Apache-ijsberg is een open tabelformaat voor grote datasets in Amazon eenvoudige opslagservice (Amazon S3) en biedt snelle queryprestaties over grote tabellen, atomaire commits, gelijktijdig schrijven en SQL-compatibele tabelevolutie. Wanneer u uw transactionele datalake bouwt met behulp van Apache Iceberg om uw functionele use-cases op te lossen, moet u zich richten op operationele use-cases voor uw S3-datalake om de productieomgeving te optimaliseren. Enkele van de belangrijke niet-functionele use-cases voor een S3-datalake waarop organisaties zich richten, zijn onder meer optimalisatie van opslagkosten, mogelijkheden voor noodherstel en bedrijfscontinuïteit, toegang voor meerdere accounts en meerdere regio's tot de datalake, en het verwerken van toegenomen Amazon S3 tarieven aanvragen.
In dit bericht laten we u zien hoe u de operationele efficiëntie van uw Apache Iceberg-tabellen kunt verbeteren Amazon S3-gegevensmeer en Amazon EMR big data-platform.
Optimaliseer data lake-opslag
Een van de grote voordelen van het bouwen van moderne datameren op Amazon S3 is dat het lagere kosten biedt zonder concessies te doen aan de prestaties. U kunt Amazon S3 Lifecycle-configuraties en Amazon S3-objecttagging gebruiken met Apache Iceberg-tabellen om de kosten van uw totale data lake-opslag te optimaliseren. Een Amazon S3 Lifecycle-configuratie is een set regels die acties definiëren die Amazon S3 toepast op een groep objecten. Er zijn twee soorten acties:
- Overgangsacties – Deze acties definiëren wanneer objecten overgaan naar een andere opslagklasse; bijvoorbeeld Amazon S3 Standard naar Amazon S3 Glacier.
- Verval acties – Deze acties definiëren wanneer objecten verlopen. Amazon S3 verwijdert namens u verlopen objecten.
Amazon S3 gebruikt objecttagging om opslag te categoriseren waarbij elke tag een sleutel-waardepaar is. Vanuit een Apache Iceberg-perspectief ondersteunt het een aangepast Amazon S3-object labels die kunnen worden toegevoegd aan S3-objecten tijdens het schrijven en verwijderen in de tabel. Met Iceberg kun je ook een op tags gebaseerd levenscyclusbeleid voor objecten configureren op bucketniveau om objecten over te zetten naar verschillende Amazon S3-lagen. Met de s3.delete.tags config in Iceberg, worden objecten getagd met de geconfigureerde sleutel-waardeparen voordat ze worden verwijderd. Wanneer de catalogus eigenschap s3.delete-enabled is ingesteld op false, worden de objecten niet definitief verwijderd uit Amazon S3. Dit zal naar verwachting worden gebruikt in combinatie met Amazon S3 delete-tagging, dus objecten worden getagd en verwijderd met behulp van een Amazon S3 levenscyclusbeleid. Deze eigenschap is ingesteld op true standaard.
Het voorbeeldnotitieblok in dit bericht toont een voorbeeldimplementatie van S3-objecttagging en levenscyclusregels voor Apache Iceberg-tabellen om de opslagkosten te optimaliseren.
Implementeer bedrijfscontinuïteit
Amazon S3 geeft elke ontwikkelaar toegang tot dezelfde zeer schaalbare, betrouwbare, snelle en goedkope infrastructuur voor gegevensopslag die Amazon gebruikt om zijn eigen wereldwijde netwerk van websites te runnen. Amazon S3 is ontworpen voor 99.999999999% (11 9's) duurzaamheid, S3 Standard is ontworpen voor 99.99% beschikbaarheid en Standard - IA is ontworpen voor 99.9% beschikbaarheid. Maar om uw data lake-workloads zeer beschikbaar te maken in een onwaarschijnlijke uitvalsituatie, kunt u uw S3-gegevens repliceren naar een andere AWS-regio als back-up. Met S3-gegevens die zich in meerdere regio's bevinden, kunt u een S3-toegangspunt voor meerdere regio's gebruiken als oplossing om toegang te krijgen tot de gegevens van de back-upregio. Met Failover-besturingselementen voor Amazon S3 toegangspunten voor meerdere regio's, kunt u al het S3-gegevensverzoekverkeer via één wereldwijd eindpunt routeren en op elk moment rechtstreeks de verschuiving van S3-gegevensverzoekverkeer tussen regio's regelen. Tijdens een geplande of ongeplande regionale verkeersonderbreking kunt u met failover-controles de failover tussen buckets in verschillende regio's en accounts binnen enkele minuten regelen. Apache Iceberg ondersteunt access points om S3-bewerkingen uit te voeren door een toewijzing van bucket aan toegangspunten op te geven. We voegen later in dit bericht een voorbeeldimplementatie toe van een S3-toegangspunt met Apache Iceberg.
Verhoog de prestaties en doorvoer van Amazon S3
Amazon S3 ondersteunt een verzoeksnelheid van 3,500 PUT/COPY/POST/DELETE of 5,500 GET/HEAD verzoeken per seconde per prefix in een bucket. De resources voor deze aanvraagsnelheid worden niet automatisch toegewezen wanneer een voorvoegsel wordt gemaakt. In plaats daarvan, naarmate de aanvraagsnelheid voor een voorvoegsel geleidelijk toeneemt, schaalt Amazon S3 automatisch om de verhoogde aanvraagsnelheid te verwerken. Voor bepaalde workloads die een plotselinge verhoging van de aanvraagsnelheid voor objecten in een prefix nodig hebben, kan Amazon S3 503 Slow Down-fouten retourneren, ook wel bekend als S3-beperking. Het doet dit terwijl het op de achtergrond schaalt om de verhoogde aanvraagsnelheid te verwerken. Als de ondersteunde verzoekfrequenties worden overschreden, is het ook een best practice om objecten en verzoeken over meerdere te verdelen voorvoegsels. Het implementeren van deze oplossing om objecten en verzoeken over meerdere prefixen te verdelen, brengt wijzigingen met zich mee in uw toepassingen voor gegevensinvoer of gegevensuitvoer. Het gebruik van de Apache Iceberg-bestandsindeling voor uw S3-datalake kan de technische inspanning aanzienlijk verminderen door de ObjectStoreLocationProvider functie, die een S3-hash [0*7FFFFF]-voorvoegsel toevoegt aan uw opgegeven S3-objectpad.
Iceberg gebruikt standaard de Hive-opslagindeling, maar u kunt deze omschakelen om de ObjectStoreLocationProvider. Deze optie is standaard niet ingeschakeld om flexibiliteit te bieden bij het kiezen van de locatie waar u het hash-voorvoegsel wilt toevoegen. Met ObjectStoreLocationProvider, wordt een deterministische hash gegenereerd voor elk opgeslagen bestand en wordt een submap toegevoegd direct na de S3-map die is opgegeven met de parameter write.data.path (write.object-storage-path voor Iceberg versie 0.12 en lager). Dit zorgt ervoor dat bestanden die naar Amazon S3 worden geschreven, gelijkmatig worden verdeeld over meerdere prefixen in uw S3-bucket, waardoor de throttling-fouten worden geminimaliseerd. In het volgende voorbeeld stellen we de write.data.path waarde als s3://my-table-data-bucket, en door Iceberg gegenereerde S3-hash-voorvoegsels worden na deze locatie toegevoegd:
Uw S3-bestanden worden gerangschikt onder MURMUR3 S3 hash-voorvoegsels zoals de volgende:
IJsberg gebruiken ObjectStoreLocationProvider is geen onfeilbaar mechanisme om S3 503-fouten te voorkomen. U moet nog steeds de juiste EMRFS-pogingen instellen om extra veerkracht te bieden. U kunt uw strategie voor opnieuw proberen aanpassen door de maximale limiet voor opnieuw proberen te verhogen voor de standaard exponentiële uitstelstrategie voor opnieuw proberen of door de additieve toename/multiplicatieve afname (AIMD) strategie voor opnieuw proberen in te schakelen en te configureren. AIMD wordt ondersteund voor Amazon EMR-releases 6.4.0 en later. Voor meer informatie, zie Probeer Amazon S3-verzoeken opnieuw met EMRFS.
In de volgende secties geven we voorbeelden van deze use cases.
Optimalisatie van opslagkosten
In dit voorbeeld gebruiken we Iceberg's S3-tags-functie met de write-tag als write-tag-name=created en verwijder tag als delete-tag-name=deleted. Dit voorbeeld wordt gedemonstreerd op een EMR-versie emr-6.10.0-cluster met geïnstalleerde applicaties Hadoop 3.3.3, Jupyter Enterprise Gateway 2.6.0 en Spark 3.3.1. De voorbeelden worden uitgevoerd op een Jupyter Notebook-omgeving die is gekoppeld aan het EMR-cluster. Raadpleeg voor meer informatie over het maken van een EMR-cluster met Iceberg en het gebruik van Amazon EMR Studio Gebruik een Iceberg-cluster met Spark en Amazon EMR Studio-beheergids, Respectievelijk.
De volgende voorbeelden zijn ook beschikbaar in het voorbeeldnotitieboek in de aws-samples GitHub-opslagplaats voor snel experimenteren.
Configureer Iceberg tijdens een Spark-sessie
Configureer uw Spark-sessie met behulp van de %%configure magische opdracht. U kunt ofwel de AWS-lijmgegevenscatalogus (aanbevolen) of een Hive-catalogus voor Iceberg-tabellen. In dit voorbeeld gebruiken we een Hive-catalogus, maar we kunnen overschakelen naar de gegevenscatalogus met de volgende configuratie:
Voordat u deze stap uitvoert, maakt u een S3-bucket en een ijsbergmap in uw AWS-account met de naamgevingsconventie <your-iceberg-storage-blog>/iceberg/.
bijwerken your-iceberg-storage-blog in de volgende configuratie met de bucket die u hebt gemaakt om dit voorbeeld te testen. Let op de configuratieparameters s3.write.tags.write-tag-name en s3.delete.tags.delete-tag-name, waarmee de nieuwe S3-objecten en verwijderde objecten worden getagd met overeenkomstige tagwaarden. We gebruiken deze tags in latere stappen om S3-levenscyclusbeleid te implementeren om de objecten over te zetten naar een goedkopere opslaglaag of om ze te laten verlopen op basis van de use case.
Maak een Apache Iceberg-tabel met behulp van Spark-SQL
Nu maken we een ijsbergtafel voor de Dataset voor Amazon-productrecensies:
In de volgende stap laden we de tabel met de dataset met behulp van Spark-acties.
Gegevens in de Iceberg-tabel laden
Tijdens het invoegen van de gegevens, verdelen we de gegevens op basis van review_date volgens de tabeldefinitie. Voer de volgende Spark-opdrachten uit in uw PySpark-notebook:
Voeg één record in dezelfde Iceberg-tabel in, zodat er een partitie ontstaat met de huidige review_date:
U kunt controleren of de nieuwe snapshot is gemaakt na deze toevoegbewerking door de Iceberg-snapshot op te vragen:
U ziet een uitvoer die vergelijkbaar is met de volgende die de bewerkingen laat zien die op de tafel worden uitgevoerd.
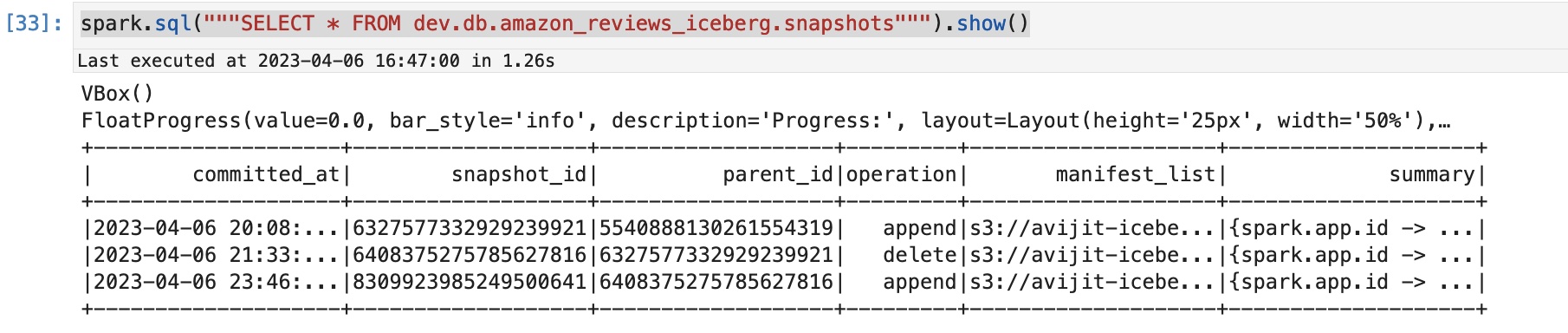
Controleer de populatie van S3-tags
U kunt gebruik maken van de AWS-opdrachtregelinterface (AWS CLI) of de AWS-beheerconsole om de tags te controleren die zijn ingevuld voor de nieuwe schrijfbewerkingen. Laten we de tag controleren die overeenkomt met het object dat is gemaakt door een enkele rij invoeging.
Controleer op de Amazon S3-console de S3-map s3://your-iceberg-storage-blog/iceberg/db/amazon_reviews_iceberg/data/ en wijs naar de partitie review_date_year=2023/. Controleer vervolgens het Parquet-bestand onder deze map om de tags te controleren die zijn gekoppeld aan het gegevensbestand in Parquet-indeling.
Voer vanuit de AWS CLI de volgende opdracht uit om te controleren of de tag is gemaakt op basis van de Spark-configuratie spark.sql.catalog.dev.s3.write.tags.write-tag-name":"created":
In deze stap verwijderen we een record uit de Iceberg-tabel en vervallen de momentopname die overeenkomt met het verwijderde record. We verwijderen het nieuwe enkele record dat we met het huidige hebben ingevoegd review_date:
We kunnen nu controleren of er een nieuwe momentopname is gemaakt met de bewerking gemarkeerd als delete:
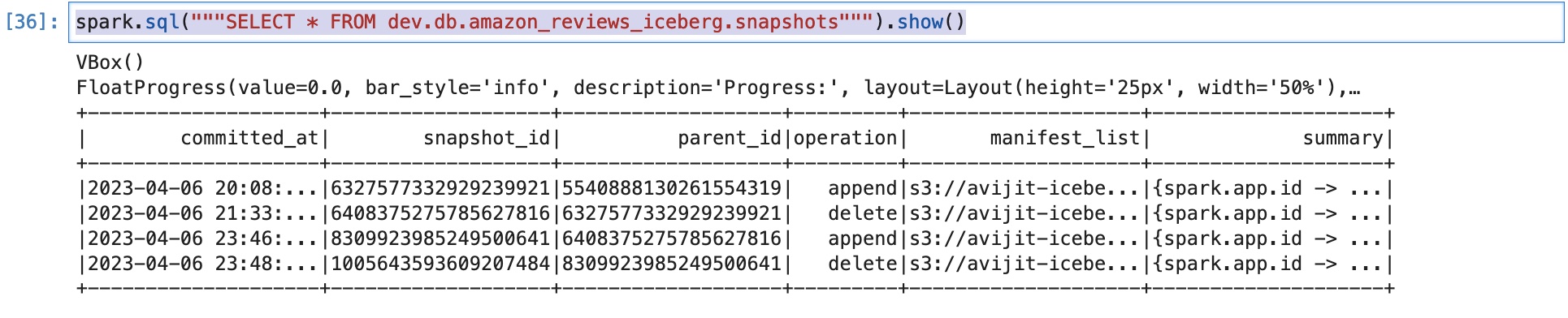
Dit is handig als we in de tijd willen reizen en de verwijderde rij in de toekomst willen controleren. In dat geval moeten we de tabel met de opvragen snapshot-id overeenkomend met de verwijderde rij. We bespreken tijdreizen echter niet als onderdeel van dit bericht.
We vervallen de oude snapshots van de tabel en behouden alleen de laatste twee. U kunt de query wijzigen op basis van uw specifieke vereisten om de snapshots te behouden:
Als we dezelfde query uitvoeren op de snapshots, kunnen we zien dat we slechts twee snapshots beschikbaar hebben:

Vanuit de AWS CLI kunt u de volgende opdracht uitvoeren om te zien of de tag is gemaakt op basis van de Spark-configuratie spark.sql.catalog.dev.s3. delete.tags.delete-tag-name":"deleted":
De snapshots die zijn verlopen, tonen de nieuwste snapshot-ID als null.
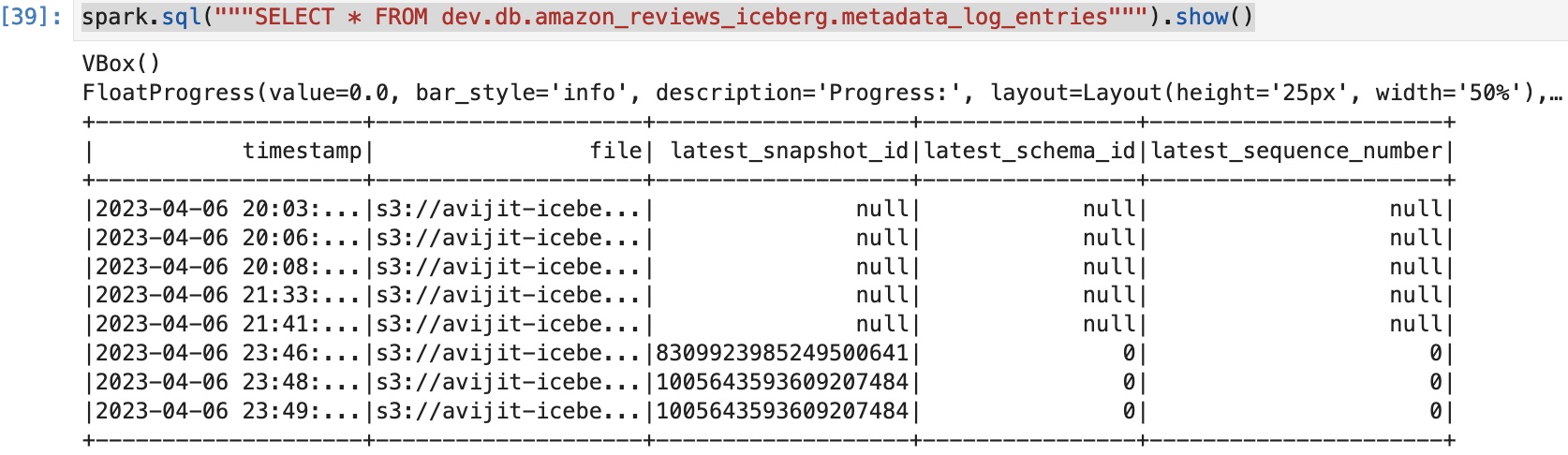
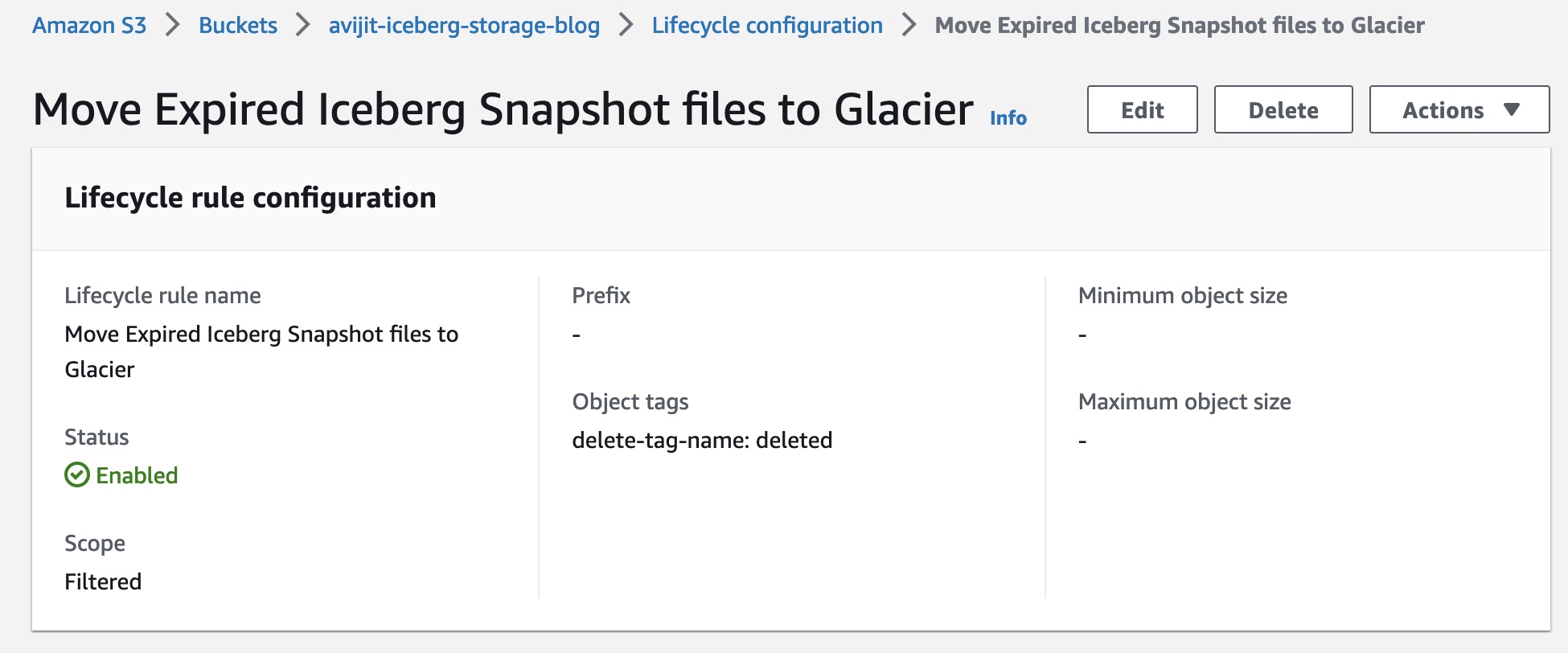
Maak S3-levenscyclusregels om de buckets over te zetten naar een andere opslaglaag
Maak een levenscyclusconfiguratie voor de bucket om objecten met de delete-tag-name=deleted S3-tag over te zetten naar de klasse Glacier Instant Retrieval. Amazon S3 voert levenscyclusregels één keer per dag om middernacht Universal Coordinated Time (UTC) uit en het kan tot 48 uur duren voordat nieuwe levenscyclusregels de eerste run voltooien. Amazon S3 Glacier is zeer geschikt voor het archiveren van gegevens die onmiddellijke toegang nodig hebben (met ophalen in milliseconden). Met S3 Glacier Instant Retrieval kunt u tot 68% besparen op opslagkosten in vergelijking met het gebruik van de opslagklasse S3 Standard-Infrequent Access (S3 Standard-IA), wanneer de gegevens eenmaal per kwartaal worden opgevraagd.
Wanneer u toegang wilt tot de gegevens terug, kan dat herstel in bulk de gearchiveerde objecten. Nadat u de objecten terugzet in de S3 Standard-klasse, kunt u de metagegevens en gegevens registreren als een archieftabel voor querydoeleinden. De locatie van het metadatabestand kan worden opgehaald uit de metadatalogvermeldingen die metatabel zijn, zoals eerder geïllustreerd. Zoals eerder vermeld, geeft de nieuwste snapshot-ID met Null-waarden verlopen snapshots aan. We kunnen een van de verlopen snapshots nemen en het bulkherstel uitvoeren:
Mogelijkheden voor noodherstel en bedrijfscontinuïteit, toegang voor meerdere accounts en meerdere regio's tot het datameer
Omdat Iceberg geen relatieve paden ondersteunt, kunt u gebruiken access points om Amazon S3-bewerkingen uit te voeren door een toewijzing van buckets aan toegangspunten op te geven. Dit is handig voor toegang tot meerdere regio's, toegang tot meerdere regio's, noodherstel en meer.
Voor cross-regionale toegangspunten moeten we bovendien de use-arn-region-enabled catalogus eigendom aan true in staat te stellen S3FileIO om interregionale gesprekken te voeren. Als een Amazon S3-resource-ARN wordt doorgegeven als het doel van een Amazon S3-bewerking die een andere regio heeft dan de regio waarmee de client is geconfigureerd, moet deze vlag worden ingesteld op 'true' om de client toe te staan een interregionale aanroep te doen naar de regio die is opgegeven in de ARN, anders wordt er een uitzondering gegenereerd. Echter, voor dezelfde toegangspunten of toegangspunten met meerdere regio's, de use-arn-region-enabled vlag moet worden ingesteld op 'false.
Als u bijvoorbeeld een S3-toegangspunt wilt gebruiken met toegang voor meerdere regio's in Spark 3.3, kunt u de Spark SQL-shell starten met de volgende code:
In dit voorbeeld staan de objecten in Amazon S3 op my-bucket1 en my-bucket2 emmers gebruiken de arn:aws:s3::123456789012:accesspoint:mfzwi23gnjvgw.mrap toegangspunt voor alle Amazon S3-bewerkingen.
Raadpleeg voor meer informatie over het gebruik van toegangspunten Toegangspunten gebruiken met compatibele Amazon S3-bewerkingen.
Stel dat uw tabelpad onder is mybucket1, dus beide mybucket1 in regio 1 en mybucket2 in Regio hebben paden van mybucket1 in de metadatabestanden. Op het moment van de S3-aanroep (GET/PUT) vervangen we de mybucket1 referentie met een toegangspunt voor meerdere regio's.
Omgaan met verhoogde S3-verzoeksnelheden
Tijdens gebruik ObjectStoreLocationProvider (voor meer details, zie Objectopslag bestandsindeling), wordt voor elk opgeslagen bestand een deterministische hash gegenereerd, waarbij de hash direct achter de write.data.path. Het probleem hiermee is dat het standaard hash-algoritme hash-waarden genereert tot Integer MAX_VALUE, wat in Java (2^31)-1 is. Wanneer dit wordt geconverteerd naar hex, produceert het 0x7FFFFFFFF, dus de variantie van het eerste teken is beperkt tot slechts [0-8]. Volgens Amazon S3 aanbevelingen, zouden we hier de maximale variantie moeten hebben om dit te verminderen.
Vanaf Amazon EMR 6.10, heeft Amazon EMR een geoptimaliseerde locatieprovider toegevoegd die ervoor zorgt dat de gegenereerde prefix-hash een uniforme distributie heeft in de eerste twee tekens met behulp van de tekenset van [0-9][AZ][az].
Deze locatieprovider is onlangs open source gemaakt door Amazon EMR via Kern: Verbeter de bitdichtheid in de lay-out van de objectopslag en zou beschikbaar moeten zijn vanaf Iceberg 1.3.0.
Om te gebruiken, zorg ervoor dat de iceberg.enabled classificatie is ingesteld op true en write.location-provider.impl is ingesteld op org.apache.iceberg.emr.OptimizedS3LocationProvider.
Het volgende is een voorbeeld van een Spark-shellopdracht:
Het volgende voorbeeld laat zien dat wanneer u de objectopslag in uw Iceberg-tabel inschakelt, het hash-voorvoegsel wordt toegevoegd aan uw S3-pad direct na de locatie die u opgeeft in uw DDL.
Definieer de tabel write.object-storage.enabled parameter en geef het S3-pad op, waarna u het hash-voorvoegsel wilt toevoegen met behulp van write.data.path (voor Iceberg versie 0.13 en hoger) of write.object-storage.path (voor Iceberg versie 0.12 en lager) parameters.
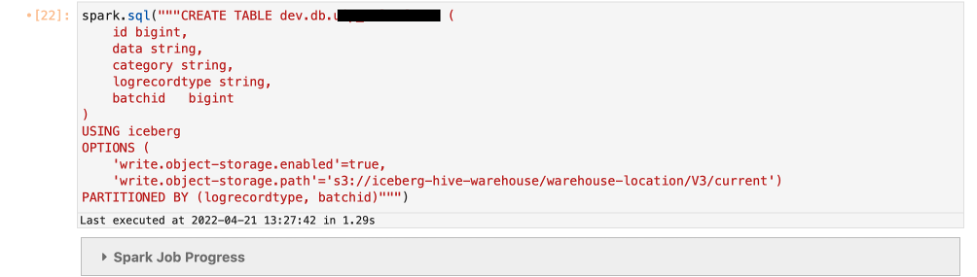
Voeg gegevens in de tabel die u hebt gemaakt.

Het hash-voorvoegsel wordt toegevoegd direct na het /current/-voorvoegsel in het S3-pad zoals gedefinieerd in de DDL.

Opruimen
Nadat u de test hebt voltooid, ruimt u uw resources op om terugkerende kosten te voorkomen:
- Verwijder de S3-buckets die u voor deze test hebt gemaakt.
- Verwijder het EMR-cluster.
- Stop en verwijder de EMR-notebookinstantie.
Conclusie
Naarmate bedrijven doorgaan met het bouwen van nieuwere gebruiksscenario's voor transactionele datameren met behulp van het open-tabelformaat Apache Iceberg op zeer grote datasets op S3-datameren, zal er meer aandacht komen voor het optimaliseren van die productieomgevingen op petabyte-schaal om kosten te verlagen, de efficiëntie te verbeteren en hoogwaardige implementaties te implementeren. beschikbaarheid. Dit bericht demonstreerde mechanismen om de operationele efficiëntie te implementeren voor Apache Iceberg open-tabelformaten die op AWS draaien.
Raadpleeg de volgende bronnen voor meer informatie over Apache Iceberg en het implementeren van dit open-tabelformaat voor uw gebruiksscenario's voor transactionele data lakes:
Over de auteurs
 Avijit Gosvami is Principal Solutions Architect bij AWS gespecialiseerd in data en analytics. Hij ondersteunt strategische klanten van AWS bij het bouwen van hoogwaardige, veilige en schaalbare data lake-oplossingen op AWS met behulp van AWS-beheerde services en open-sourceoplossingen. Buiten zijn werk houdt Avijit van reizen, wandelen in de San Francisco Bay Area-paden, naar sport kijken en naar muziek luisteren.
Avijit Gosvami is Principal Solutions Architect bij AWS gespecialiseerd in data en analytics. Hij ondersteunt strategische klanten van AWS bij het bouwen van hoogwaardige, veilige en schaalbare data lake-oplossingen op AWS met behulp van AWS-beheerde services en open-sourceoplossingen. Buiten zijn werk houdt Avijit van reizen, wandelen in de San Francisco Bay Area-paden, naar sport kijken en naar muziek luisteren.
 Rajarshi Sarkar is Software Development Engineer bij Amazon EMR/Athena. Hij werkt aan geavanceerde functies van Amazon EMR/Athena en is ook betrokken bij open-sourceprojecten zoals Apache Iceberg en Trino. In zijn vrije tijd houdt hij van reizen, films kijken en uitgaan met vrienden.
Rajarshi Sarkar is Software Development Engineer bij Amazon EMR/Athena. Hij werkt aan geavanceerde functies van Amazon EMR/Athena en is ook betrokken bij open-sourceprojecten zoals Apache Iceberg en Trino. In zijn vrije tijd houdt hij van reizen, films kijken en uitgaan met vrienden.
 prashant singh is Software Development Engineer bij AWS. Hij is geïnteresseerd in databases en datawarehouse-engines en heeft gewerkt aan het optimaliseren van Apache Spark-prestaties op EMR. Hij levert een actieve bijdrage aan open source-projecten zoals Apache Spark en Apache Iceberg. In zijn vrije tijd geniet hij van het ontdekken van nieuwe plaatsen, eten en wandelen.
prashant singh is Software Development Engineer bij AWS. Hij is geïnteresseerd in databases en datawarehouse-engines en heeft gewerkt aan het optimaliseren van Apache Spark-prestaties op EMR. Hij levert een actieve bijdrage aan open source-projecten zoals Apache Spark en Apache Iceberg. In zijn vrije tijd geniet hij van het ontdekken van nieuwe plaatsen, eten en wandelen.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/improve-operational-efficiencies-of-apache-iceberg-tables-built-on-amazon-s3-data-lakes/

