Amazon Kendra is een zeer nauwkeurige en gebruiksvriendelijke intelligente zoekservice die wordt aangedreven door machine learning (ML). Amazon Kendra biedt een reeks gegevensbronconnectoren om het proces van het opnemen en indexeren van uw inhoud te vereenvoudigen, waar deze zich ook bevindt.
Waardevolle data in organisaties wordt opgeslagen in zowel gestructureerde als ongestructureerde repositories. Een enterprise search-oplossing moet in staat zijn om gegevens uit verschillende gestructureerde en ongestructureerde repositories samen te brengen om te indexeren en te doorzoeken.
Een van die ongestructureerde gegevensopslagplaatsen is Confluence. Confluence is een teamwerkruimte die kenniswerkersteams een plek biedt om elk project of idee te creëren, vast te leggen en eraan samen te werken. Teamruimtes helpen teams bij het structureren, organiseren en delen van werk, zodat elk teamlid inzicht heeft in de institutionele kennis en toegang heeft tot de informatie die ze nodig hebben.
Er zijn twee Samenvloeiing aanbod:
- Cloud – Dit wordt aangeboden als een software-as-a-service (SaaS) product. Het staat altijd aan, wordt voortdurend bijgewerkt en is uiterst veilig.
- Datacenter (in eigen beheer) – Hier host u Confluence op uw infrastructuur, die zich op locatie of in de cloud kan bevinden. Hierdoor kunt u gegevens binnen uw netwerk houden en zelf beheren.
We zijn verheugd aan te kondigen dat je nu de nieuwe Amazon Kendra-connector V2 voor Confluence kunt gebruiken om informatie te doorzoeken die is opgeslagen in je Confluence-account, zowel in de cloud als in je datacenter. In dit bericht laten we zien hoe u informatie kunt indexeren die is opgeslagen in Confluence en hoe u de intelligente zoekfunctie van Amazon Kendra kunt gebruiken. Bovendien kan de door ML aangedreven intelligente zoekfunctie nauwkeurig informatie vinden uit ongestructureerde documenten met verhalende inhoud in natuurlijke taal, waarvoor zoeken op trefwoord niet erg effectief is.
Wat is er nieuw voor deze versie
Deze versie ondersteunt OAuth 2.0-authenticatie naast basisauthenticatie voor de Cloud-editie. Voor de Data Center (on-premises) editie hebben we OAuth2 toegevoegd naast basisauthenticatie en persoonlijke toegangstokens voor het tonen van zoekresultaten op basis van gebruikerstoegangsrechten. U kunt profiteren van de volgende functies:
- U kunt nu naast ruimtes, pagina's, blogs en bijlagen ook opmerkingen crawlen
- U heeft nu fijnmazige keuzes voor uw synchronisatiebereik: u kunt pagina's, blogs, opmerkingen en bijlagen specificeren
- U kunt ervoor kiezen om identiteiten te importeren (of niet)
- Deze versie biedt regex-ondersteuning voor het kiezen van entiteitstitels en bestandstypen
- Je hebt de keuze uit meerdere synchronisatiemodi
Overzicht oplossingen
Met Amazon Kendra kunt u meerdere gegevensbronnen configureren om een centrale plek te bieden voor het doorzoeken van uw documentrepository. Voor onze oplossing laten we zien hoe u een Confluence-repository kunt indexeren met behulp van de Amazon Kendra-connector voor Confluence. De oplossing bestaat uit de volgende stappen:
- Kies een authenticatiemechanisme.
- Configureer een app op Confluence en ontvang de verbindingsdetails.
- Bewaar de gegevens in AWS-geheimenmanager.
- Maak een Confluence-gegevensbron V2 via de Amazon Kendra-console.
- Indexeer de gegevens in de Confluence-repository.
- Voer een voorbeeldquery uit om de oplossing te testen.
Voorwaarden
Om de Amazon Kendra-connector voor Confluence uit te proberen, heb je het volgende nodig:
Kies een authenticatiemechanisme
Kies uw gewenste authenticatiemethode:
- Basic - Dit werkt op zowel de Cloud- als de Data Center-editie. U hebt een gebruikers-ID en een wachtwoord nodig om deze methode te configureren.
- Persoonlijke toegangstoken – Deze optie werkt alleen voor de Data Center-editie.
- OAuth2 - Dit is meer betrokken en werkt voor zowel Cloud- als Data Center-edities.
Verzamel authenticatiegegevens
In dit gedeelte laten we de stappen zien om uw authenticatiegegevens te verzamelen, afhankelijk van uw authenticatiemethode.
Basisverificatie
Voor basisauthenticatie met de Data Center-editie heeft u alleen uw login en wachtwoord nodig. Zorg ervoor dat uw login rechten heeft om alle inhoud te verzamelen.
Voor de Cloud-editie dient uw gebruikers-ID als uw gebruikerslogin. Voor uw wachtwoord heeft u een token nodig. Voer de volgende stappen uit:
- Inloggen https://id.atlassian.com/manage-profile/security/api-tokens En kies API-token maken.

- Voor label, voer een naam in voor het token.
- Kies creëren.
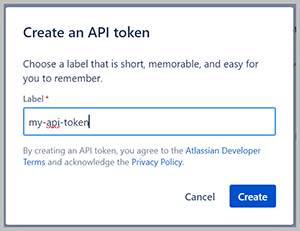
- Kopieer de waarde en sla deze op om te gebruiken als uw wachtwoord.

Persoonlijke toegangstoken
Deze authenticatiemethode werkt alleen voor on-premises (datacenter). Voer de volgende stappen uit om authenticatiegegevens te verkrijgen:
- Meld u aan bij uw Confluence-URL met de gebruikers-ID en het wachtwoord die Amazon Kendra moet gebruiken bij het ophalen van inhoud.
- Kies het profielpictogram en kies Instellingen.

- Kies Persoonlijke toegangstokens in het navigatievenster en kies vervolgens Token maken.

- Voor Token naam, voer een naam in.
- Voor Vervaldatum, deselecteren Automatische vervaldatum.
- Kies creëren.

- Kopieer het token en bewaar het op een veilige plaats.
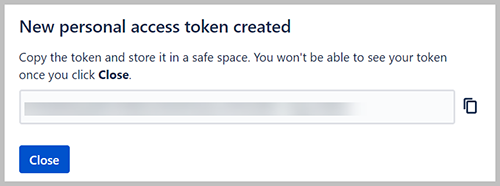
Om Secrets Manager te configureren, gebruiken we de login-URL en deze waarde.
OAuth2-authenticatie voor Confluence Cloud-editie
Deze authenticatiemethode volgt het volledige OAuth2.0 (3LO) documentatie van Samenvloeiing. We maken en configureren eerst een app op Confluence en schakelen deze in voor OAuth2. Het proces is iets anders voor de Cloud- en Data Center-edities. We krijgen dan een autorisatietoken en wisselen deze in voor een toegangstoken. Ten slotte krijgen we de klant-ID, het klantgeheim en de klantcode. Voer de volgende stappen uit:
- Log in op de Confluence-app.
- Navigeer naar https://developer.atlassian.com/.
- Naast Mijn apps, kiezen creëren En kies OAuth2-integratie.

- Voor Naam, voer een naam in.
- Kies creëren.
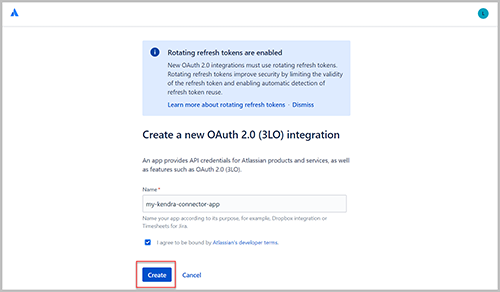
- Kies autorisatie in het navigatievenster.
- Kies Toevoegen naast uw autorisatietype.
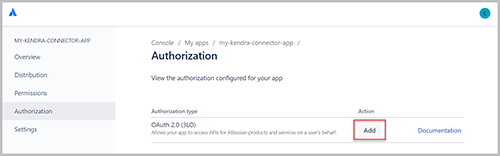
- Voor Terugbel-URL, voer de URL in die je gebruikt om in te loggen bij Confluence.
- Kies Wijzigingen opslaan.
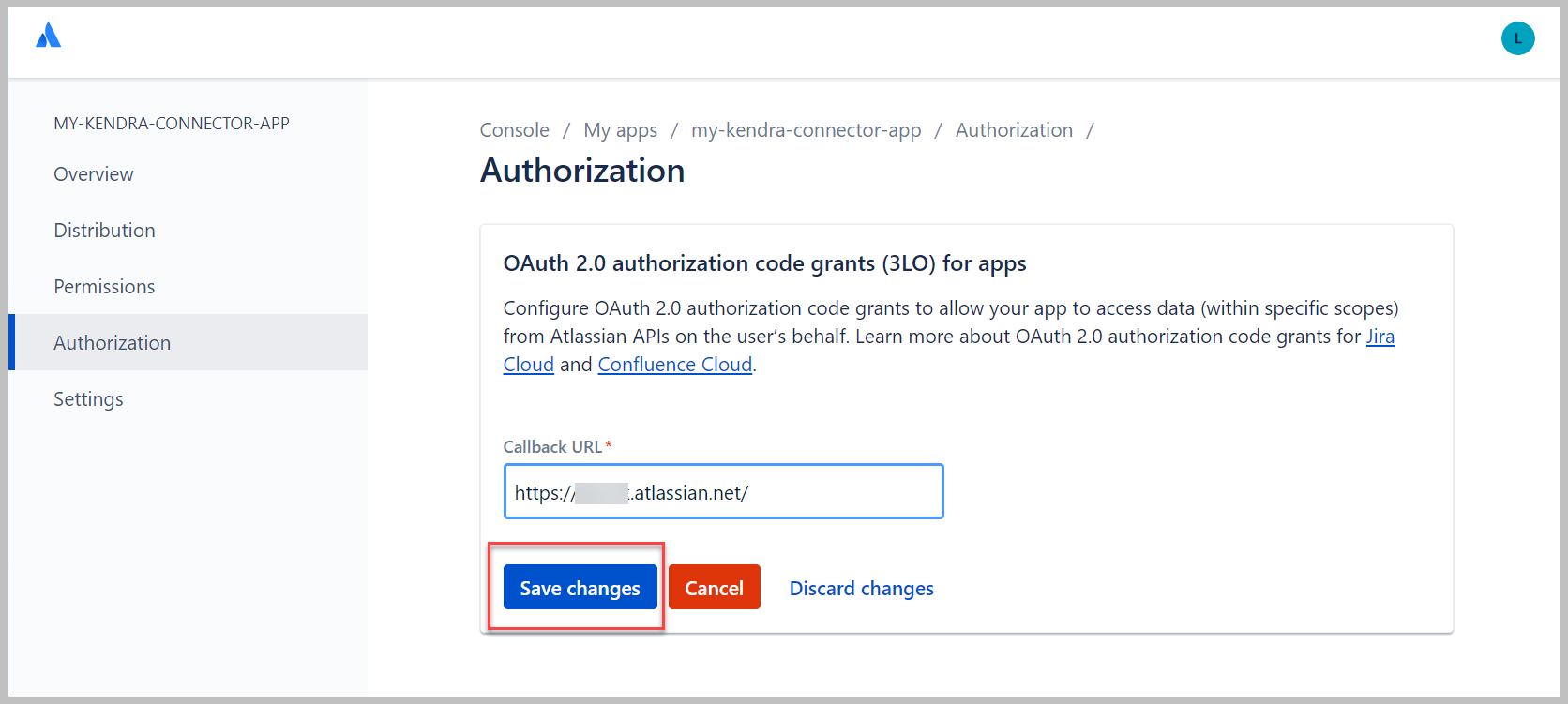
- Onder Autorisatie-URL-generator, kiezen API's toevoegen.
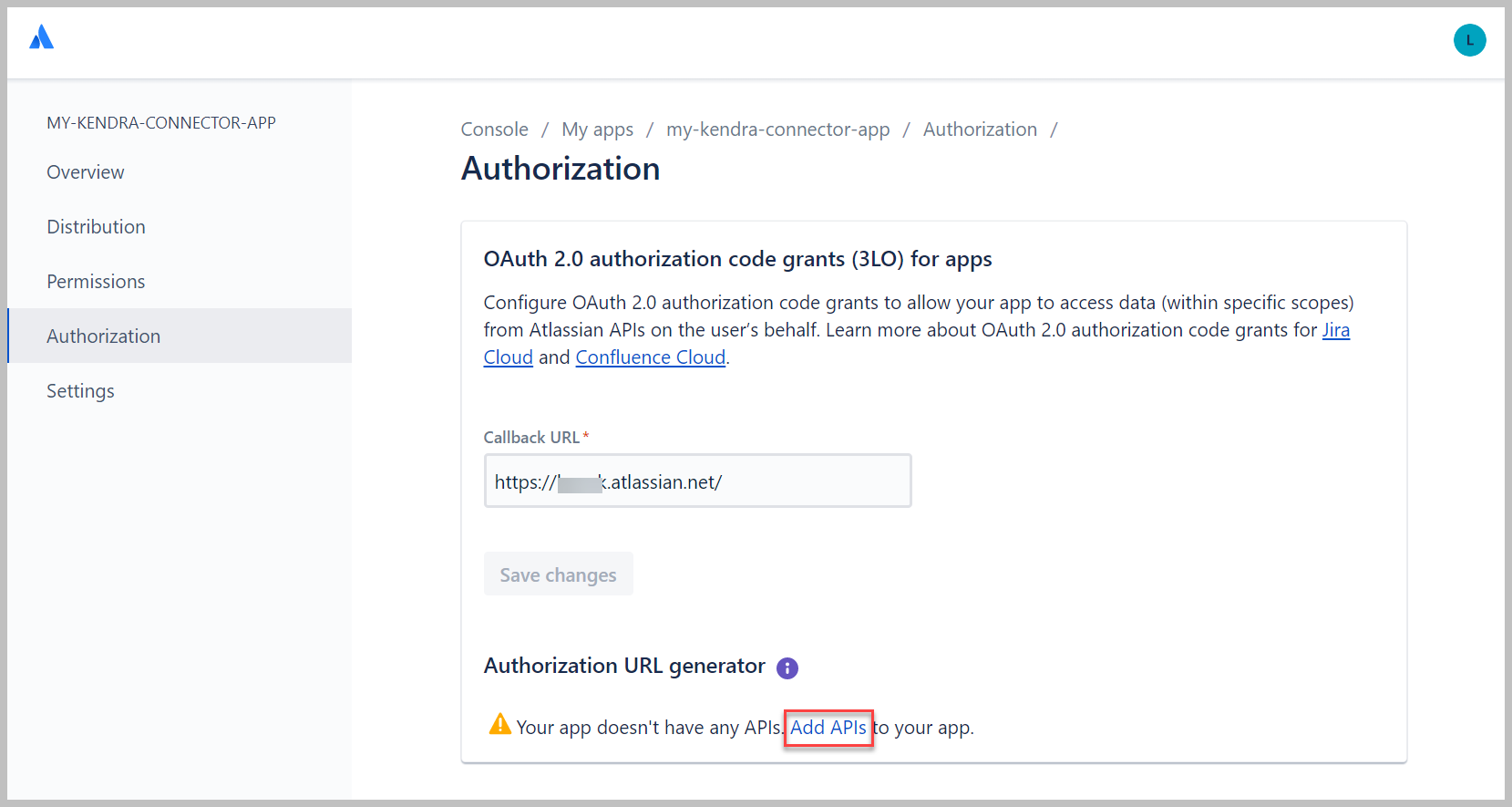
- Naast API voor gebruikersidentiteit, kiezen Toevoegen, kies dan Configure .
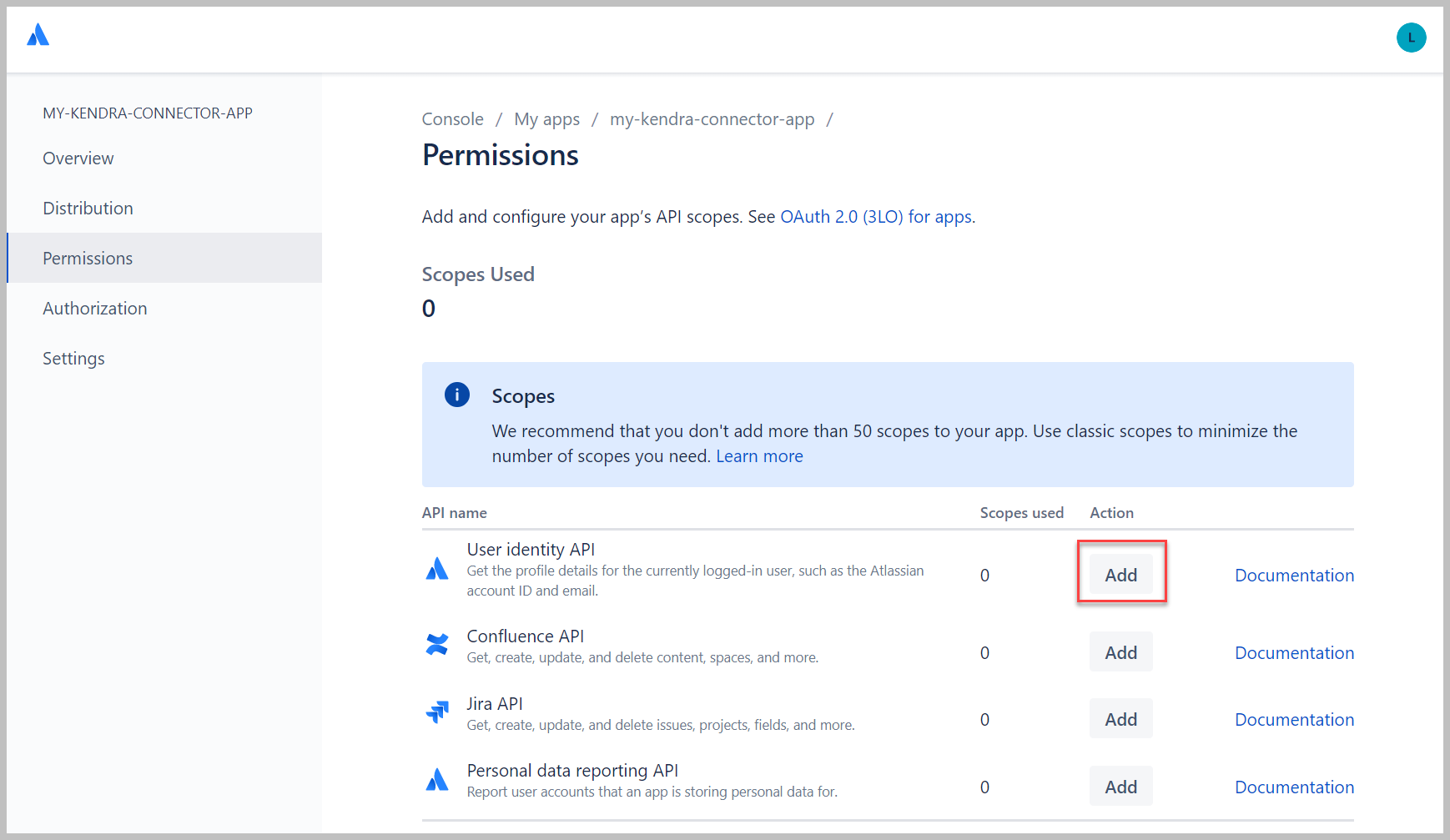
- Kies Bereiken bewerken om leesbereiken voor de app te configureren.
- kies Bekijk actief gebruikersprofiel en Gebruikersprofielen bekijken.
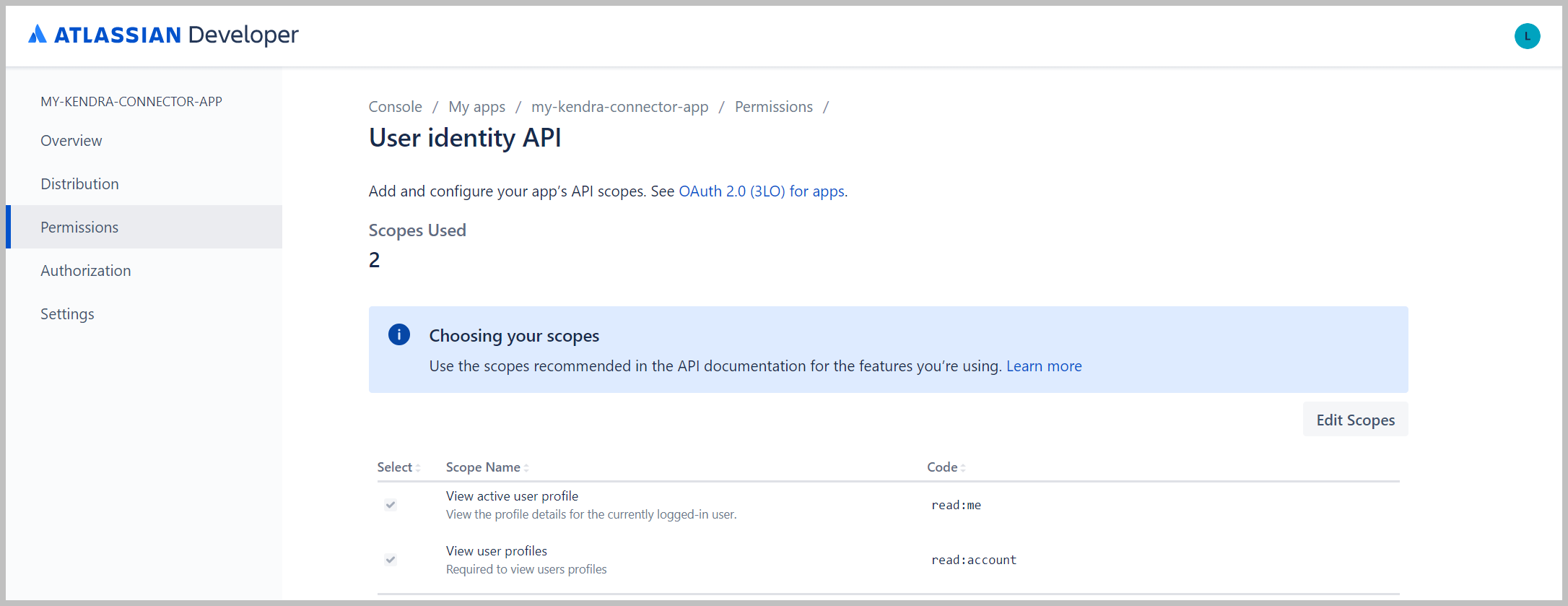
- Kies machtigingen in het navigatievenster.
- Naast Confluence-API, kiezen Toevoegen, kies dan Configure .
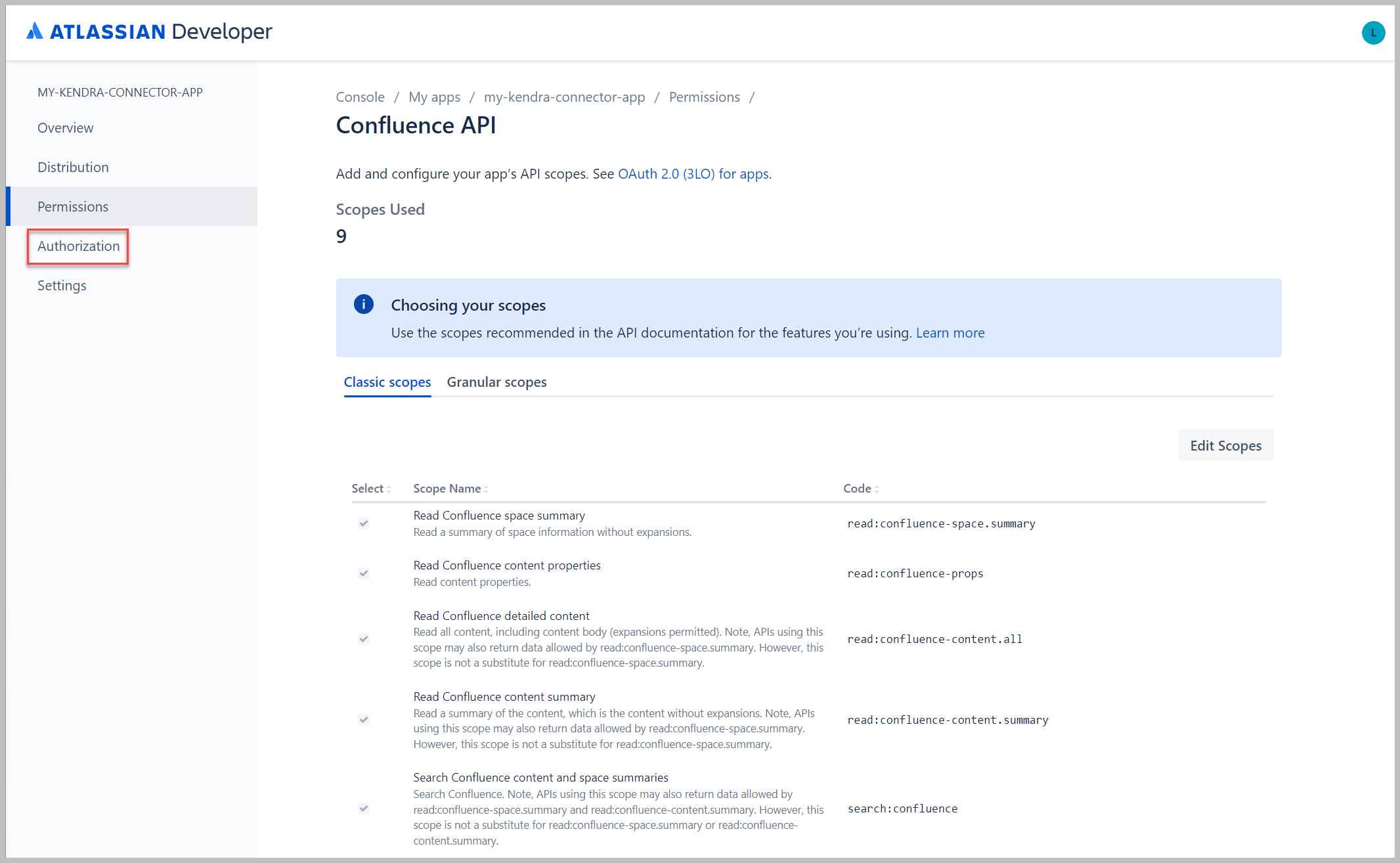
- Op de Klassieke scopes tabblad, kies Bereiken bewerken.
- Selecteer alle lees-, zoek- en downloadbereiken.
- Kies Bespaar.
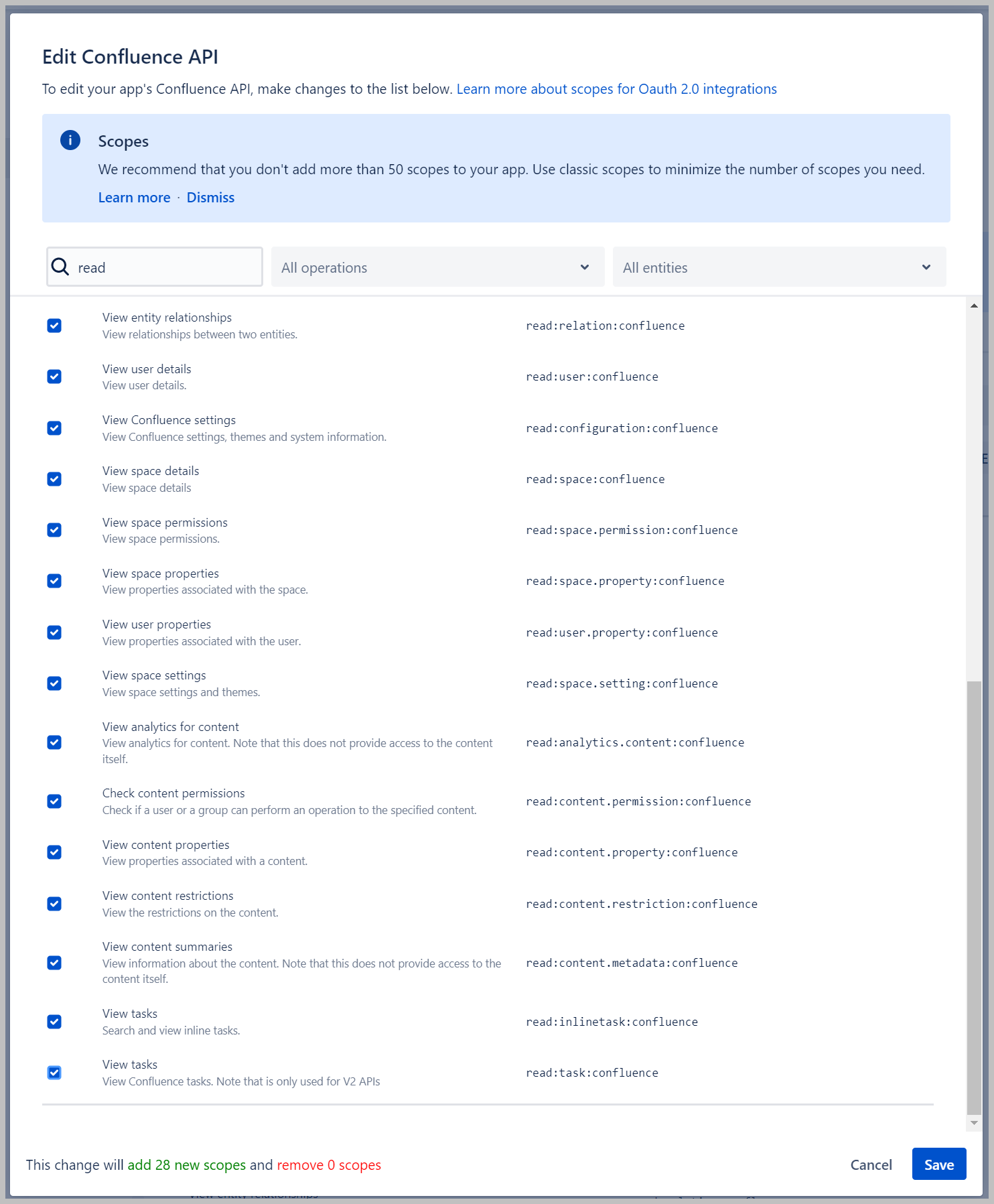
- Op de Gedetailleerde scopes tabblad, kies Bereiken bewerken.
- Zoek naar read en selecteer alle gevonden scopes.
- Kies Bespaar.
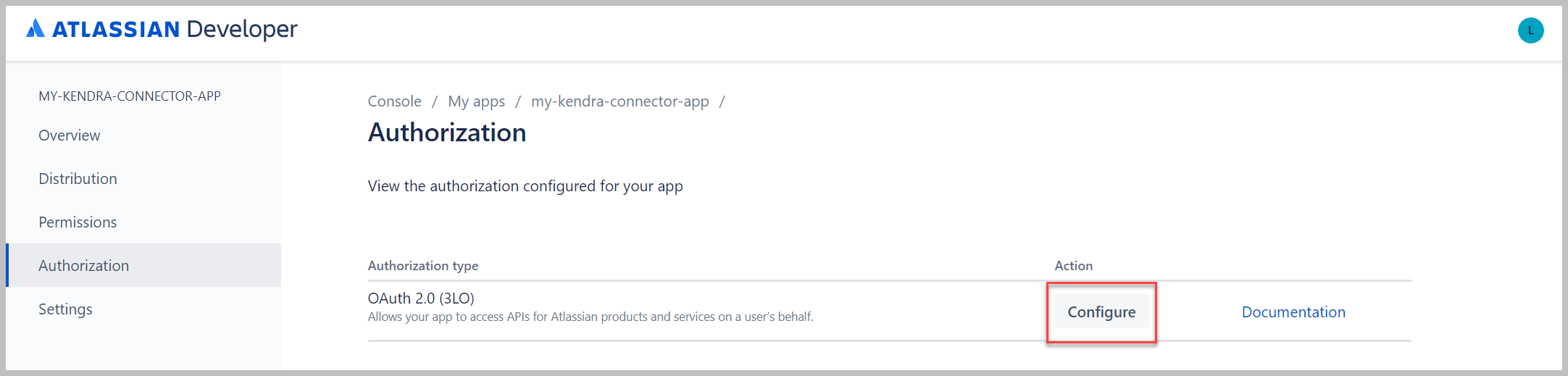
- Kies autorisatie in het navigatievenster.
- Kies naast uw autorisatietype Configure .
U zou drie URL's moeten zien staan.
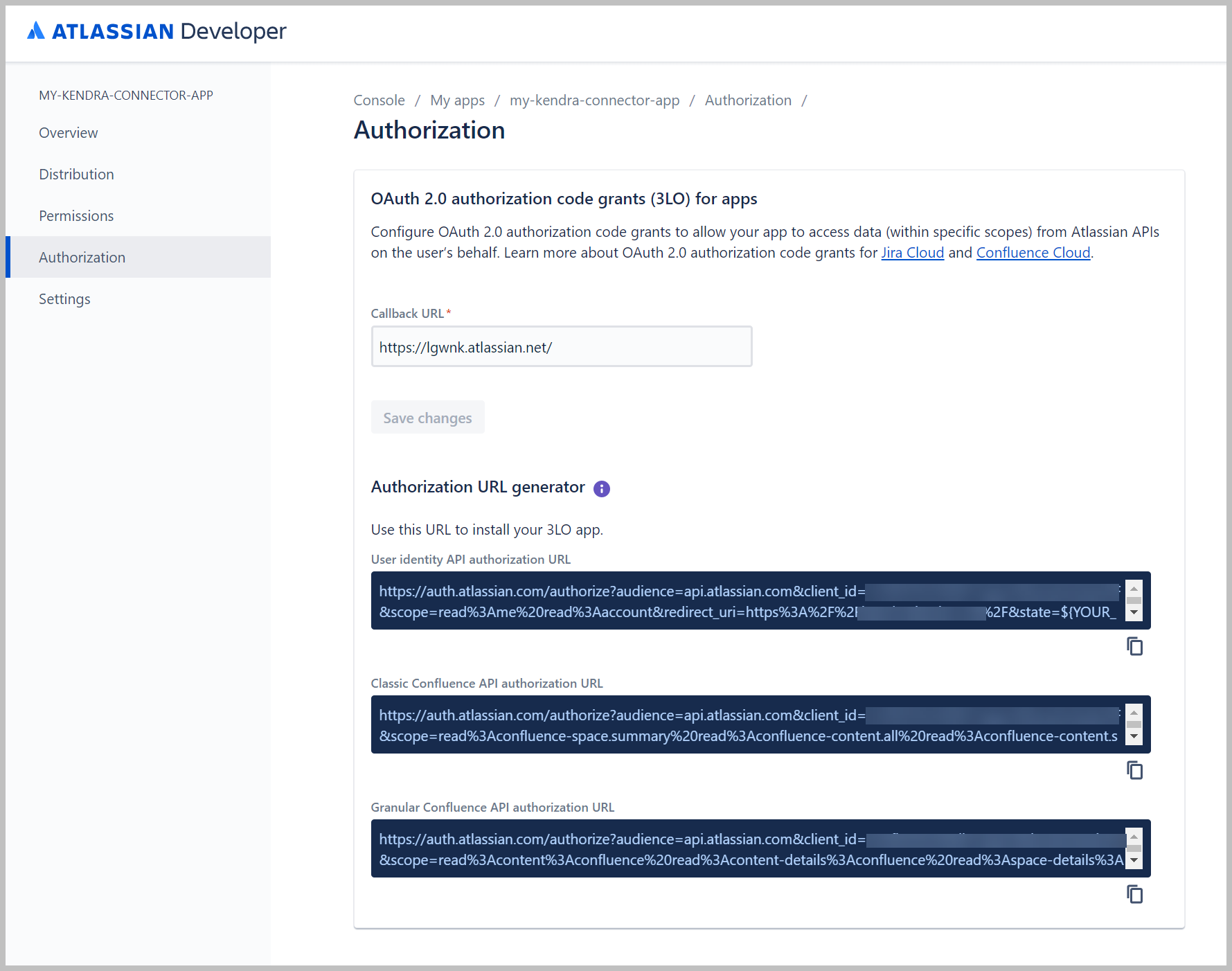
- Kopieer de code voor Gedetailleerde Confluence API-autorisatie-URL.
Het volgende is voorbeeldcode:
- Als u een vernieuwingstoken wilt genereren zodat u dit proces niet hoeft te herhalen, voegt u toe
offline_access(of%20offline_access) toe aan het einde van alle bereiken in de URL (bijvoorbeeld&scope=REQUESTED_SCOPE%20REQUESTED_SCOPE_TWO%20offline_access). - Als u elke keer een nieuw token wilt genereren, voert u gewoon de URL in uw browser in.
- Kies ACCEPTEREN.
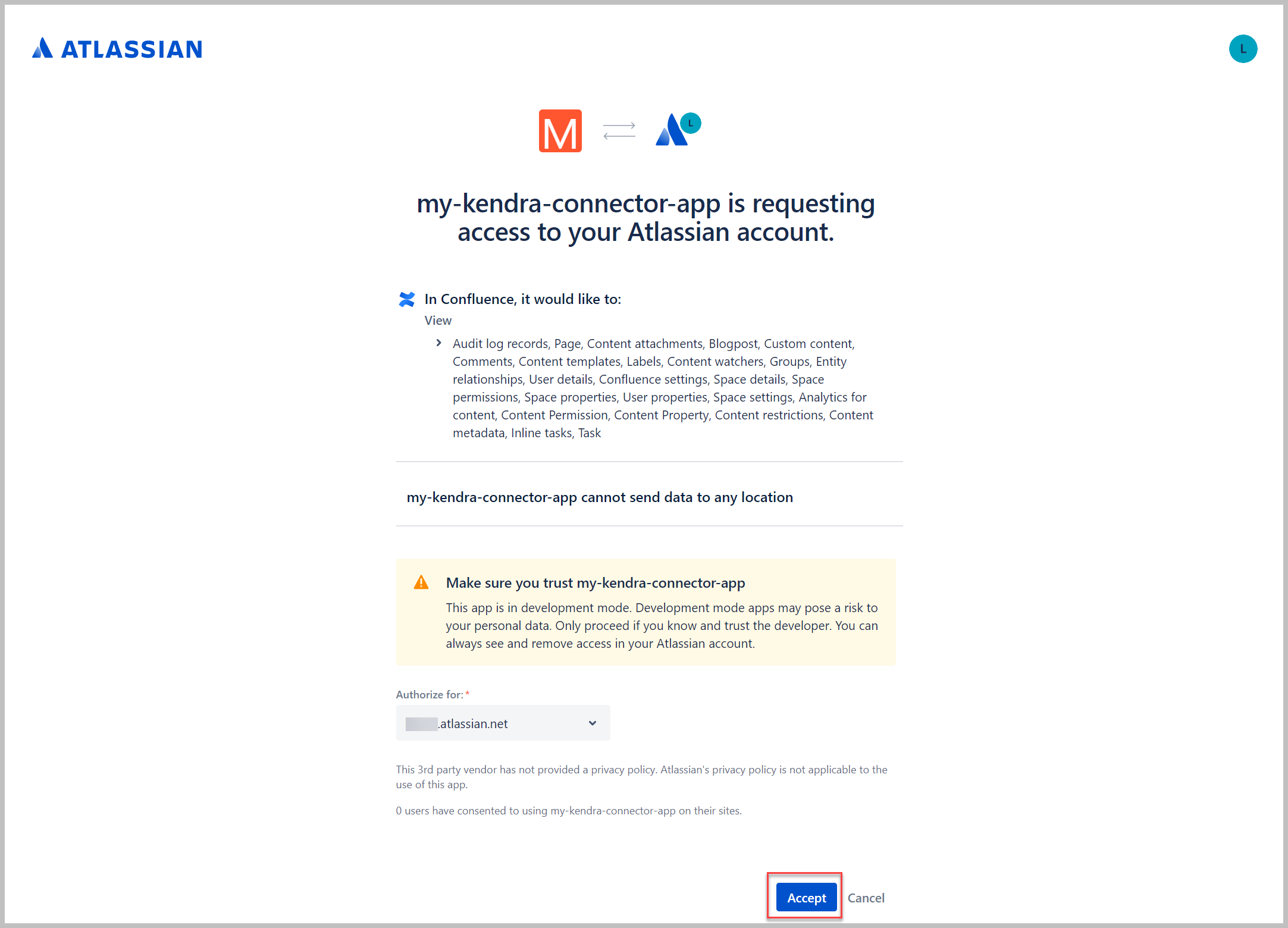
Je wordt omgeleid naar je startpagina van Confluence.
- Inspecteer de browser-URL en zoek
code=xxxxx. - Kopieer deze code en sla deze op.
Dit is de autorisatiecode die we gebruiken om uit te wisselen met het toegangstoken.

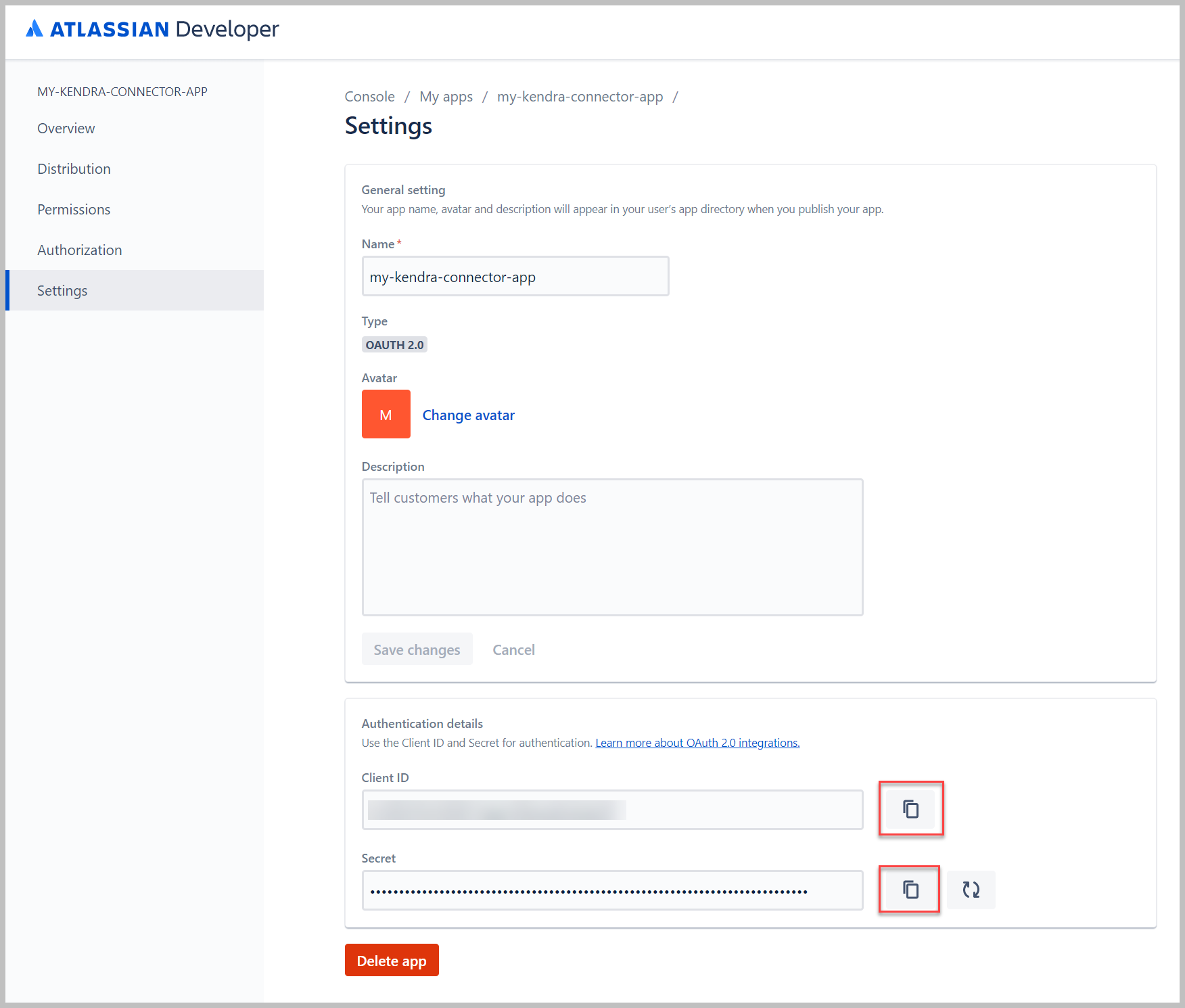
- Keer terug naar de Atlassian-ontwikkelaarsconsole en kies Instellingen in het navigatievenster.
- Kopieer de waarden van de client-ID en geheime ID en sla ze op.
We hebben deze waarden nodig om een aanroep te doen om het autorisatietoken uit te wisselen met het toegangstoken.
Vervolgens gebruiken we de Postbode hulpprogramma om de autorisatiecode te posten om het toegangstoken te krijgen. U kunt alternatieve tools gebruiken, zoals krullen om dit ook te doen.
- De URL om de autorisatiecode te plaatsen is
https://auth.atlassian.com/oauth/token. - De te posten JSON-body is als volgt:
De grant_type parameter is hard gecodeerd. We verzamelden de waarden voor client_id en client_secret in een vorige stap. De waarde voor code is de autorisatiecode die we eerder hebben verzameld.
Bij een succesvolle reactie wordt het toegangstoken geretourneerd. Als je eerder offline toegang tot de URL hebt toegevoegd, krijg je ook een vernieuwingstoken.
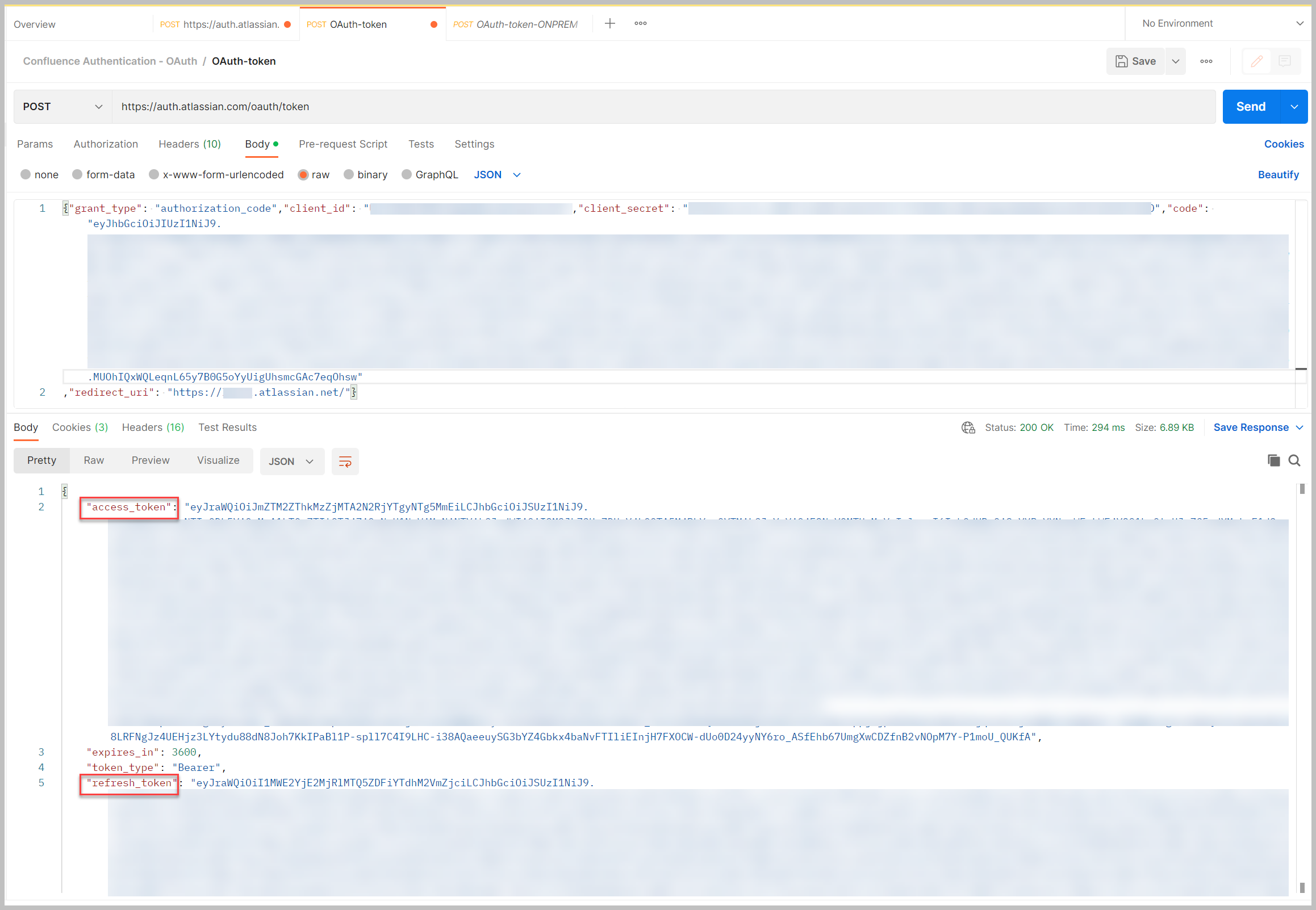
- Sla het toegangstoken op om te gebruiken bij het instellen van Secrets Manager.
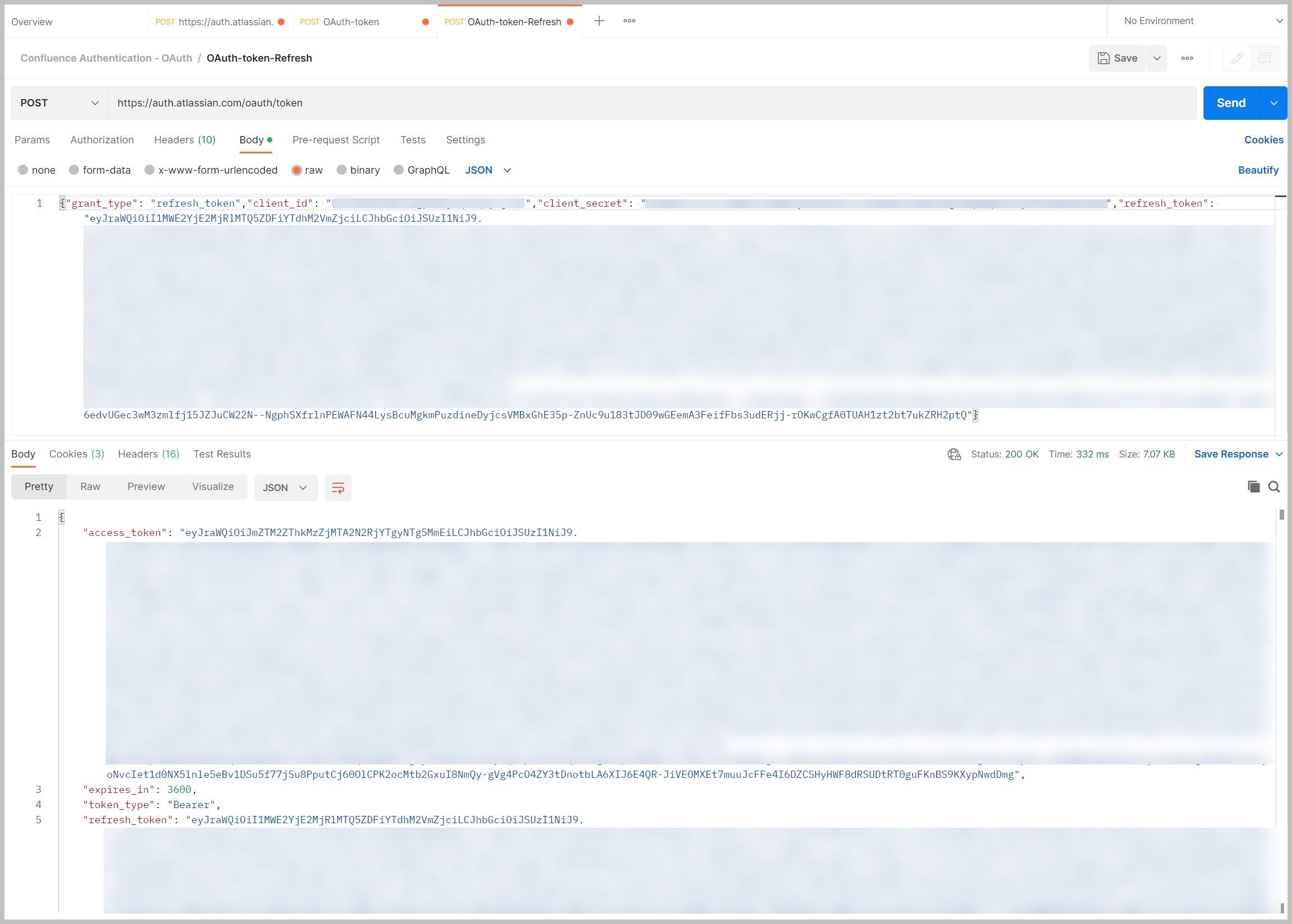
Als u een nieuw token genereert op basis van het vernieuwingstoken, is het huidige token slechts 1 uur geldig. Als je een nieuw token nodig hebt, kun je helemaal opnieuw beginnen. Als u echter het vernieuwingstoken hebt, zoals voorheen, gebruikt u Postman om naar de volgende URL te posten: https://auth.atlassian.com/oauth/token. Gebruik de volgende JSON-indeling voor de hoofdtekst van het token:
De aanroep retourneert een nieuw toegangstoken
OAuth2-authenticatie voor Confluence Data Center-editie
Als u de Data Center-editie met OAuth2-authenticatie gebruikt, voert u de volgende stappen uit:
- Log in op de Confluence Data Center-editie.
- Kies het tandwielpictogram en kies vervolgens Algemene configuratie.
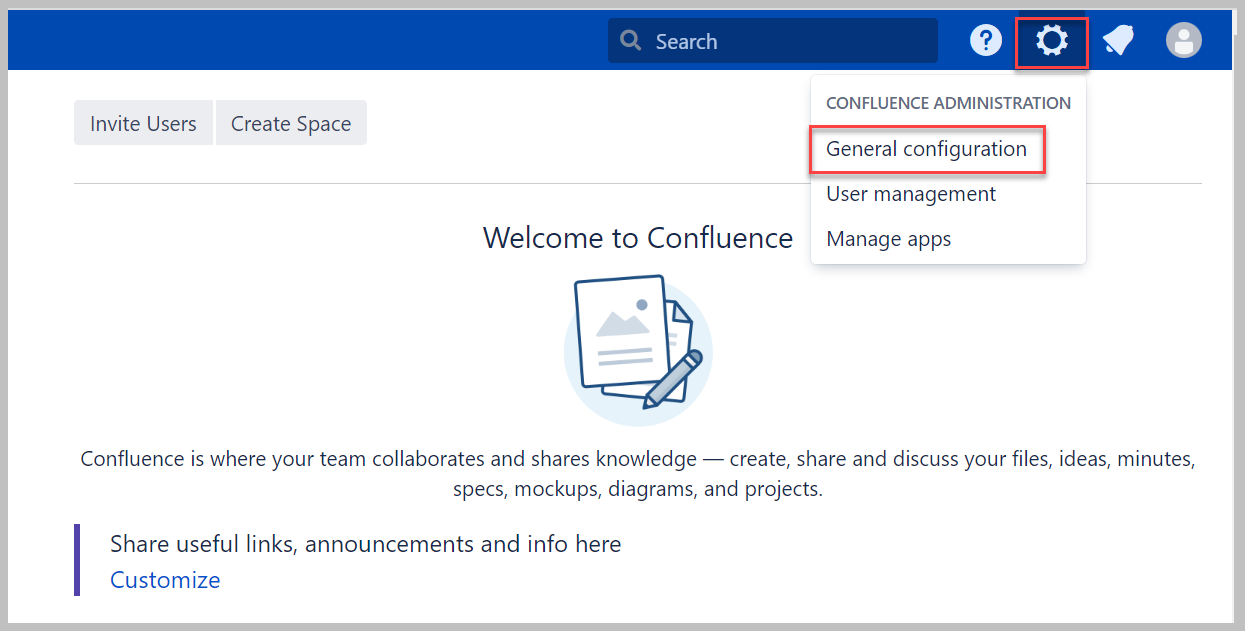
- Kies in het navigatievenster Applicatielinks, kies dan Link maken.
- In het Link maken pop-upvenster, selecteer Externe applicatie en Inkomend, kies dan voortzetten.
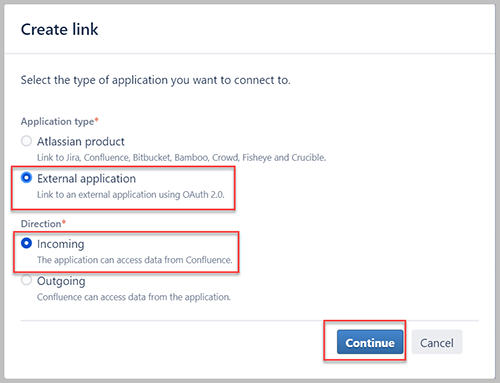
- Voor Naam, voer een naam in.
- Voor Omleidings-URL, ga naar binnen
https://httpbin.org/. - Kies Bespaar.
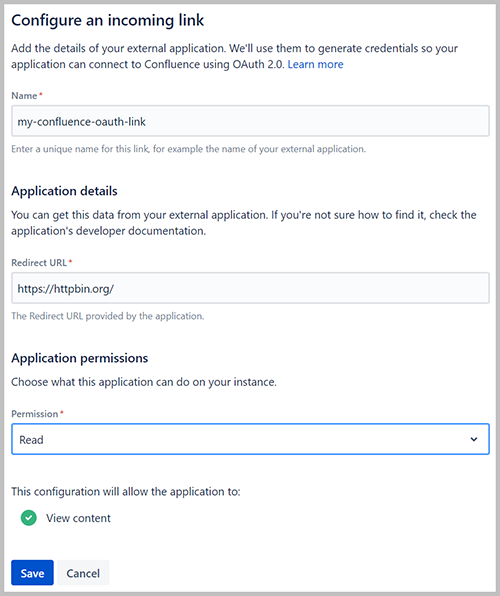
- Kopieer de waarden voor de client-ID en het clientgeheim en sla deze op.
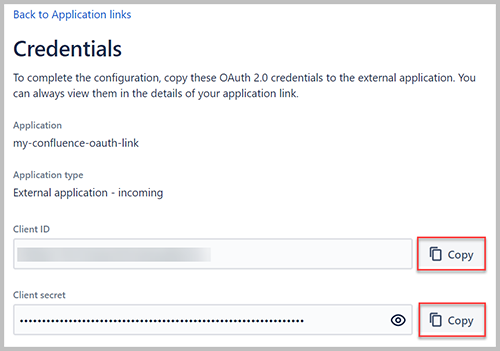
- Open de URL op een apart browsertabblad https://example-app.com/pkce.
- Kies Willekeurige reeks genereren en Hasj berekenen.
- Kopieer de waarde eronder Code-uitdaging.
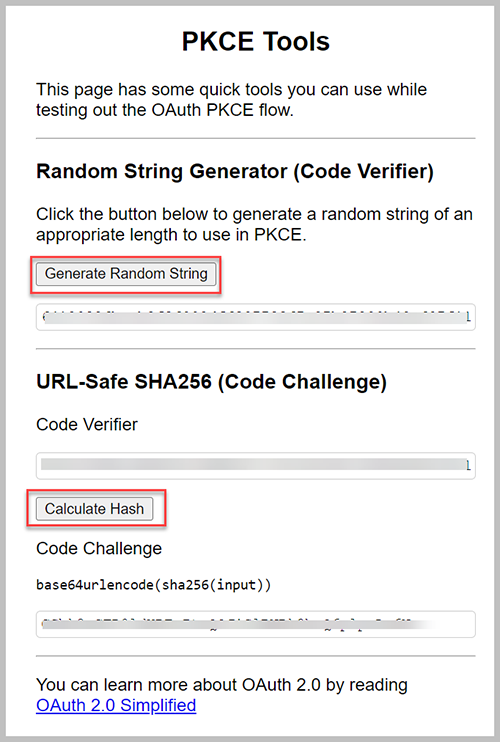
- Keer terug naar je oorspronkelijke tabblad.
- Gebruik de volgende URL om de autorisatiecode op te halen:
Gebruik de client-ID die u eerder hebt gekopieerd, en https://httpbin.org voor de omleidings-URI. Voor CODE_CHALLENGE, voer de code in die je eerder hebt gekopieerd.
- Kies Allow.

Je wordt doorverwezen naar httpbin.org.
- Sla de code op om in de volgende stap te gebruiken.

- Gebruik een tool zoals krullen or Postbode om de volgende waarden naar te posten
https://<your confluence URL>/rest/oauth2/latest/token:
Gebruik de klant-ID, het klantgeheim en de autorisatiecode die u eerder hebt opgeslagen. Voor CODE_VERIFIER, voer de waarde in vanaf het moment dat u de code-uitdaging heeft gegenereerd.
- Kopieer het toegangstoken en het vernieuwingstoken om later te gebruiken
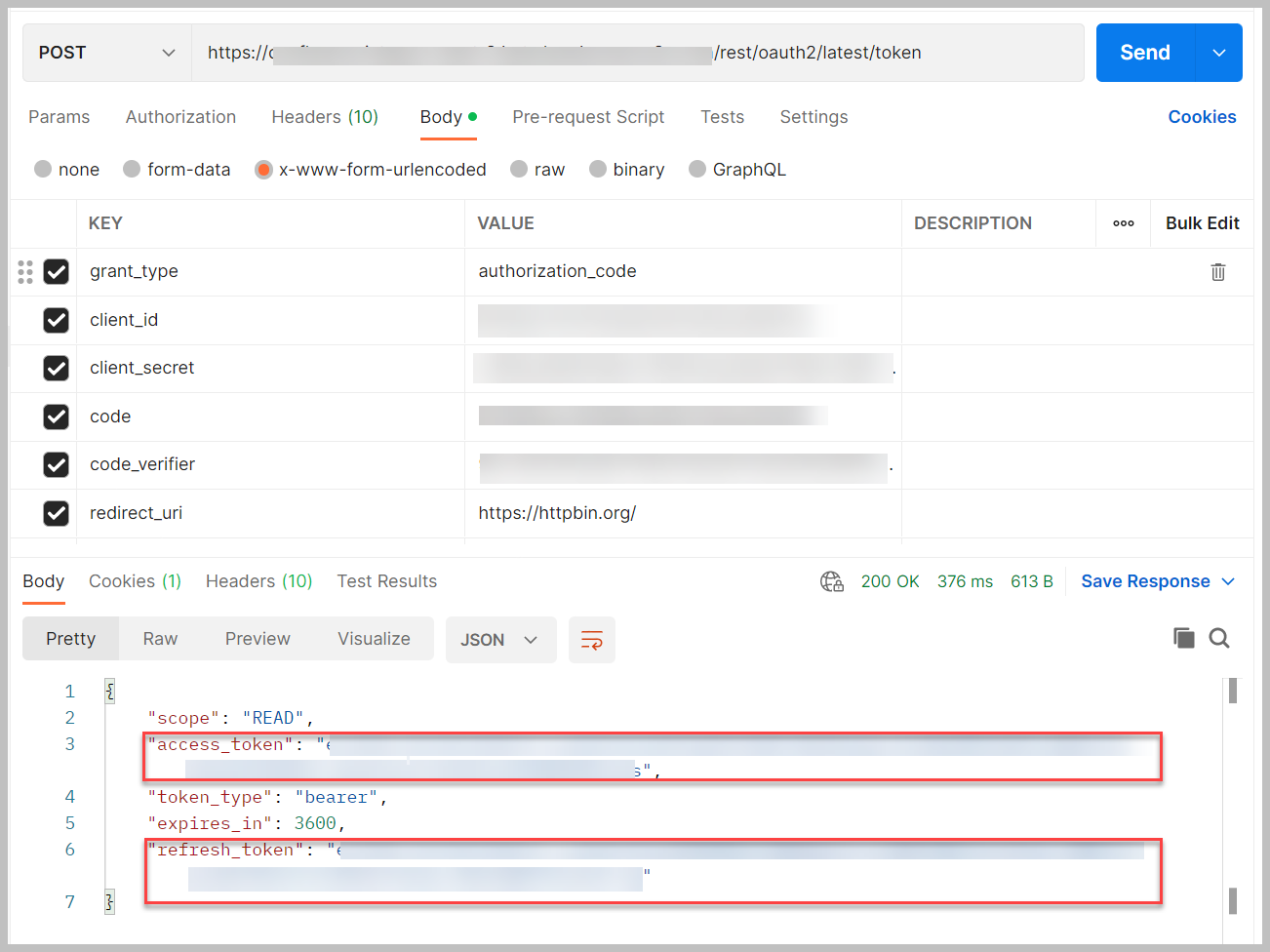
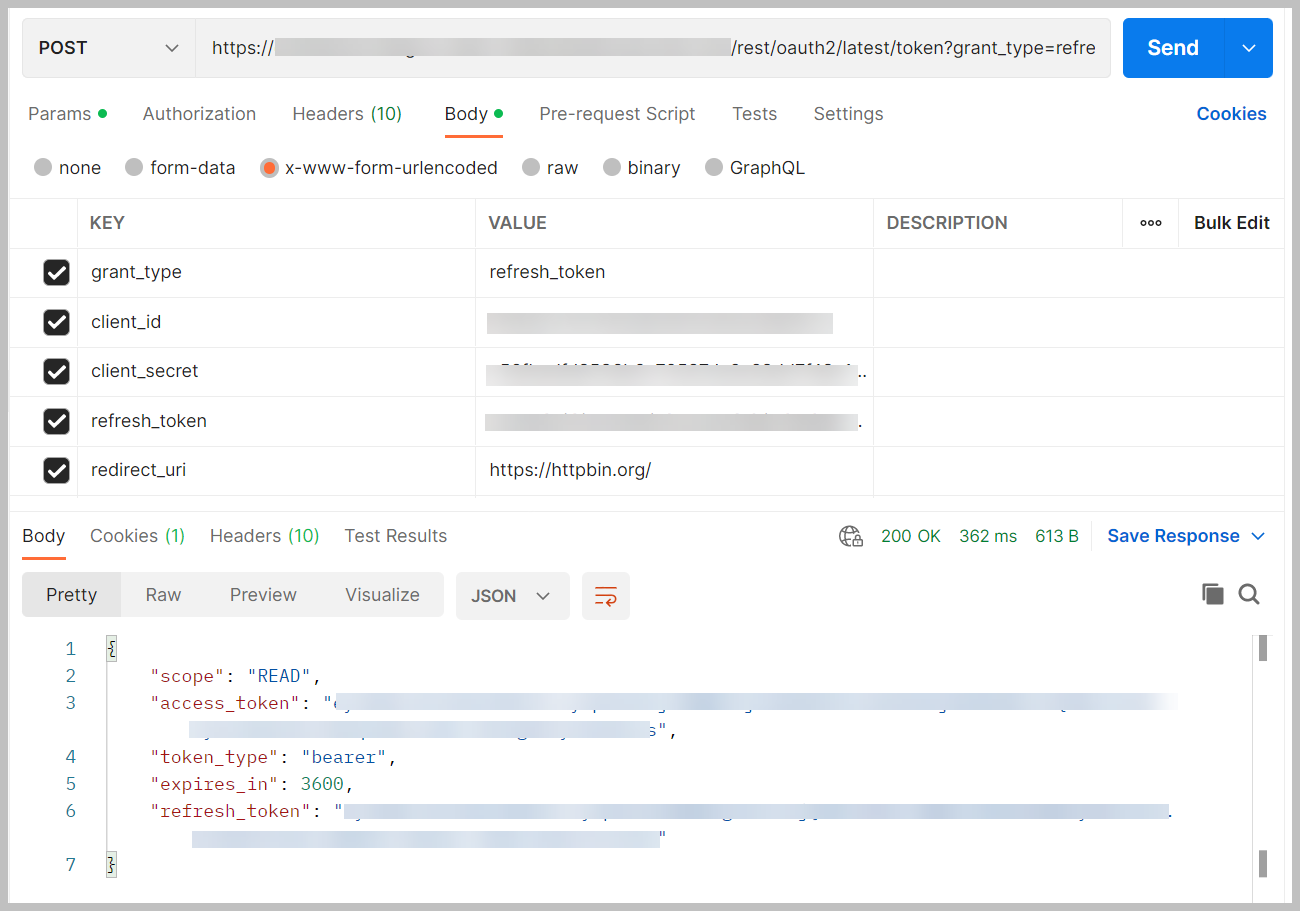
Het toegangstoken en het vernieuwingstoken zijn slechts 1 uur geldig. Om het token te vernieuwen, plaatst u de volgende code op dezelfde URL om nieuwe waarden te krijgen:
De nieuwe tokens zijn 1 uur geldig.
Bewaar Confluence-referenties in Secrets Manager
Voer de volgende stappen uit om uw Confluence-referenties op te slaan in Secrets Manager:
- Kies op de Secrets Manager-console Bewaar een nieuw geheim.
- kies Ander soort geheim.
- Voer de sleutel/waarden als volgt in, afhankelijk van het type geheim:
- Voer voor Confluence Cloud-basisauthenticatie de volgende sleutel-waardeparen in (houd er rekening mee dat het wachtwoord niet het inlogwachtwoord is, maar het token dat u eerder hebt gemaakt):
- Voer voor Confluence Cloud OAuth-authenticatie de volgende sleutel-waardeparen in:
- Voer voor de basisverificatie van Confluence Data Center de volgende sleutel-waardeparen in:
- Voer voor Confluence Data Center persoonlijke toegangstokenverificatie de volgende sleutel-waardeparen in:
- Voer voor Confluence Data Center OAuth-authenticatie de volgende sleutel-waardeparen in:
- Kies Volgende.
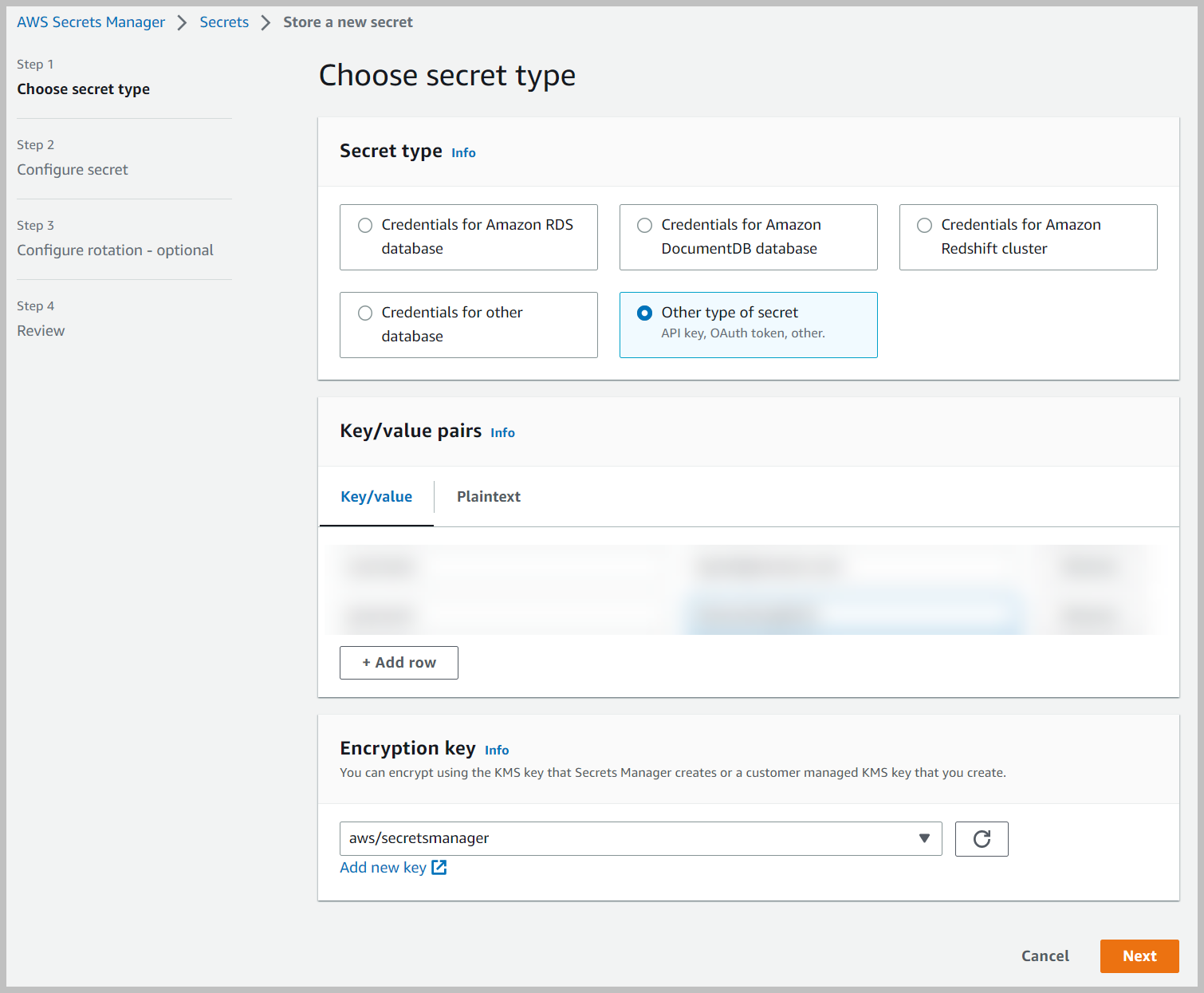
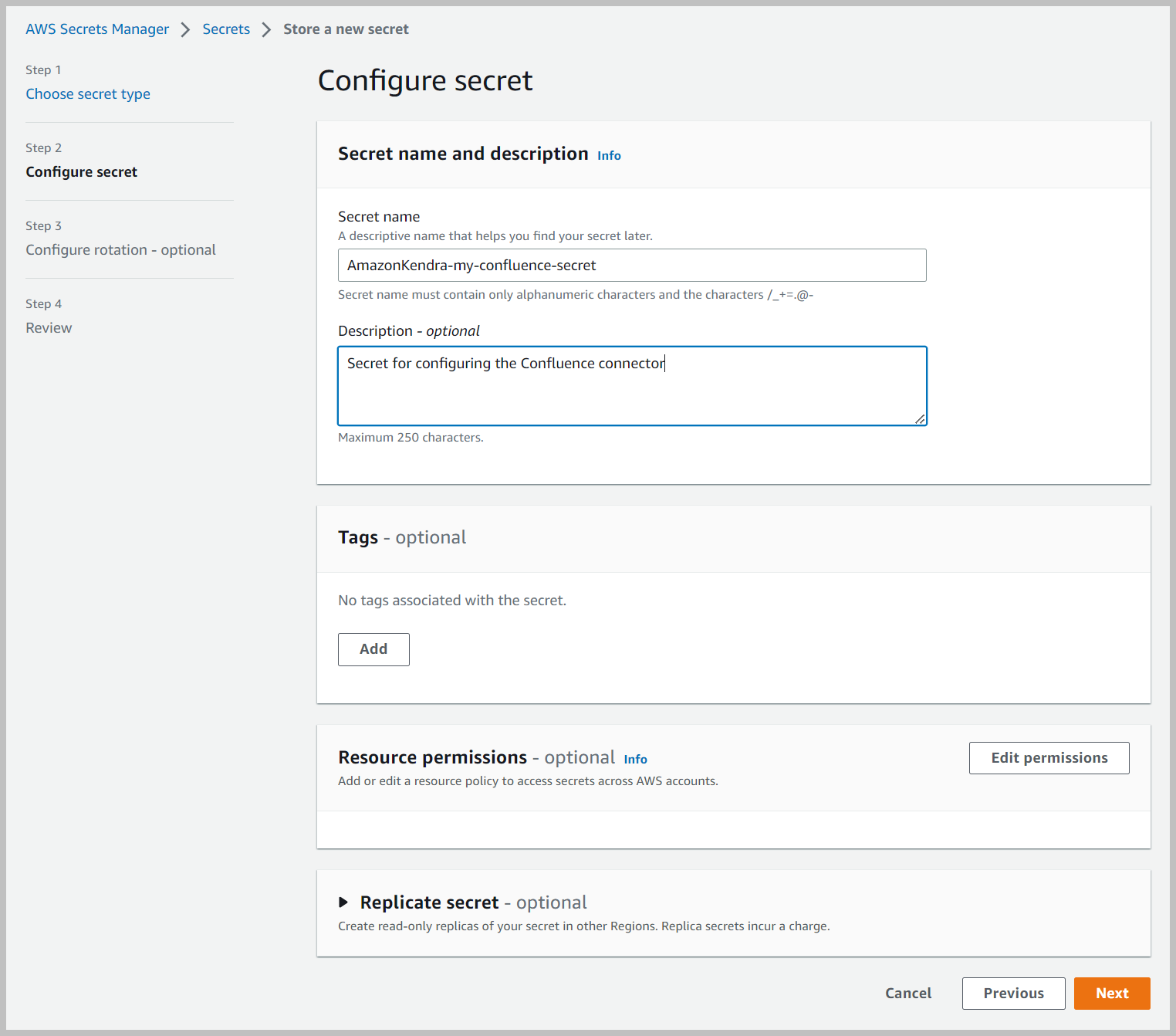
- Voor Geheime naam, voer een naam in (bijvoorbeeld
AmazonKendra-my-confluence-secret). - Voer een optionele beschrijving in.
- Kies Volgende.
- In het Rotatie configureren sectie, bewaar alle instellingen op hun standaardwaarden en kies Volgende.
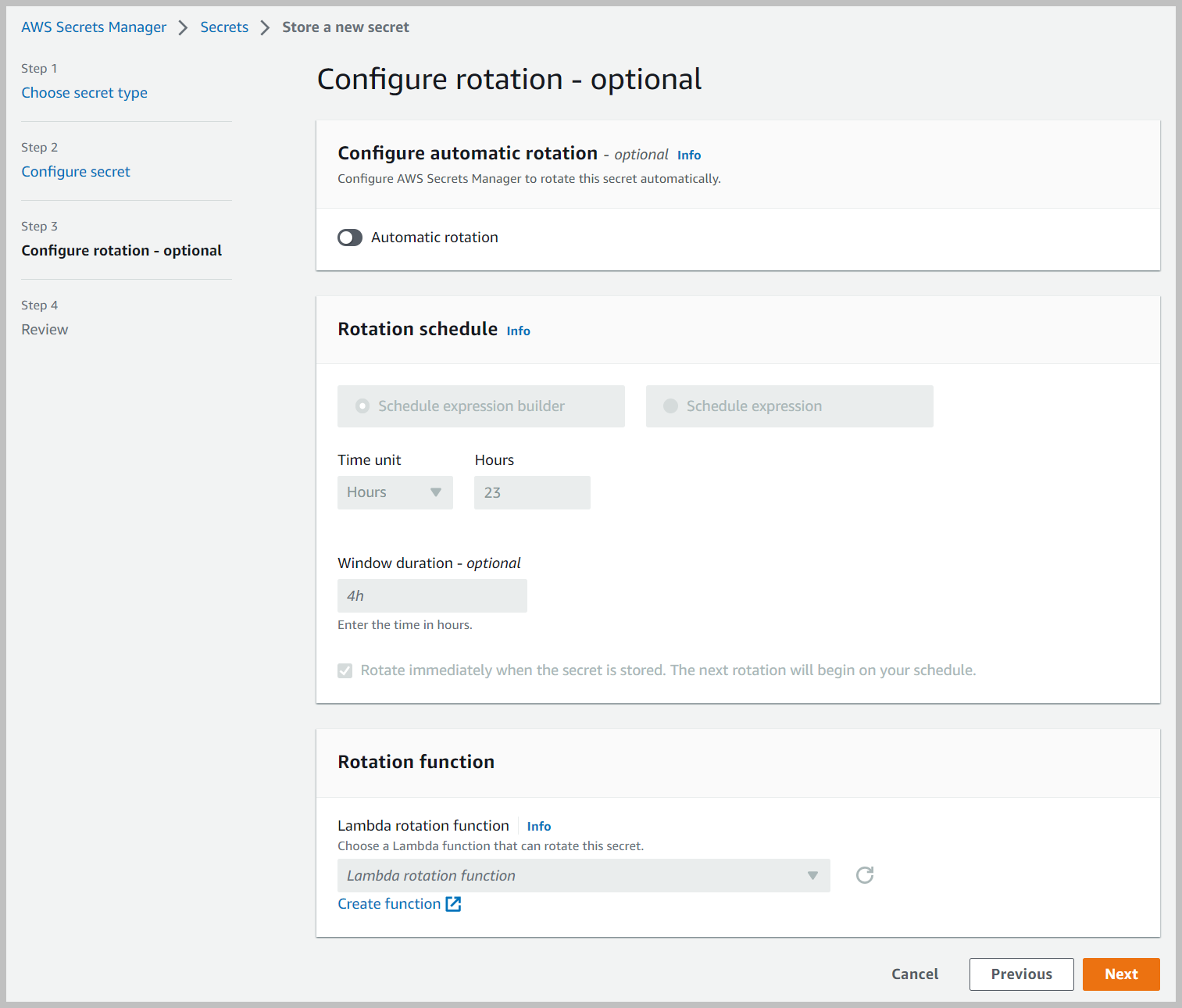
- Op de Beoordeling pagina, kies Shop.
Configureer de Amazon Kendra-connector voor Confluence
Voer de volgende stappen uit om de Amazon Kendra-connector te configureren:
- Kies op de Amazon Kendra-console Maak een index.
- Voor Indexnaam, voer een naam in voor de index (bijvoorbeeld
my-confluence-index). - Voer een optionele beschrijving in.
- Voor Rol naam, voer een IAM-rolnaam in.
- Configureer optionele coderingsinstellingen en tags.
- Kies Volgende.
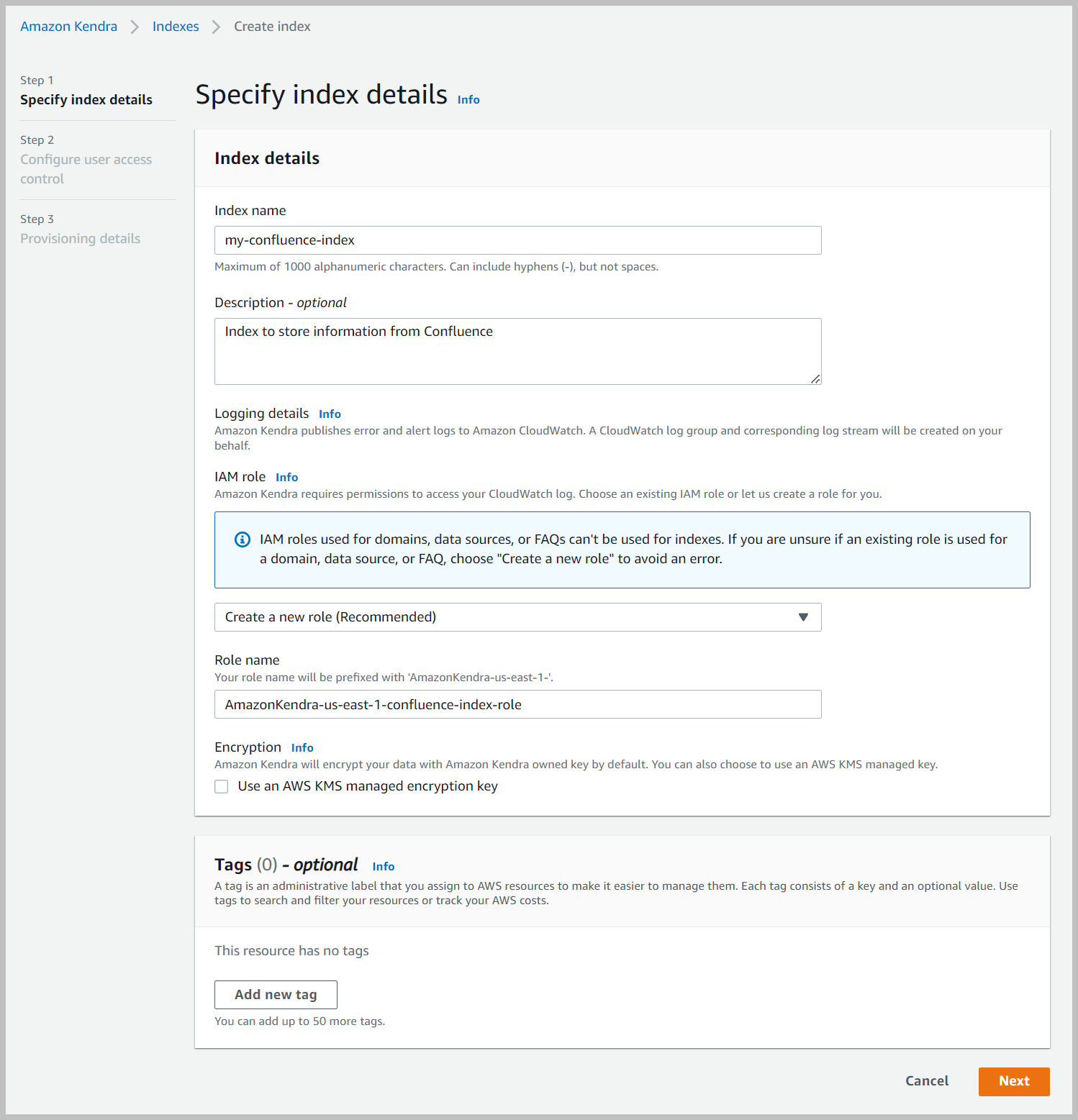
- In het Gebruikerstoegangsbeheer configureren sectie, laat de instellingen op hun standaardwaarden en kies Volgende.
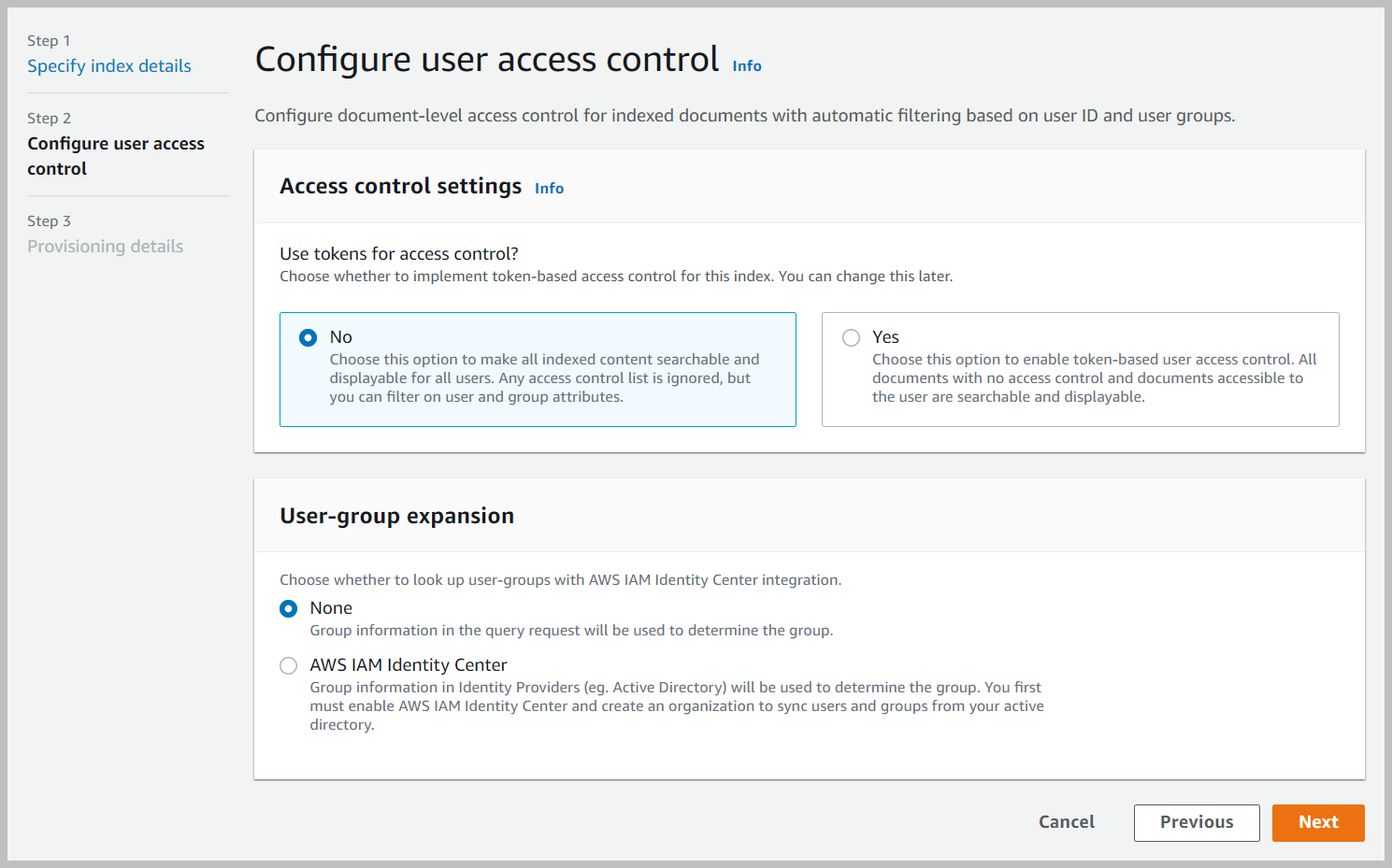
- In het Specificeer inrichting sectie, selecteer Developer-editie En kies Volgende.
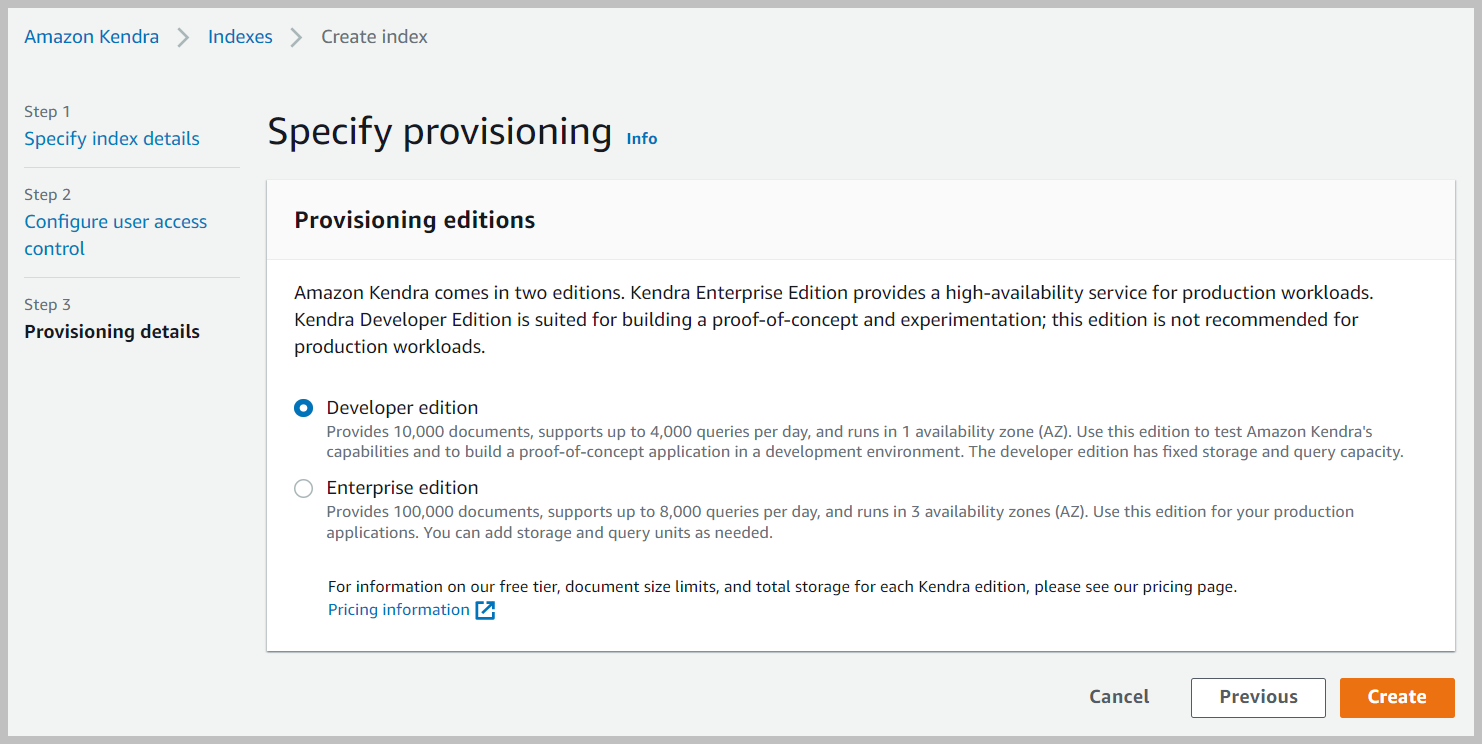
- Kies op de beoordelingspagina creëren.
Dit creëert en verspreidt de IAM-rol en creëert vervolgens de Amazon Kendra-index, wat tot 30 minuten kan duren.
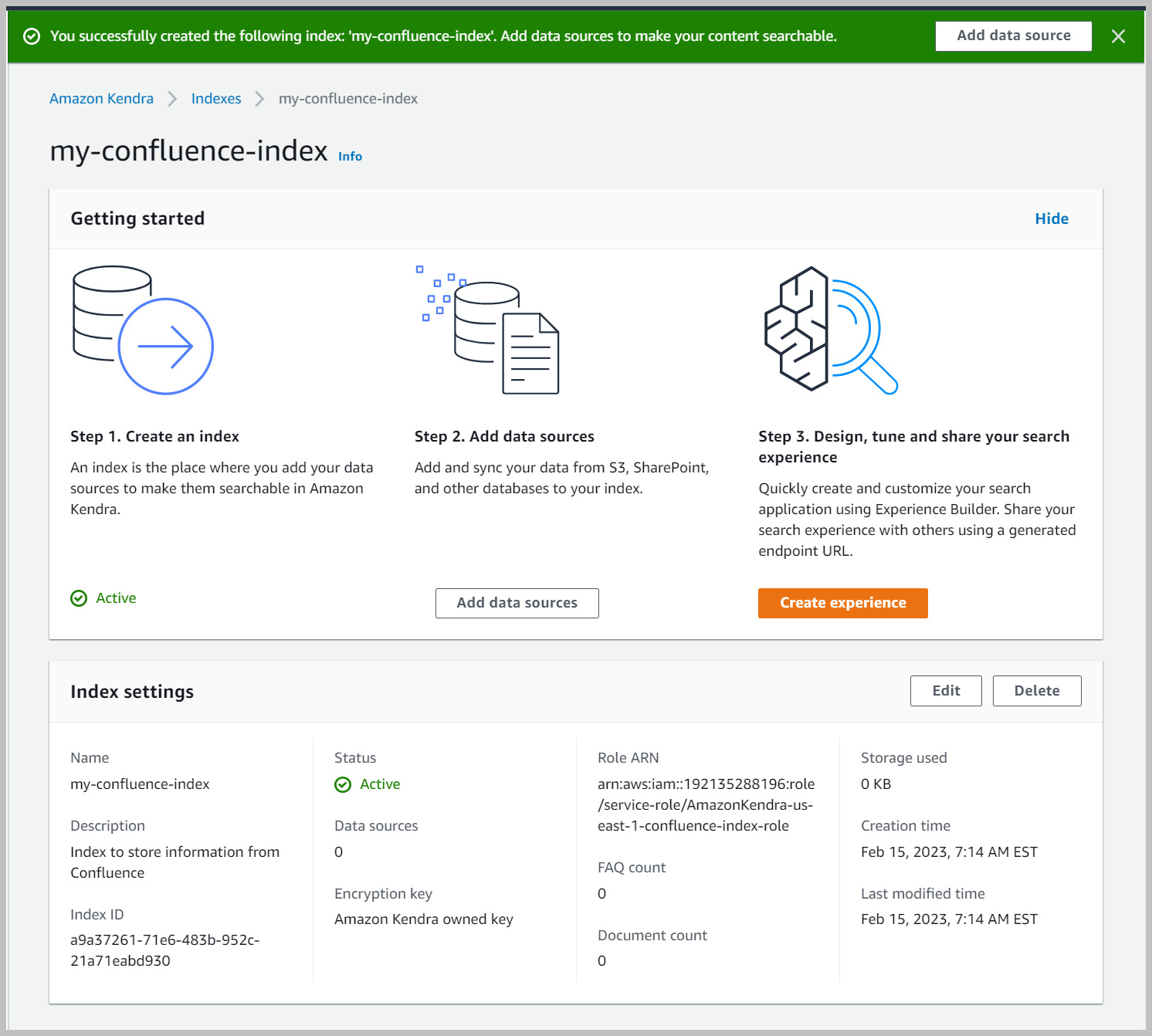
Maak een Confluence-gegevensbron
Voer de volgende stappen uit om uw gegevensbron te maken:
- Kies op de Amazon Kendra-console Data bronnen in het navigatievenster.
- Onder Confluence-connector V2.0, kiezen Connector toevoegen.
.
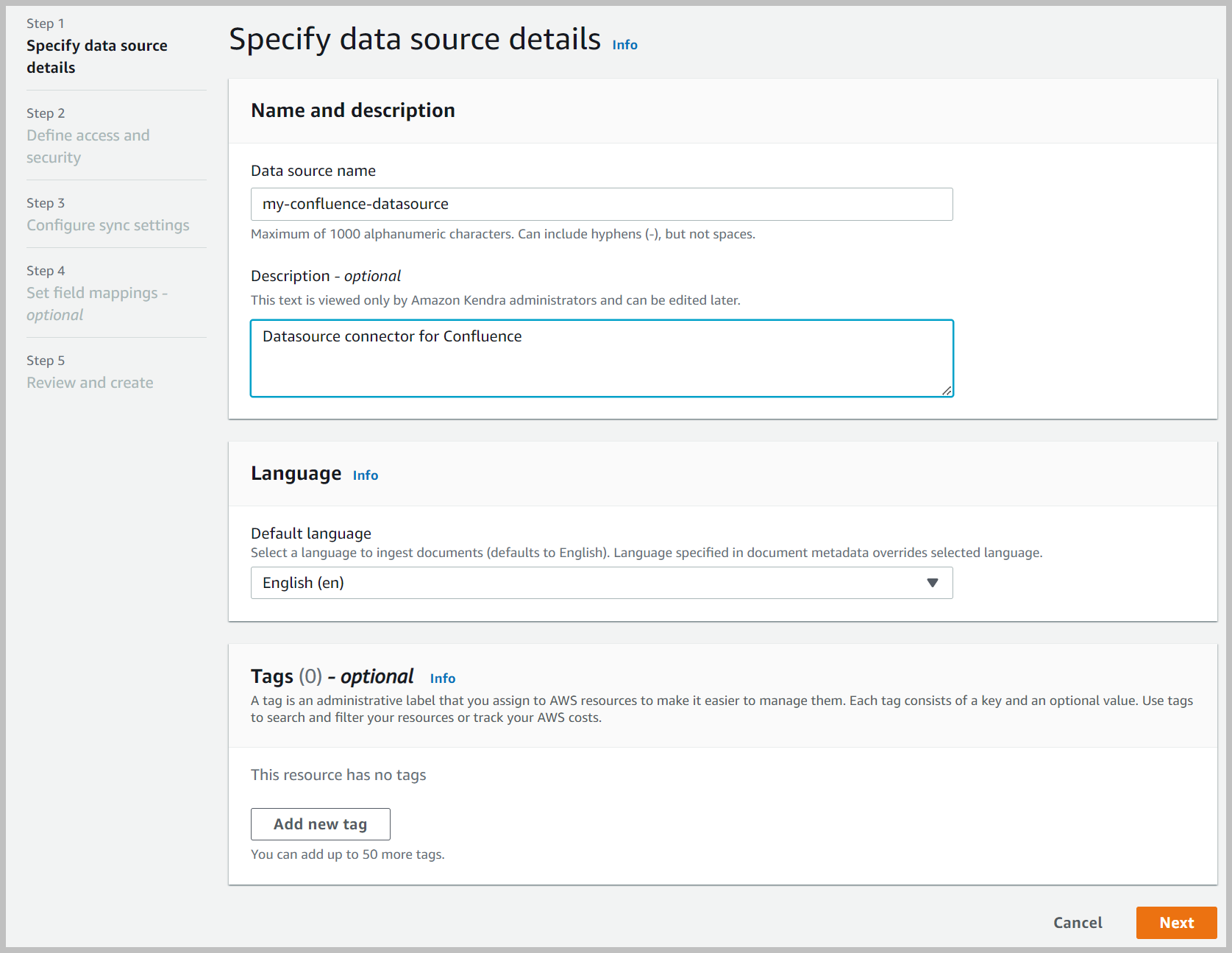
- Voor Naam gegevensbron, voer een naam in (bijvoorbeeld
my-Confluence-data-source). - Voer een optionele beschrijving in.
- Kies Volgende.
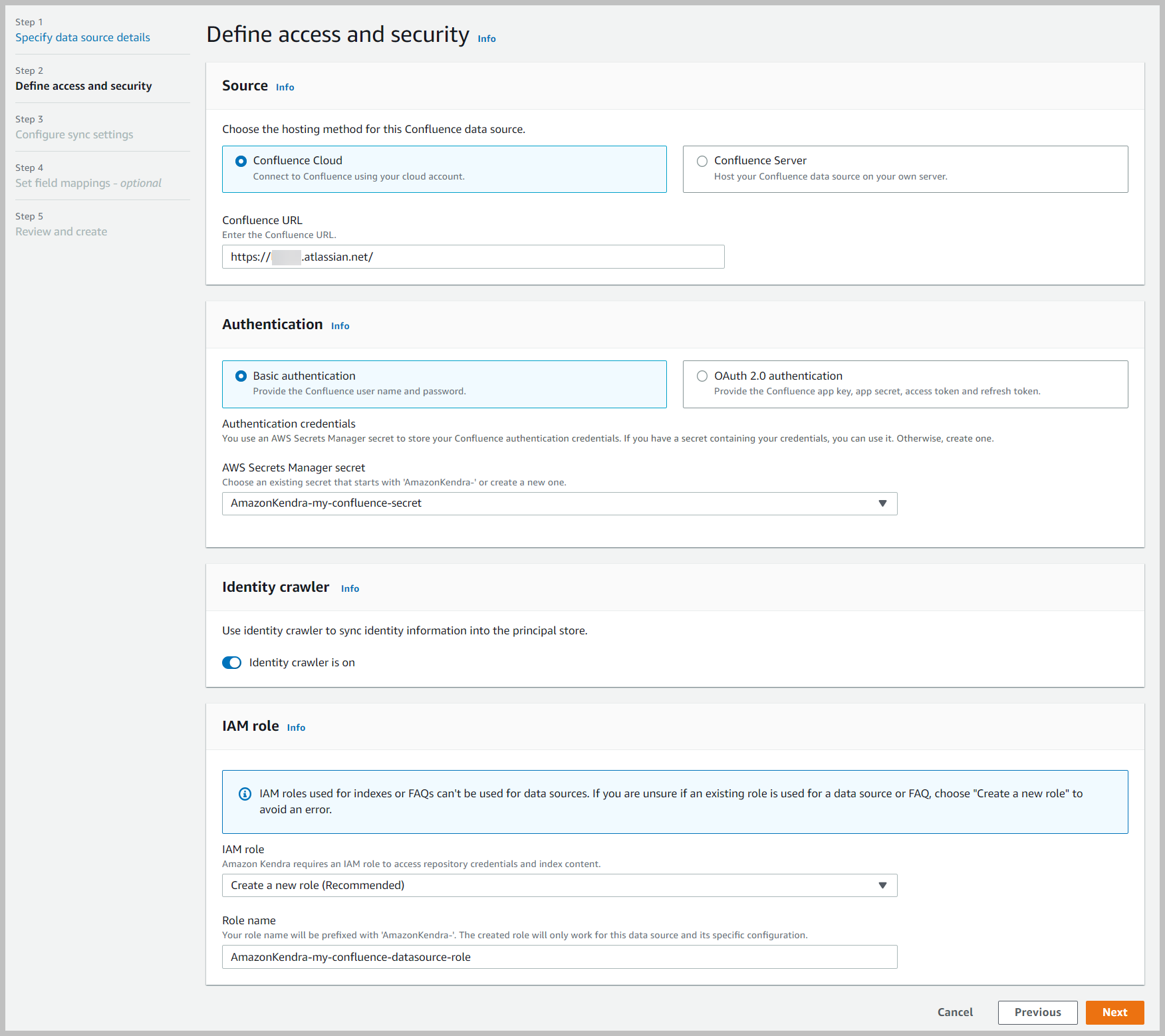
- Kies een van beide Confluence-wolk or Confluence-server afhankelijk van uw gegevensbron.
- Voor authenticatie, kies uw authenticatie-optie.
- kies Identiteitscrawler is ingeschakeld.
- Voor IAM-rolKiezen Maak een nieuwe rol.
- Voor Rol naam, voer een naam in (bijvoorbeeld
AmazonKendra-my-confluence-datasource-role). - Kies Volgende.
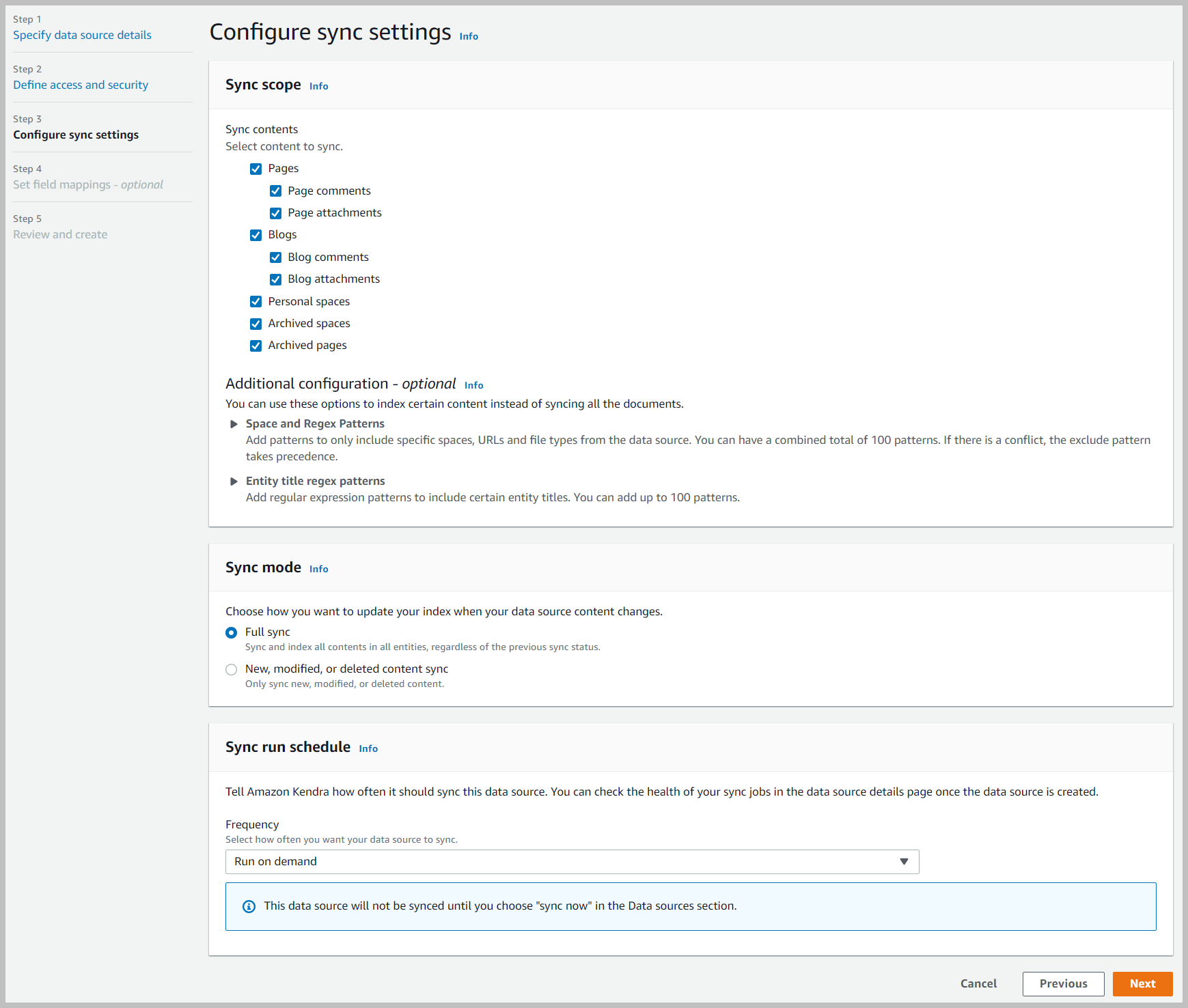
Voor Confluence Data Center- en Cloud-edities kunnen we aanvullende optionele informatie toevoegen (niet weergegeven), zoals de VPC. Alleen voor de Data Center-editie kunnen we aanvullende informatie voor de webproxy toevoegen. Er is ook een extra authenticatieoptie bij gebruik van een persoonlijk toegangstoken dat alleen geldig is voor Data Center en niet voor Cloud-editie.
- Voor Synchronisatiebereik, selecteert u alle inhoud die u wilt synchroniseren.
- Voor Synchronisatiemodusselecteer Volledige synchronisatie.
- Voor Frequentie, kiezen Rennen op aanvraag.
- Kies Volgende.
- Optioneel kunt u toewijzingsvelden instellen.
Het toewijzen van velden is een nuttige oefening waarbij u veldnamen kunt vervangen door waarden die gebruiksvriendelijk zijn en passen in het vocabulaire van uw organisatie.
- Bewaar voor dit bericht alle standaardinstellingen en kies Volgende.
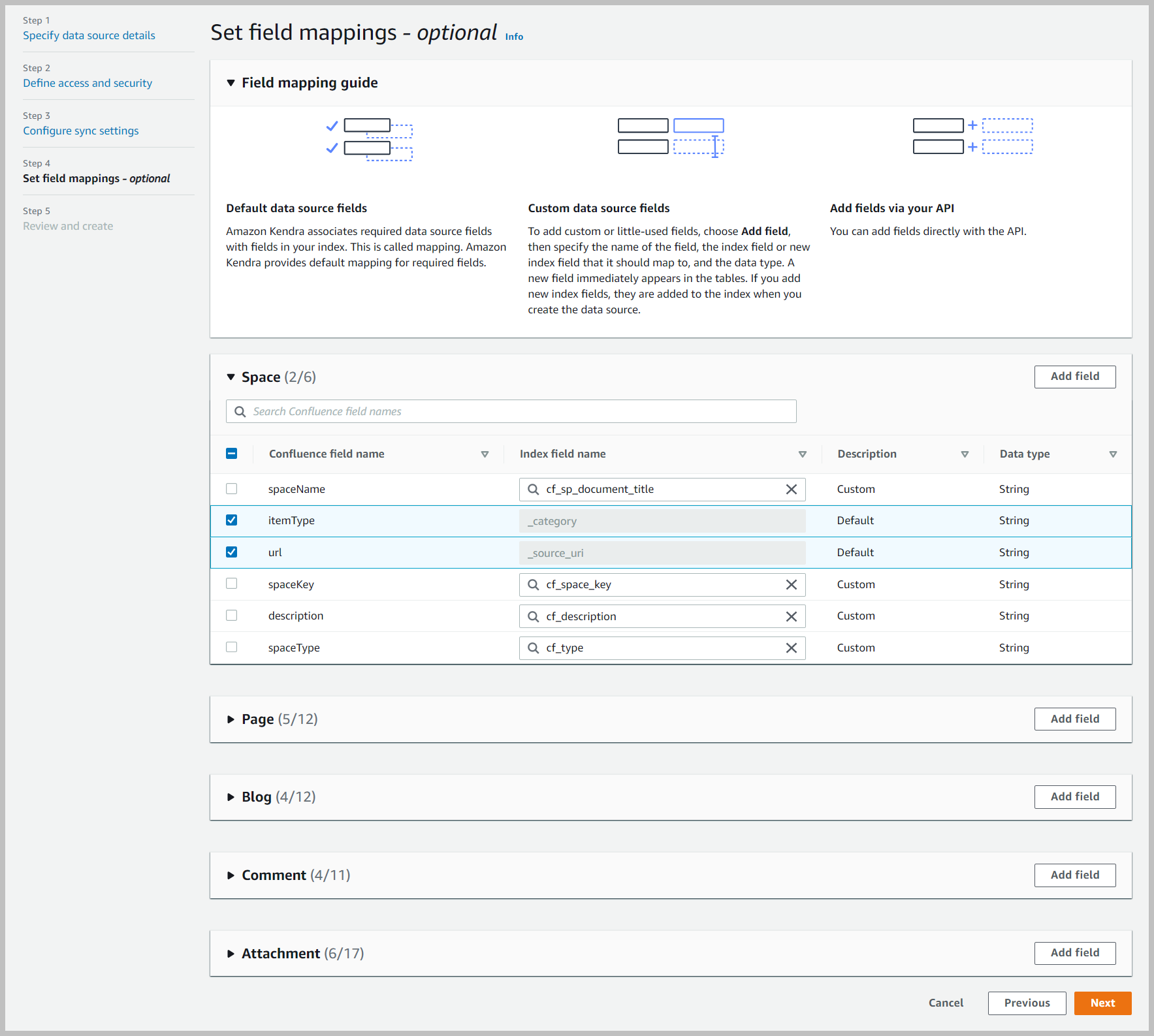
- Bekijk de instellingen en kies Gegevensbron toevoegen.
- Kies om de gegevensbron te synchroniseren Synchroniseer nu.
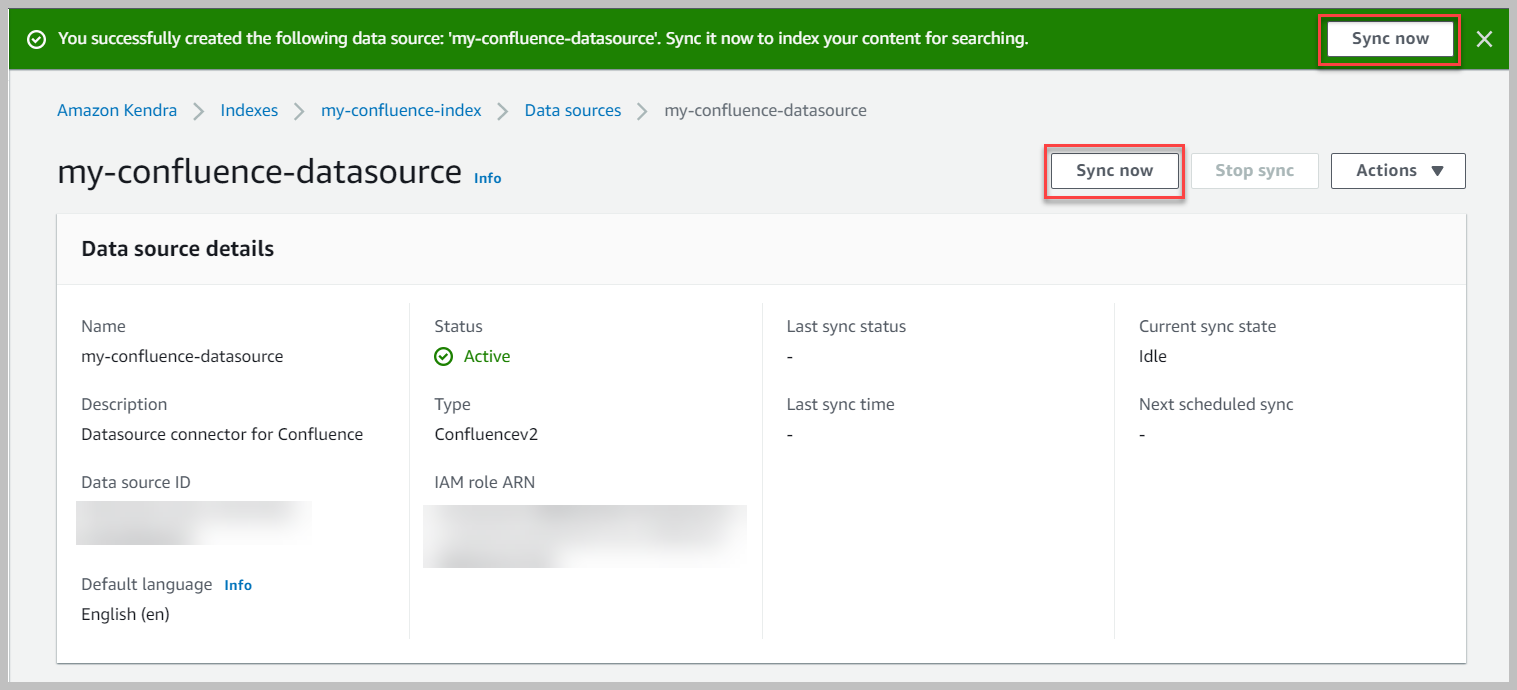
Er verschijnt een bannerbericht wanneer de synchronisatie is voltooid.
Test de oplossing
Nu je de inhoud van je Confluence-account hebt opgenomen in je Amazon Kendra-index, kun je enkele vragen testen. Voor onze test hebben we een Confluence-website gemaakt met twee teams: team1 met het lid Analyst1 en team2 met het lid Analyst2.
- Navigeer op de Amazon Kendra-console naar uw index en kies Doorzoek geïndexeerde inhoud.
- Voer een voorbeeldzoekopdracht in en bekijk uw zoekresultaten (uw resultaten variëren op basis van de inhoud van uw account).
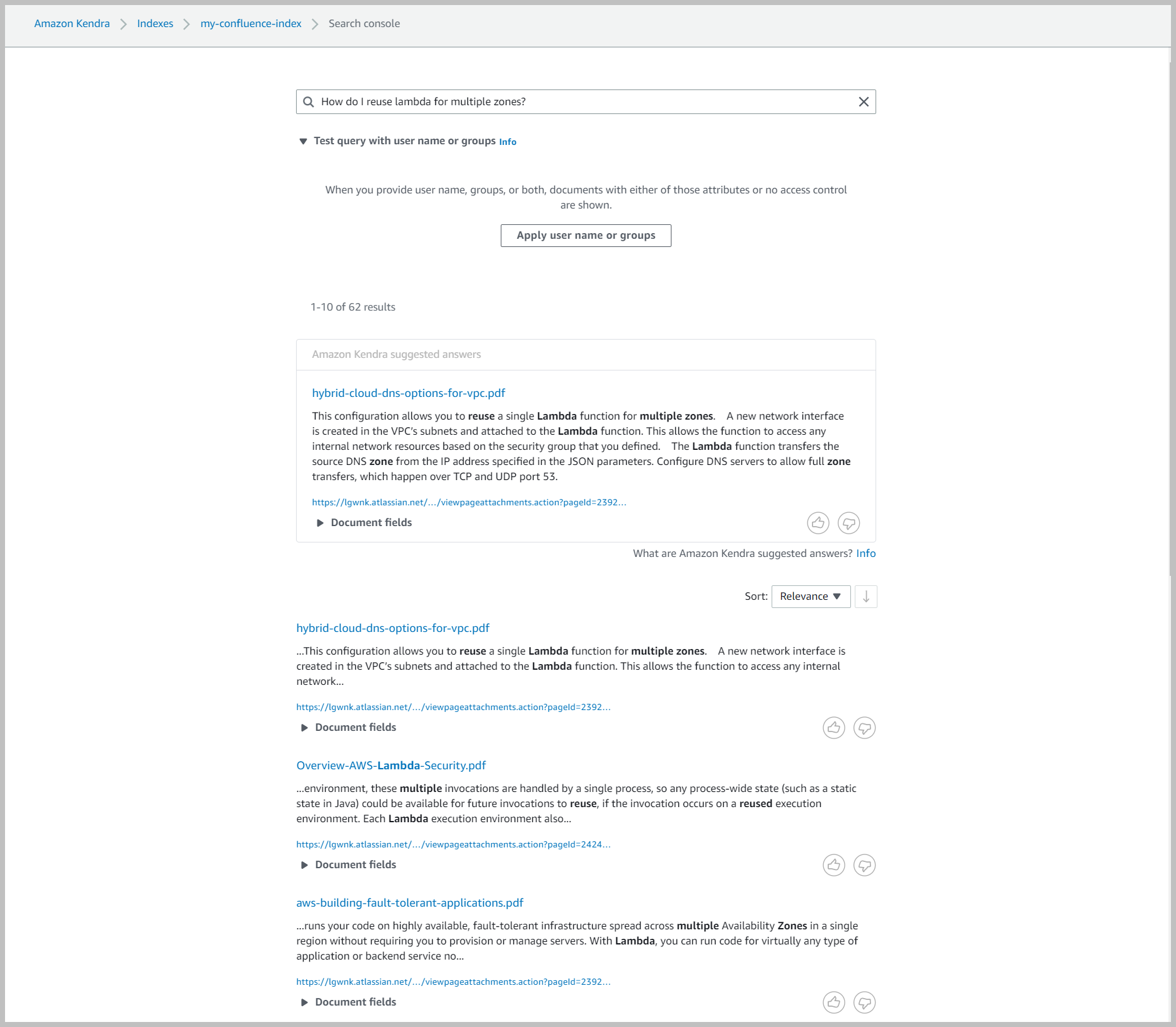
De Confluence-connector crawlt ook lokale identiteitsgegevens van Confluence. U kunt deze functie gebruiken om uw zoekopdracht per gebruiker te verfijnen. Confluence biedt uitgebreide zichtbaarheidsopties. Gebruikers kunnen ervoor kiezen hun inhoud te laten zien door andere gebruikers, op ruimteniveau of door groepen. Wanneer u uw zoekopdrachten filtert op gebruikers, retourneert de query alleen die documenten waartoe de gebruiker toegang heeft op het moment van opname.
- Vouw uit om deze functie te gebruiken Testquery met gebruikersnaam of groepen En kies Gebruikersnaam of groepen toepassen.
- Voer de gebruikersnaam van uw gebruiker in en kies Solliciteer.
Houd er rekening mee dat voor de Confluence Data Center-editie de gebruikersnaam de e-mail-ID is.
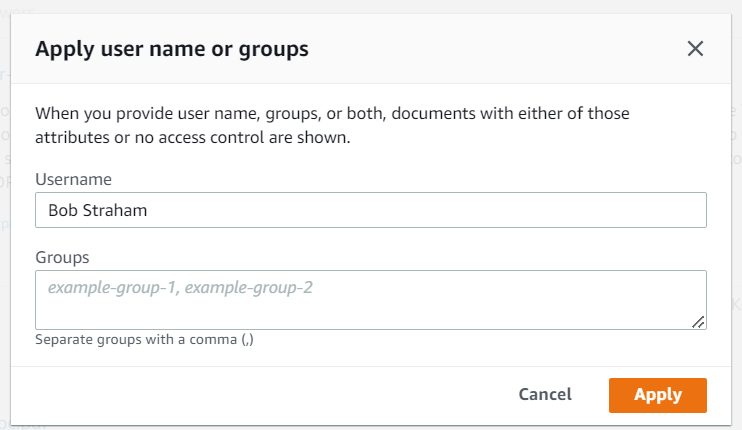
Voer uw zoekopdracht opnieuw uit.
Dit levert u een gefilterde reeks resultaten op. Merk op dat we slechts 62 resultaten terugbrengen.
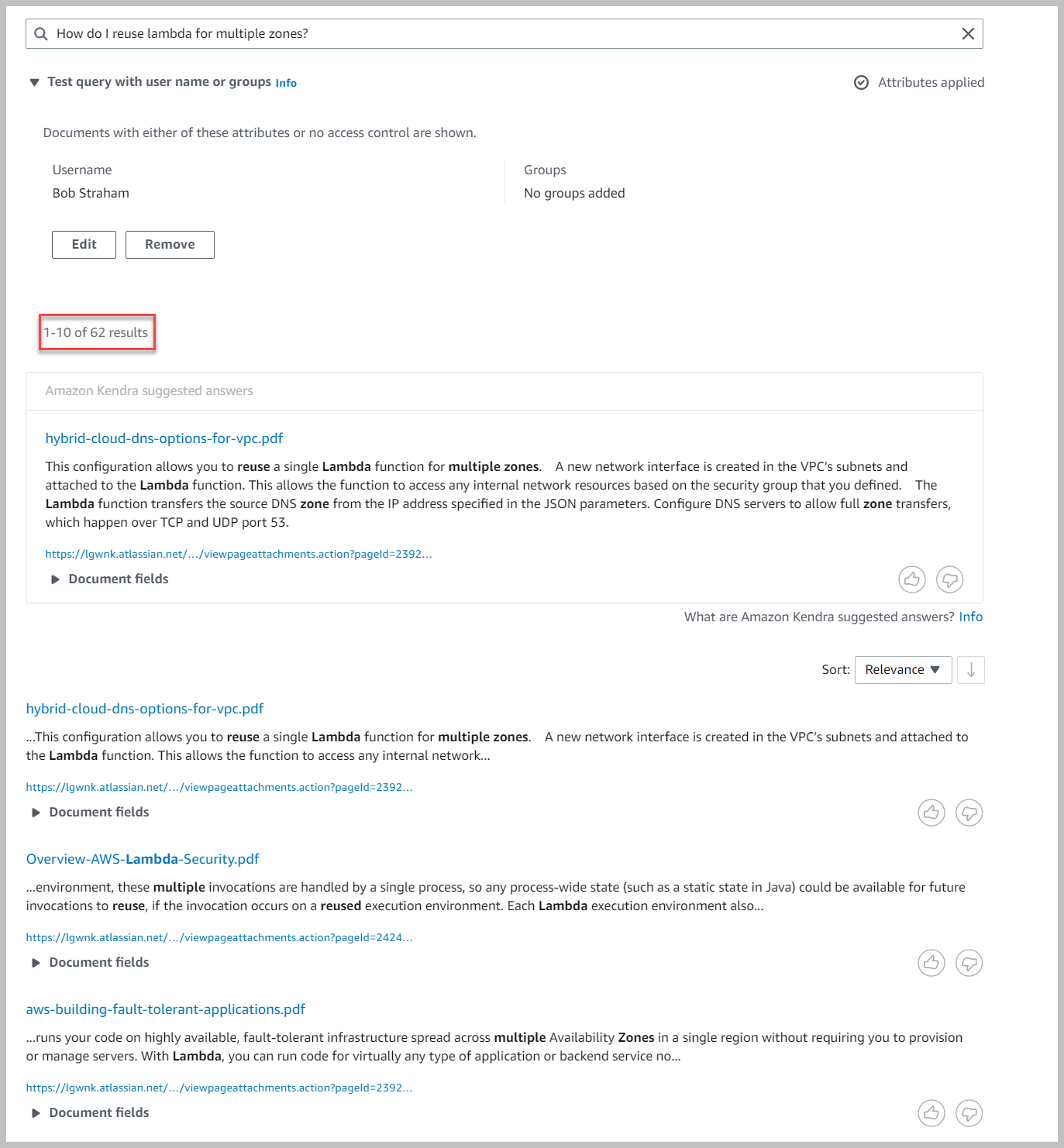
We gaan nu terug en beperken Bob Straham om alleen toegang te krijgen tot zijn werkruimte en de zoekopdracht opnieuw uit te voeren.
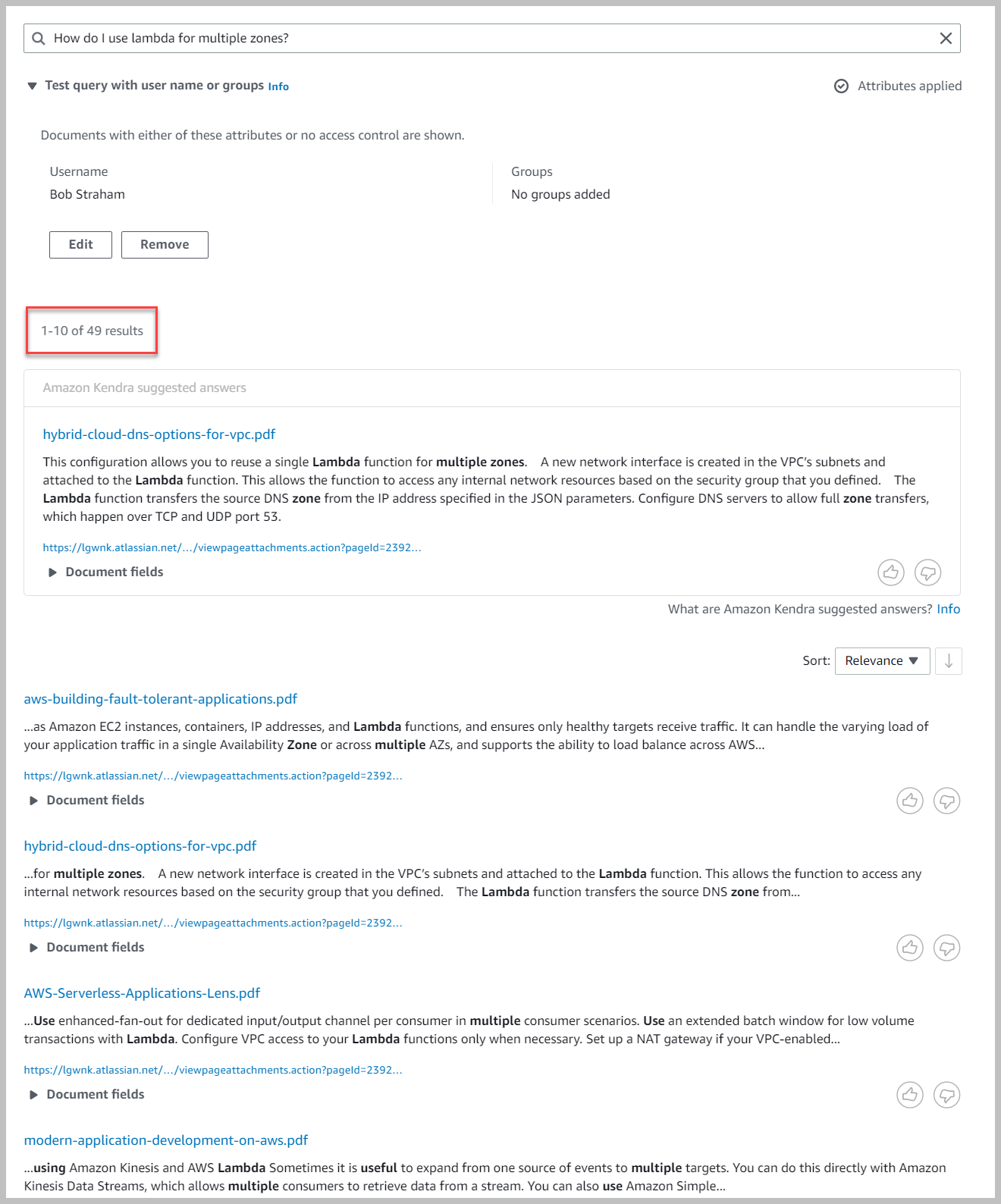
Merk op dat we slechts een subset van de resultaten krijgen omdat de zoekopdracht beperkt is tot alleen de inhoud van Bob.
Wanneer je Amazon Kendra confronteert met een applicatie zoals een applicatie die is gebouwd met behulp van Ervaringsbouwer, kunt u de gebruikersidentiteit (in de vorm van de e-mail-ID voor Cloud-editie of gebruikersnaam voor Data Center-editie) doorgeven aan Amazon Kendra om ervoor te zorgen dat elke gebruiker alleen inhoud ziet die specifiek is voor zijn gebruikers-ID. Als alternatief kunt u gebruiken AWS IAM Identiteitscentrum (opvolger van AWS Single Sign-On) om gebruikerscontext te controleren die wordt doorgegeven aan Amazon Kendra om zoekopdrachten per gebruiker te beperken.
Gefeliciteerd! Je hebt met succes Amazon Kendra gebruikt om antwoorden en inzichten naar boven te halen op basis van de inhoud die is geïndexeerd vanuit je Confluence-account.
Opruimen
Om toekomstige kosten te voorkomen, ruimt u de resources op die u als onderdeel van deze oplossing hebt gemaakt. Als u tijdens het testen van deze oplossing een nieuwe Amazon Kendra-index hebt gemaakt, verwijdert u deze. Als u alleen een nieuwe gegevensbron hebt toegevoegd met behulp van de Amazon Kendra-connector voor Confluence V2, verwijdert u die gegevensbron.
Conclusie
Met de nieuwe Confluence-connector V2 voor Amazon Kendra kunnen organisaties gebruikmaken van de opslagplaats van informatie die veilig in hun account is opgeslagen met behulp van intelligent zoeken mogelijk gemaakt door Amazon Kendra.
Raadpleeg voor meer informatie over deze mogelijkheden en meer de Amazon Kendra-ontwikkelaarsgids. Raadpleeg voor meer informatie over hoe je metadata en inhoud kunt maken, wijzigen of verwijderen bij het opnemen van je gegevens van Confluence Uw documenten verrijken tijdens inname en Verrijk uw inhoud en metadata om uw zoekervaring te verbeteren met aangepaste documentverrijking in Amazon Kendra.
Over de auteur
 Ashish Lagwankar is Senior Enterprise Solutions Architect bij AWS. Zijn belangrijkste interesses zijn AI/ML, serverloze en containertechnologieën. Ashish is gevestigd in de omgeving van Boston, MA en houdt van lezen, buitenshuis en tijd doorbrengen met zijn gezin.
Ashish Lagwankar is Senior Enterprise Solutions Architect bij AWS. Zijn belangrijkste interesses zijn AI/ML, serverloze en containertechnologieën. Ashish is gevestigd in de omgeving van Boston, MA en houdt van lezen, buitenshuis en tijd doorbrengen met zijn gezin.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/index-your-confluence-content-using-the-new-confluence-connector-v2-for-amazon-kendra/

