Hallo!, techneuten, ik weet zeker dat dit artikel u zal helpen begrijpen hoe u Azure Databricks-notebook kunt gebruiken om gegevensgerelateerde bewerkingen erin uit te voeren. Laten we gaan!
Databricks
Databricks Data Science & Engineering (soms simpelweg "Werkruimte“) is een analyseplatform gebaseerd op Apache Spark. Het is geïntegreerd met Azuur, AWS en GCP om een installatie met één klik, gestroomlijnde workflows en een interactieve werkruimte te bieden die samenwerking tussen data-engineers, datawetenschappers en machine learning-engineers mogelijk maakt.
Azure Databricks is een data-analyseplatform dat is geoptimaliseerd voor het Microsoft Azure-cloudservicesplatform. Azure Databricks biedt twee omgevingen voor het ontwikkelen van data-intensieve applicaties: Databricks gegevenswetenschap en -techniek, en Databricks machine learning. Azure is de first-party serviceprovider van Databricks (wat betekent dat alle ondersteuningsservices voor databricks door Azure in de cloud worden geleverd). U kunt de databricks-werkruimte hieronder zien: -
Stappen om de Azure Databricks-service te maken
Voorwaarde
U moet ten minste een abonnement op de gratis laag van Azure hebben.
Stap 1: – Open de Azure-portal (portal.azure.com)
Stap 2:- Om de Databricks-service te maken, moet u op het pictogram "Create a Resource" klikken.
Stap 2.1:- Zoek nu naar de "Azure Databricks" service en klik vervolgens op de optie Create-knop.
Stap 2.2:- Vul nu de details in die nodig zijn voor het maken van de service in het gedeelte met projectdetails.
Selecteer de juiste abonnement uit de vervolgkeuzelijst gebruik ik voor mij een gratis proefversie, dus ik zal de standaardoptie kiezen die wordt aangeboden.
Nu moet je een resource groep, klik gewoon op nieuwe maken als je die niet hebt, anders kies je er een uit de vervolgkeuzelijst.
Nu moet je de Instantiedetails secties geven hieronder
Naam werkruimte:- geef de naam op voor uw werkruimte
Regio:- selecteer de regio die bij u past. Ik zal de standaard kiezen.
Prijsniveau:- Ik zal de standaard kiezen.
Stap 2.3:- Nu zal ik andere dingen standaard houden en op volgende klikken in de secties Netwerken, Geavanceerd en Taggen.
Stap 2.4:- Klik ten slotte op de “Beoordelen + Maken” knop.
stap 2.5:- Zodra het bericht “Validatie geslaagd” is weergegeven, Klik op de "Creëren" knop.
stap 2.6:- Klik nu op ga naar service en u wordt doorgestuurd naar uw azure databricks-servicepagina klik op "Start werkruimte" en u wordt doorgestuurd naar uw werkruimte.
Nu is onze azure databricks-service gemaakt. Het is tijd om een cluster te maken om de notebook uit te voeren. Laten we creëren...
Clustercreatie in Databricks
Stap-1:- Klik in de menu-opties voor databricks op "Berekenen" om een cluster te maken.
Stap-2:- U wordt doorgestuurd naar de rekenpagina, hier krijgt u 2 soorten opties voor het maken van clusters, één is "Clusters voor alle doeleinden" en de andere is "Vacaturecluster".
Cluster voor alle doeleinden: - Ze worden gebruikt voor gegevensanalyse met behulp van notebooks en voeren gegevensopname en transformatie uit met behulp van notebooks.
Functiecluster:- Ze worden gebruikt voor het uitvoeren van de taak of het plannen van notebooks om de bewerkingen uit te voeren die in de notebooks zijn geschreven.
Hier gaan we clusters voor alle doeleinden maken, klik nu op de knop Cluster maken.
Stap-3:- Nu wordt u verplaatst naar de pagina voor het maken van nieuwe clusters. Hier moet u de volgende details instellen: -
Clusternaam:- Kies de naam die u uw cluster wilt geven. Ik heb "blogdemocls" gegeven.
Clustermodus: - Hier krijg je drie opties "Hoge gelijktijdigheid", "Standard" en "Enkel knooppunt". Momenteel zit ik op het gratis niveau, dus ik zal kiezen "Enkel knooppunt". U kunt andere opties kiezen volgens uw computervereisten.
Databricks Runtime-versie:- Hierin krijgt u verschillende runtime-versies van Scala en Spark. Hierin zal ik de nieuwste versie kiezen met de optie LTS (Long Term Support). U kunt kiezen volgens uw vereisten.
Stuurautomaat opties:- Hierin kunt u de inactiviteitstijd definiëren. Het cluster wordt gestopt als het inactief wordt gedurende de gedefinieerde inactiviteitstijd.
Opmerking:- Als u een andere clustermodus kiest, krijgt u twee andere opties "Werknemertype" en "Bestuurderstype". Maar we bevinden ons momenteel op het gratis niveau, dus deze twee opties zijn voor ons uitgeschakeld.
Knooppunttype:- Hier definieert u de configuratie van uw machine die u nodig heeft om uw gegevens te verwerken. Zoals hoeveel geheugen en cores je nodig had. U krijgt veel opties, of u nu reken-, geheugen- of opslagdoeleinden nodig heeft, u kunt uit deze kiezen. Hierin kiezen we a Standaard D4a_v4-machine voor algemeen gebruik met 16 GB geheugen en 4 cores. U vindt deze machine in de categorie Algemeen gebruik en klik vervolgens op meer opties.
Klik nu op de knop Create Cluster en wacht op de creatie ervan. Als het nu is gemaakt, klik dan op de startknop en het zal binnen 3 tot 5 minuten aan de slag gaan.
Aanmaken van notitieboekjes
Nu is ons cluster actief en gaan we ons eerste databricks-notebook maken.
Stap-1:- Ga naar de werkruimte en klik erop en klik vervolgens op de vervolgkeuzepijl in de werkruimte en maak een nieuwe map om alle notebooks erin te bewaren. We zullen deze map "inshortsnews" noemen.
Stap-2:- Klik nu op de vervolgkeuzepijl van de map "inshortsnews", klik op maken en klik vervolgens op het notitieboek.
Stap-2.1:- Geef nu alle details voor het maken van een notitieblok, zoals naam, Ik geef de naam "inshorts-news-data-scrapping" aan ons notitieboekje, standaard taal, zullen we "Python" kiezen. Als u wilt, kunt u ook kiezen tussen R, Scala en SQL als standaardtaal voor uw project.
Stap-2.2:- Klik op maken en het notitieboek wordt gemaakt met de opgegeven taal.
In het kort Nieuws Scrapping
Nu gaan we de nieuwsgegevens van de Inshorts-nieuwsweb-app schrapen met behulp van python, panda's en andere bibliotheken.
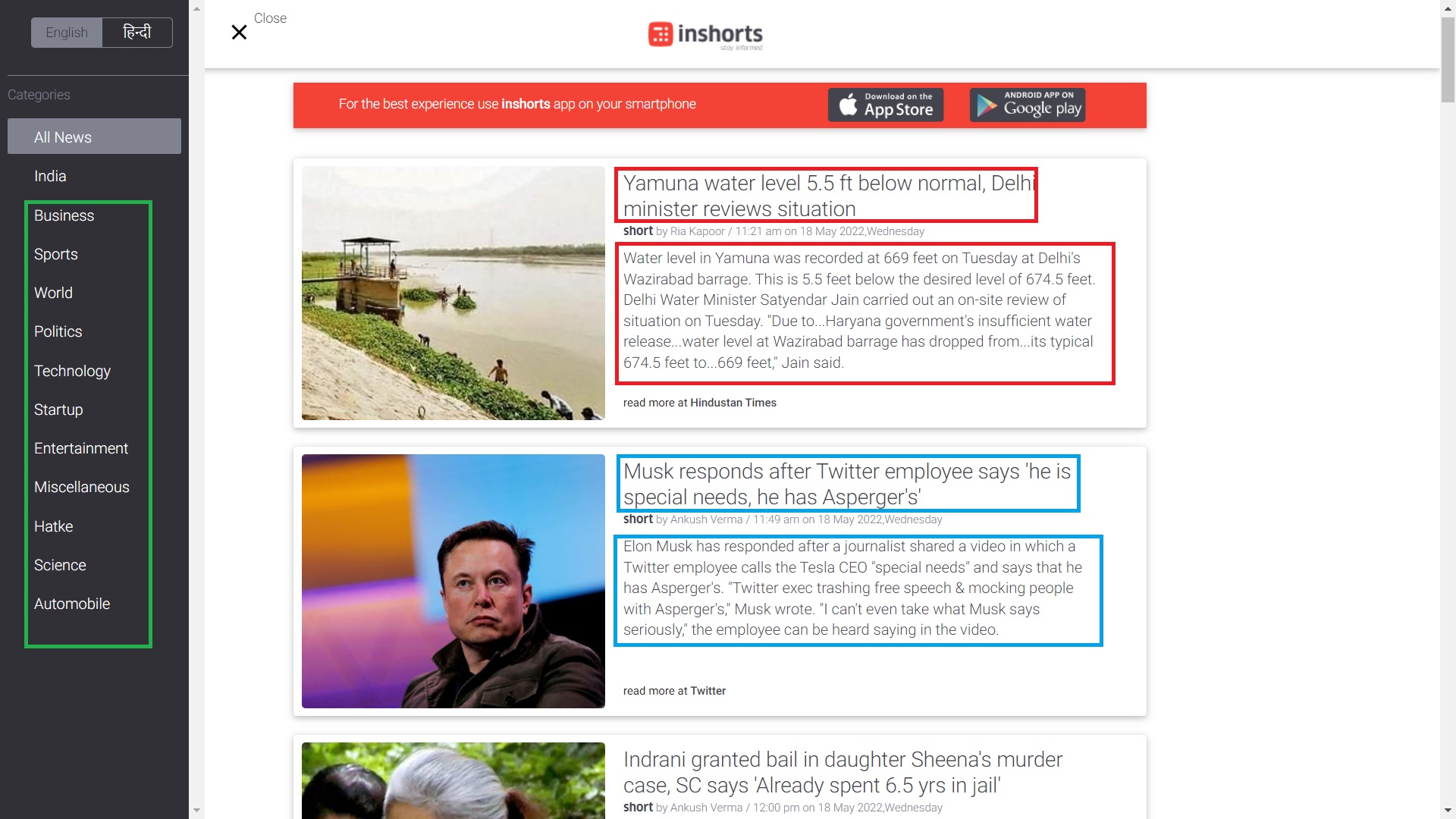
In kortebroek is een aggregator-app die nieuwsartikelen in 60 woorden samenvat en een breed scala aan onderwerpen behandelt, waaronder technologie, zaken en andere inhoud zoals video's, infographics en blogs. In de onderstaande afbeelding gaan we de gegevens schrapen die zich in de rechthoekige vakken bevinden.
Hierin gaan we de artikelen schrapen nieuwskoppen, nieuws inhoudEn categorie van de nieuwsartikelen.
Nieuwskop:- Het is een zin van één regel die een overzicht van het nieuwsartikel bevat.
Nieuwsartikel:- Het is een zin met meerdere regels en bevat alle informatie over het nieuws in 60 woorden.
Nieuws categorie: - Het vertelt de categorie van het nieuwsartikel.
Voorbeeld
news_headline:- Musk's Boring Company deelt een glimp van het loopstation in Las Vegas.
news_article:- The Boring Company heeft een korte clip op Twitter gedeeld waarin een van de metrostations te zien is die het bedrijf aan het bouwen is als onderdeel van de lus van het Las Vegas Convention Center (LVCC). In september zei oprichter Elon Musk dat de eerste operationele tunnel onder Vegas bijna voltooid was. "Tunnels onder steden met zelfrijdende elektrische auto's zullen aanvoelen als warp drive", had hij eraan toegevoegd.
nieuwe_categorie: - Technologie
De artikelen zijn in veel categorieën ingedeeld, maar we gaan slechts 7 verschillende categorieën schrappen en ze zijn als volgt: - technology, sports, politics, entertainment, world, automobile en science.
Laten we beginnen met coderen
Om deze gegevens te verzamelen heb ik de volgende bibliotheken gebruikt requests, BeautifulSoup4 en pandas. Dus om deze bibliotheken te gebruiken, moeten we ze eerst in onze notebook installeren. We hoeven alleen maar te installeren Mooie soep lib en de andere twee zijn al bij onze notebook geleverd.
Stap-1:- Om bibliotheken in databricks-notebooks te installeren, gebruiken we de onderstaande methode:-
Stap-2:- Importeer nu alle vereiste bibliotheken
Stap-3:- Definieer nu de eindpunten voor elke categorie van waaruit we de gegevens willen schrapen.
Stap-04:- Nu zullen we verzoeken verzenden voor elk van de hierboven gedefinieerde "URL's" en vervolgens de antwoordgegevens verfraaien. Vervolgens gebruikten we lijstbegrip om alle nieuwskoppen en nieuwe inhoud uit de responsgegevens te vinden. We splitsen ook de URL's om de nieuwscategorie te krijgen.
Stap-05:- Maak het dataframe uit het woordenboek van de gegevens die we uit de Inshorts-nieuwswebapp hebben gehaald.
Stap-06:- Geef nu de gegevens weer die we hebben geschraapt.
Proost!!! over het bereiken van het einde van de gids en het leren van behoorlijk interessante dingen over Azure Databricks. Uit deze gids hebt u met succes geleerd hoe u databricks-services in azure cloud kunt starten. Daarnaast heb je ook geleerd hoe je clusters voor notebooks kunt maken in databricks en de basis van het schrappen van gegevens met behulp van python en panda's.
Nu gaan we in het volgende artikel A verkennenzure Data Lake Storage Gen2 (ADLS Gen2), hoe u ADLS gen2-opslagservices kunt maken en daarnaast gaan we onze geschraapte gegevens opslaan in dit opslagaccount door onze notebook op uurbasis te plannen met behulp van de Azure Data Factory (ADF) methoden. Hierdoor creëren we onze eigen tekstuele dataset voor de NLP-taken.
Voel je vrij om contact met mij op te nemen LinkedIn en GitHub voor meer content over Data Engineering en Machine Learning!
Veel plezier met leren!!!
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.














.png)






