Introductie
Vandaag gaan we in deze handleiding dieper in op Kubernetes en gebruiken we het om containers op grote schaal in te zetten en te beheren.
Container- en microservice-architectuur hadden meer gebruikt om moderne apps te maken. Kubernetes is open-sourcesoftware waarmee u containers op schaal kunt implementeren en beheren. Het verdeelt containers in logische delen om het beheer, de detectie en het schalen van uw toepassing gemakkelijker te maken.
Het belangrijkste doel van deze gids is om een compleet overzicht van het Kubernetes-ecosysteem te bieden, terwijl het eenvoudig en duidelijk blijft. Het behandelt de kernideeën van Kubernetes voordat ze worden toegepast op een realistisch scenario.
Zelfs als u geen eerdere ervaring met Kubernetes heeft, is dit artikel een uitstekend startpunt voor uw reis.
Dus laten we zonder verder oponthoud beginnen met dit leren.
Waarom Kubernetes?
Voordat we ingaan op de technische ideeën, laten we beginnen met waarom een ontwikkelaar Kubernetes in de eerste plaats zou moeten gebruiken. Hier zijn een paar redenen waarom ontwikkelaars Kubernetes in hun projecten zouden moeten gebruiken.
Draagbaarheid
Bij het gebruik van Kubernetes lijkt het verplaatsen van gecontaineriseerde applicaties van ontwikkeling naar productie een eenvoudig proces. Met Kubernetes kunnen ontwikkelaars containers in verschillende omgevingen orkestreren, waaronder on-premises infrastructuur, openbare en hybride clouds.
Schaalbaarheid
Kubernetes vereenvoudigt het proces van het definiëren van complexe gecontaineriseerde applicaties en deze wereldwijd te implementeren over meerdere clusters van servers door resources te verminderen op basis van uw gewenste status. Kubernetes controleert en onderhoudt automatisch de status van containers bij het horizontaal schalen van applicaties.
rekbaarheid
Kubernetes heeft een enorme en steeds groter wordende verzameling extensies en plug-ins gemaakt door ontwikkelaars en bedrijven die het eenvoudig maken om unieke mogelijkheden aan uw clusters toe te voegen, zoals beveiliging, monitoring of beheer.
Concepts
Het gebruik van Kubernetes vereist een goed begrip van de verschillende abstracties die het gebruikt om de toestand van het systeem weer te geven. Dat is de focus van dit onderdeel. We maken kennis met de essentiële concepten en geven u een beter beeld van de totale architectuur.
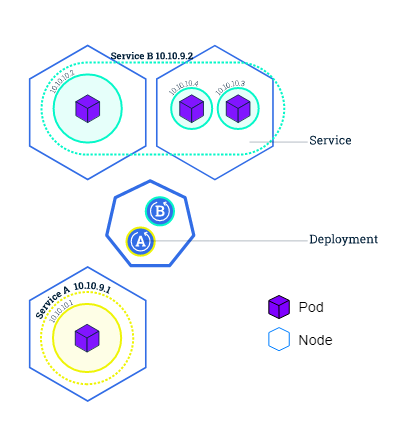
Pods
Een pod is een verzameling van meerdere containers met applicaties die opslag delen, een uniek cluster-IP-adres en instructies om ze uit te voeren (bijvoorbeeld poorten, herstarten, containerimage en foutbeleid).
Ze vormen de basis van het Kubernetes-platform. Bij het maken van een service of implementatie maakt Kubernetes een pod met de container erin.
Elke pod wordt uitgevoerd op het knooppunt waar het is gepland en blijft daar totdat het wordt beëindigd of verwijderd. Als het knooppunt uitvalt of stopt, plant Kubernetes automatisch identieke pods op de andere beschikbare knooppunten van het cluster.

Knooppunt
Een knoop punt is een werkmachine in een Kubernetes-cluster die virtueel of fysiek kan zijn, afhankelijk van het clustertype. De master heeft de leiding over elk knooppunt. De master plant onvrijwillig pods over alle knooppunten in het cluster, op basis van hun beschikbare resources en huidige configuratie.
Elk knooppunt is vereist om ten minste twee services uit te voeren:
- Kubelet is een proces dat communiceert tussen de Kubernetes-master en het knooppunt.
- Een containerruntime is verantwoordelijk voor het downloaden en uitvoeren van een containerimage (bijv. Docker)

Diensten
Een service is een abstractie die een logische set pods beschrijft en het beleid voor toegang tot deze. Services maken de losse koppeling van afhankelijke pods mogelijk.
Hoewel elke pod een apart IP-adres heeft, zijn die adressen niet zichtbaar voor de buitenwereld. Als gevolg hiervan stelt een service uw implementatie in staat verkeer van externe bronnen te ontvangen.
We kunnen op verschillende manieren diensten aanbieden:
- ClusterIP (standaard) – Stel de poort alleen bloot aan de interne onderdelen van het cluster.
- NodePort - Gebruik NAT om de service op dezelfde poort op elk knooppunt in het cluster te onthullen
- Loadbalancer – Maak een externe load balancer om de service naar een opgegeven IP-adres te exporteren.
implementaties
Implementaties bevatten een beschrijving van de gewenste status van uw toepassing. De implementatiecontroller zorgt ervoor dat de huidige status van de toepassing overeenkomt met die beschrijving.
Een implementatie voert automatisch veel replica's van uw programma uit en vervangt alle instanties die mislukken of niet meer reageren. Implementaties helpen om te weten dat uw programma klaar is om gebruikersverzoeken op deze manier te verwerken.

Installatie
Voordat we ons cluster gaan bouwen, moeten we eerst Kubernetes installeren op ons lokale werkstation.
Docker-bureaublad
Als u Docker-desktop op Windows of Mac gebruikt, kunt u Kubernetes rechtstreeks installeren vanuit het instellingenvenster van de gebruikersinterface.
Overig
Als u het Docker-bureaublad niet gebruikt, raad ik u aan de officiële installatie procedure voor Kubectl en Minikube.
De Basis
Nu we de fundamentele ideeën hebben behandeld. Laten we verder gaan met de praktische kant van Kubernetes. In dit hoofdstuk wordt u door de basisprincipes geleid die nodig zijn om apps in een cluster te implementeren.
Cluster maken
Wanneer u Minikube start, vormt het onmiddellijk een cluster.
minikube start
Na installatie zou de Docker-desktop ook automatisch een cluster moeten bouwen. U kunt de volgende opdrachten gebruiken om te zien of uw cluster actief is:
# Informatie verkrijgen over het cluster kubectl cluster-info # Alle knooppunten van het cluster kubectl ophalen knooppunten
Een applicatie implementeren:
Nu we de installatie hebben voltooid en ons eerste cluster hebben opgezet, zijn we klaar om een toepassing op Kubernetes te implementeren.
kubectl create deployment nginx --image=nginx:latestWe gebruiken de opdracht create deployment en geven invoer door als de naam van de implementatie en de containerafbeelding. In dit voor beeld wordt Nginx geïmplementeerd met één container en één replica.
Met de opdracht get deployments kunt u uw actieve implementaties bekijken.
kubectl get deploymentsInformatie over implementaties
Hier volgen enkele opdrachten die u kunt gebruiken om meer te weten te komen over uw Kubernetes-implementaties en pods.
Alle pods verkrijgen
Met de opdracht kubectl get pods kun je een lijst krijgen van alle actieve pods:
kubectl get podsGedetailleerde beschrijving van een pod
Gebruik de opdracht description om meer gedetailleerde informatie over een pod te krijgen.
kubectl describe podsLogboeken van een pod
De gegevens die uw toepassing naar STDOUT zou verzenden, worden containerlogboeken. De volgende opdracht geeft u toegang tot die logboeken.
kubectl logs $POD_NAMEOpmerking: u kunt de naam van uw pod achterhalen door de opdrachten get pods te gebruiken of pods te beschrijven.
Commando uitvoeren in Container
De opdracht kubectl exec, die de naam van de pod en de term gebruikt om als argumenten uit te voeren, stelt ons in staat om opdrachten rechtstreeks in onze container uit te voeren.
kubectl exec $POD_NAME commandLaten we eens kijken naar een voorbeeld waarbij we een bash-terminal in de container starten om te zien wat ik bedoel.
kubectl exec -it $POD_NAME bashApp openbaar maken
Een service stelt, zoals eerder gezegd, een beleid vast waarmee de implementatie toegankelijk kan zijn. We zullen in deze sectie bekijken hoe dit wordt bereikt en in andere alternatieven die u heeft wanneer u uw services aan het publiek bekendmaakt.
Een dienst ontwikkelen:
We kunnen een service bouwen met de opdracht create-service, die de poort die we willen vrijgeven en het soort poort als parameters neemt.
kubectl create service nodeport nginx --tcp=80:80Het genereert service voor onze Nginx-implementatie en stelt poort 80 van onze container bloot aan een poort op onze hostcomputer.
Gebruik op het hostsysteem de opdracht kubectl get services om de poort te verkrijgen:

Zoals je kunt zien, was poort 80 van de container gerouteerd naar poort 31041 van mijn hostmachine. Als u de poort hebt, kunt u uw implementatie testen door toegang te krijgen tot uw localhost op die poort.
Een dienst verwijderen
De opdracht delete service kan ook worden gebruikt om bestaande services te verwijderen.
kubectl delete service nginxDe app opschalen
Uw applicatie op en neer schalen is een fluitje van een cent met Kubernetes. Door deze opdracht te gebruiken, kunt u het aantal replica's wijzigen en Kubernetes zal alles voor u genereren en onderhouden.
kubectl scale deployments/nginx --replicas=5Deze opdracht repliceert onze Nginx-service naar maximaal vijf replica's.
Deze manier van applicatie-implementatie werkt goed voor kleine apps met één container, maar mist het overzicht en de herbruikbaarheid die vereist zijn voor grotere applicaties. YAML-bestanden zijn handig in deze situatie.
Met YAML-bestanden kunt u uw implementatie, services en pods specificeren met behulp van een opmaaktaal, waardoor ze beter herbruikbaar en schaalbaar zijn. De volgende hoofdstukken gaan uitgebreid in op Yaml-bestanden.
Kubernetes-object in YAML
Elk object in Kubernetes was uitgedrukt als een declaratief YAML-object dat specificeert wat en hoe het moet worden uitgevoerd. Deze bestanden waren vaak gebruikt om de herbruikbaarheid van resourceconfiguraties, zoals implementaties, services en volumes, te bevorderen.
Deze sectie leidt u door de basisprincipes van YAML en hoe u een lijst met alle beschikbare parameters en kenmerken voor een Kubernetes-object kunt verkrijgen. We bladeren door de implementatie- en servicebestanden om de syntaxis te begrijpen en hoe deze was geïmplementeerd.
Parameters van verschillende objecten
Er zijn talloze Kubernetes-objecten en het is moeilijk om elke instelling te onthouden. Dat is waar het commando explain binnenkomt.
U kunt ook documentatie voor een specifiek veld verkrijgen door de syntaxis te gebruiken:
kubectl explain deployment.spec.replicasimplementatie bestand
Voor het gemak van herbruikbaarheid en veranderbaarheid worden meer geavanceerde implementaties doorgaans geschreven in YAML.
De basisbestandsstructuur is als volgt:
apiVersion: apps/v1 soort: Metadata van implementatie: # De naam en het label van uw implementatienaam: mongodb-implementatielabels: app: mongo spec: # Hoeveel exemplaren van elke pod wilt u replica's: 3 # Welke pods worden hiermee beheerd deployment selector: matchLabels: app: mongo # Normale podconfiguratie / Definieert containers, volumes en omgevingsvariabele sjabloon: metadata: # label de pod-labels: app: mongo spec: containers: - naam: mongo afbeelding: mongo:4.2 poorten: - containerPort : 27017
Er zijn verschillende cruciale secties in het YAML-bestand:
- apiVersion – Specificeert de API-versie.
- soort – Het Kubernetes-objecttype dat in het bestand is gedefinieerd (bijv. implementatie, service, persistent volume, …)
- metadata: een beschrijving van uw YAML-component die de naam, labels en andere informatie van de component bevat.
- spec: specificeert de kenmerken van uw implementatie, zoals replica's en resourcebeperkingen.
- template: de podconfiguratie van het implementatiebestand.
Nu u de basisindeling begrijpt, kunt u de opdracht Apply gebruiken om het bestand te implementeren.
Servicebestand
Servicebestanden zijn op dezelfde manier gestructureerd als implementaties, met kleine variaties in de parameters.
apiVersion: v1 soort: Service metadata: naam: mongo spec: selector: app: mongo poorten: - poort: 27017 targetPort: 27017 type: LoadBalancer
Opbergen
Wanneer de container opnieuw wordt opgestart of de pod wordt verwijderd, wordt het volledige bestandssysteem verwijderd. Het is een goed teken, omdat het ervoor zorgt dat uw staatloze toepassing niet verstopt raakt met onnodige gegevens. In andere omstandigheden is het behouden van de gegevens van uw bestandssysteem van cruciaal belang voor uw toepassing.
Er zijn verschillende soorten opslag beschikbaar:
- Het containerbestandssysteem slaat de gegevens van een enkele container op tot zijn bestaan.
- Met volumes kunt u gegevens opslaan en deze tussen containers delen zolang de pod actief is.
- Gegevens zijn opgeslagen, zelfs als de pod wordt gewist of opnieuw wordt opgestart met behulp van permanente volumes. Ze zijn de langetermijnopslag van uw Kubernetes-cluster.
Volumes
Met volumes kunt u gegevens tussen talloze containers in de pod opslaan, uitwisselen en bewaren. Het is handig als u pods hebt met veel containers die gegevens communiceren.
In Kubernetes zijn er twee fasen voor het gebruik van een volume:
- Het volume was bepaald door de pod.
- De container gebruikt volume-mounts om het volume toe te voegen aan een bepaald bestandssysteempad.
U kunt een volume aan uw pod toevoegen met behulp van de syntaxis:
apiVersion: v1 soort: Pod-metadata: naam: nginx spec: containers: - naam: nginx afbeelding: nginx volumeMounts: - naam: nginx-storage mountPath: /etc/nginx volumes: - naam: nginx-storage emptyDir: {}
Hier wordt de volume-tag gebruikt om een volume te leveren dat is gekoppeld aan een bepaalde map van het containerbestandssysteem (in dit geval /etc/nginx).
Aanhoudende volumes
Deze zijn bijna identiek aan conventionele volumes, met unieke verschilgegevens die bewaard zijn gebleven, zelfs als de pod wordt gewist. Daarom worden ze gebruikt voor langdurige gegevensopslag, zoals een database.
Een Persistent Volume Claim (PVC)-object, dat via een reeks abstracties verbinding maakt met backend-opslagvolumes, is de meest typische manier om een persistent volume te definiëren.
Voorbeeld van YAML-configuratiebestand.
apiVersion: v1 soort: PersistentVolumeClaim metadata: naam: pv-claim labels: app: sampleAppName spec: accessModes: - ReadWriteOnce bronnen: verzoeken: opslag: 20Gi
Er zijn meer opties om uw gegevens in Kubernetes op te slaan en u kunt het proces zoveel mogelijk automatiseren. Hier is een lijst met een paar interessante onderwerpen om naar te kijken.
Computerbronnen
Met het oog op de indeling van containers is het beheer van rekenresources voor uw containers en toepassingen van cruciaal belang.
Wanneer uw containers een bepaald aantal resources hebben, kan de planner verstandige beslissingen nemen over welk knooppunt de pod moet worden geplaatst. U zult ook minder problemen hebben met resourceconflicten met diverse implementaties.
In de volgende twee delen gaan we dieper in op twee soorten resourcedefinities.
Aanvragen
Verzoeken vertellen Kubernetes wat de pod nodig heeft en dat het de pod alleen op knooppunten mag plaatsen die aan die behoeften voldoen. Verzoeken worden gedefinieerd in de resourcetag van uw container.
Grenzen
Bronbeperkingen worden gebruikt om het geheugen en het CPU-gebruik van een pod te beperken en de maximale hoeveelheid bronnen in te stellen die het nooit kan overtreffen.
Secrets
Met geheimen in Kubernetes kunt u gevoelige gegevens zoals wachtwoorden, API-tokens en SSH-sleutels veilig opslaan en beheren.
Als u een geheim in uw pod wilt gebruiken, moet u er eerst naar verwijzen. Het kan op veel verschillende manieren gebeuren:
- Een omgevingsvariabele gebruiken en als een bestand op een schijf die is gekoppeld aan een container.
- Wanneer kubelet een afbeelding uit een privéregister haalt.
Een geheim maken
Geheimen waren gemaakt met behulp van de kubelet-opdrachttool of door een geheim Kubernetes-object in YAML te declareren.
De kubus gebruiken
Met Kubelet kunt u geheimen maken met een create-opdracht waarvoor alleen de gegevens en de geheime naam nodig zijn. De gegevens worden ingevoerd met behulp van een bestand of een letterlijke.
kubectl create secret generic admin-credentials --from-literal=user=poweruser --from-literal=password='test123'Als u een bestand gebruikt, ziet dezelfde functionaliteit er als volgt uit.
echo -n 'poweruser' > ./gebruikersnaam.txt echo -n 'test123' > ./password.txt kubectl maak geheime generieke admin-credentials--from-file=./username.txt --from-file=./ wachtwoord.txt
Gebruik maken van definitiebestanden
Geheimen kunnen, net als andere Kubernetes-objecten, worden gedeclareerd in een YAML-bestand.
apiVersion: v1 soort: Geheime metadata: naam: geheime-apikey data: apikey: YWRtaW4=
Uw gevoelige informatie wordt in het geheim opgeslagen als een sleutel-waardepaar, met apiKey als de sleutel en YWRtaW4= als de gedecodeerde basiswaarde.
Met behulp van de opdracht Apply kunt u nu het geheim genereren.
kubectl apply -f secret.yamlGebruik in plaats daarvan het kenmerk stringData als u gewone gegevens wilt geven en Kubernetes de codering wilt laten afhandelen.
apiVersion: v1 soort: geheime metadata: naam: platte tekst-geheime stringData: wachtwoord: test
ImagePullSecrets
Als u een afbeelding uit een privéregister haalt, moet u zich mogelijk eerst verifiëren. Wanneer al uw knooppunten een specifieke afbeelding moeten maken, bewaart een ImagePullSecrets-bestand de authenticatie-informatie en maakt deze voor hen beschikbaar.
apiVersion: v1 soort: Pod metadata: naam: private-image spec: containers: - naam: privateapp image: gabrieltanner/graphqltesting imagePullSecrets: - naam: authenticatie-geheim
Namespaces
Naamruimten zijn virtuele clusters die werden gebruikt om grote projecten te beheren en clusterbronnen aan veel gebruikers toe te wijzen. Ze bieden verschillende namen en kunnen in elkaar worden genest.
Het beheren en gebruiken van naamruimten met kubectl is eenvoudig. In dit gedeelte wordt u door de meest voorkomende naamruimteacties en -opdrachten geleid.
Kijk naar de bestaande naamruimten
U kunt de opdracht kubectl get namespaces gebruiken om alle momenteel toegankelijke naamruimten van uw cluster te zien.
kubectl get namespaces # Uitvoer NAAM STATUS LEEFTIJD standaard Actief 32d docker Actief 32d kube-public Actief 32d kube-system Actief 32d
Naamruimte maken
Naamruimten kunnen worden gemaakt met de kubectl CLI of door YAML te gebruiken om een Kubernetes-object te maken.
kubectl create namespace testnamespace # Output namespace/testnamespace aangemaakt
Dezelfde functionaliteit kan worden bereikt met een YAML-bestand.
apiVersion: v1 soort: naamruimte metadata: naam: testnamespace
De opdracht kubectl apply kan vervolgens worden gebruikt om het configuratiebestand toe te passen.
kubectl apply -f testNamespace.yamlNaamruimte filteren
Wanneer een nieuw object in Kubernetes is gemaakt zonder een aangepaste naamruimte-eigenschap, wordt dit toegevoegd aan de standaardnaamruimte.
U kunt dit doen als u uw item in een andere werkruimte wilt bouwen.
kubectl create deployment --image=nginx nginx --namespace=testnamespaceU kunt nu de opdracht get gebruiken om te filteren op uw implementatie.
kubectl get deployment --namespace=testnamespaceNaamruimte wijzigen
U hebt nu geleerd hoe u objecten construeert in een andere naamruimte dan de standaardnaam. Het toevoegen van de naamruimte aan elke opdracht die u wilt uitvoeren, kost echter tijd en geeft een foutmelding.
Als gevolg hiervan kunt u de opdracht set-context gebruiken om de standaardcontext te wijzigen waarop instructies van toepassing waren.
kubectl config set-context $(kubectl config current-context) --namespace=testnamespaceDe opdracht get-context kan worden gebruikt om de wijzigingen te valideren.
kubectl config get-contexts # Uitvoer HUIDIGE NAAM CLUSTER AUTHINFO NAMESPACE * Standaard Standaard Standaard testnaamruimte
Kubernetes met Docker Compose
Voor individuen die uit de Docker-gemeenschap komen, kan het schrijven van Docker Compose-bestanden in plaats van Kubernetes-objecten eenvoudig zijn. Kompose komt in deze situatie om de hoek kijken. Het gebruikt een eenvoudige CLI om uw docker-compose-bestand naar Kubernetes (opdrachtregelinterface) te converteren of te implementeren.
Hoe Kompose te installeren
Het is eenvoudig en snel te implementeren op alle drie de volwassen besturingssystemen.
Om Kompose op Linux of Mac te installeren, krul je de binaire bestanden.
# Linux curl -L https://github.com/kubernetes/kompose/releases/download/v1.21.0/kompose-linux-amd64 -o kompose # macOS curl -L https://github.com/kubernetes/kompose/ releases/download/v1.21.0/kompose-darwin-amd64 -o kompose chmod +x kompose sudo mv ./kompose /usr/local/bin/kompose
Implementeren met Kompose
Kompose implementeert Docker Compose-bestanden op Kubernetes met behulp van bestaande Docker Compose-bestanden. Beschouw het volgende samengestelde bestand als voorbeeld.
versie: "2" services: redis-master: afbeelding: k8s.gcr.io/redis:e2e-poorten: - "6379" redis-slave: afbeelding: gcr.io/google_samples/gb-redisslave:v1-poorten: - "6379 " omgeving: - GET_HOSTS_FROM=dns frontend: afbeelding: gcr.io/google-samples/gb-frontend:v4 poorten: - "80:80" omgeving: - GET_HOSTS_FROM=dns-labels: kompose.service.type: LoadBalancer
Met Kompose kunnen we, net als Docker Compose, onze setup implementeren met een enkele opdracht.
kom op
Je zou nu in staat moeten zijn om de bronnen te zien die waren geproduceerd.
kubectl get deployment,svc,pods,pvcKompose omzetten
Kompose kan ook uw bestaande Docker Compose-bestand omzetten in het Kubernetes-object dat u nodig hebt.
kompose convertDe opdracht Apply was gebruikt om uw toepassing te implementeren.
kubectl apply -f filenamesToepassing Implementatie
Nu je de theorie en alle kernideeën van Kubernetes onder de knie hebt, is het tijd om het geleerde in de praktijk te brengen. In dit hoofdstuk wordt uitgelegd hoe u Kubernetes gebruikt om een backend-applicatie te implementeren.
De specifieke toepassing van deze tutorial is een GraphQL-boilerplate voor het backend-framework van Nest.js.
Laten we eerst de repository klonen.
git clone https://github.com/[user name]/nestjs-graphql-boilerplate.gitAfbeeldingen naar een register
We moeten de afbeeldingen eerst naar een openbaar toegankelijk Image Register pushen voordat we beginnen met de constructie van Kubernetes-objecten. Het kan een openbaar register zijn zoals DockerHub of een eigen privéregister.
Bezoek dit bericht voor meer informatie over het maken van je eigen privé Docker-afbeelding.
Om de afbeelding te pushen, neemt u de afbeeldingstag op in uw Compose-bestand samen met het register dat u wilt verplaatsen.
versie: '3' services: nodejs: build: context: ./ dockerfile: Dockerfile afbeelding: gabrieltanner.dev/nestgraphql herstart: altijd omgeving: - DATABASE_HOST=mongo - PORT=3000 poorten: - '3000:3000' depend_on: [mongo ] mongo: afbeelding: mongo poorten: - '27017:27017' volumes: - mongo_data:/data/db volumes: mongo_data: {}
Ik gebruikte een privéregister dat ik eerder had ingesteld, maar DockerHub zou net zo goed werken.
Kubernetes-objecten maken
Nu u uw afbeelding naar een register heeft gepubliceerd, gaan we onze Kubernetes-objecten schrijven.
Maak om te beginnen een nieuwe map waarin u de implementaties wilt opslaan.
mkdir-implementaties cd-implementaties touch mongo.yaml touch nestjs.yaml
Dit is hoe de MongoDB-service en -implementatie eruit zullen zien.
apiVersion: v1 soort: Service metadata: naam: mongo spec: selector: app: mongo poorten: - poort: 27017 targetPort: 27017 --- apiVersion: apps/v1 soort: implementatie metadata: naam: mongo spec: selector: matchLabels: app : mongo-sjabloon: metadata: labels: app: mongo spec: containers: - naam: mongo afbeelding: mongo-poorten: - containerPort: 27017
Een implementatieobject met een enkele MongoDB-container met de naam mongo was in het bestand opgenomen. Het wordt ook geleverd met een service waarmee het Kubernetes-netwerk poort 27017 kan gebruiken.
Omdat de container enkele aanvullende instellingen vereist, zoals omgevingsvariabelen en imagePullSecrets, is het Nest.js Kubernetes-object iets gecompliceerder.
Een load balancer helpt de service die de poort beschikbaar maakt op de hostcomputer.
Implementeer de applicatie
Nu de Kubernetes-objectbestanden gereed zijn. Laten we kubectl gebruiken om ze te implementeren.
kubectl Apply -f mongo.yaml kubectl Apply -f nestjs.yaml
Op localhost/graphql zou je nu de GraphQL-speeltuin moeten zien.
Gefeliciteerd, u heeft zojuist uw eerste Kubernetes-toepassing geïmplementeerd.

Je hebt volgehouden tot het einde! Ik hoop dat deze handleiding je een beter begrip heeft gegeven van Kubernetes en de manier waarop je Kubernetes kunt gebruiken om je ontwikkelproces te verbeteren, met betere oplossingen van productiekwaliteit.
Kubernetes is gemaakt met behulp van de tien jaar ervaring van Google met het op grote schaal uitvoeren van gecontaineriseerde apps. Het is al overgenomen door de beste leveranciers van openbare cloud en technologieleveranciers en wordt nu overgenomen door de meeste softwarefabrikanten en bedrijven. Het resulteerde zelfs in de oprichting van de Cloud Native Computing Foundation (CNCF) in 2015, het eerste project dat afstudeerde onder CNCF en begon met het stroomlijnen van het container-ecosysteem naast andere containergerelateerde projecten zoals CNI, Containers, Envoy, Fluentd, gRPC, Jagger, Linkerd en Prometheus. Het onberispelijke ontwerp, de samenwerking met marktleiders, het open source maken en altijd openstaan voor ideeën en bijdragen, kunnen de belangrijkste redenen zijn voor zijn populariteit en goedkeuring op zo'n hoog niveau.
Deel dit met andere ontwikkelaars, als je het nuttig vindt.
Bekijk de onderstaande links voor meer informatie over Kubernetes:
Leer basisprincipes van onze blog.
Referenties
Afbeelding-1 – Foto door Ian Taylor On Unsplash
Afbeelding-2,3,4,5 – https://kubernetes.io/docs/tutorials/kubernetes-basics/
Afbeelding-6 – Foto door Xan Griffioen On Unsplash
De in dit artikel getoonde media zijn geen eigendom van Analytics Vidhya en worden naar goeddunken van de auteur gebruikt.
Verwant
Bron: https://www.analyticsvidhya.com/blog/2022/01/a-comprehensive-guide-on-kubernetes/

