Niet alleen voor deep learning: hoe GPU's datawetenschap en data-analyse versnellen
Het succes van moderne AI/ML-systemen is in grote mate afhankelijk geweest van hun vermogen om enorme hoeveelheden onbewerkte gegevens parallel te verwerken met behulp van voor taak geoptimaliseerde hardware. Kunnen we de kracht van GPU en gedistribueerde computing ook gebruiken voor reguliere gegevensverwerkingstaken?

Hoe GPU's datawetenschap en data-analyse versnellen
Kunstmatige intelligentie (AI) zal de wereldwijde productiviteit, werkpatronen en levensstijlen veranderen en enorme rijkdom creëren. Onderzoeksbureau Gartner verwacht dat de wereldwijde AI-economie zal toenemen van ongeveer $ 1.2 biljoen vorig jaar tot ongeveer $ 3.9 biljoen tegen 2022, terwijl McKinsey ziet dat het een wereldwijde economische activiteit van ongeveer $ 13 biljoen door 2030. In veel opzichten wordt deze transformatie in de kern gevoed door krachtige Machine Learning (ML)-tools en -technieken.
Het is nu algemeen bekend dat het succes van moderne AI/ML-systemen in grote mate afhankelijk is geweest van hun vermogen om: enorme hoeveelheden onbewerkte gegevens op een parallelle manier verwerken met voor taak geoptimaliseerde hardware. Daarom speelde het gebruik van gespecialiseerde hardware zoals Graphics Processing Units (GPU's) een belangrijke rol in dit vroege succes. Sindsdien is er veel nadruk gelegd op het bouwen van sterk geoptimaliseerde softwaretools en aangepaste wiskundige verwerkingsengines (zowel hardware als software) om de kracht en architectuur van GPU's en parallel computing te benutten.
Hoewel het gebruik van GPU's en gedistribueerde computing veel wordt besproken in academische en zakelijke kringen voor kerntaken op het gebied van AI/ML (bijvoorbeeld het uitvoeren van een 100-laags diep neuraal netwerk voor beeldclassificatie of een BERT-spraaksynthesemodel met miljard parameters), vinden ze minder dekking als het gaat om hun bruikbaarheid voor reguliere datawetenschaps- en data-engineeringtaken. Deze gegevensgerelateerde taken zijn de essentiële voorloper van elke ML-workload in een AI-pipeline en ze vormen vaak een meerderheidspercentage van de tijd en intellectuele inspanning die wordt besteed door een datawetenschapper of zelfs een ML-ingenieur.
Onlangs sprak de beroemde AI-pionier Andrew Ng over de overgang van een modelgerichte naar een datagerichte benadering voor AI ontwikkeling van hulpmiddelen. Dit betekent dat u veel meer tijd besteedt aan de onbewerkte gegevens en deze voorverwerkt voordat een daadwerkelijke AI-workload op uw pijplijn wordt uitgevoerd.
Je kunt het interview met Andrew hier bekijken: https://www.youtube.com/watch?v=06-AZXmwHjo

Dit brengt ons bij een belangrijke vraag…
Kunnen we de kracht van GPU en gedistribueerd computergebruik ook gebruiken voor reguliere gegevensverwerkingstaken??
Het antwoord is niet triviaal en vereist enige speciale aandacht en kennisuitwisseling. In dit artikel zullen we proberen enkele van de tools en platforms te laten zien die voor dit doel kunnen worden gebruikt.

Beeldbron
RAPIDS: gebruik GPU voor datawetenschap
De VERSNELLINGEN suite van open source softwarebibliotheken en API's geeft u de mogelijkheid om end-to-end datawetenschaps- en analysepijplijnen volledig op GPU's uit te voeren. NVIDIA heeft dit project geïncubeerd en tools gebouwd om te profiteren van CUDA-primitieven voor computeroptimalisatie op laag niveau. Het richt zich specifiek op het blootleggen van GPU-parallellisme en geheugensnelheidsfuncties met hoge bandbreedte via de vriendelijke Python-taal populair bij alle datawetenschappers en analyseprofessionals.
Veelvoorkomende taken voor gegevensvoorbereiding en ruzie worden zeer gewaardeerd in het RAPIDS-ecosysteem omdat ze een aanzienlijke hoeveelheid tijd in beslag nemen in een typische datawetenschapspijplijn. een bekende dataframe-achtige API is ontwikkeld met veel optimalisatie en robuustheid ingebouwd. Het is ook aangepast om te integreren met een verscheidenheid aan ML-algoritmen voor end-to-end pijplijnversnellingen met stijgende serialisatiekosten.
RAPIDS bevat ook een aanzienlijke hoeveelheid interne ondersteuning voor multi-node, multi-GPU-implementatie en gedistribueerde verwerking. Het integreert met andere bibliotheken die maken: geen geheugen meer (dwz dataset groter dan individuele computer RAM) gegevensverwerking gemakkelijk en toegankelijk voor individuele datawetenschappers.
Dit zijn de meest prominente bibliotheken die zijn opgenomen in het RAPIDS-ecosysteem.
CuPy
Een door CUDA aangedreven array-bibliotheek die eruitziet en aanvoelt als Numpy, de basis van alle numerieke computing en ML met Python. Het maakt gebruik van CUDA-gerelateerde bibliotheken, waaronder cuBLAS, cuDNN, cuRand, cuSolver, cuSPARSE, cuFFT en NCCL om volledig gebruik te maken van de GPU-architectuur met als doel GPU-versneld computergebruik met Python te bieden.
De interface van CuPy lijkt sterk op die van NumPy en kan worden gebruikt als een eenvoudige vervanging voor de meeste gebruikssituaties. Hier is de gedetailleerde lijst op moduleniveau van API-compatibiliteit tussen CuPy en NumPy.
Bekijk de CuPy-vergelijkingstabel.
De versnelling ten opzichte van NumPy kan verbijsterend zijn, afhankelijk van het gegevenstype en de gebruikssituatie. Hier is een versnelde vergelijking tussen CuPy en NumPy voor twee verschillende arraygroottes en voor verschillende veelvoorkomende numerieke bewerkingen - FFT, slicing, som en standaarddeviatie, matrixvermenigvuldiging, SVD - die veel worden gebruikt door bijna alle ML-algoritmen.
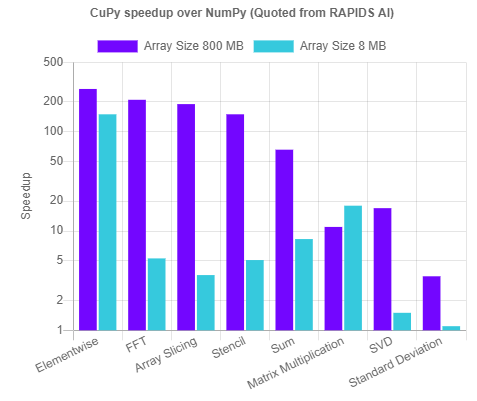
CuPy-snelheden vergeleken met NumPy, Beeldbron
CuDF
Gebouwd op basis van het zuilvormige geheugenformaat Apache Arrow, cuDF is een GPU DataFrame-bibliotheek voor het laden, samenvoegen, aggregeren, filteren en anderszins manipuleren van gegevens. Het biedt een panda-achtige API dat zal bekend zijn bij bijna alle data-ingenieurs en datawetenschappers, zodat ze het kunnen gebruiken om hun workflows gemakkelijk te versnellen met behulp van krachtige GPU's zonder in te gaan op de details van CUDA-programmering.
Momenteel wordt cuDF alleen ondersteund op Linux en met Python-versies 3.7 en hoger. Andere eisen zijn,
- CUDA 11.0+
- NVIDIA-stuurprogramma 450.80.02+
- Pascal-architectuur of beter (Compute Capability >=6.0)
Bekijk meer over deze krachtige bibliotheek in de API-documenten voor CuDF.
Tenslotte datawetenschappers en analisten (dat wil zeggen degenen die niet noodzakelijkerwijs diepgaand leren in een van hun dagelijkse taken) kunnen zich verheugen en krachtige AI-werkstations gebruiken zoals de volgende om hun productiviteit te verhogen.

Data science werkstation van Exact Corporation, Beeldbron
CuML
cuML stelt datawetenschappers, analisten en onderzoekers in staat om traditionele/klassieke ML algoritmische taken uit te voeren met (meestal) tabellarische datasets op GPU's zonder in te gaan op de details van CUDA-programmering. In de meeste gevallen komt de Python API van cuML overeen met die van de populaire Python-bibliotheek Scikit - leer de overgang naar GPU-hardware snel en pijnloos te maken.
Bekijk de GitHub-opslagplaats voor CuML documentatie voor meer informatie.
CuML integreert ook met Dashboard, waar het kan, aan te bieden multi-GPU en multi-node-GPU-ondersteuning voor een steeds groter aantal algoritmen die profiteren van dergelijke gedistribueerde verwerking.
CuGraf
CuGraph is een verzameling GPU-versnelde grafiekalgoritmen die gegevens verwerken die zijn gevonden in GPU-gegevensframes. De visie van cuGraph is om grafiekanalyse alomtegenwoordig te maken tot het punt dat gebruikers alleen denken in termen van analyse en niet in technologieën of kaders.
Datawetenschappers die bekend zijn met Python zullen snel doorhebben hoe cuGraph integreert met de Pandas-achtige API van cuDF. Evenzo zullen gebruikers die bekend zijn met NetworkX de NetworkX-achtige API in cuGraph snel herkennen, met als doel om bestaande code met minimale inspanning naar RAPIDS te porteren.
Momenteel ondersteunt het allerlei algoritmen voor grafiekanalyse,
- Centrality
- Gemeenschap
- Link analyse
- Linkvoorspelling
- traversal
Veel wetenschappelijke en zakelijke analysetaken omvatten het gebruik van uitgebreide grafiekalgoritmen op grote datasets. Bibliotheken zoals cuGraph geven de zekerheid van een hogere productiviteit aan die ingenieurs wanneer ze investeren in GPU-aangedreven werkstations.

Maak sociale grafiekanalyse mogelijk met behulp van GPU-versneld computergebruik, Beeldbron
De algemene pijplijn voor GPU-gegevenswetenschap
RAPIDS voorziet als volgt een hele pijplijn voor GPU-aangedreven datawetenschapstaken. Let daar op deep learning, dat van oudsher de primaire focus was van GPU-gebaseerde computing, is slechts een subonderdeel van dit systeem.

De GPU Data Science-pijplijn, Beeldbron
Dask: gedistribueerde analyse met Python
Zoals we hebben opgemerkt, kunnen moderne pijplijnen voor gegevensverwerking vaak profiteren van gedistribueerde verwerking van grote gegevensbrokken. Dit verschilt enigszins van het parallellisme dat wordt geboden door de duizenden kernen in een enkele GPU. Dit gaat meer over het opsplitsen van een alledaagse gegevensverwerking (die kan plaatsvinden lang voordat de gegevensset klaar is voor ML-algoritmen) in brokken en verwerken in het gebruik van meerdere rekenknooppunten.
Deze rekenknooppunten kunnen GPU-kernen zijn of het kunnen zelfs eenvoudige logische/virtuele kernen van de CPU zijn.
Met opzet, meest populaire data science-bibliotheken zoals Pandas, Numpy en Scikit-learn kunnen niet gemakkelijk profiteren van echt gedistribueerde verwerking. Dask probeert dit probleem op te lossen door de functies van intelligente taakplanning en big data chunk-verwerking in reguliere Python-code te brengen. Uiteraard bestaat het uit twee delen:
- Dynamische taakplanning geoptimaliseerd voor berekeningen. Dit is vergelijkbaar met Airflow, Luigi, Celery of Make, maar geoptimaliseerd voor interactieve rekentaken.
- "Big Data"-verzamelingen zoals parallelle arrays, dataframes en lijsten die gemeenschappelijke interfaces zoals NumPy, Panda's of Python-iterators uitbreiden naar meer dan geheugen of gedistribueerde omgevingen. Deze parallelle collecties draaien bovenop de eerder genoemde dynamische taakplanners.
Hier is een illustratief diagram van een typische Dask-taakstroom.
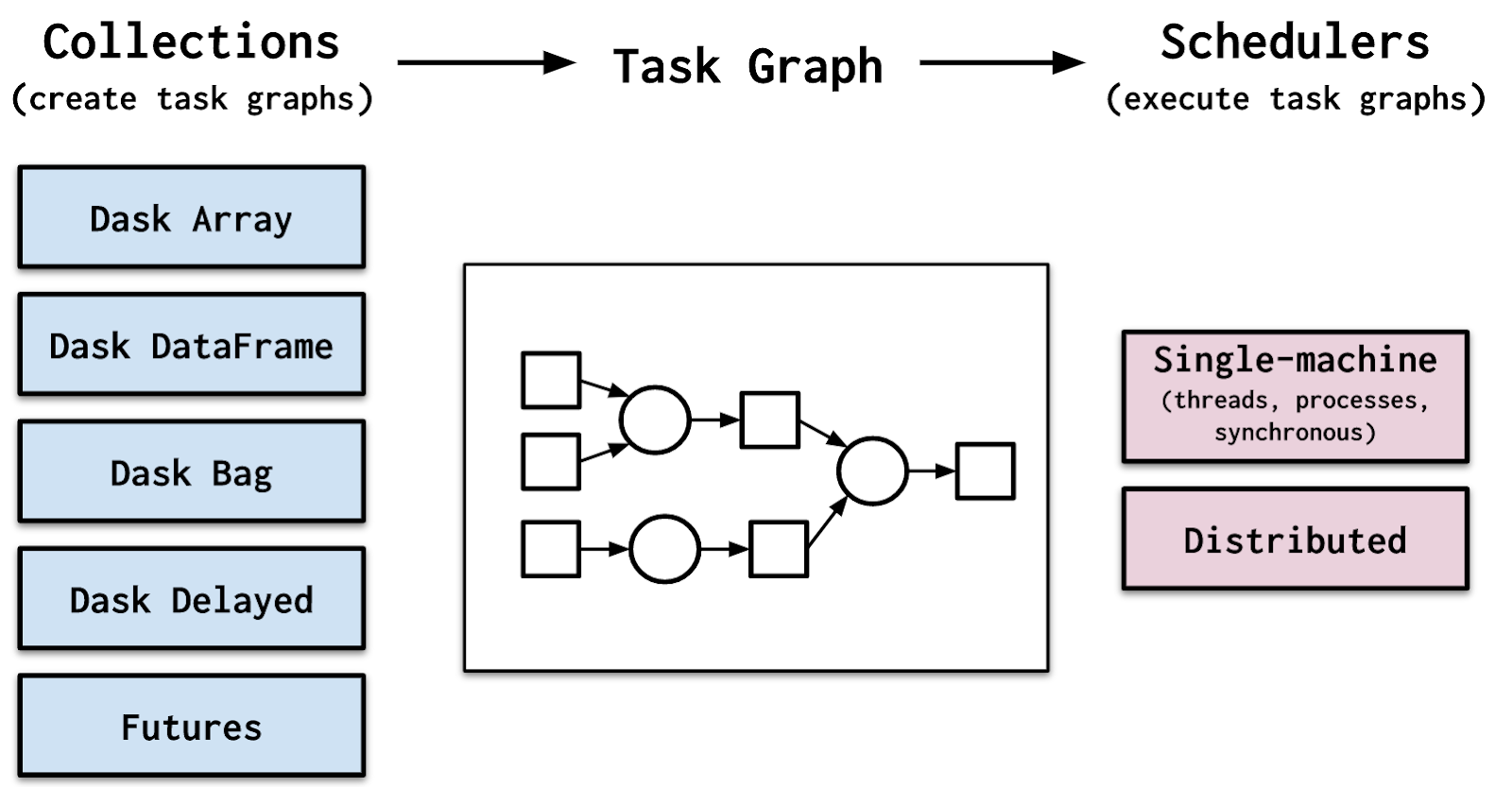
Officiële Dask Flow-documentatie, Beeldbron
Eenvoudig om te zetten bestaande codebase
Vertrouwdheid vormt de kern van het Dask-ontwerp, zodat een typische datawetenschapper dat kan pak gewoon zijn/haar bestaande op Panda's/Numpy gebaseerde codebase en converteer deze naar Dask-code een minimale leercurve volgen. Hier zijn enkele van de canonieke voorbeelden uit hun officiële documentatie.
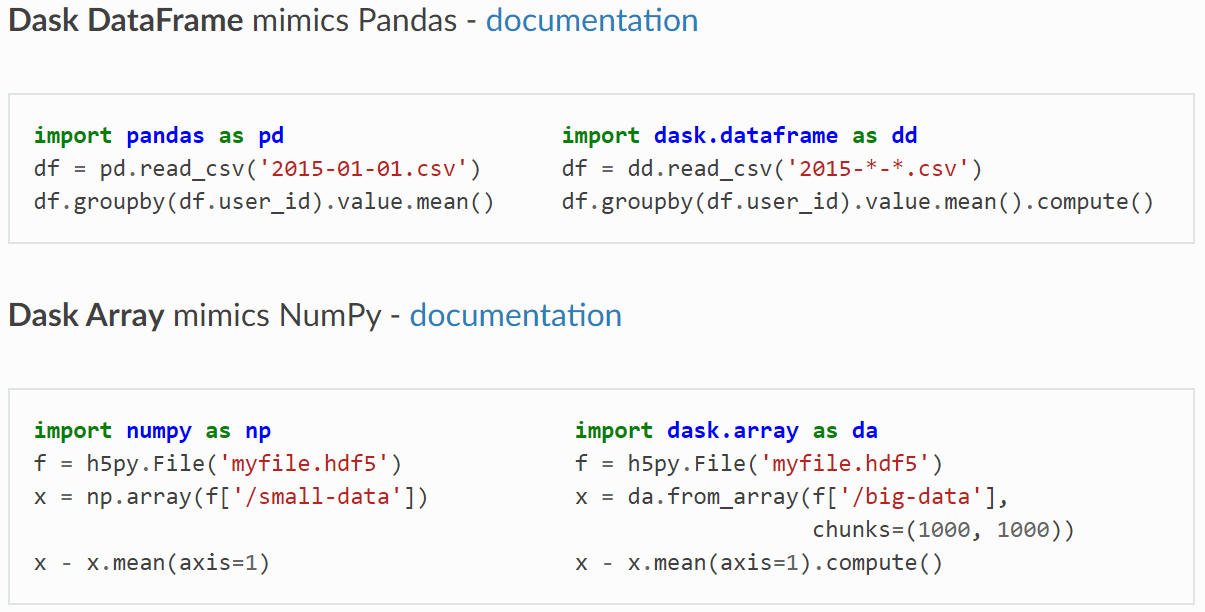
Dask-documentatie waarin Panda's en NumPy worden vergeleken, Beeldbron
Dask-ML voor schaalbaarheidsuitdagingen
Er zijn verschillende soorten schaalbaarheidsuitdagingen voor ML-ingenieurs. De volgende afbeelding illustreert ze. De machine learning-bibliotheek Dask-ML biedt iets voor elk van deze scenario's. Daarom kan men zich concentreren op modelgerichte verkenning of datacentrische ontwikkeling op basis van de unieke bedrijfs- of onderzoeksvereisten.
Het belangrijkste is dat focus op vertrouwdheid hier weer een rol speelt en de DASK-ML API is ontworpen om die van de alom populaire Scikit-learn API na te bootsen.

Dask-documentatie voor XGBRegressor, Beeldbron
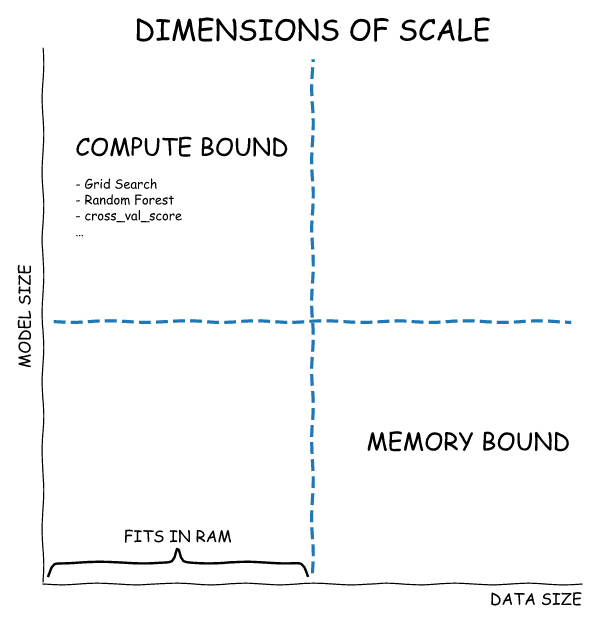
Voordelen van Dask van multi-core CPU-systemen
Opgemerkt moet worden dat de primaire aantrekkingskracht van Dask voortkomt uit zijn rol als een efficiënte taakplanner op hoog niveau die met elke Python-code of datastructuur kan werken. Daarom is het niet afhankelijk van een GPU om bestaande datawetenschapsworkloads te stimuleren met gedistribueerde verwerking.
Zelfs multi-core CPU-systemen kunnen optimaal profiteren van Dask als de code is geschreven om daarop te focussen. Grote wijzigingen in de code zijn niet nodig.
Met Dask kunt u uw convexe optimalisatieroutine of hyperparameterzoekopdracht over vele kernen van uw laptop verdelen. Of u kunt gewoon verschillende delen van een eenvoudig DataFrame verwerken op basis van enkele filtercriteria met behulp van het volledige multi-core parallellisme. Dit opent de mogelijkheid om de productiviteit te verhogen van alle datawetenschappers en analisten die geen dure grafische kaarten voor hun machine hoeven te kopen, maar gewoon kunnen investeren in een werkstation met 16 of 24 CPU-kernen.
Samenvatting van gedistribueerde datawetenschap aangedreven door GPU's
In dit artikel hebben we enkele opwindende nieuwe ontwikkelingen besproken in het Python-ecosysteem voor datawetenschap, waardoor gewone datawetenschappers, analisten, wetenschappelijke onderzoekers, academici GPU-aangedreven hardwaresystemen kunnen gebruiken voor een veel grotere verscheidenheid aan gegevensgerelateerde taken dan alleen wat gerelateerd is tot beeldclassificatie en natuurlijke taalverwerking. Dit zal de aantrekkingskracht van dergelijke hardwaresystemen zeker vergroten voor deze grote groepen gebruikers en het gebruikersbestand van datawetenschap nog meer democratiseren.
We hebben ook gesproken over de mogelijkheden van gedistribueerde analyse met de Dask-bibliotheek die multi-core CPU-werkstations kan gebruiken.
Hopelijk zal dit soort convergentie van krachtige hardware en moderne softwarestack eindeloze mogelijkheden bieden voor zeer efficiënte datawetenschapsworkflows.
ORIGINELE. Met toestemming opnieuw gepost.
Zie ook:
PlatoAi. Web3 opnieuw uitgevonden. Gegevensintelligentie versterkt.
Klik hier om toegang te krijgen.

