Dit is het tweede bericht in een tweedelige serie waarin ik een praktische gids voor organisaties voorstel, zodat u de kwaliteit van tekstsamenvattingsmodellen voor uw domein kunt beoordelen.
Voor een inleiding tot tekstsamenvattingen, een overzicht van deze tutorial en de stappen om een basislijn voor ons project te maken (ook wel sectie 1 genoemd), raadpleegt u de eerste bericht.
Dit bericht is verdeeld in drie secties:
- Deel 2: Genereer samenvattingen met een zero-shot model
- Deel 3: Een samenvattend model trainen
- Deel 4: Evalueer het getrainde model
Deel 2: Genereer samenvattingen met een zero-shot model
In dit bericht gebruiken we het concept van zero-shot leren (ZSL), wat betekent dat we een model gebruiken dat is getraind om tekst samen te vatten, maar geen voorbeelden heeft gezien van de arXiv-gegevensset. Het is een beetje alsof je probeert een portret te schilderen terwijl je in je leven alleen maar landschapsschilderijen hebt gedaan. Je weet hoe je moet schilderen, maar je bent misschien niet zo bekend met de fijne kneepjes van portretschilderen.
Voor deze sectie gebruiken we het volgende: notitieboekje.
Waarom zero-shot learning?
ZSL is de afgelopen jaren populair geworden omdat je hiermee de modernste NLP-modellen kunt gebruiken zonder training. En hun prestaties zijn soms best verbazingwekkend: de Grote wetenschappelijke onderzoekswerkgroep heeft onlangs hun T0pp-model (uitgesproken als "T Zero Plus Plus") uitgebracht, dat speciaal is getraind voor het onderzoeken van zero-shot multitask-leren. Het kan vaak beter presteren dan modellen die zes keer zo groot zijn op de BIG-bank benchmark, en kan beter presteren dan de GPT-3 (16 keer groter) op verschillende andere NLP-benchmarks.
Een ander voordeel van ZSL is dat er slechts twee regels code nodig zijn om het te gebruiken. Door het uit te proberen, creëren we een tweede basislijn, die we gebruiken om de winst in modelprestaties te kwantificeren nadat we het model op onze dataset hebben verfijnd.
Een zero-shot leerpijplijn opzetten
Om ZSL-modellen te gebruiken, kunnen we Hugging Face's gebruiken Pijplijn-API. Deze API stelt ons in staat om een tekstsamenvattingsmodel te gebruiken met slechts twee regels code. Het zorgt voor de belangrijkste verwerkingsstappen in een NLP-model:
- Bewerk de tekst voor in een formaat dat het model kan begrijpen.
- Geef de voorverwerkte invoer door aan het model.
- Bewerk de voorspellingen van het model na, zodat u ze kunt begrijpen.
Het maakt gebruik van de samenvattende modellen die al beschikbaar zijn op de Hugging Face-model hub.
Voer de volgende code uit om het te gebruiken:
Dat is het! De code downloadt een samenvattingsmodel en maakt lokaal samenvattingen op uw computer. Als je je afvraagt welk model het gebruikt, kun je het opzoeken in de broncode of gebruik het volgende commando:
Wanneer we deze opdracht uitvoeren, zien we dat het standaardmodel voor tekstsamenvatting wordt genoemd sshleifer/distilbart-cnn-12-6:
![]()
We kunnen de vinden model kaart voor dit model op de Hugging Face-website, waar we ook kunnen zien dat het model is getraind op twee datasets: de CNN Dailymail-gegevensset en Extreme samenvatting (XSum) dataset. Het is vermeldenswaard dat dit model niet bekend is met de arXiv-dataset en alleen wordt gebruikt om teksten samen te vatten die vergelijkbaar zijn met degene waarin het is getraind (meestal nieuwsartikelen). De nummers 12 en 6 in de modelnaam verwijzen respectievelijk naar het aantal encoderlagen en decoderlagen. Uitleggen wat deze zijn, valt buiten het bestek van deze tutorial, maar je kunt er meer over lezen in de post Introductie van BART door Sam Shleifer, die het model heeft gemaakt.
In de toekomst gebruiken we het standaardmodel, maar ik raad u aan om verschillende vooraf getrainde modellen uit te proberen. Alle modellen die geschikt zijn voor samenvatting zijn te vinden op de Hugging Face-website. Als u een ander model wilt gebruiken, kunt u de modelnaam opgeven wanneer u de Pipeline-API aanroept:
Extractieve versus abstracte samenvatting
We hebben nog niet gesproken over twee mogelijke maar verschillende benaderingen van tekstsamenvatting: extractief vs abstractief. Extractieve samenvatting is de strategie om uittreksels uit een tekst samen te voegen tot een samenvatting, terwijl abstractie het corpus parafraseert met behulp van nieuwe zinnen. De meeste samenvattingsmodellen zijn gebaseerd op modellen die nieuwe tekst genereren (het zijn modellen voor het genereren van natuurlijke taal, zoals bijvoorbeeld GPT-3). Dit betekent dat de samenvattende modellen ook nieuwe tekst genereren, waardoor ze abstracte samenvattende modellen worden.
Genereer zero-shot samenvattingen
Nu we weten hoe we het moeten gebruiken, willen we het gebruiken in onze testdataset - dezelfde dataset die we in hebben gebruikt sectie 1 basislijn te creëren. We kunnen dat doen met de volgende lus:
We maken gebruik van de min_length en max_length parameters om de samenvatting te bepalen die het model genereert. In dit voorbeeld stellen we min_length tot 5 omdat we willen dat de titel minimaal vijf woorden lang is. En door de referentiesamenvattingen (de eigenlijke titels voor de onderzoekspapers) te schatten, bepalen we dat 20 een redelijke waarde zou kunnen zijn voor max_length. Maar nogmaals, dit is slechts een eerste poging. Wanneer het project zich in de experimenteerfase bevindt, kunnen en moeten deze twee parameters worden gewijzigd om te zien of de modelprestaties veranderen.
Aanvullende parameters
Als u al bekend bent met het genereren van tekst, weet u wellicht dat er veel meer parameters zijn om de tekst die een model genereert te beïnvloeden, zoals zoeken naar bundels, bemonstering en temperatuur. Deze parameters geven u meer controle over de tekst die wordt gegenereerd, bijvoorbeeld om de tekst vloeiender en minder repetitief te maken. Deze technieken zijn niet beschikbaar in de Pipeline API—u kunt zien in de broncode dat min_length en max_length zijn de enige parameters die in aanmerking worden genomen. Nadat we ons eigen model hebben getraind en geïmplementeerd, hebben we echter toegang tot die parameters. Daarover meer in sectie 4 van dit bericht.
Modelevaluatie
Nadat we de nul-shot-samenvattingen hebben gegenereerd, kunnen we onze ROUGE-functie opnieuw gebruiken om de kandidaat-samenvattingen te vergelijken met de referentie-samenvattingen:
Als we deze berekening uitvoeren op de samenvattingen die zijn gegenereerd met het ZSL-model, krijgen we de volgende resultaten:
![]()
Als we die vergelijken met onze basislijn, zien we dat dit ZSL-model eigenlijk slechter presteert dan onze eenvoudige heuristiek om alleen de eerste zin te nemen. Nogmaals, dit is niet onverwacht: hoewel dit model nieuwsartikelen weet samen te vatten, heeft het nog nooit een voorbeeld gezien van het samenvatten van de samenvatting van een academische onderzoekspaper.
Vergelijking basislijn
We hebben nu twee basislijnen gemaakt: een met een eenvoudige heuristiek en een met een ZSL-model. Door de ROUGE-scores te vergelijken, zien we dat de eenvoudige heuristiek momenteel beter presteert dan het deep learning-model.
![]()
In de volgende sectie nemen we hetzelfde deep learning-model en proberen we de prestaties ervan te verbeteren. We doen dit door het te trainen op de arXiv-dataset (deze stap wordt ook wel scherpstellen). We profiteren van het feit dat het al weet hoe tekst in het algemeen moet worden samengevat. Vervolgens laten we veel voorbeelden zien van onze arXiv-dataset. Deep learning-modellen zijn uitzonderlijk goed in het identificeren van patronen in datasets nadat ze erop getraind zijn, dus we verwachten dat het model beter zal worden in deze specifieke taak.
Deel 3: Een samenvattend model trainen
In deze sectie trainen we het model dat we hebben gebruikt voor zero-shot-samenvattingen in sectie 2 (sshleifer/distilbart-cnn-12-6) op onze dataset. Het idee is om het model te leren hoe samenvattingen voor samenvattingen van onderzoekspapers eruit zien door het veel voorbeelden te laten zien. Na verloop van tijd zou het model de patronen in deze dataset moeten herkennen, waardoor het betere samenvattingen kan maken.
Het is de moeite waard om nogmaals op te merken dat als je gegevens hebt gelabeld, namelijk teksten en bijbehorende samenvattingen, je die moet gebruiken om een model te trainen. Alleen zo kan het model de patronen van uw specifieke dataset leren.
De volledige code voor de modeltraining staat hieronder: notitieboekje.
Een trainingstaak instellen
Omdat het trainen van een deep learning-model een paar weken zou duren op een laptop, gebruiken we Amazon Sage Maker in plaats daarvan opleidingsbanen. Voor meer details, zie: Train een model met Amazon SageMaker. In dit bericht benadruk ik kort het voordeel van het gebruik van deze trainingstaken, naast het feit dat ze ons in staat stellen om GPU-rekeninstanties te gebruiken.
Laten we aannemen dat we een cluster van GPU-instanties hebben die we kunnen gebruiken. In dat geval willen we waarschijnlijk een Docker-image maken om de training uit te voeren, zodat we de trainingsomgeving gemakkelijk op andere machines kunnen repliceren. Vervolgens installeren we de benodigde pakketten en omdat we meerdere instances willen gebruiken, moeten we ook gedistribueerde trainingen opzetten. Wanneer de training is voltooid, willen we deze computers snel afsluiten omdat ze duur zijn.
Bij het gebruik van opleidingstaken worden al deze stappen van ons weggenomen. In feite kunnen we een model op dezelfde manier trainen als beschreven door de trainingsparameters op te geven en dan slechts één methode aan te roepen. SageMaker zorgt voor de rest, inclusief het stoppen van de GPU-instanties wanneer de training is voltooid, om geen verdere kosten te maken.
Daarnaast hebben Hugging Face en AWS eerder in 2022 een samenwerking aangekondigd die het nog makkelijker maakt om Hugging Face-modellen op SageMaker te trainen. Deze functionaliteit is beschikbaar door de ontwikkeling van Hugging Face AWS diepe leercontainers (DLC's). Deze containers bevatten Hugging Face Transformers, Tokenizers en de Datasets-bibliotheek, waardoor we deze bronnen kunnen gebruiken voor trainings- en inferentietaken. Voor een lijst met beschikbare DLC-afbeeldingen, zie available Hugging Face Deep Learning Containers-afbeeldingen. Ze worden onderhouden en regelmatig bijgewerkt met beveiligingspatches. We kunnen veel voorbeelden vinden van hoe Hugging Face-modellen te trainen met deze DLC's en de Knuffelend gezicht Python SDK in de volgende GitHub repo.
We gebruiken een van die voorbeelden als een sjabloon omdat het bijna alles doet wat we nodig hebben voor ons doel: een samenvattend model trainen op een specifieke dataset op een gedistribueerde manier (met behulp van meer dan één GPU-instantie).
Eén ding waar we echter rekening mee moeten houden, is dat dit voorbeeld een dataset rechtstreeks uit de Hugging Face-datasethub gebruikt. Omdat we onze eigen aangepaste gegevens willen leveren, moeten we de notebook iets aanpassen.
Gegevens doorgeven aan de trainingstaak
Om rekening te houden met het feit dat we onze eigen dataset meebrengen, moeten we gebruik maken van kanalen. Voor meer informatie, zie: Hoe Amazon SageMaker trainingsinformatie biedt.
Ik vind deze term persoonlijk een beetje verwarrend, dus in mijn hoofd denk ik altijd in kaart brengen wanneer ik hoor kanalen, omdat het me helpt beter te visualiseren wat er gebeurt. Laat het me uitleggen: zoals we al hebben geleerd, draait de opleidingsbaan een cluster van Amazon Elastic Compute-cloud (Amazon EC2) instances en kopieert er een Docker-image naar. Onze datasets worden echter opgeslagen in: Amazon eenvoudige opslagservice (Amazon S3) en is niet toegankelijk voor die Docker-afbeelding. In plaats daarvan moet de trainingstaak de gegevens van Amazon S3 naar een predef kopiëren
lokaal in die Docker-image. De manier waarop het dat doet, is door ons de trainingstaak te vertellen waar de gegevens zich in Amazon S3 bevinden en waar op de Docker-afbeelding de gegevens naartoe moeten worden gekopieerd, zodat de trainingstaak er toegang toe heeft. Wij kaart de Amazon S3-locatie met het lokale pad.
We stellen het lokale pad in de hyperparameters-sectie van de trainingstaak in:
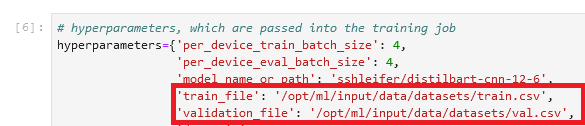
Vervolgens vertellen we de trainingstaak waar de gegevens zich bevinden in Amazon S3 bij het aanroepen van de fit()-methode, die de training start:
![]()
Merk op dat de mapnaam na /opt/ml/input/data komt overeen met de kanaalnaam (datasets). Hierdoor kan de trainingstaak de gegevens van Amazon S3 naar het lokale pad kopiëren.
Start de training
We zijn nu klaar om te beginnen met de opleidingsopdracht. Zoals eerder vermeld, doen we dit door te bellen met de fit() methode. De trainingstaak duurt ongeveer 40 minuten. U kunt de voortgang volgen en aanvullende informatie bekijken op de SageMaker-console.
![]()
Wanneer de trainingstaak is voltooid, is het tijd om ons nieuw getrainde model te evalueren.
Deel 4: Evalueer het getrainde model
Het evalueren van ons getrainde model lijkt erg op wat we deden in sectie 2, waar we het ZSL-model evalueerden. We noemen het model en genereren kandidaat-samenvattingen en vergelijken deze met de referentie-samenvattingen door de ROUGE-scores te berekenen. Maar nu zit het model in Amazon S3 in een bestand met de naam model.tar.gz (om de exacte locatie te vinden, kunt u de trainingstaak op de console controleren). Dus hoe krijgen we toegang tot het model om samenvattingen te genereren?
We hebben twee opties: implementeer het model op een SageMaker-eindpunt of download het lokaal, vergelijkbaar met wat we deden in sectie 2 met het ZSL-model. In deze tutorial, ik het model implementeren op een SageMaker-eindpunt omdat het handiger is en door een krachtiger exemplaar voor het eindpunt te kiezen, kunnen we de inferentietijd aanzienlijk verkorten. De GitHub-repo bevat een notitieboekje dat laat zien hoe het model lokaal kan worden geëvalueerd.
Een model implementeren
Het is meestal heel eenvoudig om een getraind model op SageMaker te implementeren (zie nogmaals het volgende voorbeeld op GitHub van Hugging Face). Nadat het model is getraind, kunnen we bellen: estimator.deploy() en SageMaker doet de rest voor ons op de achtergrond. Omdat we in onze tutorial overschakelen van de ene notebook naar de andere, moeten we eerst de trainingstaak en het bijbehorende model lokaliseren, voordat we het kunnen implementeren:
![]()
Nadat we de modellocatie hebben opgehaald, kunnen we deze implementeren op een SageMaker-eindpunt:
Implementatie op SageMaker is eenvoudig omdat het gebruikmaakt van de SageMaker Toolkit voor knuffelgezichtsinferentie, een open-sourcebibliotheek voor het aanbieden van Transformers-modellen op SageMaker. Normaal gesproken hoeven we niet eens een inferentiescript op te geven; daar zorgt de toolkit voor. In dat geval maakt de toolkit echter weer gebruik van de Pipeline API, en zoals we in sectie 2 hebben besproken, staat de Pipeline API ons niet toe om geavanceerde technieken voor het genereren van tekst te gebruiken, zoals zoeken en bemonsteren van bundels. Om deze beperking te vermijden, bieden we onze aangepast inferentiescript.
Eerste evaluatie
Voor de eerste evaluatie van ons nieuw getrainde model gebruiken we dezelfde parameters als in sectie 2 met het zero-shot-model om de kandidaat-samenvattingen te genereren. Dit maakt het mogelijk om een appel-tot-appels vergelijking te maken:
We vergelijken de door het model gegenereerde samenvattingen met de referentiesamenvattingen:
![]()
Dit is bemoedigend! Onze eerste poging om het model te trainen, zonder enige hyperparameter-afstemming, heeft de ROUGE-scores aanzienlijk verbeterd.
![]()
Tweede evaluatie
Nu is het tijd om wat meer geavanceerde technieken te gebruiken, zoals het zoeken naar bundels en bemonstering, om met het model te spelen. Voor een gedetailleerde uitleg wat elk van deze parameters doet, zie: Hoe tekst te genereren: verschillende decoderingsmethoden gebruiken voor het genereren van talen met Transformers. Laten we het proberen met een semi-willekeurige set waarden voor enkele van deze parameters:
Wanneer we ons model met deze parameters uitvoeren, krijgen we de volgende scores:
![]()
Dat ging niet helemaal zoals we hadden gehoopt - de ROUGE-scores zijn zelfs iets gedaald. Laat dit u echter niet ontmoedigen om verschillende waarden voor deze parameters uit te proberen. In feite is dit het punt waar we eindigen met de opstartfase en de overgang naar de experimenteerfase van het project.
Conclusie en volgende stappen
We hebben de opstelling voor de experimenteerfase afgerond. In deze tweedelige serie hebben we onze gegevens gedownload en voorbereid, een baseline gemaakt met een eenvoudige heuristiek, een nieuwe baseline gemaakt met behulp van zero-shot learning, en vervolgens ons model getraind en een aanzienlijke prestatieverbetering gezien. Nu is het tijd om te spelen met elk onderdeel dat we hebben gemaakt om nog betere samenvattingen te maken. Stel je de volgende situatie voor:
- De gegevens op de juiste manier voorverwerken – Verwijder bijvoorbeeld stopwoorden en leestekens. Onderschat dit onderdeel niet: in veel datawetenschapsprojecten is de voorverwerking van gegevens een van de belangrijkste aspecten (zo niet het belangrijkste), en datawetenschappers besteden doorgaans het grootste deel van hun tijd aan deze taak.
- Probeer verschillende modellen uit – In onze tutorial hebben we het standaardmodel gebruikt voor samenvattingen (
sshleifer/distilbart-cnn-12-6) doel nog veel meer modellen zijn beschikbaar die u voor deze taak kunt gebruiken. Een daarvan past misschien beter bij uw gebruiksscenario. - Hyperparameter-afstemming uitvoeren – Bij het trainen van het model hebben we een bepaalde set hyperparameters gebruikt (leersnelheid, aantal epochs, enzovoort). Deze parameters zijn niet in steen gebeiteld, integendeel. U moet deze parameters wijzigen om te begrijpen hoe ze de prestaties van uw model beïnvloeden.
- Gebruik verschillende parameters voor het genereren van tekst – We hebben al een ronde gedaan met het maken van samenvattingen met verschillende parameters om het zoeken en bemonsteren van de bundel te gebruiken. Probeer verschillende waarden en parameters uit. Voor meer informatie, zie: Hoe tekst te genereren: verschillende decoderingsmethoden gebruiken voor het genereren van talen met Transformers.
Ik hoop dat je het einde hebt gehaald en deze tutorial nuttig vond.
Over de auteur
![]() Heiko Hotz is Senior Solutions Architect voor AI & Machine Learning en leidt de Natural Language Processing (NLP)-gemeenschap binnen AWS. Voorafgaand aan deze functie was hij Head of Data Science voor Amazon's EU Customer Service. Heiko helpt onze klanten om succesvol te zijn in hun AI/ML-reis op AWS en heeft met organisaties in veel sectoren gewerkt, waaronder verzekeringen, financiële diensten, media en entertainment, gezondheidszorg, nutsbedrijven en productie. In zijn vrije tijd reist Heiko zoveel mogelijk.
Heiko Hotz is Senior Solutions Architect voor AI & Machine Learning en leidt de Natural Language Processing (NLP)-gemeenschap binnen AWS. Voorafgaand aan deze functie was hij Head of Data Science voor Amazon's EU Customer Service. Heiko helpt onze klanten om succesvol te zijn in hun AI/ML-reis op AWS en heeft met organisaties in veel sectoren gewerkt, waaronder verzekeringen, financiële diensten, media en entertainment, gezondheidszorg, nutsbedrijven en productie. In zijn vrije tijd reist Heiko zoveel mogelijk.
- Coinsmart. Europa's beste Bitcoin- en crypto-uitwisseling.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. GRATIS TOEGANG.
- CryptoHawk. Altcoin-radar. Gratis proefversie.
- Bron: https://aws.amazon.com/blogs/machine-learning/part-2-set-up-a-text-summarization-project-with-hugging-face-transformers/

