Machine learning (ML) heeft de afgelopen jaren de bedrijfsvoering in alle sectoren verbeterd - van het aanbevelingssysteem op uw Prime Video account, om samenvattingen en efficiënt zoeken te documenteren met Alexa's stem assistentie. De vraag blijft echter hoe u deze technologie kunt integreren in uw bedrijf. In tegenstelling tot traditionele, op regels gebaseerde methoden, leidt ML automatisch patronen uit gegevens af om uw taak van belang uit te voeren. Hoewel dit de noodzaak om regels voor automatisering te beheren omzeilt, betekent dit ook dat ML-modellen alleen zo goed kunnen zijn als de gegevens waarop ze zijn getraind. Het creëren van gegevens is echter vaak een uitdagende taak. Bij de Amazon Machine Learning Solutions-lab, zijn we dit probleem herhaaldelijk tegengekomen en willen we deze reis voor onze klanten vergemakkelijken. Als u dit proces wilt ontlasten, kunt u gebruik maken van Amazon SageMaker Ground Truth Plus.
Aan het einde van dit bericht kun je het volgende bereiken:
- Begrijp de bedrijfsprocessen die betrokken zijn bij het opzetten van een data-acquisitiepijplijn
- Identificeer AWS Cloud-services voor het ondersteunen en versnellen van uw pijplijn voor gegevenslabeling
- Voer een data-acquisitie- en labeltaak uit voor aangepaste gebruiksscenario's
- Creëer hoogwaardige gegevens volgens zakelijke en technische best practices
In deze post richten we ons op het proces voor het maken van gegevens en vertrouwen we op AWS-services om de infrastructuur en procescomponenten af te handelen. We gebruiken namelijk Amazon SageMaker Grondwaarheid om de etiketteringsinfrastructuurpijplijn en gebruikersinterface af te handelen. Deze service gebruikt een point-and-go-benadering om uw gegevens te verzamelen van Amazon eenvoudige opslagservice (Amazon S3) en stel een etiketteringsworkflow in. Voor labelen biedt het u de ingebouwde flexibiliteit om gegevenslabels te verkrijgen met uw privéteam, en Amazon Mechanical Turk force, of uw favoriete labelleverancier van: AWS Marketplace. Ten slotte kunt u gebruik maken van AWS Lambda en Amazon SageMaker-notebooks om de gegevens te verwerken, te visualiseren of op kwaliteit te controleren, zowel vóór als na het labelen.
Nu alle stukjes zijn neergelegd, laten we beginnen met het proces!
Het proces voor het maken van gegevens
In tegenstelling tot wat vaak wordt gedacht, is de eerste stap voor het maken van gegevens niet het verzamelen van gegevens. Het is van cruciaal belang om vanaf de gebruikers achteruit te werken om het probleem te verwoorden. Wat vinden gebruikers bijvoorbeeld belangrijk in het uiteindelijke artefact? Waar denken experts dat de signalen die relevant zijn voor de use case zich in de data bevinden? Welke informatie over de use case-omgeving zou kunnen worden verstrekt om te modelleren? Als u het antwoord op deze vragen niet weet, hoeft u zich geen zorgen te maken. Geef uzelf wat tijd om met gebruikers en veldexperts te praten om de nuances te begrijpen. Dit eerste begrip zal u in de juiste richting oriënteren en u voorbereiden op succes.
Voor dit bericht gaan we ervan uit dat je dit eerste proces van specificatie van gebruikersvereisten hebt behandeld. De volgende drie secties leiden u door het daaropvolgende proces van het maken van kwaliteitsgegevens: planning, het maken van brongegevens en gegevensannotatie. Het testen van loops bij de stappen voor het maken van gegevens en het maken van aantekeningen zijn van vitaal belang om te zorgen voor een efficiënte aanmaak van gelabelde gegevens. Dit omvat iteratie tussen gegevenscreatie, annotatie, kwaliteitsborging en het bijwerken van de pijplijn indien nodig.
De volgende afbeelding geeft een overzicht van de stappen die nodig zijn in een typische pijplijn voor het maken van gegevens. U kunt vanuit de use case achteruit werken om de gegevens te identificeren die u nodig hebt (specificatie van vereisten), een proces bouwen om de gegevens te verkrijgen (planning), het daadwerkelijke gegevensverzamelingsproces implementeren (gegevensverzameling en annotatie) en de resultaten beoordelen. Met pilot-runs, gemarkeerd met stippellijnen, kunt u het proces herhalen totdat een hoogwaardige data-acquisitiepijplijn is ontwikkeld.
Overzicht van de stappen die vereist zijn in een typische pijplijn voor het maken van gegevens.
Planning
Een standaard proces voor het creëren van gegevens kan tijdrovend zijn en een verspilling van waardevolle menselijke hulpbronnen als het inefficiënt wordt uitgevoerd. Waarom zou het tijdrovend zijn? Om deze vraag te beantwoorden, moeten we de reikwijdte van het gegevenscreatieproces begrijpen. Om u te helpen, hebben we een checklist op hoog niveau verzameld en een beschrijving van de belangrijkste componenten en belanghebbenden waarmee u rekening moet houden. Het beantwoorden van deze vragen kan in het begin moeilijk zijn. Afhankelijk van uw gebruikssituatie kunnen slechts enkele hiervan van toepassing zijn.
- Identificeer het juridische aanspreekpunt voor vereiste goedkeuringen – Voor het gebruik van gegevens voor uw toepassing kan een beoordeling van licenties of leverancierscontracten nodig zijn om naleving van het bedrijfsbeleid en gebruiksscenario's te garanderen. Het is belangrijk om uw juridische ondersteuning te identificeren tijdens de stappen voor gegevensverzameling en annotatie van het proces.
- Identificeer het beveiligingscontactpunt voor gegevensverwerking –Lekkage van aangekochte gegevens kan leiden tot ernstige boetes en gevolgen voor uw bedrijf. Het is belangrijk om uw beveiligingsondersteuning te identificeren tijdens de stappen voor gegevensverzameling en annotatie om veilige praktijken te garanderen.
- Vereisten voor gebruiksscenario's en richtlijnen voor brongegevens en annotaties definiëren – Het maken en annoteren van gegevens is moeilijk vanwege de hoge vereiste specificiteit. Belanghebbenden, inclusief gegevensgeneratoren en annotators, moeten volledig op elkaar zijn afgestemd om verspilling van middelen te voorkomen. Hiertoe is het gebruikelijk om een document met richtlijnen te gebruiken dat elk aspect van de annotatietaak specificeert: exacte instructies, randgevallen, een voorbeeld-walkthrough, enzovoort.
- Stem af op de verwachtingen voor het verzamelen van uw brongegevens - Stel je de volgende situatie voor:
- Onderzoek doen naar potentiële gegevensbronnen – Bijvoorbeeld openbare datasets, bestaande datasets van andere interne teams, zelf verzamelde of gekochte data van leveranciers.
- Kwaliteitsbeoordeling uitvoeren – Creëer een analysepijplijn met betrekking tot de uiteindelijke use case.
- Stem af op de verwachtingen voor het maken van gegevensannotaties - Stel je de volgende situatie voor:
- Identificeer de technische belanghebbenden – Dit is meestal een persoon of team in uw bedrijf dat in staat is de technische documentatie met betrekking tot Ground Truth te gebruiken om een annotatiepijplijn te implementeren. Deze belanghebbenden zijn ook verantwoordelijk voor de kwaliteitsbeoordeling van de geannoteerde gegevens om ervoor te zorgen dat deze voldoen aan de behoeften van uw downstream ML-toepassing.
- Identificeer de gegevensannotators – Deze personen gebruiken vooraf bepaalde instructies om labels toe te voegen aan uw brongegevens binnen Ground Truth. Ze moeten mogelijk over domeinkennis beschikken, afhankelijk van uw gebruiksscenario en annotatierichtlijnen. U kunt een intern personeelsbestand in uw bedrijf gebruiken, of betalen voor een personeel beheerd door een externe leverancier.
- Zorg voor toezicht op het proces voor het maken van gegevens – Zoals u uit de voorgaande punten kunt zien, is het creëren van gegevens een gedetailleerd proces waarbij tal van gespecialiseerde belanghebbenden betrokken zijn. Daarom is het van cruciaal belang om het van begin tot eind te monitoren naar het gewenste resultaat. Als een toegewijde persoon of team toezicht houdt op het proces, kunt u zorgen voor een samenhangend, efficiënt proces voor het creëren van gegevens.
Afhankelijk van de route die u besluit te nemen, moet u ook rekening houden met het volgende:
- De brongegevensset maken – Dit verwijst naar gevallen waarin bestaande gegevens niet geschikt zijn voor de uit te voeren taak, of wanneer wettelijke beperkingen u ervan weerhouden deze te gebruiken. Er moet gebruik worden gemaakt van interne teams of externe leveranciers (volgende punt). Dit is vaak het geval voor zeer gespecialiseerde domeinen of gebieden met weinig publiek onderzoek. Bijvoorbeeld de veelvoorkomende vragen van een arts, kledingstukken of sportexperts. Het kan intern of extern zijn.
- Onderzoek leveranciers en voer een onboardingproces uit – Wanneer er gebruik wordt gemaakt van externe leveranciers, moet tussen beide entiteiten een proces voor contractering en onboarding worden ingesteld.
In deze sectie hebben we de componenten en belanghebbenden besproken waarmee we rekening moeten houden. Maar hoe ziet het daadwerkelijke proces eruit? In de volgende afbeelding schetsen we een procesworkflow voor het maken en annoteren van gegevens. De iteratieve aanpak maakt gebruik van kleine hoeveelheden gegevens, pilots genaamd, om de doorlooptijd te verkorten, fouten vroegtijdig te detecteren en verspilling van middelen te voorkomen bij het creëren van gegevens van lage kwaliteit. We beschrijven deze pilotrondes verderop in dit bericht. We behandelen ook enkele best practices voor het maken, annoteren en kwaliteitscontrole van gegevens.
De volgende afbeelding illustreert de iteratieve ontwikkeling van een pijplijn voor het maken van gegevens. Verticaal vinden we het datasourcingblok (groen) en het annotatieblok (blauw). Beide blokken hebben onafhankelijke proefrondes (Gegevenscreatie/Annotatie, QAQC en Update). Er worden steeds hogere brongegevens gemaakt en deze kunnen worden gebruikt om annotaties van steeds hogere kwaliteit te maken.
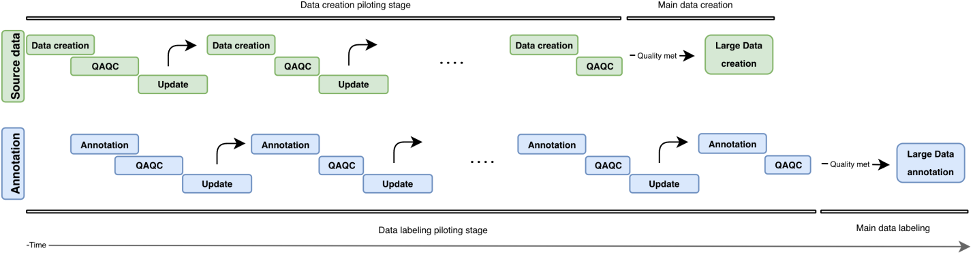
Overzicht van iteratieve ontwikkeling in een pijplijn voor het maken van gegevens.
Brongegevens maken
Het proces voor het maken van invoer draait om het ensceneren van uw interessante items, die afhankelijk zijn van uw taaktype. Dit kunnen afbeeldingen zijn (krantenscans), video's (verkeersscènes), 3D-puntenwolken (medische scans) of gewoon tekst (ondertitelingstracks, transcripties). Zorg in het algemeen voor het volgende wanneer u uw taakgerelateerde items ensceneert:
- Weerspiegel de praktijk van het gebruik van het uiteindelijke AI/ML-systeem – De instellingen voor het verzamelen van afbeeldingen of video's voor uw trainingsgegevens moeten nauw aansluiten bij de instellingen voor uw invoergegevens in de praktijktoepassing. Dit betekent consistente plaatsingsoppervlakken, lichtbronnen of camerahoeken.
- Houd rekening met variabiliteitsbronnen en minimaliseer deze - Stel je de volgende situatie voor:
- Best practices ontwikkelen voor het onderhouden van normen voor gegevensverzameling – Afhankelijk van de granulariteit van uw gebruiksscenario, moet u mogelijk vereisten specificeren om consistentie tussen uw datapunten te garanderen. Als u bijvoorbeeld beeld- of videogegevens verzamelt van afzonderlijke camerapunten, moet u wellicht zorgen voor een consistente plaatsing van uw interessante objecten, of een kwaliteitscontrole van de camera vereisen voordat een gegevensverzamelingsronde plaatsvindt. Dit kan problemen zoals het kantelen of wazig maken van de camera voorkomen en downstream overhead minimaliseren, zoals het verwijderen van buiten het frame of wazige afbeeldingen, en het handmatig centreren van het afbeeldingsframe op uw interessegebied.
- Pre-empt testtijd bronnen van variabiliteit – Als u tijdens de testperiode variabiliteit verwacht in een van de tot dusver genoemde kenmerken, zorg er dan voor dat u die variabiliteitsbronnen kunt vastleggen tijdens het maken van trainingsgegevens. Als u bijvoorbeeld verwacht dat uw ML-toepassing in meerdere verschillende lichtinstellingen werkt, moet u ernaar streven om trainingsafbeeldingen en -video's te maken bij verschillende lichtinstellingen. Afhankelijk van de gebruikssituatie kan variabiliteit in camerapositionering ook de kwaliteit van uw labels beïnvloeden.
- Voeg eerdere domeinkennis toe indien beschikbaar - Stel je de volgende situatie voor:
- Invoer over foutbronnen – Domeinbeoefenaars kunnen op basis van hun jarenlange ervaring inzicht verschaffen in foutenbronnen. Ze kunnen feedback geven over de best practices voor de vorige twee punten: Welke instellingen weerspiegelen het beste de praktijksituatie? Wat zijn de mogelijke bronnen van variabiliteit tijdens het verzamelen van gegevens of op het moment van gebruik?
- Best practices voor domeinspecifieke gegevensverzameling – Hoewel uw technische belanghebbenden misschien al een goed idee hebben van de technische aspecten waarop de verzamelde afbeeldingen of video's zich moeten concentreren, kunnen domeinbeoefenaars feedback geven over hoe de gegevens het beste kunnen worden geënsceneerd of verzameld, zodat aan deze behoeften wordt voldaan.
Kwaliteitscontrole en kwaliteitsborging van de gecreëerde gegevens
Nu u de pijplijn voor gegevensverzameling hebt opgezet, is het misschien verleidelijk om door te gaan en zoveel mogelijk gegevens te verzamelen. Wacht even! We moeten eerst controleren of de gegevens die via de installatie zijn verzameld, geschikt zijn voor uw echte gebruiksscenario. We kunnen enkele eerste voorbeelden gebruiken en de opstelling iteratief verbeteren door de inzichten die we hebben verkregen door die voorbeeldgegevens te analyseren. Werk tijdens het proefproces nauw samen met uw technische, zakelijke en annotatiebelanghebbenden. Dit zorgt ervoor dat uw resulterende pijplijn voldoet aan de zakelijke behoeften en genereert ML-ready gelabelde gegevens met minimale overheadkosten.
Annotaties
De annotatie van invoer is waar we de magische toets aan onze gegevens toevoegen: de labels! Afhankelijk van uw taaktype en het proces voor het maken van gegevens, hebt u mogelijk handmatige annotators nodig of kunt u kant-en-klare geautomatiseerde methoden gebruiken. De pijplijn voor gegevensannotaties zelf kan een technisch uitdagende taak zijn. Ground Truth vergemakkelijkt deze reis voor uw technische belanghebbenden met zijn ingebouwd repertoire van labelworkflows voor veelvoorkomende gegevensbronnen. Met een paar extra stappen kunt u ook bouwen aangepaste workflows voor labels verder dan vooraf geconfigureerde opties.
Stel uzelf de volgende vragen bij het ontwikkelen van een geschikte annotatieworkflow:
- Heb ik een handmatig annotatieproces nodig voor mijn gegevens? In sommige gevallen kunnen geautomatiseerde etiketteringsservices voldoende zijn voor de uit te voeren taak. Door de documentatie en beschikbare tools te bekijken, kunt u bepalen of handmatige annotatie nodig is voor uw gebruik (voor meer informatie, zie Wat is datalabeling?). Het proces voor het maken van gegevens kan zorgen voor verschillende niveaus van controle met betrekking tot de granulariteit van uw gegevensannotatie. Afhankelijk van dit proces kunt u soms ook de noodzaak van handmatige annotatie omzeilen. Voor meer informatie, zie: Bouw een aangepaste Q&A-dataset met Amazon SageMaker Ground Truth om een Hugging Face Q&A NLU-model te trainen.
- Wat vormt mijn grondwaarheid? In de meeste gevallen zal de grondwaarheid uit uw annotatieproces komen - dat is het hele punt! In andere kan de gebruiker toegang hebben tot grondwaarheidslabels. Dit kan uw kwaliteitsborgingsproces aanzienlijk versnellen of de overhead verminderen die nodig is voor meerdere handmatige annotaties.
- Wat is de bovengrens voor de mate van afwijking van mijn grondwaarheidstoestand? Werk samen met uw eindgebruikers om de typische fouten rond deze labels, de bronnen van dergelijke fouten en de gewenste vermindering van fouten te begrijpen. Dit zal u helpen te identificeren welke aspecten van de labeltaak het meest uitdagend zijn of waarschijnlijk annotatiefouten bevatten.
- Zijn er reeds bestaande regels die door de gebruikers of veldwerkers worden gebruikt om deze items te labelen? Gebruik en verfijn deze richtlijnen om een set instructies op te stellen voor uw handmatige annotators.
Piloten van het invoerannotatieproces
Houd bij het testen van het invoerannotatieproces rekening met het volgende:
- Bekijk de instructies met de annotators en veldwerkers – Instructies moeten beknopt en specifiek zijn. Vraag om feedback van uw gebruikers (zijn de instructies nauwkeurig? Kunnen we eventuele instructies herzien om ervoor te zorgen dat ze begrijpelijk zijn voor niet-veldwerkers?) en annotators (Is alles begrijpelijk? Is de taak duidelijk?). Voeg indien mogelijk een voorbeeld toe van goede en slechte gelabelde gegevens om uw annotators te helpen bepalen wat er wordt verwacht en hoe veelvoorkomende labelfouten eruit kunnen zien.
- Gegevens verzamelen voor annotaties – Beoordeel de gegevens met uw klant om er zeker van te zijn dat deze voldoen aan de verwachte normen en om af te stemmen op de verwachte resultaten van de handmatige annotatie.
- Geef voorbeelden aan uw pool van handmatige annotators als testrun – Wat is de typische variantie tussen de annotators in deze reeks voorbeelden? Bestudeer de variantie voor elke annotatie binnen een bepaalde afbeelding om de consistentietrends tussen annotators te identificeren. Vergelijk vervolgens de verschillen tussen de afbeeldingen of videoframes om te bepalen welke labels moeilijk te plaatsen zijn.
Kwaliteitscontrole van de annotaties
De kwaliteitscontrole van annotaties bestaat uit twee hoofdcomponenten: het beoordelen van de consistentie tussen de annotators en het beoordelen van de kwaliteit van de annotaties zelf.
U kunt meerdere annotators aan dezelfde taak toewijzen (bijvoorbeeld drie annotators labelen de belangrijkste punten op dezelfde afbeelding) en de gemiddelde waarde meten naast de standaarddeviatie van deze labels onder de annotators. Als u dit doet, kunt u eventuele uitschieterannotaties identificeren (onjuist label gebruikt of label ver verwijderd van de gemiddelde annotatie), die als leidraad kunnen dienen voor bruikbare resultaten, zoals het verfijnen van uw instructies of het geven van verdere training aan bepaalde annotators.
Het beoordelen van de kwaliteit van annotaties zelf is gekoppeld aan annotatorvariabiliteit en (indien beschikbaar) de beschikbaarheid van domeinexperts of grondwaarheidsinformatie. Zijn er bepaalde labels (voor al je afbeeldingen) waar de gemiddelde variantie tussen annotators constant hoog is? Zijn er labels die ver verwijderd zijn van uw verwachtingen van waar ze zouden moeten zijn, of hoe ze eruit zouden moeten zien?
Op basis van onze ervaring kan een typische kwaliteitscontrolelus voor gegevensannotatie er als volgt uitzien:
- Herhaal de instructies of beeldfasering op basis van de resultaten van de testrun – Zijn er objecten geoccludeerd of komt de beeldstaging niet overeen met de verwachtingen van annotators of gebruikers? Zijn de instructies misleidend, of heb je labels of veelvoorkomende fouten in je voorbeeldafbeeldingen gemist? Kun je de instructies voor je annotators verfijnen?
- Als u tevreden bent dat u eventuele problemen van de testrun hebt opgelost, maakt u een reeks aantekeningen – Volg voor het testen van de resultaten van de batch dezelfde benadering voor kwaliteitsbeoordeling voor het beoordelen van variabiliteiten tussen annotatoren en labels tussen afbeeldingen.
Conclusie
Dit bericht dient als een gids voor zakelijke belanghebbenden om de complexiteit van gegevenscreatie voor AI/ML-toepassingen te begrijpen. De beschreven processen dienen ook als richtlijn voor technische professionals om kwaliteitsgegevens te genereren en tegelijkertijd bedrijfsbeperkingen zoals personeel en kosten te optimaliseren. Als het niet goed wordt gedaan, kan een pijplijn voor het maken en labelen van gegevens meer dan 4-6 maanden in beslag nemen.
Met de richtlijnen en suggesties die in dit bericht worden beschreven, kunt u wegblokkades voorkomen, de tijd tot voltooiing verkorten en de kosten minimaliseren tijdens uw reis naar het maken van hoogwaardige gegevens.
Over de auteurs
 Jasleen Grewal is een Applied Scientist bij Amazon Web Services, waar ze samenwerkt met AWS-klanten om problemen in de echte wereld op te lossen met behulp van machine learning, met speciale aandacht voor precisiegeneeskunde en genomica. Ze heeft een sterke achtergrond in bio-informatica, oncologie en klinische genomica. Ze is gepassioneerd door het gebruik van AI/ML en clouddiensten om de patiëntenzorg te verbeteren.
Jasleen Grewal is een Applied Scientist bij Amazon Web Services, waar ze samenwerkt met AWS-klanten om problemen in de echte wereld op te lossen met behulp van machine learning, met speciale aandacht voor precisiegeneeskunde en genomica. Ze heeft een sterke achtergrond in bio-informatica, oncologie en klinische genomica. Ze is gepassioneerd door het gebruik van AI/ML en clouddiensten om de patiëntenzorg te verbeteren.
 Boris Aronchik is een manager in het Amazon AI Machine Learning Solutions Lab, waar hij een team van ML-wetenschappers en -ingenieurs leidt om AWS-klanten te helpen bij het realiseren van zakelijke doelen door gebruik te maken van AI/ML-oplossingen.
Boris Aronchik is een manager in het Amazon AI Machine Learning Solutions Lab, waar hij een team van ML-wetenschappers en -ingenieurs leidt om AWS-klanten te helpen bij het realiseren van zakelijke doelen door gebruik te maken van AI/ML-oplossingen.
 Miguel Romero Calvo is een Applied Scientist bij de Amazon ML Solutions-lab waar hij samenwerkt met interne teams van AWS en strategische klanten om hun bedrijf te versnellen door middel van ML en cloudadoptie.
Miguel Romero Calvo is een Applied Scientist bij de Amazon ML Solutions-lab waar hij samenwerkt met interne teams van AWS en strategische klanten om hun bedrijf te versnellen door middel van ML en cloudadoptie.
 Lin Lee Cheong is Senior Scientist en Manager bij het Amazon ML Solutions Lab-team bij Amazon Web Services. Ze werkt samen met strategische AWS-klanten om kunstmatige intelligentie en machine learning te verkennen en toe te passen om nieuwe inzichten te ontdekken en complexe problemen op te lossen.
Lin Lee Cheong is Senior Scientist en Manager bij het Amazon ML Solutions Lab-team bij Amazon Web Services. Ze werkt samen met strategische AWS-klanten om kunstmatige intelligentie en machine learning te verkennen en toe te passen om nieuwe inzichten te ontdekken en complexe problemen op te lossen.

