
Afbeelding door auteur
Machine learning is een groeiend veld dat de manier verandert waarop we gegevens verwerken en analyseren.
Bootstrapping is een belangrijke techniek in de wereld van machine learning. Het is cruciaal voor het bouwen van robuuste en nauwkeurige modellen.
In dit artikel gaan we dieper in op wat bootstrapping is en hoe het kan worden gebruikt bij machine learning.
We zullen ook de beslissingsboomclassificatie en de Iris-dataset onderzoeken. Het zal worden gebruikt om bootstrapping te tonen in een realistisch voorbeeld.
Met dit artikel willen we een uitgebreid begrip van bootstrapping bieden.
We zullen ook de toepassingen ervan in machine learning behandelen. Dat zal u voorzien van de kennis om het op uw eigen toe te passen machine learning-projecten.
Maar eerst, wat is bootstrapping?
Bootstrapping is een resampling-techniek die helpt bij het schatten van de onzekerheid van een statistisch model.
Het omvat het bemonsteren van de originele dataset met vervanging en het genereren van meerdere nieuwe datasets van dezelfde grootte als het origineel.
Elk van deze nieuwe datasets wordt vervolgens gebruikt om de gewenste statistiek te berekenen, zoals het gemiddelde of de standaarddeviatie.
Dit proces wordt meerdere keren herhaald en de resulterende waarden worden gebruikt om een kansverdeling voor de gewenste statistiek te construeren.
Deze techniek wordt vaak gebruikt bij machine learning om de nauwkeurigheid van een model te schatten, de prestaties ervan te valideren en gebieden te identificeren die verbetering behoeven.
We kunnen bijvoorbeeld bootstrap-sampling gebruiken om de populatiegemiddelden te berekenen. Het resultaat zou ook als volgt zijn.
Afbeelding door auteur
We zullen dit voorbeeld later in dit artikel ook behandelen.
Bootstrapping kan op verschillende manieren worden gebruikt bij machine learning, waaronder het schatten van modelprestaties, modelselectie en het identificeren van de belangrijkste kenmerken in een dataset.
Een van de populaire use-cases van bootstrapping bij machine learning is het schatten van de nauwkeurigheid van een classificatie, wat we in dit artikel zullen doen.
Laten we beginnen met een eenvoudig voorbeeld van bootstrapping in Python als opwarming.
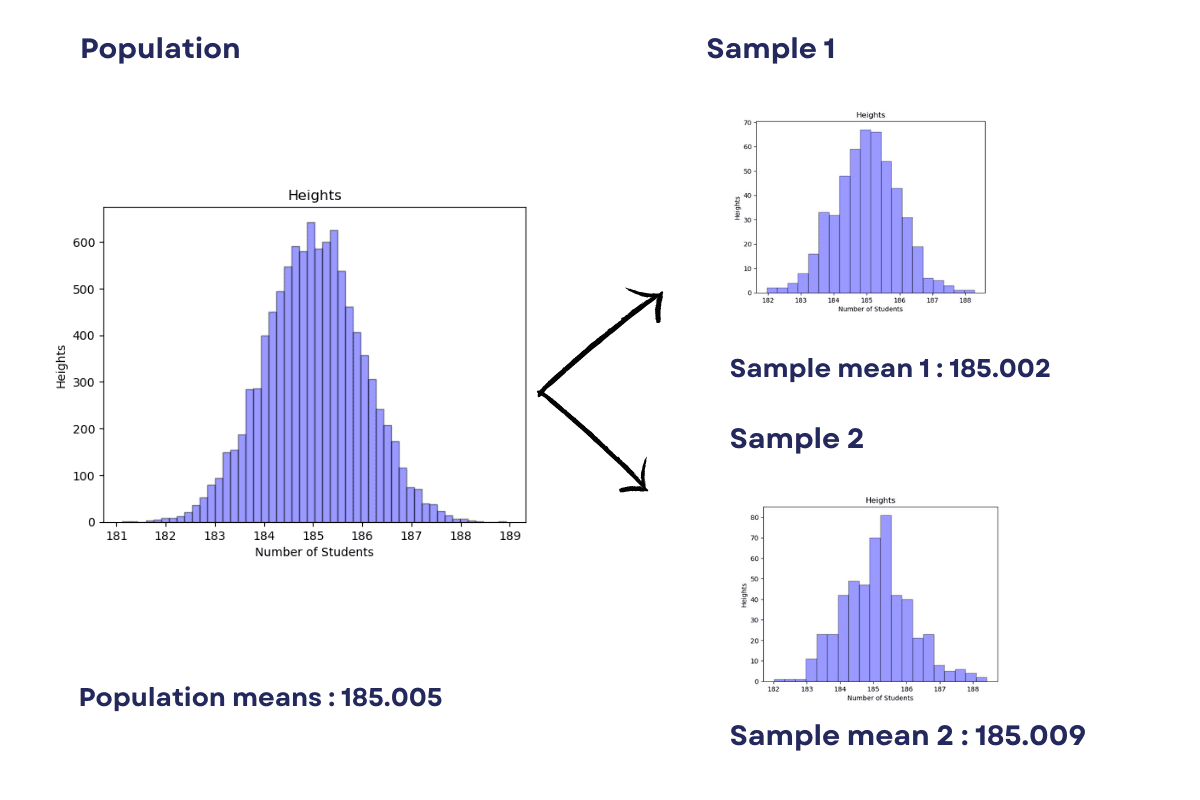
We zullen laten zien hoe bootstrapping kan worden gebruikt om de gemiddelde lengte van leerlingen in een school met 10,000 leerlingen te schatten.
De algemene benadering is om het gemiddelde te berekenen door alle hoogten bij elkaar op te tellen en de som te delen door 10,000.
Genereer eerst een steekproef van 10,000 willekeurig gegenereerde getallen (hoogten) met behulp van de NumPy-bibliotheek.
import numpy as np
import pandas as pd
x = np.random.normal(loc= 185.0, scale=1.0, size=10000)
np.mean(x)
Hier is de output van het gemiddelde.
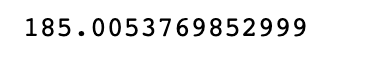
Hoe kunnen we nu de lengte van deze studenten berekenen op basis van 200 studenten?
Bij bootstrap-steekproeven maken we verschillende steekproeven van de populatie door willekeurig elementen uit de populatie te selecteren met vervangingen.
In ons voorbeeld is de steekproefomvang 5. Dit betekent dat er 40 steekproeven zijn voor de populatie van 200 studenten.
Met onderstaande code trekken we 40 steekproeven, grootte van 5, van de leerlingen. (X)
Dit omvat het trekken van willekeurige steekproeven met vervangingen van de originele steekproef om 40 nieuwe steekproeven te creëren.
Wat bedoel ik met vervangingen?
Ik bedoel eerst een van de 10,000 selecteren, vergeten wie ik heb gekozen, en dan weer een van de 10,000 selecteren.
Je kunt dezelfde student selecteren, maar de kans is klein. Vervangingen klinken niet zo slim meer, toch?
Elk nieuw monster heeft een grootte van 5, wat kleiner is dan het originele monster. Het gemiddelde van elk nieuw monster wordt berekend en opgeslagen in de lijst sample_mean.
Ten slotte wordt het gemiddelde van alle 40 steekproefgemiddelden berekend en vertegenwoordigt het de schatting van het populatiegemiddelde.
Hier is de code.
import random sample_mean = [] # Bootstrap Sampling
for i in range(40): y = random.sample(x.tolist(), 5) avg = np.mean(y) sample_mean.append(avg)
np.mean(sample_mean)
Hier is de uitvoer.
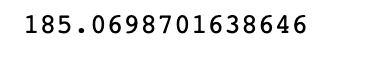
Het is redelijk dichtbij, toch?
Hier zullen we het gebruik van bootstrapping zien in classificatie met een beslissingsboom met behulp van de Iris-gegevensset. Maar laten we eerst eens kijken wat een beslisboom is.
Wat is een beslisboom?
A beslissingsboom is een van de populaire algoritmen voor machine learning die veel wordt gebruikt voor zowel classificatie- als regressieproblemen. Het is een op bomen gebaseerd model waarbij voorspellingen worden gedaan door vanuit het hoofdknooppunt te vertakken en beslissingen te nemen op basis van bepaalde voorwaarden.
De beslissingsboomclassificatie is een specifieke implementatie van dit algoritme dat wordt gebruikt om binaire classificatietaken uit te voeren.
Het hoofddoel van de beslisboomclassificatie is het bepalen van de belangrijkste kenmerken die bijdragen aan de voorspelling van een doelvariabele. Het algoritme gebruikt een hebzuchtige benadering om de onzuiverheid van de boom te minimaliseren door het kenmerk met de hoogste informatiewinst te selecteren. De boom gaat door met splitsen totdat de gegevens volledig zuiver zijn of totdat een stopcriterium is bereikt.
Wat is de Iris-gegevensset?
De Iris-dataset is een van de populaire datasets die worden gebruikt om classificatietaken te evalueren.
Deze dataset bevat 150 waarnemingen van irisbloemen, waarbij elke waarneming kenmerken bevat zoals de lengte van het kelkblad, de breedte van het kelkblaadje, de lengte van het bloemblad en de breedte van het bloemblad.
De doelvariabele is de soort van de irisplant.
De Iris-dataset wordt veel gebruikt in machine learning-algoritmen om de prestaties van verschillende modellen te evalueren en wordt ook gebruikt als voorbeeld om het concept van beslissingsboomclassificaties te demonstreren.
Laten we nu kijken hoe bootstrapping en een beslissingsboom in classificatie kunnen worden gebruikt.
Codering van Bootstrapping
De code implementeert een bootstrapping-techniek voor een machine learning-model met behulp van de DecisionTreeClassifier uit de sci-kit-learn-bibliotheek.
De eerste paar regels laden de Iris-gegevensset en extraheren de kenmerkgegevens (X) en doelgegevens (y) eruit.
De bootstrap-functie neemt de kenmerkgegevens (X), doelgegevens (y) en het aantal monsters (n_samples) op om te gebruiken bij bootstrapping.
De functie retourneert een lijst met getrainde modellen en een panda's-dataframe met precisie, recall, F1-score en de indices die worden gebruikt voor bootstrapping.
Het bootstrapping-proces wordt uitgevoerd in een for loop.
Voor elke iteratie gebruikt de functie de np.willekeurige.keuze methode om willekeurig een steekproef van de kenmerkgegevens (X) en doelgegevens (y) te selecteren.
De voorbeeldgegevens worden vervolgens opgesplitst in trainings- en testsets met behulp van de train_test_split methode. De DecisionTreeClassifier wordt getraind op de trainingsgegevens en vervolgens gebruikt om voorspellingen te doen over de testgegevens.
De precisie-, recall- en F1-scores worden berekend met behulp van de metrics.precision_score, metrics.recall_score en metrics.f1_score methoden uit de sci-kit-learn-bibliotheek. Deze scores worden vervolgens toegevoegd aan een lijst voor elke iteratie.
Ten slotte worden de resultaten opgeslagen in een panda-dataframe met kolommen voor precisie, recall, F1-score, de getrainde modellen en de indices die worden gebruikt voor bootstrapping. Het dataframe wordt vervolgens geretourneerd door de functie.
Laten we nu de code bekijken.
from sklearn import metrics
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_iris
from sklearn.tree import DecisionTreeClassifier # Load the iris dataset
iris = load_iris()
X, y = iris.data, iris.target def bootstrap(X, y, n_samples=2000): models = [] precision = [] recall = [] f1 = [] indices_x = [] indices_y = [] for i in range(n_samples): index_x = np.random.choice(X.shape[0], size=X.shape[0], replace=True) indices_x.append(index_x) X_sample = X[index_x, :] index_y = np.random.choice(y.shape[0], size=y.shape[0], replace=True) indices_y.append(index_y) y_sample = y[index_y] X_train, X_test, y_train, y_test = train_test_split( X_sample, y_sample, test_size=0.2, random_state=42 ) model = DecisionTreeClassifier().fit(X_train, y_train) models.append(model) y_pred = model.predict(X_test) precision.append( metrics.precision_score(y_test, y_pred, average="macro") ) recall.append(metrics.recall_score(y_test, y_pred, average="macro")) f1.append(metrics.f1_score(y_test, y_pred, average="macro")) # Save the results to a Pandas dataframe pred_df = pd.DataFrame( { "Precision": precision, "Recall": recall, "F1": f1, "Models": models, "Indices_X": indices_x, "Indices_Y": indices_y, } )
Roep nu de functie aan.
models, pred_df = bootstrap(X, y)
Toon de resultaten van het dataframe dat de functie maakt.
pred_df.head()

Voeg nu de indexkolom toe als het modelnummer,
pred_df['Model Number'] = pred_df.index,
en sorteer de waarden op precisie.
pred_df.sort_values(by= "Precision", ascending = False).head(5)
Om de resultaten beter te zien, zullen we wat datavisualisatie maken.

Bootstrapping-visualisatie
De onderstaande code maakt drie staafdiagrammen om de prestaties van bootstrapped modellen weer te geven.
De prestaties van de modellen worden gemeten aan de hand van de precisie, recall en F1-scores. We zullen dus een dataframe maken met de naam pred_df. Dit dataframe slaat de scores van de modellen op.
De code creëert een figuur met 3 subplots.
De eerste subplot (ax2) is een staafdiagram dat de precisiescores van de top 5 modellen weergeeft.
De x-as toont de precisiescore en de y-as toont de index van het model. Voor elke balk wordt de waarde weergegeven in het midden van deze 3 cijfers. De titel van deze grafiek is "Precisie".
De tweede subplot (ax3) is een staafdiagram dat de recall-scores van de top 5 modellen laat zien. De x-as toont de recall-score en de y-as toont de index van het model. De titel van deze grafiek is “Herinneren”.
De derde subplot (ax4) is een staafdiagram dat de F1-scores van de top 5 modellen laat zien. De x-as toont de F1-score en de y-as toont de index van het model. De titel van deze grafiek is "F1".
De algemene titel van de figuur is "Bootstrapped Model Performance Metrics". We zullen deze afbeeldingen weergeven met behulp van plt.show().
Hier is de code.
import matplotlib.pyplot as plt # Create a figure and subplots
fig, (ax2, ax3, ax4) = plt.subplots(1, 3, figsize=(14, 8)) best_of = pred_df.sort_values(by="Precision", ascending=False).head(5) # Create the first graph
best_of.plot( kind="barh", x="Model Number", y="Precision", color="mediumturquoise", ax=ax2, legend=False,
)
ax2.set_xlabel( "Precision Score", fontstyle="italic", fontsize=14, font="Courier New", fontweight="bold", y=1.1,
)
ylabel = "ModelnName"
ax2.set_ylabel(ylabel, fontsize=16, font="Courier")
ax2.set_title("Precision", fontsize=16, fontstyle="italic") for index, value in enumerate(best_of["Precision"]): ax2.text( value / 2, index, str(round(value, 2)), ha="center", va="center", fontsize=14, font="Comic Sans MS", )
best_of = pred_df.sort_values(by="Recall", ascending=False).head(5) # Create the second graph
best_of.plot( kind="barh", x="Model Number", y="Recall", color="orange", ax=ax3, legend=False,
)
ax3.set_xlabel( "Recall Score", fontstyle="italic", fontsize=14, font="Courier New", fontweight="bold",
)
ax3.set_ylabel(ylabel, fontsize=16, font="Courier")
ax3.set_title("Recall", fontsize=16, fontstyle="italic") for index, value in enumerate(best_of["Recall"]): ax3.text( value / 2, index, str(round(value, 2)), ha="center", va="center", fontsize=14, font="Comic Sans MS", )
# Create the third graph
best_of = pred_df.sort_values(by="F1", ascending=False).head(5)
best_of.plot( kind="barh", x="Model Number", y="F1", color="darkorange", ax=ax4, legend=False,
)
ax4.set_xlabel( "F1 Score", fontstyle="italic", fontsize=14, font="Courier New", fontweight="bold",
)
ax4.set_ylabel(ylabel, fontsize=16, font="Courier")
ax4.set_title("F1", fontsize=16, fontstyle="italic") for index, value in enumerate(best_of["F1"]): ax4.text( value / 2, index, str(round(value, 2)), ha="center", va="center", fontsize=14, font="Comic Sans MS", )
# Fit the figure
plt.tight_layout() plt.suptitle( "Bootstrapped Model Performance Metrics", fontsize=18, y=1.05, fontweight="bold", fontname="Comic Sans MS",
) # Show the figure
plt.show()
Hier is de uitvoer.
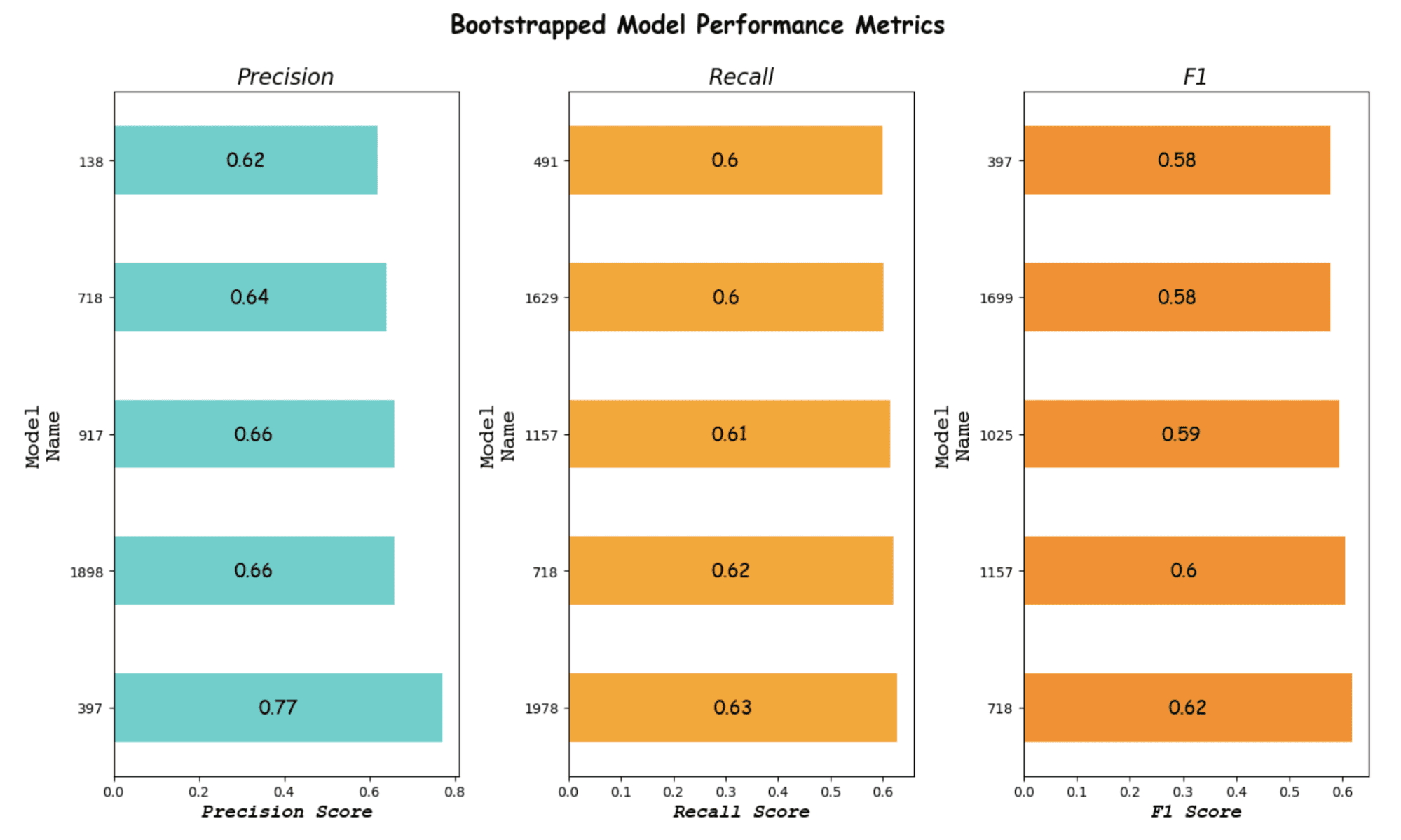
Afbeelding door auteur
Het lijkt erop dat model 397 ons beste model is volgens de precisie en de F1-score.
Als de terugroepactie belangrijker is voor uw project, kunt u natuurlijk Model 718 of een ander model kiezen.
De beste resultaten reproduceren
Nu hebben we de indexen al opgeslagen om reproduceerbare resultaten te creëren. We zullen het 397e model selecteren en de resultaten bekijken of de resultaten reproduceerbaar zijn of niet.
De volgende code begint met het selecteren van een voorbeeld van de gegevens (X en y) met behulp van de indices die zijn opgeslagen in de 397e rij van het pred_df-gegevensframe.
De voorbeeldgegevens worden vervolgens opgesplitst in trainings- en testgegevenssets met behulp van de train_test_split methode met een testgrootte van 0.2 en een willekeurige toestand van 42.
Vervolgens wordt een classificatiemodel voor een beslissingsboom getraind met behulp van de trainingsgegevens en opgeslagen in de lijst van het model. Het getrainde model wordt vervolgens gebruikt om voorspellingen te doen over de testgegevens met behulp van de voorspellen() methode.
Ten slotte worden de precisie-, recall- en F1-scores van het model berekend met behulp van de precisie_score, terugroepen_score en f1_score functies van de metrische module en afgedrukt naar de console.
Deze scores evalueren de prestaties van het model door het vermogen van het model te meten om de gegevens correct te classificeren en het niveau van fout-positieven en fout-negatieven die door het model worden gegenereerd.
Hier is de code.
X_sample = X[pred_df.iloc[397]["Indices_X"], :]
y_sample = y[pred_df.iloc[397]["Indices_Y"]] X_train, X_test, y_train, y_test = train_test_split( X_sample, y_sample, test_size=0.2, random_state=42
) model = DecisionTreeClassifier().fit(X_train, y_train)
models.append(model) y_pred = model.predict(X_test)
precision_397 = metrics.precision_score(y_test, y_pred, average="macro")
recall_397 = metrics.recall_score(y_test, y_pred, average="macro")
f1_397 = metrics.f1_score(y_test, y_pred, average="macro")
print("Precision : {}".format(precision_397))
print("Recall : {}".format(recall_397))
print("F1 : {}".format(f1_397))
Hier is de uitvoer.

Kortom, bootstrapping is een krachtige tool in machine learning die kan worden gebruikt om de prestaties van algoritmen te verbeteren. Door meerdere subsets van de gegevens te creëren, helpt bootstrapping het risico van overfitting te verminderen en de nauwkeurigheid van de resultaten te verbeteren.
We hebben gedemonstreerd hoe bootstrapping voor het classificatie-algoritme kan worden gebruikt met een beslissingsboomclassificatie.
Door bootstrapping en beslissingsboomclassificatie te combineren, kunnen we een krachtig machine learning-model creëren dat nauwkeurige en betrouwbare resultaten oplevert, die kunnen worden toegepast op andere classificatie-algoritmen.
Het begrijpen van alle genoemde concepten is essentieel voor datawetenschappers en professionals op het gebied van machine learning. Verplicht zou ik zeggen! Ze stellen u in staat weloverwogen beslissingen te nemen over de tools en technieken die ze gebruiken om echte problemen op te lossen.
Nate Rosidi is een datawetenschapper en in productstrategie. Hij is ook een adjunct-professor onderwijsanalyse en is de oprichter van StrataScratch, een platform dat datawetenschappers helpt bij het voorbereiden van hun interviews met echte interviewvragen van topbedrijven. Maak contact met hem op Twitter: StrataScratch or LinkedIn.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/03/bootstrapping.html?utm_source=rss&utm_medium=rss&utm_campaign=machine-learning-what-is-bootstrapping

