Introduksjon
Kjernen datavitenskap ligger statistikk, som har eksistert i århundrer, men som fortsatt er grunnleggende viktig i dagens digitale tidsalder. Hvorfor? Fordi grunnleggende statistikkbegreper er ryggraden i dataanalyse, som gjør oss i stand til å forstå de enorme datamengdene som genereres daglig. Det er som å snakke med data, der statistikk hjelper oss å stille de riktige spørsmålene og forstå historiene data prøver å fortelle.
Fra å forutsi fremtidige trender og ta beslutninger basert på data til å teste hypoteser og måle ytelse, er statistikk verktøyet som driver innsikten bak datadrevne beslutninger. Det er broen mellom rådata og handlingskraftig innsikt, noe som gjør det til en uunnværlig del av datavitenskap.
I denne artikkelen har jeg samlet topp 15 grunnleggende statistikkkonsepter som enhver nybegynner i datavitenskap bør vite!

Innholdsfortegnelse
1. Statistisk utvalg og datainnsamling
Vi vil lære noen grunnleggende statistikkkonsepter, men å forstå hvor dataene våre kommer fra og hvordan vi samler dem er avgjørende før du dykker dypt ned i havet av data. Det er her populasjoner, prøver og ulike prøvetakingsteknikker kommer inn i bildet.
Tenk deg at vi ønsker å vite gjennomsnittshøyden til mennesker i en by. Det er praktisk å måle alle, så vi tar en mindre gruppe (utvalg) som representerer den større befolkningen. Trikset ligger i hvordan vi velger denne prøven. Teknikker som tilfeldig, stratifisert eller klyngeprøver sikrer at utvalget vårt er godt representert, minimerer skjevhet og gjør funnene våre mer pålitelige.
Ved å forstå populasjoner og utvalg kan vi trygt utvide vår innsikt fra utvalget til hele populasjonen, og ta informerte beslutninger uten å måtte undersøke alle.
2. Datatyper og måleskalaer
Data kommer i ulike varianter, og å vite hvilken type data du har å gjøre med er avgjørende for å velge de riktige statistiske verktøyene og teknikkene.
Kvantitative og kvalitative data
- Kvantitativ data: Denne typen data handler om tall. Det er målbart og kan brukes til matematiske beregninger. Kvantitative data forteller oss «hvor mye» eller «hvor mange», som antall brukere som besøker et nettsted eller temperaturen i en by. Det er enkelt og objektivt, og gir et klart bilde gjennom numeriske verdier.
- Kvalitative data: Omvendt omhandler kvalitative data egenskaper og beskrivelser. Det handler om «hvilken type» eller «hvilken kategori». Tenk på det som dataene som beskriver kvaliteter eller egenskaper, for eksempel fargen på en bil eller sjangeren til en bok. Disse dataene er subjektive, basert på observasjoner i stedet for målinger.
Fire målestørrelser
- Nominell skala: Dette er den enkleste formen for måling som brukes for å kategorisere data uten en bestemt rekkefølge. Eksempler inkluderer typer mat, blodgrupper eller nasjonalitet. Det handler om merking uten noen kvantitativ verdi.
- Ordinalskala: Data kan bestilles eller rangeres her, men intervallene mellom verdier er ikke definert. Tenk på en tilfredshetsundersøkelse med alternativer som fornøyd, nøytral og misfornøyd. Den forteller oss rekkefølgen, men ikke avstanden mellom rangeringene.
- Intervallskala: Intervall skalerer ordredata og kvantifiserer forskjellen mellom oppføringer. Det er imidlertid ikke noe faktisk nullpunkt. Et godt eksempel er temperatur i Celsius; forskjellen mellom 10°C og 20°C er den samme som mellom 20°C og 30°C, men 0°C betyr ikke fravær av temperatur.
- Forholdsskala: Den mest informative skalaen har alle egenskapene til en intervallskala pluss et meningsfullt nullpunkt, noe som muliggjør en nøyaktig sammenligning av størrelser. Eksempler inkluderer vekt, høyde og inntekt. Her kan vi si at noe er dobbelt så mye som et annet.
3. Beskrivende statistikk
Forestille beskrivende statistikk som din første date med dataene dine. Det handler om å bli kjent med det grunnleggende, de brede strekene som beskriver det som ligger foran deg. Deskriptiv statistikk har to hovedtyper: sentrale tendens- og variabilitetsmål.
Mål for sentral tendens: Disse er som dataens tyngdepunkt. De gir oss en enkelt verdi som er typisk eller representativ for datasettet vårt.
Mener: Gjennomsnittet beregnes ved å legge sammen alle verdiene og dele på antall verdier. Det er som den totale vurderingen av en restaurant basert på alle anmeldelser. Den matematiske formelen for gjennomsnittet er gitt nedenfor:

Median: Den midterste verdien når dataene er sortert fra minste til største. Hvis antallet observasjoner er partall, er det gjennomsnittet av de to midterste tallene. Den brukes til å finne midtpunktet på en bro.
Hvis n er partall, er medianen gjennomsnittet av de to sentrale tallene.
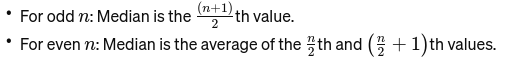
Mode: Det er hyppigst forekommende verdi i et datasett. Tenk på det som den mest populære retten på en restaurant.
Mål for variasjon: Mens mål på sentral tendens bringer oss til sentrum, forteller mål for variasjon oss om spredningen eller spredningen.
Range: Forskjellen mellom høyeste og laveste verdi. Det gir en grunnleggende idé om spredningen.
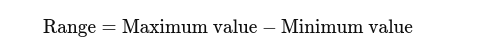
Forskjell: Måler hvor langt hvert tall i settet er fra gjennomsnittet og dermed fra annethvert tall i settet. For en prøve er den beregnet som:
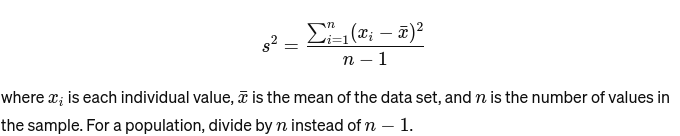
Standardavvik: Kvadratroten av variansen gir et mål på gjennomsnittlig avstand fra gjennomsnittet. Det er som å vurdere konsistensen til en bakers kakestørrelser. Det er representert som:
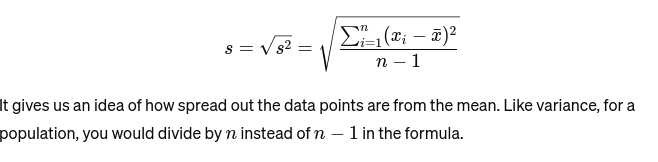
Før vi går til neste grunnleggende statistikkkonsept, her er en Nybegynnerveiledning til statistisk analyse for deg!
4. Datavisualisering
Datavisualisering er kunsten og vitenskapen å fortelle historier med data. Det gjør komplekse resultater fra vår analyse til noe håndgripelig og forståelig. Det er avgjørende for utforskende dataanalyse, der målet er å avdekke mønstre, korrelasjoner og innsikt fra data uten å trekke formelle konklusjoner.
- Diagrammer og grafer: Fra og med det grunnleggende gir stolpediagrammer, linjediagrammer og sektordiagram grunnleggende innsikt i dataene. De er ABC-ene for datavisualisering, avgjørende for enhver dataforteller.
Vi har et eksempel på et stolpediagram (venstre) og et linjediagram (høyre) nedenfor.
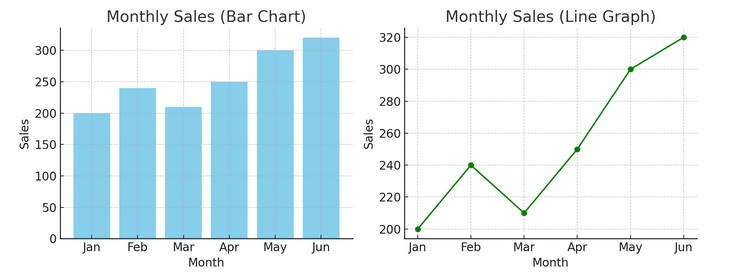
- Avanserte visualiseringer: Når vi dykker dypere, gir varmekart, spredningsplott og histogrammer mulighet for mer nyansert analyse. Disse verktøyene hjelper til med å identifisere trender, distribusjoner og uteliggere.
Nedenfor er et eksempel på et spredningsplott og et histogram

Visualiseringer bygger bro mellom rådata og menneskelig erkjennelse, slik at vi raskt kan tolke og forstå komplekse datasett.
5. Grunnleggende om sannsynlighet
Sannsynlighet er grammatikken til statistikkspråket. Det handler om sjansen eller sannsynligheten for at hendelser skjer. Å forstå begreper i sannsynlighet er avgjørende for å tolke statistiske resultater og gjøre spådommer.
- Uavhengige og avhengige arrangementer:
- Uavhengige arrangementer: En hendelses utfall påvirker ikke en annens utfall. Som å kaste en mynt, endrer ikke oddsen for neste vending å få hodet på en flip.
- Avhengige hendelser: Utfallet av en hendelse påvirker resultatet av en annen. For eksempel, hvis du trekker et kort fra en kortstokk og ikke erstatter det, endres sjansene dine for å trekke et annet spesifikt kort.
Sannsynlighet gir grunnlaget for å trekke slutninger om data og er avgjørende for å forstå statistisk signifikans og hypotesetesting.
6. Vanlige sannsynlighetsfordelinger
Sannsynlighetsfordelinger er som forskjellige arter i statistikkøkosystemet, hver tilpasset sin nisje av applikasjoner.
- Normal distribusjon: Ofte kalt klokkekurven på grunn av formen, er denne fordelingen preget av gjennomsnittet og standardavviket. Det er en vanlig antagelse i mange statistiske tester fordi mange variabler er naturlig fordelt på denne måten i den virkelige verden.
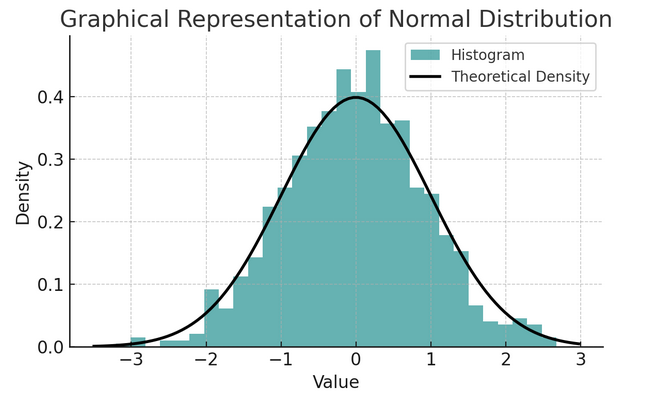
Et sett med regler kjent som den empiriske regelen eller 68-95-99.7 regelen oppsummerer egenskapene til en normalfordeling, som beskriver hvordan data er spredt rundt gjennomsnittet.
68-95-99.7-regel (empirisk regel)
Denne regelen gjelder for en helt normal fordeling og skisserer følgende:
- 68% av dataene faller innenfor ett standardavvik (σ) av gjennomsnittet (μ).
- 95% av dataene faller innenfor to standardavvik av gjennomsnittet.
- Omtrent 99.7% av dataene faller innenfor tre standardavvik fra gjennomsnittet.
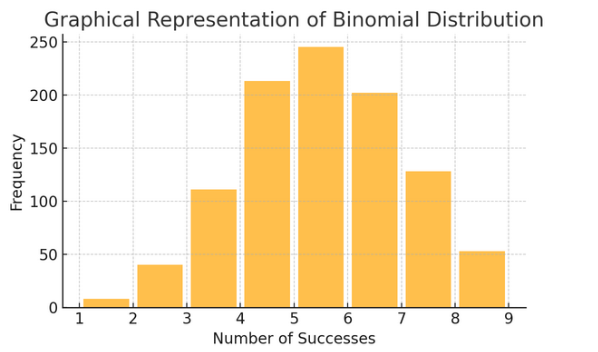
Binomial distribusjon: Denne fordelingen gjelder situasjoner med to utfall (som suksess eller fiasko) gjentatt flere ganger. Det hjelper med å modellere hendelser som å kaste en mynt eller ta en sann/falsk test.
Poisson Distribusjon teller antall ganger noe skjer over et bestemt intervall eller mellomrom. Den er ideell for situasjoner der hendelser skjer uavhengig og konstant, som de daglige e-postene du mottar.
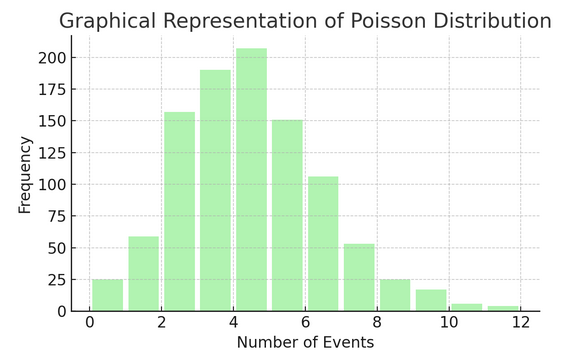
Hver distribusjon har sitt eget sett med formler og egenskaper, og å velge den riktige avhenger av arten av dataene dine og hva du prøver å finne ut. Ved å forstå disse fordelingene kan statistikere og dataforskere modellere fenomener fra den virkelige verden og forutsi fremtidige hendelser nøyaktig.
7. Hypotesetesting
Tenker på hypotesetesting som detektivarbeid i statistikk. Det er en metode for å teste om en bestemt teori om dataene våre kan være sanne. Denne prosessen starter med to motstridende hypoteser:
- Nullhypotese (H0): Dette er standardantakelsen, som antyder at det er effekt eller forskjell. Den sier: "Ikke" ny her."
- Al "alternativ hypotese (H1 eller Ha): Dette utfordrer status quo, og foreslår en effekt eller en forskjell. Den hevder: "Noe er interessant på gang."
Eksempel: Tester om et nytt diettprogram fører til vekttap sammenlignet med å ikke følge noen diett.
- Nullhypotese (H0): Det nye diettprogrammet fører ikke til vekttap (ingen forskjell i vekttap mellom de som følger det nye diettprogrammet og de som ikke gjør det).
- Alternativ hypotese (H1): Det nye diettprogrammet fører til vekttap (en forskjell i vekttap mellom de som følger det og de som ikke gjør det).
Hypotesetesting innebærer å velge mellom disse to basert på bevisene (våre data).
Type I og II feil- og betydningsnivåer:
- Type I-feil: Dette skjer når vi feilaktig avviser nullhypotesen. Den dømmer en uskyldig person.
- Type II feil: Dette skjer når vi ikke klarer å avvise en falsk nullhypotese. Det lar en skyldig person gå fri.
- Signifikansnivå (α): Dette er terskelen for å avgjøre hvor mye bevis som er nok til å forkaste nullhypotesen. Den er ofte satt til 5 % (0.05), noe som indikerer en 5 % risiko for en type I-feil.
8. Konfidensintervaller
Tillitsintervaller gi oss et verdiområde der vi forventer at den gyldige populasjonsparameteren (som et gjennomsnitt eller en andel) faller med et visst konfidensnivå (vanligvis 95 %). Det er som å forutsi et idrettslags sluttresultat med en feilmargin; vi sier: "Vi er 95 % sikre på at den sanne poengsummen vil være innenfor dette området."
Å konstruere og tolke konfidensintervaller hjelper oss å forstå nøyaktigheten av estimatene våre. Jo bredere intervallet er, er estimatet vårt mindre presist, og omvendt.
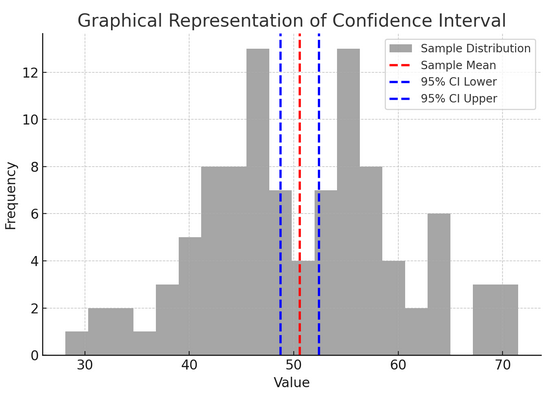
Figuren ovenfor illustrerer konseptet med et konfidensintervall (CI) i statistikk, ved å bruke en utvalgsfordeling og dets 95 % konfidensintervall rundt prøvegjennomsnittet.
Her er en oversikt over de kritiske komponentene i figuren:
- Prøvefordeling (grå histogram): Dette representerer fordelingen av 100 datapunkter tilfeldig generert fra en normalfordeling med et gjennomsnitt på 50 og et standardavvik på 10. Histogrammet viser visuelt hvordan datapunktene er spredt rundt gjennomsnittet.
- Eksempelgjennomsnitt (rød stiplet linje): Denne linjen angir prøvedataenes middelverdi (gjennomsnittlig). Det fungerer som punktestimatet som vi konstruerer konfidensintervallet rundt. I dette tilfellet representerer det gjennomsnittet av alle prøveverdiene.
- 95 % konfidensintervall (blå stiplede linjer): Disse to linjene markerer de nedre og øvre grensene for 95 % konfidensintervallet rundt prøvegjennomsnittet. Intervallet beregnes ved å bruke standardfeilen til gjennomsnittet (SEM) og en Z-score som tilsvarer ønsket konfidensnivå (1.96 for 95 % konfidens). Konfidensintervallet antyder at vi er 95 % sikre på at populasjonsgjennomsnittet ligger innenfor dette området.
9. Korrelasjon og årsakssammenheng
Korrelasjon og årsakssammenheng blir ofte blandet sammen, men de er forskjellige:
- Sammenheng: Indikerer en sammenheng eller assosiasjon mellom to variabler. Når den ene endrer seg, har den andre en tendens til å endre seg også. Korrelasjon måles med en korrelasjonskoeffisient som går fra -1 til 1. En verdi nærmere 1 eller -1 indikerer en sterk sammenheng, mens 0 antyder ingen bindinger.
- Årsakssammenheng: Det innebærer at endringer i en variabel direkte forårsaker endringer i en annen. Det er en mer robust påstand enn korrelasjon og krever streng testing.
Bare fordi to variabler er korrelerte betyr ikke det at den ene forårsaker den andre. Dette er et klassisk tilfelle av ikke å forveksle "korrelasjon" med "årsakssammenheng."
10. Enkel lineær regresjon
Enkelt lineær regresjon er en måte å modellere forholdet mellom to variabler ved å tilpasse en lineær ligning til observerte data. En variabel regnes som en forklarende variabel (uavhengig), og den andre er en avhengig variabel.
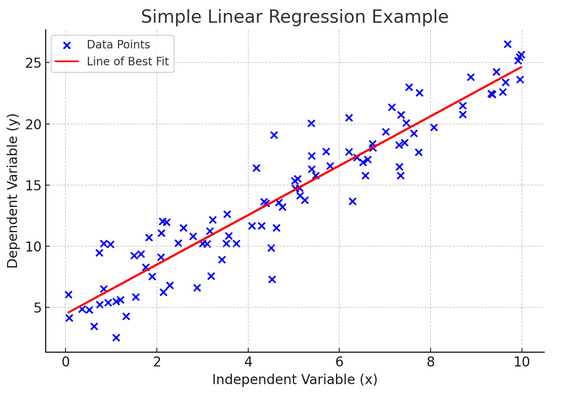
Enkel lineær regresjon hjelper oss å forstå hvordan endringer i den uavhengige variabelen påvirker den avhengige variabelen. Det er et kraftig verktøy for prediksjon og er grunnleggende for mange andre komplekse statistiske modeller. Ved å analysere forholdet mellom to variabler kan vi lage informerte spådommer om hvordan de vil samhandle.
Enkel lineær regresjon antar en lineær sammenheng mellom den uavhengige variabelen (forklaringsvariabelen) og den avhengige variabelen. Hvis forholdet mellom disse to variablene ikke er lineært, kan forutsetningene om enkel lineær regresjon bli krenket, noe som potensielt kan føre til unøyaktige spådommer eller tolkninger. Derfor er det viktig å verifisere et lineært forhold i dataene før du bruker enkel lineær regresjon.
11. Multippel lineær regresjon
Tenk på multippel lineær regresjon som en utvidelse av enkel lineær regresjon. Likevel, i stedet for å prøve å forutsi et utfall med én ridder i skinnende rustning (prediktor), har du et helt lag. Det er som å oppgradere fra en en-til-en basketballkamp til en hel laginnsats, der hver spiller (prediktor) bringer unike ferdigheter. Tanken er å se hvordan flere variabler sammen påvirker et enkelt utfall.
Men med et større team kommer utfordringen med å håndtere relasjoner, kjent som multikollinearitet. Det oppstår når prediktorer er for nær hverandre og deler lignende informasjon. Se for deg to basketballspillere som hele tiden prøver å ta det samme skuddet; de kan komme i veien for hverandre. Regresjon kan gjøre det vanskelig å se hver prediktors unike bidrag, noe som potensielt forvrider vår forståelse av hvilke variabler som er signifikante.
12. Logistisk regresjon
Mens lineær regresjon forutsier kontinuerlige utfall (som temperatur eller priser), logistisk regresjon brukes når resultatet er definitivt (som ja/nei, vinn/tape). Tenk deg å prøve å forutsi om et lag vil vinne eller tape basert på ulike faktorer; logistisk regresjon er din gå-til-strategi.
Den transformerer den lineære ligningen slik at utgangen faller mellom 0 og 1, som representerer sannsynligheten for å tilhøre en bestemt kategori. Det er som å ha en magisk linse som konverterer kontinuerlige poengsum til en klar "denne eller den"-visningen, slik at vi kan forutsi kategoriske utfall.
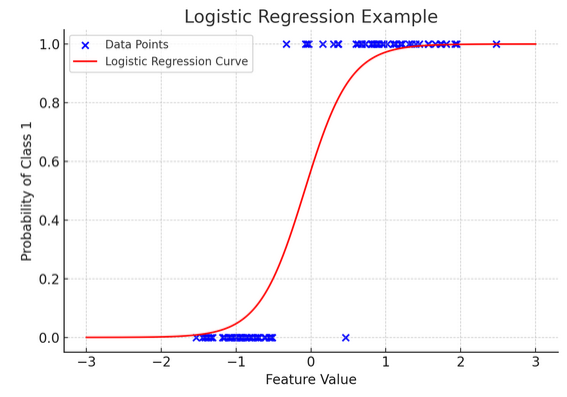
Den grafiske representasjonen illustrerer et eksempel på logistisk regresjon brukt på et syntetisk binært klassifiseringsdatasett. De blå prikkene representerer datapunktene, med deres posisjon langs x-aksen som indikerer funksjonsverdien og y-aksen som indikerer kategorien (0 eller 1). Den røde kurven representerer den logistiske regresjonsmodellens prediksjon av sannsynligheten for å tilhøre klasse 1 (f.eks. «vinn») for ulike funksjonsverdier. Som du kan se, går kurven jevnt over fra sannsynligheten for klasse 0 til klasse 1, noe som viser modellens evne til å forutsi kategoriske utfall basert på et underliggende kontinuerlig trekk. ?
Formelen for logistisk regresjon er gitt av:

Denne formelen bruker den logistiske funksjonen til å transformere den lineære ligningens utgang til en sannsynlighet mellom 0 og 1. Denne transformasjonen lar oss tolke utdataene som sannsynligheter for å tilhøre en bestemt kategori basert på verdien av den uavhengige variabelen xx.
13. ANOVA og Chi-Square tester
ANOVA (Analysis of Variance) og Chi-Square tester er som detektiver i statistikkverdenen, og hjelper oss med å løse forskjellige mysterier. Jegt lar oss sammenligne gjennomsnitt på tvers av flere grupper for å se om minst én er statistisk forskjellig. Tenk på det som å smake på prøver fra flere partier med informasjonskapsler for å finne ut om en batch smaker vesentlig annerledes.
På den annen side brukes Chi-Square-testen for kategoriske data. Det hjelper oss å forstå om det er en signifikant sammenheng mellom to kategoriske variabler. Er det for eksempel en sammenheng mellom en persons favorittmusikksjanger og aldersgruppen? Chi-Square-testen hjelper deg med å svare på slike spørsmål.
14. The Central Limit Theorem og dens betydning i datavitenskap
De Central Limit Theorem (CLT) er et grunnleggende statistisk prinsipp som føles nesten magisk. Den forteller oss at hvis du tar nok prøver fra en populasjon og beregner gjennomsnittene deres, vil disse middelene danne en normalfordeling (klokkekurven), uavhengig av populasjonens opprinnelige fordeling. Dette er utrolig kraftig fordi det lar oss trekke slutninger om populasjoner selv når vi ikke vet deres eksakte fordeling.
Innen datavitenskap underbygger CLT mange teknikker, som gjør det mulig for oss å bruke verktøy designet for normaldistribuerte data selv når dataene våre i utgangspunktet ikke oppfyller disse kriteriene. Det er som å finne en universell adapter for statistiske metoder, noe som gjør mange kraftige verktøy anvendelige i flere situasjoner.
15. Bias-Variance Tradeoff
In prediktiv modellering og maskinlæringden avveining mellom skjevhet og varians er et avgjørende konsept som fremhever spenningen mellom to hovedtyper av feil som kan få modellene våre til å gå galt. Bias refererer til feil fra altfor forenklede modeller som ikke fanger de underliggende trendene godt. Tenk deg å prøve å passe en rett linje gjennom en buet vei; du vil gå glipp av målet. Omvendt fanger variasjoner fra for komplekse modeller opp støy i dataene som om det var et faktisk mønster – som å spore hver eneste vri og snu på en humpete sti, og tro at det er veien videre.
Kunsten ligger i å balansere disse to for å minimere den totale feilen, og finne sweet spot der modellen din er akkurat passe – kompleks nok til å fange de nøyaktige mønstrene, men enkel nok til å ignorere den tilfeldige støyen. Det er som å stemme en gitar; det høres ikke riktig ut hvis det er for stramt eller løst. Avveiningen mellom skjevhet og varians handler om å finne den perfekte balansen mellom disse to. Bias-varians-avveiningen er essensen av å justere våre statistiske modeller for å yte sitt beste når det gjelder å forutsi utfall nøyaktig.
konklusjonen
Fra statistisk prøvetaking til avveiningen av skjevhet og varians, er disse prinsippene ikke bare akademiske forestillinger, men essensielle verktøy for innsiktsfull dataanalyse. De utstyrer ambisiøse dataforskere med ferdighetene til å gjøre store data om til handlingskraftig innsikt, og legger vekt på statistikk som ryggraden i datadrevet beslutningstaking og innovasjon i den digitale tidsalderen.
Har vi savnet noe grunnleggende statistikkkonsept? Gi oss beskjed i kommentarfeltet nedenfor.
Utforsk vår ende til ende statistikkguide for datavitenskap å vite om emnet!
- SEO-drevet innhold og PR-distribusjon. Bli forsterket i dag.
- PlatoData.Network Vertical Generative Ai. Styrk deg selv. Tilgang her.
- PlatoAiStream. Web3 Intelligence. Kunnskap forsterket. Tilgang her.
- PlatoESG. Karbon, CleanTech, Energi, Miljø, Solenergi, Avfallshåndtering. Tilgang her.
- PlatoHelse. Bioteknologisk og klinisk etterretning. Tilgang her.
- kilde: https://www.analyticsvidhya.com/blog/2024/03/basic-statistics-concepts/

