Afbeelding door auteur
De onevenwichtige dataset is een probleem in de datawetenschap. Het probleem doet zich voor omdat onbalans vaak leidt tot prestatieproblemen bij het modelleren. Om het onbalansprobleem te verminderen, kunnen we de oversampling-methode gebruiken. Oversampling is het herbemonsteren van minderheidsgegevens om de gegevens in evenwicht te brengen.
Er zijn veel manieren om te oversamplen, en een daarvan is door SMOTE1 te gebruiken. Laten we veel SMOTE-implementaties verkennen om meer te weten te komen over oversampling-technieken.
Voordat we verder gaan, zullen we de churn-dataset van Kaggle2 gebruiken om de onevenwichtige dataset weer te geven. Het doel van de dataset is de 'verlaten' variabele en we zouden zien hoe de SMOTE de gegevens zou overbemonsteren op basis van het minderheidsdoel.
import pandas as pd df = pd.read_csv('churn.csv')
df['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])
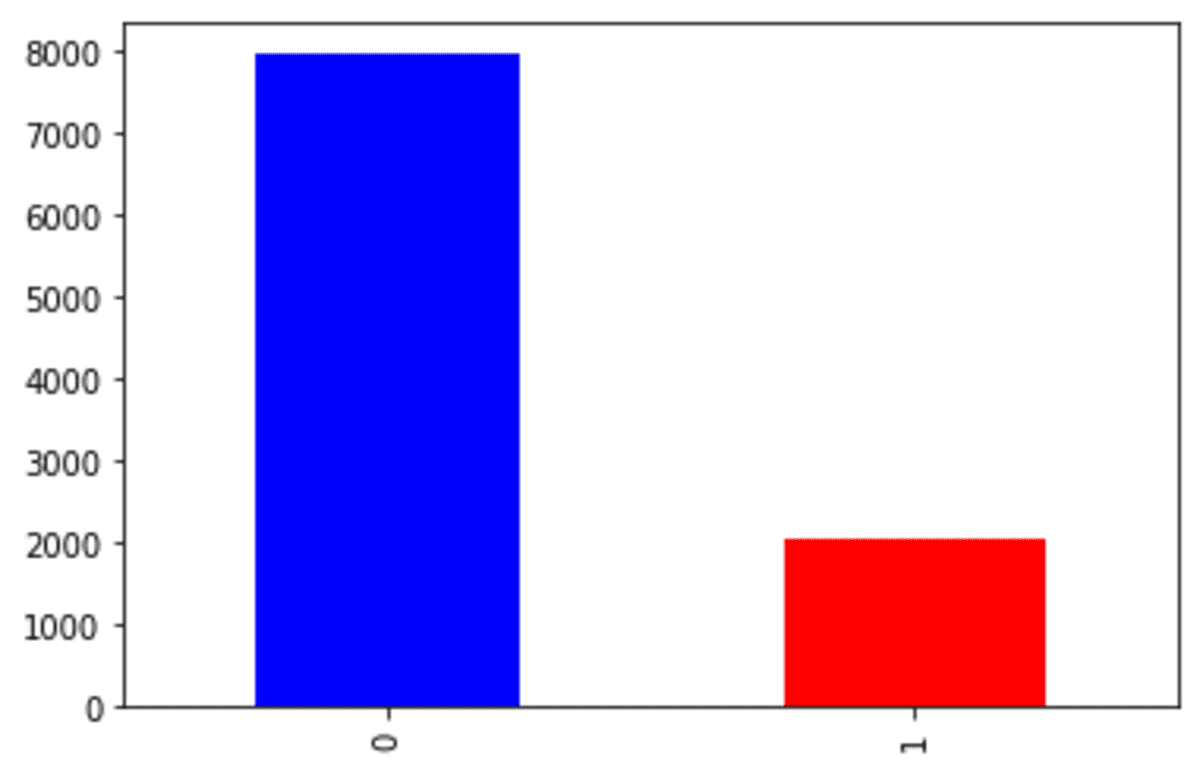
We kunnen zien dat onze churn-dataset wordt geconfronteerd met een onbalansprobleem. Laten we de SMOTE proberen om de gegevens te overbemonsteren.
1. SMOET
SMOTE wordt vaak gebruikt om continue gegevens voor ML-problemen te overbemonsteren door kunstmatige of synthetische gegevens te ontwikkelen. We gebruiken continue gegevens omdat het model voor het ontwikkelen van de steekproef alleen continue gegevens accepteert1.
Voor ons voorbeeld zouden we twee continue variabelen uit het voorbeeld van de dataset gebruiken; 'Geschat Salaris' en 'Leeftijd'. Laten we eens kijken hoe beide variabelen zich verspreiden in vergelijking met het gegevensdoel.
import seaborn as sns
sns.scatterplot(data =df, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
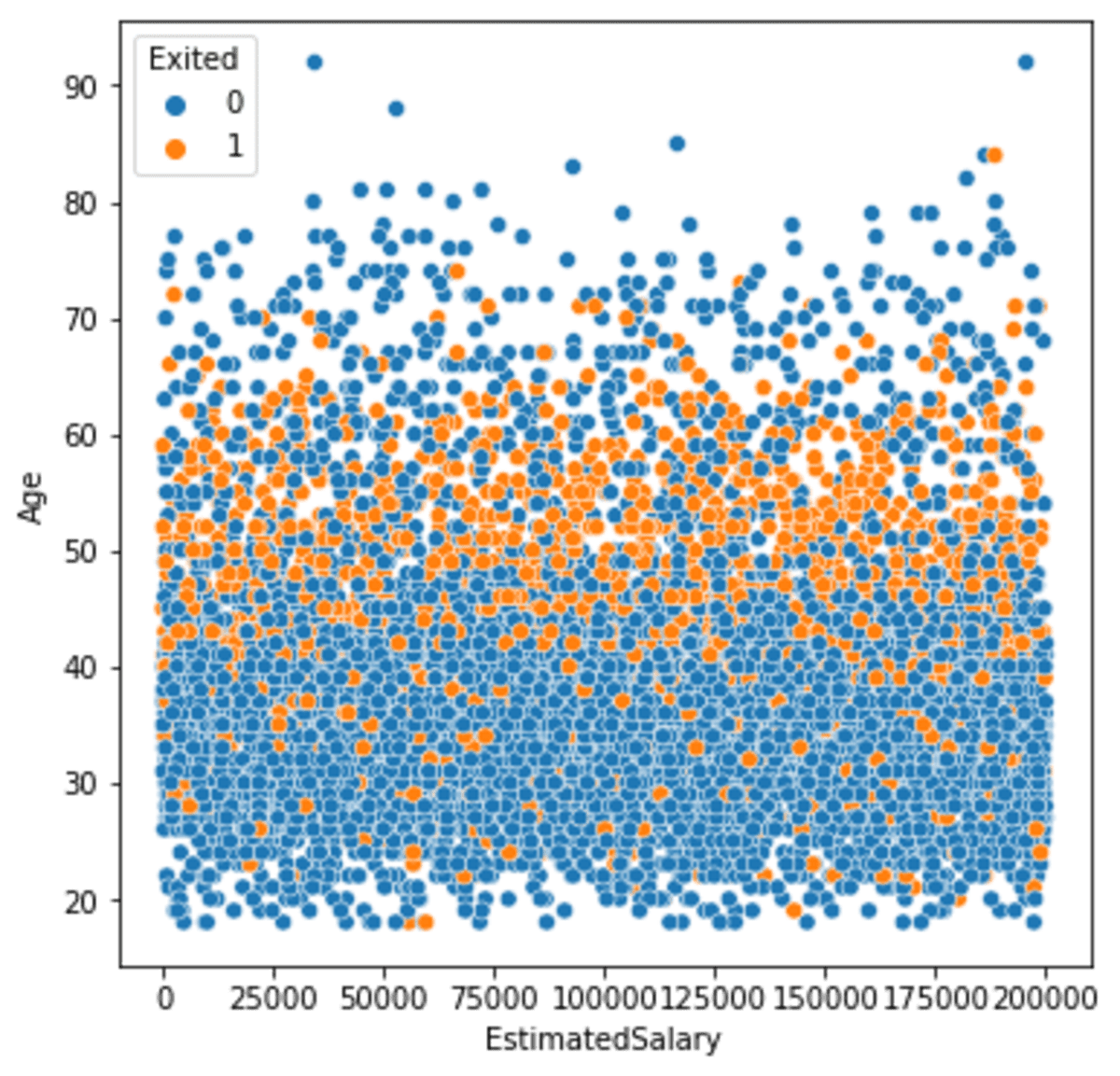
We zien de minderheidsklasse meestal verspreid over het middelste deel van het perceel. Laten we proberen de gegevens te overbemonsteren met SMOTE en kijken hoe de verschillen zijn gemaakt. Om de SMOTE-oversampling te vergemakkelijken, zouden we het imblearn Python-pakket gebruiken.
pip install imblearn
Met imblearn zouden we onze churn-gegevens overbemonsteren.
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state = 42) X, y = smote.fit_resample(df[['EstimatedSalary', 'Age']], df['Exited'])
df_smote = pd.DataFrame(X, columns = ['EstimatedSalary', 'Age'])
df_smote['Exited'] = y
Imblearn-pakket is gebaseerd op de scikit-learn API, die gemakkelijk te gebruiken was. In het bovenstaande voorbeeld hebben we de dataset overbemonsterd met SMOTE. Laten we eens kijken naar de variabelenverdeling 'Verlaten'.
df_smote['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])

Zoals we kunnen zien in de bovenstaande uitvoer, heeft de doelvariabele nu vergelijkbare verhoudingen. Laten we eens kijken hoe de continue variabele zich verspreidde met de nieuwe SMOTE overbemonsterde gegevens.
import matplotlib.pyplot as plt sns.scatterplot(data = df_smote, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('SMOTE')
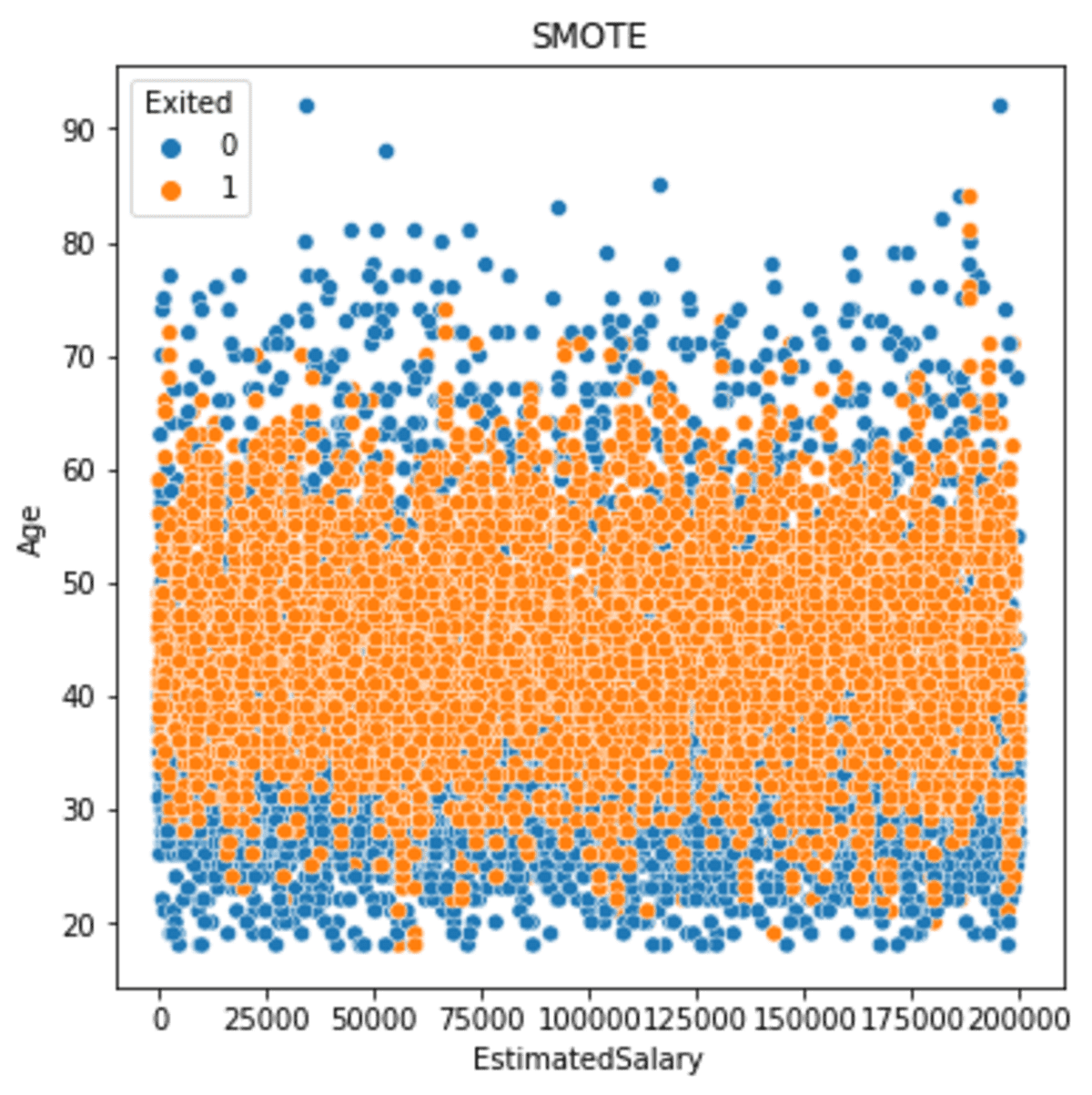
De bovenstaande afbeelding laat zien dat de minderheidsgegevens nu meer verspreid zijn dan voordat we de gegevens oversampelden. Als we de uitvoer in meer detail bekijken, kunnen we zien dat de spreiding van minderheidsgegevens nog steeds dicht bij de kern ligt en zich breder heeft verspreid dan voorheen. Dit gebeurt omdat de steekproef was gebaseerd op het buurmodel, dat de steekproef schatte op basis van de naaste buur.
2. SMOTE-NC
SMOTE-NC is SMOTE voor de categorische gegevens. Zoals ik hierboven al zei, werkt SMOTE alleen voor continue gegevens.
Waarom coderen we de categorische variabele niet gewoon in de continue variabele?
Het probleem is dat de SMOTE een steekproef maakt op basis van de naaste buur. Als u de categorische gegevens codeert, bijvoorbeeld de variabele 'HasCrCard', die de klassen 0 en 1 bevat, kan het voorbeeldresultaat 0.8 of 0.34 zijn, enzovoort.
Vanuit het oogpunt van data is het niet logisch. Daarom zouden we SMOTE-NC kunnen gebruiken om ervoor te zorgen dat de categorische oversampling van gegevens zinvol zou zijn.
Laten we het proberen met voorbeeldgegevens. Voor deze specifieke steekproef zouden we de variabelen 'HasCrCard' en 'Leeftijd' gebruiken. Eerst wil ik de initiële 'HasCrCard' variabele spread laten zien.
pd.crosstab(df['HasCrCard'], df['Exited'])
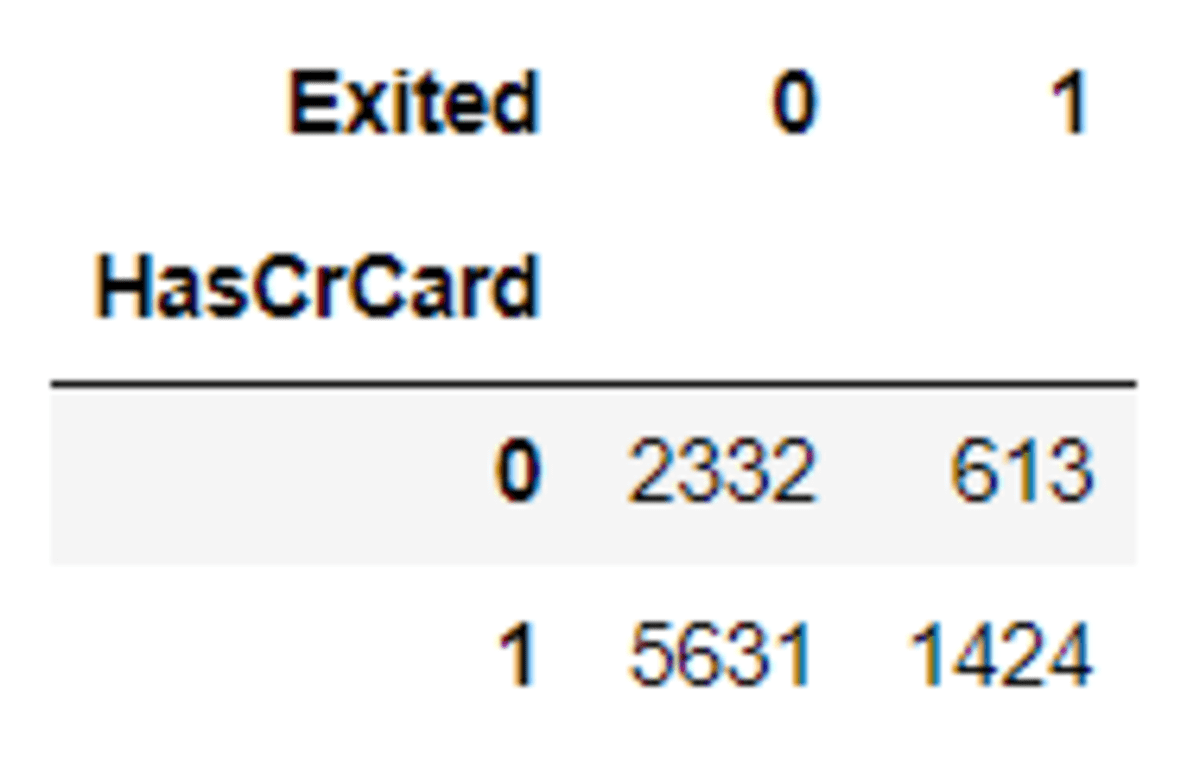
Laten we dan eens kijken wat de verschillen zijn na het oversamplingproces met SMOTE-NC.
from imblearn.over_sampling import SMOTENC smotenc = SMOTENC([1],random_state = 42)
X_os_nc, y_os_nc = smotenc.fit_resample(df[['Age', 'HasCrCard']], df['Exited'])
Merk op dat in de bovenstaande code de categorische variabelepositie is gebaseerd op de variabelepositie in het DataFrame.
Laten we eens kijken hoe de 'HasCrCard' zich verspreidde na de oversampling.
pd.crosstab(X_os_nc['HasCrCard'], y_os_nc)
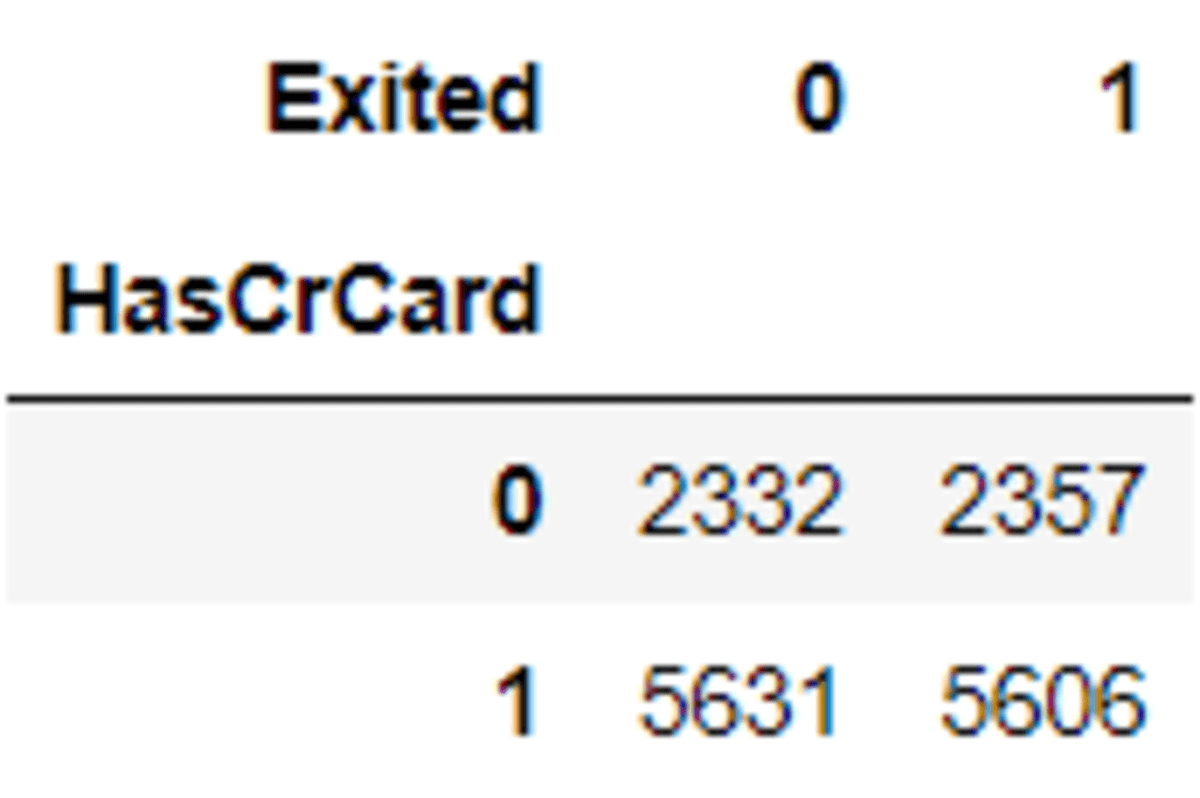
Zie dat de data-oversampling bijna dezelfde verhoudingen hebben. Je zou kunnen proberen met een andere categorische variabele om te zien hoe SMOTE-NC werkt.
3. Borderline-SMOTE
Borderline-SMOTE is een SMOTE die is gebaseerd op de classificatie borderline. Borderline-SMOTE zou de gegevens overbemonsteren die dicht bij de grens van de classificatie lagen. Dit komt omdat hoe dichter de steekproef bij de grens ligt, de kans op misclassificatie en dus belangrijker op oversampling naar verwachting groter zal zijn.3
Er zijn twee soorten Borderline-SMOTE; Borderline-SMOTE1 en Borderline-SMOTE2. De verschillen zijn Borderline-SMOTE1 zou beide klassen overbemonsteren die dicht bij de borderline liggen. Ter vergelijking: Borderline-SMOTE2 zou de minderheidsklasse alleen maar overbemonsteren.
Laten we de Borderline-SMOTE eens proberen met een voorbeeld van een dataset.
from imblearn.over_sampling import BorderlineSMOTE
bsmote = BorderlineSMOTE(random_state = 42, kind = 'borderline-1')
X_bd, y_bd = bsmote.fit_resample(df[['EstimatedSalary', 'Age']], df['Exited'])
df_bd = pd.DataFrame(X_bd, columns = ['EstimatedSalary', 'Age'])
df_bd['Exited'] = y_bd
Laten we eens kijken hoe de verspreiding verloopt nadat we de Borderline-SMOTE hebben gestart.
sns.scatterplot(data = df_bd, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('Borderline-SMOTE')
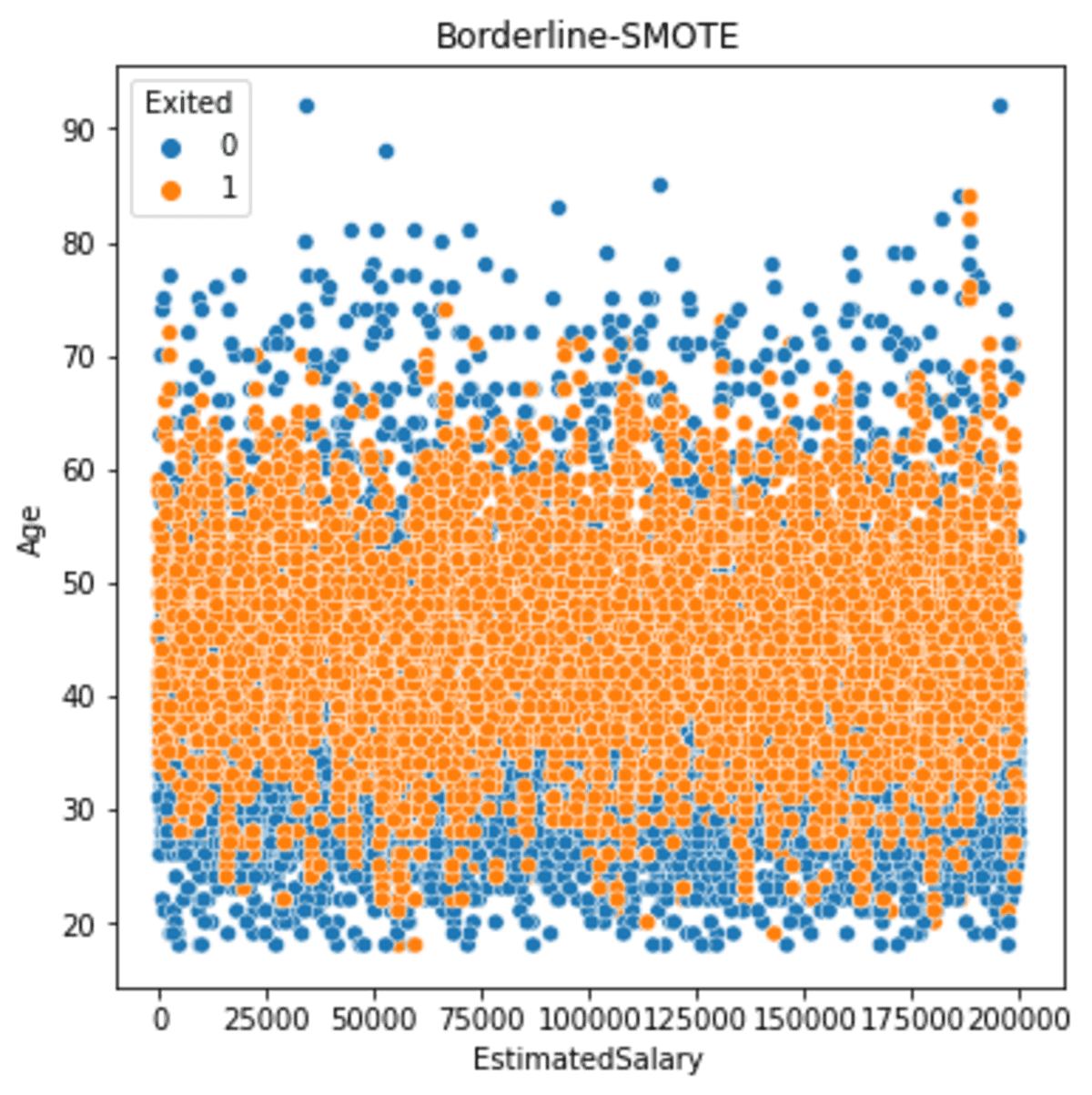
Als we het bovenstaande resultaat zien, is de uitvoer vergelijkbaar met de SMOTE-uitvoer, maar Borderline-SMOTE-oversampling resulteert iets dichter bij de grens.
4. SMOTE-Tomek
SMOTE-Tomek gebruikt een combinatie van zowel SMOTE als de undersampling Tomek-link. Tomek-link is een manier om gegevens op te schonen om de meerderheidsklasse te verwijderen die overlapt met de minderheidsklasse4.
Laten we SMOTE-TOMEK proberen met de voorbeeldgegevensset.
from imblearn.combine import SMOTETomek s_tomek = SMOTETomek(random_state = 42)
X_st, y_st = s_tomek.fit_resample(df[['EstimatedSalary', 'Age']], df['Exited'])
df_st = pd.DataFrame(X_st, columns = ['EstimatedSalary', 'Age'])
df_st['Exited'] = y_st
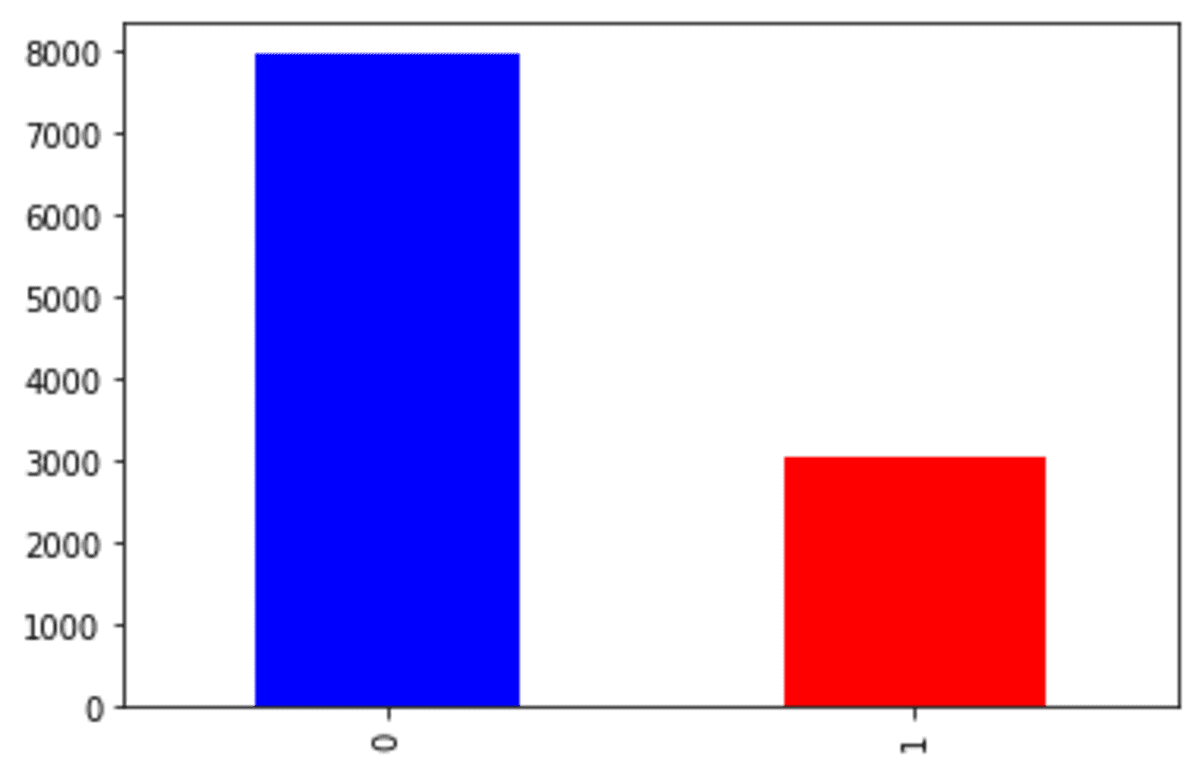
Laten we eens kijken naar het resultaat van de doelvariabele nadat we SMOTE-Tomek hebben gebruikt.
df_st['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])

Het 'Verlaten' klasse 0-nummer is nu rond de 6000 vergeleken met de originele dataset, die bijna 8000 is. Dit gebeurt omdat SMOTE-Tomek de klasse 0 onderbemonsterde terwijl de minderheidsklasse werd overbemonsterd.
Laten we eens kijken hoe de gegevens zich verspreiden nadat we de gegevens hebben oversampled met SMOTE-Tomek.
sns.scatterplot(data = df_st, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('SMOTE-Tomek')
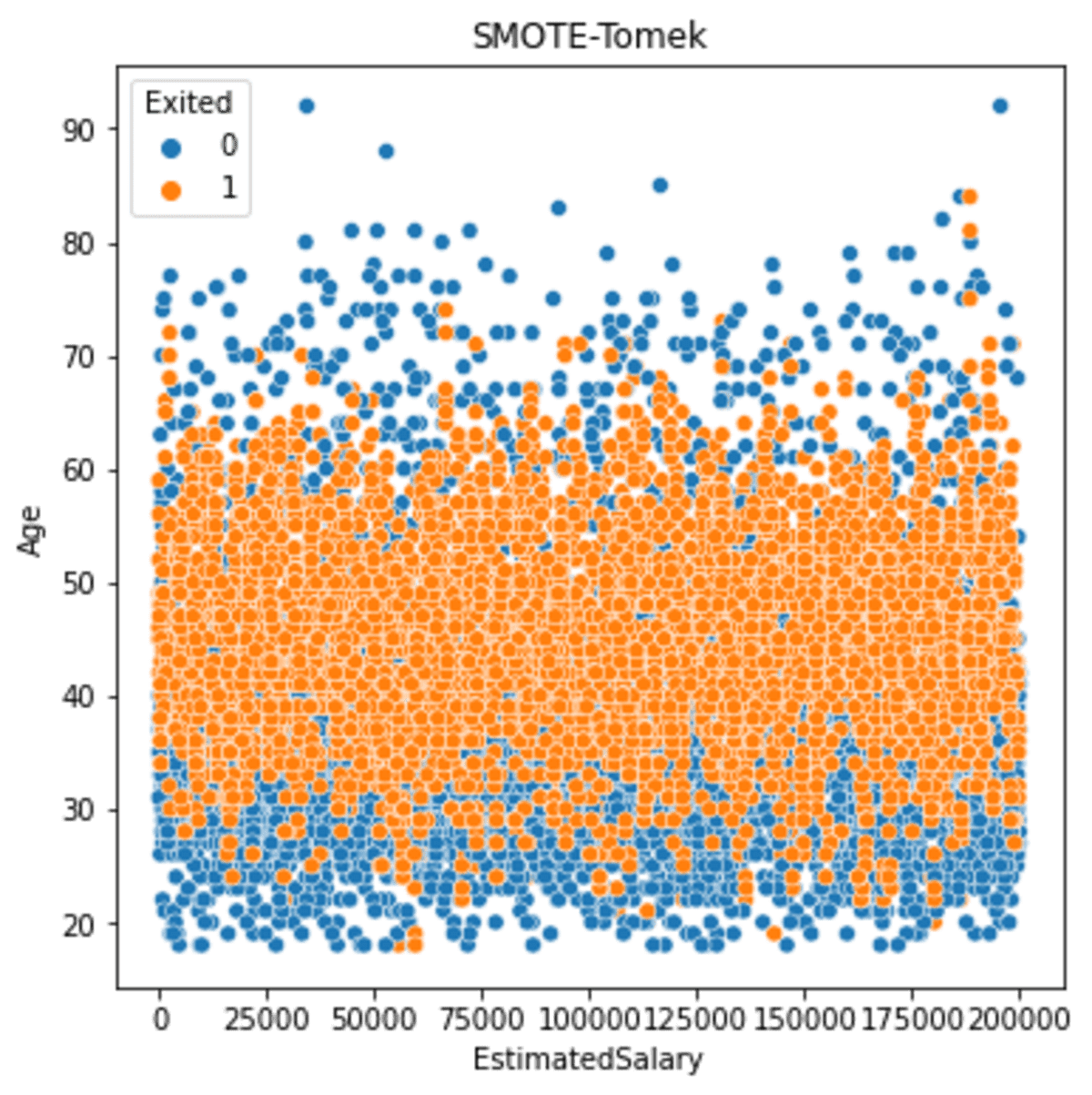
De resulterende spread is nog steeds vergelijkbaar met voorheen. Maar als we meer details zien, wordt er minder minderheidsoversampling geproduceerd naarmate de gegevens verder zijn.
5. SMOTE-ENN
Net als bij de SMOTE-Tomek combineert SMOTE-ENN (Edited Nearest Neighbour) oversampling en undersampling. De SMOTE deed de oversampling, terwijl de ENN de undersampling deed.
De bewerkte dichtstbijzijnde buur is een manier om steekproeven van meerderheidsklassen te verwijderen in zowel de oorspronkelijke datasets als de datasets van de steekproefresultaten waar de steekproeven van de dichtstbijzijnde minderheidsklasse5 deze verkeerd classificeren. Het zal de meerderheidsklasse dicht bij de grens verwijderen waar deze verkeerd was geclassificeerd.
Laten we de SMOTE-ENN eens proberen met een voorbeeld van een dataset.
from imblearn.combine import SMOTEENN s_enn = SMOTEENN(random_state=42)
X_se, y_se = s_enn.fit_resample(df[['EstimatedSalary', 'Age']], df['Exited'])
df_se = pd.DataFrame(X_se, columns = ['EstimatedSalary', 'Age'])
df_se['Exited'] = y_se
Laten we het SMOTE-ENN-resultaat bekijken. Eerst kijken we naar de doelvariabele.
df_se['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])
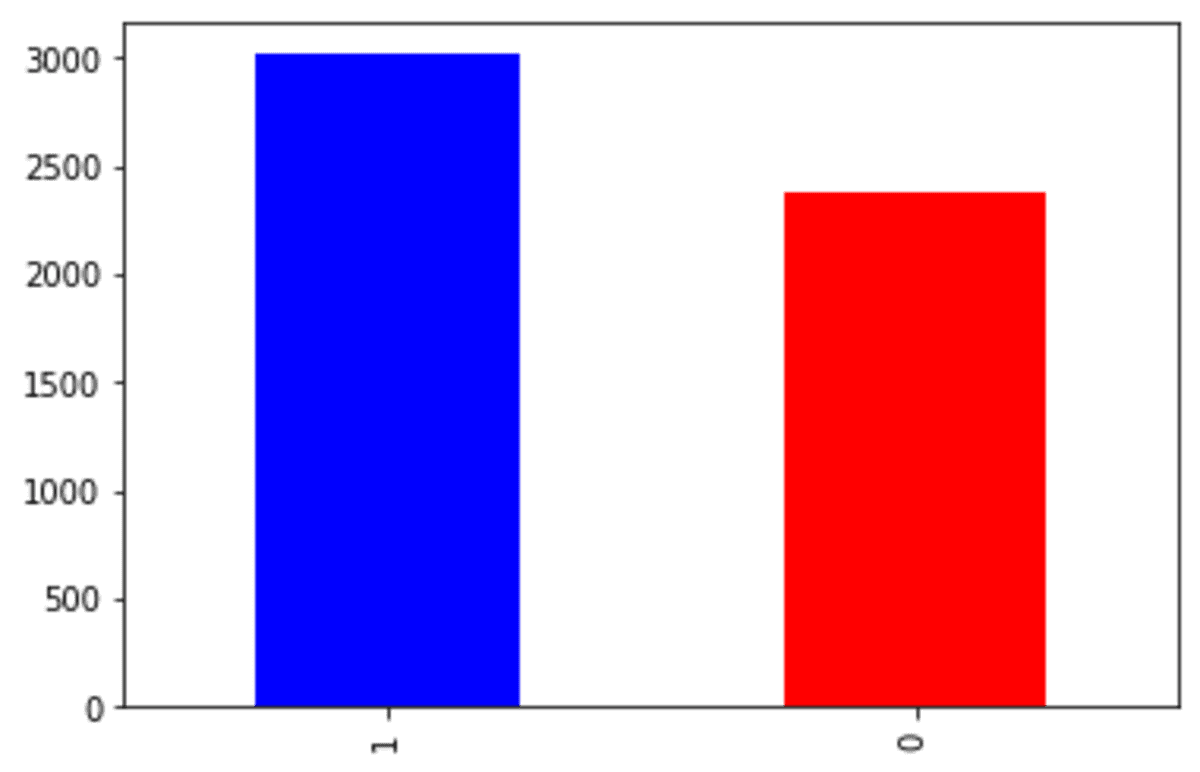
Het onderbemonsteringsproces van de SMOTE-ENN is veel strikter in vergelijking met de SMOTE-Tomek. Uit het bovenstaande resultaat bleek dat meer dan de helft van de oorspronkelijke 'Verlaten' klasse 0 onderbemonsterd was, en slechts een lichte toename van de minderheidsklasse.
Laten we eens kijken naar de gegevensspreiding nadat de SMOTE-ENN is toegepast.
sns.scatterplot(data = df_se, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('SMOTE-ENN')
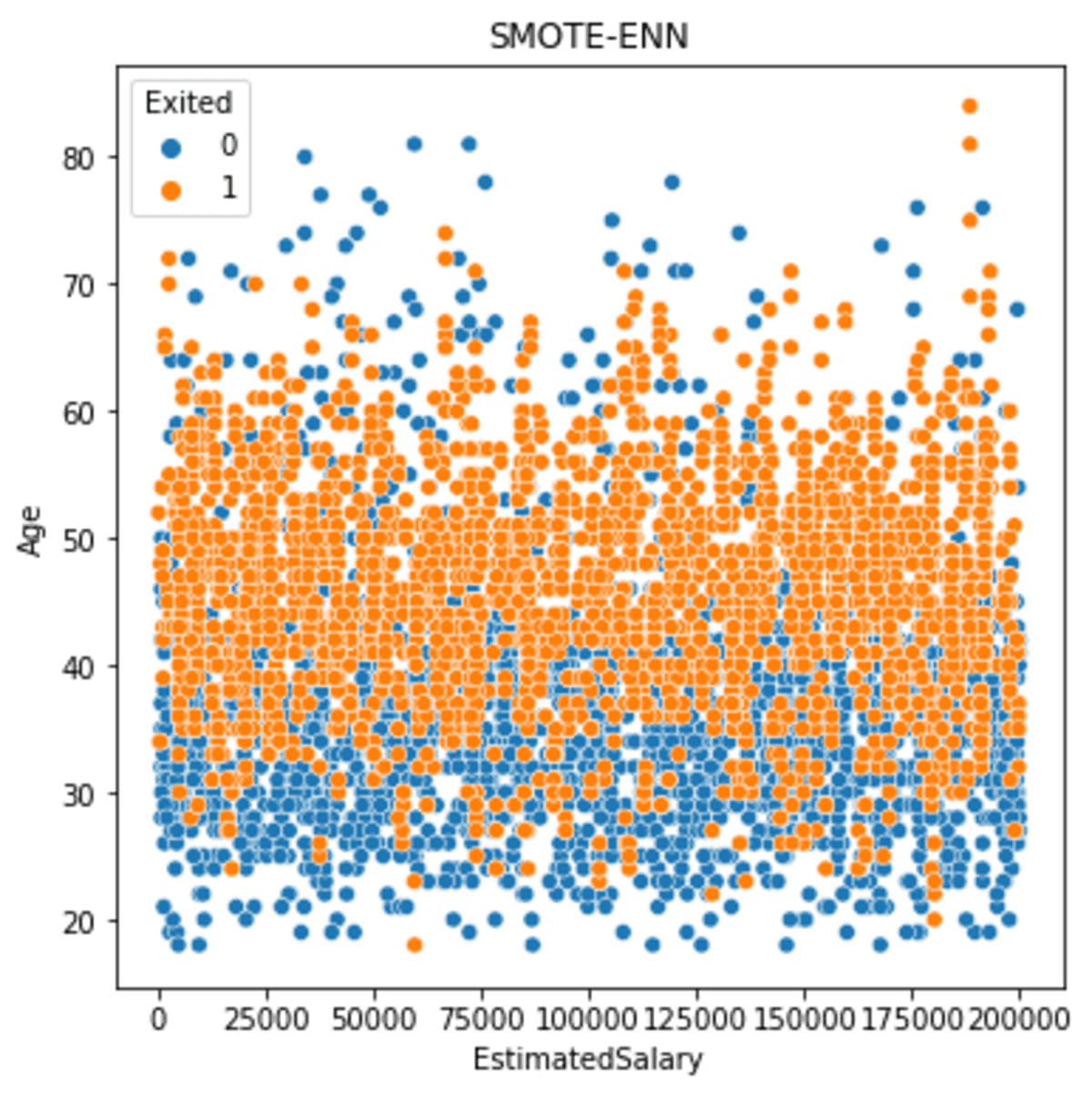
De dataspreiding tussen de klassen is veel groter dan voorheen. We moeten echter onthouden dat de resultaatgegevens kleiner zijn.
6. SMOTE-CUT
SMOTE-CUT of SMOTE-Clustered Undersampling Technique combineert oversampling, clustering en undersampling.
SMOTE-CUT implementeert oversampling met SMOTE, waarbij zowel het origineel als het resultaat worden geclusterd en de klassenmeerderheidssamples uit clusters worden verwijderd.
SMOTE-CUT-clustering is gebaseerd op het EM-algoritme of Expectation Maximization-algoritme, dat aan elke gegevens een waarschijnlijkheid toekent om tot clusters te behoren. Het resultaat van de clustering zou het algoritme leiden tot oversampling of undersampling, zodat de datasetdistributie in evenwicht komt6.
Laten we proberen een voorbeeld van een dataset te gebruiken. Voor dit voorbeeld zouden we het crucio Python-pakket gebruiken.
pip install crucio
Met het crucio-pakket oversampelen we de dataset met behulp van de volgende code.
from crucio import SCUT
df_sample = df[['EstimatedSalary', 'Age', 'Exited']].copy() scut = SCUT()
df_scut= scut.balance(df_sample, 'Exited')
Laten we eens kijken naar de doelgegevensverdeling.
df_scut['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])

De klasse 'Exited' is gelijk, hoewel het ondersamplingproces vrij streng is. Veel van de 'Exited' klasse 0 zijn verwijderd vanwege de onderbemonstering.
Laten we eens kijken hoe de gegevens zich verspreidden nadat SMOTE-CUT was geïmplementeerd.
sns.scatterplot(data = df_scut, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('SMOTE-CUT')
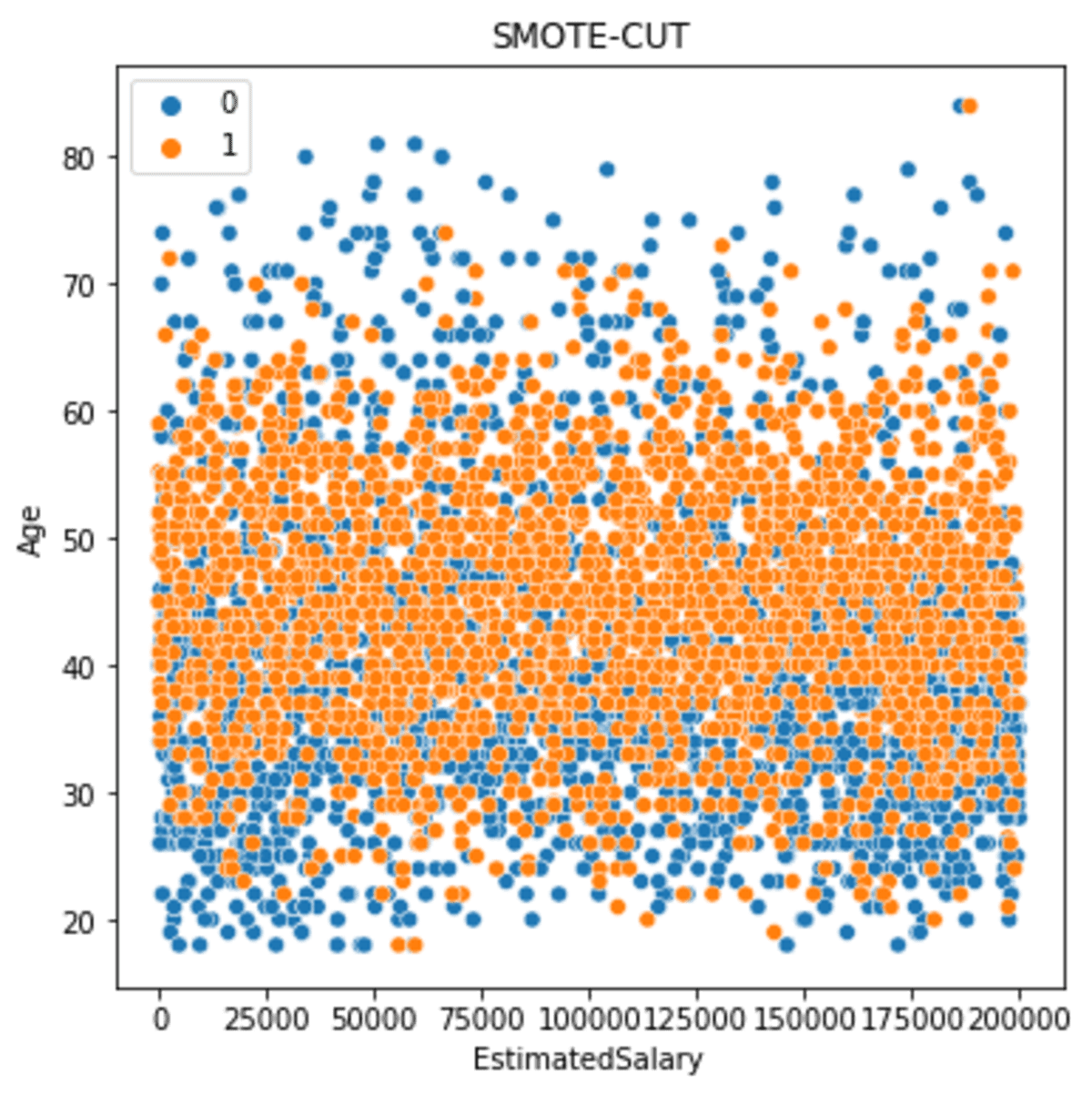
De dataspreiding is meer verspreid maar minder dan de SMOTE-ENN.
7. ADASYN
ADASYN of Adaptive Synthetic Sampling is een SMOTE die probeert de minderheidsgegevens te overbemonsteren op basis van de gegevensdichtheid. ADASYN kent een gewogen verdeling toe aan elk van de minderheidssteekproeven en geeft voorrang aan oversampling aan de minderheidssteekproeven die moeilijker te leren zijn7.
Laten we ADASYN eens proberen met de voorbeelddataset.
from crucio import ADASYN
df_sample = df[['EstimatedSalary', 'Age', 'Exited']].copy() ada = ADASYN()
df_ada= ada.balance(df_sample, 'Exited')
Laten we het doelverdelingsresultaat bekijken.
df_ada['Exited'].value_counts().plot(kind = 'bar', color = ['blue', 'red'])
Omdat de ADASYN zich zou concentreren op de gegevens die moeilijker te leren of minder compact zijn, was het oversamplingresultaat minder dan het andere.
Laten we eens kijken hoe de dataspreiding was.
sns.scatterplot(data = df_ada, x ='EstimatedSalary', y = 'Age', hue = 'Exited')
plt.title('ADASYN')
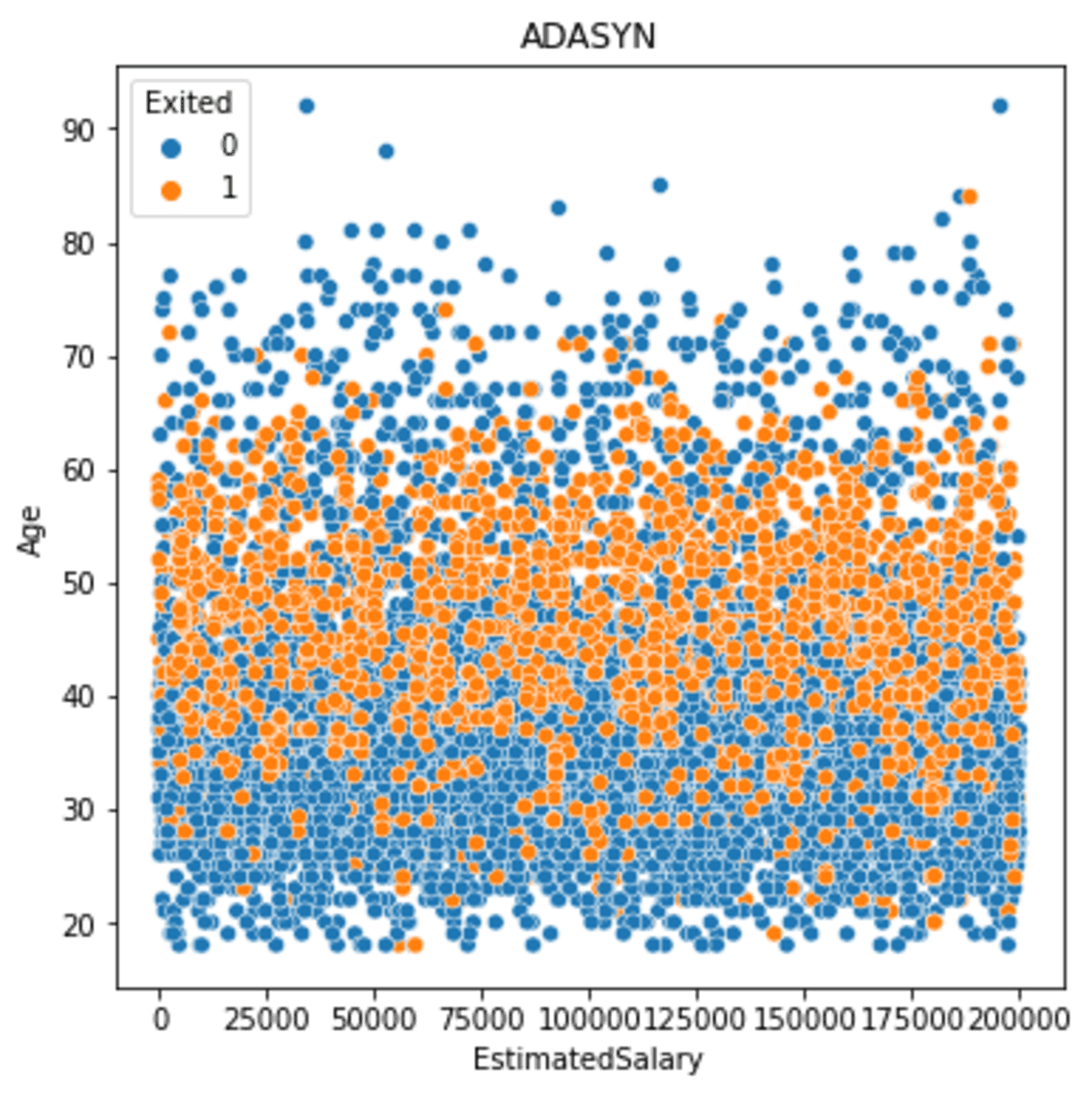
Zoals we op de afbeelding hierboven kunnen zien, ligt de spreiding dichter bij de kern, maar dichter bij de minderheidsgegevens met een lage dichtheid.
Data-onbalans is een probleem in het dataveld. Een manier om het onbalansprobleem te verminderen, is door de dataset te overbemonsteren met SMOTE. Met onderzoeksontwikkeling zijn er veel SMOTE-methoden gecreëerd die we kunnen gebruiken.
In dit artikel nemen we 7 verschillende SMOTE-technieken door, waaronder
- VLOT
- SMOTE-NC
- Borderline-SMOTE
- SMOTE-TOMEK
- SMOTE-ENN
- SMOTE-CUT
- ADASYN
Referenties
- SMOTE: Techniek voor overbemonstering door synthetische minderheden - Arxiv.org
- Churn-modellering dataset van Kaggle-licenties onder CC0: Public Domain.
- Borderline-SMOTE: een nieuwe overbemonsteringsmethode bij het leren van ongebalanceerde datasets - Semanticscholar.org
- Evenwichtige trainingsgegevens voor geautomatiseerde annotatie van trefwoorden: een casestudy - inf.ufrgs.br
- Verbetering van de risico-identificatie van nadelige gevolgen bij chronisch hartfalen met behulp van SMOTE+ENN en machine learning – dovepress. com
- Crucio SMOTE en Clustered Undersampling Technique gebruiken voor ongebalanceerde datasets - sigmoid.ai
- ADASYN: adaptieve synthetische bemonsteringsbenadering voor onevenwichtig leren – Researchgate
Cornellius Yudha Wijaya is een data science assistent-manager en dataschrijver. Terwijl hij fulltime bij Allianz Indonesia werkt, deelt hij graag Python- en Data-tips via sociale media en schrijvende media.
- Door SEO aangedreven content en PR-distributie. Word vandaag nog versterkt.
- Platoblockchain. Web3 Metaverse Intelligentie. Kennis versterkt. Toegang hier.
- Bron: https://www.kdnuggets.com/2023/01/7-smote-variations-oversampling.html?utm_source=rss&utm_medium=rss&utm_campaign=7-smote-variations-for-oversampling

