In het huidige digitale tijdperk is logboekregistratie een essentieel aspect van de ontwikkeling en het beheer van applicaties, maar het efficiënt beheren van logboeken en tegelijkertijd voldoen aan de regelgeving inzake gegevensbescherming kan een grote uitdaging zijn. Zoom, in samenwerking met de AWS-datalab team, een innovatieve architectuur ontwikkeld om deze uitdagingen het hoofd te bieden en hun logging- en recordverwijderingsprocessen te stroomlijnen. In dit bericht onderzoeken we de architectuur en de voordelen die deze biedt voor Zoom en zijn gebruikers.
Uitdagingen voor toepassingslogboeken: gegevensbeheer en naleving
Applicatielogboeken zijn een essentieel onderdeel van elke applicatie; ze bieden waardevolle informatie over het gebruik en de prestaties van het systeem. Deze logboeken worden voor verschillende doeleinden gebruikt, zoals foutopsporing, auditing, prestatiebewaking, bedrijfsinformatie, systeemonderhoud en beveiliging. Hoewel deze applicatielogboeken nodig zijn voor het onderhouden en verbeteren van de applicatie, vormen ze ook een interessante uitdaging. Deze toepassingslogboeken kunnen persoonlijk identificeerbare gegevens bevatten, zoals gebruikersnamen, e-mailadressen, IP-adressen en browsegeschiedenis, wat aanleiding geeft tot bezorgdheid over de privacy van gegevens.
Wetten zoals de General Data Protection Regulation (GDPR) en de California Consumer Privacy Act (CCPA) vereisen dat organisaties applicatielogboeken gedurende een bepaalde periode bewaren. De exacte tijdsduur die nodig is voor gegevensopslag varieert afhankelijk van de specifieke regelgeving en het type gegevens dat wordt opgeslagen. De reden voor deze bewaartermijnen is om ervoor te zorgen dat bedrijven persoonsgegevens niet langer bewaren dan nodig is, wat het risico op datalekken en andere beveiligingsincidenten zou kunnen vergroten. Dit helpt er ook voor te zorgen dat bedrijven persoonlijke gegevens niet gebruiken voor andere doeleinden dan waarvoor ze zijn verzameld, wat een schending van de privacywetgeving zou kunnen zijn. Deze wetten geven individuen ook het recht om te verzoeken om verwijdering van hun persoonlijke gegevens, ook wel bekend als het "recht om vergeten te worden". Individuen hebben het recht om hun persoonsgegevens zonder onnodige vertraging te laten wissen.
Aan de ene kant moeten organisaties dus applicatieloggegevens verzamelen om de goede werking van hun services te garanderen, en de gegevens gedurende een bepaalde periode bewaren. Maar aan de andere kant kunnen ze verzoeken van individuen ontvangen om hun persoonlijke gegevens uit de logboeken te verwijderen. Dit zorgt voor een evenwichtsoefening voor organisaties, omdat ze moeten voldoen aan zowel de vereisten voor het bewaren van gegevens als het verwijderen van gegevens.
Dit probleem wordt een steeds grotere uitdaging voor grotere organisaties die in meerdere landen en staten actief zijn, omdat elk land en elke staat mogelijk zijn eigen regels en voorschriften heeft met betrekking tot het bewaren en verwijderen van gegevens. De Personal Information Protection and Electronic Documents Act (PIPEDA) in Canada en de Australian Privacy Act in Australië zijn bijvoorbeeld vergelijkbare wetten als de AVG, maar ze kunnen andere bewaartermijnen of andere uitzonderingen hebben. Daarom moeten organisaties, groot of klein, door dit complexe landschap van vereisten voor het bewaren en verwijderen van gegevens navigeren en er tegelijkertijd voor zorgen dat ze voldoen aan alle toepasselijke wet- en regelgeving.
De initiële architectuur van Zoom
Tijdens de COVID-19-pandemie schoot het gebruik van Zoom omhoog, omdat steeds meer mensen werden gevraagd om thuis te werken en lessen te volgen. Het bedrijf moest zijn diensten snel opschalen om de piek op te vangen en werkte samen met AWS om capaciteit in te zetten in de meeste regio's wereldwijd. Met een plotselinge toename van het grote aantal applicatie-eindpunten, moesten ze hun architectuur voor loganalyse snel ontwikkelen en werkten ze samen met het AWS Data Lab-team om snel een prototype te maken en een architectuur in te zetten voor hun compliance-use-case.
Bij Zoom zijn de verwerkingscapaciteit en prestatievereisten voor gegevensopname zeer streng. Er moesten gegevens worden opgenomen van enkele duizenden applicatie-eindpunten die elke minuut meer dan 30 miljoen berichten produceerden, wat resulteerde in meer dan 100 TB aan loggegevens per dag. De bestaande opnamepijplijn bestond uit het schrijven van de gegevens naar Apache Hadoop HDFS-opslag door Apache Kafka eerst en vervolgens dagelijkse taken uitvoeren om de gegevens naar permanente opslag te verplaatsen. Dit duurde enkele uren, terwijl ook de opname werd vertraagd en er kans op gegevensverlies ontstond. Het schalen van de architectuur was ook een probleem, omdat HDFS-gegevens moesten worden verplaatst wanneer er knooppunten werden toegevoegd of verwijderd. Bovendien was er transactionele semantiek op miljarden records nodig om te voldoen aan nalevingsgerelateerde verzoeken om gegevens te verwijderen, en de bestaande architectuur van dagelijkse batchtaken was operationeel inefficiënt.
Het was in die tijd, door gesprekken met het AWS-accountteam, dat het AWS Data Lab-team betrokken raakte om te helpen bij het bouwen van een oplossing voor de hyperschaal van Zoom.
Overzicht oplossingen
Het AWS Data Lab biedt versnelde, gezamenlijke engineering-opdrachten tussen klanten en technische middelen van AWS om tastbare deliverables te creëren die data, analyse, kunstmatige intelligentie (AI), machine learning (ML), serverloze en containermoderniseringsinitiatieven versnellen. Het Data Lab heeft drie aanbiedingen: het Build Lab, het Design Lab en Resident Architect. Tijdens de Build and Design Labs ondersteunden AWS Data Lab Solutions Architects en AWS-experts Zoom specifiek door prescriptieve architecturale begeleiding te bieden, best practices te delen, een werkend prototype te bouwen en technische obstakels te verwijderen om aan hun productiebehoeften te voldoen.
Zoom en het AWS-team (in de toekomst gezamenlijk "het team" genoemd) identificeerden twee belangrijke workflows voor het opnemen en verwijderen van gegevens.
Werkstroom voor gegevensopname
Het volgende diagram illustreert de workflow voor gegevensopname.
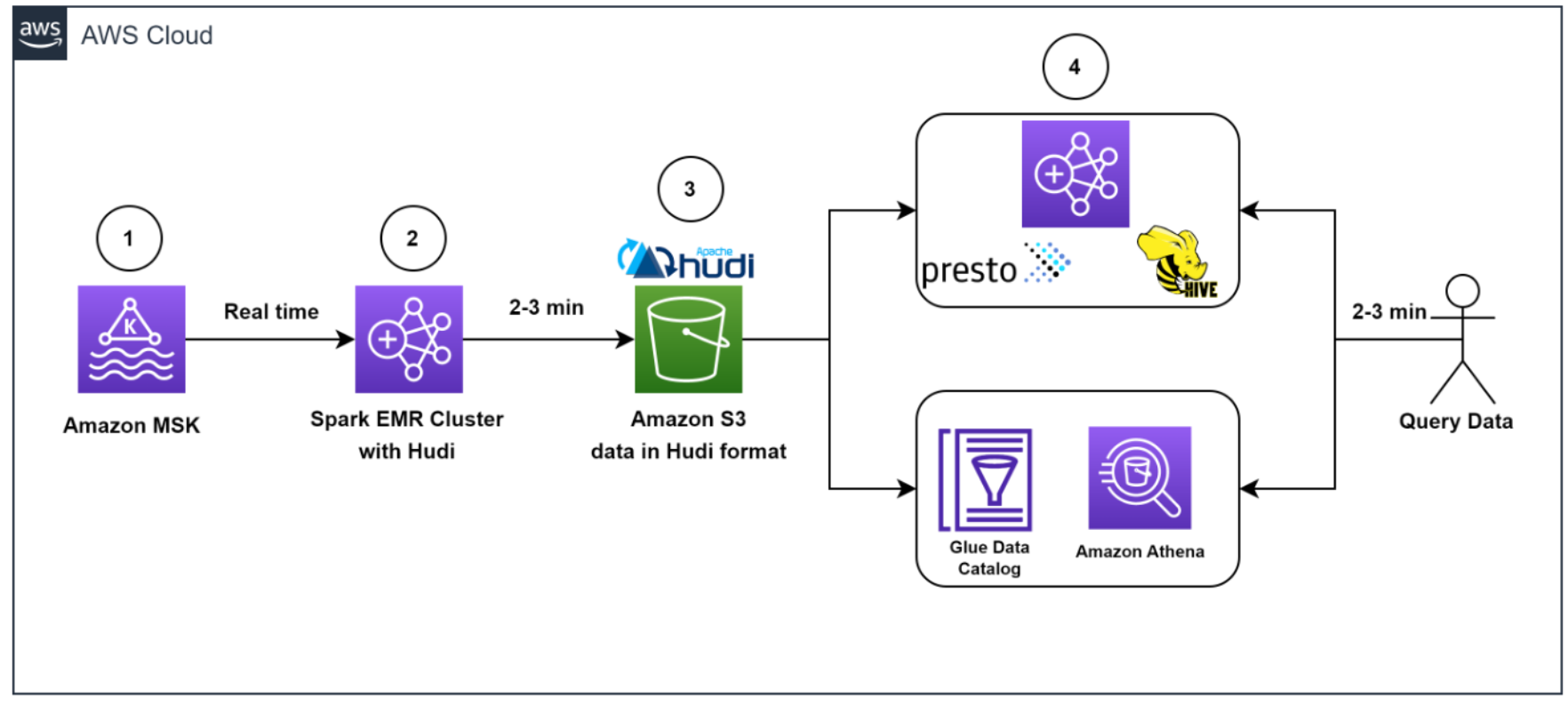
Het team moest hiervoor snel miljoenen Kafka-berichten in de ontwikkel-/testomgeving vullen. Om het proces te versnellen, hebben wij (het team) ervoor gekozen om te gebruiken Amazon Managed Streaming voor Apache Kafka (Amazon MSK), waardoor het eenvoudig is om streaminggegevens in realtime op te nemen en te verwerken, en we waren binnen een dag aan de slag.
Om testgegevens te genereren die leken op productiegegevens, creëerde het AWS Data Lab-team een aangepast Python-script dat meer dan 1.2 miljard berichten verdeeld over verschillende Kafka-partities gelijkmatig vulde. Om overeen te komen met de productie-instellingen in het ontwikkelingsaccount, moesten we de limiet voor het cloudquotum verhogen via een ondersteuningsticket.
We gebruikten Amazon MSK en de Spark Structured Streaming-mogelijkheid in Amazon EMR om de inkomende Kafka-berichten met hoge doorvoer en lage latentie op te nemen en te verwerken. Concreet hebben we de gegevens van de bron in EMR-clusters ingevoegd met een maximale inkomende snelheid van 150 miljoen Kafka-berichten elke 5 minuten, waarbij elk Kafka-bericht 7-25 loggegevensrecords bevat.
Om de gegevens op te slaan, hebben we ervoor gekozen om te gebruiken Apache Hudi als het tabelformaat. We hebben voor Hudi gekozen omdat het een open-source raamwerk voor gegevensbeheer is dat mogelijkheden biedt voor invoegen, bijwerken en verwijderen op recordniveau bovenop een onveranderlijke opslaglaag zoals Amazon eenvoudige opslagservice (Amazone S3). Bovendien is Hudi geoptimaliseerd voor het verwerken van grote datasets en werkt het goed met Spark Structured Streaming, dat al bij Zoom werd gebruikt.
Nadat 150 miljoen berichten waren gebufferd, verwerkten we de berichten met behulp van Spark Structured Streaming op Amazon EMR en schreven we de gegevens elke 3 minuten naar Amazon S5 in Apache Hudi-compatibel formaat. We hebben eerst de berichtenarray afgevlakt en één record gemaakt van de geneste reeks berichten. Vervolgens hebben we aan elk bericht een unieke sleutel toegevoegd, de zogenaamde Hudi-recordsleutel. Met deze sleutel kan Hudi bewerkingen voor het invoegen, bijwerken en verwijderen van de gegevens op recordniveau uitvoeren. We hebben ook de veldwaarden, inclusief de Hudi-partitiesleutels, uit inkomende berichten gehaald.
Dankzij deze architectuur konden eindgebruikers de gegevens opvragen die zijn opgeslagen in Amazon S3 met behulp van Amazone Athene met de AWS-lijmgegevenscatalogus of gebruiken Apache-bijenkorf en Presto.
Workflow voor het verwijderen van gegevens
Het volgende diagram illustreert de werkstroom voor het verwijderen van gegevens.
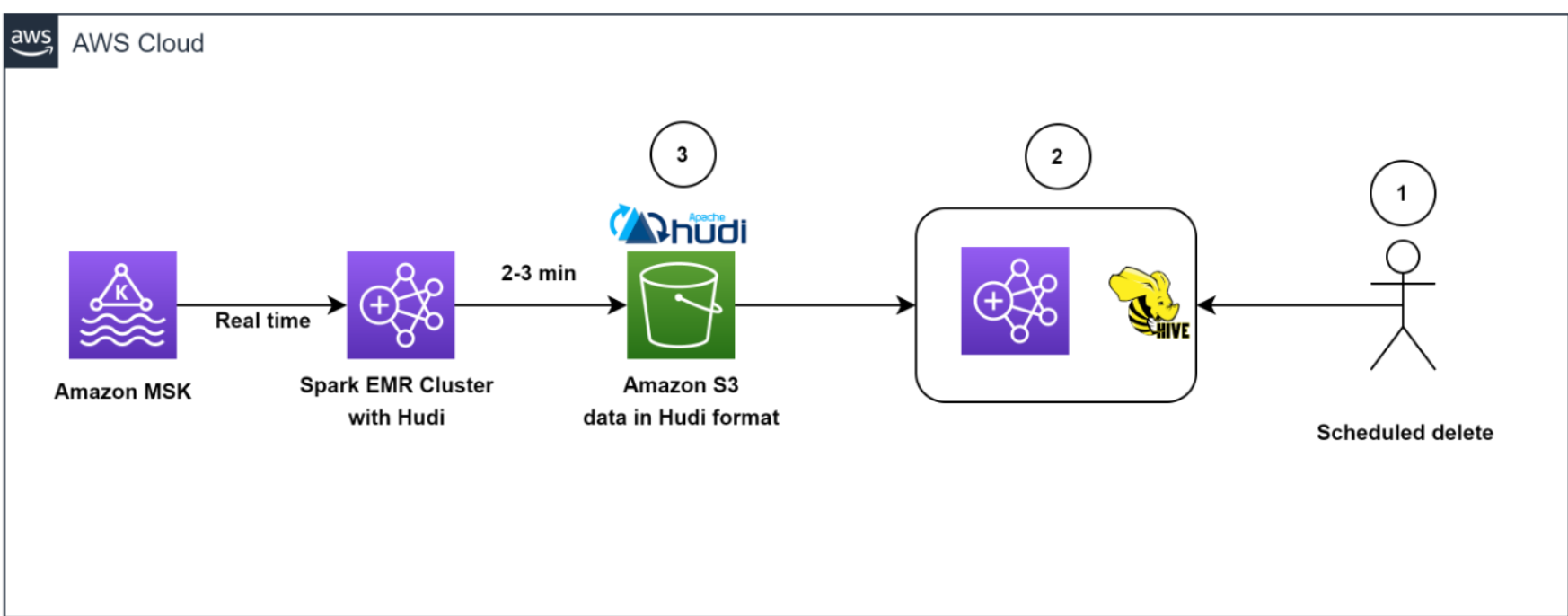
Onze architectuur zorgde voor een efficiënte verwijdering van gegevens. Om te helpen voldoen aan het door de klant geïnitieerde gegevensbewaringsbeleid voor AVG-verwijderingen, werden er dagelijks geplande taken uitgevoerd om de gegevens te identificeren die in batchmodus moesten worden verwijderd.
Vervolgens hebben we een tijdelijk EMR-cluster opgezet om de GDPR-upsert-taak uit te voeren om de records te verwijderen. De gegevens werden opgeslagen in Amazon S3 in Hudi-indeling en dankzij de ingebouwde index van Hudi konden we records efficiënt verwijderen met behulp van bloeifilters en bestandsbereiken. Omdat alleen de bestanden die de recordsleutels bevatten, hoefden te worden gelezen en herschreven, duurde het slechts ongeveer 1 à 2 minuten om 1,000 records van de 1 miljard records te verwijderen, wat voorheen uren in beslag had genomen omdat volledige partities werden gelezen.
Over het algemeen maakte onze oplossing een efficiënte verwijdering van gegevens mogelijk, wat een extra laag van gegevensbeveiliging bood die cruciaal was voor Zoom, in het licht van de AVG-vereisten.
Architectuur om schaal, prestaties en kosten te optimaliseren
In dit gedeelte delen we de volgende strategieën die Zoom heeft gevolgd om de schaal, prestaties en kosten te optimaliseren:
- Inname optimaliseren
- Optimalisatie van de doorvoer en het gebruik van Amazon EMR
- Ontkoppeling van opname en AVG-verwijdering met behulp van EMRFS
- Efficiënt verwijderen met Apache Hudi
- Optimaliseren voor lezen met lage latentie met Apache Hudi
- Monitoren
Inname optimaliseren
Om de opslag in Kafka lean en optimaal te houden, en om een real-time weergave van gegevens te krijgen, hebben we een Spark-taak gemaakt om inkomende Kafka-berichten in batches van 150 miljoen berichten te lezen en elke keer naar Amazon S3 te schrijven in Hudi-compatibele indeling. 5 minuten. Zelfs tijdens de beginfasen van de iteratie, toen we nog niet waren begonnen met schalen en afstemmen, konden we alle Kafka-berichten consistent binnen 2.5 minuut laden met behulp van de Amazon EMR-runtime voor Apache Spark.
Optimalisatie van de doorvoer en het gebruik van Amazon EMR
We hebben een kostengeoptimaliseerd EMR-cluster gelanceerd en zijn overgestapt van uniforme instantiegroepen naar het gebruik van EMR-instantievloten. We hebben gekozen voor instance-vloten omdat we de flexibiliteit nodig hadden om Spot Instances te gebruiken voor taakknooppunten en omdat we het risico van onvoldoende capaciteit wilden diversifiëren voor een specifiek instancetype in onze beschikbaarheidszone.
We begonnen te experimenteren met testruns door eerst het aantal Kafka-partities te wijzigen van 400 in 1,000 en vervolgens het aantal taakknooppunten en instantietypen te wijzigen. Op basis van de resultaten van de run kwam het AWS-team met de aanbeveling om Amazon EMR te gebruiken met drie kernknooppunten (r5.16xlarge (elk 64 vCPU's)) en 18 taakknooppunten met behulp van Spot-vlootinstanties (een combinatie van r5.16xlarge ( 64 vCPU's), r5.12xlarge (48 vCPU's), r5.8xlarge (32 vCPU's)). Deze aanbevelingen hielpen Zoom om hun Amazon EMR-kosten met meer dan 80% te verlagen, terwijl ze hun gewenste prestatiedoelen bereikten om 150 miljoen Kafka-berichten binnen 5 minuten te verwerken.
Ontkoppeling van opname en AVG-verwijdering met behulp van EMRFS
Een bekend voordeel van de scheiding van opslag en rekenkracht is dat u de twee onafhankelijk van elkaar kunt schalen. Maar een niet zo voor de hand liggend voordeel is dat je continue workloads kunt loskoppelen van sporadische workloads. Voorheen werden gegevens opgeslagen in HDFS. Resource-intensieve GDPR-verwijderingstaken en dataverplaatsingstaken zouden strijden om resources met de stroomopname, waardoor een achterstand van meer dan 5 uur zou ontstaan in stroomopwaartse Kafka-clusters, waardoor de Kafka-opslag bijna vol was (die slechts 6 uur aan gegevensretentie had ) en mogelijk gegevensverlies veroorzaken. Het offloaden van gegevens van HDFS naar Amazon S3 gaf ons de vrijheid om op verzoek onafhankelijke tijdelijke EMR-clusters te lanceren om gegevens te verwijderen, waardoor ervoor werd gezorgd dat de voortdurende gegevensopname van Kafka naar Amazon EMR niet wordt uitgehongerd voor middelen. Hierdoor kon het systeem elke 5 minuten gegevens opnemen en elke Spark Streaming-lezing in 2-3 minuten voltooien. Een ander neveneffect van het gebruik van EMRFS is een qua kosten geoptimaliseerd cluster, omdat we de afhankelijkheid van Amazon elastische blokwinkel (Amazon EBS) volumes voor meer dan 300 TB opslag die werd gebruikt voor drie kopieën (inclusief twee replica's) van HDFS-gegevens. We betalen nu voor slechts één exemplaar van de gegevens in Amazon S3, dat 11 9s duurzaamheid biedt en relatief goedkope opslag is.
Efficiënt verwijderen met Apache Hudi
Hoe zit het met het conflict tussen ingest-schrijfbewerkingen en AVG-verwijderingen bij gelijktijdige uitvoering? Dit is waar de kracht van Apache Hudi opvalt.
Apache Hudi biedt een tabelindeling voor datalakes met transactionele semantiek die de scheiding mogelijk maakt van opnameworkloads en updates wanneer deze gelijktijdig worden uitgevoerd. Het systeem was in staat om in minder dan een minuut consistent 1,000 records te verwijderen. Er waren enkele beperkingen bij gelijktijdig schrijven Apache Hudi 0.7.0, maar het Amazon EMR-team loste dit snel op door back-porting Apache Hudi 0.8.0, welke ondersteunt optimistisch gelijktijdigheidscontrole, naar de huidige (ten tijde van de AWS Data Lab-samenwerking) Amazon EMR 6.4-release. Dit bespaarde tijd bij het testen en zorgde voor een snelle overgang naar de nieuwe versie met minimale testen. Hierdoor konden we de gegevens snel rechtstreeks opvragen met behulp van Athena zonder een cluster te hoeven opstarten om ad-hocquery's uit te voeren, en konden we de gegevens opvragen met Presto, Trino en Hive. De ontkoppeling van de opslag- en rekenlagen bood de flexibiliteit om niet alleen gegevens uit verschillende EMR-clusters op te vragen, maar ook gegevens te verwijderen met behulp van een volledig onafhankelijk tijdelijk cluster.
Optimaliseren voor lezen met lage latentie met Apache Hudi
Om te optimaliseren voor lezen met lage latentie met Apache Hudi, moesten we het probleem aanpakken dat er te veel kleine bestanden werden gemaakt binnen Amazon S3 vanwege de continue stroom van gegevens naar het datameer.
We hebben de functies van Apache Hudi gebruikt om de bestandsgrootte af te stemmen voor optimale query's. We hebben met name de mate van parallellisme in Hudi teruggebracht van de standaardwaarde van 1,500 naar een lager aantal. Parallellisme verwijst naar het aantal threads dat wordt gebruikt om gegevens naar Hudi te schrijven; door het te verkleinen, konden we grotere bestanden maken die meer optimaal waren voor query's.
Omdat we moesten optimaliseren voor streaming met een hoog volume, hebben we ervoor gekozen om de samenvoegen bij lezen tabeltype (in plaats van kopiëren op schrijven) voor onze werklast. Met dit tabeltype konden we de binnenkomende gegevens snel opnemen in deltabestanden in rijformaat (Avro) en de deltabestanden asynchroon comprimeren tot Parquet-bestanden in kolommen voor snel lezen. Om dit te doen, hebben we de Hudi-verdichtingstaak op de achtergrond uitgevoerd. Compactie is het proces van het samenvoegen van op rijen gebaseerde deltabestanden om nieuwe versies van kolombestanden te produceren. Omdat de verdichtingstaak extra rekenresources zou gebruiken, hebben we de mate van parallellisme voor invoeging aangepast naar een lagere waarde van 1,000 om rekening te houden met het extra resourcegebruik. Door deze aanpassing konden we grotere bestanden maken zonder in te leveren op prestatiedoorvoer.
Over het algemeen stelde onze benadering van optimalisatie voor lezen met lage latentie met Apache Hudi ons in staat om bestandsgroottes beter te beheren en de algehele prestaties van ons datameer te verbeteren.
Monitoren
Het team monitorde MSK-clusters met Prometheus (een open-source monitoringtool). Daarnaast hebben we laten zien hoe Spark-streamingtaken kunnen worden gecontroleerd met behulp van Amazon Cloud Watch statistieken. Voor meer informatie, zie Bewaak Spark-streamingtoepassingen op Amazon EMR.
Resultaten
De samenwerking tussen Zoom en het AWS Data Lab heeft aanzienlijke verbeteringen aangetoond in de opname, verwerking, opslag en verwijdering van gegevens met behulp van een architectuur met Amazon EMR en Apache Hudi. Een belangrijk voordeel van de architectuur was een verlaging van de infrastructuurkosten, die werd bereikt door het gebruik van cloud-native technologieën en het efficiënte beheer van gegevensopslag. Een ander voordeel was een verbetering van de mogelijkheden voor gegevensbeheer.
We hebben aangetoond dat de kosten van EMR-clusters met ongeveer 82% kunnen worden verlaagd, terwijl de opslagkosten met ongeveer 90% kunnen worden verlaagd in vergelijking met de eerdere op HDFS gebaseerde architectuur. Dit alles terwijl de data binnen 5 minuten na inname van de bron beschikbaar is in het datameer. We hebben ook aangetoond dat het verwijderen van gegevens uit een datameer met meerdere petabytes aan gegevens veel efficiënter kan worden uitgevoerd. Met onze geoptimaliseerde aanpak waren we in staat om ongeveer 1,000 records in slechts 1 à 2 minuten te verwijderen, vergeleken met de eerder vereiste 3 uur of meer.
Conclusie
Concluderend, het loganalyseproces, waarbij loggegevens van verschillende bronnen zoals servers, applicaties en apparaten worden verzameld, verwerkt, opgeslagen, geanalyseerd en verwijderd, is van cruciaal belang om organisaties te helpen bij het werken aan hun veerkracht, beveiliging en prestaties. monitoring, probleemoplossing en nalevingsbehoeften, zoals de AVG.
In dit bericht werd gedeeld wat Zoom en het AWS Data Lab-team samen hebben bereikt om kritieke datapijplijnuitdagingen op te lossen, en Zoom heeft de oplossing verder uitgebreid om ETL-taken (extraheren, transformeren en laden) en resource-efficiëntie te optimaliseren. U kunt de hier gepresenteerde architectuurpatronen echter ook gebruiken om snel kosteneffectieve en schaalbare oplossingen te bouwen voor andere gebruiksscenario's. Neem contact op met uw AWS-team voor meer informatie of contact Verkoop.
Over de auteurs
 Sekar Srinivasan is een Sr. Specialist Solutions Architect bij AWS gericht op Big Data en Analytics. Sekar heeft meer dan 20 jaar ervaring in het werken met data. Hij is gepassioneerd om klanten te helpen bij het bouwen van schaalbare oplossingen, het moderniseren van hun architectuur en het genereren van inzichten uit hun data. In zijn vrije tijd werkt hij graag aan non-profit projecten gericht op onderwijs voor kansarme kinderen.
Sekar Srinivasan is een Sr. Specialist Solutions Architect bij AWS gericht op Big Data en Analytics. Sekar heeft meer dan 20 jaar ervaring in het werken met data. Hij is gepassioneerd om klanten te helpen bij het bouwen van schaalbare oplossingen, het moderniseren van hun architectuur en het genereren van inzichten uit hun data. In zijn vrije tijd werkt hij graag aan non-profit projecten gericht op onderwijs voor kansarme kinderen.
 Chandra Dhandapani is een Senior Solutions Architect bij AWS, waar hij gespecialiseerd is in het creëren van oplossingen voor klanten op het gebied van Analytics, AI/ML en Databases. Hij heeft veel ervaring met het bouwen en schalen van applicaties in verschillende sectoren, waaronder de gezondheidszorg en Fintech. Buiten zijn werk is hij een fervent reiziger en houdt hij van sporten, lezen en amusement.
Chandra Dhandapani is een Senior Solutions Architect bij AWS, waar hij gespecialiseerd is in het creëren van oplossingen voor klanten op het gebied van Analytics, AI/ML en Databases. Hij heeft veel ervaring met het bouwen en schalen van applicaties in verschillende sectoren, waaronder de gezondheidszorg en Fintech. Buiten zijn werk is hij een fervent reiziger en houdt hij van sporten, lezen en amusement.
 Amit Kumar Agrawal is een Senior Solutions Architect bij AWS, gevestigd in de San Francisco Bay Area. Hij werkt samen met grote strategische ISV-klanten om cloudoplossingen te ontwerpen die hun zakelijke uitdagingen aanpakken. In zijn vrije tijd trekt hij er graag op uit met zijn gezin.
Amit Kumar Agrawal is een Senior Solutions Architect bij AWS, gevestigd in de San Francisco Bay Area. Hij werkt samen met grote strategische ISV-klanten om cloudoplossingen te ontwerpen die hun zakelijke uitdagingen aanpakken. In zijn vrije tijd trekt hij er graag op uit met zijn gezin.
 Virale sjah is een Analytics Sales Specialist die al 5 jaar bij AWS werkt om klanten te helpen succesvol te zijn in hun datatraject. Hij heeft meer dan 20 jaar ervaring in het werken met zakelijke klanten en startups, voornamelijk op het gebied van data en databases. Hij houdt van reizen en quality time doorbrengen met zijn gezin.
Virale sjah is een Analytics Sales Specialist die al 5 jaar bij AWS werkt om klanten te helpen succesvol te zijn in hun datatraject. Hij heeft meer dan 20 jaar ervaring in het werken met zakelijke klanten en startups, voornamelijk op het gebied van data en databases. Hij houdt van reizen en quality time doorbrengen met zijn gezin.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/how-zoom-implemented-streaming-log-ingestion-and-efficient-gdpr-deletes-using-apache-hudi-on-amazon-emr/

