Introductie

Leerdoelen:
In dit artikel zullen we:
1. Begrijp het bouwen van een prijsvoorspellingsmodel.
2. het proces van het bouwen van het model begrijpen, zoals gegevensanalyse, selectie, voorspelling, interpretatie, enz.
3. Leer hoe u een weloverwogen beslissing kunt nemen met een bepaalde dataset.
Inhoudsopgave
- De gegevens en de probleemstelling begrijpen
1.1 Probleemstelling
1.2 Gegevensbeschrijving - Gegevensanalyse van prijsvoorspellingsmodel
2.1 Ontbrekende waarden
2.2 Omgaan met de ontbrekende waarden
2.3 Uitschieters
2.4 Verkennende gegevensanalyse
2.5 Model ontwikkeling - Conclusie
De gegevens en de probleemstelling begrijpen
Probleemstelling
De probleemstelling is het voorspellen van de verkoopprijs van een huis, gegeven de kenmerken van het huis. De features zijn de kolommen in de dataset en de doelvariabele is de SalePrice-kolom. Het probleem is een regressieprobleem, aangezien de doelvariabele continu is.
Gegevensbeschrijving
De gegevensbeschrijving is beschikbaar op Kaggle en u kunt deze vinden hier. De gegevensbeschrijving bevat een gedetailleerde beschrijving van elke kolom in de gegevensset. De gegevensbeschrijving is erg handig, omdat deze een gedetailleerde beschrijving geeft van elke kolom in de gegevensset. Het geeft ook informatie over de ontbrekende waarden in de dataset.
Data-analyse van het prijsvoorspellingsmodel
Python-code:
Ontbrekende waarden
# Een lijst maken van kolommen met ontbrekende waarden missing_values = [col voor col in data.columns if data[col].isnull().any()]
# Afdrukken van het aantal ontbrekende waarden en het percentage ontbrekende waarden in elke kolom
voor col in ontbrekende_waarden:
print(col, round(data[col].isnull().mean(), 3), '% ontbrekende waarden')
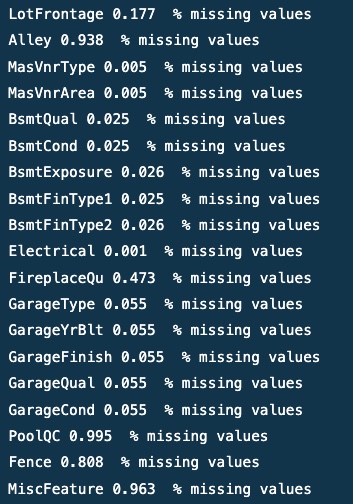
uitgang
Omgaan met de ontbrekende waarden
# De kolommen laten vallen met meer dan 15% ontbrekende waarden data.drop(['Alley', 'FireplaceQu', 'PoolQC', 'Fence', 'MiscFeature'], axis=1, inplace=True)
# De ontbrekende waarden in de overige kolommen vullen met de meest voorkomende waarde new_missing_values = [col for col in data.columns if data[col].isnull().any()] for col in new_missing_values: if data[col].dtype == 'O': data[col].fillna(data[col].mode()[0], inplace=True) else: data[col].fillna(data[col].median(), inplace=True )
Uitschieters
continuous_features = [col voor col in data.columns if data[col].dtype != 'O'] voor col in continuous_features: data_copy = data.copy() if 0 in data_copy[col].unique(): pass else: data_copy[col] = np.log(data_copy[col]) data_copy['SalePrice'] = np.log(data_copy['SalePrice']) plt.scatter(data_copy[col], data_copy['SalePrice']) plt. xlabel(col) plt.ylabel('Verkoopprijs')



uitgang
Verkennende gegevensanalyse
plt.figure(figsize=(10, 15)) # De heatmap plotten met betrekking tot de correlatie van de kenmerken met de doelvariabele 'SalePrice' sns.heatmap(data.corr()[['SalePrice']].sort_values( by='SalePrice', oplopend=False), annot=True, cmap='viridis')
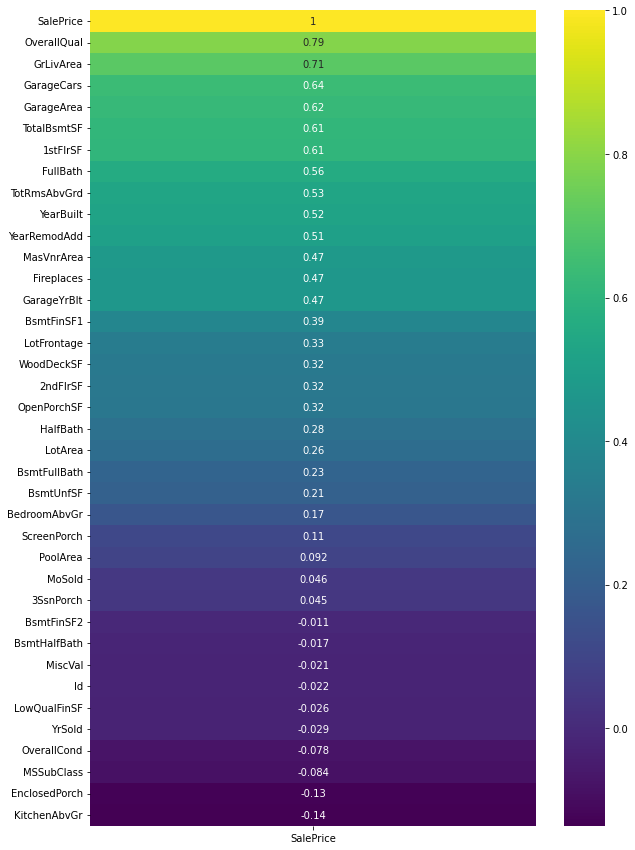
uitgang
We kunnen zien dat 'OverallQual', 'GrLivArea' en 'TotalBsmtSF' sterk correleren met 'SalePrice'. Controleer de onderstaande spreidingsdiagrammen.
# Regressieplot tussen de doelvariabele en de meest gecorreleerde variabelen die een correlatie groter dan 0.5 hebben voor col in data.corr()[data.corr()['SalePrice'] > 0.5].index: if col == 'SalePrice ': pass else: sns.regplot(x=data[col], y=data['SalePrice']) plt.show()


uitgang
Alle kenmerken hebben een positieve correlatie met de doelvariabele.
Model ontwikkeling
# Coderen van de categorische variabelen naar het numerieke datatype van sklearn.preprocessing import LabelEncoder voor col in data.columns: if data[col].dtype == 'O': label_encoder = LabelEncoder() data[col] = label_encoder.fit_transform(data [col])
# Laten we Ridge Regression gebruiken om het model te bouwen van sklearn.linear_model import Ridge van sklearn.model_selection import cross_val_score van sklearn.metrics import mean_squared_error
# maak X- en y-variabelen van Features en doelvariabele X = data[['OverallQual', 'GrLivArea', 'GarageCars', 'GarageArea', 'TotalBsmtSF', '1stFlrSF', 'FullBath', 'TotRmsAbvGrd', 'YearBuilt ', 'YearRemodAdd']] y = data['SalePrice']
# Functie om nokregressie uit te voeren def ridge_regression(alpha, data): ridge = Ridge(alpha=alpha) ridge.fit(X, y) scores = cross_val_score(ridge, X, y, scoring='neg_mean_squared_error', cv=5) rmse = np.sqrt(-scores) geeft rmse terug
# De beste waarde vinden van de hyperparameter van Ridge - alpha alpha = [0.001, 0.01, 0.1, 1, 10, 100, 1000] voor i in alpha: print('Alpha: ', i) print('Mean RMSE: ', ridge_regression(i, data).mean()) print('Standaarddeviatie: ', ridge_regression(i, data).std()) print()
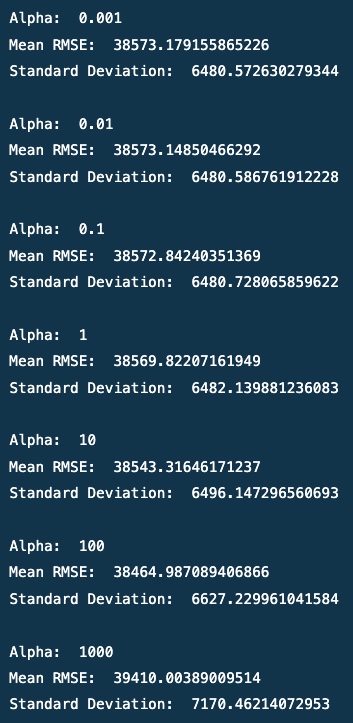
uitgang
Voor alfa = 100 is de RMSE de laagste en presteert het model het beste. De RMSE is 38464. Het model presteert het beste met alpha = 100.
# Ik zal het nokregressiemodel gebruiken met alpha = 100 ridge = Ridge(alpha=100) ridge.fit(X, y)
# De testgegevens laden test_data = pd.read_csv('test.csv')
# Alle wijzigingen doorvoeren die zijn gedaan in de trainingsgegevens test_data.drop(['Alley', 'FireplaceQu', 'PoolQC', 'Fence', 'MiscFeature'], axis=1, inplace=True) new_missing_values = [col for col in test_data.columns if test_data[col].isnull().any()] for col in new_missing_values: if test_data[col].dtype == 'O': test_data[col].fillna(test_data[col]. mode()[0], inplace=True) else: test_data[col].fillna(test_data[col].median(), inplace=True)
# Codering van de categorische variabelen van testgegevens voor col in test_data.columns: if test_data[col].dtype == 'O': label_encoder = LabelEncoder() test_data[col] = label_encoder.fit_transform(test_data[col])
# Functies selecteren X_test = test_data[['OverallQual', 'GrLivArea', 'GarageCars', 'GarageArea', 'TotalBsmtSF', '1stFlrSF', 'FullBath', 'TotRmsAbvGrd', 'YearBuilt', 'YearRemodAdd']] # De doelvariabele voorspellen y_pred = ridge.predict(X_test)
# De voorspellingen opslaan in een csv-bestand output = pd.DataFrame({'Id': test_data.Id, 'SalePrice': y_pred}) output.to_csv('my_submission.csv', index=False)
In dit artikel hebben we de woningdataset van Ames gekozen als prijsvoorspellingsmodel, de probleemstelling begrijpen en uitvoeren Verkennende gegevensanalyse. We hebben ook imputatie van ontbrekende waarden en codering van categorische variabelen op de trein- en testgegevenssets uitgevoerd. Vervolgens pasten we Ridge-regressie toe met verschillende alfawaarden en vonden we de beste waarde van alfa om de RMSE te minimaliseren.
Key Takeaways:
- Drie kenmerken, 'OverallQual', 'GrLivArea' en 'TotalBsmtSF' bleken sterke positieve correlaties te hebben met de doelvariabele 'SalePrice'.
- Het model presteerde het beste met alpha = 100, resulterend in amses van 38464.
- De analyse toonde aan hoe belangrijk het is om meerdere kenmerken in voorspellingsmodellen voor onroerend goed te overwegen.
- Regularisatietechnieken zoals Ridge regressie kan de complexiteit van het model verminderen en overfitting voorkomen.
- De resultaten van dit project benadrukken het potentieel voor het gebruik van datawetenschap in onroerend goed om beter geïnformeerde beslissingen te nemen en voorspellingen te verbeteren.
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.analyticsvidhya.com/blog/2023/02/how-to-build-a-real-estate-price-prediction-model/

