I dag er vi glade for å kunngjøre det Amazon DataZone er nå i stand til å presentere datakvalitetsinformasjon for dataressurser. Denne informasjonen gir sluttbrukere mulighet til å ta informerte beslutninger om hvorvidt de skal bruke spesifikke eiendeler.
Mange organisasjoner bruker allerede AWS limdatakvalitet å definere og håndheve regler for datakvalitet på dataene deres, validere data mot forhåndsdefinerte regler, spore datakvalitetsmålinger og overvåke datakvaliteten over tid ved hjelp av kunstig intelligens (AI). Andre organisasjoner overvåker kvaliteten på dataene sine gjennom tredjepartsløsninger.
Amazon DataZone integreres nå direkte med AWS Glue for å vise datakvalitetspoeng for AWS Glue Data Catalog-ressurser. I tillegg tilbyr Amazon DataZone nå APIer for import av datakvalitetspoeng fra eksterne systemer.
I dette innlegget diskuterer vi de nyeste funksjonene til Amazon DataZone for datakvalitet, integrasjonen mellom Amazon DataZone og AWS Glue Data Quality og hvordan du kan importere datakvalitetspoeng produsert av eksterne systemer til Amazon DataZone via API.
Utfordringer
Et av de vanligste spørsmålene vi får fra kunder er knyttet til visning av datakvalitetsscore i Amazon DataZone forretningsdatakatalog for å la bedriftsbrukere få innsyn i helsen og påliteligheten til datasettene.
Ettersom data blir stadig mer avgjørende for å drive forretningsbeslutninger, er Amazon DataZone-brukere svært interessert i å levere de høyeste standardene for datakvalitet. De anerkjenner viktigheten av nøyaktige, fullstendige og tidsriktige data for å muliggjøre informert beslutningstaking og fremme tillit i analyse- og rapporteringsprosessene deres.
Amazon DataZone-dataressurser kan oppdateres med varierende frekvens. Etter hvert som data oppdateres og oppdateres, kan endringer skje gjennom oppstrømsprosesser som setter dem i fare for ikke å opprettholde den tiltenkte kvaliteten. Datakvalitetspoeng hjelper deg å forstå om data har opprettholdt det forventede kvalitetsnivået for dataforbrukere å bruke (gjennom analyse eller nedstrømsprosesser).
Fra en produsents perspektiv kan dataansvarlige nå sette opp Amazon DataZone for automatisk å importere datakvalitetspoeng fra AWS Glue Data Quality (planlagt eller på forespørsel) og inkludere denne informasjonen i Amazon DataZone-katalogen for å dele med forretningsbrukere. I tillegg kan du nå bruke nye Amazon DataZone API-er for å importere datakvalitetspoeng produsert av eksterne systemer til datamidlene.
Med den siste forbedringen kan Amazon DataZone-brukere nå oppnå følgende:
- Få tilgang til innsikt om datakvalitetsstandarder direkte fra Amazon DataZone-nettportalen
- Se datakvalitetspoeng på ulike KPIer, inkludert datafullstendighet, unikhet og nøyaktighet
- Sørg for at brukerne har et helhetlig syn på kvaliteten og påliteligheten til dataene deres.
I den første delen av dette innlegget går vi gjennom integrasjonen mellom AWS Glue Data Quality og Amazon DataZone. Vi diskuterer hvordan du visualiserer datakvalitetspoeng i Amazon DataZone, aktiverer AWS Glue Data Quality når du oppretter en ny Amazon DataZone-datakilde, og aktiverer datakvalitet for et eksisterende dataelement.
I den andre delen av dette innlegget diskuterer vi hvordan du kan importere datakvalitetspoeng produsert av eksterne systemer til Amazon DataZone via API. I dette eksemplet bruker vi Amazon EMR-serverløs i kombinasjon med åpen kildekode-biblioteket Pydeequ å fungere som et eksternt system for datakvalitet.
Visualiser AWS Glue Data Quality-poeng i Amazon DataZone
Du kan nå visualisere AWS Glue Data Quality-poeng i dataressurser som har blitt publisert i Amazon DataZone-bedriftskatalogen og som er søkbare gjennom Amazon DataZone-nettportalen.
Hvis aktivaet har AWS Glue Data Quality aktivert, kan du nå raskt visualisere datakvalitetspoengene direkte i katalogsøkeruten.

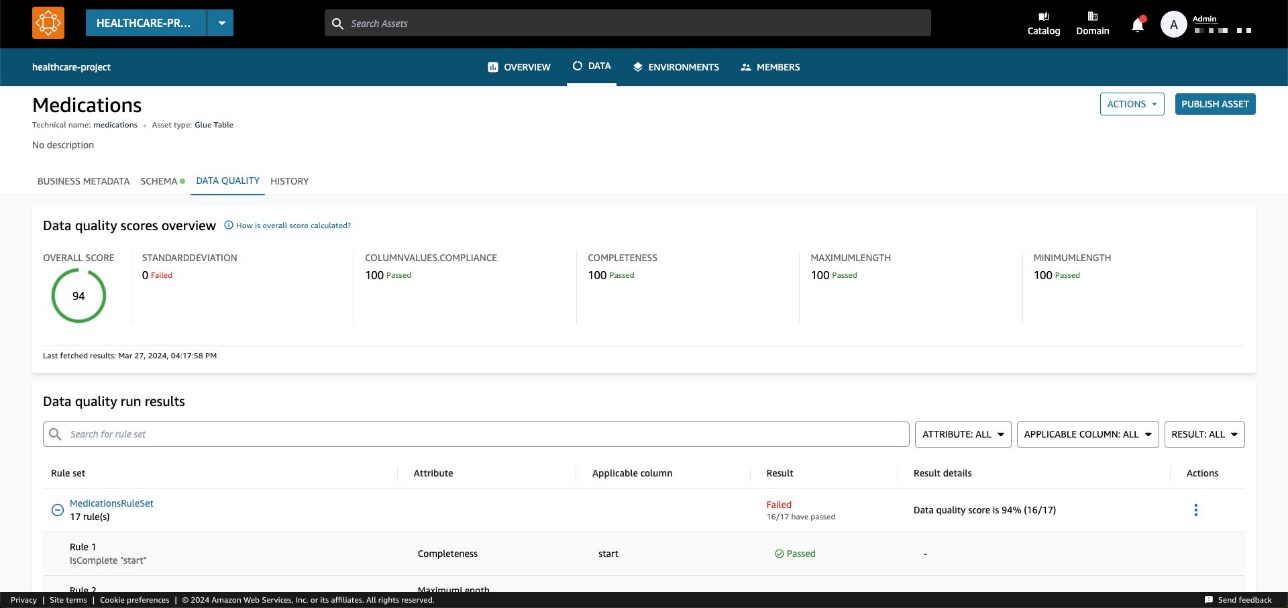
Ved å velge den tilsvarende ressursen kan du forstå innholdet gjennom readme, ordlisteuttrykkog tekniske og forretningsmessige metadata. I tillegg vises den generelle kvalitetspoengindikatoren i Eiendelsdetaljer seksjon.

En datakvalitetspoeng fungerer som en samlet indikator på et datasetts kvalitet, beregnet basert på reglene du definerer.
På Datakvalitet fanen, kan du få tilgang til detaljene for datakvalitetsoversiktsindikatorer og resultatene av datakvalitetskjøringene.
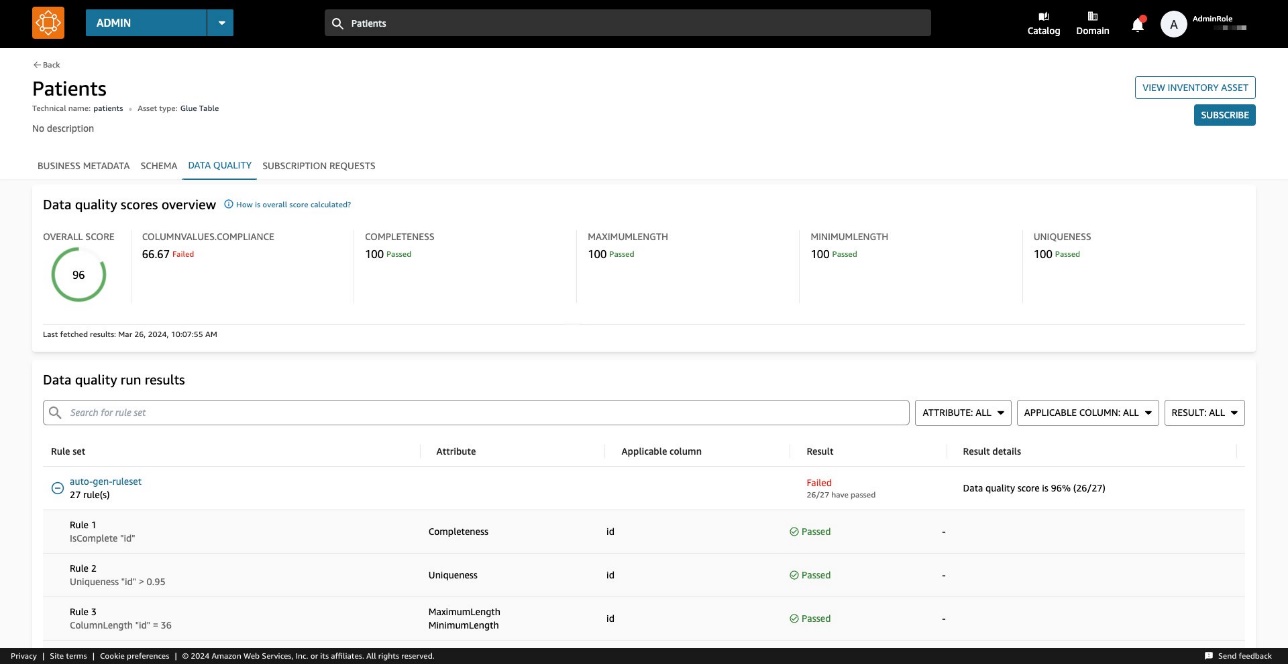
Indikatorene vist på Oversikt fanen beregnes basert på resultatene av regelsettene fra datakvalitetskjøringene.
Hver regel er tildelt et attributt som bidrar til beregningen av indikatoren. For eksempel regler som har Completeness attributt vil bidra til beregningen av den tilsvarende indikatoren på Oversikt fanen.
For å filtrere datakvalitetsresultater, velg Gjeldende kolonne rullegardinmenyen og velg ønsket filterparameter.

Du kan også visualisere datakvaliteten på kolonnenivå fra og med Skjema fanen.

Når datakvalitet er aktivert for ressursen, blir datakvalitetsresultatene tilgjengelige, og gir innsiktsfulle kvalitetspoeng som gjenspeiler integriteten og påliteligheten til hver kolonne i datasettet.
Når du velger en av koblingene for datakvalitetsresultater, blir du omdirigert til detaljsiden for datakvalitet, filtrert etter den valgte kolonnen.

Datakvalitetshistoriske resultater i Amazon DataZone
Datakvaliteten kan endres over tid av mange årsaker:
- Dataformater kan endres på grunn av endringer i kildesystemene
- Ettersom data akkumuleres over tid, kan de bli utdaterte eller inkonsekvente
- Datakvaliteten kan påvirkes av menneskelige feil ved datainntasting, databehandling eller datamanipulering
I Amazon DataZone kan du nå spore datakvalitet over tid for å bekrefte pålitelighet og nøyaktighet. Ved å analysere det historiske rapportens øyeblikksbilde kan du identifisere områder for forbedring, implementere endringer og måle effektiviteten til disse endringene.

Aktiver AWS Glue Data Quality når du oppretter en ny Amazon DataZone-datakilde
I denne delen går vi gjennom trinnene for å aktivere AWS Glue Data Quality når du oppretter en ny Amazon DataZone-datakilde.
Forutsetninger
For å følge med, bør du ha et domene for Amazon DataZone, et Amazon DataZone-prosjekt og et nytt Amazon DataZone-miljø (med en DataLakeProfile). For instruksjoner, se Amazon DataZone hurtigstart med AWS Glue-data.
Du må også definere og kjøre et regelsett mot dataene dine, som er et sett med datakvalitetsregler i AWS Glue Data Quality. For å sette opp datakvalitetsreglene og for mer informasjon om emnet, se følgende innlegg:
Etter at du har opprettet datakvalitetsreglene, sørg for at Amazon DataZone har tillatelsene til å få tilgang til AWS Glue-databasen som administreres gjennom AWS Lake formasjon. For instruksjoner, se Konfigurer Lake Formation-tillatelser for Amazon DataZone.
I vårt eksempel har vi konfigurert et regelsett mot en tabell som inneholder pasientdata innenfor en syntetiske helsedatasett generert ved hjelp av Synthea. Synthea er en syntetisk pasientgenerator som lager realistiske pasientdata og tilhørende medisinske journaler som kan brukes til å teste helseprogramvareapplikasjoner.
Regelsettet inneholder 27 individuelle regler (en av dem mislykkes), så den samlede datakvalitetsscore er 96 %.
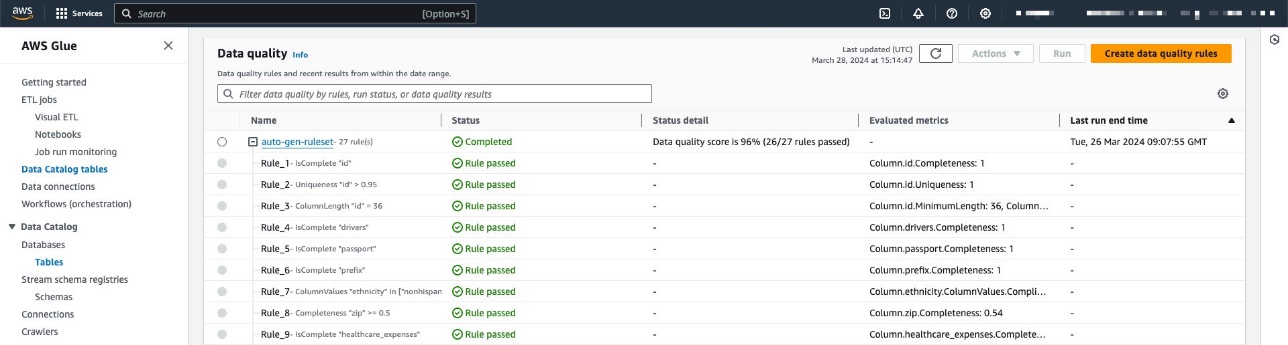
Hvis du bruker Amazon DataZone-administrerte retningslinjer, er det ingen handling nødvendig fordi disse vil automatisk bli oppdatert med nødvendige handlinger. Ellers må du tillate at Amazon DataZone har de nødvendige tillatelsene for å liste og få AWS Glue Data Quality-resultater, som vist i Amazon DataZone brukerveiledning.
Opprett en datakilde med datakvalitet aktivert
I denne delen oppretter vi en datakilde og aktiverer datakvalitet. Du kan også oppdatere en eksisterende datakilde for å aktivere datakvalitet. Vi bruker denne datakilden til å importere metadatainformasjon relatert til våre datasett. Amazon DataZone vil også importere datakvalitetsinformasjon relatert til (en eller flere) eiendeler som finnes i datakilden.
- På Amazon DataZone-konsollen velger du Datakilder i navigasjonsruten.
- Velg Lag datakilde.

- Til Navn, skriv inn et navn for datakilden.
- Til Datakildetype, plukke ut AWS Lim.
- Til Miljø, velg ditt miljø.

- Til Databasens navn, skriv inn et navn for databasen.
- Til Utvalgskriterier for tabell, velg dine kriterier.
- Velg neste.

- Til Datakvalitet, plukke ut Aktiver datakvalitet for denne datakilden.
Hvis datakvalitet er aktivert, vil Amazon DataZone automatisk hente datakvalitetspoeng fra AWS Glue ved hver datakildekjøring.
- Velg neste.

Nå kan du kjøre datakilden.

Mens du kjører datakilden, importerer Amazon DataZone de siste 100 AWS Glue Data Quality-kjøringsresultatene. Denne informasjonen er nå synlig på eiendelsiden og vil være synlig for alle Amazon DataZone-brukere etter publisering av eiendelen.
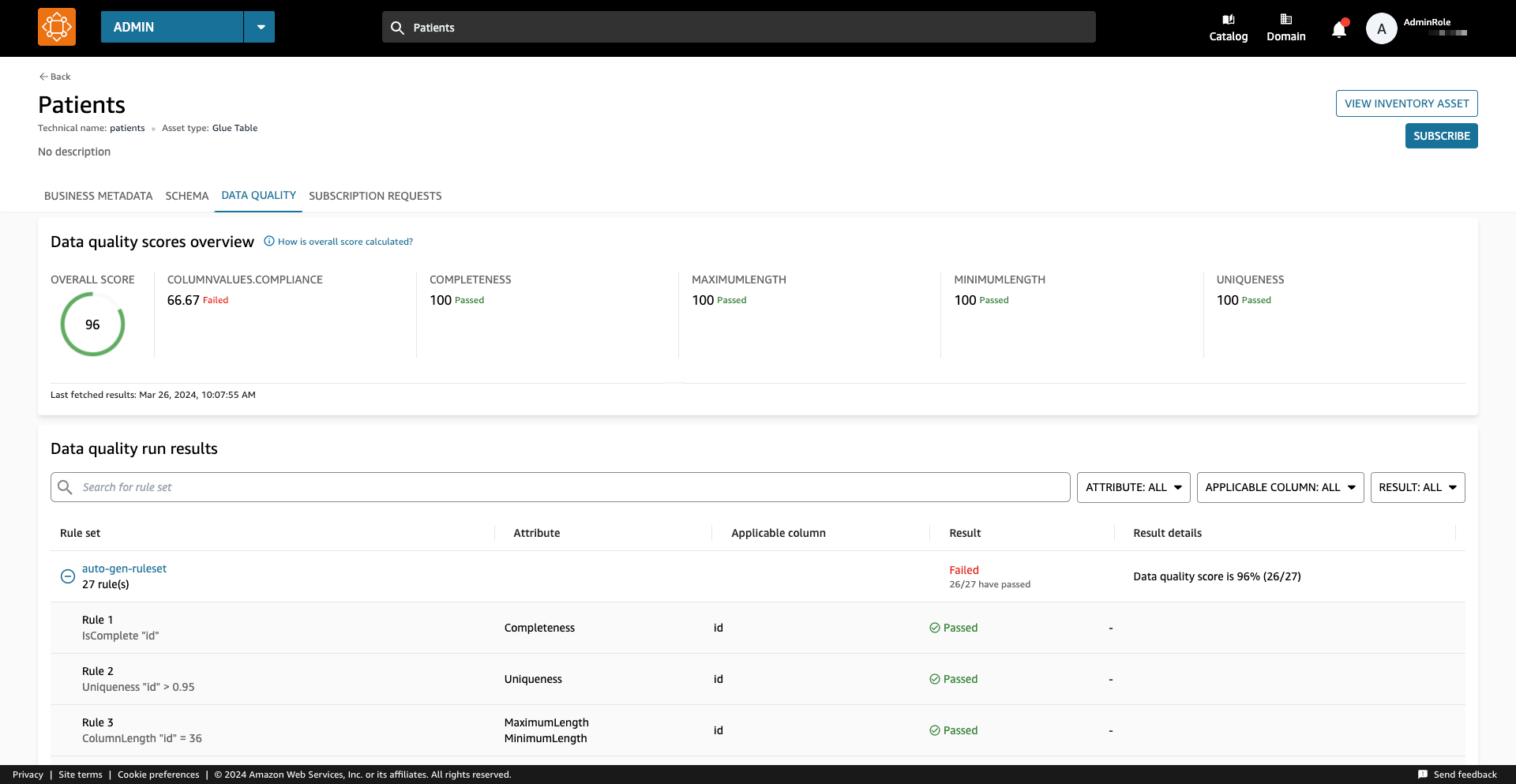
Aktiver datakvalitet for et eksisterende dataelement
I denne delen aktiverer vi datakvalitet for en eksisterende ressurs. Dette kan være nyttig for brukere som allerede har datakilder på plass og ønsker å aktivere funksjonen etterpå.
Forutsetninger
For å følge med, bør du allerede ha kjørt datakilden og produsert et AWS Glue-tabelldataelement. I tillegg bør du ha definert et regelsett i AWS Glue Data Quality over måltabellen i Data Catalog.

For dette eksemplet kjørte vi datakvalitetsjobben flere ganger mot tabellen, og produserte de relaterte AWS Glue Data Quality-poengene, som vist i følgende skjermbilde.

Importer datakvalitetspoeng til dataelementet
Fullfør følgende trinn for å importere de eksisterende AWS Glue Data Quality-poengene til dataelementet i Amazon DataZone:
- Innenfor Amazon DataZone-prosjektet, naviger til Inventardata ruten og velg datakilden.
Hvis du velger Datakvalitet fanen, kan du se at det fortsatt ikke er informasjon om datakvalitet fordi AWS Glue Data Quality-integrering ikke er aktivert for dette dataelementet ennå.
- På Datakvalitet kategorien, velg Aktiver datakvalitet.

- på Datakvalitet seksjon, velg Aktiver datakvalitet for denne datakilden.
- Velg Spar.

Nå, tilbake i inventardataruten, kan du se en ny fane: Datakvalitet.
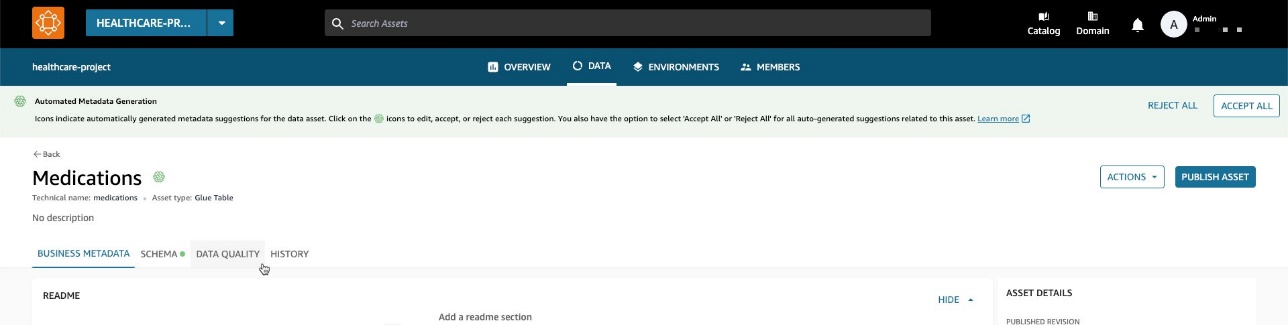
På Datakvalitet fanen, kan du se datakvalitetspoeng importert fra AWS Glue Data Quality.
Få inn datakvalitetspoeng fra en ekstern kilde ved hjelp av Amazon DataZone APIer
Mange organisasjoner bruker allerede systemer som beregner datakvalitet ved å utføre tester og påstander på datasettene deres. Amazon DataZone støtter nå import av tredjeparts datakvalitetspoeng via API, slik at brukere som navigerer på nettportalen kan se denne informasjonen.
I denne delen simulerer vi et tredjepartssystem som sender datakvalitetspoeng inn i Amazon DataZone via APIer Boto3 (Python SDK for AWS).
For dette eksemplet bruker vi det samme syntetisk datasett som tidligere, generert med Synthea.
Følgende diagram illustrerer løsningsarkitekturen.

Arbeidsflyten består av følgende trinn:
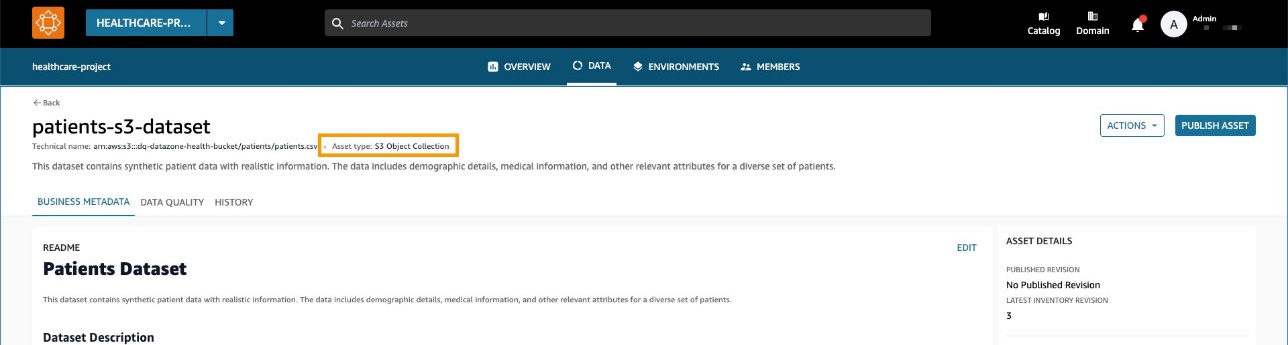
- Les et datasett over pasienter i Amazon enkel lagringstjeneste (Amazon S3) direkte fra Amazon EMR ved hjelp av Spark.
Datasettet er opprettet som en generisk S3-aktivasamling i Amazon DataZone.
- I Amazon EMR, utfør datavalideringsregler mot datasettet.
- Beregningene lagres i Amazon S3 for å ha en vedvarende utgang.
- Bruk Amazon DataZone APIer gjennom Boto3 for å pushe tilpassede metadata for datakvalitet.
- Sluttbrukere kan se datakvalitetspoengene ved å navigere til dataportalen.
Forutsetninger
Vi bruker Amazon EMR-serverløs og Pydeequ for å kjøre en fullstendig administrert Spark miljø. For å lære mer om Pydeequ som et rammeverk for datatesting, se Testing av datakvalitet i skala med Pydeequ.
For å tillate Amazon EMR å sende data til Amazon DataZone-domenet, sørg for at IAM-rollen som brukes av Amazon EMR har tillatelser til å gjøre følgende:
- Les fra og skriv til S3-bøttene
- Ring
post_time_series_data_pointshandling for Amazon DataZone:
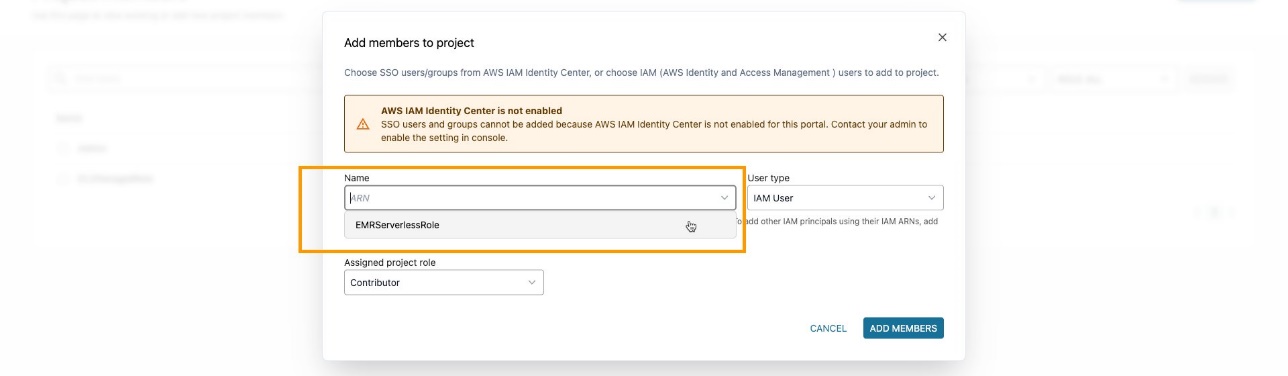
Sørg for at du har lagt til EMR-rollen som en prosjektmedlem i Amazon DataZone-prosjektet. På Amazon DataZone-konsollen, naviger til Prosjektmedlemmer siden og velg Legg til medlemmer.

Legg til EMR-rollen som bidragsyter.
Innta og analysere PySpark-kode
I denne delen analyserer vi PySpark-koden som vi bruker til å utføre datakvalitetskontroller og sende resultatene til Amazon DataZone. Du kan laste ned hele PySpark-skript.
For å kjøre skriptet helt, kan du sende inn en jobb til EMR Serverless. Tjenesten tar seg av å planlegge jobben og automatisk tildele ressursene som trengs, slik at du kan spore jobbkjøringsstatuser gjennom hele prosessen.
Du kan send inn en jobb til EMR i Amazon EMR-konsollen ved å bruke EMR Studio eller programmatisk ved å bruke AWS CLI eller bruke en av AWS SDK-er.
I Apache Spark, en SparkSession er inngangspunktet for interaksjon med DataFrames og Sparks innebygde funksjoner. Skriptet vil begynne å initialisere a SparkSession:
Vi leser et datasett fra Amazon S3. For økt modularitet kan du bruke skriptinngangen til å referere til S3-banen:
Deretter setter vi opp et metrikklager. Dette kan være nyttig for å opprettholde kjøreresultatene i Amazon S3.
Pydeequ lar deg lage regler for datakvalitet ved å bruke byggmestermønsteret, som er et velkjent designmønster for programvareutvikling, som setter sammen instruksjoner for å instansiere en VerificationSuite gjenstand:
Følgende er utdataene for datavalideringsreglene:
På dette tidspunktet ønsker vi å sette inn disse datakvalitetsverdiene i Amazon DataZone. For å gjøre det bruker vi post_time_series_data_points funksjon i Boto3 Amazon DataZone-klienten.
De PostTimeSeriesDataPoints DataZone API lar deg sette inn nye tidsseriedatapunkter for en gitt eiendel eller oppføring, uten å opprette en ny revisjon.
På dette tidspunktet vil du kanskje også ha mer informasjon om hvilke felt som sendes som input for API. Du kan bruke APIer for å få spesifikasjonen for Amazon DataZone-skjematyper; i vårt tilfelle er det amazon.datazone.DataQualityResultFormType.
Du kan også bruke AWS CLI til å påkalle API og vise skjemastrukturen:
Denne utgangen hjelper til med å identifisere de nødvendige API-parametrene, inkludert felt og verdigrenser:
For å sende de riktige skjemadataene, må vi konvertere Pydeequ-utdataene til å matche DataQualityResultsFormType kontrakt. Dette kan oppnås med en Python-funksjon som behandler resultatene.
For hver DataFrame-rad trekker vi ut informasjon fra begrensningskolonnen. Ta for eksempel følgende kode:
Vi konverterer det til følgende:
Sørg for å sende en utgang som samsvarer med KPIene du vil spore. I vårt tilfelle legger vi til _custom til statistikknavnet, noe som resulterer i følgende format for KPIer:
Completeness_customUniqueness_custom
I et virkelighetsscenario vil du kanskje angi en verdi som samsvarer med rammeverket for datakvalitet i forhold til KPI-ene du vil spore i Amazon DataZone.
Etter å ha brukt en transformasjonsfunksjon, har vi et Python-objekt for hver regelevaluering:
Vi bruker også constraint_status kolonne for å beregne den samlede poengsummen:
I vårt eksempel gir dette en bestått prosentandel på 85.71 %.
Vi setter denne verdien i passingPercentage inndatafeltet sammen med den øvrige informasjonen knyttet til evalueringene i inndataene til Boto3-metoden post_time_series_data_points:
Boto3 påkaller Amazon DataZone APIer. I disse eksemplene brukte vi Boto3 og Python, men du kan velge en av AWS SDK-er utviklet på språket du foretrekker.
Etter å ha angitt riktig domene og aktiva-ID og kjørt metoden, kan vi sjekke på Amazon DataZone-konsollen at datakvaliteten nå er synlig på aktivasiden.
Vi kan observere at den totale poengsummen samsvarer med API-inndataverdien. Vi kan også se at vi var i stand til å legge til tilpassede KPIer på oversiktsfanen gjennom parameterverdier for tilpassede typer.
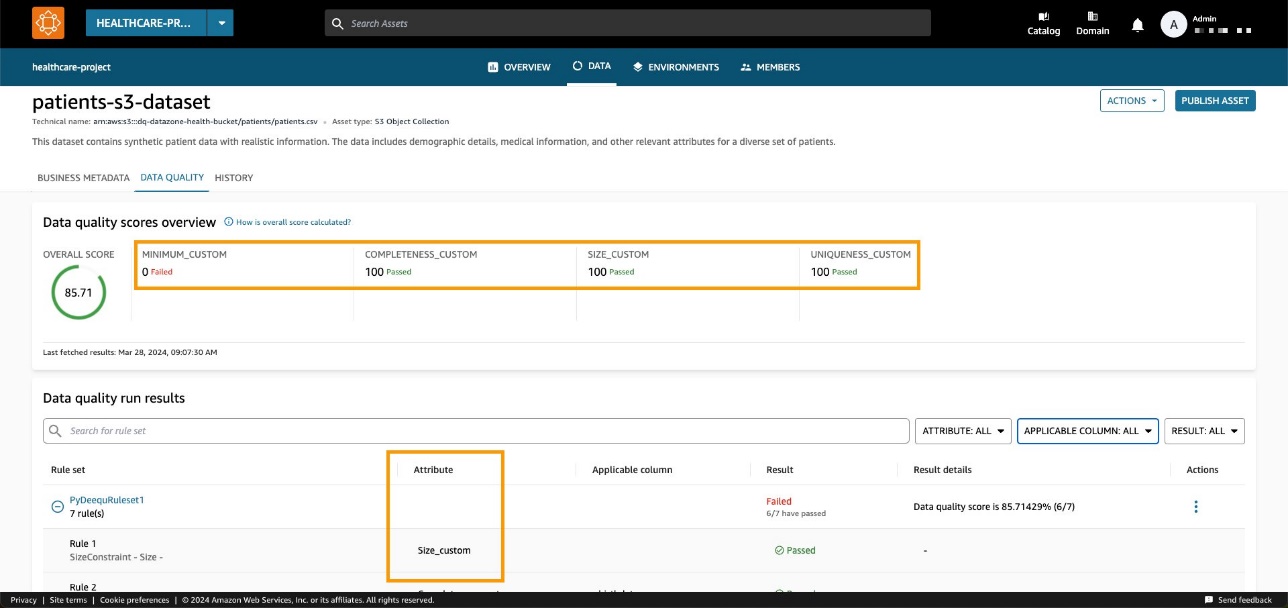
Med de nye Amazon DataZone API-ene kan du laste datakvalitetsregler fra tredjepartssystemer inn i et spesifikt dataelement. Med denne muligheten lar Amazon DataZone deg utvide typene indikatorer som finnes i AWS Glue Data Quality (som fullstendighet, minimum og unikhet) med tilpassede indikatorer.
Rydd opp
Vi anbefaler å slette potensielt ubrukte ressurser for å unngå å pådra seg uventede kostnader. For eksempel kan du slette Amazon DataZone-domenet og EMR søknad du opprettet under denne prosessen.
konklusjonen
I dette innlegget fremhevet vi de nyeste funksjonene til Amazon DataZone for datakvalitet, og gir sluttbrukere bedre kontekst og synlighet i datamidlene deres. Videre fordypet vi oss i den sømløse integrasjonen mellom Amazon DataZone og AWS Glue Data Quality. Du kan også bruke Amazon DataZone API-er for å integrere med eksterne datakvalitetsleverandører, slik at du kan opprettholde en omfattende og robust datastrategi i ditt AWS-miljø.
For å lære mer om Amazon DataZone, se Amazon DataZone brukerveiledning.
Om forfatterne
 Andrea Filippo er en Partner Solutions Architect hos AWS som støtter offentlig sektor partnere og kunder i Italia. Han fokuserer på moderne dataarkitekturer og hjelper kunder med å akselerere sin skyreise med serverløse teknologier.
Andrea Filippo er en Partner Solutions Architect hos AWS som støtter offentlig sektor partnere og kunder i Italia. Han fokuserer på moderne dataarkitekturer og hjelper kunder med å akselerere sin skyreise med serverløse teknologier.
 Emanuele er løsningsarkitekt hos AWS, basert i Italia, etter å ha bodd og jobbet i Spania i mer enn 5 år. Han liker å hjelpe store selskaper med å ta i bruk skyteknologier, og kompetanseområdet hans er hovedsakelig fokusert på Data Analytics og Data Management. Utenom jobben liker han å reise og samle actionfigurer.
Emanuele er løsningsarkitekt hos AWS, basert i Italia, etter å ha bodd og jobbet i Spania i mer enn 5 år. Han liker å hjelpe store selskaper med å ta i bruk skyteknologier, og kompetanseområdet hans er hovedsakelig fokusert på Data Analytics og Data Management. Utenom jobben liker han å reise og samle actionfigurer.
 Varsha Velagapudi er senior teknisk produktsjef hos Amazon DataZone hos AWS. Hun fokuserer på å forbedre dataoppdagelse og kurering som kreves for dataanalyse. Hun brenner for å forenkle kundenes AI/ML- og analysereise for å hjelpe dem med å lykkes med sine daglige oppgaver. Utenom jobben liker hun natur og friluftsliv, lesing og reise.
Varsha Velagapudi er senior teknisk produktsjef hos Amazon DataZone hos AWS. Hun fokuserer på å forbedre dataoppdagelse og kurering som kreves for dataanalyse. Hun brenner for å forenkle kundenes AI/ML- og analysereise for å hjelpe dem med å lykkes med sine daglige oppgaver. Utenom jobben liker hun natur og friluftsliv, lesing og reise.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/amazon-datazone-now-integrates-with-aws-glue-data-quality-and-external-data-quality-solutions/

