
ഉപയോഗിച്ച് സൃഷ്ടിച്ച ചിത്രം Ideogram.ai
അതിനാൽ, ഈ വെക്റ്റർ ഡാറ്റാബേസ് നിബന്ധനകളെല്ലാം നിങ്ങൾ കേട്ടേക്കാം. ചിലർ അതിനെക്കുറിച്ച് മനസ്സിലാക്കിയേക്കാം, ചിലർക്ക് മനസ്സിലാകില്ല. വെക്റ്റർ ഡാറ്റാബേസുകൾ സമീപ വർഷങ്ങളിൽ കൂടുതൽ പ്രധാന വിഷയമായി മാറിയതിനാൽ അവയെ കുറിച്ച് നിങ്ങൾക്ക് അറിയില്ലെങ്കിൽ വിഷമിക്കേണ്ടതില്ല.
ജനറേറ്റീവ് AI പൊതുജനങ്ങൾക്ക്, പ്രത്യേകിച്ച് LLM-ൻ്റെ പരിചയപ്പെടുത്തലിന് നന്ദി പറഞ്ഞ് വെക്റ്റർ ഡാറ്റാബേസുകൾക്ക് ജനപ്രീതി വർദ്ധിച്ചു.
GPT-4, Gemini തുടങ്ങിയ നിരവധി LLM ഉൽപ്പന്നങ്ങൾ, ഞങ്ങളുടെ ഇൻപുട്ടിന് ടെക്സ്റ്റ് ജനറേഷൻ കഴിവ് നൽകിക്കൊണ്ട് ഞങ്ങളുടെ പ്രവർത്തനത്തെ സഹായിക്കുന്നു. ശരി, വെക്റ്റർ ഡാറ്റാബേസുകൾ യഥാർത്ഥത്തിൽ ഈ LLM ഉൽപ്പന്നങ്ങളിൽ ഒരു പങ്ക് വഹിക്കുന്നു.
എന്നാൽ വെക്റ്റർ ഡാറ്റാബേസ് എങ്ങനെ പ്രവർത്തിച്ചു? LLM-ൽ അവരുടെ പ്രസക്തി എന്താണ്?
ഈ ലേഖനത്തിൽ നമ്മൾ എന്ത് ഉത്തരം നൽകും എന്നതാണ് മുകളിലുള്ള ചോദ്യം. ശരി, നമുക്ക് അവ ഒരുമിച്ച് പര്യവേക്ഷണം ചെയ്യാം.
വെക്റ്റർ ഡാറ്റ സംഭരിക്കാനും സൂചികയാക്കാനും അന്വേഷിക്കാനും രൂപകൽപ്പന ചെയ്ത ഒരു പ്രത്യേക ഡാറ്റാബേസ് സംഭരണമാണ് വെക്റ്റർ ഡാറ്റാബേസ്. സാധാരണയായി ഇത് മെഷീൻ ലേണിംഗ് മോഡലിൻ്റെ, പ്രത്യേകിച്ച് LLM-ൻ്റെ ഔട്ട്പുട്ടായതിനാൽ, ഹൈ-ഡൈമൻഷണൽ വെക്റ്റർ ഡാറ്റയ്ക്കായി ഇത് ഒപ്റ്റിമൈസ് ചെയ്യപ്പെടുന്നു.
ഒരു വെക്റ്റർ ഡാറ്റാബേസിൻ്റെ സന്ദർഭത്തിൽ, വെക്റ്റർ ഡാറ്റയുടെ ഗണിതശാസ്ത്രപരമായ പ്രതിനിധാനമാണ്. ഓരോ വെക്ടറിലും ഡാറ്റ സ്ഥാനത്തെ പ്രതിനിധീകരിക്കുന്ന സംഖ്യാ പോയിൻ്റുകളുടെ ഒരു നിര അടങ്ങിയിരിക്കുന്നു. ടെക്സ്റ്റ് ഡാറ്റയേക്കാൾ വെക്റ്റർ പ്രോസസ്സ് ചെയ്യുന്നത് എളുപ്പമുള്ളതിനാൽ ടെക്സ്റ്റ് ഡാറ്റയെ പ്രതിനിധീകരിക്കാൻ LLM-ൽ വെക്റ്റർ ഉപയോഗിക്കാറുണ്ട്.
LLM സ്പെയ്സിൽ, മോഡലിന് ഒരു ടെക്സ്റ്റ് ഇൻപുട്ട് ഉണ്ടായിരിക്കാം, കൂടാതെ ടെക്സ്റ്റിൻ്റെ സെമാൻ്റിക്, വാക്യഘടന സവിശേഷതകളെ പ്രതിനിധീകരിക്കുന്ന ഒരു ഹൈ-ഡൈമൻഷണൽ വെക്ടറാക്കി മാറ്റാനും കഴിയും. ഈ പ്രക്രിയയെ നമ്മൾ എംബെഡിംഗ് എന്ന് വിളിക്കുന്നു. ലളിതമായി പറഞ്ഞാൽ, എംബെഡിംഗ് എന്നത് ടെക്സ്റ്റിനെ സംഖ്യാ ഡാറ്റയുള്ള വെക്റ്ററുകളാക്കി മാറ്റുന്ന ഒരു പ്രക്രിയയാണ്.
എംബഡിംഗ് സ്പെയ്സിലെ ടെക്സ്റ്റിനെ പ്രതിനിധീകരിക്കാൻ എംബഡിംഗ് മോഡൽ എന്ന ന്യൂറൽ നെറ്റ്വർക്ക് മോഡൽ എംബഡിംഗ് സാധാരണയായി ഉപയോഗിക്കുന്നു.
നമുക്ക് ഒരു ഉദാഹരണ വാചകം ഉപയോഗിക്കാം: "ഐ ലവ് ഡാറ്റാ സയൻസ്". ഓപ്പൺഎഐ മോഡൽ ടെക്സ്റ്റ്-എംബെഡിംഗ്-3-സ്മോൾ ഉപയോഗിച്ച് അവയെ പ്രതിനിധീകരിക്കുന്നത് 1536 അളവുകളുള്ള ഒരു വെക്റ്ററിന് കാരണമാകും.
[0.024739108979701996, -0.04105354845523834, 0.006121257785707712, -0.02210472710430622, 0.029098540544509888,...]
വെക്ടറിനുള്ളിലെ നമ്പർ മോഡലിൻ്റെ എംബെഡിംഗ് സ്പെയ്സിനുള്ളിലെ കോർഡിനേറ്റാണ്. അവർ ഒരുമിച്ച്, മാതൃകയിൽ നിന്ന് വരുന്ന വാക്യത്തിൻ്റെ അദ്വിതീയ പ്രാതിനിധ്യം സൃഷ്ടിക്കും.
ഈ എംബെഡിംഗ് മോഡൽ ഔട്ട്പുട്ടുകൾ സംഭരിക്കുന്നതിന് വെക്റ്റർ ഡാറ്റാബേസ് ഉത്തരവാദിയായിരിക്കും. ഉപയോക്താവിന് ആവശ്യമായ വെക്ടറിനെ അന്വേഷിക്കാനും സൂചികയാക്കാനും വീണ്ടെടുക്കാനും കഴിയും.
ഒരുപക്ഷേ അത് മതിയാകും ആമുഖം, നമുക്ക് കൂടുതൽ സാങ്കേതികമായ കൈകളിലേക്ക് കടക്കാം. ഒരു ഓപ്പൺ സോഴ്സ് വെക്റ്റർ ഡാറ്റാബേസ് ഉപയോഗിച്ച് വെക്റ്ററുകൾ സ്ഥാപിക്കാനും സംഭരിക്കാനും ഞങ്ങൾ ശ്രമിക്കും നെയ്തെടുക്കുക.
Weaviate എന്നത് ഞങ്ങളുടെ വെക്റ്റർ സംഭരിക്കുന്നതിനുള്ള ഒരു ചട്ടക്കൂടായി പ്രവർത്തിക്കുന്ന ഒരു ഓപ്പൺ സോഴ്സ് വെക്റ്റർ ഡാറ്റാബേസാണ്. ഡോക്കർ പോലുള്ള സന്ദർഭങ്ങളിൽ വീവിയേറ്റ് പ്രവർത്തിപ്പിക്കാം അല്ലെങ്കിൽ വീവിയേറ്റ് ക്ലൗഡ് സേവനങ്ങൾ (ഡബ്ല്യുസിഎസ്) ഉപയോഗിക്കാം.
Weaviate ഉപയോഗിക്കുന്നത് ആരംഭിക്കുന്നതിന്, ഇനിപ്പറയുന്ന കോഡ് ഉപയോഗിച്ച് ഞങ്ങൾ പാക്കേജുകൾ ഇൻസ്റ്റാൾ ചെയ്യേണ്ടതുണ്ട്:
pip install weaviate-client
കാര്യങ്ങൾ എളുപ്പമാക്കുന്നതിന്, ഞങ്ങളുടെ വെക്റ്റർ ഡാറ്റാബേസായി പ്രവർത്തിക്കാൻ ഞങ്ങൾ WCS-ൽ നിന്നുള്ള ഒരു സാൻഡ്ബോക്സ് ക്ലസ്റ്റർ ഉപയോഗിക്കും. ഒരു പേയ്മെൻ്റ് രീതിയും രജിസ്റ്റർ ചെയ്യാതെ തന്നെ ഞങ്ങളുടെ വെക്ടറുകൾ സംഭരിക്കാൻ ഉപയോഗിക്കാവുന്ന 14 ദിവസത്തെ സൗജന്യ ക്ലസ്റ്റർ വീവിയേറ്റ് നൽകുന്നു. അത് ചെയ്യുന്നതിന്, നിങ്ങൾ അവരിൽ രജിസ്റ്റർ ചെയ്യണം WCS കൺസോൾ തുടക്കത്തിൽ.
WCS പ്ലാറ്റ്ഫോമിൽ ഒരിക്കൽ, ഒരു ക്ലസ്റ്റർ സൃഷ്ടിക്കുക തിരഞ്ഞെടുത്ത് നിങ്ങളുടെ സാൻഡ്ബോക്സിൻ്റെ പേര് നൽകുക. UI ചുവടെയുള്ള ചിത്രം പോലെ ആയിരിക്കണം.
ചിത്രം രചയിതാവ്
WCS API കീ വഴി ഈ ക്ലസ്റ്റർ ആക്സസ് ചെയ്യാൻ ഞങ്ങൾ ആഗ്രഹിക്കുന്നതിനാൽ, പ്രാമാണീകരണം പ്രവർത്തനക്ഷമമാക്കാൻ മറക്കരുത്. ക്ലസ്റ്റർ തയ്യാറായ ശേഷം, API കീയും ക്ലസ്റ്റർ URL ഉം കണ്ടെത്തുക, അത് വെക്റ്റർ ഡാറ്റാബേസ് ആക്സസ് ചെയ്യാൻ ഞങ്ങൾ ഉപയോഗിക്കും.
കാര്യങ്ങൾ തയ്യാറായിക്കഴിഞ്ഞാൽ, വെക്റ്റർ ഡാറ്റാബേസിൽ ഞങ്ങളുടെ ആദ്യത്തെ വെക്റ്റർ സംഭരിക്കുന്നത് ഞങ്ങൾ അനുകരിക്കും.
വെക്റ്റർ ഡാറ്റാബേസ് സംഭരിക്കുന്നതിനുള്ള ഉദാഹരണത്തിനായി, ഞാൻ ഉപയോഗിക്കും പുസ്തക ശേഖരം Kaggle-ൽ നിന്നുള്ള ഉദാഹരണ ഡാറ്റാസെറ്റ്. ഞാൻ ഏറ്റവും മികച്ച 100 വരികളും 3 നിരകളും (ശീർഷകം, വിവരണം, ആമുഖം) മാത്രമേ ഉപയോഗിക്കൂ.
import pandas as pd
data = pd.read_csv('commonlit_texts.csv', nrows = 100, usecols=['title', 'description', 'intro'])
നമുക്ക് നമ്മുടെ ഡാറ്റ മാറ്റിവെച്ച് നമ്മുടെ വെക്റ്റർ ഡാറ്റാബേസുമായി ബന്ധിപ്പിക്കാം. ആദ്യം, ഞങ്ങൾ API കീയും നിങ്ങളുടെ ക്ലസ്റ്റർ URL ഉം ഉപയോഗിച്ച് ഒരു റിമോട്ട് കണക്ഷൻ സജ്ജീകരിക്കേണ്ടതുണ്ട്.
import weaviate
import os
import requests
import json
cluster_url = "Your Cluster URL"
wcs_api_key = "Your WCS API Key"
Openai_api_key ="Your OpenAI API Key"
client = weaviate.connect_to_wcs(
cluster_url=cluster_url,
auth_credentials=weaviate.auth.AuthApiKey(wcs_api_key),
headers={
"X-OpenAI-Api-Key": openai_api_key
}
)
നിങ്ങളുടെ ക്ലയൻ്റ് വേരിയബിൾ സജ്ജീകരിച്ചുകഴിഞ്ഞാൽ, ഞങ്ങൾ Weaviate ക്ലൗഡ് സേവനത്തിലേക്ക് കണക്റ്റുചെയ്ത് വെക്റ്റർ സംഭരിക്കുന്നതിന് ഒരു ക്ലാസ് സൃഷ്ടിക്കും. വീവിയേറ്റിലെ ക്ലാസ് എന്നത് ഒരു റിലേഷണൽ ഡാറ്റാബേസിലെ ടേബിൾ നെയിമിൻ്റെ ഡാറ്റ ശേഖരണമോ അനലോഗുകളോ ആണ്.
import weaviate.classes as wvc
client.connect()
book_collection = client.collections.create(
name="BookCollection",
vectorizer_config=wvc.config.Configure.Vectorizer.text2vec_openai(),
generative_config=wvc.config.Configure.Generative.openai()
)
മുകളിലുള്ള കോഡിൽ, ഞങ്ങൾ വീവിയേറ്റ് ക്ലസ്റ്ററിലേക്ക് കണക്റ്റുചെയ്ത് ഒരു ബുക്ക് കളക്ഷൻ ക്ലാസ് സൃഷ്ടിക്കുന്നു. ടെക്സ്റ്റ് ഡാറ്റയും OpenAI ജനറേറ്റീവ് മൊഡ്യൂളും വെക്ടറൈസ് ചെയ്യുന്നതിന് ക്ലാസ് ഒബ്ജക്റ്റ് OpenAI text2vec എംബെഡിംഗ് മോഡലും ഉപയോഗിക്കുന്നു.
ഒരു വെക്റ്റർ ഡാറ്റാബേസിൽ ടെക്സ്റ്റ് ഡാറ്റ സംഭരിക്കാൻ ശ്രമിക്കാം. അത് ചെയ്യുന്നതിന്, നിങ്ങൾക്ക് ഇനിപ്പറയുന്ന കോഡ് ഉപയോഗിക്കാം.
sent_to_vdb = data.to_dict(orient='records')
book_collection.data.insert_many(sent_to_vdb)
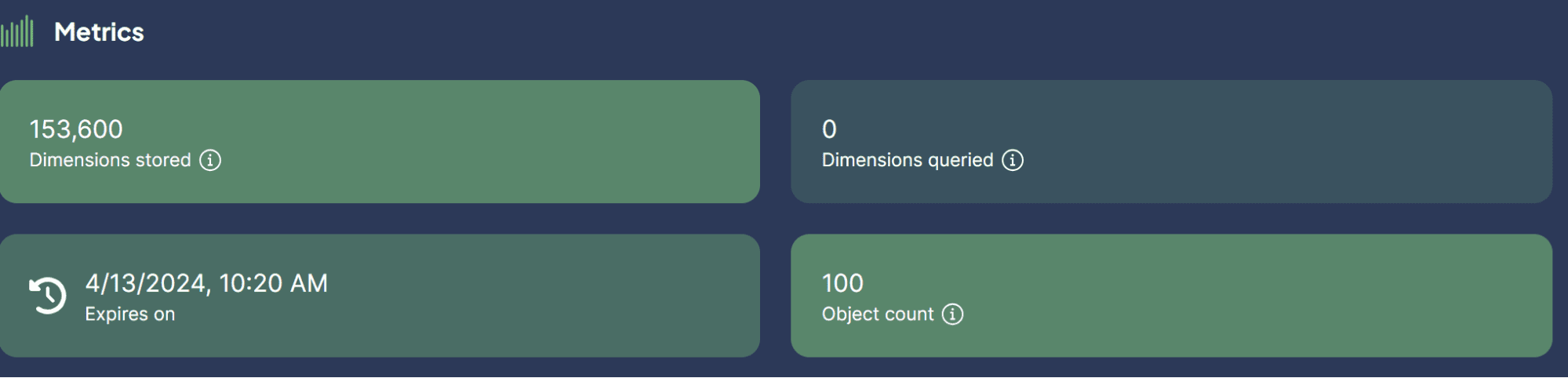
ചിത്രം രചയിതാവ്
വെക്റ്റർ ഡാറ്റാബേസിൽ ഞങ്ങൾ ഞങ്ങളുടെ ഡാറ്റാസെറ്റ് വിജയകരമായി സംഭരിച്ചു! അത് എത്ര എളുപ്പമാണ്?
ഇപ്പോൾ, LLM-നൊപ്പം വെക്റ്റർ ഡാറ്റാബേസുകൾ ഉപയോഗിക്കുന്നതിനുള്ള ഉപയോഗ സാഹചര്യങ്ങളെക്കുറിച്ച് നിങ്ങൾക്ക് ജിജ്ഞാസയുണ്ടായേക്കാം. അതാണ് നമ്മൾ അടുത്തതായി ചർച്ച ചെയ്യാൻ പോകുന്നത്.
വെക്റ്റർ ഡാറ്റാബേസിനൊപ്പം LLM പ്രയോഗിക്കാൻ കഴിയുന്ന കുറച്ച് ഉപയോഗ കേസുകൾ. നമുക്ക് അവ ഒരുമിച്ച് പര്യവേക്ഷണം ചെയ്യാം.
സെമാന്റിക് തിരയൽ
പരമ്പരാഗത കീവേഡ് അധിഷ്ഠിത തിരയലിൽ മാത്രം ആശ്രയിക്കുന്നതിനുപകരം പ്രസക്തമായ ഫലങ്ങൾ വീണ്ടെടുക്കുന്നതിന് അന്വേഷണത്തിൻ്റെ അർത്ഥം ഉപയോഗിച്ച് ഡാറ്റ തിരയുന്ന പ്രക്രിയയാണ് സെമാൻ്റിക് തിരയൽ.
ഈ പ്രക്രിയയിൽ അന്വേഷണത്തിൻ്റെ LLM മോഡൽ ഉൾച്ചേർക്കൽ ഉപയോഗപ്പെടുത്തുന്നതും വെക്റ്റർ ഡാറ്റാബേസിൽ സംഭരിച്ചിരിക്കുന്ന ഞങ്ങളുടെ സംഭരിച്ചിരിക്കുന്നതിലേക്ക് എംബഡിംഗ് സമാനത തിരയൽ നടത്തുന്നതും ഉൾപ്പെടുന്നു.
ഒരു നിർദ്ദിഷ്ട അന്വേഷണത്തെ അടിസ്ഥാനമാക്കി ഒരു സെമാൻ്റിക് തിരയൽ നടത്താൻ Weaviate ഉപയോഗിക്കാൻ ശ്രമിക്കാം.
book_collection = client.collections.get("BookCollection")
client.connect()
response = book_collection.query.near_text(
query="childhood story,
limit=2
)
മുകളിലെ കോഡിൽ, കുട്ടിക്കാലത്തെ ചോദ്യവുമായി അടുത്ത ബന്ധമുള്ള രണ്ട് മികച്ച പുസ്തകങ്ങൾ കണ്ടെത്താൻ Weaviate ഉപയോഗിച്ച് ഒരു സെമാൻ്റിക് തിരയൽ നടത്താൻ ഞങ്ങൾ ശ്രമിക്കുന്നു. സെമാൻ്റിക് തിരയൽ ഞങ്ങൾ മുമ്പ് സജ്ജീകരിച്ച OpenAI എംബെഡിംഗ് മോഡൽ ഉപയോഗിക്കുന്നു. ഫലം നിങ്ങൾക്ക് ചുവടെ കാണാൻ കഴിയും.
{'title': 'Act Your Age', 'description': 'A young girl is told over and over again to act her age.', 'intro': 'Colleen Archer has written for nHighlightsn. In this short story, a young girl is told over and over again to act her age.nAs you read, take notes on what Frances is doing when she is told to act her age. '}
{'title': 'The Anklet', 'description': 'A young woman must deal with unkind and spiteful treatment from her two older sisters.', 'intro': "Neil Philip is a writer and poet who has retold the best-known stories from nThe Arabian Nightsn for a modern day audience. nThe Arabian Nightsn is the English-language nickname frequently given to nOne Thousand and One Arabian Nightsn, a collection of folk tales written and collected in the Middle East during the Islamic Golden Age of the 8th to 13th centuries. In this tale, a poor young woman must deal with mistreatment by members of her own family.nAs you read, take notes on the youngest sister's actions and feelings."}
നിങ്ങൾക്ക് കാണാനാകുന്നതുപോലെ, കുട്ടിക്കാലത്തെ കഥകളെക്കുറിച്ചുള്ള നേരിട്ടുള്ള വാക്കുകളൊന്നും മുകളിലുള്ള ഫലത്തിൽ ഇല്ല. എന്നിരുന്നാലും, ഫലം ഇപ്പോഴും കുട്ടികളെ ലക്ഷ്യമിടുന്ന ഒരു കഥയുമായി അടുത്ത ബന്ധമുള്ളതാണ്.
ജനറേറ്റീവ് തിരയൽ
സെമാൻ്റിക് തിരയലിനുള്ള ഒരു വിപുലീകരണ ആപ്ലിക്കേഷനായി ജനറേറ്റീവ് തിരയൽ നിർവചിക്കാം. ജനറേറ്റീവ് സെർച്ച്, അല്ലെങ്കിൽ റിട്രീവൽ ഓഗ്മെൻ്റഡ് ജനറേഷൻ (RAG), വെക്റ്റർ ഡാറ്റാബേസിൽ നിന്ന് ഡാറ്റ വീണ്ടെടുത്ത സെമാൻ്റിക് തിരയലിനൊപ്പം LLM പ്രോംപ്റ്റിംഗ് ഉപയോഗിക്കുന്നു.
RAG ഉപയോഗിച്ച്, അന്വേഷണ തിരയലിൽ നിന്നുള്ള ഫലം LLM-ലേക്ക് പ്രോസസ്സ് ചെയ്യുന്നു, അതിനാൽ അവ റോ ഡാറ്റയ്ക്ക് പകരം നമുക്ക് ആവശ്യമുള്ള രൂപത്തിൽ ലഭിക്കും. വെക്റ്റർ ഡാറ്റാബേസിനൊപ്പം RAG ലളിതമായി നടപ്പിലാക്കാൻ ശ്രമിക്കാം.
response = book_collection.generate.near_text(
query="childhood story",
limit=2,
grouped_task="Write a short LinkedIn post about these books."
)
print(response.generated)
ഫലം ചുവടെയുള്ള വാചകത്തിൽ കാണാം.
Excited to share two captivating short stories that explore themes of age and mistreatment. "Act Your Age" by Colleen Archer follows a young girl who is constantly told to act her age, while "The Anklet" by Neil Philip delves into the unkind treatment faced by a young woman from her older sisters. These thought-provoking tales will leave you reflecting on societal expectations and family dynamics. #ShortStories #Literature #BookRecommendations 📚
നിങ്ങൾക്ക് കാണാനാകുന്നതുപോലെ, ഡാറ്റ ഉള്ളടക്കം മുമ്പത്തേതിന് സമാനമാണ്, എന്നാൽ ഇപ്പോൾ ഒരു ചെറിയ ലിങ്ക്ഡ്ഇൻ പോസ്റ്റ് നൽകുന്നതിന് OpenAI LLM ഉപയോഗിച്ച് പ്രോസസ്സ് ചെയ്തിട്ടുണ്ട്. ഈ രീതിയിൽ, ഡാറ്റയിൽ നിന്ന് പ്രത്യേക ഫോം ഔട്ട്പുട്ട് ആവശ്യമുള്ളപ്പോൾ RAG ഉപയോഗപ്രദമാണ്.
RAG ഉപയോഗിച്ചുള്ള ചോദ്യത്തിനുള്ള ഉത്തരം
ഞങ്ങളുടെ മുമ്പത്തെ ഉദാഹരണത്തിൽ, ഞങ്ങൾക്ക് ആവശ്യമുള്ള ഡാറ്റ ലഭിക്കുന്നതിന് ഞങ്ങൾ ഒരു ചോദ്യം ഉപയോഗിച്ചു, കൂടാതെ RAG ആ ഡാറ്റയെ ഉദ്ദേശിച്ച ഔട്ട്പുട്ടിലേക്ക് പ്രോസസ്സ് ചെയ്തു.
എന്നിരുന്നാലും, നമുക്ക് RAG കഴിവിനെ ഒരു ചോദ്യോത്തര ഉപകരണമാക്കി മാറ്റാം. LangChain ചട്ടക്കൂടുമായി അവയെ സംയോജിപ്പിച്ച് നമുക്ക് ഇത് നേടാനാകും.
ആദ്യം, നമുക്ക് ആവശ്യമായ പാക്കേജുകൾ ഇൻസ്റ്റാൾ ചെയ്യാം.
pip install langchain
pip install langchain_community
pip install langchain_openai
തുടർന്ന്, പാക്കേജുകൾ ഇറക്കുമതി ചെയ്യാനും RAG വർക്ക് ഉപയോഗിച്ച് QA ഉണ്ടാക്കാൻ ആവശ്യമായ വേരിയബിളുകൾ ആരംഭിക്കാനും ശ്രമിക്കാം.
from langchain.chains import RetrievalQA
from langchain_community.vectorstores import Weaviate
import weaviate
from langchain_openai import OpenAIEmbeddings
from langchain_openai.llms.base import OpenAI
llm = OpenAI(openai_api_key = openai_api_key, model_name = 'gpt-3.5-turbo-instruct', temperature = 1)
embeddings = OpenAIEmbeddings(openai_api_key = openai_api_key )
client = weaviate.Client(
url=cluster_url, auth_client_secret=weaviate.AuthApiKey(wcs_api_key)
)
മുകളിലെ കോഡിൽ, ടെക്സ്റ്റ് ജനറേഷൻ, എംബെഡിംഗ് മോഡൽ, വീവിയേറ്റ് ക്ലയൻ്റ് കണക്ഷൻ എന്നിവയ്ക്കായി ഞങ്ങൾ LLM സജ്ജീകരിച്ചു.
അടുത്തതായി, ഞങ്ങൾ വെക്റ്റർ ഡാറ്റാബേസിലേക്ക് Weaviate കണക്ഷൻ സജ്ജമാക്കുന്നു.
weaviate_vectorstore = Weaviate(client=client, index_name='BookCollection', text_key='intro',by_text = False, embedding=embeddings)
retriever = weaviate_vectorstore.as_retriever()
മുകളിലെ കോഡിൽ, ആവശ്യപ്പെടുമ്പോൾ 'ആമുഖം' ഫീച്ചർ തിരയുന്ന RAG ടൂളായി വീവിയേറ്റ് ഡാറ്റാബേസ് ബുക്ക് കളക്ഷനെ മാറ്റുക.
തുടർന്ന്, താഴെയുള്ള കോഡ് ഉപയോഗിച്ച് ഞങ്ങൾ LangChain-ൽ നിന്ന് ചോദ്യോത്തര ശൃംഖല സൃഷ്ടിക്കും.
qa_chain = RetrievalQA.from_chain_type(
llm=llm, chain_type="stuff", retriever = retriever
)
ഇപ്പോൾ എല്ലാം തയ്യാറാണ്. ഇനിപ്പറയുന്ന കോഡ് ഉദാഹരണം ഉപയോഗിച്ച് RAG ഉപയോഗിച്ച് QA പരീക്ഷിക്കാം.
response = qa_chain.invoke(
"Who is the writer who write about love between two goldfish?")
print(response)
ഫലം ചുവടെയുള്ള വാചകത്തിൽ കാണിച്ചിരിക്കുന്നു.
{'query': 'Who is the writer who write about love between two goldfish?', 'result': ' The writer is Grace Chua.'}
എല്ലാ ടെക്സ്റ്റ് ഡാറ്റയും സംഭരിക്കുന്നതിനുള്ള സ്ഥലമായി വെക്റ്റർ ഡാറ്റാബേസ് ഉപയോഗിച്ച്, ലാങ്ചെയിൻ ഉപയോഗിച്ച് ക്യുഎ നടത്താൻ ഞങ്ങൾക്ക് RAG നടപ്പിലാക്കാം. അത് എത്ര വൃത്തിയാണ്?
വെക്റ്റർ ഡാറ്റ സംഭരിക്കാനും സൂചികയാക്കാനും അന്വേഷിക്കാനും രൂപകൽപ്പന ചെയ്തിരിക്കുന്ന ഒരു പ്രത്യേക സംഭരണ പരിഹാരമാണ് വെക്റ്റർ ഡാറ്റാബേസ്. ഇത് പലപ്പോഴും ടെക്സ്റ്റ് ഡാറ്റ സംഭരിക്കുന്നതിനും വലിയ ഭാഷാ മോഡലുകളുമായി (എൽഎൽഎം) സംയോജിപ്പിച്ച് നടപ്പിലാക്കുന്നതിനും ഉപയോഗിക്കുന്നു. സെമാൻ്റിക് സെർച്ച്, റിട്രീവൽ-ഓഗ്മെൻ്റഡ് ജനറേഷൻ (RAG), RAG ഉപയോഗിച്ചുള്ള ചോദ്യത്തിനുള്ള ഉത്തരം എന്നിവ പോലുള്ള ഉദാഹരണ ഉപയോഗ കേസുകൾ ഉൾപ്പെടെ, വെക്റ്റർ ഡാറ്റാബേസ് വീവിയേറ്റിൻ്റെ ഒരു ഹാൻഡ്-ഓൺ സെറ്റപ്പ് ഈ ലേഖനം പരീക്ഷിക്കും.
കൊർണേലിയസ് യുദ്ധ വിജയ ഒരു ഡാറ്റാ സയൻസ് അസിസ്റ്റൻ്റ് മാനേജരും ഡാറ്റാ റൈറ്ററുമാണ്. അലയൻസ് ഇന്തോനേഷ്യയിൽ മുഴുവൻ സമയ ജോലി ചെയ്യുമ്പോൾ, സോഷ്യൽ മീഡിയയിലൂടെയും എഴുത്ത് മാധ്യമങ്ങളിലൂടെയും പൈത്തണും ഡാറ്റ ടിപ്പുകളും പങ്കിടാൻ അദ്ദേഹം ഇഷ്ടപ്പെടുന്നു. വിവിധതരം AI, മെഷീൻ ലേണിംഗ് വിഷയങ്ങളിൽ കോർണേലിയസ് എഴുതുന്നു.
- SEO പവർ ചെയ്ത ഉള്ളടക്കവും PR വിതരണവും. ഇന്ന് ആംപ്ലിഫൈഡ് നേടുക.
- PlatoData.Network ലംബ ജനറേറ്റീവ് Ai. സ്വയം ശാക്തീകരിക്കുക. ഇവിടെ പ്രവേശിക്കുക.
- PlatoAiStream. Web3 ഇന്റലിജൻസ്. വിജ്ഞാനം വർധിപ്പിച്ചു. ഇവിടെ പ്രവേശിക്കുക.
- പ്ലേറ്റോഇഎസ്ജി. കാർബൺ, ക്ലീൻ ടെക്, ഊർജ്ജം, പരിസ്ഥിതി, സോളാർ, മാലിന്യ സംസ്കരണം. ഇവിടെ പ്രവേശിക്കുക.
- പ്ലേറ്റോ ഹെൽത്ത്. ബയോടെക് ആൻഡ് ക്ലിനിക്കൽ ട്രയൽസ് ഇന്റലിജൻസ്. ഇവിടെ പ്രവേശിക്കുക.
- അവലംബം: https://www.kdnuggets.com/vector-databases-in-ai-and-llm-use-cases?utm_source=rss&utm_medium=rss&utm_campaign=vector-databases-in-ai-and-llm-use-cases

