Modelverklaarbaarheid verwijst naar het proces van het relateren van de voorspelling van een machine learning (ML)-model aan de invoerkenmerkwaarden van een instantie in menselijk begrijpelijke termen. Dit veld wordt vaak aangeduid als verklaarbare kunstmatige intelligentie (XII). Amazon SageMaker verduidelijken is een kenmerk van Amazon Sage Maker waarmee datawetenschappers en ML-engineers de voorspellingen van hun ML-modellen kunnen verklaren. Het gebruikt model-agnostische methoden zoals Vormige additieve uitleg (SHAP) voor kenmerkattributie. Naast ondersteunende uitleg voor tabelgegevens, ondersteunt Clarify ook uitlegbaarheid voor zowel computervisie (CV) als natuurlijke taalverwerking (NLP) met behulp van hetzelfde SHAP-algoritme.
In dit bericht illustreren we het gebruik van Clarify voor het uitleggen van NLP-modellen. Concreet laten we zien hoe u de voorspellingen kunt uitleggen van een tekstclassificatiemodel dat is getraind met behulp van de SageMaker BlazingText algoritme. Dit helpt u te begrijpen welke delen of woorden van de tekst het belangrijkst zijn voor de voorspellingen van het model. Deze observaties kunnen vervolgens onder andere worden gebruikt om verschillende processen te verbeteren, zoals data-acquisitie die vertekening in de dataset vermindert en modelvalidatie om ervoor te zorgen dat modellen presteren zoals bedoeld, en om vertrouwen te winnen bij alle belanghebbenden wanneer het model wordt geïmplementeerd. Dit kan een belangrijke vereiste zijn in veel toepassingsdomeinen, zoals sentimentanalyse, juridische beoordelingen, medische diagnose en meer.
We bieden ook een algemeen ontwerppatroon dat u kunt gebruiken terwijl u Clarify gebruikt met een van de SageMaker-algoritmen.
Overzicht oplossingen
SageMaker-algoritmen hebben vaste invoer- en uitvoergegevensindelingen. De BlazingText-algoritmecontainer accepteert bijvoorbeeld invoer in JSON-indeling. Maar klanten hebben vaak specifieke formaten nodig die compatibel zijn met hun datapijplijnen. We presenteren een aantal opties die u kunt volgen om Clarify te gebruiken.
Optie A
In deze optie gebruiken we de inferentiepijplijnfunctie van SageMaker-hosting. Een inferentiepijplijn is een SageMaker-model dat een reeks containers vormt die deductieverzoeken verwerkt. Het volgende diagram illustreert een voorbeeld.
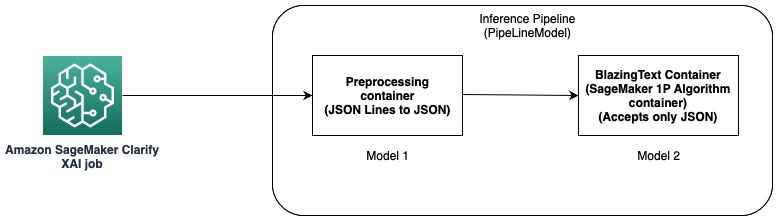
U kunt inferentiepijplijnen gebruiken om een combinatie van uw eigen aangepaste modellen en ingebouwde SageMaker-algoritmen te implementeren, verpakt in verschillende containers. Voor meer informatie, zie Modellen hosten samen met voorverwerkingslogica als seriële inferentiepijplijn achter één eindpunt. Omdat Clarify alleen CSV- en JSON-regels als invoer ondersteunt, moet u de volgende stappen uitvoeren:
- Maak een model en een container om de gegevens van CSV (of JSON Lines) naar JSON te converteren.
- Direct na de modeltrainingsstap met het BlazingText-algoritme het model implementeren. Hiermee wordt het model geïmplementeerd met behulp van de BlazingText-container, die JSON als invoer accepteert. Wanneer een ander algoritme wordt gebruikt, maakt SageMaker het model met behulp van de container van dat algoritme.
- Gebruik de voorgaande twee modellen om een PijpleidingModel. Dit koppelt de twee modellen in een lineaire volgorde en creëert een enkel model. Zie voor een voorbeeld Inferentiepijplijn met Scikit-learn en Linear Learner.
Met deze oplossing hebben we met succes één model gemaakt waarvan de invoer compatibel is met Clarify en die door Clarify kan worden gebruikt om uitleg te genereren.
Optie B
Deze optie laat zien hoe u het gebruik van verschillende gegevensindelingen tussen Clarify- en SageMaker-algoritmen kunt integreren door uw eigen container mee te nemen voor het hosten van het SageMaker-model. Het volgende diagram illustreert de architectuur en de stappen die betrokken zijn bij de oplossing:

De stappen zijn als volgt:
- Gebruik het BlazingText-algoritme via de SageMaker Estimator om een tekstclassificatiemodel te trainen.
- Nadat het model is getraind, maakt u een aangepaste Docker-container die kan worden gebruikt om een SageMaker-model te maken en het model optioneel te implementeren als een SageMaker-modeleindpunt.
- Configureer en maak een Clarify-taak om de hostingcontainer te gebruiken voor het genereren van een uitlegrapport.
- De aangepaste container accepteert het deductieverzoek als CSV en stelt Clarify in staat om uitleg te genereren.
Opgemerkt moet worden dat deze oplossing het idee demonstreert om offline uitleg te verkrijgen met behulp van Clarify voor een BlazingText-model. Voor meer informatie over online uitlegbaarheid, zie Online uitlegbaarheid met SageMaker Clarify.
In de rest van dit bericht wordt elk van de stappen in de tweede optie uitgelegd.
Train een BlazingText-model
We trainen eerst een tekstclassificatiemodel met behulp van het BlazingText-algoritme. In dit voorbeeld gebruiken we de DBpedia Ontology-gegevensset. DBpedia is een crowd-sourced initiatief om gestructureerde inhoud te extraheren met behulp van informatie uit verschillende Wikimedia-projecten zoals Wikipedia. Concreet gebruiken we de DBpedia ontology dataset zoals gemaakt door Zhang et al. Het wordt samengesteld door 14 niet-overlappende klassen uit DBpedia 2014 te selecteren. De velden bevatten een samenvatting van een Wikipedia-artikel en de overeenkomstige klasse. Het doel van een tekstclassificatiemodel is om de klasse van een artikel te voorspellen gezien de samenvatting ervan.
Hieronder vindt u een gedetailleerd stapsgewijs proces voor het trainen van het model notitieboekje. Nadat u het model hebt getraind, let op de Amazon eenvoudige opslagservice (Amazon S3) URI-pad waar de modelartefacten worden opgeslagen. Voor een stapsgewijze handleiding, zie Tekstclassificatie met behulp van SageMaker BlazingText.
Implementeer het getrainde BlazingText-model met uw eigen container op SageMaker
Met Clarify zijn er twee opties om de modelinformatie te verstrekken:
- Maak een SageMaker-model zonder het op een eindpunt te implementeren - Wanneer een SageMaker-model aan Clarify wordt verstrekt, wordt een kortstondig eindpunt gemaakt met behulp van het model.
- Maak een SageMaker-model en implementeer het op een eindpunt – Wanneer een eindpunt beschikbaar wordt gesteld aan Clarify, gebruikt het het eindpunt voor het verkrijgen van uitleg. Dit voorkomt dat er een kortstondig eindpunt wordt gemaakt en kan de uitvoeringstijd van een Clarify-taak verkorten.
In dit bericht gebruiken we de eerste optie met Clarify. Wij gebruiken de SageMaker Python-SDK Voor dit doeleinde. Voor andere opties en meer details, zie Maak uw eindpunt en implementeer uw model.
Neem je eigen container mee (BYOC)
We bouwen eerst een aangepaste Docker-image die wordt gebruikt om het SageMaker-model. U kunt de bestanden en code in het bronmap van onze GitHub-repository.
De Dockerfile beschrijft de afbeelding die we willen bouwen. We beginnen met een standaard Ubuntu-installatie en installeren vervolgens Scikit-learn. Wij klonen ook snelle tekst en installeer het pakket. Het wordt gebruikt om het BlazingText-model te laden voor het maken van voorspellingen. Ten slotte voegen we de code toe die ons algoritme implementeert in de vorm van de voorgaande bestanden en zetten we de omgeving in de container op. De hele Dockerfile wordt geleverd in onze repository en u kunt het gebruiken zoals het is. Verwijzen naar Gebruik uw eigen inferentiecode met hostingservices voor meer informatie over hoe SageMaker omgaat met uw Docker-container en de bijbehorende vereisten.
Voorts voorspeller.py bevat de code voor het laden van het model en het maken van de voorspellingen. Het accepteert invoergegevens als CSV, waardoor het compatibel is met Clarify.
Nadat u de Dockerfile hebt, bouwt u de Docker-container en uploadt u deze naar Amazon Elastic Container-register (Amazone ECR). U vindt het stapsgewijze proces in de vorm van een shell-script in onze GitHub-repository, die u kunt gebruiken om de Docker-afbeelding te maken en te uploaden naar Amazon ECR.
Maak het BlazingText-model
De volgende stap is het maken van een modelobject van de SageMaker Python SDK Model klasse die kan worden geïmplementeerd op een HTTPS-eindpunt. We configureren Clarify om dit model te gebruiken voor het genereren van uitleg. Raadpleeg voor de code en andere vereisten voor deze stap Implementeer uw getrainde SageMaker BlazingText-model met uw eigen container in Amazon SageMaker.
Configureer Clarify
Clarify NLP is compatibel met regressie- en classificatiemodellen. Het helpt u te begrijpen welke delen van de invoertekst de voorspellingen van uw model beïnvloeden. Clarify ondersteunt 62 talen en kan tekst in meerdere talen verwerken. We gebruiken de SageMaker Python SDK om de drie configuraties te definiëren die door Clarify worden gebruikt voor het maken van het uitlegbaarheidsrapport.
Eerst moeten we het processorobject maken en ook de locatie specificeren van de invoergegevensset die zal worden gebruikt voor de voorspellingen en de kenmerkattributie:
Gegevensconfiguratie
Hier moet u de locatie van de invoergegevens configureren, de kenmerkkolom en waar u wilt dat de Clarify-taak de uitvoer opslaat. Dit wordt gedaan door de relevante argumenten door te geven tijdens het maken van een DataConfig-object:
ModelConfig
Met ModelConfig moet u informatie over uw getrainde model opgeven. Hier specificeren we de naam van het BlazingText SageMaker-model dat we in een eerdere stap hebben gemaakt en stellen we ook andere parameters in, zoals de Amazon Elastic Compute-cloud (Amazon EC2) instantietype en de indeling van de inhoud:
SHAPConfig
Dit wordt gebruikt om Clarify te informeren over het verkrijgen van de kenmerkattributies. TextConfig wordt gebruikt om de granulariteit van de tekst en de taal te specificeren. Omdat we in onze dataset de invoertekst willen opsplitsen in woorden en de taal Engels is, stellen we deze waarden in op respectievelijk token en Engels. Afhankelijk van de aard van uw dataset, kunt u de granulariteit instellen op zin of alinea. De basislijn is ingesteld op een speciaal token. Dit betekent dat Clarify subsets van de invoertekst laat vallen en vervangt door waarden van de basislijn, terwijl voorspellingen worden verkregen voor het berekenen van de SHAP-waarden. Dit is hoe het het effect van de tokens op de voorspellingen van het model bepaalt en op zijn beurt hun belang identificeert. Het aantal samples dat moet worden gebruikt in het Kernel SHAP-algoritme wordt bepaald door de waarde van de num_samples argument. Hogere waarden resulteren in robuustere kenmerkattributies, maar dat kan ook de looptijd van de taak verlengen. Daarom moet u een afweging maken tussen de twee. Zie de volgende code:
Voor meer informatie, zie Functieattributies die Shapley-waarden gebruiken en Whitepaper over eerlijkheid en verklaarbaarheid van Amazon AI.
ModelPredictedLabelConfig
Om ervoor te zorgen dat Clarify een voorspeld label of voorspelde scores of kansen kan extraheren, moet dit configuratieobject worden ingesteld. Zie de volgende code:
Voor meer details, zie de documentatie in de SDK.
Voer een Clarify-taak uit
Nadat u de verschillende configuraties hebt gemaakt, bent u nu klaar om de Clarify-verwerkingstaak te activeren. De verwerkingstaak valideert de invoer en parameters, creëert het kortstondige eindpunt en berekent lokale en globale kenmerkattributies met behulp van het SHAP-algoritme. Wanneer dat is voltooid, wordt het kortstondige eindpunt verwijderd en worden de uitvoerbestanden gegenereerd. Zie de volgende code:
De looptijd van deze stap is afhankelijk van de grootte van de dataset en het aantal monsters dat door SHAP wordt gegenereerd.
Visualiseer de resultaten
Ten slotte laten we een visualisatie zien van de resultaten van het lokale kenmerkattributierapport dat is gegenereerd door de Clarify-verwerkingstaak. De uitvoer is in een JSON Lines-indeling en met enige verwerking; u kunt de scores voor de tokens in de invoertekst plotten zoals in het volgende voorbeeld. Hogere balken hebben meer impact op het doellabel. Bovendien worden positieve waarden geassocieerd met hogere voorspellingen in de doelvariabele en negatieve waarden met lagere voorspellingen. In dit voorbeeld doet het model een voorspelling voor de invoertekst "Wesebach is een rivier van Hessen Duitsland". De voorspelde klasse is Natural Place en de scores geven aan dat het model het woord 'rivier' het meest informatief vond om deze voorspelling te doen. Dit is intuïtief voor een mens en door meer monsters te onderzoeken, kunt u bepalen of het model de juiste functies leert en zich gedraagt zoals verwacht.

Conclusie
In dit bericht hebben we uitgelegd hoe u Clarify kunt gebruiken om voorspellingen uit te leggen van een tekstclassificatiemodel dat is getraind met SageMaker BlazingText. Ga aan de slag met het uitleggen van voorspellingen van uw tekstclassificatiemodellen met behulp van het voorbeeldnotitieblok Tekstverklaarbaarheid voor SageMaker BlazingText.
We hebben ook een meer generiek ontwerppatroon besproken dat u kunt gebruiken wanneer u Clarify gebruikt met ingebouwde SageMaker-algoritmen. Voor meer informatie, zie Wat is eerlijkheid en modelverklaarbaarheid voor voorspellingen van machine learning?. We raden u ook aan om de Whitepaper over eerlijkheid en verklaarbaarheid van Amazon AI, dat een overzicht geeft van het onderwerp en best practices en beperkingen bespreekt.
Over de auteurs
 Pinak Panigrahi werkt samen met klanten om op machine learning gebaseerde oplossingen te bouwen om strategische zakelijke problemen op AWS op te lossen. Als hij niet bezig is met machine learning, is hij te vinden tijdens een wandeling, een boek lezen of sporten.
Pinak Panigrahi werkt samen met klanten om op machine learning gebaseerde oplossingen te bouwen om strategische zakelijke problemen op AWS op te lossen. Als hij niet bezig is met machine learning, is hij te vinden tijdens een wandeling, een boek lezen of sporten.
 Dhawal Patel is een Principal Machine Learning Architect bij AWS. Hij heeft gewerkt met organisaties variërend van grote ondernemingen tot middelgrote startups aan problemen met betrekking tot gedistribueerde computing en kunstmatige intelligentie. Hij richt zich op Deep learning inclusief NLP en Computer Vision domeinen. Hij helpt klanten bij het bereiken van high-performance modelinferentie op SageMaker.
Dhawal Patel is een Principal Machine Learning Architect bij AWS. Hij heeft gewerkt met organisaties variërend van grote ondernemingen tot middelgrote startups aan problemen met betrekking tot gedistribueerde computing en kunstmatige intelligentie. Hij richt zich op Deep learning inclusief NLP en Computer Vision domeinen. Hij helpt klanten bij het bereiken van high-performance modelinferentie op SageMaker.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/explain-text-classification-model-predictions-using-amazon-sagemaker-clarify/

