In dit artikel zullen we leren hoe u het GPT4All-model implementeert en gebruikt op uw computer met alleen CPU (Ik gebruik een Macbook Pro zonder gpu!)

Gebruik GPT4All op uw computer — Afbeelding door de auteur
In dit artikel gaan we GPT4All (een krachtige LLM) op onze lokale computer installeren en zullen we ontdekken hoe we met python met onze documenten kunnen omgaan. Een verzameling pdf's of online artikelen vormt de kennisbank voor onze vragen/antwoorden.
Van de officiële website GPT4All het wordt beschreven als een gratis te gebruiken, lokaal draaiende, privacybewuste chatbot. Geen GPU of internet vereist.
GTP4All is een ecosysteem om te trainen en in te zetten krachtige en aangepaste grote taalmodellen die draaien plaatselijk op CPU's van consumentenkwaliteit.
Ons GPT4All-model is een bestand van 4 GB dat u kunt downloaden en aansluiten op de GPT4All open-source ecosysteemsoftware. Nomische AI faciliteert hoogwaardige en veilige software-ecosystemen, waardoor individuen en organisaties moeiteloos hun eigen grote taalmodellen lokaal kunnen trainen en implementeren.
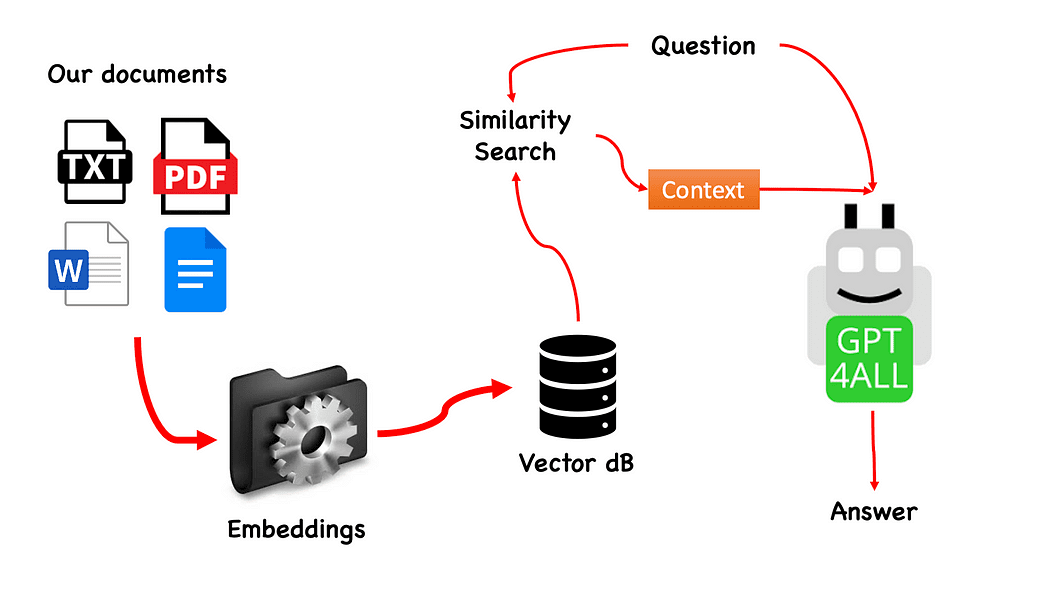
Workflow van de QnA met GPT4All — gemaakt door de auteur
Het proces is heel eenvoudig (als je het weet) en kan ook met andere modellen worden herhaald. De stappen zijn als volgt:
- laad het GPT4All-model
- . Langketen om onze documenten op te halen en ze te laden
- splits de documenten op in kleine stukjes die verteerbaar zijn door Embeddings
- Gebruik FAISS om onze vectordatabase met de inbeddingen te maken
- Voer een zoekopdracht naar overeenkomsten (semantisch zoeken) uit op onze vectordatabase op basis van de vraag die we willen doorgeven aan GPT4All: dit wordt gebruikt als een verband voor onze vraag
- Voer de vraag en de context mee naar GPT4All Langketen en wacht op het antwoord.
Dus wat we nodig hebben is inbedding. Een inbedding is een numerieke weergave van een stuk informatie, bijvoorbeeld tekst, documenten, afbeeldingen, audio, enz. De weergave geeft de semantische betekenis weer van wat wordt ingebed, en dit is precies wat we nodig hebben. Voor dit project kunnen we niet vertrouwen op zware GPU-modellen: dus zullen we het native Alpaca-model downloaden en gebruiken Langketen de LamaCppInbedden. Maak je geen zorgen! Alles wordt stap voor stap uitgelegd
Creëer een virtuele omgeving
Maak een nieuwe map aan voor je nieuwe Python-project, bijvoorbeeld GPT4ALL_Fabio (zet je naam...):
mkdir GPT4ALL_Fabio
cd GPT4ALL_FabioMaak vervolgens een nieuwe virtuele Python-omgeving. Als u meer dan één python-versie hebt geïnstalleerd, geeft u de gewenste versie op: in dit geval zal ik mijn hoofdinstallatie gebruiken, gekoppeld aan python 3.10.
python3 -m venv .venvHet bevel python3 -m venv .venv creëert een nieuwe virtuele omgeving met de naam .venv (de stip maakt een verborgen map met de naam venv).
Een virtuele omgeving biedt een geïsoleerde Python-installatie, waarmee u pakketten en afhankelijkheden alleen voor een specifiek project kunt installeren zonder de systeembrede Python-installatie of andere projecten te beïnvloeden. Deze isolatie helpt de consistentie te behouden en mogelijke conflicten tussen verschillende projectvereisten te voorkomen.
Nadat de virtuele omgeving is gemaakt, kunt u deze activeren met de volgende opdracht:
source .venv/bin/activate 
Geactiveerde virtuele omgeving
De bibliotheken die moeten worden geïnstalleerd
Voor het project dat we aan het bouwen zijn, hebben we niet al te veel pakketten nodig. We hebben alleen nodig:
- python-bindingen voor GPT4All
- Langchain om te communiceren met onze documenten
LangChain is een raamwerk voor het ontwikkelen van applicaties aangedreven door taalmodellen. Hiermee kunt u niet alleen een taalmodel aanroepen via een API, maar ook een taalmodel verbinden met andere gegevensbronnen en een taalmodel laten communiceren met zijn omgeving.
pip install pygpt4all==1.0.1
pip install pyllamacpp==1.0.6
pip install langchain==0.0.149
pip install unstructured==0.6.5
pip install pdf2image==1.16.3
pip install pytesseract==0.3.10
pip install pypdf==3.8.1
pip install faiss-cpu==1.7.4Voor LangChain zie je dat we ook de versie hebben gespecificeerd. Deze bibliotheek ontvangt de laatste tijd veel updates, dus om er zeker van te zijn dat onze installatie ook morgen zal werken, is het beter om een versie op te geven waarvan we weten dat die goed werkt. Ongestructureerd is een vereiste afhankelijkheid voor de pdf-lader en pytesseract en pdf2afbeelding .
NOTITIE: op de GitHub-repository is er een requirements.txt-bestand (voorgesteld door jl adr) met alle versies die aan dit project zijn gekoppeld. U kunt de installatie in één keer uitvoeren, nadat u het in de hoofdmap van het projectbestand hebt gedownload met de volgende opdracht:
pip install -r requirements.txtAan het einde van het artikel heb ik een sectie voor het oplossen van problemen. De GitHub-repo heeft ook een bijgewerkte READ.ME met al deze informatie.
Houd er rekening mee dat sommige bibliotheken hebben versies beschikbaar, afhankelijk van de python-versie u draait op uw virtuele omgeving.
Download de modellen op uw pc
Dit is echt een belangrijke stap.
Voor het project hebben we GPT4All zeker nodig. Het proces beschreven op Nomic AI is erg ingewikkeld en vereist hardware die niet iedereen heeft (zoals ik). Dus hier is de link naar het model al omgebouwd en klaar voor gebruik. Klik gewoon op downloaden.

Download het GPT4All-model
Zoals kort beschreven in de inleiding hebben we ook het model nodig voor de inbeddingen, een model dat we op onze CPU kunnen draaien zonder te crashen. Klik op de link hier om de alpaca-native-7B-ggml te downloaden al geconverteerd naar 4-bit en klaar om te gebruiken als ons model voor de inbedding.
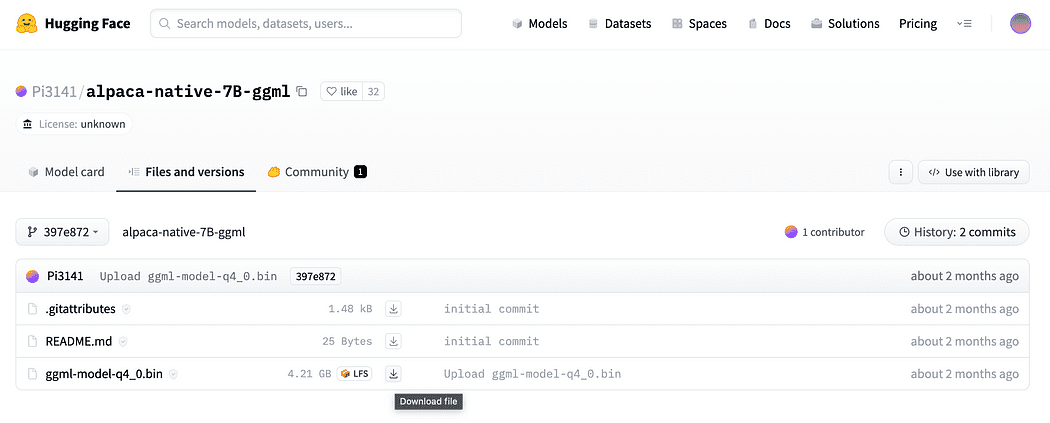
Klik op de downloadpijl ernaast ggml-model-q4_0.bin
Waarom hebben we inbeddingen nodig? Als u zich herinnert uit het stroomschema, is de eerste vereiste stap, nadat we de documenten voor onze kennisbank hebben verzameld, om insluiten hen. De LLamaCPP-inbeddingen van dit Alpaca-model passen perfect bij de taak en dit model is ook vrij klein (4 Gb). Je kunt trouwens ook het Alpaca-model gebruiken voor je QnA!
Update 2023.05.25: Mani Windows-gebruikers hebben problemen met het gebruik van de lamaCPP-insluitingen. Dit gebeurt vooral omdat tijdens de installatie van het python-pakket llama-cpp-python met:
pip install llama-cpp-pythonhet pip-pakket gaat compileren vanuit de broncode van de bibliotheek. Windows heeft meestal geen CMake- of C-compiler standaard op de machine geïnstalleerd. Maar wees niet bang dat er een oplossing is
Het uitvoeren van de installatie van llama-cpp-python, vereist door LangChain met de llamaEmbeddings, op Windows CMake C complier is niet standaard geïnstalleerd, dus u kunt niet vanaf de bron bouwen.
Op Mac-gebruikers met Xtools en op Linux is de C-complier meestal al beschikbaar op het besturingssysteem.
Om het probleem te vermijden u MOET een vooraf nageleefd wiel gebruiken.
Ga hier https://github.com/abetlen/llama-cpp-python/releases
en zoek naar het conforme wiel voor uw architectuur en python-versie - u MOET Weels versie 0.1.49 nemen omdat hogere versies niet compatibel zijn.
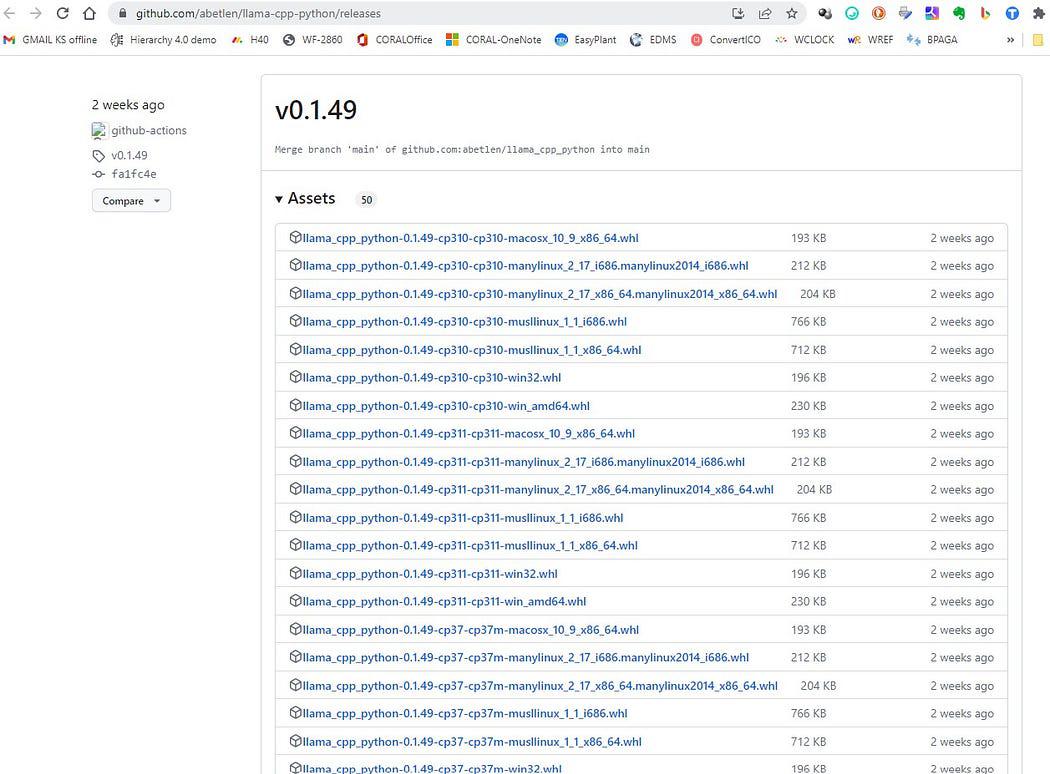
Schermafbeelding van https://github.com/abetlen/llama-cpp-python/releases
In mijn geval heb ik Windows 10, 64 bit, python 3.10
dus mijn bestand is llama_cpp_python-0.1.49-cp310-cp310-win_amd64.whl
Deze probleem wordt bijgehouden in de GitHub-repository
Na het downloaden moet u de twee modellen in de modellenmap plaatsen, zoals hieronder weergegeven.

Directorystructuur en waar de modelbestanden moeten worden geplaatst
Omdat we controle willen hebben over onze interactie met het GPT-model, moeten we een python-bestand maken (laten we het noemen pygpt4all_test.py), importeer de afhankelijkheden en geef de instructie aan het model. Je zult zien dat dat vrij eenvoudig is.
from pygpt4all.models.gpt4all import GPT4AllDit is de pythonbinding voor ons model. Nu kunnen we het noemen en beginnen met vragen. Laten we een creatieve proberen.
We maken een functie die de callback van het model leest en we vragen GPT4All om onze zin af te maken.
def new_text_callback(text): print(text, end="") model = GPT4All('./models/gpt4all-converted.bin')
model.generate("Once upon a time, ", n_predict=55, new_text_callback=new_text_callback)De eerste instructie vertelt ons programma waar het model te vinden is (onthoud wat we in het bovenstaande gedeelte hebben gedaan)
De tweede verklaring vraagt het model om een reactie te genereren en onze prompt "Er was eens" te voltooien.
Om het uit te voeren, moet u ervoor zorgen dat de virtuele omgeving nog steeds is geactiveerd en voert u gewoon het volgende uit:
python3 pygpt4all_test.pyJe zou een laadtekst van het model en de voltooiing van de zin moeten zien. Afhankelijk van uw hardwarebronnen kan dit even duren.
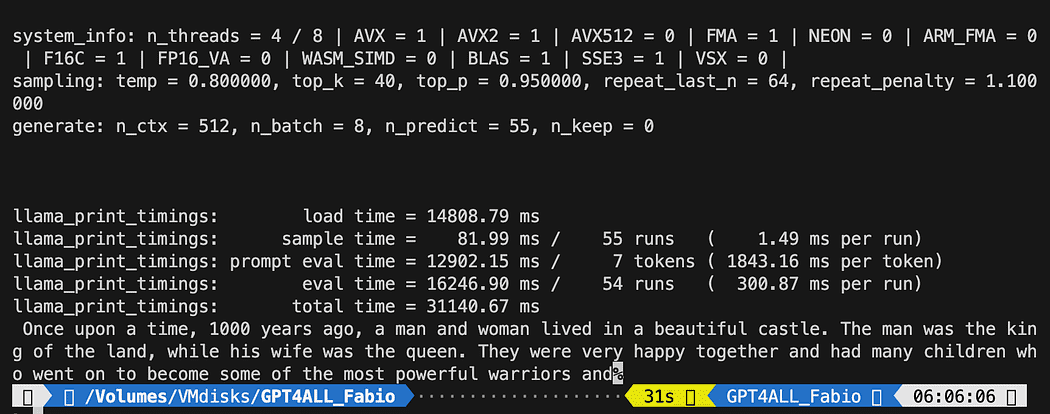
Het resultaat kan anders zijn dan dat van jou... Maar voor ons is het belangrijk dat het werkt en we kunnen doorgaan met LangChain om geavanceerde dingen te maken.
OPMERKING (bijgewerkt 2023.05.23): als u een fout tegenkomt met betrekking tot pygpt4all, raadpleeg dan het gedeelte over probleemoplossing over dit onderwerp met de oplossing die wordt gegeven door Rajneesh Aggarwal or van Oscar Jeong.
Het LangChain-framework is echt een geweldige bibliotheek. Het zorgt voor COMPONENTEN om op een gebruiksvriendelijke manier met taalmodellen te werken, en het biedt ook Ketens. Ketens kunnen worden gezien als het samenstellen van deze componenten op bepaalde manieren om een bepaalde use case zo goed mogelijk uit te voeren. Deze zijn bedoeld als interface op een hoger niveau waarmee mensen gemakkelijk aan de slag kunnen met een specifieke use case. Deze kettingen zijn ook ontworpen om aanpasbaar te zijn.
In onze volgende python-test zullen we een Prompt-sjabloon. Taalmodellen nemen tekst als invoer — die tekst wordt gewoonlijk een prompt genoemd. Meestal is dit niet zomaar een hardgecodeerde tekenreeks, maar eerder een combinatie van een sjabloon, enkele voorbeelden en gebruikersinvoer. LangChain biedt verschillende klassen en functies om het construeren van en werken met prompts eenvoudig te maken. Laten we eens kijken hoe we het ook kunnen doen.
Maak een nieuw python-bestand en noem het mijn_langketen.py
# Import of langchain Prompt Template and Chain
from langchain import PromptTemplate, LLMChain # Import llm to be able to interact with GPT4All directly from langchain
from langchain.llms import GPT4All # Callbacks manager is required for the response handling from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler local_path = './models/gpt4all-converted.bin' callback_manager = CallbackManager([StreamingStdOutCallbackHandler()])We hebben vanuit LangChain de Prompt Template en Chain en GPT4All llm-klasse geïmporteerd om rechtstreeks met ons GPT-model te kunnen communiceren.
Vervolgens, na het instellen van ons llm-pad (zoals we eerder deden), instantiëren we de callback-managers zodat we de antwoorden op onze vraag kunnen opvangen.
Een sjabloon maken is heel eenvoudig: volg de documentatie handleiding zoiets kunnen we wel gebruiken...
template = """Question: {question} Answer: Let's think step by step on it. """
prompt = PromptTemplate(template=template, input_variables=["question"])De sjabloon variabele is een string met meerdere regels die onze interactiestructuur met het model bevat: tussen accolades voegen we de externe variabelen in de sjabloon in, in ons scenario is onze vraag.
Aangezien het een variabele is, kunt u beslissen of het een hardgecodeerde vraag is of een vraag die door de gebruiker is ingevoerd: hier de twee voorbeelden.
# Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User input question...
question = input("Enter your question: ")Voor onze testrun zullen we de gebruikersinvoer becommentariëren. Nu hoeven we alleen ons sjabloon, de vraag en het taalmodel aan elkaar te koppelen.
template = """Question: {question}
Answer: Let's think step by step on it. """ prompt = PromptTemplate(template=template, input_variables=["question"]) # initialize the GPT4All instance
llm = GPT4All(model=local_path, callback_manager=callback_manager, verbose=True) # link the language model with our prompt template
llm_chain = LLMChain(prompt=prompt, llm=llm) # Hardcoded question
question = "What Formula 1 pilot won the championship in the year Leonardo di Caprio was born?" # User imput question...
# question = input("Enter your question: ") #Run the query and get the results
llm_chain.run(question)Vergeet niet om te controleren of uw virtuele omgeving nog steeds geactiveerd is en voer de opdracht uit:
python3 my_langchain.pyU krijgt mogelijk andere resultaten dan de mijne. Wat verbazingwekkend is, is dat je de hele redenering kunt zien die wordt gevolgd door GPT4All die probeert een antwoord voor je te krijgen. Het aanpassen van de vraag kan ook betere resultaten opleveren.

Langchain met Prompt-sjabloon op GPT4All
Hier beginnen we met het verbazingwekkende deel, omdat we met onze documenten gaan praten met behulp van GPT4All als een chatbot die onze vragen beantwoordt.
De volgorde van stappen, verwijzend naar Workflow van de QnA met GPT4All, is om onze pdf-bestanden te laden, ze in stukjes te maken. Daarna hebben we een Vector Store nodig voor onze inbeddingen. We moeten onze gesegmenteerde documenten in een vectoropslag plaatsen om informatie op te halen en dan zullen we ze samen met de gelijkeniszoekopdracht in deze database insluiten als context voor onze LLM-query.
Voor deze doeleinden gaan we FAISS rechtstreeks van gebruiken Langketen bibliotheek. FAISS is een open-sourcebibliotheek van Facebook AI Research, ontworpen om snel vergelijkbare items te vinden in grote verzamelingen hoogdimensionale gegevens. Het biedt indexerings- en zoekmethoden om het gemakkelijker en sneller te maken om de meest vergelijkbare items binnen een dataset te vinden. Het is vooral handig voor ons omdat het vereenvoudigt informatie ophalen en ons in staat stellen om de gemaakte database lokaal op te slaan: dit betekent dat deze na de eerste creatie zeer snel zal worden geladen voor verder gebruik.
Aanmaak van de vectorindex db
Maak een nieuw bestand aan en noem het mijn_kennis_qna.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler # function for loading only TXT files
from langchain.document_loaders import TextLoader # text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter # to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader # Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator # LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings # FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS import os #for interaaction with the files
import datetimeDe eerste bibliotheken zijn dezelfde die we eerder gebruikten: bovendien gebruiken we Langketen voor het maken van de vectoropslagindex, de LamaCppInbedden om te communiceren met ons Alpaca-model (gekwantiseerd naar 4-bit en gecompileerd met de cpp-bibliotheek) en de PDF-lader.
Laten we ook onze LLM's laden met hun eigen paden: één voor de inbedding en één voor het genereren van tekst.
# assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True)Laten we voor de test eens kijken of we erin geslaagd zijn om alle pdf-bestanden te lezen: de eerste stap is het declareren van 3 functies die op elk afzonderlijk document moeten worden gebruikt. De eerste is om de geëxtraheerde tekst in stukken te splitsen, de tweede is om de vectorindex te maken met de metadata (zoals paginanummers enz...) en de laatste is om het zoeken naar overeenkomsten te testen (ik zal het later beter uitleggen).
# Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sourcesNu kunnen we de indexgeneratie testen voor de documenten in het docs directory: we moeten daar al onze pdf's plaatsen. Langketen heeft ook een methode om de hele map te laden, ongeacht het bestandstype: aangezien het postproces gecompliceerd is, zal ik dit behandelen in het volgende artikel over LaMini-modellen.

mijn map met documenten bevat 4 pdf-bestanden
We zullen onze functies toepassen op het eerste document in de lijst
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
# load the documents with Langchain
docs = loader.load()
# Split in chunks
chunks = split_chunks(docs)
# create the db vector index
db0 = create_index(chunks)In de eerste regels gebruiken we de os-bibliotheek om de lijst met pdf-bestanden in de map docs. Vervolgens laden we het eerste document (doc_lijst[0]) uit de map docs met Langketen, splitsen in stukjes en dan maken we de vectordatabase met de Lama inbeddingen.
Zoals je zag gebruiken we de pyPDF-methode. Deze is iets langer in gebruik, omdat je de bestanden een voor een moet laden, maar PDF moet laden met pypdf into array of documents stelt u in staat om een array te hebben waarin elk document de pagina-inhoud en metadata bevat page nummer. Dit is erg handig als u de bronnen wilt weten van de context die we met onze zoekopdracht aan GPT4All zullen geven. Hier het voorbeeld uit de readthedocs:
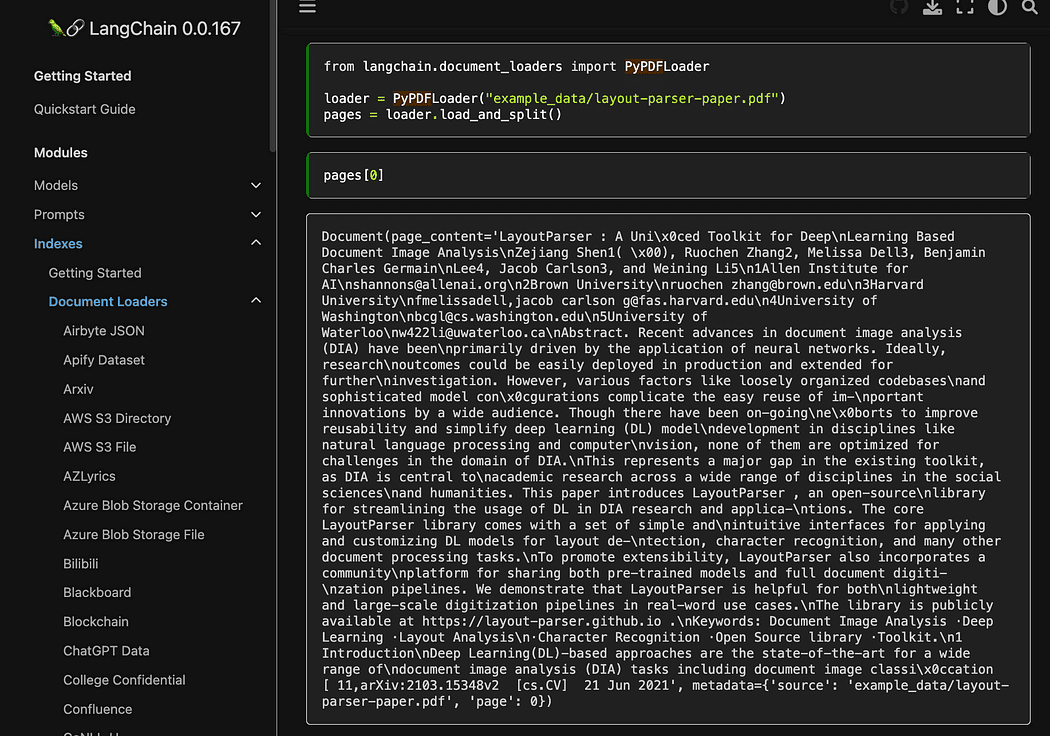
Schermafbeelding van Langchain-documentatie
We kunnen het python-bestand uitvoeren met de opdracht van terminal:
python3 my_knowledge_qna.pyNa het laden van het model voor inbedding zul je de tokens aan het werk zien voor de indexering: raak niet in paniek, want het zal tijd kosten, vooral als je alleen op CPU draait, zoals ik (het duurde 8 minuten).
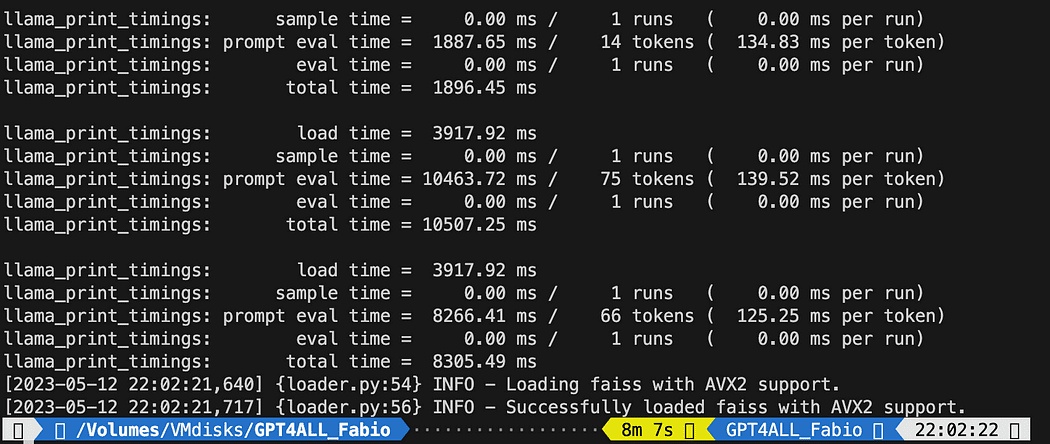
Voltooiing van de eerste vector db
Zoals ik al aan het uitleggen was, is de pyPDF-methode langzamer, maar geeft ons aanvullende gegevens voor het zoeken naar overeenkomsten. Om al onze bestanden te doorlopen, gebruiken we een handige methode van FAISS waarmee we verschillende databases kunnen SAMENVOEGEN. Wat we nu doen, is dat we de bovenstaande code gebruiken om de eerste db te genereren (we zullen het db0) en met een for-lus maken we de index van het volgende bestand in de lijst en voegen deze onmiddellijk samen db0.
Hier is de code: merk op dat ik enkele logboeken heb toegevoegd om u de status van de voortgang te geven met behulp van datumtijd.datumtijd.nu() en het afdrukken van de delta van eindtijd en starttijd om te berekenen hoe lang de operatie duurde (je kunt het verwijderen als je het niet leuk vindt).
De samenvoeginstructies zijn als volgt
# merge dbi with the existing db0
db0.merge_from(dbi)Een van de laatste instructies is om onze database lokaal op te slaan: de hele generatie kan zelfs uren duren (hangt af van hoeveel documenten je hebt), dus het is echt goed dat we het maar één keer hoeven te doen!
# Save the databasae locally
db0.save_local("my_faiss_index")Hier de hele code. We zullen een groot deel ervan becommentariëren wanneer we GPT4All gebruiken om de index rechtstreeks vanuit onze map te laden.
# get the list of pdf files from the docs directory into a list format
pdf_folder_path = './docs'
doc_list = [s for s in os.listdir(pdf_folder_path) if s.endswith('.pdf')]
num_of_docs = len(doc_list)
# create a loader for the PDFs from the path
general_start = datetime.datetime.now() #not used now but useful
print("starting the loop...")
loop_start = datetime.datetime.now() #not used now but useful
print("generating fist vector database and then iterate with .merge_from")
loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[0]))
docs = loader.load()
chunks = split_chunks(docs)
db0 = create_index(chunks)
print("Main Vector database created. Start iteration and merging...")
for i in range(1,num_of_docs): print(doc_list[i]) print(f"loop position {i}") loader = PyPDFLoader(os.path.join(pdf_folder_path, doc_list[i])) start = datetime.datetime.now() #not used now but useful docs = loader.load() chunks = split_chunks(docs) dbi = create_index(chunks) print("start merging with db0...") db0.merge_from(dbi) end = datetime.datetime.now() #not used now but useful elapsed = end - start #not used now but useful #total time print(f"completed in {elapsed}") print("-----------------------------------")
loop_end = datetime.datetime.now() #not used now but useful
loop_elapsed = loop_end - loop_start #not used now but useful
print(f"All documents processed in {loop_elapsed}")
print(f"the daatabase is done with {num_of_docs} subset of db index")
print("-----------------------------------")
print(f"Merging completed")
print("-----------------------------------")
print("Saving Merged Database Locally")
# Save the databasae locally
db0.save_local("my_faiss_index")
print("-----------------------------------")
print("merged database saved as my_faiss_index")
general_end = datetime.datetime.now() #not used now but useful
general_elapsed = general_end - general_start #not used now but useful
print(f"All indexing completed in {general_elapsed}")
print("-----------------------------------")  Het uitvoeren van het python-bestand duurde 22 minuten
Het uitvoeren van het python-bestand duurde 22 minuten
Stel vragen aan GPT4All over uw documenten
Nu zijn we hier. We hebben onze index, we kunnen hem laden en met een Prompt Template kunnen we GPT4All vragen om onze vragen te beantwoorden. We beginnen met een hardgecodeerde vraag en doorlopen vervolgens onze invoervragen.
Plaats de volgende code in een python-bestand db_loading.py en voer het uit met de opdracht van terminal python3 db_loading.py
from langchain import PromptTemplate, LLMChain
from langchain.llms import GPT4All
from langchain.callbacks.base import CallbackManager
from langchain.callbacks.streaming_stdout import StreamingStdOutCallbackHandler
# function for loading only TXT files
from langchain.document_loaders import TextLoader
# text splitter for create chunks
from langchain.text_splitter import RecursiveCharacterTextSplitter
# to be able to load the pdf files
from langchain.document_loaders import UnstructuredPDFLoader
from langchain.document_loaders import PyPDFLoader
from langchain.document_loaders import DirectoryLoader
# Vector Store Index to create our database about our knowledge
from langchain.indexes import VectorstoreIndexCreator
# LLamaCpp embeddings from the Alpaca model
from langchain.embeddings import LlamaCppEmbeddings
# FAISS library for similaarity search
from langchain.vectorstores.faiss import FAISS
import os #for interaaction with the files
import datetime # TEST FOR SIMILARITY SEARCH # assign the path for the 2 models GPT4All and Alpaca for the embeddings gpt4all_path = './models/gpt4all-converted.bin' llama_path = './models/ggml-model-q4_0.bin' # Calback manager for handling the calls with the model
callback_manager = CallbackManager([StreamingStdOutCallbackHandler()]) # create the embedding object
embeddings = LlamaCppEmbeddings(model_path=llama_path)
# create the GPT4All llm object
llm = GPT4All(model=gpt4all_path, callback_manager=callback_manager, verbose=True) # Split text def split_chunks(sources): chunks = [] splitter = RecursiveCharacterTextSplitter(chunk_size=256, chunk_overlap=32) for chunk in splitter.split_documents(sources): chunks.append(chunk) return chunks def create_index(chunks): texts = [doc.page_content for doc in chunks] metadatas = [doc.metadata for doc in chunks] search_index = FAISS.from_texts(texts, embeddings, metadatas=metadatas) return search_index def similarity_search(query, index): # k is the number of similarity searched that matches the query # default is 4 matched_docs = index.similarity_search(query, k=3) sources = [] for doc in matched_docs: sources.append( { "page_content": doc.page_content, "metadata": doc.metadata, } ) return matched_docs, sources # Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings)
# Hardcoded question
query = "What is a PLC and what is the difference with a PC"
docs = index.similarity_search(query)
# Get the matches best 3 results - defined in the function k=3
print(f"The question is: {query}")
print("Here the result of the semantic search on the index, without GPT4All..")
print(docs[0])De gedrukte tekst is de lijst van de 3 bronnen die het best overeenkomen met de zoekopdracht, en geeft ons ook de documentnaam en het paginanummer.
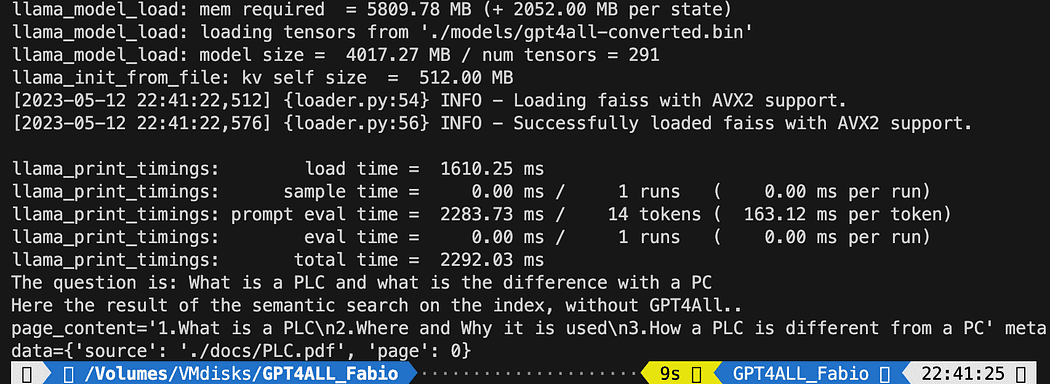
Resultaten van de semantische zoekopdracht die het bestand uitvoert db_loading.py
Nu kunnen we de gelijkeniszoekopdracht gebruiken als context voor onze zoekopdracht met behulp van de promptsjabloon. Vervang na de 3 functies gewoon alle code door het volgende:
# Load our local index vector db
index = FAISS.load_local("my_faiss_index", embeddings) # create the prompt template
template = """
Please use the following context to answer questions.
Context: {context}
---
Question: {question}
Answer: Let's think step by step.""" # Hardcoded question
question = "What is a PLC and what is the difference with a PC"
matched_docs, sources = similarity_search(question, index)
# Creating the context
context = "n".join([doc.page_content for doc in matched_docs])
# instantiating the prompt template and the GPT4All chain
prompt = PromptTemplate(template=template, input_variables=["context", "question"]).partial(context=context)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Print the result
print(llm_chain.run(question))Na het hardlopen krijg je een resultaat als dit (maar kan variëren). Geweldig nee!?!?
Please use the following context to answer questions.
Context: 1.What is a PLC
2.Where and Why it is used
3.How a PLC is different from a PC
PLC is especially important in industries where safety and reliability are
critical, such as manufacturing plants, chemical plants, and power plants.
How a PLC is different from a PC
Because a PLC is a specialized computer used in industrial and
manufacturing applications to control machinery and processes.,the
hardware components of a typical PLC must be able to interact with
industrial device. So a typical PLC hardware include:
---
Question: What is a PLC and what is the difference with a PC
Answer: Let's think step by step. 1) A Programmable Logic Controller (PLC), also called Industrial Control System or ICS, refers to an industrial computer that controls various automated processes such as manufacturing machines/assembly lines etcetera through sensors and actuators connected with it via inputs & outputs. It is a form of digital computers which has the ability for multiple instruction execution (MIE), built-in memory registers used by software routines, Input Output interface cards(IOC) to communicate with other devices electronically/digitally over networks or buses etcetera
2). A Programmable Logic Controller is widely utilized in industrial automation as it has the ability for more than one instruction execution. It can perform tasks automatically and programmed instructions, which allows it to carry out complex operations that are beyond a Personal Computer (PC) capacity. So an ICS/PLC contains built-in memory registers used by software routines or firmware codes etcetera but PC doesn't contain them so they need external interfaces such as hard disks drives(HDD), USB ports, serial and parallel communication protocols to store data for further analysis or report generation.Als u wilt dat een door de gebruiker ingevoerde vraag de regel vervangt
question = "What is a PLC and what is the difference with a PC"met zoiets als dit:
question = input("Your question: ")Het is tijd voor jou om te experimenteren. Stel verschillende vragen over alle onderwerpen met betrekking tot uw documenten en bekijk de resultaten. Er is veel ruimte voor verbetering, zeker op de prompt en het sjabloon: je kunt een kijkje nemen hier voor wat inspiratie. Maar Langketen documentatie is echt geweldig (ik zou het kunnen volgen!!).
U kunt de code uit het artikel volgen of deze controleren mijn github-opslagplaats.
Fabio Matricardi een opvoeder, leraar, ingenieur en leerliefhebber. Hij geeft al 15 jaar les aan jonge studenten en leidt nu nieuwe medewerkers op bij Key Solution Srl. Hij begon mijn carrière als Industrial Automation Engineer in 2010. Gepassioneerd door programmeren sinds hij een tiener was, ontdekte hij de schoonheid van het bouwen van software en Human Machine Interfaces om iets tot leven te brengen. Lesgeven en coachen maakt deel uit van mijn dagelijkse routine, evenals studeren en leren hoe ik een gepassioneerd leider kan zijn met up-to-date managementvaardigheden. Ga met mij mee op reis naar een beter ontwerp, een voorspellende systeemintegratie met behulp van machine learning en kunstmatige intelligentie gedurende de gehele technische levenscyclus.
ORIGINELE. Met toestemming opnieuw gepost.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- EVM Financiën. Uniforme interface voor gedecentraliseerde financiën. Toegang hier.
- Quantum Media Groep. IR/PR versterkt. Toegang hier.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/06/gpt4all-local-chatgpt-documents-free.html?utm_source=rss&utm_medium=rss&utm_campaign=gpt4all-is-the-local-chatgpt-for-your-documents-and-it-is-free

