

@sagolunTaras Baranyuk
17+ jaar ervaring in het maken van softwareproducten in verschillende functies.
Sentimentanalyse is een Natuurlijke taalverwerking (NLP) techniek die wordt gebruikt om te bepalen of gegevens dat zijn positief, negatiefof neutraal.
Sentimentanalyse is fundamenteel, omdat het helpt om de emotionele tonen in taal te begrijpen. Dit helpt op zijn beurt om automatisch de meningen achter beoordelingen, discussies op sociale media, enz. Te sorteren, zodat u snellere, nauwkeurigere beslissingen kunt nemen.
Hoewel sentimentanalyse de laatste tijd enorm populair is geworden, wordt er sinds het begin van de jaren 2000 aan gewerkt.
Traditionele machine learning-methoden zoals Naive Bayesian, Logistic Regression en Support Vector Machines (SVM's) worden veel gebruikt voor grootschalige sentimentanalyse omdat ze goed kunnen worden geschaald. Het is nu bewezen dat Deep Learning (DL) -technieken een betere nauwkeurigheid bieden voor verschillende NLP-taken, waaronder sentimentanalyse; ze zijn echter meestal langzamer en duurder om te leren en te gebruiken.
In dit verhaal wil ik een weinig bekend alternatief bieden dat snelheid en kwaliteit combineert. Voor conclusies en beoordelingen van de voorgestelde methode heb ik een baselinemodel nodig. Ik koos voor de beproefde en populaire BERT.
De gegevens ophalen
Social media is een bron die op ongekende schaal een enorme hoeveelheid data produceert. De dataset die ik voor dit verhaal ga gebruiken is Coronavirus tweet NLP.
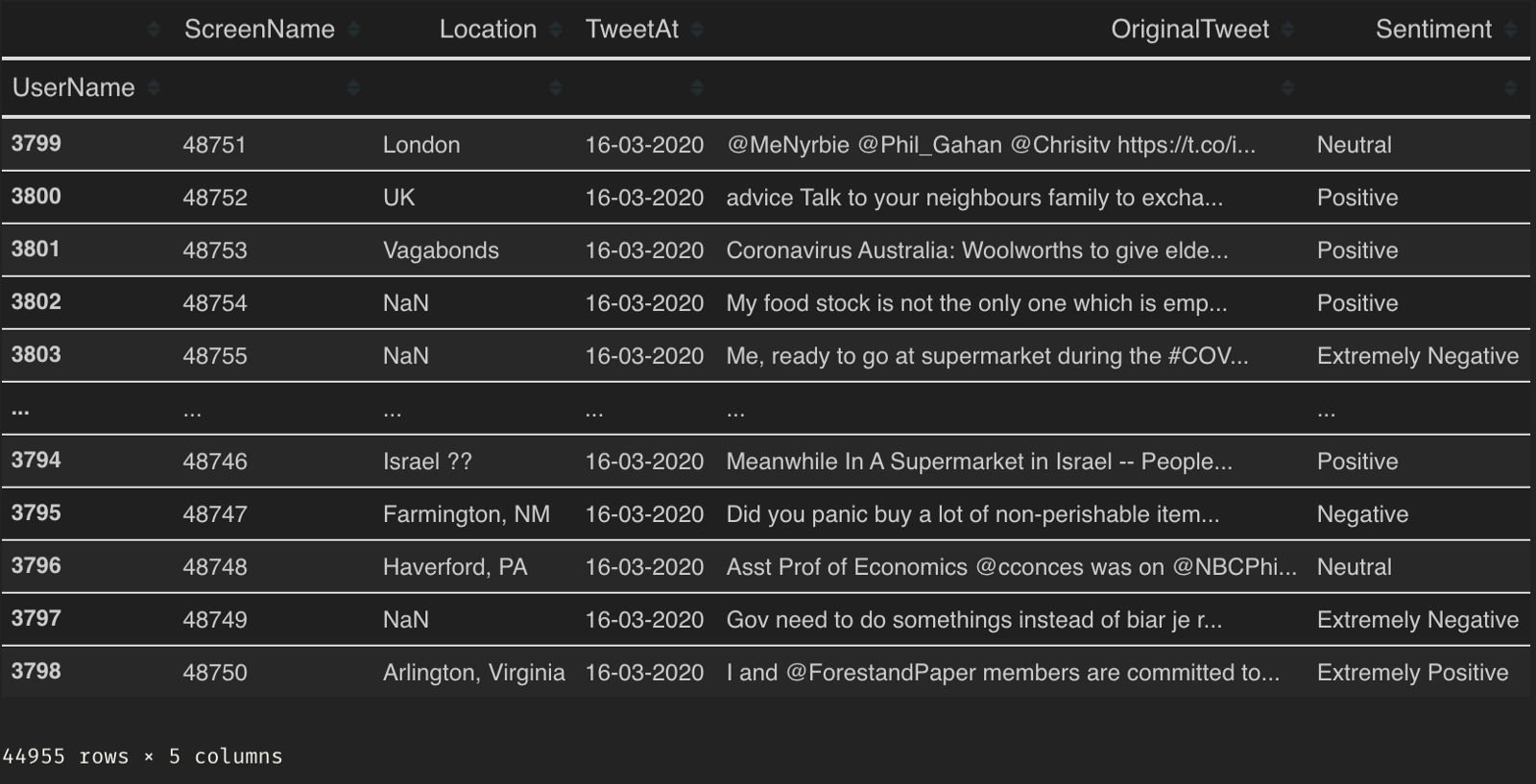
Zoals ik kan zien, zijn er niet zo veel gegevens voor het model, en op het eerste gezicht lijkt het erop dat men niet zonder een vooraf getraind model kan.
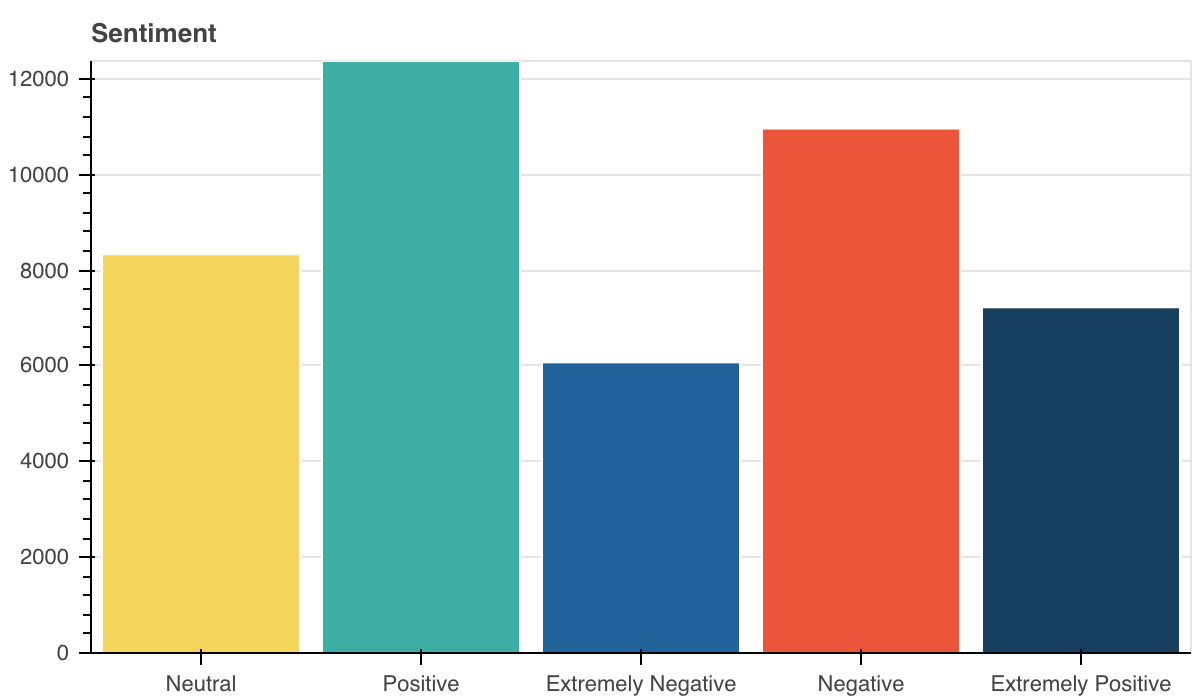
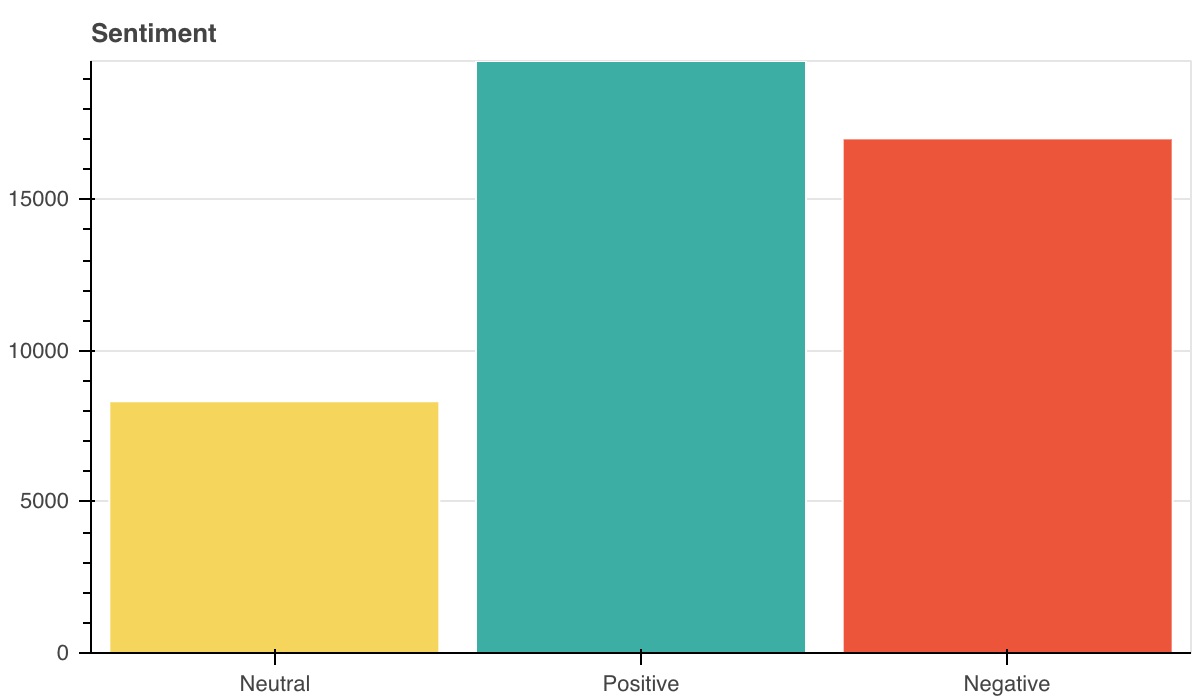
Vanwege het kleine aantal samples voor training reduceer ik het aantal lessen tot 3 door ze te combineren.
Baseline BERT-model
Laten we TensorFlow Hub gebruiken. TensorFlow Hub is een opslagplaats van getrainde machine learning-modellen die klaar zijn voor afstemming en overal inzetbaar zijn. U kunt getrainde modellen zoals BERT en Faster R-CNN gebruiken met slechts een paar regels code.
!pip install tensorflow_hub
!pip install tensorflow_textsmall_bert / bert_en_uncased_L-4_H-512_A-8 - Kleiner BERT-model.
Dit is een van de kleinere BERT-modellen waarnaar wordt verwezen Goedgelezen studenten leren beter: over het belang van compacte modellen voorafgaand aan de training De kleinere BERT-modellen zijn bedoeld voor omgevingen met beperkte rekenkracht. Ze kunnen op dezelfde manier worden verfijnd als de originele BERT-modellen. Ze zijn echter het meest effectief in de context van kennisdistillatie, waar een grotere en nauwkeurigere leraar de afstemmingslabels produceert.
bert_en_uncased_preprocess - Tekstvoorbewerking voor BERT. Dit model maakt gebruik van een Engelse woordenschat uit Wikipedia en BooksCorpus. Tekstinvoer is genormaliseerd op de "niet-gekapte" manier, wat betekent dat de tekst in kleine letters is geschreven voordat de tekst in woordstukken is omgezet, en dat eventuele accentmarkeringen zijn verwijderd.
tfhub_handle_encoder = "https://tfhub.dev/tensorflow/small_bert/bert_en_uncased_L-4_H-512_A-8/1"
tfhub_handle_preprocess = "https://tfhub.dev/tensorflow/bert_en_uncased_preprocess/3"Ik zal de selectie van parameters en optimalisatie niet maken om de code niet ingewikkelder te maken. Toch is dit het basismodel, niet SOTA.
def build_classifier_model(): text_input = tf.keras.layers.Input( shape=(), dtype=tf.string, name='text') preprocessing_layer = hub.KerasLayer( tfhub_handle_preprocess, name='preprocessing') encoder_inputs = preprocessing_layer(text_input) encoder = hub.KerasLayer( tfhub_handle_encoder, trainable=True, name='BERT_encoder') outputs = encoder(encoder_inputs) net = outputs['pooled_output'] net = tf.keras.layers.Dropout(0.1)(net) net = tf.keras.layers.Dense( 3, activation='softmax', name='classifier')(net) model = tf.keras.Model(text_input, net) loss = tf.keras.losses.CategoricalCrossentropy(from_logits=True) metric = tf.metrics.CategoricalAccuracy('accuracy') optimizer = Adam( learning_rate=5e-05, epsilon=1e-08, decay=0.01, clipnorm=1.0) model.compile( optimizer=optimizer, loss=loss, metrics=metric) model.summary() return modelIk heb een model gemaakt met iets minder dan 30 miljoen parameters.
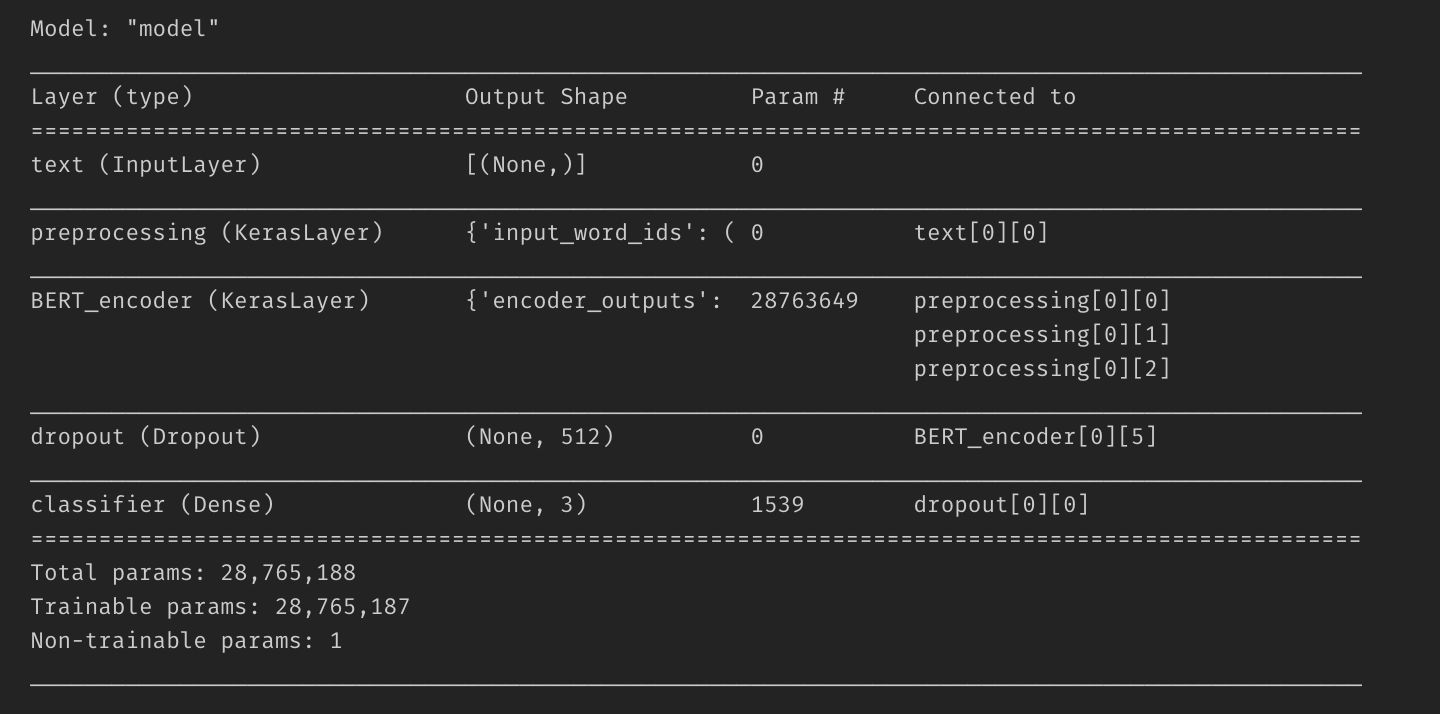
Ik heb 30 procent van de trein gegevens voor modelvalidatie.
train, valid = train_test_split( df_train, train_size=0.7, random_state=0, stratify=df_train['Sentiment'])
y_train, X_train = train['Sentiment'], train.drop(['Sentiment'], axis=1)
y_valid, X_valid = valid['Sentiment'], valid.drop(['Sentiment'], axis=1)
y_train_c = tf.keras.utils.to_categorical( y_train.astype('category').cat.codes.values, num_classes=3)
y_valid_c = tf.keras.utils.to_categorical( y_valid.astype('category').cat.codes.values, num_classes=3)Het aantal tijdperken is intuïtief gekozen en hoefde niet te worden gerechtvaardigd 🙂
history = classifier_model.fit( x=X_train['Tweet'].values, y=y_train_c, validation_data=(X_valid['Tweet'].values, y_valid_c), epochs=5)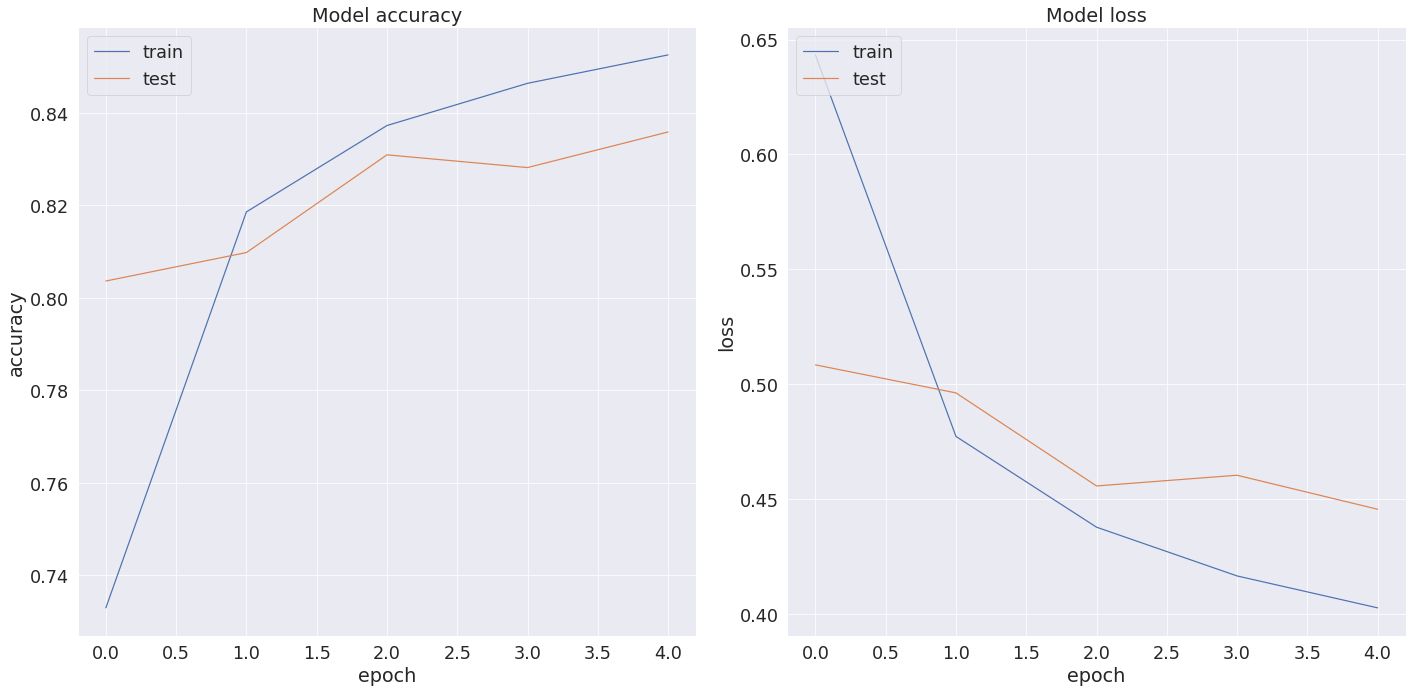
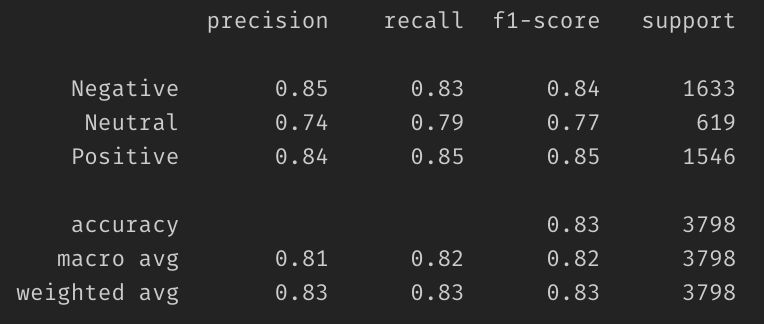
BERT Accuracy: 0.833859920501709Verwaringsmatrix:
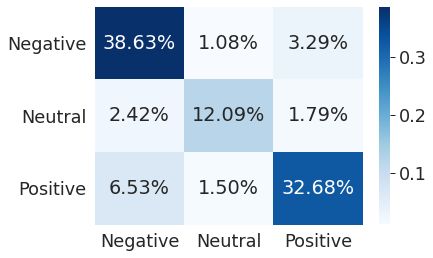
Classificatierapport:

Hier heb ik het basismodel. Het is duidelijk dat ik dit model verder kan verbeteren. Maar laten we deze taak als uw huiswerk laten.
CatBoost-model
KatBoost is een hoogwaardige, open-sourcebibliotheek voor het verhogen van de gradiënt van beslissingsbomen. Vanaf release 0.19.1 ondersteunt het out-of-the-box tekstfuncties voor classificatie op GPU.
Het belangrijkste voordeel is dat CatBoost categorische functies en tekstfuncties in uw gegevens kan opnemen zonder extra voorverwerking. Voor degenen die waarde hechten aan inferentiesnelheid: CatBoost-voorspellingen zijn 20 tot 40 keer sneller dan andere open-source gradiëntverhogende bibliotheken, waardoor CatBoost nuttig is voor latentiekritieke taken.
!pip install catboostIk zal niet de optimale parameters selecteren; laat dat je andere huiswerk zijn. Laten we een functie schrijven om het model te initialiseren en te trainen.
def fit_model(train_pool, test_pool, **kwargs): model = CatBoostClassifier( task_type='GPU', iterations=5000, eval_metric='Accuracy', od_type='Iter', od_wait=500, **kwargs )
return model.fit( train_pool, eval_set=test_pool, verbose=100, plot=True, use_best_model=True)Als ik met CatBoost werk, raad ik aan om een Zwembad The Pool is een handige wrapper die functies, labels en andere metadata zoals categorische en tekstfuncties combineert.
train_pool = Pool( data=X_train, label=y_train, text_features=['Tweet']
)
valid_pool = Pool( data=X_valid, label=y_valid, text_features=['Tweet']
)Tekstfuncties - Een eendimensionale matrix van indices van tekstkolommen (gespecificeerd als gehele getallen) of namen (gespecificeerd als strings). Alleen gebruiken als de dataparameter een tweedimensionale objectmatrix is (heeft een van de volgende typen: lijst, numpy.ndarray, pandas.DataFrame, pandas.Series). Als elementen in deze array zijn opgegeven als namen in plaats van indices, moeten namen voor alle kolommen worden opgegeven. Gebruik hiervoor de parameter feature_names van deze constructor om ze expliciet op te geven of geef een pandas.DataFrame door met kolomnamen die zijn opgegeven in de dataparameter.
ondersteunde trainingsparameters:
- tokenizers - Tokenizers worden gebruikt om functiekolommen van het teksttype voor te verwerken voordat het woordenboek wordt gemaakt.
- woordenboeken - Woordenboeken die worden gebruikt om functiekolommen van het teksttype voor te verwerken.
- feature_calcers - Feature calcers gebruikt om nieuwe features te berekenen op basis van voorverwerkte tekst type feature kolommen.
Ik stel alle parameters intuïtief in; het afstemmen ervan wordt weer je huiswerk.
model = fit_model( train_pool, valid_pool, learning_rate=0.35, tokenizers=[ { 'tokenizer_id': 'Sense', 'separator_type': 'BySense', 'lowercasing': 'True', 'token_types':['Word', 'Number', 'SentenceBreak'], 'sub_tokens_policy':'SeveralTokens' } ], dictionaries = [ { 'dictionary_id': 'Word', 'max_dictionary_size': '50000' } ], feature_calcers = [ 'BoW:top_tokens_count=10000' ]
)Nauwkeurigheid:
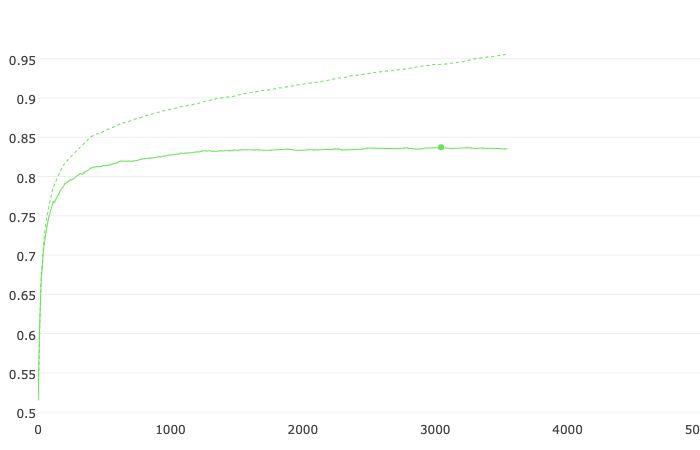
Verlies:

CatBoost model accuracy: 0.8299104791995787Verwaringsmatrix:
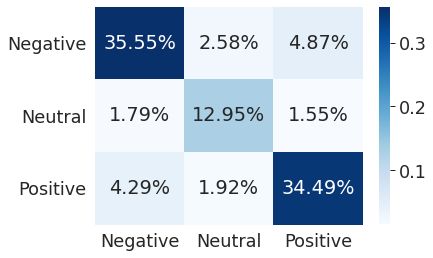
Classificatierapport:
Het resultaat komt heel dicht in de buurt van wat het BERT-basismodel heeft laten zien. Omdat ik heel weinig gegevens heb voor training en het model vanaf nul is onderwezen, is het resultaat naar mijn mening indrukwekkend.
Bonus
Ik heb twee modellen met zeer vergelijkbare resultaten. Kan dit ons nog iets anders nuttigs opleveren? Beide modellen hebben in de kern weinig gemeen, wat betekent dat hun combinatie een synergetisch effect moet geven. De eenvoudigste manier om deze conclusie te testen, is door het resultaat te middelen en te kijken wat er gebeurt.
y_proba_avg = np.argmax((y_proba_cb + y_proba_bert)/2, axis=1)De winst is indrukwekkend.
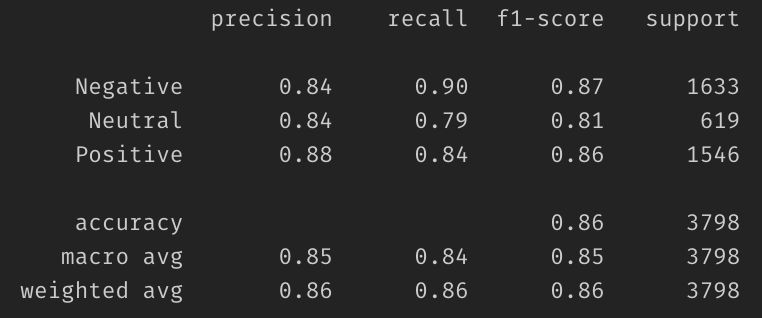
Average accuracy: 0.855713533438652Verwaringsmatrix:

Classificatierapport:
Samengevat
In dit verhaal, ik:
- creëerde een baselinemodel met BERT;
- een model gemaakt met CatBoost met behulp van ingebouwde tekstmogelijkheden;
- gekeken wat er gebeurt als het resultaat van beide modellen gemiddeld wordt.
Naar mijn mening kunnen complexe en langzame SOTA's in de meeste gevallen worden vermeden, vooral als snelheid een cruciale behoefte is.
CatBoost biedt direct uit de doos geweldige mogelijkheden voor sentimentanalyse. Voor wedstrijdliefhebbers zoals Kaggle, Gedreven gegevens, enz., kan CatBoost een goed model bieden, zowel als basisoplossing als als onderdeel van een ensemble van modellen.
De code uit het verhaal kan worden bekeken hier.
Verwant

 14 reacties
14 reacties
7 reacties

Tags
Maak uw gratis account aan om uw persoonlijke leeservaring te ontgrendelen.
Afrekenen PrimeXBT
Handel met de officiële CFD-partners van AC Milan
De eenvoudigste manier om crypto te verhandelen.
Bron: https://hackernoon.com/unconventional-sentiment-analysis-bert-vs-catboost-713v33zz?source=rss

