Introductie
Vindt u veel tijd aan het beheren van uw machine learning-taken? Bent u op zoek naar een manier om te automatiseren en te vereenvoudigen? Airflow kan u helpen uw workflow te beheren en uw leven gemakkelijker te maken met zijn bewakings- en meldingsfuncties. Stelt u zich eens voor dat u uw ML-taken zo plant dat ze automatisch worden uitgevoerd zonder handmatige tussenkomst. Stelt u zich eens voor dat u de status van uw workflows en taken in realtime kunt bekijken en direct wijzigingen kunt aanbrengen.
In deze blog geven we een complete handleiding over het gebruik van Airflow voor machine learning-taken. We behandelen de installatie, hoe u een DAG maakt, hoe u taken definieert, hoe u afhankelijkheden tussen taken instelt, hoe u de webservers en SLA's (Service Level Agreements) voor uw taken start. Of u nu nieuw bent bij Airflow of een ervaren gebruiker bent, deze gids geeft u een uitgebreid inzicht in het gebruik van Airflow voor machine learning-taken en leidt u door het volledige proces van het instellen van Airflow voor het monitoren en waarschuwen van machine learning-taken ervan, u kunt helemaal zelf een monitoring- en waarschuwingssysteem maken met behulp van Airflow's notificatie en SLA-functies.

leerdoelen
- Begrijp de basisprincipes van Airflow en het gebruik ervan in machine learning-taken.
- Leer hoe u een maakt DAG (gerichte acyclische grafiek) voor machine learning-taken.
- Begrijp het belang van meldingen en SLA's bij het bewaken van machine learning-taken.
- Leer hoe u meldingen instelt voor machine learning in en speling.
- Leer hoe u SLA's instelt voor machine learning-taken.
- Ontwikkel de a
- Meer informatie over het aanpassen van meldingen en SLA's voor uw taken
Dit artikel is gepubliceerd als onderdeel van het Data Science-blogathon.
Inhoudsopgave
- Wat is luchtstroom?
- 1.1 Hoe kan Airflow worden gebruikt voor machine learning?
- Wat is een DAG?
- Stapsgewijze handleiding
- Luchtstroom installeren
- Initialiseer de Airflow-database
- Maak een DAG
- Stel de afhankelijkheden tussen taken in
- De pijpleiding uitvoeren
- Start de Airflow-webserver
- Basisprincipes van luchtstroommeldingen
- Waarom hebben we meldingen nodig?
- Meldingsniveaus
- Meldingstriggers
- Aangepaste Meldingen
- Luchtstroommeldingen: de sleutel tot een soepele workflow
- E-mailberichten
- Slack-meldingen
- Airflow SLA's: op schema blijven en toezeggingen nakomen
- Conclusie
- Aanvullende bronnen voor meer informatie over Airflow
Wat is luchtstroom?
Laten we eerst eens definiëren wat Airflow is. Airflow is een gratis tool waarmee u uw workflows of datapijplijnen kunt automatiseren en beheren. Hiermee kunt u workflows maken en plannen, dit zijn een reeks taken die in een specifieke volgorde moeten worden uitgevoerd. Met Airflow automatiseer je eenvoudig repetitieve taken, zoals data-extractie, transformatie en laden. Dit kan u veel tijd en moeite besparen, omdat u deze taken niet elke keer handmatig hoeft uit te voeren.
Airbnb ontwikkelde het concept van luchtstroom voor het eerst in oktober 2014. Ze maakten luchtstroom om hun steeds complexere workflows te beheren. Later sloot het project zich in maart 2016 aan bij het Incubator-programma van de Apache Software Foundation, en de Foundation kondigde in januari 2019 Apache Airflow aan als een topproject.
Airflow is eenvoudig te gebruiken omdat de taken of workflows in Airflow kunnen worden geschreven met behulp van de programmeertaal Python. Het wordt veel gebruikt op verschillende gebieden, waaronder data-engineering, ETL en machine learning. Bij machine learning biedt Airflow een eenvoudige manier om ks te automatiseren die vaak worden geassocieerd met het bouwen en implementeren van machine learning-modellen.
Hoe kan Airflow worden gebruikt voor machine learning?
Airflow kan worden gebruikt voor machine learning-taken, zoals gegevensvoorverwerking, modeltraining en modelimplementatie. Het helpt om de taken in de juiste volgorde uit te voeren en zorgt ervoor dat de ene taak eerder is voltooid dan de andere. Het biedt ook de mogelijkheid om taken opnieuw te proberen als ze mislukken.
Wat is een DAG?
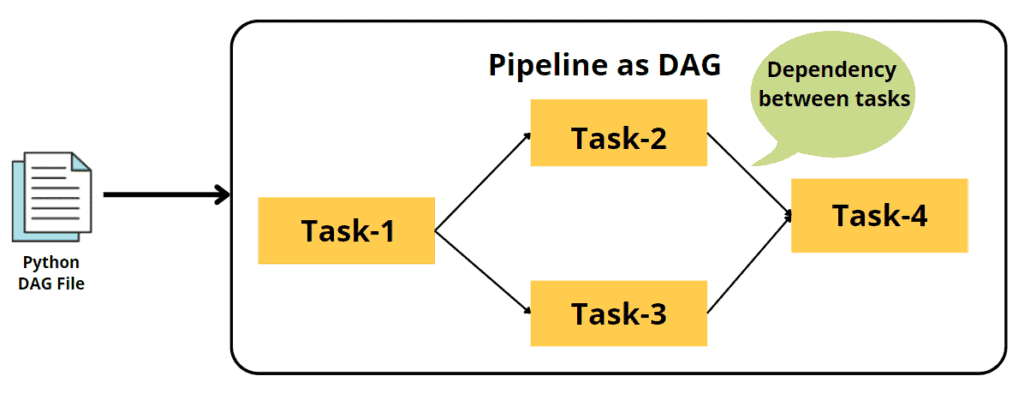
U kunt een DAG zien als een blauwdruk voor uw werk.fDAG, of gerichte acyclische grafiek, is een manier om taken in Airflow te organiseren en weer te geven. Het bestaat uit een reeks taken, vertegenwoordigd door operators, die in een bepaalde volgorde met elkaar verbonden zijn. De taken in een DAG zijn zo georganiseerd dat er geen lussen zijn, waardoor het een "acyclische" grafiek wordt. Wanneer u een DAG uitvoert, voert Airflow de taken uit in de volgorde waarin ze zijn aangesloten. Als taak A bijvoorbeeld moet worden uitgevoerd vóór taak B, koppelt u taak A aan taak B in de DAG. Wanneer u vervolgens de DAG uitvoert, wordt eerst taak A uitgevoerd, gevolgd door taak B. De pijl geeft aan dat taak B en taak C parallel starten nadat taak A is voltooid, en dat taak D wordt gevolgd door taak E.

In de bovenstaande afbeelding is elke taak een operator. Sommige operators van Apache Airflow zijn-
- PythonOperator — voert een python-code uit
- BashOperator — voert bash-scripts uit
- PostgresOperator — voert SQL-query's uit naar een PostgreSQL-database
- EmailOperator — verzendt e-mails
De volledige lijst met operators is hier: https://airflow.apache.org/docs/apache-airflow/stable/_api/airflow/operators/index.html. Een DAG zou bijvoorbeeld taken zijn zoals gegevensextractie, opschoning, voorverwerking, training, implementatie en monitoring in machine learning.
Stapsgewijze handleiding
Luchtstroom installeren
De eerste stap bij het gebruik van Airflow is om het op uw machine te installeren. Airflow kan worden geïnstalleerd met behulp van pip, een pakketbeheerder voor Python. Om Airflow te installeren, moet u Python en pip op uw machine installeren. Zodra je deze hebt, kun je de volgende opdracht uitvoeren om Airflow te installeren:
pip installeer apache-airflow
Initialiseer de Airflow-database
Nadat Airflow is geïnstalleerd, kunt u de database initialiseren door de volgende opdracht uit te voeren:
luchtstroom initdb
"airflow initdb" is een opdracht die de database voor Airflow instelt. Het creëert de nodige mappen om informatie over de taken en workflows of DAG op te slaan. Deze opdracht moet één keer worden uitgevoerd voordat Airflow wordt gebruikt; het helpt de tool om te weten waar de informatie moet worden opgeslagen die het zal verzamelen en volgen.
Maak een DAG
Om de taken in Airflow te definiëren, moet u een Python-bestand maken met de naam DAG (Directed Acyclic Graph) en uw taken definiëren met behulp van Python-functies. Elke taak wordt gedefinieerd met behulp van de "PythonOperator", waarmee u een Python-functie als een taak kunt uitvoeren.
Hier is een voorbeeld van hoe u een DAG kunt maken voor machine learning-taken in Airflow:
from airflow import DAG from airflow.operators.python_operator import PythonOperator from datetime import datetime, timedelta # Definieer default_args woordenboek om door te geven aan de DAG default_args = { 'owner': 'me', 'start_date': datetime(2022, 1, 1) , 'depends_on_past': False, 'retry's': 1, 'retry_delay': timedelta(minuten=5) } # Instantieer een DAG dag = DAG( 'machine_learning_pipeline', default_args=default_args, schedule_interval=timedelta(days=1) # Uitvoeren de pijplijn elke dag) # Definieer een taak voor data preprocessing def data_preprocessing(): # Uw code voor data preprocessing komt hier pass data_preprocessing_task = PythonOperator( task_id='data_preprocessing', python_callable=data_preprocessing, dag=dag ) # Definieer een taak voor training def training(): # Uw code voor training komt hier pass training_task = PythonOperator( task_id='training', python_callable=training, dag=dag ) # Definieer een taak voor implementatie def deployment(): # Uw code voor implementatie komt hier pass deployment_task = PythonO perator( task_id='deployment', python_callable=deployment, dag=dag )
In het bovenstaande codevoorbeeld maken we een pijplijn voor machine learning-taken met behulp van Airflow. Deze pijplijn omvat drie taken: gegevensvoorverwerking, training en implementatie.
Eerst importeren we de benodigde modules uit Airflow. De klasse "DAG" maakt een pijplijn en "PythonOperator" definieert een taak als een python-functie. We importeren ook de klassen "datetime" en "timedelta" die worden gebruikt om het schema-interval en de startdatum van de pijplijn in te stellen.
Vervolgens definiëren we enkele standaardinstellingen voor de pijplijn door een woordenboek te maken met de naam "default_args". Dit woordenboek bevat instellingen zoals de persoon die verantwoordelijk is voor de pijplijn, de startdatum en het geplande interval voor het uitvoeren van de pijplijn, het aantal nieuwe pogingen en de vertraging bij nieuwe pogingen in geval van fouten. De "start_date" is ingesteld op de huidige datum, de "depends_on_past" is ingesteld op "False", wat betekent dat de pijplijn niet afhankelijk is van de vorige runs, en het "schedule_interval" is ingesteld op "time_delta(days=1) ”, wat betekent dat de pijpleiding elke dag zal lopen.
Daarna maken we een instantie van de DAG-klasse, de belangrijkste container voor onze pijplijn. We geven het een naam, "machine_learning_pipeline", en we stellen de standaardinstellingen en het schema-interval in dat we eerder hebben gedefinieerd.
Vervolgens definiëren we elk van de drie taken met behulp van de klasse PythonOperator. Met deze klasse kunnen we een Python-functie als een taak uitvoeren. Elke taak wordt gedefinieerd met een unieke task_id en een verwijzing naar de DAG. De taak "data_preprocessing" neemt geen invoer en retourneert geen uitvoer; het verwerkt de gegevens gewoon voor. De taak "training" neemt de voorverwerkte gegevens als invoer, traint een model en retourneert het getrainde model. De taak "implementatie" neemt het getrainde model als invoer en implementeert het.
Ten slotte stellen we de volgorde van de taken in met behulp van de set_upstream-methode, zodat eerst de gegevensvoorverwerkingstaak wordt uitgevoerd, gevolgd door de trainingstaak en vervolgens de implementatietaak. Zo weet Airflow in welke volgorde de taken moeten worden uitgevoerd.
Stel de afhankelijkheden tussen taken in
# Stel de volgorde van de taken in training_task.set_upstream(data_preprocessing_task) deployment_task.set_upstream(training_task)
Door de "set_upstream"-methode voor elke taak aan te roepen, specificeren we dat de "training"-taak pas mag worden uitgevoerd nadat de "data_preprocessing"-taak is voltooid en dat de "deployment"-taak pas mag worden uitgevoerd nadat de "training"-taak is voltooid .
Dit is een eenvoudig voorbeeld van het gebruik van Airflow om een pijplijn te maken voor machine learning-taken. U kunt meer taken en functionaliteiten toevoegen op basis van uw vereisten en de web-UI van Airflow gebruiken om de pijplijn te bewaken en te beheren. U kunt ook triggers toevoegen en de e-mailmelding en andere functies van Airflow instellen om de pijplijn robuust en beheersbaar te maken.
Het runnen van de pijplijn
Na het instellen van de vereisten, zou de volgende stap zijn om de pijplijn uit te voeren. Om een pijplijn te starten, kunt u de opdracht "airflow run" gebruiken, gevolgd door de naam van de DAG en de taaknaam.
luchtstroom uitgevoerd machine_learning_pipeline data_preprocessing
Deze opdracht activeert de uitvoering van de "data_preprocessing"-taak en vervolgens worden de "training"- en "deployment"-taken uitgevoerd, aangezien deze afhankelijk zijn van de "data_preprocessing"-taak.
Start de Airflow-webserver
Terwijl de pijplijn loopt, kunt u de voortgang volgen met behulp van de Airflow web-UI. Dit is toegankelijk door te rennen
luchtstroom webserver
In de webinterface van Airflow ziet u een lijst met uw DAG's en de status van elke taak. U kunt ook de logboeken voor elke taak bekijken, wat handig kan zijn bij het oplossen van problemen.

Daarnaast kunt u ook plannen dat uw pijplijn automatisch op specifieke tijden wordt uitgevoerd of dat deze wordt geactiveerd op basis van een externe gebeurtenis, bijvoorbeeld wanneer een nieuw bestand wordt toegevoegd aan een specifieke map. Dit kan u de moeite besparen om de pijplijn elke keer handmatig te activeren en ervoor te zorgen dat de pijplijn werkt, zelfs als u niet in de buurt bent.
Luchtstroommeldingen - Houd uw pijpleidingen in de gaten
Luchtstroommeldingen zijn een coole functie die u laat weten wat er met uw pijpleidingen gebeurt. U kunt ze instellen om updates over de status van uw pijplijn te ontvangen en zelfs meldingen te ontvangen als er iets misgaat. Op deze manier kunt u snel eventuele problemen oplossen. Deze meldingen kunnen op verschillende manieren worden verzonden, zoals e-mail, speling of aangepaste webhooks
Waarom hebben we meldingen nodig?
Meldingen helpen bij foutopsporing. Ze houden u op de hoogte van wat er met uw pijplijn gebeurt, zodat u eventuele problemen snel kunt opsporen en oplossen.
Meldingsniveaus
Airflow heeft drie verschillende meldingsniveaus: geslaagd, mislukt en opnieuw proberen. Succesmeldingen worden verzonden wanneer een taak zonder problemen is voltooid, foutmeldingen worden verzonden wanneer een taak niet werkt zoals verwacht en meldingen voor opnieuw proberen worden verzonden wanneer een taak opnieuw wordt geprobeerd.
Meldingstriggers
Airflow heeft een ingebouwd triggersysteem waarmee u meldingen kunt instellen op basis van verschillende omstandigheden. U kunt bijvoorbeeld instellen dat er een melding wordt verzonden wanneer een taak te lang duurt om te voltooien of wanneer een taak mislukt.
Aangepaste Meldingen
Met Airflow kunt u ook aangepaste meldingen maken. U kunt bijvoorbeeld een melding maken die een bericht naar een slap kanaal of uw e-mail stuurt. U kunt instellen dat deze aangepaste meldingen worden verzonden wanneer aan bepaalde voorwaarden is voldaan.
Luchtstroommeldingen: de sleutel tot een soepele workflow
Luchtstroommeldingen zijn een geweldige manier om op de hoogte te blijven van wat er met uw pijpleidingen gebeurt. Er zijn verschillende manieren om meldingen te verzenden, zoals e-mail of speling. In dit gedeelte worden twee populaire methoden besproken: e-mail en slappe meldingen.
E-mailberichten

E-mailmeldingen zijn een geweldige manier om updates over uw Airflow-taken te ontvangen, vooral als er iets misgaat. Om e-mailmeldingen in te stellen, moet u uw SMTP-instellingen (Simple Mail Transfer Protocol) configureren in het Airflow-configuratiebestand. Dit omvat doorgaans uw e-mailadres, serveradres en inloggegevens.
Zodra u uw SMTP-instellingen heeft ingesteld, kunt u de "email_opearator" gebruiken om een e-mail te sturen wanneer een bepaalde gebeurtenis plaatsvindt. Hier is een voorbeeld van hoe u de "email_opearator" zou kunnen gebruiken om een e-mail te sturen wanneer een taak mislukt:
from airflow.operators.email_operator import EmailOperator task_fail_email = EmailOperator( task_id='send_failure_email', to='[e-mail beveiligd]', subject='Airflow-taak mislukt', html_content='Taak {{ task_instance.task_id }} mislukt', trigger_rule='one_failed', dag=dag) task >> task_fail_email
In dit voorbeeld is de operator "task_fail_email" ingesteld om een e-mail naar uw e-mailadres te sturen wanneer de voorgaande taak, "taak", mislukt. Het veld "aan" is ingesteld op uw e-mailadres, het veld "onderwerp" is ingesteld op "Airflow-taak mislukt" en het veld "html_contrent" is ingesteld om de ID van de mislukte taak op te nemen. De "trigger_rule" is ingesteld op "one_failed", wat betekent dat de e-mail wordt verzonden wanneer een taak mislukt. De operator is ook verbonden met de dag zodat deze kan lopen wanneer de dag loopt.
Het is ook mogelijk om een e-mail te sturen wanneer een taak met succes of volgens een bepaald schema is voltooid. Meer informatie over het configureren van de e-mailoperator vindt u in de Airflow-documentatie: https://airflow.apache.org/docs/apache-airflow/stable/howto/email-config.html
Slack-meldingen

Slack-meldingen zijn een andere geweldige manier om updates over uw Airflow-taken te ontvangen. Om Slack-meldingen in te stellen, moet u een inkomende webhook maken in uw Slack-werkruimte. Dit geeft je een unieke URL die je kunt gebruiken om berichten naar een specifiek kanaal in je werkruimte te sturen.
Zodra u uw inkomende webhook-URL heeft, kunt u de "SlackWebhookOperator" gebruiken om een bericht naar een Slack-kanaal te sturen wanneer een bepaalde gebeurtenis plaatsvindt. Hier is een voorbeeld van hoe u de "SlackWebhookOperator" zou kunnen gebruiken om een bericht naar een Slack-kanaal te sturen wanneer een taak mislukt:
van airflow.contrib.operators.slack_webhook_operator SlackWebhookOperator importeren task_fail_slack = SlackWebhookOperator( task_id='send_failure_slack', http_conn_id='slack', webhook_token=SLACK_WEBHOOK_TOKEN, message='Taak {{task_instance.task_id}} mislukt', trigger_rule='one_failed', dag=dag) taak >> task_fail_slack
In dit voorbeeld stellen we een Slack-melding in om een bericht naar een specifiek kanaal in onze Slack-werkruimte te sturen wanneer een taak mislukt. We gebruiken hiervoor de "SlackWebhookOperator". We hebben de melding de task_id van 'send_failure_slack' gegeven en gespecificeerd dat het de verbinding met de naam 'slack' moet gebruiken die we eerder hebben opgezet. We hebben ook het inkomende webhook-token verstrekt dat we hebben gegenereerd en gespecificeerd dat het bericht de ID van de mislukte taak moet bevatten. Ten slotte hebben we de triggerregel ingesteld op 'one_failed', wat inhoudt dat het bericht alleen wordt verzonden als één taak mislukt. De operator is ook verbonden met de dag zodat deze kan lopen wanneer de dag loopt.
Het is ook mogelijk om een bericht te sturen wanneer een taak met succes of volgens een bepaald schema is voltooid. Meer informatie over het configureren van de Slack-operator vindt u in de Airflow-documentatie:
https://airflow.apache.org/docs/apache-airflow-providers-slack/stable/_api/airflow/providers/slack/operators/slack/index.html
Airflow SLA's: op schema blijven en toezeggingen nakomen
Met Airflow kunnen we Service Level Agreements (SLA's) opstellen voor onze taken en workflows. Een SLA is een set regels die een taak of workflow moet volgen, en als deze niet voldoet aan de SLA, zullen we hiervan op de hoogte worden gesteld. Op deze manier kunnen we ervoor zorgen dat onze machine learning-taken goed verlopen en eventuele problemen oplossen.
Om een SLA in Airflow op te zetten, gebruiken we de parameter "sla" bij het maken van een taak. Als we bijvoorbeeld een SLA van 2 uur willen instellen voor een taak met de naam "mijn_taak", schrijven we:
my_task = BashOperator( task_id='my_task', bash_command='echo "Hello World"', sla=timedelta(hours=2), dag=dag )
Dit stelt de sla van de taak "my_task" in op 2 uur. Bij het maken van de DAG kunnen we ook SLA's instellen voor de hele DAG door de parameter "sla_miss_callback" te gebruiken. Deze parameter heeft een functie die wordt aangeroepen wanneer niet aan de SLA van de DAG wordt voldaan. Op deze manier kunnen we worden gewaarschuwd als er zich problemen voordoen en deze tijdig oplossen.
Conclusie
Uiteindelijk kunnen we zeggen dat het een geweldige tool is die ons kan helpen onze machine-learningtaken uit te voeren en soepel te laten verlopen. We hebben geleerd hoe we onze taken kunnen instellen en afhankelijk van elkaar kunnen maken, hoe we ze kunnen plannen, SLA kunnen instellen en hoe we meldingen kunnen ontvangen als er iets misgaat. Door deze handleiding te lezen, zou u nu moeten begrijpen hoe u deze kunt gebruiken voor uw machine-learningtaken. Het is een krachtige tool die tijd kan besparen en uw werk efficiënter kan maken, dus wees niet bang om het uit te proberen. Hier zijn enkele van de belangrijkste afhaalrestaurants uit mijn artikel:
Key Takeaways
- Het is een krachtige tool voor het beheren en plannen van machine learning-taken.
- Het maken van een DAG is de eerste stap voor machine learning-taken.
- Meldingen en SLA's zijn essentieel voor het bewaken en oplossen van machine learning-taken.
- E-mail en Slack zijn populaire methoden om meldingen te ontvangen.
- Het aanpassen van meldingen en SLA's aan uw specifieke use case is eenvoudig.
- Door een geheel nieuw bewakings- en waarschuwingssysteem op te bouwen met behulp van de meldings- en SLA-functies van Airflow, kunt u de efficiëntie en betrouwbaarheid van uw machine learning-pijplijn verhogen.
Resources
De Airflow-documentatie: De officiële documentatie https://airflow.apache.org/docs/apache-airflow/stable/index.html is een uitgebreide bron die alle aspecten omvat, van installatie tot geavanceerd gebruik. Het is een prima startpunt om meer te weten te komen over de basisprincipes van Airflow.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/02/monitoring-and-alerting-system-using-airflow/

