Novo Nordisk is een toonaangevend wereldwijd farmaceutisch bedrijf, verantwoordelijk voor de productie van levensreddende medicijnen die dagelijks meer dan 34 miljoen patiënten bereiken. Ze doen dit volgens hun drievoudige bottom line: dat ze ernaar moeten streven ecologisch duurzaam, sociaal duurzaam en financieel duurzaam te zijn. De combinatie van het gebruik van AWS en data ondersteunt al deze doelen.
Gegevens zijn alomtegenwoordig in de gehele waardeketen van Novo Nordisk. Van fundamenteel onderzoek, productielijnen, verkoop en marketing, klinische proeven, geneesmiddelenbewaking tot patiëntgerichte datagestuurde toepassingen. Daarom is het verkrijgen van de basis van hoe gegevens worden opgeslagen, beveiligd en gebruikt op een manier die de meeste waarde oplevert, een van de belangrijkste drijfveren voor verbeterde bedrijfsresultaten.
Samen met AWS professionele services, bouwen we een data- en analyseoplossing met behulp van een moderne data-architectuur. De samenwerking tussen Novo Nordisk en AWS Professional Services is een strategische en langdurige nauwe samenwerking, waarbij ontwikkelaars van beide organisaties al jaren nauw samenwerken. De data- en analyseomgevingen zijn gebouwd rond de kernprincipes van de datamesh: gedecentraliseerd domeineigendom van data, data als een product, selfservice data-infrastructuur en gefedereerd computationeel bestuur. Hierdoor kunnen de gebruikers van de omgeving met gegevens werken op een manier die de beste bedrijfsresultaten oplevert. We hebben dit gecombineerd met elementen uit evolutionaire architecturen waarmee we verschillende functionaliteiten kunnen aanpassen terwijl AWS voortdurend nieuwe diensten en mogelijkheden ontwikkelt.
In deze reeks posts leer je hoe Novo Nordisk en AWS Professional Services een data- en analyse-ecosysteem hebben gebouwd om innovatie op petabyte-schaal te versnellen:
- In dit eerste bericht leer je hoe het algehele ontwerp ervoor heeft gezorgd dat de afzonderlijke componenten op een modulaire manier samenkomen. We duiken diep in hoe we een datamanagementoplossing hebben gebouwd op basis van de datamesh-architectuur.
- In het tweede bericht wordt besproken hoe we een vertrouwensnetwerk hebben opgebouwd tussen de systemen die de volledige oplossing vormen. We laten zien hoe we gebeurtenisgestuurde architecturen gebruiken, gekoppeld aan het gebruik van op attributen gebaseerde toegangscontroles, om ervoor te zorgen dat permissiegrenzen op grote schaal worden gerespecteerd.
- In het derde bericht laten we zien hoe eindgebruikers gegevens kunnen consumeren uit hun tool naar keuze, zonder dat dit ten koste gaat van het gegevensbeheer. Dit omvat hoe Okta te configureren, AWS Lake-formatie, en Microsoft Power BI om op SAML gebaseerd gefedereerd gebruik van Amazone Athene voor een enterprise business intelligence (BI) activiteit.
Farmaceutische omgeving
Als farmaceutische industrie is GxP-naleving een mandaat voor Novo Nordisk. GxP is een algemene afkorting voor de "Good x Practice"-kwaliteitsrichtlijnen en -regelgeving die zijn gedefinieerd door regelgevers zoals het Europees Geneesmiddelenbureau, de Amerikaanse Food and Drug Administration en anderen. Deze richtlijnen zijn opgesteld om ervoor te zorgen dat geneesmiddelen veilig en effectief zijn voor het beoogde gebruik. In de context van een gegevensomgeving omvat GxP-compliance het implementeren van integriteitscontroles voor gegevens die worden gebruikt bij besluitvorming en processen en wordt het gebruikt om te begeleiden hoe verandermanagementprocessen worden geïmplementeerd om continu naleving in de loop van de tijd te garanderen.
Omdat deze data-omgeving teams in de hele organisatie ondersteunt, moet elke individuele data-eigenaar verantwoordelijk blijven voor zijn data. Functies zijn ontworpen om gegevenseigenaren autonomie en transparantie te bieden bij het beheer van hun gegevens, zodat ze deze verantwoordelijkheid kunnen nemen. Dit omvat de mogelijkheid om persoonlijk identificeerbare informatie (PII)-gegevens en andere gevoelige workloads te verwerken. Om traceerbaarheid van de omgeving te bieden, zijn auditmogelijkheden toegevoegd, die we in dit bericht meer beschrijven.
Overzicht oplossingen
De volledige oplossing is een uitgestrekt landschap van onafhankelijke services die samenwerken om data en analyses mogelijk te maken met een gedecentraliseerd data governance-model op petabyte-schaal. Schematisch kan het worden weergegeven zoals in de volgende afbeelding.

De architectuur is opgesplitst in drie onafhankelijke lagen: databeheer, virtualisatie en consumptie. De eindgebruiker zit in de consumptielaag en werkt met zijn favoriete tool. Het is bedoeld om zoveel mogelijk van de AWS-native bronnen te abstraheren naar applicatie-primitieven. De verbruikslaag is geïntegreerd in de virtualisatielaag, die de toegang tot data abstraheert. Het doel van de virtualisatielaag is de vertaalslag te maken tussen dataconsumptie en datamanagementoplossingen. De toegang tot gegevens wordt beheerd door wat we datamanagementoplossingen noemen. We bespreken later in dit bericht een van onze veelzijdige oplossingen voor gegevensbeheer. Elke laag in deze architectuur is onafhankelijk van elkaar en vertrouwt in plaats daarvan alleen op goed gedefinieerde interfaces.
Centraal in deze architectuur staat dat de toegang is ingekapseld in een AWS Identiteits- en toegangsbeheer (IAM) rollensessie. De gegevensbeheerlaag richt zich op het voorzien van de IAM-rol van de juiste machtigingen en governance, de virtualisatielaag biedt toegang tot de rol en de verbruikslaag abstraheert het gebruik van de rollen in de tools naar keuze.
Technische architectuur
Elk van de drie lagen in de algehele architectuur heeft een eigen verantwoordelijkheid, maar geen enkele implementatie. Zie ze als abstracte klassen. Ze kunnen worden geïmplementeerd in concrete klassen en in ons geval vertrouwen ze op fundamentele AWS-services en -mogelijkheden. Laten we elk van de drie lagen doornemen.
Datamanagement laag
De datamanagementlaag is verantwoordelijk voor het ontsluiten en beheren van data. Zoals geïllustreerd in het volgende diagram, is een minimale constructie in de gegevensbeheerlaag de combinatie van een Amazon eenvoudige opslagservice (Amazon S3) bucket en een IAM rol die toegang geeft tot de S3 bucket. Deze constructie kan worden uitgebreid met granulaire toestemming met Lake Formation, auditing met AWS CloudTrail, en mogelijkheden voor beveiligingsreacties van AWS-beveiligingshub. Het volgende diagram laat ook zien dat een enkele datamanagementoplossing geen enkelvoudig bereik heeft. Het kan vele AWS-accounts kruisen en kan bestaan uit een willekeurig aantal IAM-rolcombinaties.
We hebben met opzet het vertrouwensbeleid van deze rollen niet geïllustreerd in deze figuur, omdat deze een gezamenlijke verantwoordelijkheid zijn tussen de virtualisatielaag en de gegevensbeheerlaag. We gaan in detail in op hoe dat werkt in de volgende post in deze serie. Professionals op het gebied van data-engineering staan vaak rechtstreeks in verbinding met de databeheerlaag, waar ze data cureren en voorbereiden voor gebruik.
Virtualisatie laag
Het doel van de virtualisatielaag is om bij te houden wie wat kan doen. Het heeft zelf geen mogelijkheden, maar vertaalt de eisen van de datamanagementecosystemen naar de verbruikslagen en vice versa. Het stelt eindgebruikers op de consumptielaag in staat om toegang te krijgen tot gegevens op een of meer gegevensbeheerecosystemen en deze te manipuleren, op basis van hun toestemmingen. Deze laag abstraheert van eindgebruikers de technische details over gegevenstoegang, zoals toestemmingsmodel, rolaannames en opslaglocatie. Het bezit de interfaces naar de andere lagen en dwingt de logica van de abstractie af. In de context van hexagonale architecturen (zie Evolutionaire architectuur ontwikkelen met AWS Lambda), speelt de interfacelaag de rol van de domeinlogica, poorten en adapters. De andere twee lagen zijn acteurs. De gegevensbeheerlaag communiceert de status van de laag naar de virtualisatielaag en ontvangt omgekeerd informatie over het te vertrouwen servicelandschap. De architectuur van de virtualisatielaag wordt weergegeven in het volgende diagram.

Verbruikslaag
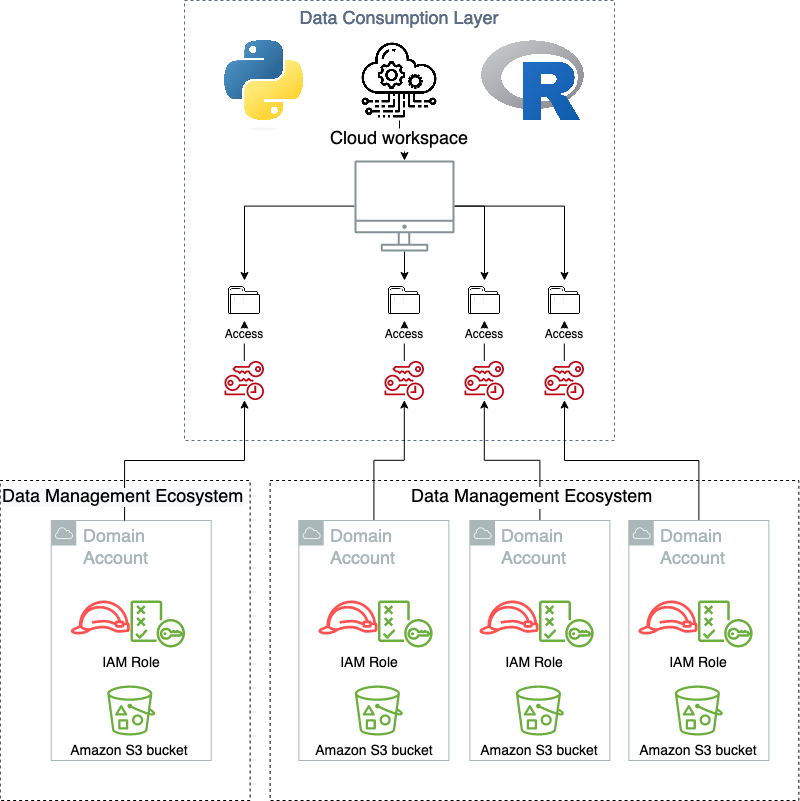
De verbruikslaag is waar de eindgebruikers van de dataproducten zitten. Dit kunnen datawetenschappers, business intelligence-analisten of een derde partij zijn die waarde genereert door het consumeren van de data. Het is belangrijk voor dit type architectuur dat de verbruikslaag een op een hook gebaseerde aanmeldingsstroom heeft, waarbij de autorisatie in de toepassing tijdens het aanmelden kan worden gewijzigd. Dit is om de AWS-specifieke vereisten te vertalen naar de doelapplicaties. Nadat de sessie in de client-side applicatie met succes is gestart, is het aan de applicatie zelf om te instrumenteren voor datalaag-abstractie, omdat dit applicatiespecifiek zal zijn. En dit is een extra belangrijke ontkoppeling, waarbij een deel van de verantwoordelijkheid bij de gedecentraliseerde eenheden wordt geschoven. Veel moderne software as a service (SaaS)-applicaties ondersteunen deze ingebouwde mechanismen, zoals Databricks or Domino Datalab, terwijl meer traditionele client-side applicaties zoals RStudio-server hebben hiervoor een beperktere native ondersteuning. In het geval dat native ondersteuning ontbreekt, kan een vertaling naar de OS-gebruikerssessie worden gedaan om de abstractie mogelijk te maken. In onderstaand schema is de verbruikslaag schematisch weergegeven.

Wanneer de verbruikslaag wordt gebruikt zoals bedoeld, weten de gebruikers niet dat de virtualisatielaag bestaat. Het volgende diagram illustreert de patronen voor gegevenstoegang.
modulariteit
Een van de belangrijkste voordelen van het adopteren van het hexagonale architectuurpatroon en het delegeren van zowel de verbruikende laag als de gegevensbeheerlaag aan primaire en secundaire actoren, betekent dat ze kunnen worden gewijzigd of vervangen wanneer nieuwe functionaliteiten worden uitgebracht die nieuwe oplossingen vereisen. Dit geeft een hub-and-spoke-type patroon, waar veel verschillende typen producenten/consumentensystemen kunnen worden aangesloten en tegelijkertijd kunnen samenwerken. Een voorbeeld hiervan is dat de huidige oplossing die in Novo Nordisk draait meerdere, gelijktijdige datamanagementoplossingen ondersteunt en op een homogene manier in de consumerende laag wordt weergegeven. Dit omvat zowel een datameer, de datamesh-oplossing die in dit bericht wordt gepresenteerd, als verschillende onafhankelijke oplossingen voor gegevensbeheer. En deze worden blootgesteld aan meerdere soorten consumerende applicaties, van op maat beheerde, zelfgehoste applicaties tot SaaS-aanbiedingen.
Ecosysteem voor gegevensbeheer
Om het gebruik van de data te schalen en de vrijheid te vergroten, heeft Novo Nordisk, samen met AWS Professional Services, een datamanagement- en governance-omgeving gebouwd, genaamd Novo Nordisk Enterprise DataHub (NNEDH). NNEDH implementeert een gedecentraliseerde gedistribueerde gegevensarchitectuur en gegevensbeheermogelijkheden, zoals een bedrijfsgegevenscatalogus en een werkstroom voor het delen van gegevens. NNEDH is een voorbeeld van een datamanagementecosysteem in het eerder geïntroduceerde conceptuele kader.
Gedecentraliseerde architectuur: van een gecentraliseerd datameer naar een gedistribueerde architectuur
Het gecentraliseerde datameer van Novo Nordisk bestaat uit 2.3 PB aan data uit meer dan 30 zakelijke datadomeinen over de hele wereld en bedient meer dan 2000 interne gebruikers in de hele waardeketen. Het draait al enkele jaren met succes. Het is een van de ecosystemen voor gegevensbeheer die momenteel worden ondersteund.
Binnen de gecentraliseerde data-architectuur worden data van elk datadomein gekopieerd, opgeslagen en verwerkt op één centrale locatie: een centraal datameer dat wordt gehost in één dataopslag. Dit patroon heeft uitdagingen op schaal omdat het eigendom van de gegevens bij het centrale team blijft. Op grote schaal vertraagt dit model de reis naar een datagedreven organisatie, omdat het eigenaarschap van de data niet voldoende verankerd is bij de professionals die het dichtst bij het domein staan.
De monolithische data lake-architectuur wordt weergegeven in het volgende diagram.
Binnen de gedecentraliseerde gedistribueerde gegevensarchitectuur worden de gegevens van elk domein binnen het domein bewaard op een eigen gegevensopslag- en rekenaccount. In dit geval worden de gegevens dicht bij domeinexperts gehouden, omdat zij degenen zijn die hun eigen gegevens het beste kennen en uiteindelijk de eigenaar zijn van alle gegevensproducten die rond hun gegevens zijn gebouwd. Zij werken vaak nauw samen met business analisten om het dataproduct te bouwen en weten daardoor wat goede data betekent voor consumenten van hun dataproducten. In dit geval is de gegevensverantwoordelijkheid ook gedecentraliseerd, waarbij elk domein zijn eigen gegevenseigenaar heeft, waardoor de verantwoordelijkheid bij de echte eigenaren van de gegevens ligt. Desalniettemin werkt dit model mogelijk niet op kleine schaal, bijvoorbeeld een organisatie met slechts één bedrijfseenheid en tientallen gebruikers, omdat het meer overhead zou introduceren bij het IT-team om de organisatiegegevens te beheren. Het past beter bij grote organisaties, of kleine en middelgrote organisaties die willen groeien en schalen.
De datamesh-architectuur van Novo Nordisk wordt weergegeven in het volgende diagram.

Gegevensdomeinen en gegevensactiva
Om de schaalbaarheid van gegevensdomeinen in de hele organisatie mogelijk te maken, is het verplicht om een standaard machtigingsmodel en gegevenstoegangspatroon te hebben. Deze standaard mag niet zo beperkend zijn dat het een blocker kan zijn voor specifieke use cases, maar wel zodanig gestandaardiseerd dat dezelfde interface tussen de datamanagement- en virtualisatielaag wordt gebruikt.
De gegevensdomeinen op NNEDH worden geïmplementeerd door een constructie genaamd an milieu. Een omgeving bestaat uit minimaal één AWS-account en één AWS-regio. Het is een werkplek waar datadomeinteams kunnen werken en samenwerken om dataproducten te bouwen. Het koppelt het NNEDH-besturingsvlak aan de AWS-accounts waar de gegevens en rekenkracht van het domein zich bevinden. De machtigingen voor gegevenstoegang worden ook gedefinieerd op omgevingsniveau, beheerd door de eigenaar van het gegevensdomein. De omgevingen hebben drie hoofdcomponenten: een gegevensbeheer- en governancelaag, gegevensactiva en optionele blauwdrukken voor gegevensverwerking.
Voor gegevensbeheer en -beheer vertrouwen de gegevensdomeinen op Lake Formation, AWS lijmen CloudTrail. De implementatiemethode en configuratie van deze componenten is gestandaardiseerd voor alle datadomeinen. Op deze manier kan het NNEDH-besturingsvlak op een gestandaardiseerde manier connectiviteit en beheer bieden voor datadomeinen.
De data-assets van elk domein dat zich in een omgeving bevindt, zijn georganiseerd in een dataset, een verzameling gerelateerde data die wordt gebruikt voor het bouwen van een dataproduct. Het omvat technische metadata zoals gegevensformaat, grootte en aanmaaktijd, en zakelijke metadata zoals de producent, gegevensclassificatie en bedrijfsdefinitie. Een dataproduct kan gebruik maken van één of meerdere datasets. Het wordt geïmplementeerd via beheerde S3-buckets en de AWS Glue Data Catalog.
Gegevensverwerking kan op verschillende manieren worden geïmplementeerd. NNEDH biedt blauwdrukken voor datapijplijnen met vooraf gedefinieerde connectiviteit met data-assets om de levering van dataproducten te versnellen. Gebruikers van datadomeinen hebben de vrijheid om elke andere rekenmogelijkheid op hun domein te gebruiken, bijvoorbeeld door gebruik te maken van AWS-services die niet vooraf zijn gedefinieerd op de blauwdrukken of door toegang te krijgen tot de datasets van andere analysetools die in de verbruikslaag zijn geïmplementeerd, zoals eerder in dit bericht vermeld.
Data domein persona's en rollen
Op NNEDH worden de machtigingsniveaus op datadomeinen beheerd via vooraf gedefinieerde persona's, bijvoorbeeld data-eigenaar, datastewards, ontwikkelaars en lezers. Elke persona is gekoppeld aan een IAM-rol met een vooraf gedefinieerd machtigingsniveau. Deze machtigingen zijn gebaseerd op de typische behoeften van gebruikers op deze rollen. Niettemin, om meer flexibiliteit te geven aan datadomeinen, kunnen deze machtigingen indien nodig worden aangepast en uitgebreid.
De machtigingen die aan elke persona zijn gekoppeld, hebben alleen betrekking op acties die zijn toegestaan op het AWS-account van het gegevensdomein. Voor de verantwoording van gegevensactiva wordt de gegevenstoegang tot de activa beheerd door specifiek resourcebeleid in plaats van IAM-rollen. Alleen de eigenaar van elke dataset, of door de eigenaar gedelegeerde datastewards, kunnen datatoegang verlenen of intrekken.
Op datasetniveau is een vereiste persona de data-eigenaar. Meestal werken ze nauw samen met een of meer datastewards als dataproductmanagers. De data steward is de data subject matter expert van het dataproductdomein, verantwoordelijk voor het interpreteren van verzamelde data en metadata om diepgaande zakelijke inzichten te verkrijgen en het product te bouwen. De datasteward slaat een brug tussen zakelijke gebruikers en technische teams op elk datadomein.
Enterprise bedrijfsgegevenscatalogus
Om vrijheid mogelijk te maken en de gegevensactiva van de organisatie vindbaar te maken, is een webgebaseerde portalgegevenscatalogus geïmplementeerd. Het indexeert in een enkele repository metadata van datasets die zijn gebouwd op datadomeinen, waardoor datasilo's in de hele organisatie worden doorbroken. De gegevenscatalogus maakt het zoeken en ontdekken van gegevens in verschillende domeinen mogelijk, evenals automatisering en beheer van het delen van gegevens.
De bedrijfsdatacatalogus implementeert data governance processen binnen de organisatie. Het zorgt voor het eigendom van de gegevens: iemand in de organisatie is verantwoordelijk voor de oorsprong, definitie, zakelijke kenmerken, relaties en afhankelijkheden van de gegevens.
De centrale constructie van een bedrijfsdatacatalogus is een dataset. Het is de zoekeenheid binnen de bedrijfscatalogus, met zowel technische als zakelijke metadata. Om technische metadata van gestructureerde data te verzamelen, vertrouwt het op AWS Glue-crawlers om datastructuren te herkennen en te extraheren uit de meest populaire dataformaten, waaronder CSV, JSON, Avro en Apache Parquet. Het biedt informatie zoals het gegevenstype, de aanmaakdatum en het formaat. De metadata kunnen door zakelijke gebruikers worden verrijkt door een beschrijving van de zakelijke context, tags en dataclassificatie toe te voegen.
De datasetdefinitie en gerelateerde metadata worden opgeslagen in een Amazon Aurora zonder server database en Amazon OpenSearch-service, waarmee u tekstuele query's op de gegevenscatalogus kunt uitvoeren.
Het delen van gegevens
NNEDH implementeert een workflow voor het delen van gegevens, waardoor het peer-to-peer delen van gegevens tussen AWS-accounts mogelijk wordt gemaakt met behulp van Lake Formation. De werkstroom is als volgt:
- Een dataconsument vraagt toegang tot de dataset.
- De data-eigenaar verleent toegang door het toegangsverzoek goed te keuren. Zij kunnen de goedkeuring van toegangsverzoeken delegeren aan de datasteward.
- Na goedkeuring van een toegangsverzoek wordt een nieuwe toestemming toegevoegd aan de specifieke dataset in Lake Formation van het producentenaccount.
De workflow voor het delen van gegevens wordt schematisch weergegeven in de volgende afbeelding.

Beveiliging en controle
De gegevens in de Novo Nordisk-datamesh bevinden zich in AWS-accounts die eigendom zijn van zakelijke Novo Nordisk-accounts. De configuratie en de statussen van de data mesh worden opgeslagen in Amazon relationele databaseservice (Amazone RDS). De beveiligingsarchitectuur van Novo Nordisk wordt weergegeven in de volgende afbeelding.

Toegang tot en bewerkingen van de gegevens in NNEDH moeten worden geregistreerd voor auditdoeleinden. We moeten kunnen zien wie gegevens heeft gewijzigd, wanneer de wijziging heeft plaatsgevonden en welke wijzigingen zijn aangebracht. Daarnaast moeten we kunnen beantwoorden waarom de wijziging destijds door die persoon is toegestaan.
Om aan deze vereisten te voldoen, gebruiken we de volgende componenten:
- CloudTrail om API-oproepen te loggen. We maken specifiek CloudTrail-registratie van gegevensgebeurtenissen mogelijk voor S3-buckets en -objecten. Door de logging te activeren, kunnen we eventuele wijzigingen in bestanden in de data lake herleiden tot de persoon die de wijziging heeft aangebracht. We dwingen het gebruik van bron identiteit voor IAM-rolsessies om de traceerbaarheid van gebruikers te garanderen.
- We gebruiken Amazon RDS om de configuratie van de data mesh op te slaan. We registreren query's tegen de RDS-database. Samen met CloudTrail stelt dit log ons in staat om de vraag te beantwoorden waarom een wijziging van een bestand in Amazon S3 op een bepaald moment door een specifiek persoon mogelijk is.
- Amazon Cloud Watch om activiteiten over de mesh te loggen.
Naast deze logboekmechanismen worden de S3-buckets gemaakt met behulp van de volgende eigenschappen:
- De bucket is versleuteld met versleuteling aan de serverzijde met AWS Sleutelbeheerservice (AWS KMS) en door de klant beheerde sleutels
- Amazon S3-versiebeheer is standaard geactiveerd
De toegang tot de gegevens in NNEDH wordt beheerd op groepsniveau in plaats van op individuele gebruikers. De groep komt overeen met de groep die is gedefinieerd in de Novo Nordisk-directorygroep. Om bij te houden wie de gegevens in de datalakes heeft aangepast, gebruiken we het bronidentiteitsmechanisme dat in de post wordt uitgelegd Hoe IAM-rolactiviteit te relateren aan bedrijfsidentiteit.
Conclusie
In dit bericht hebben we laten zien hoe Novo Nordisk een moderne data-architectuur heeft gebouwd om de levering van datagestuurde use-cases te versnellen. Het bevat een gedistribueerde data-architectuur, om het gebruik te schalen naar petabyte-schaal voor meer dan 2,000 interne gebruikers in de hele waardeketen, evenals een gedistribueerde beveiligings- en auditarchitectuur die zorgt voor gegevensverantwoording en traceerbaarheid in de omgeving om te voldoen aan hun nalevingsvereisten.
Het volgende bericht in deze serie beschrijft de implementatie van gedistribueerd databeheer en controle op schaal van de moderne data-architectuur van Novo Nordisk.
Over de auteurs
 Jonatan Selsing is voormalig onderzoeker met een doctoraat in de astrofysica die zich heeft gericht op de cloud. Hij is momenteel de Lead Cloud Engineer bij Novo Nordisk, waar hij data- en analyseworkloads op schaal mogelijk maakt. Met de nadruk op het verlagen van de totale eigendomskosten van cloudgebaseerde workloads, terwijl hij ten volle profiteert van de voordelen van de cloud, ontwerpt, bouwt en onderhoudt hij oplossingen die onderzoek voor toekomstige geneesmiddelen mogelijk maken.
Jonatan Selsing is voormalig onderzoeker met een doctoraat in de astrofysica die zich heeft gericht op de cloud. Hij is momenteel de Lead Cloud Engineer bij Novo Nordisk, waar hij data- en analyseworkloads op schaal mogelijk maakt. Met de nadruk op het verlagen van de totale eigendomskosten van cloudgebaseerde workloads, terwijl hij ten volle profiteert van de voordelen van de cloud, ontwerpt, bouwt en onderhoudt hij oplossingen die onderzoek voor toekomstige geneesmiddelen mogelijk maken.
 Hassen Riahi is Sr. Data Architect bij AWS Professional Services. Hij is gepromoveerd in Wiskunde & Informatica over grootschalig databeheer. Hij werkt samen met AWS-klanten aan het bouwen van datagedreven oplossingen.
Hassen Riahi is Sr. Data Architect bij AWS Professional Services. Hij is gepromoveerd in Wiskunde & Informatica over grootschalig databeheer. Hij werkt samen met AWS-klanten aan het bouwen van datagedreven oplossingen.
 Anwar Rizal is een Senior Machine Learning-consultant gevestigd in Parijs. Hij werkt samen met AWS-klanten om data- en AI-oplossingen te ontwikkelen om hun bedrijf duurzaam te laten groeien.
Anwar Rizal is een Senior Machine Learning-consultant gevestigd in Parijs. Hij werkt samen met AWS-klanten om data- en AI-oplossingen te ontwikkelen om hun bedrijf duurzaam te laten groeien.
 Mozes Arthur heeft een achtergrond in wiskunde en computationeel onderzoek en is gepromoveerd in Computational Intelligence, gespecialiseerd in Graph Mining. Hij is momenteel een Cloud Product Engineer bij Novo Nordisk en bouwt GxP-conforme enterprise data lakes en analyseplatforms voor Novo Nordisk wereldwijde fabrieken die gedigitaliseerde medische producten produceren.
Mozes Arthur heeft een achtergrond in wiskunde en computationeel onderzoek en is gepromoveerd in Computational Intelligence, gespecialiseerd in Graph Mining. Hij is momenteel een Cloud Product Engineer bij Novo Nordisk en bouwt GxP-conforme enterprise data lakes en analyseplatforms voor Novo Nordisk wereldwijde fabrieken die gedigitaliseerde medische producten produceren.
 Alessandro Fior is Sr. Data Architect bij AWS Professional Services. Met meer dan 10 jaar ervaring in het leveren van data- en analyseoplossingen, is hij gepassioneerd door het ontwerpen en bouwen van moderne en schaalbare dataplatforms die bedrijven versnellen om waarde uit hun data te halen.
Alessandro Fior is Sr. Data Architect bij AWS Professional Services. Met meer dan 10 jaar ervaring in het leveren van data- en analyseoplossingen, is hij gepassioneerd door het ontwerpen en bouwen van moderne en schaalbare dataplatforms die bedrijven versnellen om waarde uit hun data te halen.
 Kumari Ramar is een Agile-gecertificeerde en PMP-gecertificeerde Senior Engagement Manager bij AWS Professional Services. Ze levert data- en AI/ML-oplossingen die systeemoverschrijdende analyses en machine learning-modellen versnellen, waardoor ondernemingen datagestuurde beslissingen kunnen nemen en nieuwe innovaties kunnen stimuleren.
Kumari Ramar is een Agile-gecertificeerde en PMP-gecertificeerde Senior Engagement Manager bij AWS Professional Services. Ze levert data- en AI/ML-oplossingen die systeemoverschrijdende analyses en machine learning-modellen versnellen, waardoor ondernemingen datagestuurde beslissingen kunnen nemen en nieuwe innovaties kunnen stimuleren.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://aws.amazon.com/blogs/big-data/how-novo-nordisk-built-a-modern-data-architecture-on-aws/

