Dette innlegget er skrevet av Lisa Levy, innholdsspesialist hos Satori.
Datademokratisering gjør det mulig for brukere å oppdage og få tilgang til data raskere, forbedre informerte datadrevne beslutninger og bruke data til å generere forretningseffekt. Det øker også samarbeidet på tvers av team og organisasjoner, bryter ned datasiloer og gjør det mulig for tverrfunksjonelle team å jobbe mer effektivt sammen.
En betydelig barriere for datademokratisering er å sikre at data forblir sikre og kompatible. Evnen til å søke, lokalisere og maskere sensitive data er avgjørende for datademokratiseringsprosessen. Amazon RedShift gir en rekke funksjoner som rollebasert tilgangskontroll (RBAC), sikkerhet på radnivå (RLS), sikkerhet på kolonnenivå (CLS) og dynamisk datamaskering for å lette sikker bruk av data.
I denne todelte serien utforsker vi hvordan Satori, en Amazon Redshift Ready-partner, kan hjelpe Amazon Redshift-brukere med å automatisere sikker tilgang til data og gi databrukerne deres selvbetjent datatilgang. Satori integreres naturlig med både Amazon Redshift-klargjorte klynger og Amazon Redshift Serverløs for enkelt oppsett av Amazon Redshift-datavarehuset i den sikre Satori-portalen.
I del 1 gir vi detaljerte trinn for hvordan du integrerer Satori med ditt Amazon Redshift-datavarehus og kontrollerer hvordan data får tilgang med sikkerhetspolicyer.
I del 2 vil vi utforske hvordan du setter opp selvbetjent datatilgang med Satori til data som er lagret i Amazon Redshift.
Satoris datasikkerhetsplattform
Satori er en datasikkerhetsplattform som muliggjør friksjonsfri selvbetjeningstilgang for brukere med innebygd sikkerhet. Satori akselererer implementering av datasikkerhetskontroller på datavarehus som Amazon Redshift, er enkel å integrere og krever ingen endringer i Amazon Redshift-dataene, skjemaet eller hvordan brukerne samhandler med data.
Integrering av Satori med Amazon Redshift akselererer organisasjoners evne til å bruke dataene deres for å generere forretningsverdi. Denne raskere tiden til verdi oppnås ved å gjøre det mulig for bedrifter å administrere datatilgang mer effektivt og effektivt.
Ved å bruke Satori med Moderne dataarkitektur på AWS, kan du finne og få tilgang til data ved hjelp av en personlig dataportal, og bedrifter kan sette retningslinjer som just-in-time tilgang til data og finmasket tilgangskontroll. I tillegg blir all datatilgang revidert. Satori jobber sømløst med native Redshift-objekter, eksterne tabeller som kan spørres gjennom Amazon Redshift Spectrum, også delte databaseobjekter gjennom Redshift-datadeling.
Satori anonymiserer data på flukt, basert på dine krav, i henhold til brukere, roller og datasett. Maskeringen brukes uavhengig av den underliggende databasen og krever ikke skriving av kode eller endringer i databaser, datavarehus og datainnsjøer. Satori overvåker kontinuerlig datatilgang, identifiserer plasseringen av hvert datasett og klassifiserer dataene i hver kolonne. Resultatet er en selvutfyllende databeholdning, som også klassifiserer dataene for deg og lar deg legge til dine egne tilpassede klassifikasjoner.
Satori integreres med identitetsleverandører for å berike identitetskonteksten og levere bedre analyser og mer nøyaktige retningslinjer for tilgangskontroll. Satori samhandler med identitetsleverandører enten via API eller ved å bruke SAML-protokollen. Satori integreres også med business intelligence (BI) verktøy som Amazon QuickSight, Tableau, Power BI etc. for å overvåke og håndheve sikkerhets- og personvernregler for dataforbrukere som bruker BI-verktøy for å få tilgang til data.
I dette innlegget utforsker vi hvordan organisasjoner kan akselerere sikker databruk i Amazon Redshift med Satori, inkludert fordelene med integrasjon og de nødvendige trinnene for å starte. Vi vil gå gjennom et eksempel på å integrere Satori med en Redshift-klynge og se hvordan sikkerhetspolicyer brukes dynamisk når det spørres gjennom DBeaver.
Forutsetninger
Du bør ha følgende forutsetninger:
- En AWS-konto.
- En Redshift-klynge og Redshift Severless-endepunkt for å lagre og administrere data. Du kan opprette og administrere klyngen din gjennom AWS-administrasjonskonsoll, AWS kommandolinjegrensesnitt (AWS CLI), eller Redshift API.
- En Satori-konto og Satori-kontakten for Amazon Redshift.
- En Redshift sikkerhetsgruppe. Du må konfigurere Redshift-sikkerhetsgruppen for å tillate innkommende trafikk fra Satori-koblingen for Amazon Redshift. Merk at Satori kan distribueres som en programvare som en tjeneste (SaaS) datatilgangskontroller eller i din VPC.
Forbered dataene
For å sette opp vårt eksempel, fullfør følgende trinn:
- På Amazon Redshift-konsollen, naviger til Query Editor v2.
Hvis du er kjent med SQL notatbøker, Kan du last ned denne SQL-notatboken for demonstrasjonen og importer den for raskt å komme i gang.
- I Amazon Redshift-klargjorte klynge bruker du følgende kode for å lage en tabell, fylle den ut og opprette roller og brukere:
Koble til klargjort klynge gjennom Query Editor V2 og kjør følgende SQL:
Gjenta trinnet ovenfor for Redshift Serverless endepunkt og få navneområdet:
- Koble til Redshift klargjort klynge og opprett en utgående dataandel (produsent) med følgende SQL
- Koble til Redshift Serverless endepunkt og utfør setningene nedenfor for å konfigurere den innkommende datadelingen.
- Alternativt kan du opprette kredittkorttabellen som en ekstern tabell ved å bruke denne eksempelfil i Amazon S3 og legge til tabellen i AWS Glue Data Catalog gjennom Lim Crawler. Når tabellen er tilgjengelig i Glue Data Catalog, kan du opprette det eksterne skjemaet i ditt Amazon Redshift Serverless-endepunkt ved å bruke SQL nedenfor
Koble til Amazon Redshift
Hvis du ikke har en Satori-konto, kan du det heller opprette en prøvekjøringskonto or få Satori fra AWS Marketplace. Fullfør deretter følgende trinn for å koble til Amazon Redshift:
- Logg inn på Satori.
- Velg Datalagre Velg navigasjonsruten Legg til Datastore, og velg Amazon RedShift.
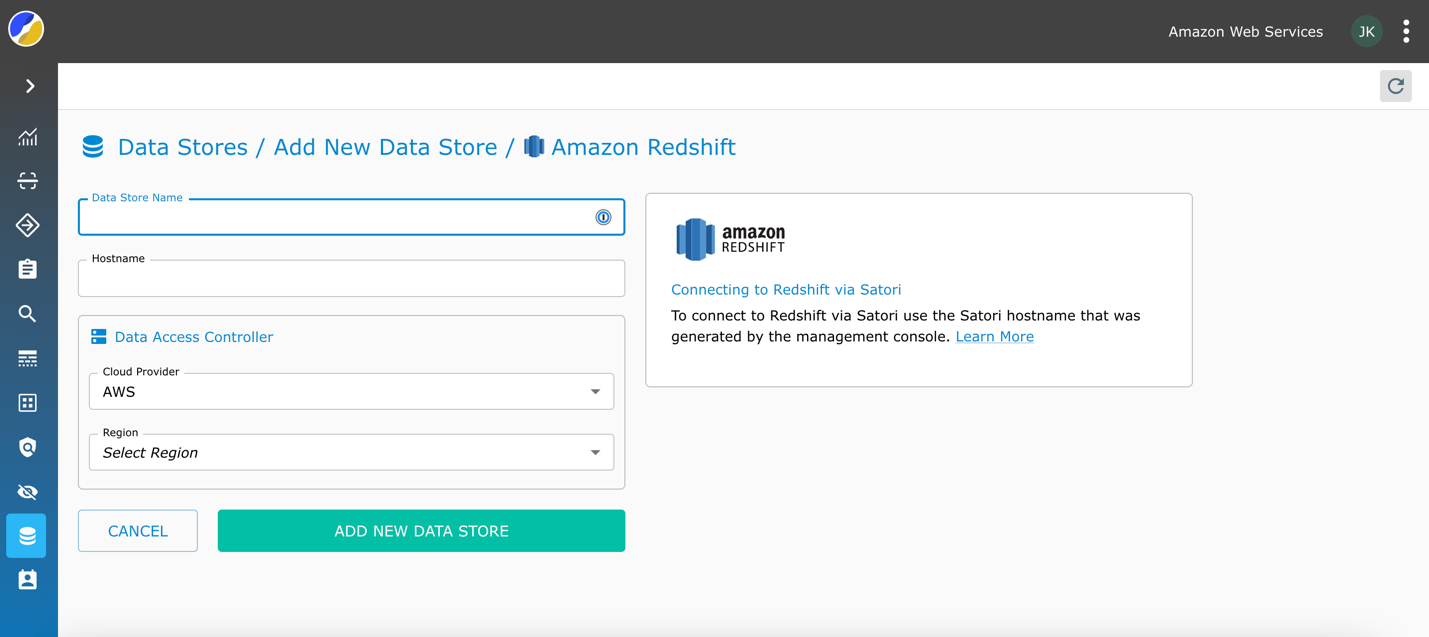
- Legg til klyngeidentifikatoren fra Amazon Redshift-konsollen. Satori vil automatisk oppdage regionen der klyngen din befinner seg i AWS-kontoen din.
- Satori vil generere et Satori-vertsnavn for klyngen din, som du vil bruke for å koble til Redshift-klyngen
- I denne demonstrasjonen vil vi legge til en Redshift klargjort klynge og et Redshift Serverless endepunkt for å lage to datalagre i Satori
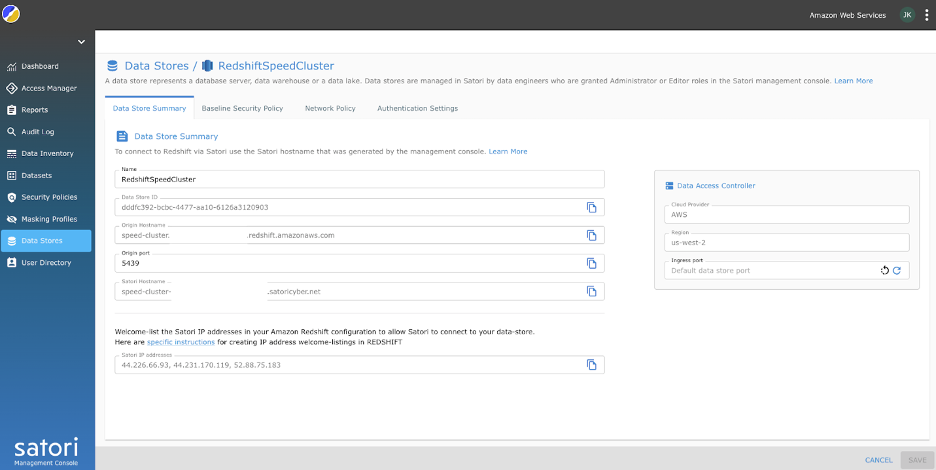

- Tillat innkommende tilgang for Satori IP-adressene som er oppført i Redshift-klyngesikkerhetsgruppen.
For mer informasjon om å koble Satori til din Redshift-klynge, se Legge til en AWS Redshift Data Store til Satori.
- Under Autentiseringsinnstillinger, skriv inn din root- eller superbrukerlegitimasjon for hver datalager.
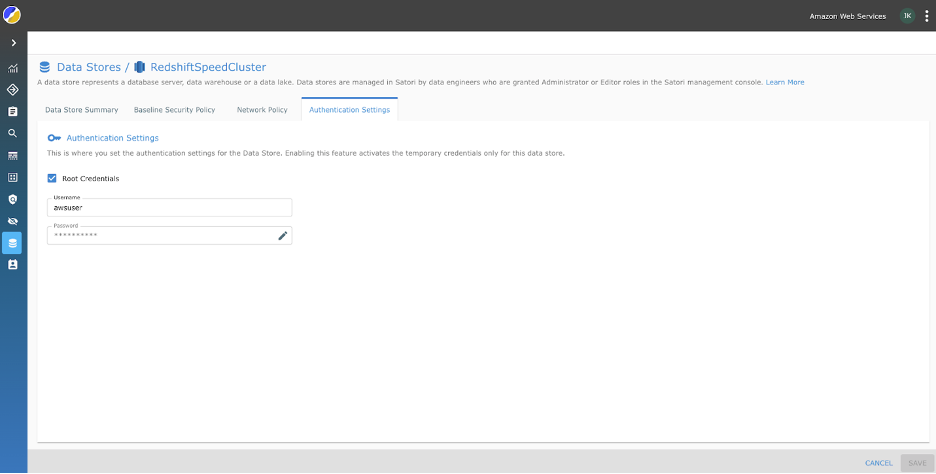
- La resten av fanene stå med standardinnstillingene og velg Spar.
Nå er datalagrene dine klare for tilgang gjennom Satori.
Lag et datasett
Fullfør følgende trinn for å opprette et datasett:
- Velg datasett i navigasjonsruten og velg Legg til nytt datasett.
- Velg datalageret ditt og skriv inn detaljene for datasettet ditt.

Et datasett kan være en samling databaseobjekter som du kategoriserer som et datasett. For Redshift klargjort klynge opprettet vi et kundedatasett med detaljer om databasen og skjemaet. Du kan også velge å fokusere på en bestemt tabell i skjemaet eller til og med ekskludere visse skjemaer eller tabeller fra datasettet.
For Redshift Serverless opprettet vi et datasett som med alle datalagerplasseringer, for å inkludere den delte tabellen og den eksterne tabellen
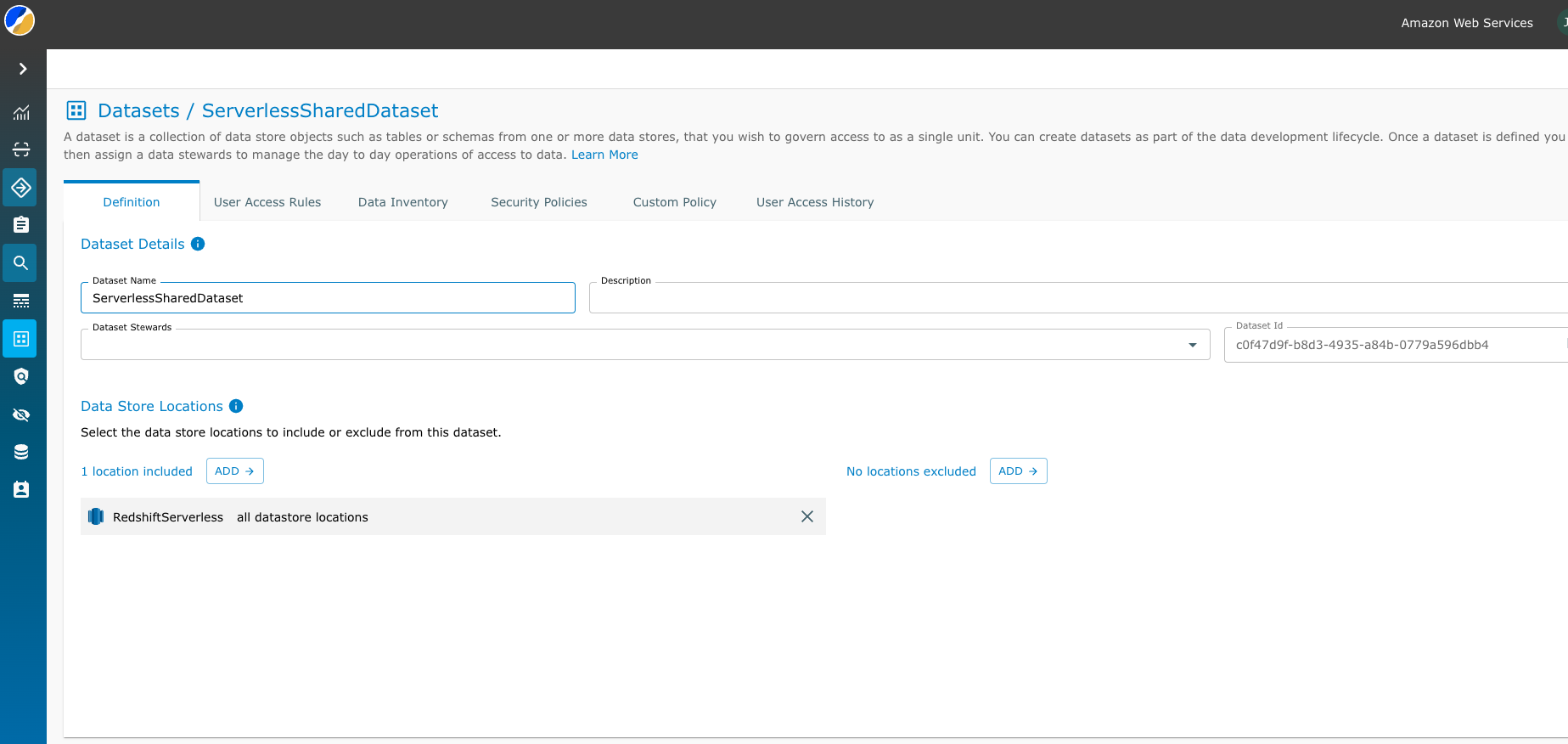
- Velg Spar.
- For hvert datasett, naviger til Regler for brukertilgang og lage retningslinjer for datasettbrukertilgang for rollene vi opprettet.
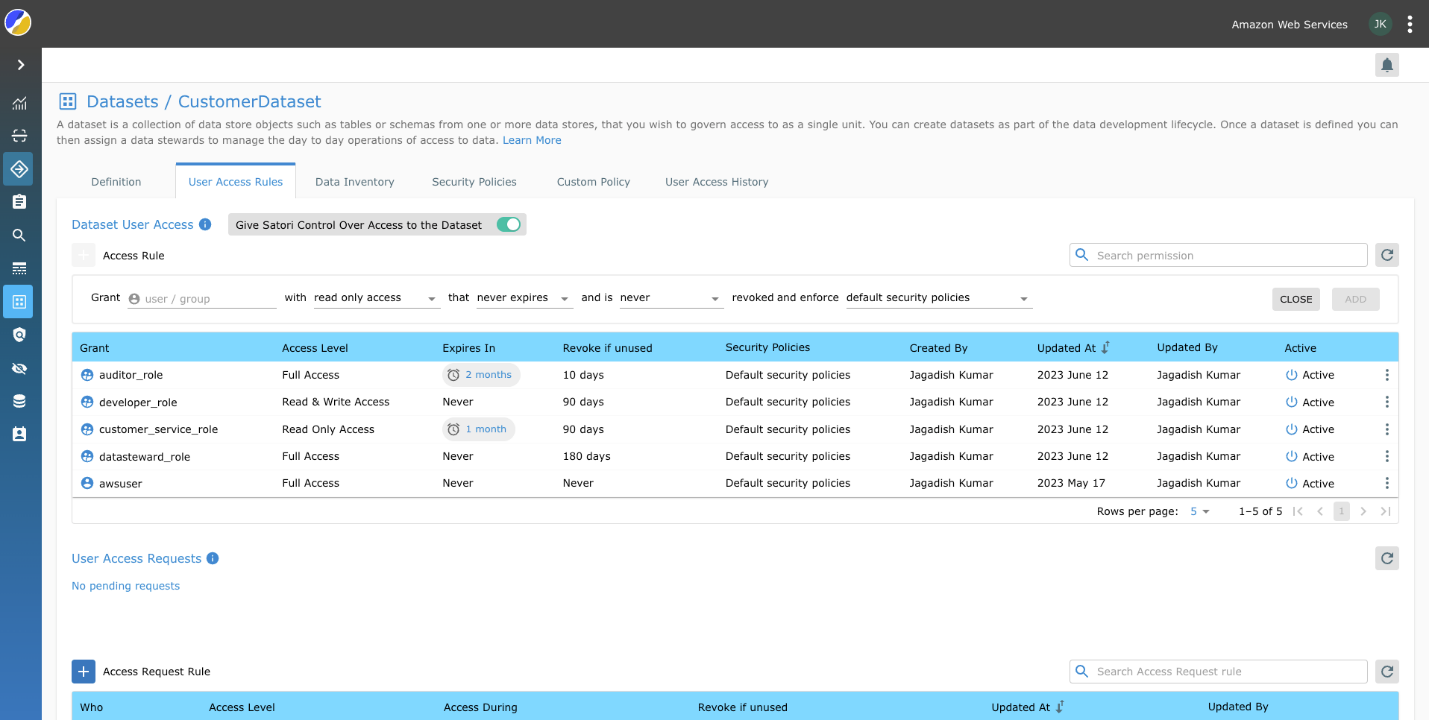
- aktiver Gi Satori kontroll over tilgang til datasettet.
- Eventuelt kan du legge til utløp og tilbakekalle tidskonfigurasjoner i tilgangspolicyene for å begrense hvor lenge tilgang gis til Redshift-klyngen.
Opprett en sikkerhetspolicy for datasettet
Satori tilbyr flere maskeringsprofilmaler som du kan bruke som en grunnlinje og tilpasse før du legger dem til i sikkerhetspolicyene dine. Fullfør følgende trinn for å lage sikkerhetspolicyen din:
- Velg Maskering av profiler i navigasjonsruten og bruk Begrensende retningslinjer mal for å lage en maskeringspolicy.
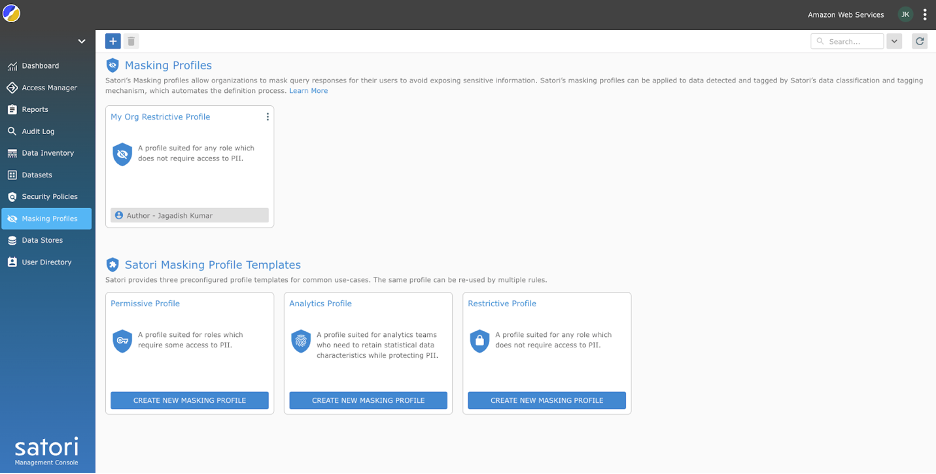
- Oppgi et beskrivende navn for policyen.
- Du kan tilpasse policyen ytterligere for å legge til egendefinerte felt og deres respektive maskeringspolicyer. Følgende eksempel viser tilleggsfeltet Kredittkortnummer som ble lagt til med handlingen for å maskere alt bortsett fra de fire siste karakterene.

- Velg Sikkerhetspolitikk i navigasjonsruten og lag en sikkerhetspolicy kalt Sikkerhetspolicy for kunder.

- Knytt policyen til maskeringsprofilen som ble opprettet i forrige trinn.

- Knytt den opprettede sikkerhetspolicyen til datasettene ved å redigere datasettet og navigere til Sikkerhetspolitikk fanen.

Nå som integrasjon, policy og tilgangskontroller er satt, la oss spørre dataene gjennom DBeaver.
Spør etter sikre data
For å spørre dataene dine, koble til Redshift-klyngen og Redshift Serverless-endepunktet ved å bruke deres respektive Satori-vertsnavn som ble oppnådd tidligere.


Når du spør etter dataene i Redshift-klargjort klynge, vil du se sikkerhetspolicyene brukt på resultatet satt under kjøring.

Når du spør etter dataene i Redshift Serverless endepunkt, vil du se sikkerhetspolicyene brukt på kredittkorttabellen delt fra Redshift-klargjorte klyngen.

Du vil få lignende resultater med retningslinjer som brukes hvis du spør etter den eksterne tabellen i Amazon S3 fra Redshift Serverless endepunkt

Oppsummering
I dette innlegget beskrev vi hvordan Satori kan hjelpe deg med sikker datatilgang fra Redshift-klyngen din uten å kreve endringer i Redshift-dataene, skjemaet eller hvordan brukerne samhandler med data. I del 2 vil vi utforske hvordan du setter opp selvbetjent datatilgang til data lagret i Amazon Redshift med de forskjellige rollene vi opprettet som en del av det første oppsettet.
Satori er tilgjengelig på AWS Marketplace. For å lære mer, start a gratis prøveperiode or be om et demomøte.
Om forfatterne
 Jagadish Kumar er en Senior Analytics Specialist Solutions Architect hos AWS med fokus på Amazon Redshift. Han er dypt lidenskapelig opptatt av dataarkitektur og hjelper kunder med å bygge analyseløsninger i stor skala på AWS.
Jagadish Kumar er en Senior Analytics Specialist Solutions Architect hos AWS med fokus på Amazon Redshift. Han er dypt lidenskapelig opptatt av dataarkitektur og hjelper kunder med å bygge analyseløsninger i stor skala på AWS.
 Lisa Levy er innholdsspesialist hos Satori. Hun publiserer informativt innhold for å effektivt beskrive hvordan Satoris datasikkerhetsplattform øker organisasjonens produktivitet.
Lisa Levy er innholdsspesialist hos Satori. Hun publiserer informativt innhold for å effektivt beskrive hvordan Satoris datasikkerhetsplattform øker organisasjonens produktivitet.
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://aws.amazon.com/blogs/big-data/accelerate-amazon-redshift-secure-data-use-with-satori-part-1/

