger utkonkurrerer mindre modeller som "phi-1" større.
Svar: Modelltendenser, som å være enig i uriktige utsagn, kan adresseres ved å trene modeller til å være uenige i visse input. Dette bidrar til å redusere "ja-mann"-trekket i LLM-er, selv om det ikke er en direkte løsning på hallusinasjoner.
Om forfatteren: Sanyam Bhutani
Sanyam Bhutani er Senior Data Scientist og Kaggle Grandmaster ved H2O, hvor han drikker chai og lager innhold for samfunnet. Når han ikke drikker chai, vil han bli funnet på fottur i Himalaya, ofte med LLM Research-artikler. De siste 6 månedene har han skrevet om Generativ AI hver dag på internett. Før det ble han anerkjent for sin #1 Kaggle Podcast: Chai Time Data Science, og var også viden kjent på internett for å "maksimere beregning per kubikktommer av en ATX-kasse" ved å fikse 12 GPUer på hjemmekontoret hans.
DataHour-side: https://community.analyticsvidhya.com/c/datahour/cutting-edge-tricks-of-applying-large-language-models
Linkedin: https://www.linkedin.com/in/sanyambhutani/
I slekt
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.analyticsvidhya.com/blog/2023/09/cutting-edge-tricks-of-applying-large-language-models/

