Afbeelding van Bing Image Creator
Wie is er niet geamuseerd door technologische vooruitgang, met name in kunstmatige intelligentie, van Alexa tot Tesla zelfrijdende auto's en talloze andere innovaties? Ik verbaas me om de andere dag over de vooruitgang, maar wat nog interessanter is, is wanneer je een idee krijgt van wat aan die innovaties ten grondslag ligt. Welkom bij Artificial Intelligence en de eindeloze mogelijkheden van diepgaand leren. Als je je hebt afgevraagd wat het is, dan ben je thuis.
In deze tutorial zal ik de terminologie deconstrueren en je laten zien hoe je een deep learning-taak in R kunt uitvoeren. Merk op dat dit artikel ervan uitgaat dat je een basiskennis hebt van machine learning concepten zoals: regressie, classificatie en clustering.
Laten we beginnen met definities van enkele terminologieën rond het concept van diep leren:
Diepe leer is een tak van machine learning die computers leert de cognitieve functies van het menselijk brein na te bootsen. Dit wordt bereikt door het gebruik van kunstmatige neurale netwerken die helpen om complexe patronen in datasets uit te pakken. Met deep learning kan een computer geluiden, afbeeldingen of zelfs teksten classificeren.
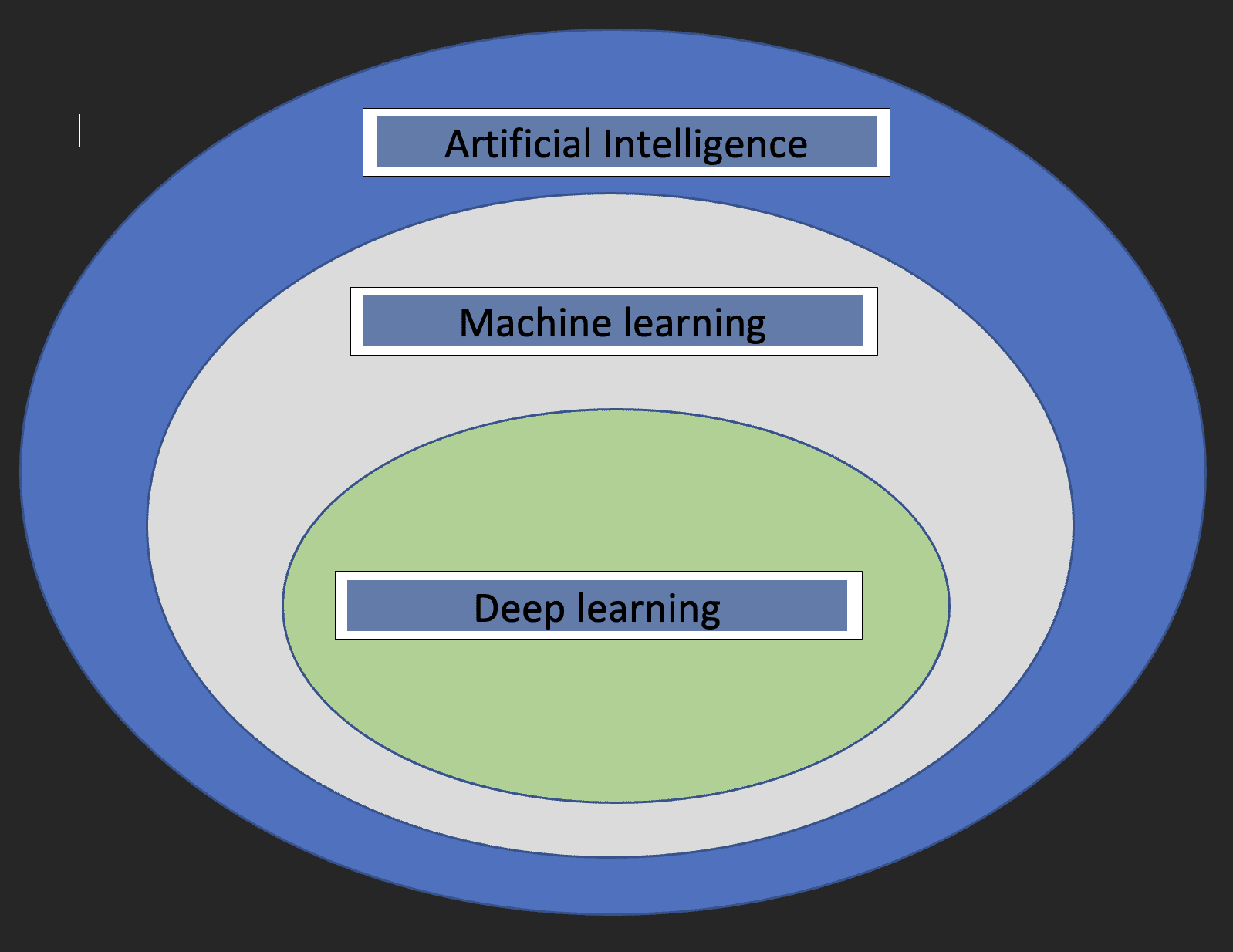
Voordat we ingaan op de details van Deep learning, zou het leuk zijn om te begrijpen wat machine learning en kunstmatige intelligentie zijn en hoe de drie concepten zich tot elkaar verhouden.
kunstmatige intelligentie: Dit is een tak van de informatica die zich bezighoudt met de ontwikkeling van machines waarvan de werking het menselijk brein nabootst.
machine learning: Dit is een subset van kunstmatige intelligentie waarmee computers kunnen leren van gegevens.
Met bovenstaande definities hebben we nu een idee van hoe diep leren zich verhoudt tot kunstmatige intelligentie en machine learning.
Het onderstaande diagram helpt de relatie te tonen.
Twee cruciale dingen om op te merken over diep leren zijn:
- Vereist enorme hoeveelheden gegevens
- Vereist krachtige rekenkracht
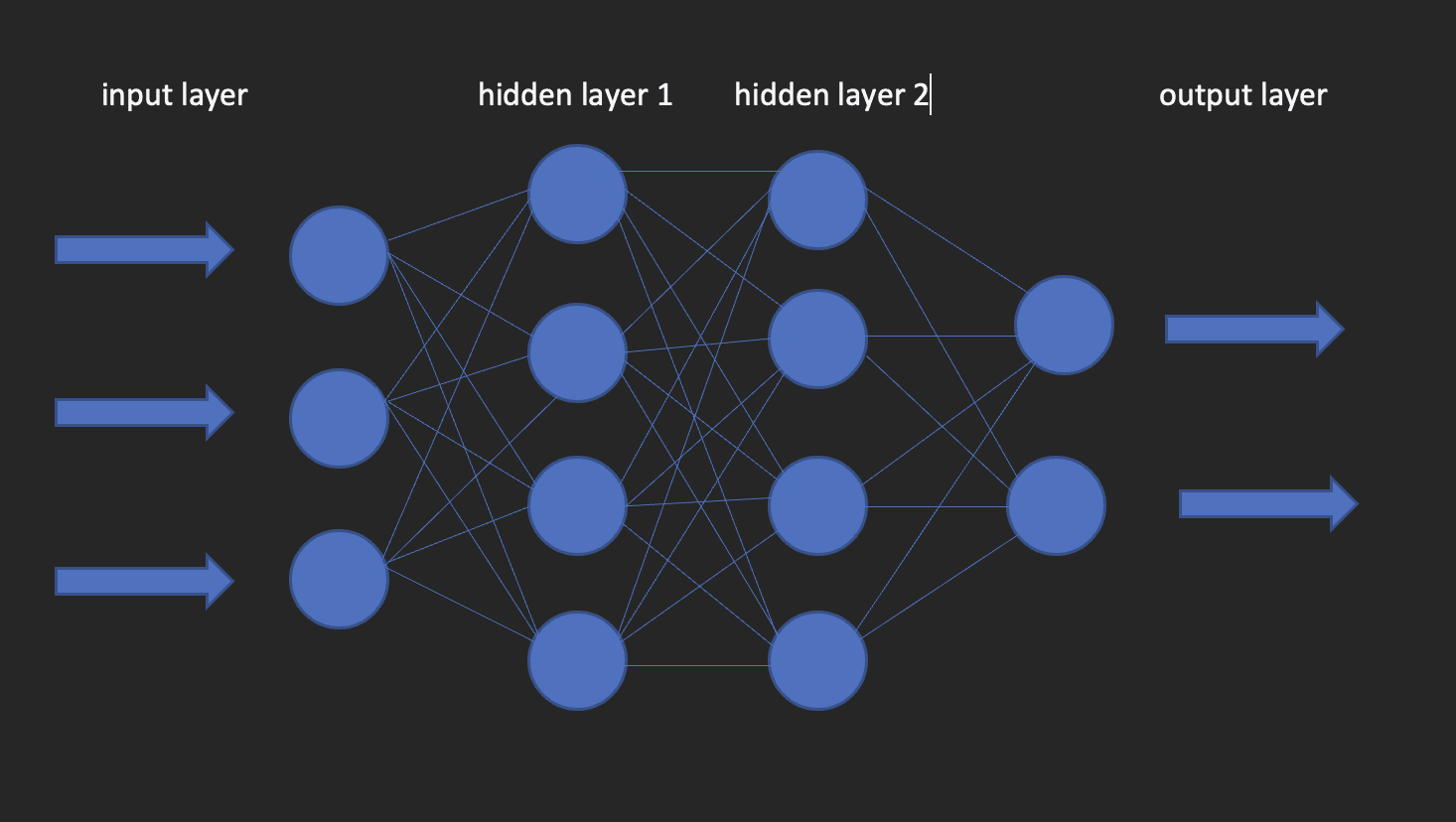
Dit zijn de bouwstenen van deep learning-modellen. Zoals de naam al doet vermoeden, komt het woord neuraal van neuronen, net als de neuronen van het menselijk brein. Eigenlijk haalt de architectuur van diepe neurale netwerken zijn inspiratie uit de structuur van het menselijk brein.
Een neuraal netwerk heeft een invoerlaag, een verborgen laag en een uitvoerlaag. Dit netwerk wordt een ondiep neuraal netwerk genoemd. Als we meer dan één verborgen laag hebben, wordt het een diep neuraal netwerk, waar de lagen wel honderden kunnen zijn.
De afbeelding hieronder laat zien hoe een neuraal netwerk eruit ziet.
Dit brengt ons bij de vraag hoe we deep learning-modellen kunnen bouwen in R? Voer kera in!
Keras is een open-source deep learning-bibliotheek die het gemakkelijk maakt om neurale netwerken te gebruiken bij machine learning. Deze bibliotheek is een wrapper die gebruikt TensorFlow als een backend-engine. Er zijn echter andere opties voor de backend zoals Theano of CNTK.
Laten we nu beide installeren TensorFlow en Keras.
Begin met het creëren van een virtuele omgeving met behulp van reticulate
library(reticulate)
virtualenv_create("virtualenv", python = "/path/to/your/python3") install.packages(“tensorflow”) #This is only done once! library(tensorflow) install_tensorflow(envname = "/path/to/your/virtualenv", version = "cpu") install.packages(“keras”) #do this once! library(keras) install_keras(envname = "/path/to/your/virtualenv") # confirm the installation was successful
tf$constant("Hello TensorFlow!")
Nu onze configuraties zijn ingesteld, kunnen we kijken hoe we deep learning kunnen gebruiken om een classificatieprobleem op te lossen.
De gegevens die ik voor deze zelfstudie zal gebruiken, zijn afkomstig uit een lopende salarisenquête uitgevoerd door https://www.askamanager.org.
De belangrijkste vraag die in het formulier wordt gesteld, is hoeveel geld u verdient, plus nog een paar details zoals branche, leeftijd, jarenlange ervaring, enz. De details worden verzameld in een Google-spreadsheet waaruit ik de gegevens heb verkregen.
Het probleem dat we met data willen oplossen, is een deep learning-model te kunnen bedenken dat voorspelt hoeveel iemand potentieel zou kunnen verdienen gegeven informatie zoals leeftijd, geslacht, aantal jaren ervaring en hoogste opleidingsniveau.
Laad de bibliotheken die we nodig hebben.
library(dplyr)
library(keras)
library(caTools)
Importeer de gegevens
url - “https://raw.githubusercontent.com/oyogo/salary_dashboard/master/data/salary_data_cleaned.csv” salary_data - read.csv(url)
Selecteer de kolommen die we nodig hebben
salary_data - salary_data %>% select(age,professional_experience_years,gender,highest_edu_level,annual_salary)
Herinner je je het informatica-GIGO-concept nog? (Vuilnis in vuilnis eruit). Welnu, dit concept is hier perfect toepasbaar, net als in andere domeinen. De resultaten van onze training zullen grotendeels afhangen van de kwaliteit van de gegevens die we gebruiken. Dit is wat het opschonen en transformeren van gegevens met zich meebrengt, een cruciale stap in elke stap data Science project.
Enkele van de belangrijkste problemen die het opschonen van gegevens probeert aan te pakken zijn; consistentie, ontbrekende waarden, spellingsproblemen, uitschieters en gegevenstypen. Ik zal niet ingaan op de details over hoe deze kwesties worden aangepakt en dit is om de simpele reden dat ik niet wil afwijken van het onderwerp van dit artikel. Daarom zal ik de opgeschoonde versie van de gegevens gebruiken, maar als je wilt weten hoe het opschonen is afgehandeld, lees dan dit artikel.
Kunstmatige neurale netwerken accepteren alleen numerieke variabelen en aangezien sommige van onze variabelen van categorische aard zijn, zullen we deze in getallen moeten coderen. Dit maakt deel uit van de gegevens voorbewerken stap, wat nodig is omdat u vaker wel dan niet gegevens krijgt die klaar zijn voor modellering.
# create an encoder function
encode_ordinal - function(x, order = unique(x)) { x - as.numeric(factor(x, levels = order, exclude = NULL))
} salary_data - salary_data %>% mutate( highest_edu_level = encode_ordinal(highest_edu_level, order = c("High School","College degree","Master's degree","Professional degree (MD, JD, etc.)","PhD")), professional_experience_years = encode_ordinal(professional_experience_years, order = c("1 year or less", "2 - 4 years","5-7 years", "8 - 10 years", "11 - 20 years", "21 - 30 years", "31 - 40 years", "41 years or more")), age = encode_ordinal(age, order = c( "under 18", "18-24","25-34", "35-44", "45-54", "55-64","65 or over")), gender = case_when(gender== "Woman" ~ 0, gender == "Man" ~ 1))
Aangezien we een classificatie willen oplossen, moeten we het jaarsalaris in twee klassen verdelen, zodat we het als responsvariabele gebruiken.
salary_data - salary_data %>% mutate(categories = case_when( annual_salary = 100000 ~ 0, annual_salary > 100000 ~ 1)) salary_data - salary_data %>% select(-annual_salary)Zoals in de basisbenaderingen van machine learning; regressie, classificatie en clustering, zullen we onze gegevens moeten opsplitsen in trainings- en testsets. Dit doen we aan de hand van de 80-20 regels, dat is 80% van de dataset voor training en 20% voor testen. Dit is niet op stenen gegoten, aangezien u kunt besluiten om naar eigen inzicht split-ratio's te gebruiken, maar houd er rekening mee dat de trainingsset een goed deel van de percentages moet hebben.
set.seed(123) sample_split - sample.split(Y = salary_data$categories, SplitRatio = 0.7)
train_set - subset(x=salary_data, sample_split == TRUE)
test_set - subset(x = salary_data, sample_split == FALSE) y_train - train_set$categories
y_test - test_set$categories
x_train - train_set %>% select(-categories)
x_test - test_set %>% select(-categories)
Keras neemt invoer op in de vorm van matrices of arrays. We gebruiken de functie as.matrix voor de conversie. We moeten ook de voorspellingsvariabelen schalen en vervolgens converteren we de responsvariabele naar het categorische gegevenstype.
x - as.matrix(apply(x_train, 2, function(x) (x-min(x))/(max(x) - min(x)))) y - to_categorical(y_train, num_classes = 2)Instantie van het model
Maak een sequentieel model waarop we lagen zullen toevoegen met behulp van de pipe-operator.
model = keras_model_sequential()Configureer de lagen
De invoer_vorm specificeert de vorm van de invoergegevens. In ons geval hebben we dat verkregen met behulp van de NcoI functie. activering: Hier specificeren we de activeringsfunctie; een wiskundige functie die de uitvoer transformeert naar een gewenste niet-lineaire indeling voordat deze wordt doorgegeven aan de volgende laag.
eenheden: het aantal neuronen in elke laag van het neurale netwerk.
model %>% layer_dense(input_shape = ncol(x), units = 10, activation = "relu") %>% layer_dense(units = 10, activation = "relu") %>% layer_dense(units = 2, activation = "sigmoid")Hiervoor gebruiken we de compile-methode. De functie heeft drie argumenten nodig;
optimizer : Dit object specificeert de trainingsprocedure. uit : Dit is de functie die moet worden geminimaliseerd tijdens optimalisatie. Beschikbare opties zijn mse (mean square error), binary_crossentropy en categorical_crossentropy.
metriek : Wat we gebruiken om de training te monitoren. Nauwkeurigheid voor classificatieproblemen.
model %>% compile( loss = "binary_crossentropy", optimizer = "adagrad", metrics = "accuracy"
)We kunnen het model nu fitten met behulp van de fit-methode van Keras. Enkele van de argumenten die passen zijn:
tijdperken : Een tijdperk is een iteratie van de trainingsdataset.
seriegrootte : Het model verdeelt de matrix/array die eraan is doorgegeven in kleinere batches die tijdens de training worden herhaald.
validatie_split : Keras zal een deel van de trainingsgegevens moeten splitsen om een validatieset te verkrijgen die zal worden gebruikt om de modelprestaties voor elk tijdvak te evalueren.
schudden : Hier geeft u aan of u uw trainingsgegevens voor elk tijdperk wilt schudden.
fit = model %>% fit( x = x, y = y, shuffle = T, validation_split = 0.2, epochs = 100, batch_size = 5
)Evalueer het model
Gebruik de evaluatiefunctie zoals hieronder om de nauwkeurigheidswaarde van het model te verkrijgen.
y_test - to_categorical(y_test, num_classes = 2)
model %>% evaluate(as.matrix(x_test),y_test)Voorspelling
Gebruik de predict_classes-functie van de keras-bibliotheek om nieuwe gegevens te voorspellen, zoals hieronder.
model %>% predict(as.matrix(x_test))Dit artikel heeft u door de basisprincipes van diep leren met Keras in R geleid. U bent van harte welkom om dieper te duiken voor een beter begrip, te spelen met de parameters, uw handen vuil te maken met gegevensvoorbereiding en misschien de berekeningen te schalen door gebruik te maken van de kracht van cloudcomputing.
Clinton Oyogo schrijver bij Saturnus Cloud is van mening dat het analyseren van gegevens voor bruikbare inzichten een cruciaal onderdeel is van zijn dagelijkse werk. Met zijn vaardigheden op het gebied van datavisualisatie, dataruzie en machine learning is hij trots op zijn werk als datawetenschapper.
ORIGINELE. Met toestemming opnieuw gepost.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- PlatoAiStream. Web3 gegevensintelligentie. Kennis versterkt. Toegang hier.
- De toekomst slaan met Adryenn Ashley. Toegang hier.
- Koop en verkoop aandelen in PRE-IPO-bedrijven met PREIPO®. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/05/deep-learning-r.html?utm_source=rss&utm_medium=rss&utm_campaign=deep-learning-with-r

