Amazon roodverschuiving is het snelste, meest gebruikte, volledig beheerde cloud datawarehouse op petabyte-schaal. Tienduizenden klanten gebruiken Amazon Redshift om elke dag exabytes aan gegevens te verwerken om hun analytische werklasten te ondersteunen. Data-engineers, data-analisten en datawetenschappers willen deze data gebruiken om analytische werklasten aan te sturen, zoals business intelligence (BI), voorspellende analyses, machine learning (ML) en realtime streaming-analyses.
Informatica Intelligente gegevensbeheercloud™ (IDMC) is een AI-aangedreven, metadata-gedreven, persona-gebaseerd, cloud-native platform om dataprofessionals in staat te stellen uitgebreide en samenhangende cloud-databeheermogelijkheden te bieden voor het ontdekken, catalogiseren, opnemen, opschonen, integreren, beheren, beveiligen, voorbereiden en stamgegevens. Informatica Data Loader voor Amazon Redshift, beschikbaar op de AWS-beheerconsole, is een kosteloze, serverloze IDMC-service die het probleemloos laden van gegevens naar Amazon Redshift mogelijk maakt.
Klanten moeten snel en op grote schaal data uit verschillende datastores kunnen halen, waaronder on-premises en legacy-systemen, applicaties van derden en AWS-services zoals Amazon relationele databaseservice (Amazone RDS), Amazon DynamoDB, en meer. Je hebt ook een eenvoudige, gebruiksvriendelijke en cloud-native oplossing nodig om snel nieuwe gegevensbronnen aan boord te krijgen of om recente gegevens te analyseren voor bruikbare inzichten. Nu, met Informatica Data Loader voor Amazon Redshift, kunt u via een eenvoudige en begeleide interface veilig verbinding maken met en data laden naar Amazon Redshift op schaal. U hebt rechtstreeks toegang tot Informatica Data Loader vanuit de Amazon Redshift-console.
Dit bericht bevat stapsgewijze instructies om gegevens in Amazon Redshift te laden met behulp van Informatica Data Loader.
Overzicht oplossingen
U hebt rechtstreeks toegang tot Informatica Data Loader vanuit het navigatievenster op de Amazon Redshift-console. Het proces volgt een vergelijkbare workflow die Amazon Redshift-gebruikers al gebruiken om toegang te krijgen tot de Amazon Redshift-query-editor om SQL-query's te schrijven en te organiseren, of om datashares te maken om live data in alleen-lezen modus te delen met clusters.
Voor dit bericht gebruiken we een Salesforce-ontwikkelaarsaccount als gegevensbron. Zie voor instructies voor het importeren van een voorbeeldgegevensset Importeer voorbeeldaccountgegevens. U kunt meer dan 30 kant-en-klare connectoren gebruiken die worden ondersteund door Informatica-services om verbinding te maken met de gegevensbron van uw keuze.
We gebruiken Informatica Data Loader om in drie eenvoudige stappen een subset van Salesforce-objecten te selecteren en naar Amazon Redshift te laden:
- Maak verbinding met de gegevensbron.
- Maak verbinding met de doelgegevensbron.
- Plan of voer het laden van gegevens uit.
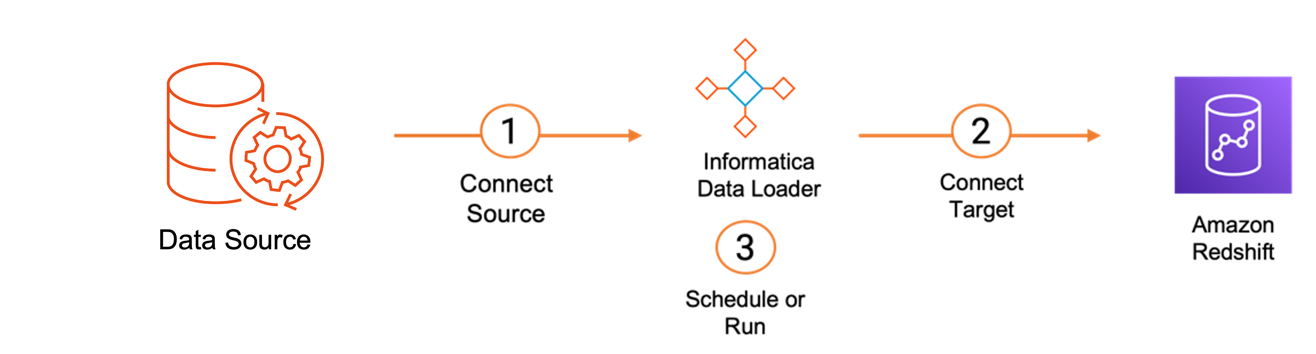
Naast filtering op objectniveau ondersteunt de service ook volledige en incrementele belasting, change data capture (CDC), op kolommen en rijen gebaseerde filtering en schema-afwijkingen. Nadat de gegevens zijn geladen, kunt u een query uitvoeren en visualisaties genereren met Amazon Redshift Query Editor v2.0.
Voorwaarden
Voltooi de volgende vereisten:
- Maak een Amazon Redshift-cluster of -werkgroep. Voor meer informatie, zie Een cluster maken in een VPC or Amazon Redshift Serverloos.
- Zorg ervoor dat het cluster toegankelijk is vanuit Informatica Data Loader. Voeg voor een privécluster een ingangsregel toe aan de beveiligingsgroep die aan uw cluster is gekoppeld om verkeer van Informatica Data Loader toe te staan. Zet het IP-adres op de toegestane lijst voor toegang tot het cluster vanuit Informatica Data Loader. Voor meer informatie over het toevoegen van regels aan een Amazon Elastic Compute-cloud (Amazon EC2) beveiligingsgroep, zie Autoriseer inkomend verkeer voor uw Linux-instanties.
- Maak een Amazon eenvoudige opslagservice (Amazon S3) bucket in dezelfde regio als de Amazon Redshift-cluster. De Informatica Data Loader plaatst de gegevens in deze bucket voordat de gegevens naar het cluster worden geüpload. Verwijzen naar Een bucket maken voor meer details. Noteer de toegangssleutel-ID en de geheime toegangssleutel voor de gebruiker met toestemming om naar de staging S3-bucket te schrijven.
- Als u geen Salesforce-account hebt, kan dat meld je aan voor een gratis ontwikkelaarsaccount.
Nu u aan de vereisten hebt voldaan, gaan we aan de slag.
Start Informatica Data Loader vanuit de Amazon Redshift-console
Voer de volgende stappen uit om Informatica Data Loader te starten:
- Op de Amazon Redshift-console, onder AWS-partnerintegratie kies in het navigatievenster Informatica-gegevenslader.
- In het pop-upvenster Creëer Informatica-integratie, kiezen Volledige Informatica-integratie.
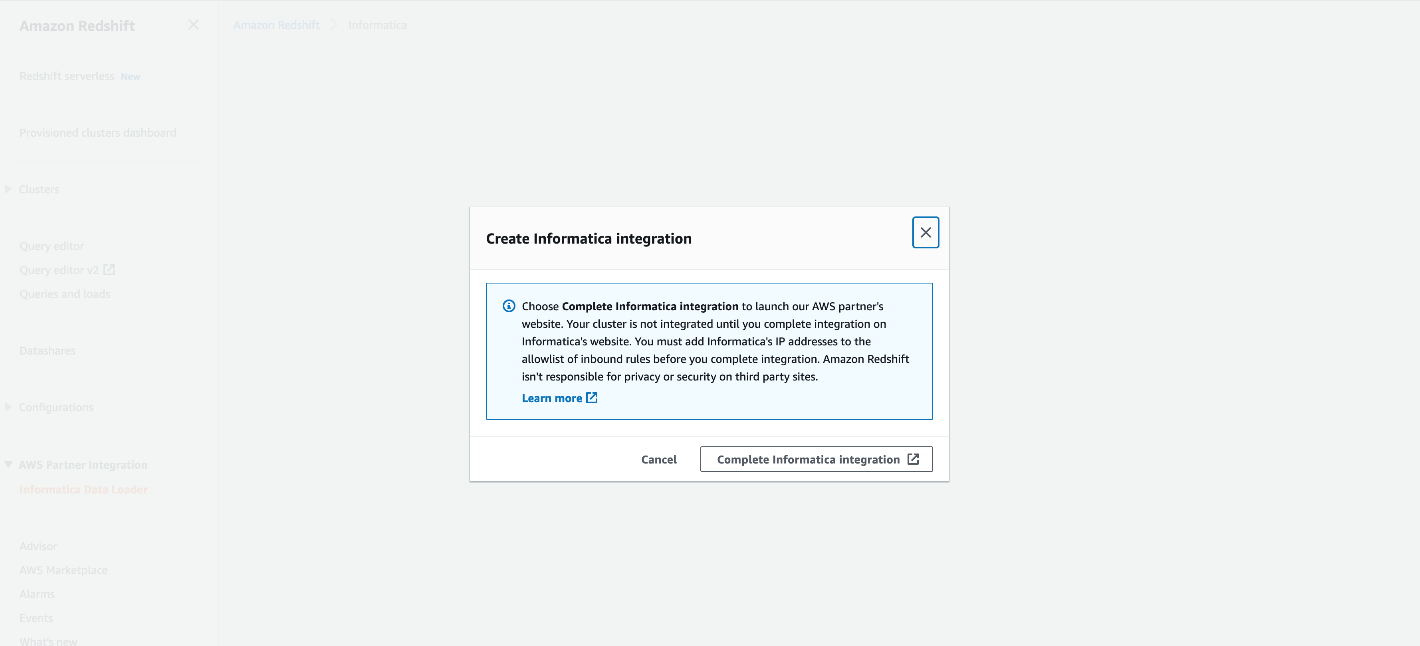 Als u de gratis Informatica Data Loader voor het eerst gebruikt, wordt u doorverwezen naar de Informatica Data Loader voor Amazon Redshift om u gratis aan te melden. Je hebt alleen je e-mailadres nodig om je aan te melden.
Als u de gratis Informatica Data Loader voor het eerst gebruikt, wordt u doorverwezen naar de Informatica Data Loader voor Amazon Redshift om u gratis aan te melden. Je hebt alleen je e-mailadres nodig om je aan te melden. - Nadat u zich heeft aangemeld, kunt u zich aanmelden bij uw Informatica-account.
Maak verbinding met een gegevensbron
Voer de volgende stappen uit om verbinding te maken met een gegevensbron:
- Kies op de Informatica Data Loader-console New in het navigatievenster.
- Kies Nieuwe verbinding.
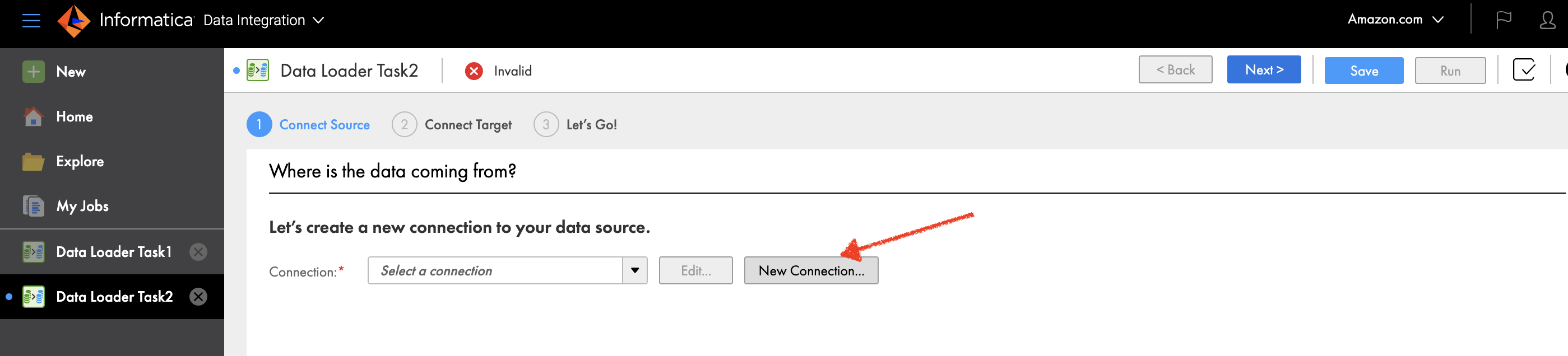
- Kies Salesforce als uw bronverbinding.
- Kies voortzetten.

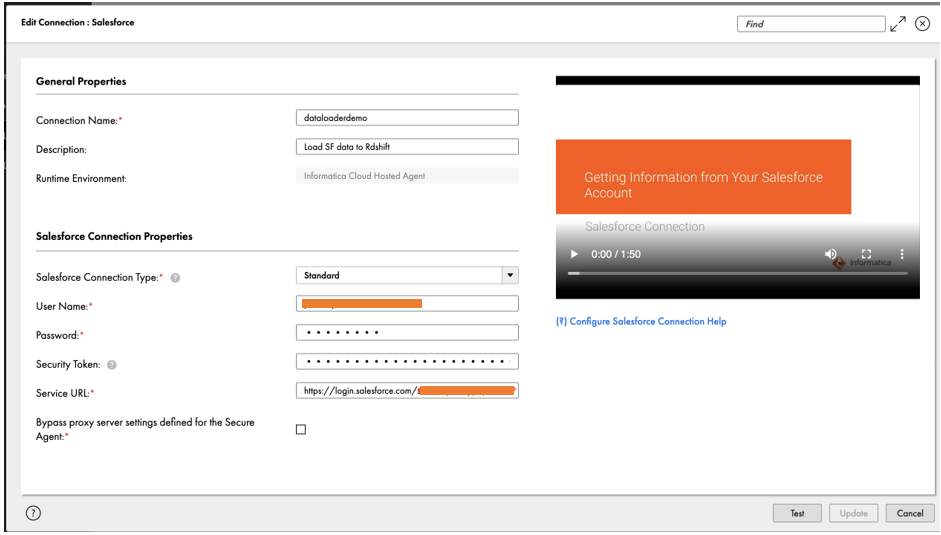
- Onder Algemene eigenschappen, voer een naam in voor uw verbinding en een optionele beschrijving.
- Onder Salesforce-verbindingseigenschappen¸ voer de inloggegevens voor uw Salesforce-account en beveiligingstoken in. Deze opties kunnen variëren afhankelijk van het brontype, het verbindingstype en de authenticatiemethode. Voor hulp kunt u de ingesloten hulpvideo voor verbindingsconfiguratie gebruiken.
- Noteer de naam van de verbinding
Salesforce_Source_Connection. - Kies test om de verbinding te verifiëren.
- Kies Toevoegen om uw verbindingsdetails op te slaan en door te gaan met het instellen van de gegevenslader. Nu u verbinding hebt gemaakt met de Salesforce-gegevensbron, laadt u de voorbeeldaccountgegevens naar Amazon Redshift. Voor deze post laden we het Account-object met onder andere informatie over klanttype en factureringsstaat of -provincie.
- Zorg ervoor dat
Salesforce_Source_Connectiondie u zojuist hebt gemaakt, is geselecteerd als Aansluiting. - Om het Account-object in Salesforce te filteren, selecteert u Voeg wat toe voor Definieer Voorwerp.
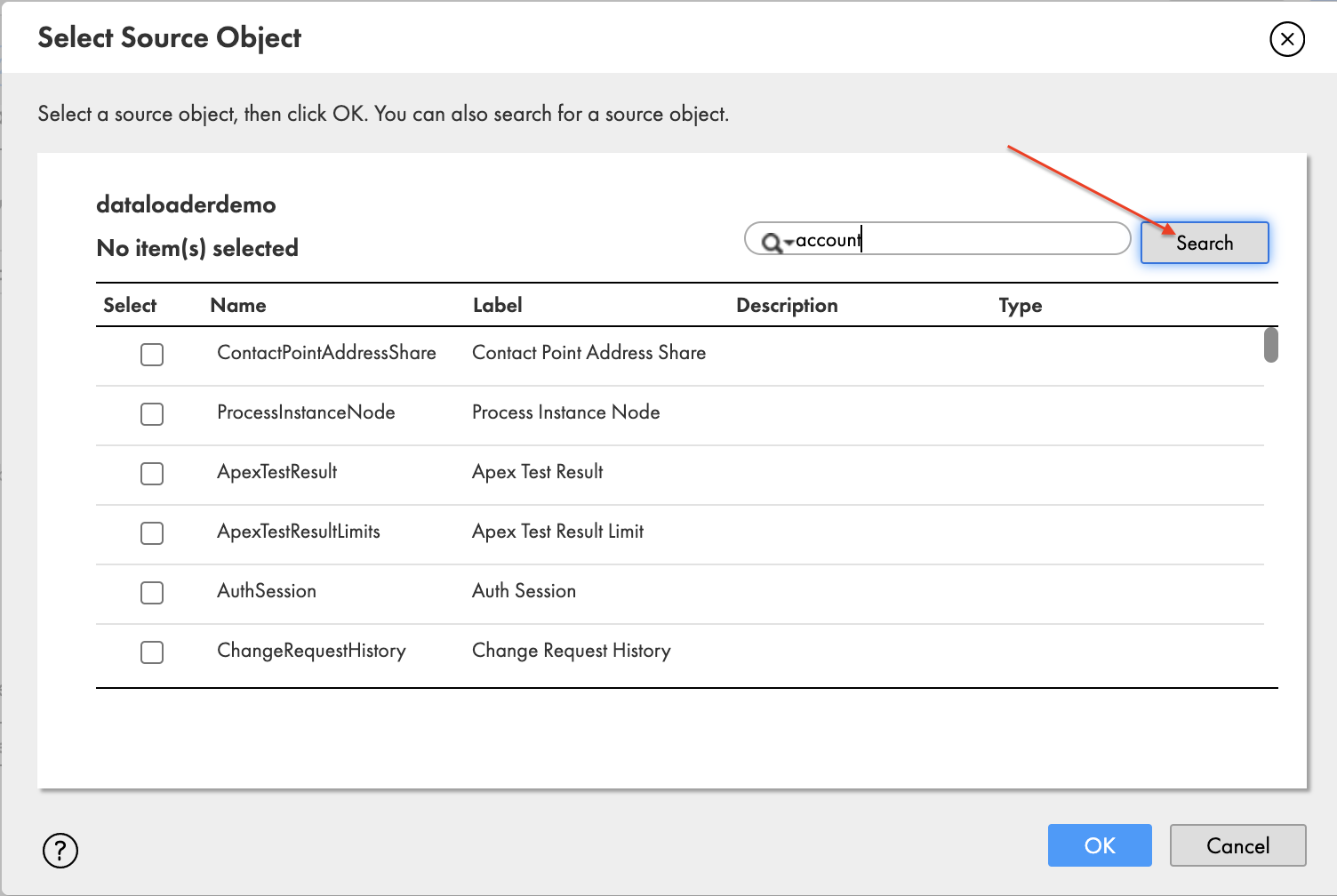
- Kies het plusteken om het bronobject Account te selecteren.
- In het pop-upvenster Selecteer Bronobject, zoek naar account en kies Ontdek.
- kies Account En kies OK.
- Voor dit bericht worden de rest van de volgende instellingen overgelaten aan hun standaardwaarde:
- Velden uitsluiten – Bronvelden uitsluiten van de brongegevens.
- Definieer filters – Filter rijen uit brongegevens op basis van een of meer gespecificeerde filters.
- Definieer primaire sleutels – Configuratie om de primaire sleutelkolom in de gegevensbron te specificeren of te detecteren.
- Watermerkvelden definiëren – Configuratie om de watermerkkolom in de gegevensbron te specificeren of te detecteren.

Maak verbinding met de doelgegevensbron
Voer de volgende stappen uit om verbinding te maken met de doelgegevensbron (Amazon Redshift):
- Kies op de Informatica Data Loader Verbind doel.
- Kies Nieuwe verbinding.
- Voor Aansluiting, kiezen Roodverschuiving (Amazon Redshift v2).
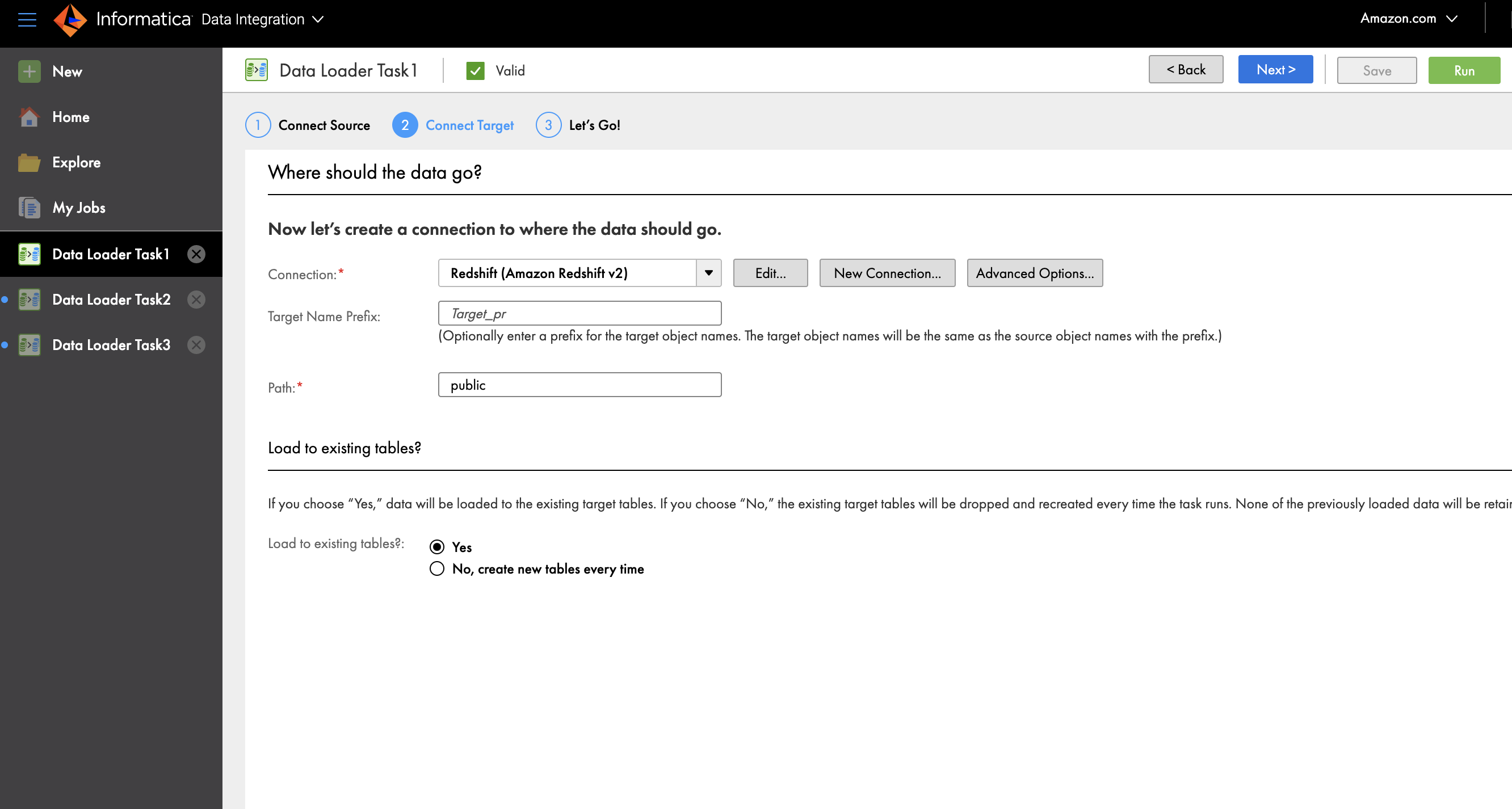
- Geef een verbindingsnaam en optionele beschrijving op.
- Onder Amazon Redshift-verbindingssectie, voert u uw toegangssleutel-ID, geheime toegangssleutel en de JDBC-URL van uw ingerichte cluster of serverloze werkgroep in.
- Kies test om de connectiviteit te verifiëren.
- Nadat de verbinding tot stand is gebracht, kiest u Toevoegen.
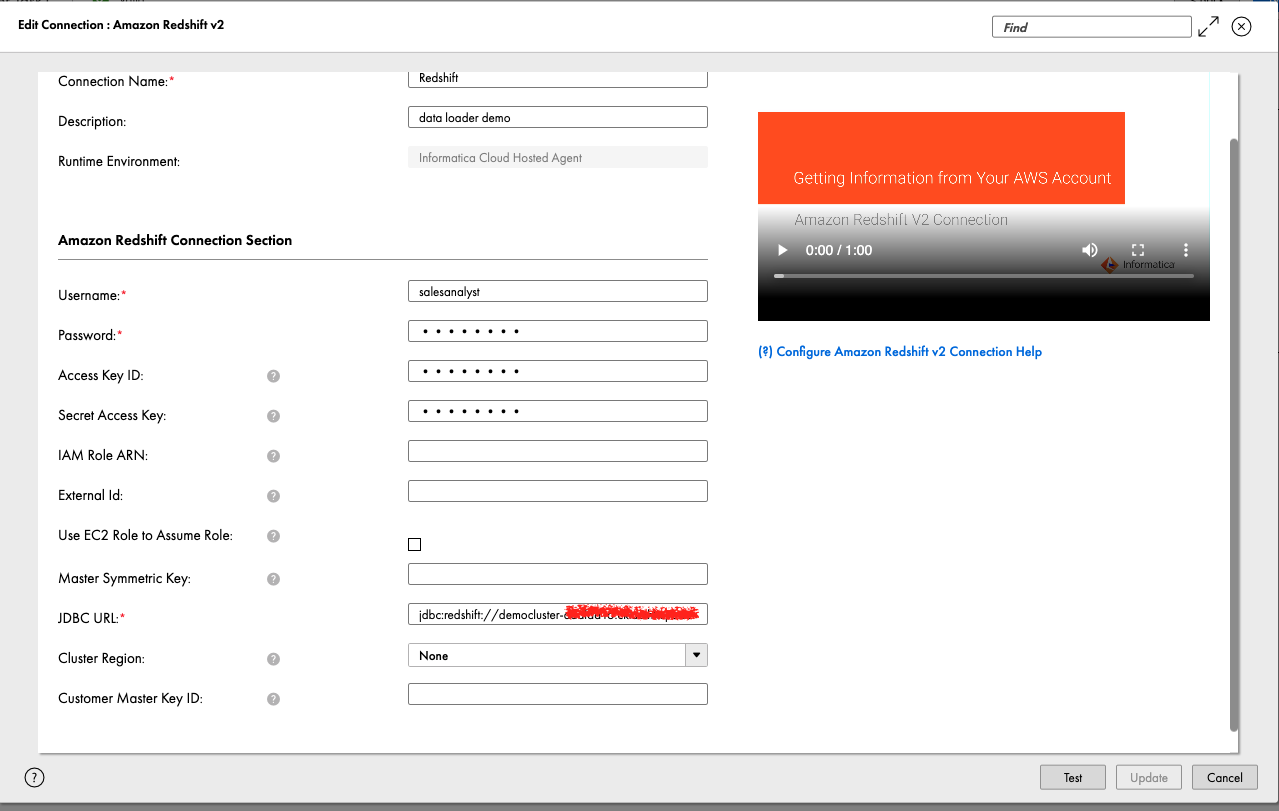
- Optioneel, voor Voorvoegsel doelnaam, voer het voorvoegsel in waaraan de objectnaam moet worden toegevoegd.
- Voor Pad, voer de schemanaam openbaar in Amazon Redshift in waar u de gegevens wilt laden.
- Voor Laden naar bestaande tabellenselecteer Nee, maak elke keer nieuwe tabellen aan.
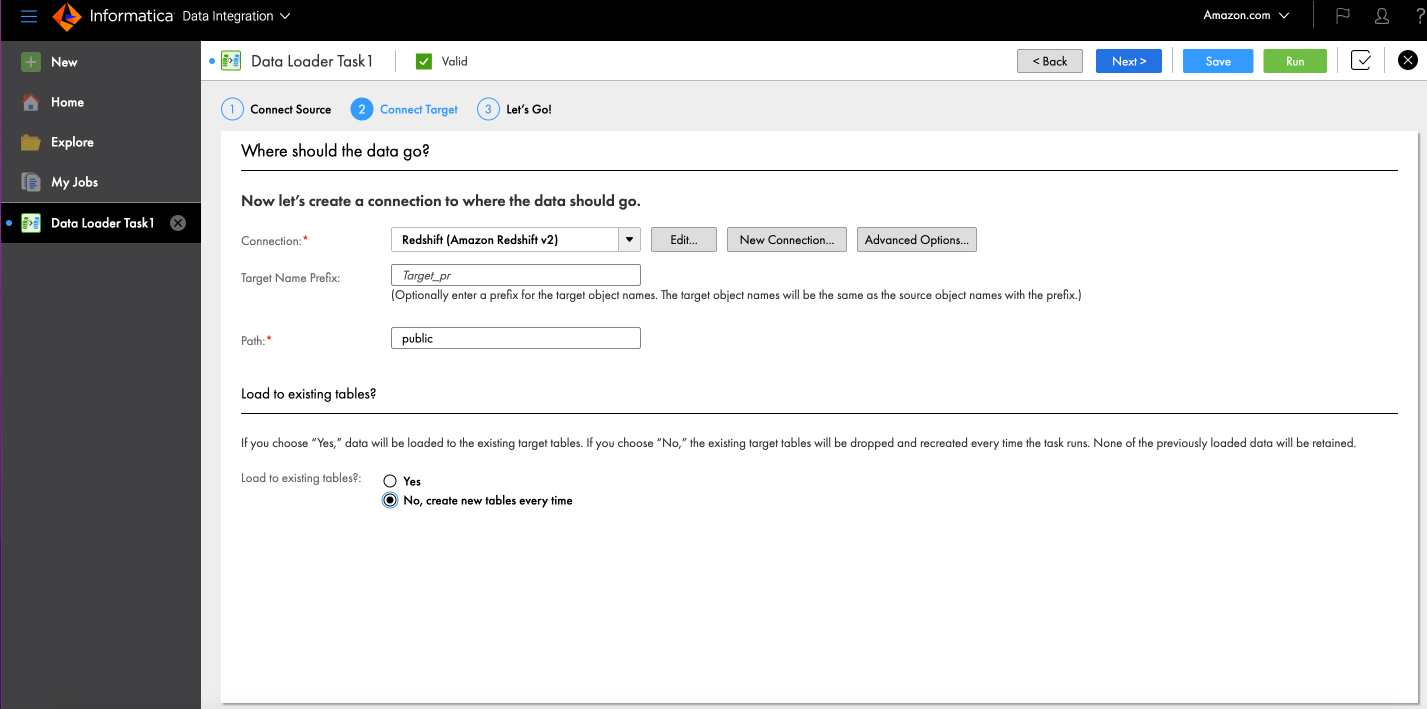
- Kies geavanceerde opties om de naam van de staging S3-bucket in te voeren.
- Kies OK.
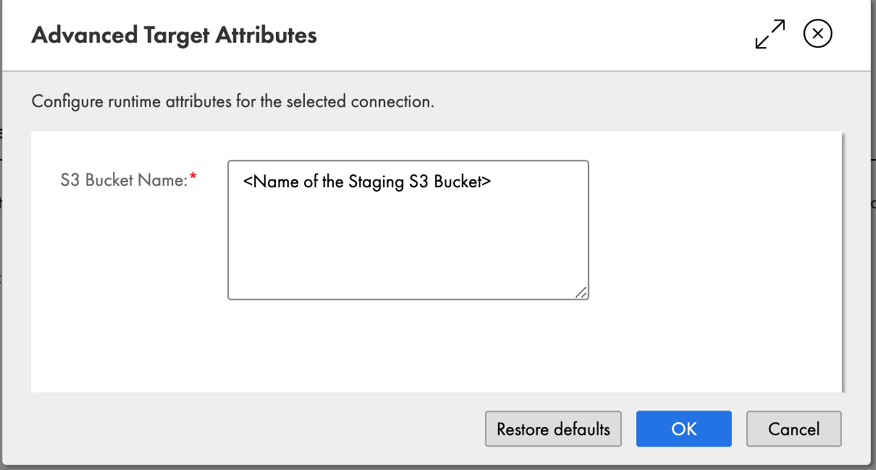
U hebt nu met succes verbinding gemaakt met een Amazon Redshift-doelcluster.
Plan of voer een gegevensbelasting uit
U kunt uw gegevens laden door te kiezen lopen of vouw het Plan gedeelte om het in te plannen.
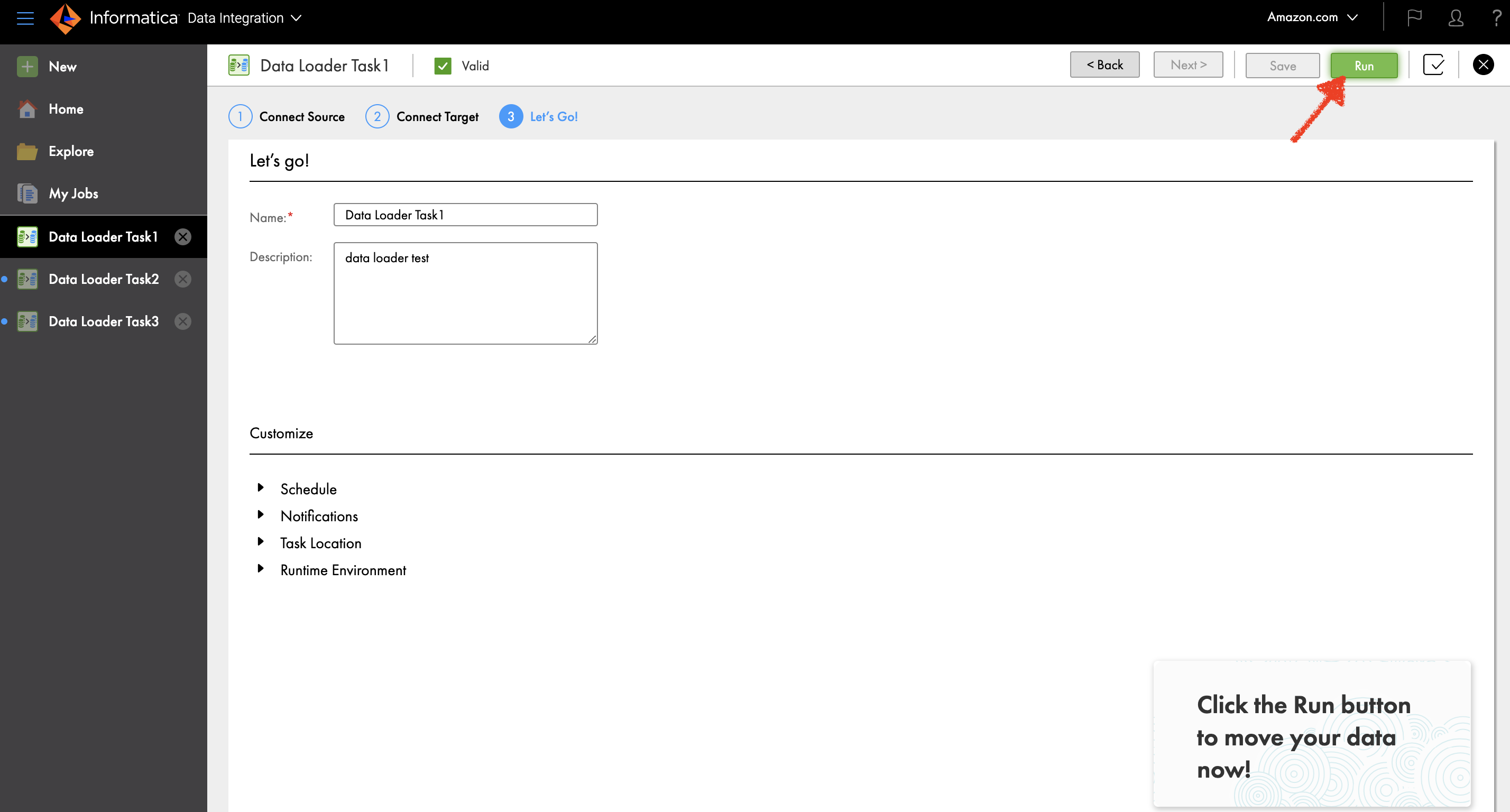
U kunt de taakstatus ook volgen op de Mijn banen pagina.

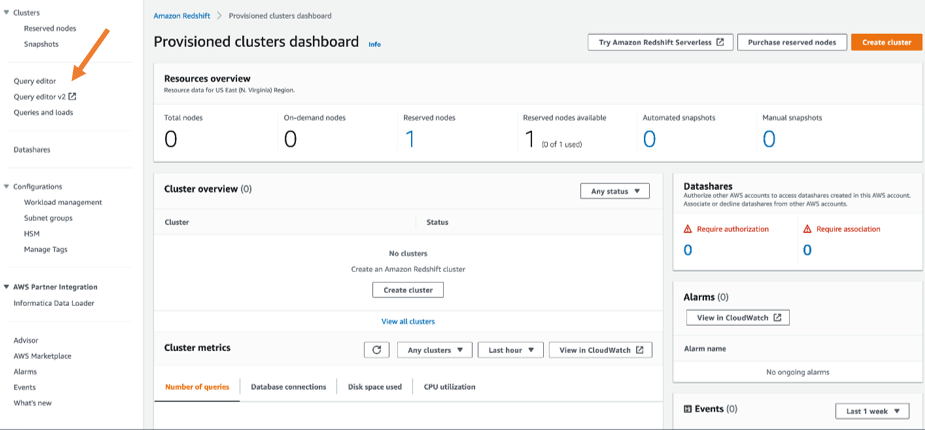
Wanneer uw taakstatus verandert in Success, kunt u terugkeren naar de Amazon Redshift-console en Query Editor V2 openen.
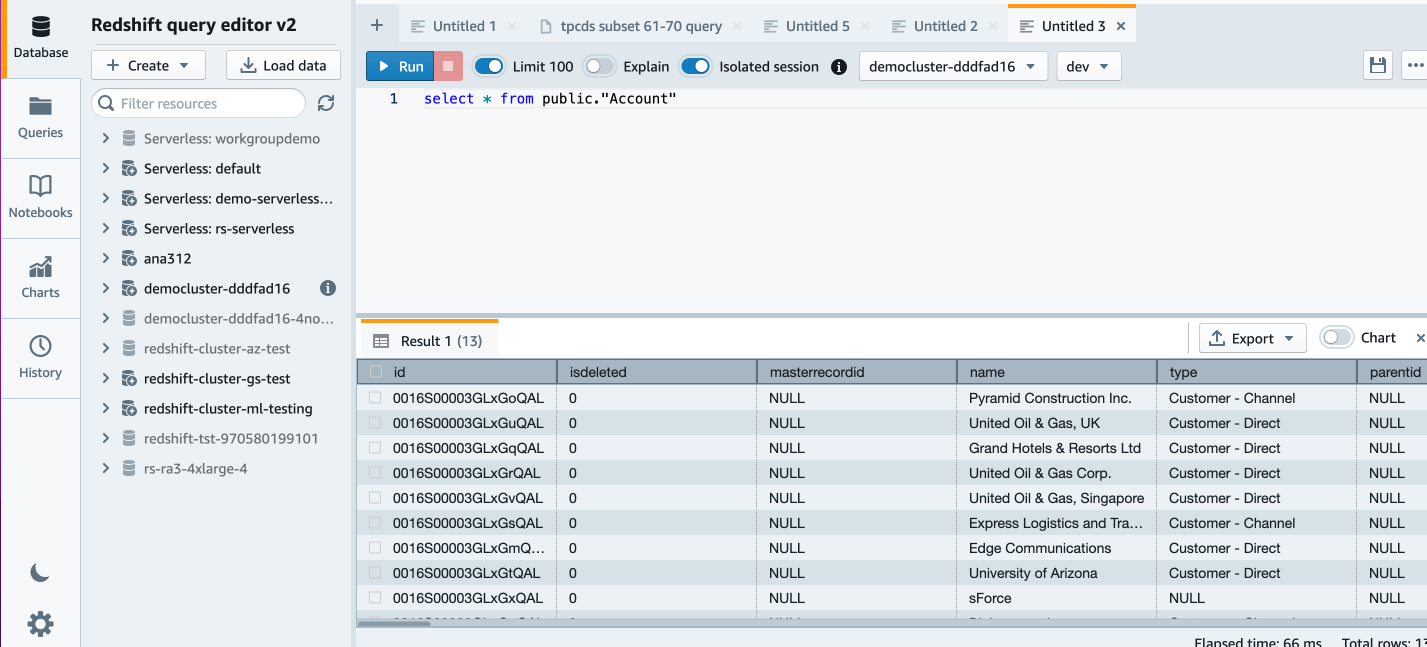
In Amazon Redshift Query Editor v2.0 kunt u de geladen gegevens verifiëren door de volgende query uit te voeren:
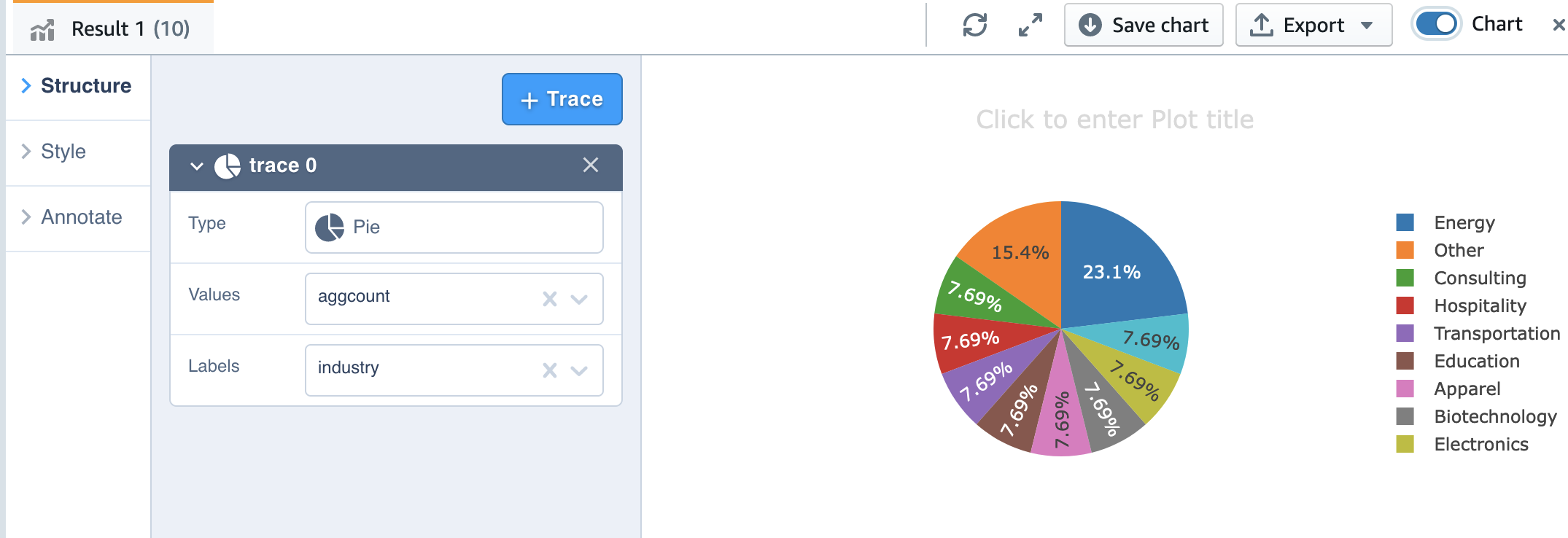
Nu kunnen we wat meer analyse doen. Laten we eens kijken naar klantaccounts per branche:
We kunnen ook de grafiekfunctie van Query Editor V2 gebruiken voor visualisatie.
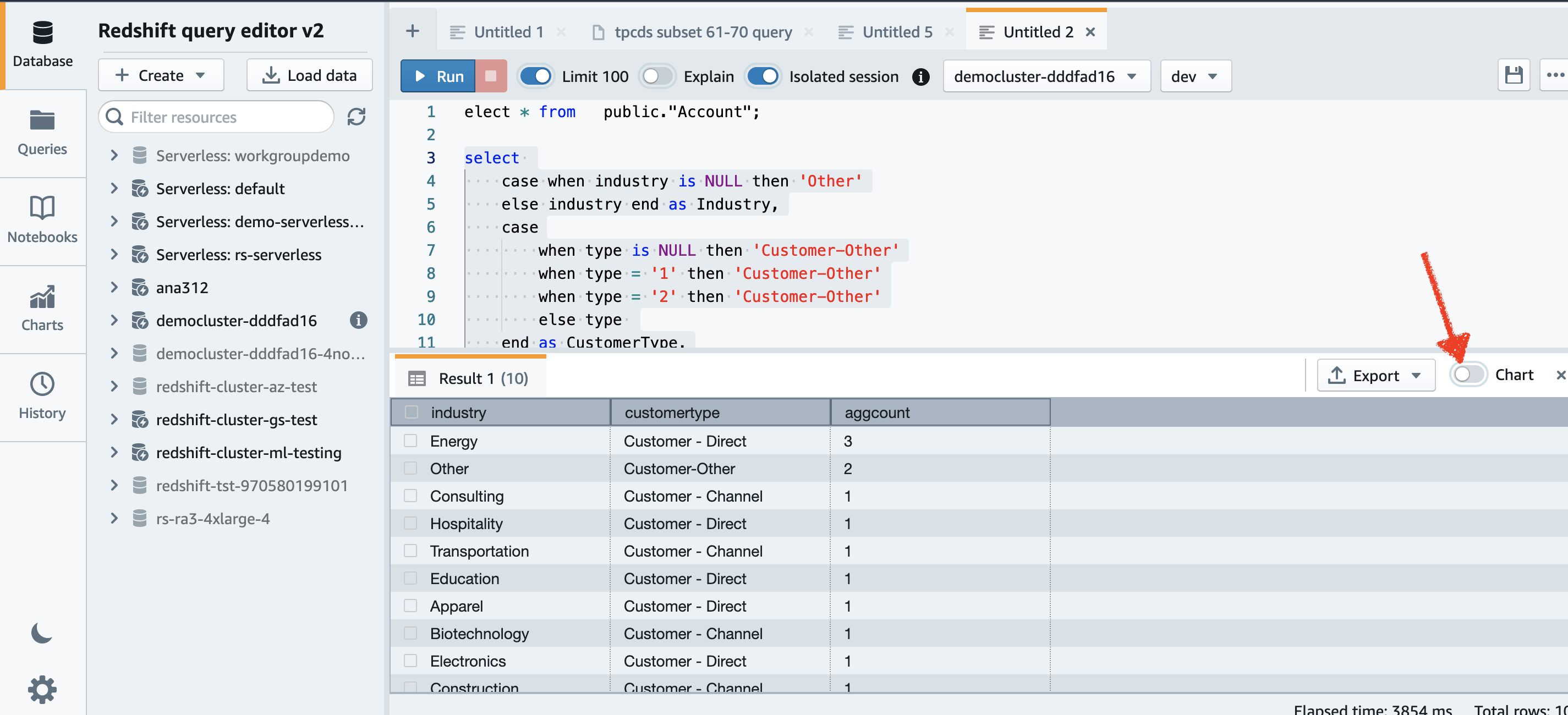
Kies eenvoudig het grafiektype en de waarde en het label dat u in kaart wilt brengen.
Conclusie
De post demonstreert de geïntegreerde Amazon Redshift-console-ervaring van het laden van gegevens met Informatica Data Loader en het opvragen van de gegevens met Amazon Redshift Query Editor. Met Informatica Data Loader kunnen Amazon Redshift-klanten in drie eenvoudige stappen snel nieuwe databronnen invoeren en just-in-time data op schaal brengen om datagestuurde beslissingen te nemen.
U kunt zich aanmelden voor Informatica Data Loader voor Amazon Redshift en begin met het laden van gegevens naar Amazon Redshift.
Over de auteurs
 Deepak Ramesvarapu is Director of Product Management bij Informatica. Hij is productleider met een strategische focus op nieuwe functies en productlanceringen, strategische productroadmap, AI/ML, clouddata-integratie en data-engineering en integratieleiderschap. Hij heeft 20 jaar ervaring met het bouwen van de beste producten en oplossingen om end-to-end datamanagementuitdagingen aan te pakken.
Deepak Ramesvarapu is Director of Product Management bij Informatica. Hij is productleider met een strategische focus op nieuwe functies en productlanceringen, strategische productroadmap, AI/ML, clouddata-integratie en data-engineering en integratieleiderschap. Hij heeft 20 jaar ervaring met het bouwen van de beste producten en oplossingen om end-to-end datamanagementuitdagingen aan te pakken.
 Rajeev Srinivasan is directeur van Technical Alliance, Ecosystem bij Informatica. Hij leidt de strategische technische samenwerking met AWS om de benodigde en innovatieve oplossingen en mogelijkheden in handen van de klanten te brengen. Naast zijn obsessie met klanten heeft hij een passie voor data- en cloudtechnologieën en voor het rijden op zijn Harley.
Rajeev Srinivasan is directeur van Technical Alliance, Ecosystem bij Informatica. Hij leidt de strategische technische samenwerking met AWS om de benodigde en innovatieve oplossingen en mogelijkheden in handen van de klanten te brengen. Naast zijn obsessie met klanten heeft hij een passie voor data- en cloudtechnologieën en voor het rijden op zijn Harley.
 Michael Yitayew is een productmanager voor Amazon Redshift, gevestigd in New York. Hij werkt samen met klanten en engineeringteams om nieuwe functies te bouwen waarmee data-engineers en data-analisten gemakkelijker data kunnen laden, datawarehouse-resources kunnen beheren en hun data kunnen opvragen. Hij ondersteunt AWS-klanten al meer dan 3 jaar in zowel productmarketing- als productmanagementrollen.
Michael Yitayew is een productmanager voor Amazon Redshift, gevestigd in New York. Hij werkt samen met klanten en engineeringteams om nieuwe functies te bouwen waarmee data-engineers en data-analisten gemakkelijker data kunnen laden, datawarehouse-resources kunnen beheren en hun data kunnen opvragen. Hij ondersteunt AWS-klanten al meer dan 3 jaar in zowel productmarketing- als productmanagementrollen.
 Phil Bates is een Senior Analytics Specialist Solutions Architect bij AWS. Hij heeft meer dan 25 jaar ervaring met het implementeren van grootschalige datawarehouse-oplossingen. Hij is gepassioneerd om klanten te helpen tijdens hun cloudreis en de kracht van ML te gebruiken binnen hun datawarehouse.
Phil Bates is een Senior Analytics Specialist Solutions Architect bij AWS. Hij heeft meer dan 25 jaar ervaring met het implementeren van grootschalige datawarehouse-oplossingen. Hij is gepassioneerd om klanten te helpen tijdens hun cloudreis en de kracht van ML te gebruiken binnen hun datawarehouse.
 Weifan Liang is Senior Partner Solutions Architect bij AWS. Hij werkt nauw samen met AWS-toppartners voor strategische data-analysesoftware om productintegratie te stimuleren, een geoptimaliseerde architectuur te bouwen, een langetermijnstrategie te ontwikkelen en thought leadership te bieden. Door samen met partners te innoveren, streeft Weifan ernaar klanten te helpen de bedrijfsresultaten te versnellen met digitale transformatie via de cloud.
Weifan Liang is Senior Partner Solutions Architect bij AWS. Hij werkt nauw samen met AWS-toppartners voor strategische data-analysesoftware om productintegratie te stimuleren, een geoptimaliseerde architectuur te bouwen, een langetermijnstrategie te ontwikkelen en thought leadership te bieden. Door samen met partners te innoveren, streeft Weifan ernaar klanten te helpen de bedrijfsresultaten te versnellen met digitale transformatie via de cloud.
- Coinsmart. Europa's beste Bitcoin- en crypto-uitwisseling.Klik Hier
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/simplify-data-loading-on-the-amazon-redshift-console-with-informatica-data-loader/

