Welkom bij dit artikel over het probleem van het voorspellen van leningen. Hieronder vindt u een korte introductie over dit onderwerp, zodat u vertrouwd raakt met wat u gaat leren.
Dit artikel is bedoeld voor mensen die binaire classificatieproblemen willen oplossen met behulp van Python. Aan het einde van dit artikel beschikt u over de nodige vaardigheden en technieken die nodig zijn om dergelijke problemen op te lossen. Dit artikel biedt u voldoende theorie- en praktijkkennis om uw vaardigheden aan te scherpen.
1. Inleiding tot het probleem
2. Verkennende gegevensanalyse (EDA) en voorverwerking
3. Modelbouw en feature-engineering
Deze secties worden aangevuld met theorie- en codeervoorbeelden. Bovendien krijgt u de gegevenssetbronnen:
Voor dit probleem hebben we drie CSV-bestanden gekregen: trein-, test- en voorbeeldinzending.
De bestandsnaam moet worden vervangen door de naam van het trein- en testbestand dat u hebt gedownload van het datahackplatform.
Laten we een kopie maken van de trein- en testgegevens, zodat we, zelfs als we iets in deze datasets veranderen, de originele datasets niet kwijtraken.
In deze sectie bekijken we de trein- en testdatasets. Eerst zullen we de kenmerken in onze gegevens controleren, en daarna zullen we kijken naar hun gegevenstypen.
We hebben 12 onafhankelijke variabelen en 1 doelvariabele, namelijk Loan_Status in de trainingsdataset. Laten we eens kijken naar de kolommen van de testgegevensset.
We hebben vergelijkbare functies in de testgegevensset als de trainingsgegevensset, behalve de Loan_Status. We zullen de Loan_Status voorspellen met behulp van het model dat is gebouwd met behulp van de treingegevens. Hieronder vindt u de beschrijving voor elke variabele.
Laten we eens kijken naar de vorm van de dataset.
We hebben 614 rijen en 13 kolommen in de trainingsdataset en 367 rijen en 12 kolommen in de testdataset.
In dit deel zullen we een univariate analyse uitvoeren. Het is de gemakkelijkste vorm van gegevensanalyse waarbij we elke variabele afzonderlijk analyseren. Voor categorische kenmerken kunnen we frequentietabellen of staafdiagrammen gebruiken om het aantal van elke categorie in een bepaalde variabele te berekenen. Kansdichtheidsfuncties (PDF) kunnen worden gebruikt om de verdeling van de numerieke variabelen te bekijken.
We zullen eerst kijken naar de doelvariabele, dat wil zeggen Loan_Status. Omdat het een categorische variabele is, laten we eens kijken naar de frequentietabel, de procentuele verdeling en het staafdiagram.
De frequentietabel van een variabele geeft ons het aantal van elke categorie in die variabele.
422 (ongeveer 69%) van de 614 mensen kregen de goedkeuring.
Laten we nu elke variabele afzonderlijk visualiseren. Verschillende soorten variabelen zijn categorisch, ordinaal en numeriek.
Laten we eerst de categorische en ordinale kenmerken visualiseren.
Laten we nu de ordinale variabelen visualiseren.
Tot nu toe hebben we de categorische en ordinale variabelen gezien en laten we nu de numerieke variabelen visualiseren. Laten we eerst eens kijken naar de verdeling van het inkomen van de aanvrager.
Hieruit kan worden afgeleid dat de meeste gegevens bij de verdeling van het inkomen van de aanvrager naar links zijn gericht, wat betekent dat deze niet normaal worden verdeeld. We zullen proberen het in latere secties normaal te maken, aangezien algoritmen beter werken als de gegevens normaal worden verdeeld.
Laten we eens kijken naar de verdeling van de variabele LoanAmount.
We zien veel uitschieters in deze variabele en de verdeling is redelijk normaal. We zullen de uitschieters in latere secties behandelen.
Nu willen we graag weten hoe goed elke functie correleert met de leenstatus. Daarom zullen we in de volgende sectie kijken naar de bivariate analyse.
Laten we enkele van de hypothesen in herinnering brengen die we eerder hebben gegenereerd:
- Aanvragers met hoge inkomens moeten meer kansen hebben op goedkeuring van de lening.
- Aanvragers die hun eerdere schulden hebben afgelost, zouden een grotere kans moeten hebben op goedkeuring van de lening.
- De goedkeuring van een lening moet ook afhankelijk zijn van het geleende bedrag. Als het geleende bedrag lager is, moet de kans op goedkeuring van de lening groot zijn.
- Hoe lager het maandelijks te betalen bedrag om de lening terug te betalen, hoe groter de kans op goedkeuring van de lening.
Laten we proberen de bovengenoemde hypothesen te testen met behulp van bivariate analyse
Nadat we elke variabele afzonderlijk hebben bekeken in univariate analyse, zullen we ze nu opnieuw verkennen met betrekking tot de doelvariabele.
Categorische onafhankelijke variabele versus doelvariabele
Allereerst zullen we de relatie vinden tussen de doelvariabele en categorische onafhankelijke variabelen. Laten we nu eens kijken naar het gestapelde staafdiagram, dat ons het aandeel van goedgekeurde en niet-goedgekeurde leningen zal geven.
Geslacht=pd.crosstab(train['Gender'],train['Loan_Status']) Gender.div(Gender.sum(1).astype(float), axis=0).plot(kind="bar", figsize =(4,4))
Hieruit kan worden afgeleid dat het aandeel mannelijke en vrouwelijke aanvragers voor zowel goedgekeurde als niet-goedgekeurde leningen min of meer gelijk is.
Laten we nu de resterende categorische variabelen visualiseren versus de doelvariabelen.
Getrouwd=pd.crosstab(trein['Getrouwd'],trein['Lening_Status']) Nabestaanden=pd.crosstab(trein['Leenstatus'],trein['Lening_Status']) Onderwijs=pd.crosstab(trein['Onderwijs '],train['Loan_Status']) Self_Employed=pd.crosstab(train['Self_Employed'],train['Loan_Status']) Married.div(Married.sum(1).astype(float), axis=0) .plot(kind="bar", figsize=(4,4)) plt.show() Dependents.div(Dependents.sum(1).astype(float), axis=0).plot(kind="bar" , stacked=True) plt.show() Education.div(Education.sum(1).astype(float), axis=0).plot(kind="bar", figsize=(4,4)) plt.show () Zelfstandige.div(Zelfstandige.sum(1).astype(float),axis=0).plot(kind="bar",figsize=(4,4)) plt.show()

- Het aandeel gehuwde aanvragers is hoger voor de goedgekeurde leningen.
- De verdeling van aanvragers met 1 of 3+ personen ten laste is vergelijkbaar in beide categorieën van Lening_Status.
- Er is niets significant dat we kunnen afleiden uit de plot Self_Employed vs Loan_Status.
Nu zullen we kijken naar de relatie tussen de resterende categorische onafhankelijke variabelen en Loan_Status.
Credit_History=pd.crosstab(trein['Kredietgeschiedenis'],trein['Lening_Status']) Property_Area=pd.crosstab(trein['Property_Area'],trein['Lening_Status']) Credit_History.div(Kredietgeschiedenis.sum(1) .astype(float), axis=0).plot(kind="bar", stacked=True, figsize=(4,4)) plt.show() Property_Area.div(Property_Area.sum(1).astype(float ), axis=0).plot(kind="bar", stacked=True) plt.show()

- Het lijkt erop dat mensen met een kredietgeschiedenis van 1 een grotere kans hebben om hun leningen goedgekeurd te krijgen.
- Het percentage leningen dat wordt goedgekeurd in semi-stedelijke gebieden is hoger dan in landelijke of stedelijke gebieden.
Laten we nu numerieke onafhankelijke variabelen visualiseren met betrekking tot de doelvariabele.
Numerieke onafhankelijke variabele versus doelvariabele
We zullen proberen het gemiddelde inkomen te vinden van mensen waarvoor de lening is goedgekeurd versus het gemiddelde inkomen van mensen waarvoor de lening niet is goedgekeurd.
train.groupby('Leningstatus')['Inkomen aanvrager'].mean().plot.bar()

Hier vertegenwoordigt de y-as het gemiddelde inkomen van de aanvrager. We zien geen verandering in het gemiddelde inkomen. Laten we dus bakken maken voor de inkomensvariabele van de aanvrager op basis van de waarden erin en de bijbehorende uitleenstatus voor elke bak analyseren.
bins=[0,2500,4000,6000,81000] group=['Laag','Gemiddeld','Hoog', 'Zeer hoog'] train['Inkomen_bin']=pd.cut(trein['AanvragerInkomen'] ,bakken,labels=groep)
Income_bin=pd.crosstab(train['Income_bin'],train['Loan_Status']) Income_bin.div(Income_bin.sum(1).astype(float), axis=0).plot(kind="bar", gestapeld =Waar) plt.xlabel('Inkomen aanvrager') P = plt.ylabel('Percentage')

Hieruit kan worden afgeleid dat het inkomen van de aanvrager geen invloed heeft op de kansen op goedkeuring van de lening, wat in tegenspraak is met onze hypothese waarin we aannamen dat als het inkomen van de aanvrager hoog is, de kans op goedkeuring van de lening ook groot is.
We zullen de variabele inkomsten en het leningbedrag van de aanvrager op een vergelijkbare manier analyseren.
bins=[0,1000,3000,42000] group=['Laag','Gemiddeld','Hoog'] train['Coapplicant_Income_bin']=pd.cut(train['CoapplicantIncome'],bins,labels=groep)
Coapplicant_Income_bin=pd.crosstab(train['Coapplicant_Income_bin'],train['Loan_Status']) Coapplicant_Income_bin.div(Coapplicant_Income_bin.sum(1).astype(float), axis=0).plot(kind="bar", gestapeld =Waar) plt.xlabel('Inkomen medeaanvrager') P = plt.ylabel('Percentage')

Hieruit blijkt dat als het inkomen van medeaanvragers lager is, de kans op goedkeuring van de lening groot is. Maar dit ziet er niet goed uit. De mogelijke reden hierachter kan zijn dat de meeste aanvragers geen medeaanvrager hebben, dus het inkomen van de medeaanvrager voor dergelijke aanvragers is 0 en daarom is de goedkeuring van de lening er niet van afhankelijk. We kunnen dus een nieuwe variabele maken waarin we het inkomen van de aanvrager en medeaanvragers zullen combineren om het gecombineerde effect van inkomen op de goedkeuring van de lening te visualiseren.
Laten we het inkomen van de aanvrager en het inkomen van de mede-aanvrager combineren en het gecombineerde effect van het totale inkomen op de lening_status bekijken.
trein['Totaal_Inkomen']=trein['AanvragerInkomen']+trein['MedeaanvragerInkomen']
bins=[0,2500,4000,6000,81000] group=['Laag','Gemiddeld','Hoog', 'Zeer hoog'] train['Total_Income_bin']=pd.cut(train['Total_Income'] ,bakken,labels=groep)
Total_Income_bin=pd.crosstab(trein['Total_Income_bin'],train['Loan_Status']) Total_Income_bin.div(Total_Income_bin.sum(1).astype(float), axis=0).plot(kind="bar", gestapeld =Waar) plt.xlabel('Totaal_inkomen') P = plt.ylabel('Percentage')

We kunnen zien dat het percentage leningen dat wordt goedgekeurd voor aanvragers met een laag totaal inkomen veel kleiner is in vergelijking met dat van aanvragers met een gemiddeld, hoog en zeer hoog inkomen.
Laten we de variabele Leningsbedrag visualiseren.
bins=[0,100,200,700] group=['Laag','Gemiddeld','Hoog'] train['LoanAmount_bin']=pd.cut(trein['LoanAmount'],bins,labels=groep)
LoanAmount_bin=pd.crosstab(trein['LoanAmount_bin'],trein['Loan_Status']) LoanAmount_bin.div(LoanAmount_bin.sum(1).astype(float), axis=0).plot(kind="bar", gestapeld =Waar) plt.xlabel('LoanAmount') P = plt.ylabel('Percentage')

Het is duidelijk dat het aandeel goedgekeurde leningen hoger is voor lage en gemiddelde leningsbedragen in vergelijking met dat voor hoge leningsbedragen, wat onze hypothese ondersteunt waarin werd aangenomen dat de kans op goedkeuring van een lening groot zal zijn als het leningsbedrag lager is.
train=train.drop(['Inkomen_bin', 'Medeaanvrager_Inkomen_bin', 'LoanAmount_bin', 'Totaal_Inkomen_bin', 'Totaal_Inkomen'], as=1)
train['Dependents'].replace('3+', 3,inplace=True) test['Dependents'].replace('3+', 3,inplace=True) train['Leningstatus'].replace(' N', 0,inplace=True) train['Leningstatus'].replace('Y', 1,inplace=True)
Laten we nu eens kijken naar de correlatie tussen alle numerieke variabelen. We zullen de hittekaart gebruiken om de correlatie te visualiseren. Heatmaps visualiseren gegevens door middel van kleurvariaties. De variabelen met donkerdere kleuren betekenen dat hun correlatie groter is.
matrix = train.corr() f, ax = plt.subplots(figsize=(9, 6)) sns.heatmap(matrix, vmax=.8, vierkant=True, cmap="BuPu");

We zien dat de meest gecorreleerde variabelen (ApplicantIncome – LoanAmount) en (Credit_History – Loan_Status) zijn. LoanAmount is ook gecorreleerd met CoapplicantIncome.
Ontbrekende waarde en behandeling van uitschieters
Nadat we alle variabelen in onze gegevens hebben onderzocht, kunnen we nu de ontbrekende waarden toeschrijven en de uitbijters behandelen, omdat ontbrekende gegevens en uitbijters de prestaties van het model negatief kunnen beïnvloeden.
Ontbrekende waarde-toerekening
Laten we de functiegewijze telling van ontbrekende waarden opsommen.
trein.isnull().sum()

Er ontbreken waarden in de functies Gender, Married, Dependents, Self_Employed, LoanAmount, Loan_Amount_Term en Credit_History.
We behandelen de ontbrekende waarden in alle functies een voor een.
We kunnen deze methoden overwegen om de ontbrekende waarden in te vullen:
- Voor numerieke variabelen: imputatie met gemiddelde of mediaan
- Voor categorische variabelen: imputatie met behulp van modus
Er zijn heel weinig ontbrekende waarden in de functies Geslacht, Getrouwd, Afhankelijken, Kredietgeschiedenis en Zelfstandigen, dus we kunnen deze invullen met behulp van de modus van de functies.
train['Geslacht'].fillna(trein['Geslacht'].mode()[0], inplace=True) train['Getrouwd'].fillna(trein['Geslacht'].mode()[0], inplace=True) train['Dependents'].fillna(trein['Dependents'].mode()[0], inplace=True) train['Zelfstandigen'].fillna(trein['Zelfstandigen'].mode() [0], inplace=True) train['Credit_History'].fillna(train['Credit_History'].mode()[0], inplace=True)
Laten we nu proberen een manier te vinden om de ontbrekende waarden in Loan_Amount_Term in te vullen. We zullen kijken naar de waarde van de variabele leningbedrag.
train['Loan_Amount_Term'].value_counts()

Het is te zien dat in de variabele leenbedrag de waarde 360 het vaakst wordt herhaald. We zullen dus de ontbrekende waarden in deze variabele vervangen met behulp van de modus van deze variabele.
train['Loan_Amount_Term'].fillna(train['Loan_Amount_Term'].mode()[0], inplace=True)
Nu zullen we de LoanAmount-variabele zien. Omdat het een numerieke variabele is, kunnen we het gemiddelde of de mediaan gebruiken om de ontbrekende waarden toe te schrijven. We zullen de mediaan gebruiken om de nulwaarden in te vullen, omdat we eerder zagen dat het “leningbedrag” uitschieters heeft, dus het gemiddelde zal niet de juiste benadering zijn, omdat dit sterk wordt beïnvloed door de aanwezigheid van uitbijters.
train['LoanAmount'].fillna(train['LoanAmount'].median(), inplace=True)
Laten we nu eens kijken of alle ontbrekende waarden in de dataset zijn ingevuld.
trein.isnull().sum()

Zoals we kunnen zien zijn alle ontbrekende waarden ingevuld in de testdataset. Laten we ook alle ontbrekende waarden in de testdataset vullen met dezelfde aanpak.
test['Gender'].fillna(train['Gender'].mode()[0], inplace=True) test['Dependents'].fillna(train['Dependents'].mode()[0], inplace=True) test['Self_Employed'].fillna(trein['Self_Employed'].mode()[0], inplace=True) test['Credit_History'].fillna(trein['Credit_History'].mode() [0], inplace=True) test['Loan_Amount_Term'].fillna(train['Loan_Amount_Term'].mode()[0], inplace=True) test['LoanAmount'].fillna(train['LoanAmount'] .median(), inplace=True)
Uitbijterbehandeling
Zoals we eerder zagen in univariate analyse, bevat LoanAmount uitschieters, dus we moeten ze behandelen omdat de aanwezigheid van uitschieters de distributie van de gegevens beïnvloedt. Laten we eens kijken wat er kan gebeuren met een dataset met uitschieters. Voor de voorbeeldgegevensset:
1, 1, 2, 2, 2, 2, 3, 3, 3, 4, 4
We vinden het volgende: gemiddelde, mediaan, modus en standaarddeviatie
Gemiddelde = 2.58
Mediaan = 2.5
Modus = 2
Standaarddeviatie = 1.08
Als we een uitbijter aan de dataset toevoegen:
1, 1, 2, 2, 2, 2, 3, 3, 3, 4, 4, 400
De nieuwe waarden van onze statistieken zijn:
Gemiddelde = 35.38
Mediaan = 2.5
Modus = 2
Standaarddeviatie = 114.74
Het is duidelijk dat het hebben van uitbijters vaak een significant effect heeft op het gemiddelde en de standaarddeviatie en daarmee de verdeling beïnvloedt. We moeten stappen ondernemen om uitbijters uit onze datasets te verwijderen.
Vanwege deze uitschieters bevindt het grootste deel van de gegevens in het geleende bedrag zich aan de linkerkant en is de rechterstaart langer. Dit wordt rechtsscheefheid genoemd. Eén manier om de scheefheid te verwijderen is door de logtransformatie uit te voeren. Als we de logtransformatie nemen, heeft deze niet veel invloed op de kleinere waarden, maar worden de grotere waarden verminderd. We krijgen dus een verdeling die lijkt op de normale verdeling.
Laten we het effect van logtransformatie visualiseren. We zullen gelijktijdig soortgelijke wijzigingen in de testgegevens aanbrengen.
train['LoanAmount_log'] = np.log(trein['LoanAmount']) train['LoanAmount_log'].hist(bins=20) test['LoanAmount_log'] = np.log(test['LoanAmount'])

Nu lijkt de verdeling veel dichter bij normaal en is het effect van extreme waarden aanzienlijk afgezwakt. Laten we een logistisch regressiemodel bouwen en voorspellingen doen voor de testdataset.
Evaluatiestatistieken voor classificatie
Het proces van modelbouw is niet compleet zonder de evaluatie van de modelprestaties. Stel dat we de voorspellingen uit het model hebben, hoe kunnen we dan bepalen of de voorspellingen accuraat zijn? We kunnen de resultaten plotten en vergelijken met de werkelijke waarden, dwz de afstand berekenen tussen de voorspellingen en de werkelijke waarden. Hoe kleiner deze afstand, hoe nauwkeuriger de voorspellingen zullen zijn. Omdat dit een classificatieprobleem is, kunnen we onze modellen evalueren met behulp van een van de volgende evaluatiestatistieken:
- Nauwkeurigheid: - Laten we het begrijpen met behulp van de verwarringsmatrix, een tabelweergave van werkelijke versus voorspelde waarden. Zo ziet een verwarringsmatrix eruit:

- Echt positief – Doelstellingen die daadwerkelijk waar zijn (Y) en we hebben ze als waar voorspeld (Y)
- True Negative – Doelstellingen die feitelijk false(N) zijn en we hebben ze als false(N) voorspeld
- Vals-positief – Doelen die feitelijk onwaar zijn (N), maar we hebben ze voorspeld als waar (T)
- Vals-negatief – Doelen die feitelijk waar zijn (T), maar we hebben ze voorspeld als onwaar (N)
Met behulp van deze waarden kunnen we de nauwkeurigheid van het model berekenen. De nauwkeurigheid wordt gegeven door:
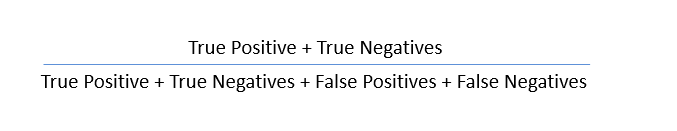
- Precisie:-: Het is een maatstaf voor de correctheid die wordt bereikt bij ware voorspellingen, dwz van waarnemingen die als waar zijn bestempeld, hoeveel ervan daadwerkelijk als waar zijn bestempeld
Precisie = TP / (TP + FP)
- Terugroepen (gevoeligheid): - Het is een maatstaf voor de feitelijke waarnemingen die correct worden voorspeld, dat wil zeggen hoeveel waarnemingen van de ware klasse correct zijn gelabeld. Het wordt ook wel 'Gevoeligheid' genoemd.
Oproepen = TP / (TP + FN)
- Specificiteit:- Het is een maatstaf voor hoeveel waarnemingen van valse klasse correct zijn geëtiketteerd.
Specificiteit = TN / (TN + FP)
Specificiteit en gevoeligheid spelen een cruciale rol bij het afleiden van de ROC-curve.
- ROC-curve
- Receiver Operating Characteristic (ROC) vat de prestaties van het model samen door de afwegingen tussen echt positief percentage (gevoeligheid) en fout-positief percentage (1-specificiteit) te evalueren.
- Het gebied onder de curve (AUC), ook wel een nauwkeurigheidsindex (A) of concordantie-index genoemd, is een perfecte prestatiemaatstaf voor de ROC-curve. Hoe hoger het gebied onder de curve, hoe beter de voorspellingskracht van het model.
Zo ziet een ROC-curve eruit:

- De oppervlakte van deze curve meet het vermogen van het model om echte positieven en echte negatieven correct te classificeren. We willen dat ons model de ware klassen als waar en de valse klassen als onwaar voorspelt.
- Er kan dus worden gezegd dat we willen dat het werkelijk positieve percentage 1 is. Maar het gaat ons niet alleen om het echt positieve percentage, maar ook om het fout-positieve percentage. In ons probleem zijn we bijvoorbeeld niet alleen bezorgd over het voorspellen van de Y-klassen als Y, maar we willen ook dat N-klassen worden voorspeld als N.
- We willen het oppervlak van de curve vergroten, dat maximaal zal zijn voor de klassen 2,3,4 en 5 in het bovenstaande voorbeeld.
- Voor klasse 1, wanneer het fout-positieve percentage 0.2 bedraagt, ligt het werkelijk-positieve percentage rond de 0.6. Maar voor klasse 2 is het werkelijk positieve percentage 1 met hetzelfde fout-positieve percentage. De AUC voor klasse 2 zal dus veel hoger zijn dan de AUC voor klasse 1. Het model voor klasse 2 zal dus beter zijn.
- De modellen van klasse 2,3,4 en 5 zullen nauwkeuriger voorspellen in vergelijking met de modellen van klasse 0 en 1, aangezien de AUC hoger is voor die klassen.
Op de wedstrijdpagina werd vermeld dat onze inzendingsgegevens zouden worden geëvalueerd op basis van nauwkeurigheid. Daarom zullen we nauwkeurigheid als onze evaluatiemetriek gebruiken.
Modelbouw: deel 1
Laten we ons eerste model de doelvariabele laten voorspellen. We beginnen met logistieke regressie, die wordt gebruikt voor het voorspellen van binaire uitkomsten.
- Logistische regressie is een classificatie-algoritme. Het wordt gebruikt om een binaire uitkomst te voorspellen (1/0, Ja / Nee, Waar / Niet waar) op basis van een reeks onafhankelijke variabelen.
- Logistische regressie is een schatting van de Logit-functie. De logit-functie is eenvoudigweg een logboek van de kansen ten gunste van de gebeurtenis.
- Deze functie creëert een S-vormige curve met de kansschatting, die sterk lijkt op de vereiste stapsgewijze functie
Laten we de variabele Loan_ID laten vallen, omdat deze geen effect heeft op de uitleenstatus. We zullen dezelfde wijzigingen aanbrengen in de testdataset als bij de trainingsdataset.
train=train.drop('Lening_ID',axis=1) test=test.drop('Lening_ID',axis=1)
We zullen "scikit-learn" (sklearn) gebruiken voor het maken van verschillende modellen, wat een open-sourcebibliotheek voor Python is. Het is een van de meest efficiënte tools die veel ingebouwde functies bevat die kunnen worden gebruikt voor het modelleren in Python.
Sklearn vereist de doelvariabele in een aparte dataset. We zullen dus onze doelvariabele uit de trainingsdataset verwijderen en opslaan in een andere dataset.
X = trein.drop('Lening_Status',1) y = trein.Lening_Status
Nu gaan we dummyvariabelen maken voor de categorische variabelen. Een dummyvariabele verandert categorische variabelen in een reeks van 0 en 1, waardoor ze een stuk gemakkelijker te kwantificeren en te vergelijken zijn. Laten we eerst het proces van dummies begrijpen:
- Beschouw de variabele "Geslacht". Het heeft twee klassen, mannelijk en vrouwelijk.
- Aangezien logistische regressie alleen de numerieke waarden als invoer neemt, moeten we mannelijk en vrouwelijk veranderen in een numerieke waarde.
- Zodra we dummy's op deze variabele toepassen, zal het de variabele “Geslacht” omzetten in twee variabelen (Geslacht_Man en Geslacht_Vrouw), één voor elke klasse, namelijk Mannelijk en Vrouwelijk.
- Gender_Male heeft een waarde van 0 als het geslacht vrouwelijk is en een waarde van 1 als het geslacht mannelijk is.
X=pd.get_dummies(X) trein=pd.get_dummies(trein) test=pd.get_dummies(test)
Nu gaan we het model trainen op de trainingsdataset en voorspellingen doen voor de testdataset. Maar kunnen we deze voorspellingen valideren? Eén manier om dit te doen is door onze treindataset in twee delen te verdelen: trein en validatie. We kunnen het model op dit trainingsgedeelte trainen en op basis daarvan voorspellingen doen voor het validatiegedeelte. Op deze manier kunnen we onze voorspellingen valideren omdat we over de echte voorspellingen beschikken voor het validatiegedeelte (wat we niet hebben voor de testdataset).
We zullen de train_test_split-functie van sklearn gebruiken om onze treindataset te verdelen. Laten we dus eerst train_test_split importeren.
uit sklearn.model_selection importeer train_test_split x_train, x_cv, y_train, y_cv = train_test_split(X,y, test_size =0.3)
De dataset is opgedeeld in trainings- en validatiedelen. Laten we LogisticRegression en accuratesse_score importeren uit sklearn en passen in het logistieke regressiemodel.
van sklearn.linear_model importeer LogisticRegressie van sklearn.metrics importeer nauwkeurigheid_score
model = LogistiekeRegressie() model.fit(x_train, y_train)

Hier vertegenwoordigt de C-parameter het omgekeerde van de regularisatiesterkte. Regularisatie is het toepassen van een sanctie op het vergroten van de omvang van parameterwaarden om overfitting te verminderen. Kleinere waarden van C specificeren sterkere regularisatie. Raadpleeg hier voor meer informatie over andere parameters:
Laten we de Loan_Status voor de validatieset voorspellen en de nauwkeurigheid ervan berekenen.
pred_cv = model.predict(x_cv)
Laten we berekenen hoe nauwkeurig onze voorspellingen zijn door de nauwkeurigheid te berekenen.
nauwkeurigheidsscore(y_cv,pred_cv)

Onze voorspellingen zijn dus bijna 80% nauwkeurig, dwz we hebben 80% van de leningstatus correct geïdentificeerd.
Laten we voorspellingen doen voor de testdataset.
pred_test = model.predict(test)
Laten we het indieningsbestand importeren dat we in de oplossingscontrole moeten indienen.
indiening=pd.read_csv("Voorbeeld_Submissie_ZAuTl8O_FK3zQHh.csv")
We hebben alleen de Loan_ID en de bijbehorende Loan_Status nodig voor de definitieve indiening. we vullen deze kolommen met de Loan_ID van de testdataset en de voorspellingen die we hebben gedaan, respectievelijk pred_test.
indiening['Loan_Status']=pred_test indiening['Loan_ID']=test_original['Loan_ID']
Onthoud dat we voorspellingen nodig hebben in Y en N. Dus laten we 1 en 0 omrekenen naar Y en N.
indiening['Leningstatus'].replace(0, 'N',inplace=True) indiening['Lening_Status'].replace(1, 'Y',inplace=True)
Ten slotte zullen we de inzending converteren naar .csv-formaat en een inzending doen om de nauwkeurigheid op het scorebord te controleren.
pd.DataFrame(inzending, kolommen=['Lening_ID','Lening_Status']).to_csv('logistiek.csv')
Uit deze inzending hebben we een nauwkeurigheid van 0.7847 op het scorebord gehaald.
In plaats van een validatieset te maken, kunnen we ook gebruik maken van kruisvalidatie om onze voorspellingen te valideren. We zullen deze techniek in de volgende sectie leren kennen.
Logistieke regressie met behulp van gestratificeerde k-vouwen kruisvalidatie
Om te controleren hoe robuust ons model is voor ongeziene gegevens, kunnen we validatie gebruiken. Het is een techniek waarbij je een bepaald sample van een dataset reserveert waarop je het model niet traint. Later test u uw model op dit voorbeeld voordat u het finaliseert. Enkele van de veelgebruikte validatiemethoden worden hieronder vermeld:
- De validatiesetbenadering
- k-voudige kruisvalidatie
- Laat één uit kruisvalidatie (LOOCV)
- Gestratificeerde k-voudige kruisvalidatie
In deze sectie zullen we leren over gestratificeerde k-voudige kruisvalidatie. . Laten we begrijpen hoe het werkt:
- Stratificatie is het proces waarbij de gegevens worden herschikt om ervoor te zorgen dat elke vouw een goede vertegenwoordiger is van het geheel.
- In een binair classificatieprobleem waarbij elke klasse bijvoorbeeld 50% van de gegevens omvat, is het het beste om de gegevens zo te rangschikken dat elke klasse in elke vouw ongeveer de helft van de instanties omvat.
- Het is over het algemeen een betere benadering als het gaat om zowel vooringenomenheid als variantie.
- Een willekeurig geselecteerde vouw vertegenwoordigt mogelijk niet voldoende de ondergeschikte klasse, vooral in gevallen waarin er een enorme klassenonbalans is.
Hieronder ziet u de visualisatie van een gestratificeerde k-voudige validatie wanneer k=5.

Laten we StratifiedKFold importeren uit sklearn en het model passen.
van sklearn.model_selection importeer StratifiedKFold
Laten we nu een logistiek model voor kruisvalidatie maken met gestratificeerde 5-vouwen en voorspellingen doen voor de testdataset.
i=1 kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True) voor train_index,test_index in kf.split(X,y): print('n{} van kfold {}'.format(i,kf .n_splits)) xtr,xvl = X.iloc[train_index],X.iloc[test_index] ytr,yvl = y.iloc[train_index],y.iloc[test_index] model = LogisticRegression(random_state=1) model.fit( xtr, ytr) pred_test = model.predict(xvl) score = nauwkeurigheid_score(yvl,pred_test) print('accuracy_score',score) i+=1 pred_test = model.predict(test) pred=model.predict_proba(xvl)[:, 1]
1 van kfold 5 nauwkeurigheidsscore 0.7983870967741935 2 van kfold 5 nauwkeurigheidsscore 0.8306451612903226 3 van kfold 5 nauwkeurigheidsscore 0.8114754098360656 4 van kfold 5 nauwkeurigheidsscore 0.7950819672131147 5 van kfold 5 nauwkeurigheidsscore 0.8278688524590164
De gemiddelde validatienauwkeurigheid voor dit model blijkt 0.81 te zijn. Laten we de roc-curve eens visualiseren.
van sklearn importeer statistieken fpr, tpr, _ = metrics.roc_curve(yvl, pred) auc = metrics.roc_auc_score(yvl, pred) plt.figure(figsize=(12,8)) plt.plot(fpr,tpr,label= "validation, auc="+str(auc)) plt.xlabel('False Positive Rate') plt.ylabel('True Positive Rate') plt.legend(loc=4) plt.show()

We kregen een AUC-waarde van 0.77.
indiening['Loan_Status']=pred_test indiening['Loan_ID']=test_original['Loan_ID']
Onthoud dat we voorspellingen nodig hebben in Y en N. Dus laten we 1 en 0 omrekenen naar Y en N.
indiening['Leningstatus'].replace(0, 'N',inplace=True) indiening['Lening_Status'].replace(1, 'Y',inplace=True)
Laten we de inzending converteren naar .csv-indeling en een inzending indienen om de nauwkeurigheid op het scorebord te controleren.
pd.DataFrame(inzending, kolommen=['Lening_ID','Lening_Status']).to_csv('Logistiek.csv')
Uit deze inzending hebben we een nauwkeurigheid van 0.78472 op het scorebord gehaald. Nu zullen we proberen deze nauwkeurigheid te verbeteren met behulp van verschillende benaderingen.
Functie-engineering
Op basis van de domeinkennis kunnen we nieuwe features bedenken die van invloed kunnen zijn op de doelvariabele. We zullen de volgende drie nieuwe functies creëren:
- Totaal inkomen: - Zoals besproken
tijdens de bivariate analyse combineren we het inkomen van de aanvrager en het inkomen van de medeaanvrager. Als het totale inkomen hoog is, is de kans op een lening groter
goedkeuring kan ook hoog zijn. - EMI: - EMI is het maandelijkse bedrag
de aanvrager moet betalen om de lening terug te betalen. Het idee achter het maken hiervan
De variabele is dat mensen met hoge EMI's dit misschien moeilijk vinden
de lening terugbetalen. We kunnen het EMI berekenen door de leningratio te nemen
bedrag met betrekking tot de looptijd van het geleend bedrag. - Saldo-inkomen: - Dit
is het inkomen dat overblijft nadat het EMI is betaald. Het idee achter creëren
deze variabele is dat als deze waarde hoog is, de kans groot is dat a
persoon zal de lening terugbetalen en daarmee de kans op een lening vergroten
goedkeuring.
trein['Totaal_Inkomen']=trein['AanvragerInkomen']+trein['MedeaanvragerInkomen'] test['Totaal_Inkomen']=test['AanvragerInkomen']+test['MedeaanvragerInkomen']
Laten we eens kijken naar de verdeling van het totale inkomen.
sns.distplot(trein['Totaal_inkomen']);

We kunnen zien dat de verdeling naar links is verschoven, dat wil zeggen dat de verdeling naar rechts scheef is. Laten we dus de logtransformatie nemen om de verdeling normaal te maken.
We kunnen zien dat de verdeling naar links is verschoven, dat wil zeggen dat de verdeling naar rechts scheef is. Laten we dus de logtransformatie nemen om de verdeling normaal te maken.
trein['Totaal_Inkomen_log'] = np.log(trein['Totaal_Inkomen']) sns.distplot(trein['Totaal_Inkomen_log']); test['Totaal_Inkomen_log'] = np.log(test['Totaal_Inkomen'])

Nu lijkt de verdeling veel dichter bij normaal en is het effect van extreme waarden aanzienlijk afgezwakt. Laten we nu de EMI-functie maken.
Nu lijkt de verdeling veel dichter bij normaal en is het effect van extreme waarden aanzienlijk afgezwakt. Laten we nu de EMI-functie maken.
trein['EMI']=trein['LoanAmount']/trein['Loan_Amount_Term'] test['EMI']=test['LoanAmount']/test['Loan_Amount_Term']
Laten we eens kijken naar de verdeling van de EMI-variabele.
sns.distplot(trein['EMI']);

Laten we nu de functie Saldo-inkomsten maken en de verdeling ervan controleren.
train['Balance Income']=train['Total_Income']-(train['EMI']*1000) # Vermenigvuldig met 1000 om de eenheden gelijk te maken test['Balance Income']=test['Total_Income']-( testen['EMI']*1000)
sns.distplot(trein['Balansinkomen']);

Laten we nu de variabelen laten vallen die we hebben gebruikt om deze nieuwe functies te creëren. De reden hiervoor is dat de correlatie tussen die oude kenmerken en deze nieuwe kenmerken erg hoog zal zijn, en logistische regressie gaat ervan uit dat de variabelen niet sterk gecorreleerd zijn. We willen ook de ruis uit de dataset verwijderen, dus het verwijderen van gecorreleerde kenmerken zal ook helpen de ruis te verminderen.
train=train.drop(['ApplicantIncome', 'CoapplicantIncome', 'LoanAmount', 'Loan_Amount_Term'], axis=1)
test=test.drop(['ApplicantIncome', 'CoapplicantIncome', 'LoanAmount', 'Loan_Amount_Term'], axis=1)
Modelbouw: deel 2
Nadat we nieuwe functies hebben gemaakt, kunnen we doorgaan met het modelbouwproces. We beginnen dus met het beslissingsboommodel en gaan dan over naar complexere modellen zoals RandomForest en XGBoost.
In deze sectie zullen we de volgende modellen bouwen.
- Beslissingsboom
- Willekeurig bos
- XGBoost
Laten we de gegevens voorbereiden om in de modellen te worden ingevoerd.
X = trein.drop('Lening_Status',1) y = trein.Lening_Status
Beslissingsboom
Een beslisboom is een soort begeleid leeralgoritme (met een vooraf gedefinieerde doelvariabele) dat meestal wordt gebruikt bij classificatieproblemen. Bij deze techniek splitsen we de populatie of steekproef op in twee of meer homogene sets (of subpopulaties) op basis van de meest significante splitter/differentiator in invoervariabelen.
Beslissingsbomen gebruiken meerdere algoritmen om te beslissen om een knooppunt in twee of meer subknooppunten te splitsen. Het creëren van subknooppunten verhoogt de homogeniteit van resulterende subknooppunten. Met andere woorden, we kunnen zeggen dat de zuiverheid van het knooppunt toeneemt ten opzichte van de doelvariabele.
van sklearn importboom
Laten we het beslissingsboommodel passen met 5 vouwen van kruisvalidatie.
i=1 kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True) voor train_index,test_index in kf.split(X,y): print('n{} van kfold {}'.format(i,kf .n_splits)) xtr,xvl = X.loc[train_index],X.loc[test_index] ytr,yvl = y[train_index],y[test_index] model = tree.DecisionTreeClassifier(random_state=1) model.fit(xtr, ytr) pred_test = model.predict(xvl) score = nauwkeurigheid_score(yvl,pred_test) print('accuracy_score',score) i+=1 pred_test = model.predict(test)

De gemiddelde validatienauwkeurigheid voor dit model is 0.69
submission['Loan_Status']=pred_test # Loan_Status vullen met voorspellingen submission['Loan_ID']=test_original['Loan_ID'] # Loan_ID vullen met test Loan_ID
indiening['Leningstatus'].replace(0, 'N',inplace=True) indiening['Lening_Status'].replace(1, 'Y',inplace=True)
# Inzendingsbestand converteren naar .csv-formaat pd.DataFrame(indiening, columns=['Loan_ID','Loan_Status']).to_csv('Decision Tree.csv')
We hebben een nauwkeurigheid van 0.69 bereikt, wat veel kleiner is dan de nauwkeurigheid van het beslisboommodel. Laten we dus een ander model bouwen, namelijk Random Forest, een op bomen gebaseerd ensemble-algoritme, en proberen ons model te verbeteren door de nauwkeurigheid te verbeteren.
Willekeurig bos
- RandomForest is een op een boom gebaseerd bootstrapping-algoritme waarin een bepaald nee. van zwakke leerlingen (beslissingsbomen) worden gecombineerd om een krachtig voorspellingsmodel te maken.
- Voor elke individuele leerling wordt een willekeurige steekproef van rijen en een paar willekeurig gekozen variabelen gebruikt om een beslissingsboommodel te bouwen.
- De uiteindelijke voorspelling kan een functie zijn van alle voorspellingen die door de individuele leerlingen zijn gedaan.
- In het geval van een regressieprobleem kan de uiteindelijke voorspelling het gemiddelde zijn van alle voorspellingen.
van sklearn.ensemble import RandomForestClassifier
i=1 kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True) voor train_index,test_index in kf.split(X,y): print('n{} van kfold {}'.format(i,kf .n_splits)) xtr,xvl = X.loc[train_index],X.loc[test_index] ytr,yvl = y[train_index],y[test_index] model = RandomForestClassifier(willekeurige_staat=1, max_diepte=10) model.fit( xtr, ytr) pred_test = model.predict(xvl) score = nauwkeurigheid_score(yvl,pred_test) print('nauwkeurigheid_score',score) i+=1 pred_test = model.predict(test)

De gemiddelde validatienauwkeurigheid voor dit model is 0.766
We zullen proberen de nauwkeurigheid te verbeteren door de hyperparameters voor dit model af te stemmen. We zullen rasterzoeken gebruiken om de geoptimaliseerde waarden van hyperparameters te verkrijgen. Grid-search is een manier om het beste uit een familie van hyperparameters te selecteren, geparametriseerd door een raster van parameters.
We zullen de parameters max_depth en n_estimators afstemmen. max_depth bepaalt de maximale diepte van de boom en n_estimators bepaalt het aantal bomen dat zal worden gebruikt in het willekeurige bosmodel.
van sklearn.model_selection importeer GridSearchCV
# Geef een bereik op voor max_diepte van 1 tot 20 met een interval van 2 en van 1 tot 200 met een interval van 20 voor n_schatters
paramgrid = {'max_diepte': lijst(bereik(1, 20, 2)), 'n_estimators': lijst(bereik(1, 200, 20))}
grid_search=GridSearchCV(RandomForestClassifier(random_state=1),paramgrid) uit sklearn.model_selection import train_test_split
# Pas het rasterzoekmodel grid_search.fit(x_train,y_train) aan
GridSearchCV(cv=Geen, error_score='raise', estimator=RandomForestClassifier(bootstrap=True, class_weight=Geen, criterium='gini', max_diepte=Geen, max_features='auto', max_leaf_nodes=Geen, min_impurity_decrease=0.0, min_impurity_split= Geen,min_samples_leaf=1, min_samples_split=2, min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1, oob_score=False, random_state=1, breedsprakig=0, warm_start=False),
fit_params=Geen, iid=Waar, n_jobs=1, param_grid={'max_diepte': [1, 3, 5, 7, 9, 11, 13, 15, 17, 19], 'n_estimators': [1, 21, 41, 61, 81, 101, 121, 141, 161, 181]}, pre_dispatch='2*n_jobs', refit=True, return_train_score='warn',scoring=Geen, uitgebreid=0)
# Het schatten van de geoptimaliseerde waarde
grid_search.best_estimator_

De geoptimaliseerde waarde voor de variabele max_diepte is dus 3 en voor n_estimator 41. Laten we nu het model bouwen met behulp van deze geoptimaliseerde waarden.
i=1 kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True) voor train_index,test_index in kf.split(X,y): print('n{} van kfold {}'.format(i,kf .n_splits)) xtr,xvl = X.loc[train_index],X.loc[test_index] ytr,yvl = y[train_index],y[test_index] model = RandomForestClassifier(random_state=1, max_diepte=3, n_estimators=41) model.fit(xtr, ytr) pred_test = model.predict(xvl) score = nauwkeurigheid_score(yvl,pred_test) print('nauwkeurigheid_score',score) i+=1 pred_test = model.predict(test) pred2 = model.predict_proba(test [:,1]

submission['Loan_Status']=pred_test # Loan_Status vullen met voorspellingen submission['Loan_ID']=test_original['Loan_ID'] # Loan_ID vullen met test Loan_ID
indiening['Leningstatus'].replace(0, 'N',inplace=True) indiening['Lening_Status'].replace(1, 'Y',inplace=True)
# Inzendingsbestand converteren naar .csv-formaat pd.DataFrame(inzending, kolommen=['Loan_ID','Loan_Status']).to_csv('Random Forest.csv')
We hebben een nauwkeurigheid van 0.7638 verkregen uit het willekeurige bosmodel op het scorebord.
Laten we nu het belang van het kenmerk bekijken, dwz welke kenmerken het belangrijkst zijn voor dit probleem. We zullen het kenmerk feature_importances_ van sklearn gebruiken om dit te doen.
importanties=pd.Series(model.feature_importances_, index=X.columns) importanties.plot(kind='barh', figsize=(12,8))

We kunnen zien dat Credit_History het belangrijkste kenmerk is, gevolgd door Balance Income, Total Income en EMI. Functie-engineering heeft ons dus geholpen bij het voorspellen van onze doelvariabele.
XGBOOST
XGBoost is een snel en efficiënt algoritme en is gebruikt door de winnaars van vele data science-wedstrijden. Het is een boostalgoritme en je kunt het onderstaande artikel raadplegen voor meer informatie over boosten:
XGBoost werkt alleen met numerieke variabelen en we hebben de categorische variabelen al vervangen door numerieke variabelen. Laten we eens kijken naar de parameters die we in ons model gaan gebruiken.
- n_estimator: Dit specificeert het aantal bomen voor het model.
- max_diepte: Met deze parameter kunnen we de maximale diepte van een boom specificeren.
van xgboost importeer XGBClassifier
i=1 kf = StratifiedKFold(n_splits=5,random_state=1,shuffle=True) voor train_index,test_index in kf.split(X,y): print('n{} van kfold {}'.format(i,kf .n_splits)) xtr,xvl = X.loc[trein_index],X.loc[test_index] ytr,yvl = y[trein_index],y[test_index] model = XGBClassifier(n_estimators=50, max_diepte=4) model.fit( xtr, ytr) pred_test = model.predict(xvl) score = nauwkeurigheid_score(yvl,pred_test) print('nauwkeurigheid_score',score) i+=1
pred_test = model.predict(test) pred2 = model.predict_proba(test[:,1]

De gemiddelde validatienauwkeurigheid voor dit model is 0.79.
submission['Loan_Status']=pred_test # Loan_Status vullen met voorspellingen submission['Loan_ID']=test_original['Loan_ID'] # Loan_ID vullen met test Loan_ID
indiening['Leningstatus'].replace(0, 'N',inplace=True) indiening['Lening_Status'].replace(1, 'Y',inplace=True)
# Inzendingsbestand converteren naar .csv-formaat pd.DataFrame(inzending, kolommen=['Loan_ID','Loan_Status']).to_csv('XGBoost.csv')
Met dit model hebben we een nauwkeurigheid van 0.73611 bereikt. Ik hoop dat dit artikel je heeft geholpen bij het begrijpen hoe een machine learning-competitie wordt benaderd en wat de stappen zijn die je moet doorlopen om een robuust model te bouwen. Dus repliceer deze analyse en laat het ons weten als u problemen ondervindt.
Conclusie
Er zijn nog steeds heel veel dingen die kunnen worden geprobeerd om de voorspellingen van onze modellen te verbeteren. We creëren en voegen meer variabelen toe, proberen verschillende modellen met een andere subset van kenmerken en/of rijen, enz. Enkele van de ideeën staan hieronder opgesomd
- We kunnen het XGBoost-model trainen met behulp van grid search om de hyperparameters te optimaliseren en de nauwkeurigheid ervan te verbeteren.
- We kunnen de aanvragers combineren met 1,2,3 of meer personen ten laste en een nieuwe functie maken zoals besproken in het EDA-gedeelte.
- We kunnen ook onafhankelijke versus onafhankelijke variabele visualisaties maken om nog meer patronen te ontdekken.
- We kunnen ook tot het EMI komen met behulp van een betere formule, die mogelijk ook rentetarieven omvat.
- We
kan zelfs ensemblemodellering proberen (een combinatie van verschillende modellen). Naar
Voor meer informatie over ensembletechnieken kunt u deze artikelen raadplegen
Belangrijkste leerpunten
1. begrijp het echte probleem
2. Verkennende gegevensanalyse (EDA) en voorverwerking
3. het concept van univariaat, bivariaat begrijpen
4. hoe u uitbijterpunten uit gegevens kunt vinden
5. hoe je een model evalueert met behulp van statistieken
6. we leren ook enkele technieken van feature engineering
7. Modelbouw met weinig algoritmen
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.

