De laatste jaren zijn taalmodellen (LM's) prominenter aanwezig in het onderzoek naar natuurlijke taalverwerking (NLP) en krijgen ze ook steeds meer impact in de praktijk. Het is aangetoond dat het opschalen van LM's de prestaties verbetert bij een reeks NLP-taken. Zo kan het opschalen van taalmodellen verbeteren verwarring over zeven ordes van grootte van modelgroottes en nieuwe mogelijkheden zoals redeneren in meerdere stappen zijn waargenomen ontstaan als gevolg van modelschaal. Een van de uitdagingen van voortdurende schaalvergroting is echter dat het trainen van nieuwe, grotere modellen grote hoeveelheden rekenkracht vereist. Bovendien worden nieuwe modellen vaak helemaal opnieuw getraind en maken ze geen gebruik van de gewichten van eerder bestaande modellen.
In deze blogpost onderzoeken we twee complementaire methoden om bestaande taalmodellen met een grote marge te verbeteren zonder gebruik te maken van enorme rekenbronnen. Eerst in “Schaalwetten overstijgen met 0.1% extra rekenkracht”, introduceren we UL2R, een lichtgewicht tweede fase van pre-training die gebruik maakt van een mix-of-denoisers doelstelling. UL2R verbetert de prestaties voor een reeks taken en ontgrendelt zelfs opkomende prestaties op taken die voorheen bijna willekeurige prestaties hadden. Ten tweede, in “Schaalinstructie-gefinetunede taalmodellen”, verkennen we het verfijnen van een taalmodel op een verzameling datasets die zijn geformuleerd als instructies, een proces dat we "Flan" noemen. Deze aanpak verbetert niet alleen de prestaties, maar verbetert ook de bruikbaarheid van het taalmodel voor gebruikersinvoer zonder engineering van prompts. Ten slotte laten we zien dat Flan en UL2R kunnen worden gecombineerd als complementaire technieken in een model genaamd Flan-U-PaLM 540B, dat 540% beter presteert dan het niet-aangepaste PaLM 10B-model in een reeks uitdagende evaluatiebenchmarks.
UL2R-training
Traditioneel zijn de meeste taalmodellen vooraf getraind op a causale taal modelleringsdoelstelling waarmee het model het volgende woord in een reeks kan voorspellen (bijv. GPT-3 or Palm) of a denoising doelstelling, waar het model leert de oorspronkelijke zin te herstellen van een gecorrumpeerde reeks woorden (bijv. T5). Hoewel er enkele compromissen zijn in de doelstellingen van taalmodellering, zijn causale LM's beter in het genereren van lange vormen en zijn LM's die zijn getraind op een doel om ruis te verminderen beter in het verfijnen. eerder werk we gedemonstreerd dat een mix van denoisers-doelstelling die beide doelstellingen omvat, resulteert in betere prestaties in beide scenario's.
Het vooraf trainen van een groot taalmodel met een ander doel vanuit het niets kan rekenkundig onbetaalbaar zijn. Daarom stellen we UL2 Repair (UL2R) voor, een extra fase van voortdurende pre-training met de UL2-doelstelling die slechts een relatief kleine hoeveelheid rekenkracht vereist. We passen UL2R toe op PaLM en noemen het resulterende nieuwe taalmodel U-PaLM.
In empirische evaluaties ontdekten we dat schaalcurves aanzienlijk verbeteren met slechts een kleine hoeveelheid UL2-training. We laten bijvoorbeeld zien dat door UL2R te gebruiken op het tussenliggende controlepunt van PaLM 540B, we de prestaties bereiken van het laatste PaLM 540B-controlepunt terwijl we 2x minder rekenkracht gebruiken (of een verschil van 4.4 miljoen TPUv4-uren). Uiteraard leidt het toepassen van UL2R op het laatste PaLM 540B-controlepunt ook tot substantiële verbeteringen, zoals beschreven in het artikel.
 |
| Bereken versus modelprestaties van PaLM 540B en U-PaLM 540B op 26 NLP-benchmarks (vermeld in Tabel 8 in de krant). U-PaLM 540B blijft PaLM trainen voor een zeer kleine hoeveelheid rekenkracht, maar levert een aanzienlijke prestatiewinst op. |
Een ander voordeel dat we hebben waargenomen bij het gebruik van UL2R, is dat de prestaties bij sommige taken veel beter zijn dan modellen die puur zijn getraind op het doel van causale taalmodellering. Er zijn er bijvoorbeeld veel BIG-bank taken die zijn beschreven als "opkomende vermogens”, dwz vaardigheden die alleen kunnen worden waargenomen in voldoende grote taalmodellen. Hoewel de manier waarop opkomende vaardigheden het meest worden gevonden, is door de grootte van de LM op te schalen, ontdekten we dat UL2R opkomende vaardigheden daadwerkelijk kan opwekken zonder de schaal van de LM te vergroten.
Bijvoorbeeld in de OP DEZE WEBSITE VIND JE taak van BIG-Bench, die het vermogen van het model meet om state tracking uit te voeren, alle modellen behalve U-PaLM met minder dan 1023 trainings-FLOP's bereiken ongeveer willekeurige prestaties. U-PaLM-prestaties liggen meer dan 10 punten daarboven. Een ander voorbeeld hiervan is de Snarks taak van BIG-Bench, die het vermogen van het model meet om sarcasme te detecteren. Nogmaals, terwijl alle modellen minder dan 1024 training FLOP's bereiken ongeveer willekeurige prestaties, U-PaLM presteert ver boven zelfs voor de 8B- en 62B-modellen.
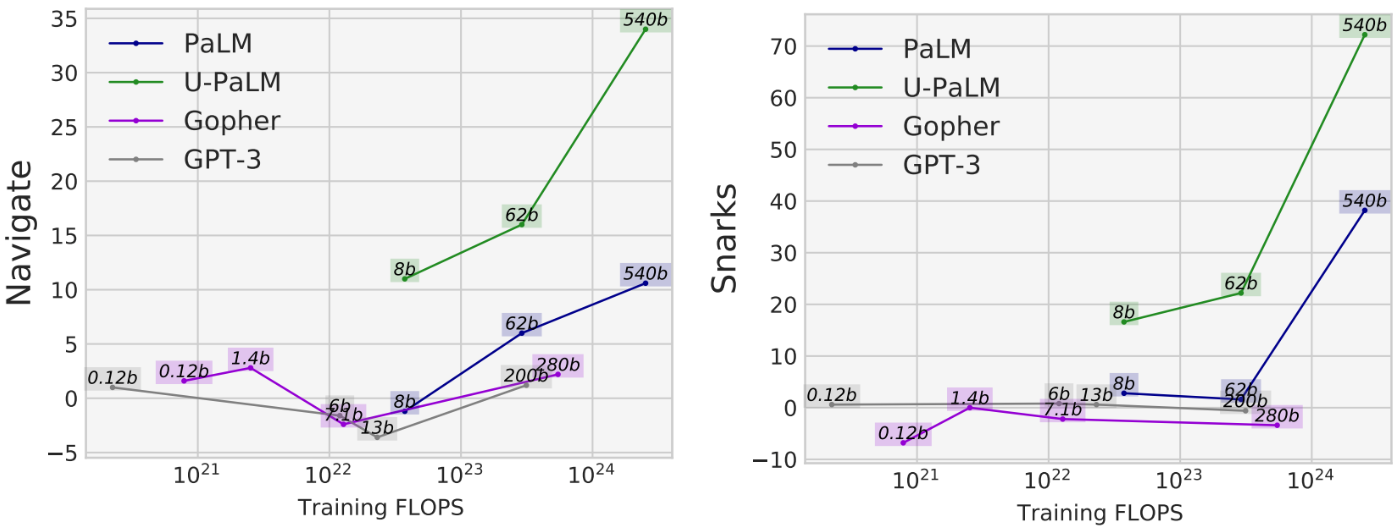 |
| Voor twee capaciteiten van BIG-bank die opkomende taakprestaties demonstreren, bereikt U-PaLM opkomst bij een kleinere modelgrootte dankzij het gebruik van de UL2R-doelstelling. |
Instructie Fine-Tuning
In onze tweede papier, onderzoeken we de verfijning van instructies, waarbij LM's worden verfijnt op een verzameling NLP-datasets die als instructies zijn geformuleerd. In eerder werkhebben we instructieverfijning toegepast op een 137B-parametermodel voor 62 NLP-taken, zoals het beantwoorden van een trivia-vraag, het classificeren van het sentiment van een film of het vertalen van een zin naar het Spaans.
In dit werk verfijnen we een 540B-parametertaalmodel voor meer dan 1.8K taken. Bovendien, terwijl eerdere pogingen een LM alleen verfijnden met exemplaren met weinig schoten (bijv. MetaICL) of zero-shot zonder voorbeelden (bijv. VLAAI, T0), stemmen we af op een combinatie van beide. Wij omvatten ook keten van gedachten fijnafstemming van gegevens, waardoor het model een meerstaps redenering kan uitvoeren. We noemen onze verbeterde methodologie "Flan", voor het verfijnen van taalmodellen. Met name, zelfs met fijnafstemming op 1.8K-taken, gebruikt Flan slechts een klein deel van de rekenkracht in vergelijking met pre-training (bijvoorbeeld voor PaLM 540B heeft Flan slechts 0.2% van de pre-training rekenkracht nodig).
 |
| We verfijnen taalmodellen op 1.8K-taken die als instructies zijn geformuleerd, en evalueren ze op ongeziene taken, die niet zijn opgenomen in de verfijning. We verfijnen zowel met als zonder voorbeelden (dwz zero-shot en few-shot) en met en zonder gedachteketen, waardoor generalisatie over een reeks evaluatiescenario's mogelijk wordt. |
In de paper geven we instructies voor het verfijnen van LM's van verschillende groottes om het gezamenlijke effect van het schalen van zowel de grootte van de LM als het aantal fijnafstemmingstaken te onderzoeken. Bijvoorbeeld voor de PaLM-klasse van LM's, die modellen met 8B-, 62B- en 540B-parameters omvat. We evalueren onze modellen op vier uitdagende benchmark-evaluatiesuites (MMLU, BBH, TyDiQA en MGSM), en ontdek dat zowel het schalen van het aantal parameters als het aantal fijnafstemmingstaken de prestaties op ongeziene taken verbetert.
 |
| Zowel het opschalen naar een 540B-parametermodel als het gebruik van 1.8K fijnafstemmingstaken verbeteren de prestaties bij ongeziene taken. De y-as is het genormaliseerde gemiddelde over vier evaluatiesuites (MMLU, BBH, TyDiQA en MGSM). |
Naast betere prestaties, stelt het nauwkeurig afstemmen van instructies een LM in staat om te reageren op instructies van de gebruiker op het moment van inferentie, zonder enkele voorbeelden of snelle engineering. Dit maakt LM's gebruiksvriendelijker voor een reeks ingangen. LM's zonder instructie-fijnafstemming kunnen bijvoorbeeld soms de invoer herhalen of instructies niet volgen, maar instructie-fijnafstemming vermindert dergelijke fouten.
 |
| Ons instructie-verfijnde taalmodel, Flan-PaLM, reageert beter op instructies in vergelijking met het PaLM-model zonder instructie-fijnafstemming. |
Ze bij elkaar zetten
Ten slotte laten we zien dat UL2R en Flan kunnen worden gecombineerd om het Flan-U-PaLM-model te trainen. Omdat Flan nieuwe gegevens van NLP-taken gebruikt en het volgen van zero-shot instructies mogelijk maakt, passen we Flan toe als de tweede methode na UL2R. We evalueren opnieuw de vier benchmarksuites en vinden dat het Flan-U-PaLM-model beter presteert dan PaLM-modellen met alleen UL2R (U-PaLM) of alleen Flan (Flan-PaLM). Verder bereikt Flan-U-PaLM een nieuwe state-of-the-art op de MMLU-benchmark met een score van 75.4% in combinatie met gedachtegang en zelfconsistentie.
 |
| Het combineren van UL2R en Flan (Flan-U-PaLM) leidt tot de beste prestaties in vergelijking met alleen het gebruik van UL2R (U-PaLM) of alleen Flan (Flan-U-PaLM). Prestaties zijn het genormaliseerde gemiddelde over vier evaluatiesuites (MMLU, BBH, TyDiQA en MGSM). |
<!–
| Gemiddelde prestatie op vier uitdagende evaluatiesuites | |
| Palm | 49.1% |
| U-PaLM | 50.2% |
| Vlaai-PaLM | 58.4% |
| Flan-U-PaLM | 59.1% |
| Het combineren van UL2R en Flan (Flan-U-PaLM) leidt tot de beste prestaties in vergelijking met alleen het gebruik van UL2R (U-PaLM) of alleen Flan (Flan-U-PaLM). Prestaties zijn het genormaliseerde gemiddelde over vier evaluatiesuites (MMLU, BBH, TyDiQA en MGSM). |
->
Over het algemeen zijn UL2R en Flan twee complementaire methoden om vooraf getrainde taalmodellen te verbeteren. UL2R past de LM aan een mix van denoisers-doelstelling aan met behulp van dezelfde gegevens, terwijl Flan trainingsgegevens van meer dan 1.8K NLP-taken gebruikt om het model instructies te leren volgen. Naarmate LM's nog groter worden, kunnen technieken zoals UL2R en Flan die de algemene prestaties verbeteren zonder grote hoeveelheden rekenkracht steeds aantrekkelijker worden.
Danksagung
Het was een voorrecht om aan deze twee artikelen samen te werken met Hyung Won Chung, Vinh Q. Tran, David R. So, Siamak Shakeri, Xavier Garcia, Huaixiu Steven Zheng, Jinfeng Rao, Aakanksha Chowdhery, Denny Zhou, Donald Metzler, Slav Petrov, Neil Houlsby, Quoc V. Le, Mostafa Dehghani, Le Hou, Shayne Longpre, Barret Zoph, Yi Tay, William Fedus, Yunxuan Li, Xuezhi Wang, Mostafa Dehghani, Siddhartha Brahma, Albert Webson, Shixiang Shane Gu, Zhuyun Dai, Mirac Suzgun , Xinyun Chen, Sharan Narang, Gaurav Mishra, Adams Yu, Vincent Zhao, Yanping Huang, Andrew Dai, Hongkun Yu, Ed H. Chi, Jeff Dean, Jacob Devlin en Adam Roberts.
#maildichter_form_1 .maildichter_form { }
#mailpoet_form_1 formulier { marge-onder: 0; }
#mailpoet_form_1 .mailpoet_column_with_background {padding: 0px; }
#mailpoet_form_1 .wp-block-column:eerste-kind, #mailpoet_form_1 .mailpoet_form_column:eerste-kind { opvulling: 0 20px; }
#mailpoet_form_1 .mailpoet_form_column:not(:first-child) { margin-left: 0; }
#mailpoet_form_1 h2.mailpoet-heading { marge: 0 0 12px 0; }
#mailpoet_form_1 .mailpoet_paragraph { regelhoogte: 20px; marge-onder: 20px; }
#mailpoet_form_1 .mailpoet_segment_label, #mailpoet_form_1 .mailpoet_text_label, #mailpoet_form_1 .mailpoet_textarea_label, #mailpoet_form_1 .mailpoet_select_label, #mailpoet_form_1 .mailpoet_radio_label, #mailpoet_form_1 .mailpoet_checkbox_label, #mailpoet_form_1 .mailpoet_list_label, #mailpoet_form_1 .mailpoet_date_label { display: block; lettergewicht: normaal; }
#mailpoet_form_1 .mailpoet_text, #mailpoet_form_1 .mailpoet_textarea, #mailpoet_form_1 .mailpoet_select, #mailpoet_form_1 .mailpoet_date_month, #mailpoet_form_1 .mailpoet_date_day, #mailpoet_form_1 .mailpoet_date_year, #mailpoet_form_1 .mailpoet_date { weergeven: blokkeren; }
#mailpoet_form_1 .mailpoet_text, #mailpoet_form_1 .mailpoet_textarea { breedte: 200px; }
#mailpoet_form_1 .mailpoet_checkbox { }
#mailpoet_form_1 .mailpoet_submit { }
#mailpoet_form_1 .mailpoet_divider { }
#mailpoet_form_1 .mailpoet_message { }
#mailpoet_form_1 .mailpoet_form_loading { breedte: 30px; tekst uitlijnen: centreren; regelhoogte: normaal; }
#mailpoet_form_1 .mailpoet_form_loading > span { breedte: 5px; hoogte: 5px; achtergrondkleur: #5b5b5b; }#mailpoet_form_1{border-radius: 3px;background: #27282e;color: #ffffff;text-align: left;}#mailpoet_form_1 form.mailpoet_form {padding: 0px;}#mailpoet_form_1{width: 100%;}#mailpoet_form_1 . mailpoet_message {marge: 0; opvulling: 0 20px;}
#mailpoet_form_1 .mailpoet_validate_success {kleur: #00d084}
#mailpoet_form_1 input.peterselie-succes {kleur: #00d084}
#mailpoet_form_1 select.peterselie-succes {kleur: #00d084}
#mailpoet_form_1 textarea.peterselie-succes {kleur: #00d084}
#mailpoet_form_1 .mailpoet_validate_error {kleur: #cf2e2e}
#mailpoet_form_1 input.peterselie-fout {kleur: #cf2e2e}
#mailpoet_form_1 select.peterselie-fout {kleur: #cf2e2e}
#mailpoet_form_1 textarea.textarea.parsley-error {kleur: #cf2e2e}
#mailpoet_form_1 .peterselie-foutenlijst {kleur: #cf2e2e}
#mailpoet_form_1 .peterselie vereist {kleur: #cf2e2e}
#mailpoet_form_1 .peterselie-aangepaste-foutmelding {kleur: #cf2e2e}
#mailpoet_form_1 .mailpoet_paragraph.last {margin-bottom: 0} @media (max-width: 500px) {#mailpoet_form_1 {background: #27282e;}} @media (min-width: 500px) {#mailpoet_form_1 .last .mailpoet_paragraph: laatste-kind {margin-bottom: 0}} @media (max-breedte: 500px) {#mailpoet_form_1 .mailpoet_form_column:last-child .mailpoet_paragraph:last-child {margin-bottom: 0}}
Betere taalmodellen zonder massale rekenkracht Heruitgegeven vanaf bron http://ai.googleblog.com/2022/11/better-language-models-without-massive.html via http://feeds.feedburner.com/blogspot/gJZg
crowdsourcing-week
<!–
->
<!–
->
- Coinsmart. Europa's beste Bitcoin- en crypto-uitwisseling.Klik Hier
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://blockchainconsultants.io/better-language-models-without-massive-compute/?utm_source=rss&utm_medium=rss&utm_campaign=better-language-models-without-massive-compute

