ONX(Neurale netwerkuitwisseling openen) is een open-sourcestandaard voor het weergeven van deep learning-modellen die breed worden ondersteund door veel providers. ONNX biedt tools voor het optimaliseren en kwantiseren van modellen om het geheugen en de rekenkracht te verminderen die nodig is om machine learning (ML)-modellen uit te voeren. Een van de grootste voordelen van ONNX is dat het een gestandaardiseerd formaat biedt voor het weergeven en uitwisselen van ML-modellen tussen verschillende frameworks en tools. Hierdoor kunnen ontwikkelaars hun modellen in het ene framework trainen en in een ander framework implementeren zonder uitgebreide modelconversie of hertraining. Om deze redenen is ONNX aanzienlijk belangrijker geworden in de ML-gemeenschap.
In dit bericht laten we zien hoe u op ONNX gebaseerde modellen kunt implementeren voor multi-model endpoints (MME's) die GPU's gebruiken. Dit is een vervolg op het bericht Voer meerdere deep learning-modellen uit op GPU met Amazon SageMaker multi-model endpoints, waar we lieten zien hoe PyTorch- en TensorRT-versies van ResNet50-modellen op de Triton Inference-server van Nvidia kunnen worden geïmplementeerd. In dit bericht gebruiken we hetzelfde ResNet50-model in ONNX-indeling, samen met een aanvullend voorbeeldmodel voor natuurlijke taalverwerking (NLP) in ONNX-indeling om te laten zien hoe het op Triton kan worden ingezet. Verder benchmarken we het ResNet50-model en zien we de prestatievoordelen die ONNX biedt in vergelijking met PyTorch- en TensorRT-versies van hetzelfde model, met dezelfde input.

ONNX-looptijd
ONNX-looptijd is een runtime-engine voor ML-inferentie die is ontworpen om de prestaties van modellen op meerdere hardwareplatforms, waaronder CPU's en GPU's, te optimaliseren. Het maakt het gebruik van ML-frameworks zoals PyTorch en TensorFlow mogelijk. Het vergemakkelijkt prestatieafstemming om modellen kostenefficiënt op de doelhardware uit te voeren en heeft ondersteuning voor functies zoals kwantisering en hardwareversnelling, waardoor het een van de ideale keuzes is voor het implementeren van efficiënte, krachtige ML-applicaties. Voor voorbeelden van hoe ONNX-modellen kunnen worden geoptimaliseerd voor Nvidia GPU's met TensorRT, zie TensorRT-optimalisatie (ORT-TRT) en ONNX Runtime met TensorRT-optimalisatie.
De Amazon Sage Maker Triton-container stroom is weergegeven in het volgende diagram.

Gebruikers kunnen een HTTPS-verzoek verzenden met de input-payload voor real-time gevolgtrekking achter een SageMaker-eindpunt. De gebruiker kan een TargetModel header die de naam bevat van het model dat het verzoek in kwestie moet aanroepen. Intern implementeert de SageMaker Triton-container een HTTP-server met dezelfde contracten als vermeld in Hoe containers dienen voor verzoeken. Het heeft ondersteuning voor dynamische batching en ondersteunt alle backends die Triton levert. Op basis van de configuratie wordt de ONNX-runtime aangeroepen en wordt het verzoek verwerkt op de CPU of GPU zoals vooraf gedefinieerd in de modelconfiguratie die door de gebruiker is opgegeven.
Overzicht oplossingen
Voer de volgende stappen uit om de ONNX-backend te gebruiken:
- Compileer het model naar ONNX-formaat.
- Configureer het model.
- Maak het SageMaker-eindpunt.
Voorwaarden
Zorg ervoor dat u voldoende toegang heeft tot een AWS-account AWS Identiteits- en toegangsbeheer IAM-machtigingen om een notebook te maken, toegang te krijgen tot een Amazon eenvoudige opslagservice (Amazon S3) bucket en implementeer modellen op SageMaker-eindpunten. Zien Maak een uitvoeringsrol voor meer informatie.
Compileer het model naar ONNX-formaat
De bibliotheek met transformatoren biedt een handige methode om het PyTorch-model naar ONNX-indeling te compileren. De volgende code realiseert de transformaties voor het NLP-model:
Het exporteren van modellen (PyTorch of TensorFlow) is eenvoudig te realiseren via de conversietool die wordt geleverd als onderdeel van de repository van Hugging Face-transformatoren.
Onder de motorkap gebeurt het volgende:
- Wijs het model toe van transformatoren (PyTorch of TensorFlow).
- Dummy-invoer doorsturen via het model. Op deze manier kan ONNX de reeks uitgevoerde bewerkingen opnemen.
- De transformatoren zorgen inherent voor dynamische assen bij het exporteren van het model.
- Sla de grafiek samen met de netwerkparameters op.
Een soortgelijk mechanisme wordt gevolgd voor de use case voor computervisie van de torchvision-modeldierentuin:
Configureer het model
In deze sectie configureren we de computervisie en het NLP-model. We laten zien hoe u een groot ResNet50- en RoBERTA-model kunt maken dat vooraf is getraind voor implementatie op een SageMaker MME door gebruik te maken van Triton Inference Server-modelconfiguraties. De ResNet50-notebook is beschikbaar op GitHub. Het RoBERTA-notebook is ook beschikbaar op GitHub. Voor ResNet50 gebruiken we de Docker-benadering om een omgeving te creëren die al alle afhankelijkheden heeft die nodig zijn om ons ONNX-model te bouwen en de modelartefacten te genereren die nodig zijn voor deze oefening. Deze aanpak maakt het veel gemakkelijker om afhankelijkheden te delen en de exacte omgeving te creëren die nodig is om deze taak te volbrengen.
De eerste stap is het maken van het ONNX-modelpakket volgens de directorystructuur die is opgegeven in ONNX-modellen. Ons doel is om de minimale modelrepository voor een ONNX-model in een enkel bestand als volgt te gebruiken:
Vervolgens maken we het model configuratie bestand dat de invoer, uitvoer en backend-configuraties beschrijft voor de Triton Server om de juiste kernels voor ONNX op te halen en aan te roepen. Dit bestand staat bekend als config.pbtxt en wordt getoond in de volgende code voor de RoBERTA use case. Merk op dat de BATCH dimensie is weggelaten uit de config.pbtxt. Bij het verzenden van de gegevens naar het model nemen we echter de batchdimensie op. De volgende code laat ook zien hoe u deze functie kunt toevoegen met modelconfiguratiebestanden om dynamische batching in te stellen met een voorkeursbatchgrootte van 5 voor de daadwerkelijke gevolgtrekking. Met de huidige instellingen wordt de modelinstantie onmiddellijk aangeroepen wanneer de gewenste batchgrootte van 5 is bereikt of de vertragingstijd van 100 microseconden is verstreken sinds het eerste verzoek de dynamische batcher bereikte.
Het volgende is het vergelijkbare configuratiebestand voor de gebruikssituatie van computervisie:
Maak het SageMaker-eindpunt
We gebruiken de Boto3 API's om het SageMaker-eindpunt te maken. Voor dit bericht laten we de stappen voor de RoBERTA-notebook zien, maar dit zijn algemene stappen en zullen ook hetzelfde zijn voor het ResNet50-model.
Een SageMaker-model maken
We maken nu een SageMaker-model. Wij gebruiken de Amazon Elastic Container-register (Amazon ECR)-afbeelding en het modelartefact uit de vorige stap om het SageMaker-model te maken.
Maak de houder
Om de container te maken, trekken we de passende afbeelding van Amazon ECR voor Triton Server. Met SageMaker kunnen we verschillende omgevingsvariabelen aanpassen en injecteren. Enkele van de belangrijkste kenmerken zijn de mogelijkheid om de BATCH_SIZE; dit kunnen we per model instellen in de config.pbtxt bestand, of we kunnen hier een standaardwaarde definiëren. Voor modellen die kunnen profiteren van een grotere gedeelde geheugengrootte, kunnen we die waarden instellen onder SHM variabelen. Stel het logboek in om logboekregistratie in te schakelen verbose niveau naar true. We gebruiken de volgende code om het model te maken dat in ons eindpunt moet worden gebruikt:
Een SageMaker-eindpunt maken
U kunt elke instantie met meerdere GPU's gebruiken om te testen. In dit bericht gebruiken we een g4dn.4xlarge-instantie. We stellen de VolumeSizeInGB parameters omdat deze instantie wordt geleverd met lokale instantieopslag. De VolumeSizeInGB parameter is van toepassing op GPU-instanties die de Amazon elastische blokwinkel (Amazon EBS) volume-bijlage. We kunnen de time-out voor het downloaden van het model en de statuscontrole voor het opstarten van de container op de standaardwaarden laten staan. Voor meer details, zie CreateEndpointConfig.
Ten slotte maken we een SageMaker-eindpunt:
Roep het modeleindpunt aan
Dit is een generatief model, dus we passeren in de input_ids en attention_mask naar het model als onderdeel van de lading. De volgende code laat zien hoe de tensoren worden gemaakt:
We maken nu de juiste payload door ervoor te zorgen dat het gegevenstype overeenkomt met wat we hebben geconfigureerd in de config.pbtxt. Dit geeft ons ook de tensoren met de batchdimensie inbegrepen, wat Triton verwacht. We gebruiken het JSON-formaat om het model aan te roepen. Triton biedt ook een native binaire aanroepmethode voor het model.
Merk op TargetModel parameter in de voorgaande code. We sturen de naam van het model dat moet worden aangeroepen als een verzoekheader omdat dit een eindpunt met meerdere modellen is. Daarom kunnen we tijdens runtime meerdere modellen aanroepen op een reeds geïmplementeerd inferentie-eindpunt door deze parameter te wijzigen. Dit toont de kracht van eindpunten met meerdere modellen!
Om het antwoord uit te voeren, kunnen we de volgende code gebruiken:
ONNX voor afstemming van prestaties
De ONNX-backend maakt gebruik van C++ arena-geheugentoewijzing. Arena-toewijzing is een C++-only functie die u helpt uw geheugengebruik te optimaliseren en de prestaties te verbeteren. Geheugentoewijzing en deallocatie vormen een aanzienlijk deel van de CPU-tijd die wordt besteed aan protocolbuffercode. Bij het maken van nieuwe objecten worden standaard heaptoewijzingen uitgevoerd voor elk object, elk van zijn subobjecten en verschillende veldtypen, zoals tekenreeksen. Deze toewijzingen vinden in bulk plaats bij het ontleden van een bericht en bij het bouwen van nieuwe berichten in het geheugen, en bijbehorende deallocaties vinden plaats wanneer berichten en hun subobjectbomen worden vrijgegeven.
Arena-gebaseerde toewijzing is ontworpen om deze prestatiekosten te verlagen. Bij arena-toewijzing worden nieuwe objecten toegewezen uit een groot stuk vooraf toegewezen geheugen, de zogenaamde arena. Objecten kunnen allemaal in één keer worden bevrijd door de hele arena af te leggen, idealiter zonder vernietigers van een ingesloten object uit te voeren (hoewel een arena indien nodig nog steeds een lijst met vernietigers kan bijhouden). Dit maakt objecttoewijzing sneller door het terug te brengen tot een eenvoudige pointer-increment, en maakt deallocatie bijna gratis. Arena-toewijzing biedt ook een grotere cache-efficiëntie: wanneer berichten worden geparseerd, is de kans groter dat ze in continu geheugen worden toegewezen, waardoor het doorkruisen van berichten waarschijnlijker hot cache-regels raakt. Het nadeel van arena-gebaseerde toewijzing is dat het C++-heapgeheugen te veel wordt toegewezen en toegewezen blijft, zelfs nadat de objecten zijn toegewezen. Dit kan leiden tot onvoldoende geheugen of een hoog CPU-geheugengebruik. Om het beste van twee werelden te bereiken, gebruiken we de volgende configuraties van Triton en ONNX:
- arena_extend_strategie - Deze parameter verwijst naar de strategie die wordt gebruikt om de geheugenarena te laten groeien met betrekking tot de grootte van het model. We raden aan om de waarde in te stellen op 1 (=
kSameAsRequested), wat geen standaardwaarde is. De redenering is als volgt: het nadeel van de standaard arena-uitbreidingsstrategie (kNextPowerOfTwo) is dat het mogelijk meer geheugen toewijst dan nodig is, wat zonde zou kunnen zijn. Zoals de naam al doet vermoeden,kNextPowerOfTwo(standaard) vergroot de arena met een macht van 2, terwijlkSameAsRequestedwordt telkens uitgebreid met een grootte die gelijk is aan het toewijzingsverzoek.kSameAsRequestedis geschikt voor geavanceerde configuraties waarbij u vooraf weet wat het verwachte geheugengebruik is. Omdat we weten dat de grootte van modellen een constante waarde is, kunnen we tijdens onze tests veilig kiezenkSameAsRequested. - gpu_mem_limit – We stellen de waarde in op de CUDA-geheugenlimiet. Om al het mogelijke geheugen te gebruiken, geeft u het maximum door
size_t. Het staat standaard opSIZE_MAXals er niets is opgegeven. We raden aan om het als standaard te behouden. - enable_cpu_mem_arena - Dit maakt de geheugenarena op CPU mogelijk. De arena kan vooraf geheugen toewijzen voor toekomstig gebruik. Zet deze optie op
falseals je het niet wilt. De standaardwaarde isTrue. Als u de arena uitschakelt, kost de toewijzing van heapgeheugen tijd, zodat de inferentielatentie toeneemt. Tijdens onze tests hebben we het als standaard gelaten. - enable_mem_pattern – Deze parameter verwijst naar de interne geheugentoewijzingsstrategie op basis van invoervormen. Als de vormen constant zijn, kunnen we deze parameter inschakelen om een geheugenpatroon voor de toekomst te genereren en wat toewijzingstijd te besparen, waardoor het sneller wordt. Gebruik 1 om het geheugenpatroon in te schakelen en 0 om uit te schakelen. Het wordt aanbevolen om dit in te stellen op 1 wanneer wordt verwacht dat de invoerfuncties hetzelfde zijn. De standaardwaarde is 1.
- do_copy_in_default_stream – In de context van de CUDA-uitvoeringsprovider in ONNX is een rekenstroom een reeks CUDA-bewerkingen die asynchroon op de GPU worden uitgevoerd. De ONNX-runtime plant bewerkingen in verschillende streams op basis van hun afhankelijkheden, waardoor de inactieve tijd van de GPU wordt geminimaliseerd en betere prestaties worden bereikt. We raden aan om de standaardinstelling van 1 te gebruiken voor het gebruik van dezelfde stream voor kopiëren en berekenen; u kunt echter 0 gebruiken voor het gebruik van afzonderlijke streams voor kopiëren en berekenen, wat ertoe kan leiden dat het apparaat de twee activiteiten in een pijplijn zet. Bij onze tests van het ResNet50-model gebruikten we zowel 0 als 1, maar konden geen noemenswaardig verschil tussen de twee vinden in termen van prestaties en geheugenverbruik van het GPU-apparaat.
- Grafiek optimalisatie - De ONNX-backend voor Triton ondersteunt verschillende parameters die helpen bij het verfijnen van de modelgrootte en de runtime-prestaties van het geïmplementeerde model. Wanneer het model wordt geconverteerd naar de ONNX-weergave (het eerste vak in het volgende diagram in de IR-fase), biedt de ONNX-runtime grafiekoptimalisaties op drie niveaus: basis-, uitgebreide en lay-outoptimalisaties. U kunt alle niveaus van grafiekoptimalisatie activeren door de volgende parameters toe te voegen aan het modelconfiguratiebestand:
- cudnn_conv_algo_search – Omdat we bij onze tests gebruik maken van op CUDA gebaseerde Nvidia GPU's, kunnen we voor onze use case voor computervisie met het ResNet50-model de op de CUDA-uitvoeringsprovider gebaseerde optimalisatie gebruiken op de vierde laag in het volgende diagram met de
cudnn_conv_algo_searchparameter. De standaardoptie is uitputtend (0), maar toen we deze configuratie veranderden in1 – HEURISTIC, zagen we de latentie van het model in stabiele toestand verminderen tot 160 milliseconden. De reden dat dit gebeurt, is omdat de ONNX-runtime het lichtere gewicht aanroept cudnnGetConvolutionForwardAlgorithm_v7 forward pass en vermindert daarom de latentie met voldoende prestaties. - Run-modus – De volgende stap is het selecteren van de juiste uitvoeringsmodus op laag 5 in het volgende diagram. Deze parameter bepaalt of u de operatoren in uw grafiek sequentieel of parallel wilt uitvoeren. Meestal als het model veel vertakkingen heeft, stelt u deze optie in op
ExecutionMode.ORT_PARALLEL(1) geeft u betere prestaties. In het scenario waarin uw model veel vertakkingen in de grafiek heeft, zal het instellen van de uitvoeringsmodus op parallel helpen bij betere prestaties. De standaardmodus is sequentieel, dus u kunt deze naar wens inschakelen.
Raadpleeg de volgende afbeelding voor een beter begrip van de mogelijkheden voor het afstemmen van prestaties in ONNX.

Benchmarknummers en afstemming van prestaties
Door de grafiekoptimalisaties in te schakelen, cudnn_conv_algo_search, en parallelle run-modusparameters tijdens onze tests van het ResNet50-model, zagen we de koude starttijd van de ONNX-modelgrafiek verminderen van 4.4 seconden naar 1.61 seconden. Een voorbeeld van een volledig modelconfiguratiebestand vindt u in de ONNX-configuratiesectie hieronder notitieboekje.
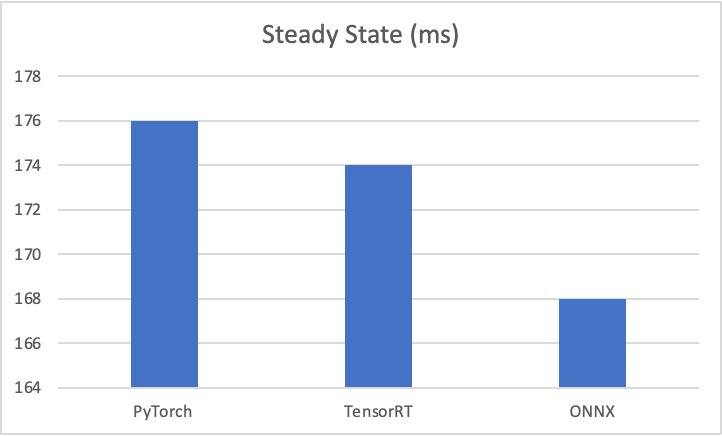
De resultaten van de testbenchmark zijn als volgt:
- PyTorch – 176 milliseconden, koude start 6 seconden
- TensorRT – 174 milliseconden, koude start 4.5 seconden
- ONNX – 168 milliseconden, koude start 4.4 seconden
De volgende grafieken visualiseren deze statistieken.


Overweeg bovendien om bij het testen van gebruiksscenario's voor computervisie de payload van het verzoek in binair formaat te verzenden met behulp van de HTTP-client van Triton, omdat dit de latentie van het aanroepen van modellen aanzienlijk verbetert.
Andere parameters die SageMaker blootlegt voor ONNX op Triton zijn als volgt:
- Dynamische batchverwerking – Dynamische batching is een functie van Triton waarmee inferentieverzoeken door de server kunnen worden gecombineerd, zodat er dynamisch een batch wordt aangemaakt. Het maken van een batch aanvragen resulteert doorgaans in een hogere verwerkingscapaciteit. De dynamische batcher moet worden gebruikt voor staatloze modellen. De dynamisch gemaakte batches worden gedistribueerd naar alle modelexemplaren die voor het model zijn geconfigureerd.
- Maximale batchgrootte - The
max_batch_sizeeigenschap geeft de maximale batchgrootte aan die het model ondersteunt voor de soorten batches die door Triton kunnen worden uitgebuit. Als de batchdimensie van het model de eerste dimensie is en alle inputs en outputs naar het model deze batchdimensie hebben, dan kan Triton zijn dynamische batcher or volgorde batcher om automatisch batchverwerking met het model te gebruiken. In dit geval,max_batch_sizemoet worden ingesteld op een waarde groter dan of gelijk aan 1, wat de maximale batchgrootte aangeeft die Triton met het model moet gebruiken. - Standaard maximale batchgrootte – De default-max-batch-size waarde wordt gebruikt voor
max_batch_sizegedurende autocomplete wanneer geen andere waarde wordt gevonden. Deonnxruntimebackend zal demax_batch_sizevan het model naar deze standaardwaarde als automatisch aanvullen heeft bepaald dat het model in staat is om aanvragen in batches te verwerken enmax_batch_sizeis 0 in de modelconfiguratie ofmax_batch_sizeis weggelaten uit de modelconfiguratie. Alsmax_batch_sizeis meer dan 1 en nee scheduler wordt verstrekt, wordt de dynamische batchplanner gebruikt. De standaard maximale batchgrootte is 4.
Opruimen
Zorg ervoor dat u het model, de modelconfiguratie en het modeleindpunt verwijdert nadat u de notebook hebt uitgevoerd. De stappen om dit te doen vindt u aan het einde van het voorbeeldnotitieblok in het GitHub rest.
Conclusie
In dit bericht zijn we diep ingegaan op de ONNX-backend die Triton Inference Server ondersteunt op SageMaker. Deze backend zorgt voor GPU-versnelling van uw ONNX-modellen. Er zijn veel opties die u kunt overwegen om de beste prestaties voor inferentie te krijgen, zoals batchgroottes, indelingen voor gegevensinvoer en andere factoren die kunnen worden afgestemd op uw behoeften. Met SageMaker kunt u deze mogelijkheid gebruiken met eindpunten met één model en meerdere modellen. MME's zorgen voor een betere balans tussen prestaties en kostenbesparingen. Om aan de slag te gaan met MME-ondersteuning voor GPU, zie Host meerdere modellen in één container achter één eindpunt.
We nodigen u uit om Triton Inference Server-containers in SageMaker te proberen en uw feedback en vragen in de opmerkingen te delen.
Over de auteurs
 Abhi Shivaditya is een Senior Solutions Architect bij AWS en werkt samen met strategische wereldwijde bedrijfsorganisaties om de acceptatie van AWS-services op gebieden als kunstmatige intelligentie, gedistribueerde computers, netwerken en opslag te vergemakkelijken. Zijn expertise ligt in Deep Learning in de domeinen Natural Language Processing (NLP) en Computer Vision. Abhi helpt klanten bij het efficiënt inzetten van krachtige machine learning-modellen binnen het AWS-ecosysteem.
Abhi Shivaditya is een Senior Solutions Architect bij AWS en werkt samen met strategische wereldwijde bedrijfsorganisaties om de acceptatie van AWS-services op gebieden als kunstmatige intelligentie, gedistribueerde computers, netwerken en opslag te vergemakkelijken. Zijn expertise ligt in Deep Learning in de domeinen Natural Language Processing (NLP) en Computer Vision. Abhi helpt klanten bij het efficiënt inzetten van krachtige machine learning-modellen binnen het AWS-ecosysteem.
 James Park is een oplossingsarchitect bij Amazon Web Services. Hij werkt samen met Amazon.com aan het ontwerpen, bouwen en implementeren van technologische oplossingen op AWS, en heeft een bijzondere interesse in AI en machine learning. In zijn vrije tijd gaat hij graag op zoek naar nieuwe culturen, nieuwe ervaringen en op de hoogte blijven van de nieuwste technologische trends. Je kunt hem vinden op LinkedIn.
James Park is een oplossingsarchitect bij Amazon Web Services. Hij werkt samen met Amazon.com aan het ontwerpen, bouwen en implementeren van technologische oplossingen op AWS, en heeft een bijzondere interesse in AI en machine learning. In zijn vrije tijd gaat hij graag op zoek naar nieuwe culturen, nieuwe ervaringen en op de hoogte blijven van de nieuwste technologische trends. Je kunt hem vinden op LinkedIn.
 Rupinder Grewal is een Sr Ai/ML Specialist Solutions Architect bij AWS. Hij richt zich momenteel op het bedienen van modellen en MLOps op SageMaker. Voorafgaand aan deze functie heeft hij gewerkt als Machine Learning Engineer voor het bouwen en hosten van modellen. Naast zijn werk speelt hij graag tennis en fietst hij graag op bergpaden.
Rupinder Grewal is een Sr Ai/ML Specialist Solutions Architect bij AWS. Hij richt zich momenteel op het bedienen van modellen en MLOps op SageMaker. Voorafgaand aan deze functie heeft hij gewerkt als Machine Learning Engineer voor het bouwen en hosten van modellen. Naast zijn werk speelt hij graag tennis en fietst hij graag op bergpaden.
 Dhawal Patel is een Principal Machine Learning Architect bij AWS. Hij heeft gewerkt met organisaties variërend van grote ondernemingen tot middelgrote startups aan problemen met betrekking tot gedistribueerde computing en kunstmatige intelligentie. Hij richt zich op Deep learning inclusief NLP en Computer Vision domeinen. Hij helpt klanten bij het bereiken van high-performance modelinferentie op SageMaker.
Dhawal Patel is een Principal Machine Learning Architect bij AWS. Hij heeft gewerkt met organisaties variërend van grote ondernemingen tot middelgrote startups aan problemen met betrekking tot gedistribueerde computing en kunstmatige intelligentie. Hij richt zich op Deep learning inclusief NLP en Computer Vision domeinen. Hij helpt klanten bij het bereiken van high-performance modelinferentie op SageMaker.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/machine-learning/host-ml-models-on-amazon-sagemaker-using-triton-onnx-models/

