Het creëren van robuuste en herbruikbare machine learning (ML)-pijplijnen kan een complex en tijdrovend proces zijn. Ontwikkelaars testen hun verwerkings- en trainingsscripts meestal lokaal, maar de pijplijnen zelf worden meestal in de cloud getest. Het creëren en uitvoeren van een volledige pijplijn tijdens het experimenteren voegt ongewenste overhead en kosten toe aan de ontwikkelingslevenscyclus. In dit bericht beschrijven we hoe u kunt gebruiken Lokale modus van Amazon SageMaker Pipelines om ML-pijplijnen lokaal uit te voeren om zowel de ontwikkeling van de pijplijn als de looptijd te verminderen en tegelijkertijd de kosten te verlagen. Nadat de pijplijn volledig lokaal is getest, kunt u deze eenvoudig opnieuw uitvoeren met Amazon Sage Maker beheerde resources met slechts een paar regels codewijzigingen.
Overzicht van de ML-levenscyclus
Een van de belangrijkste drijfveren voor nieuwe innovaties en toepassingen in ML is de beschikbaarheid en hoeveelheid gegevens, samen met goedkopere rekenopties. In verschillende domeinen heeft ML bewezen in staat te zijn problemen op te lossen die voorheen onoplosbaar waren met klassieke big data en analytische technieken, en de vraag naar datawetenschap en ML-beoefenaars neemt gestaag toe. Vanaf een zeer hoog niveau bestaat de ML-levenscyclus uit veel verschillende onderdelen, maar het bouwen van een ML-model bestaat meestal uit de volgende algemene stappen:
- Gegevens opschonen en voorbereiden (feature engineering)
- Modeltraining en tuning
- Modelevaluatie
- Modelimplementatie (of batchtransformatie)
In de gegevensvoorbereidingsstap worden gegevens geladen, gemasseerd en omgezet in het type invoer of functies dat het ML-model verwacht. Het schrijven van de scripts om de gegevens te transformeren is typisch een iteratief proces, waarbij snelle feedbackloops belangrijk zijn om de ontwikkeling te versnellen. Het is normaal gesproken niet nodig om de volledige dataset te gebruiken bij het testen van feature-engineeringscripts, daarom kunt u de lokale modus functie van SageMaker-verwerking. Hierdoor kunt u lokaal uitvoeren en de code iteratief bijwerken met een kleinere dataset. Wanneer de definitieve code gereed is, wordt deze verzonden naar de externe verwerkingstaak, die de volledige gegevensset gebruikt en wordt uitgevoerd op door SageMaker beheerde instanties.
Het ontwikkelingsproces is vergelijkbaar met de stap voor gegevensvoorbereiding voor zowel modeltraining als modelevaluatiestappen. Datawetenschappers gebruiken de lokale modus functie van SageMaker Training om snel te kunnen herhalen met kleinere gegevenssets lokaal, voordat alle gegevens worden gebruikt in een door SageMaker beheerd cluster van voor ML geoptimaliseerde instanties. Dit versnelt het ontwikkelingsproces en elimineert de kosten van het uitvoeren van door SageMaker beheerde ML-instanties tijdens het experimenteren.
Naarmate de ML-volwassenheid van een organisatie toeneemt, kunt u: Amazon SageMaker-pijpleidingen om ML-pijplijnen te maken die deze stappen aan elkaar koppelen, waardoor complexere ML-workflows worden gecreëerd die ML-modellen verwerken, trainen en evalueren. SageMaker Pipelines is een volledig beheerde service voor het automatiseren van de verschillende stappen van de ML-workflow, waaronder het laden van gegevens, gegevenstransformatie, modeltraining en -afstemming en modelimplementatie. Tot voor kort kon je je scripts lokaal ontwikkelen en testen, maar moest je je ML-pipelines in de cloud testen. Dit maakte het herhalen van de stroom en vorm van ML-pijpleidingen een langzaam en kostbaar proces. Nu, met de toegevoegde lokale modus-functie van SageMaker Pipelines, kunt u uw ML-pipelines herhalen en testen op dezelfde manier als hoe u uw verwerkings- en trainingsscripts test en itereert. U kunt uw pijplijnen uitvoeren en testen op uw lokale computer, met behulp van een kleine subset van gegevens om de pijplijnsyntaxis en -functionaliteiten te valideren.
SageMaker-pijpleidingen
SageMaker Pipelines biedt een volledig geautomatiseerde manier om eenvoudige of complexe ML-workflows uit te voeren. Met SageMaker Pipelines kunt u ML-workflows maken met een gebruiksvriendelijke Python SDK en vervolgens uw workflow visualiseren en beheren met Amazon SageMaker Studio. Uw data science-teams kunnen efficiënter werken en sneller schalen door de workflowstappen die u in SageMaker Pipelines maakt op te slaan en opnieuw te gebruiken. U kunt ook kant-en-klare sjablonen gebruiken die het maken van infrastructuur en opslagplaatsen automatiseren om modellen binnen uw ML-omgeving te bouwen, testen, registreren en implementeren. Deze sjablonen zijn automatisch beschikbaar voor uw organisatie en worden ingericht met AWS-servicecatalogus producten.
SageMaker Pipelines brengt continue integratie en continue implementatie (CI/CD)-praktijken naar ML, zoals het handhaven van pariteit tussen ontwikkel- en productieomgevingen, versiebeheer, on-demand testen en end-to-end automatisering, waarmee u ML in uw hele organisatie. DevOps-beoefenaars weten dat enkele van de belangrijkste voordelen van het gebruik van CI/CD-technieken een verhoging van de productiviteit via herbruikbare componenten en een verhoging van de kwaliteit door geautomatiseerde tests zijn, wat leidt tot een snellere ROI voor uw bedrijfsdoelstellingen. Deze voordelen zijn nu beschikbaar voor MLOps-beoefenaars door SageMaker Pipelines te gebruiken om de training, het testen en de implementatie van ML-modellen te automatiseren. Met de lokale modus kunt u nu veel sneller itereren terwijl u scripts ontwikkelt voor gebruik in een pijplijn. Merk op dat lokale pijplijninstanties niet kunnen worden bekeken of uitgevoerd binnen de Studio IDE; er zullen echter binnenkort extra weergave-opties voor lokale pijpleidingen beschikbaar zijn.
De SageMaker SDK biedt een algemeen doel configuratie lokale modus waarmee ontwikkelaars ondersteunde processors en schatters in hun lokale omgeving kunnen uitvoeren en testen. U kunt training in de lokale modus gebruiken met meerdere door AWS ondersteunde framework-images (TensorFlow, MXNet, Chainer, PyTorch en Scikit-Learn), evenals met images die u zelf aanlevert.
SageMaker Pipelines, dat een Directed Acyclic Graph (DAG) van georkestreerde workflowstappen bouwt, ondersteunt veel activiteiten die deel uitmaken van de ML-levenscyclus. In de lokale modus worden de volgende stappen ondersteund:
- Taakstappen verwerken – Een vereenvoudigde, beheerde ervaring op SageMaker om workloads voor gegevensverwerking uit te voeren, zoals functie-engineering, gegevensvalidatie, modelevaluatie en modelinterpretatie
- Trainingstaakstappen – Een iteratief proces dat een model leert om voorspellingen te doen door voorbeelden uit een trainingsdataset te presenteren
- Taken voor het afstemmen van hyperparameters – Een geautomatiseerde manier om de hyperparameters te evalueren en te selecteren die het meest nauwkeurige model opleveren
- Voorwaardelijke uitvoeringsstappen – Een stap die een voorwaardelijke reeks vertakkingen in een pijplijn biedt
- Model stap: – Met behulp van CreateModel-argumenten kan deze stap een model maken voor gebruik in transformatiestappen of latere implementatie als eindpunt
- Taakstappen transformeren – Een batchtransformatietaak die voorspellingen genereert uit grote datasets en gevolgtrekkingen uitvoert wanneer een persistent eindpunt niet nodig is
- Mislukte stappen – Een stap die een pijplijnuitvoering stopt en de uitvoering als mislukt markeert
Overzicht oplossingen
Onze oplossing demonstreert de essentiële stappen voor het maken en uitvoeren van SageMaker-pijplijnen in de lokale modus, wat inhoudt dat lokale CPU, RAM en schijfbronnen worden gebruikt om de werkstroomstappen te laden en uit te voeren. Uw lokale omgeving kan op een laptop worden uitgevoerd met behulp van populaire IDE's zoals VSCode of PyCharm, of deze kan worden gehost door SageMaker met behulp van klassieke notebook-instanties.
Met de lokale modus kunnen datawetenschappers stappen samenvoegen, waaronder verwerkings-, trainings- en evaluatietaken, en de volledige workflow lokaal uitvoeren. Als u klaar bent met lokaal testen, kunt u de pijplijn opnieuw uitvoeren in een door SageMaker beheerde omgeving door de LocalPipelineSession object met PipelineSession, wat zorgt voor consistentie in de ML-levenscyclus.
Voor dit notebookvoorbeeld gebruiken we een standaard openbaar beschikbare dataset, de UCI Machine Learning Abalone-gegevensset. Het doel is om een ML-model te trainen om de leeftijd van een abalone slak te bepalen aan de hand van zijn fysieke metingen. In de kern is dit een regressieprobleem.
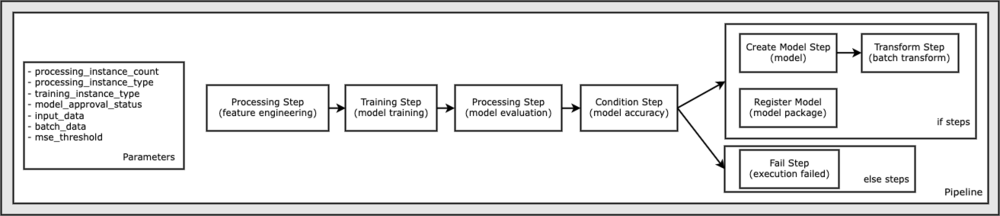
Alle code die nodig is om dit notebookvoorbeeld uit te voeren, is beschikbaar op GitHub in de amazon-sagemaker-voorbeelden opslagplaats. In dit notebookvoorbeeld wordt elke werkstroomstap voor de pijplijn afzonderlijk gemaakt en vervolgens met elkaar verbonden om de pijplijn te maken. We maken de volgende stappen:
- Verwerkingsstap (functie-engineering)
- Trainingsstap (modeltraining)
- Verwerkingsstap (modelevaluatie)
- Conditiestap (modelnauwkeurigheid)
- Modelstap maken (model)
- Transformatiestap (batchtransformatie)
- Modelstap registreren (modelpakket)
- Mislukte stap (uitvoering mislukt)
Het volgende diagram illustreert onze pijplijn.
Voorwaarden
Om dit bericht te volgen, heb je het volgende nodig:
Nadat aan deze vereisten is voldaan, kunt u het voorbeeldnotitieblok uitvoeren zoals beschreven in de volgende secties.
Bouw uw pijplijn
In dit notebookvoorbeeld gebruiken we SageMaker-scriptmodus voor de meeste ML-processen, wat betekent dat we de eigenlijke Python-code (scripts) leveren om de activiteit uit te voeren en een verwijzing naar deze code doorgeven. De scriptmodus biedt een grote flexibiliteit om het gedrag binnen de SageMaker-verwerking te controleren, doordat u uw code kunt aanpassen terwijl u toch profiteert van vooraf gebouwde SageMaker-containers zoals XGBoost of Scikit-Learn. De aangepaste code wordt naar een Python-scriptbestand geschreven met behulp van cellen die beginnen met het magische commando %%writefile, zoals het volgende:
%%writefile code/evaluation.py
De primaire enabler van de lokale modus is de LocalPipelineSession object, dat is geïnstantieerd vanuit de Python SDK. De volgende codesegmenten laten zien hoe u een SageMaker-pijplijn maakt in de lokale modus. Hoewel u voor veel van de lokale pijplijnstappen een lokaal gegevenspad kunt configureren, is Amazon S3 de standaardlocatie om de gegevensuitvoer door de transformatie op te slaan. De nieuwe LocalPipelineSession object wordt doorgegeven aan de Python SDK in veel van de SageMaker-workflow-API-aanroepen die in dit bericht worden beschreven. Merk op dat u de kunt gebruiken local_pipeline_session variabele om verwijzingen naar de S3-standaardbucket en de huidige regionaam op te halen.
Voordat we de afzonderlijke pijplijnstappen maken, stellen we enkele parameters in die door de pijplijn worden gebruikt. Sommige van deze parameters zijn letterlijke tekenreeksen, terwijl andere worden gemaakt als speciale opgesomde typen die door de SDK worden geleverd. De genummerde typering zorgt ervoor dat geldige instellingen worden verstrekt aan de pijplijn, zoals deze, die wordt doorgegeven aan de ConditionLessThanOrEqualTo stap verder naar beneden:
mse_threshold = ParameterFloat(name="MseThreshold", default_value=7.0)
Om een gegevensverwerkingsstap te maken, die hier wordt gebruikt om feature-engineering uit te voeren, gebruiken we de SKLearnProcessor om de dataset te laden en te transformeren. We passeren de local_pipeline_session variabele aan de klassenconstructor, die de werkstroomstap instrueert om in de lokale modus uit te voeren:
Vervolgens maken we onze eerste daadwerkelijke pijplijnstap, a ProcessingStep object, zoals geïmporteerd uit de SageMaker SDK. De processorargumenten worden geretourneerd door een aanroep naar de SKLearnProcessor run() methode. Deze werkstroomstap wordt gecombineerd met andere stappen aan het einde van de notebook om de volgorde van bewerking binnen de pijplijn aan te geven.
Vervolgens bieden we code om een trainingsstap vast te stellen door eerst een standaardschatter te instantiëren met behulp van de SageMaker SDK. We passeren hetzelfde local_pipeline_session variabele naar de schatter, genaamd xgb_train, als de sagemaker_session argument. Omdat we een XGBoost-model willen trainen, moeten we een geldige afbeeldings-URI genereren door de volgende parameters op te geven, inclusief het framework en verschillende versieparameters:
We kunnen optioneel extra schattermethoden aanroepen, bijvoorbeeld set_hyperparameters(), om hyperparameterinstellingen voor de trainingstaak op te geven. Nu we een schatter hebben geconfigureerd, zijn we klaar om de daadwerkelijke trainingsstap te maken. Nogmaals, we importeren de TrainingStep klasse uit de SageMaker SDK-bibliotheek:
Vervolgens bouwen we nog een verwerkingsstap om modelevaluatie uit te voeren. Dit doe je door een ScriptProcessor instantie en het passeren van de local_pipeline_session object als parameter:
Om de inzet van het getrainde model mogelijk te maken, hetzij naar een SageMaker realtime eindpunt of voor een batchtransformatie, moeten we een maken Model object door de modelartefacten, de juiste afbeeldings-URI en optioneel onze aangepaste inferentiecode door te geven. We geven dit dan door Model bezwaar maken tegen een ModelStep, die wordt toegevoegd aan de lokale pijplijn. Zie de volgende code:
Vervolgens maken we een batchtransformatiestap waarbij we een set kenmerkvectoren indienen en gevolgtrekkingen uitvoeren. We moeten eerst een maken Transformer object en geef de . door local_pipeline_session parameter eraan. Dan maken we een TransformStep, geef de vereiste argumenten door en voeg dit toe aan de pijplijndefinitie:
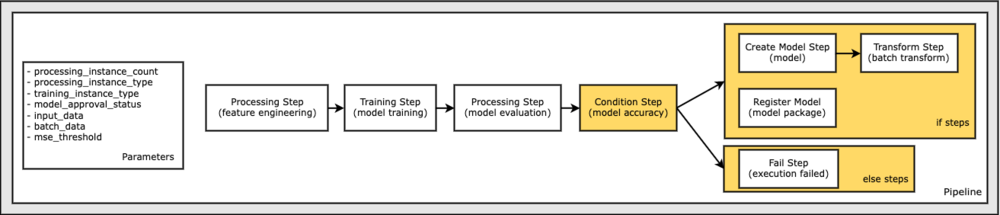
Ten slotte willen we een vertakkingsvoorwaarde aan de workflow toevoegen, zodat we alleen batchtransformatie uitvoeren als de resultaten van modelevaluatie aan onze criteria voldoen. We kunnen deze voorwaarde aangeven door a . toe te voegen ConditionStep met een bepaald type voorwaarde, zoals ConditionLessThanOrEqualTo. Vervolgens sommen we de stappen voor de twee takken op, waarbij we in wezen de if/else- of true/false-takken van de pijplijn definiëren. De if_steps in de ConditionStep (stap_create_model, stap_transform) worden uitgevoerd wanneer de voorwaarde evalueert tot True.
Het volgende diagram illustreert deze voorwaardelijke vertakking en de bijbehorende if/else-stappen. Er wordt slechts één vertakking uitgevoerd, gebaseerd op de uitkomst van de modelevaluatiestap in vergelijking met de voorwaardestap.
Nu we al onze stappen hebben gedefinieerd en de onderliggende klasseninstanties hebben gemaakt, kunnen we ze combineren in een pijplijn. We bieden enkele parameters en bepalen de volgorde van bewerking door de stappen eenvoudig in de gewenste volgorde op te sommen. Merk op dat de TransformStep wordt hier niet weergegeven omdat dit het doel is van de voorwaardelijke stap en is opgegeven als stapargument voor de ConditionalStep eerder.
Om de pijplijn uit te voeren, moet u twee methoden aanroepen: pipeline.upsert(), die de pijplijn uploadt naar de onderliggende service, en pipeline.start(), waarmee de pijplijn wordt gestart. U kunt verschillende andere methoden gebruiken om de uitvoeringsstatus op te vragen, de pijplijnstappen weer te geven en meer. Omdat we de pijplijnsessie in de lokale modus hebben gebruikt, worden deze stappen allemaal lokaal op uw processor uitgevoerd. De celuitvoer onder de startmethode toont de uitvoer van de pijplijn:
U zou een bericht onder aan de celuitvoer moeten zien, vergelijkbaar met het volgende:
Pipeline execution d8c3e172-089e-4e7a-ad6d-6d76caf987b7 SUCCEEDED
Terugkeren naar beheerde resources
Nadat we hebben bevestigd dat de pijplijn zonder fouten werkt en we tevreden zijn met de stroom en vorm van de pijplijn, kunnen we de pijplijn opnieuw maken, maar met door SageMaker beheerde bronnen en deze opnieuw uitvoeren. De enige wijziging die nodig is, is het gebruik van de PipelineSession object in plaats van LocalPipelineSession:
oppompen van sagemaker.workflow.pipeline_context importeert LocalPipelineSessionfrom sagemaker.workflow.pipeline_context import PipelineSession
local_pipeline_session = LocalPipelineSession()pipeline_session = PipelineSession()
Dit informeert de service om elke stap uit te voeren die verwijst naar dit sessieobject op door SageMaker beheerde bronnen. Gezien de kleine wijziging, illustreren we alleen de vereiste codewijzigingen in de volgende codecel, maar dezelfde wijziging zou op elke cel moeten worden geïmplementeerd met behulp van de local_pipeline_session object. De wijzigingen zijn echter identiek in alle cellen, omdat we alleen de vervangen local_pipeline_session object met de pipeline_session voorwerp.
Nadat het lokale sessieobject overal is vervangen, maken we de pijplijn opnieuw en voeren we deze uit met door SageMaker beheerde bronnen:
Opruimen
Als u de Studio-omgeving netjes wilt houden, kunt u de volgende methoden gebruiken om de SageMaker-pijplijn en het model te verwijderen. De volledige code is te vinden in het voorbeeld notitieboekje.
Conclusie
Tot voor kort kon u de lokale modusfunctie van SageMaker Processing en SageMaker Training gebruiken om uw verwerkings- en trainingsscripts lokaal te herhalen, voordat u ze op alle gegevens uitvoert met door SageMaker beheerde bronnen. Met de nieuwe lokale modusfunctie van SageMaker Pipelines kunnen ML-beoefenaars nu dezelfde methode toepassen bij het itereren van hun ML-pipelines, waarbij de verschillende ML-workflows aan elkaar worden genaaid. Wanneer de pijplijn klaar is voor productie, zijn er slechts een paar regels codewijzigingen nodig om deze te laten werken met door SageMaker beheerde bronnen. Dit verkort de looptijd van de pijplijn tijdens de ontwikkeling, wat leidt tot een snellere ontwikkeling van de pijplijn met snellere ontwikkelingscycli, terwijl de kosten van door SageMaker beheerde resources worden verlaagd.
Voor meer informatie, bezoek Amazon SageMaker-pijpleidingen or Gebruik SageMaker-pijplijnen om uw taken lokaal uit te voeren.
Over de auteurs
 Paul Hargis heeft zijn inspanningen gericht op machine learning bij verschillende bedrijven, waaronder AWS, Amazon en Hortonworks. Hij vindt het leuk om technologische oplossingen te bouwen en mensen te leren hoe ze er het beste van kunnen maken. Voorafgaand aan zijn functie bij AWS was hij hoofdarchitect voor Amazon Exports and Expansions en hielp hij amazon.com de ervaring voor internationale shoppers te verbeteren. Paul helpt klanten graag om hun machine learning-initiatieven uit te breiden om echte problemen op te lossen.
Paul Hargis heeft zijn inspanningen gericht op machine learning bij verschillende bedrijven, waaronder AWS, Amazon en Hortonworks. Hij vindt het leuk om technologische oplossingen te bouwen en mensen te leren hoe ze er het beste van kunnen maken. Voorafgaand aan zijn functie bij AWS was hij hoofdarchitect voor Amazon Exports and Expansions en hielp hij amazon.com de ervaring voor internationale shoppers te verbeteren. Paul helpt klanten graag om hun machine learning-initiatieven uit te breiden om echte problemen op te lossen.
 Nicolas Palm is Solutions Architect bij AWS in Stockholm, Zweden, waar hij klanten in heel Scandinavië helpt om succesvol te zijn in de cloud. Hij is vooral gepassioneerd door serverloze technologieën samen met IoT en machine learning. Naast zijn werk is Niklas een fervent langlaufer en snowboarder en een meester-eierkoker.
Nicolas Palm is Solutions Architect bij AWS in Stockholm, Zweden, waar hij klanten in heel Scandinavië helpt om succesvol te zijn in de cloud. Hij is vooral gepassioneerd door serverloze technologieën samen met IoT en machine learning. Naast zijn werk is Niklas een fervent langlaufer en snowboarder en een meester-eierkoker.
 Kirit Tadaka is een ML Solutions Architect die werkt in het SageMaker Service SA-team. Voordat hij bij AWS kwam, werkte Kirit in AI-startups in een vroeg stadium, gevolgd door enige tijd consulting in verschillende rollen in AI-onderzoek, MLOps en technisch leiderschap.
Kirit Tadaka is een ML Solutions Architect die werkt in het SageMaker Service SA-team. Voordat hij bij AWS kwam, werkte Kirit in AI-startups in een vroeg stadium, gevolgd door enige tijd consulting in verschillende rollen in AI-onderzoek, MLOps en technisch leiderschap.

