നിർമ്മാണത്തിൻ്റെ വികസിച്ചുകൊണ്ടിരിക്കുന്ന ലാൻഡ്സ്കേപ്പിൽ, AI, മെഷീൻ ലേണിംഗ് (ML) എന്നിവയുടെ പരിവർത്തന ശക്തി വ്യക്തമാണ്, ഇത് പ്രവർത്തനങ്ങളെ കാര്യക്ഷമമാക്കുകയും ഉൽപ്പാദനക്ഷമത വർദ്ധിപ്പിക്കുകയും ചെയ്യുന്ന ഒരു ഡിജിറ്റൽ വിപ്ലവം നയിക്കുന്നു. എന്നിരുന്നാലും, ഡാറ്റാധിഷ്ഠിത പരിഹാരങ്ങൾ നാവിഗേറ്റ് ചെയ്യുന്ന സംരംഭങ്ങൾക്ക് ഈ പുരോഗതി സവിശേഷമായ വെല്ലുവിളികൾ അവതരിപ്പിക്കുന്നു. വ്യാവസായിക സൗകര്യങ്ങൾ, സെൻസറുകൾ, ടെലിമെട്രി സംവിധാനങ്ങൾ, ഉൽപ്പാദന ലൈനുകളിൽ ചിതറിക്കിടക്കുന്ന ഉപകരണങ്ങൾ എന്നിവയിൽ നിന്ന് സ്രോതസ്സുചെയ്ത, ഘടനാരഹിതമായ ഡാറ്റയുടെ വലിയ അളവുമായി പൊരുത്തപ്പെടുന്നു. പ്രെഡിക്റ്റീവ് മെയിൻ്റനൻസ്, അനോമലി ഡിറ്റക്ഷൻ തുടങ്ങിയ ആപ്ലിക്കേഷനുകൾക്ക് റിയൽ-ടൈം ഡാറ്റ നിർണായകമാണ്, എന്നിരുന്നാലും ഓരോ വ്യാവസായിക ഉപയോഗത്തിനും ഇഷ്ടാനുസൃത ML മോഡലുകൾ വികസിപ്പിക്കുന്നതിന് അത്തരം സമയ ശ്രേണി ഡാറ്റ ഡാറ്റ ശാസ്ത്രജ്ഞരിൽ നിന്ന് ഗണ്യമായ സമയവും വിഭവങ്ങളും ആവശ്യപ്പെടുന്നു, ഇത് വ്യാപകമായ ദത്തെടുക്കലിനെ തടസ്സപ്പെടുത്തുന്നു.
ജനറേറ്റീവ് AI പോലുള്ള വലിയ പ്രീ-ട്രെയിൻഡ് ഫൗണ്ടേഷൻ മോഡലുകൾ (എഫ്എം) ഉപയോഗിക്കുന്നു ക്ലോഡ് എന്നറിയപ്പെടുന്ന ലളിതമായ ടെക്സ്റ്റ് പ്രോംപ്റ്റുകളെ അടിസ്ഥാനമാക്കി സംഭാഷണ ടെക്സ്റ്റിൽ നിന്ന് കമ്പ്യൂട്ടർ കോഡിലേക്ക് വൈവിധ്യമാർന്ന ഉള്ളടക്കം വേഗത്തിൽ സൃഷ്ടിക്കാൻ കഴിയും സീറോ-ഷോട്ട് പ്രോംപ്റ്റിംഗ്. ഓരോ ഉപയോഗ സാഹചര്യത്തിനും പ്രത്യേക ML മോഡലുകൾ സ്വമേധയാ വികസിപ്പിക്കേണ്ടതിൻ്റെ ആവശ്യകത ഡാറ്റ ശാസ്ത്രജ്ഞർക്ക് ഇത് ഇല്ലാതാക്കുന്നു, അതിനാൽ AI ആക്സസ് ജനാധിപത്യവൽക്കരിക്കുകയും ചെറുകിട നിർമ്മാതാക്കൾക്ക് പോലും പ്രയോജനം നേടുകയും ചെയ്യുന്നു. AI- സൃഷ്ടിച്ച സ്ഥിതിവിവരക്കണക്കുകൾ വഴി തൊഴിലാളികൾ ഉൽപ്പാദനക്ഷമത നേടുന്നു, എഞ്ചിനീയർമാർക്ക് അപാകതകൾ മുൻകൂട്ടി കണ്ടെത്താനാകും, സപ്ലൈ ചെയിൻ മാനേജർമാർ ഇൻവെൻ്ററികൾ ഒപ്റ്റിമൈസ് ചെയ്യുന്നു, കൂടാതെ പ്ലാൻ്റ് നേതൃത്വം വിവരവും ഡാറ്റ അടിസ്ഥാനമാക്കിയുള്ള തീരുമാനങ്ങളും എടുക്കുന്നു.
എന്നിരുന്നാലും, കോൺടെക്സ്റ്റ് സൈസ് പരിമിതികളോടെ (സാധാരണയായി) സങ്കീർണ്ണമായ വ്യാവസായിക ഡാറ്റ കൈകാര്യം ചെയ്യുന്നതിൽ ഒറ്റപ്പെട്ട എഫ്എമ്മുകൾക്ക് പരിമിതികളുണ്ട്. 200,000 ടോക്കണുകളിൽ കുറവ്), ഇത് വെല്ലുവിളികൾ ഉയർത്തുന്നു. ഇത് പരിഹരിക്കുന്നതിന്, സ്വാഭാവിക ഭാഷാ അന്വേഷണങ്ങൾക്ക് (NLQs) പ്രതികരണമായി കോഡ് സൃഷ്ടിക്കുന്നതിനുള്ള FM-ൻ്റെ കഴിവ് നിങ്ങൾക്ക് ഉപയോഗിക്കാം. ഏജൻ്റുമാർ ഇഷ്ടപ്പെടുന്നു പാണ്ഡസായ് ഉയർന്ന മിഴിവുള്ള സമയ ശ്രേണി ഡാറ്റയിൽ ഈ കോഡ് പ്രവർത്തിപ്പിക്കുകയും FM-കൾ ഉപയോഗിച്ച് പിശകുകൾ കൈകാര്യം ചെയ്യുകയും ചെയ്യുക. PandasAI എന്നത് ഒരു പൈത്തൺ ലൈബ്രറിയാണ്, അത് പാണ്ടകളിലേക്ക് ജനറേറ്റീവ് AI കഴിവുകൾ ചേർക്കുന്നു, ഇത് ജനപ്രിയ ഡാറ്റാ വിശകലനവും കൃത്രിമത്വ ഉപകരണവുമാണ്.
എന്നിരുന്നാലും, ടൈം സീരീസ് ഡാറ്റ പ്രോസസ്സിംഗ്, മൾട്ടി-ലെവൽ അഗ്രഗേഷൻ, പിവറ്റ് അല്ലെങ്കിൽ ജോയിൻ്റ് ടേബിൾ ഓപ്പറേഷനുകൾ എന്നിവ പോലുള്ള സങ്കീർണ്ണമായ NLQ-കൾ, സീറോ-ഷോട്ട് പ്രോംപ്റ്റ് ഉപയോഗിച്ച് പൈത്തൺ സ്ക്രിപ്റ്റ് പൊരുത്തക്കേട് നൽകിയേക്കാം.
കോഡ് ജനറേഷൻ കൃത്യത വർദ്ധിപ്പിക്കുന്നതിന്, ചലനാത്മകമായി നിർമ്മിക്കാൻ ഞങ്ങൾ നിർദ്ദേശിക്കുന്നു മൾട്ടി-ഷോട്ട് നിർദ്ദേശങ്ങൾ NLQ-കൾക്കായി. മൾട്ടി-ഷോട്ട് പ്രോംപ്റ്റിംഗ്, സമാന പ്രോംപ്റ്റുകൾക്കായി ആവശ്യമുള്ള ഔട്ട്പുട്ടുകളുടെ നിരവധി ഉദാഹരണങ്ങൾ കാണിച്ച്, കൃത്യതയും സ്ഥിരതയും വർദ്ധിപ്പിക്കുന്നതിലൂടെ FM-ന് അധിക സന്ദർഭം നൽകുന്നു. ഈ പോസ്റ്റിൽ, സമാനമായ ഡാറ്റാ തരത്തിൽ (ഉദാഹരണത്തിന്, ഇൻ്റർനെറ്റ് ഓഫ് തിംഗ്സ് ഉപകരണങ്ങളിൽ നിന്നുള്ള ഉയർന്ന റെസല്യൂഷൻ ടൈം സീരീസ് ഡാറ്റ) വിജയകരമായ പൈത്തൺ കോഡ് അടങ്ങിയ ഒരു ഉൾച്ചേർക്കലിൽ നിന്ന് മൾട്ടി-ഷോട്ട് പ്രോംപ്റ്റുകൾ വീണ്ടെടുക്കുന്നു. ചലനാത്മകമായി നിർമ്മിച്ച മൾട്ടി-ഷോട്ട് പ്രോംപ്റ്റ് FM-ന് ഏറ്റവും പ്രസക്തമായ സന്ദർഭം നൽകുന്നു, കൂടാതെ വിപുലമായ ഗണിത കണക്കുകൂട്ടൽ, സമയ ശ്രേണി ഡാറ്റ പ്രോസസ്സിംഗ്, ഡാറ്റ ചുരുക്കെഴുത്ത് മനസ്സിലാക്കൽ എന്നിവയിൽ FM-ൻ്റെ കഴിവ് വർദ്ധിപ്പിക്കുന്നു. ഈ മെച്ചപ്പെട്ട പ്രതികരണം എൻ്റർപ്രൈസ് തൊഴിലാളികളെയും പ്രവർത്തന ടീമുകളെയും ഡാറ്റയുമായി ഇടപഴകുന്നതിനും വിപുലമായ ഡാറ്റാ സയൻസ് കഴിവുകൾ ആവശ്യമില്ലാതെ സ്ഥിതിവിവരക്കണക്കുകൾ നേടുന്നതിനും സഹായിക്കുന്നു.
സമയ ശ്രേണി ഡാറ്റാ വിശകലനത്തിനപ്പുറം, വിവിധ വ്യാവസായിക ആപ്ലിക്കേഷനുകളിൽ FM-കൾ വിലപ്പെട്ടതായി തെളിയിക്കുന്നു. മെയിൻ്റനൻസ് ടീമുകൾ അസറ്റ് ആരോഗ്യം വിലയിരുത്തുന്നു, ചിത്രങ്ങൾ എടുക്കുന്നു ആമസോൺ റെക്കഗ്നിഷൻ-അടിസ്ഥാനത്തിലുള്ള പ്രവർത്തന സംഗ്രഹങ്ങൾ, ബുദ്ധിപരമായ തിരയലുകൾ ഉപയോഗിച്ച് അപാകത മൂലകാരണ വിശകലനം വീണ്ടെടുക്കൽ ഓഗ്മെന്റഡ് ജനറേഷൻ (RAG). ഈ വർക്ക്ഫ്ലോകൾ ലളിതമാക്കാൻ, AWS അവതരിപ്പിച്ചു ആമസോൺ ബെഡ്റോക്ക്, അത്യാധുനിക പ്രീ-ട്രെയിൻഡ് എഫ്എമ്മുകൾ ഉപയോഗിച്ച് ജനറേറ്റീവ് എഐ ആപ്ലിക്കേഷനുകൾ നിർമ്മിക്കാനും സ്കെയിൽ ചെയ്യാനും നിങ്ങളെ പ്രാപ്തമാക്കുന്നു ക്ലോഡ് v2. കൂടെ ആമസോൺ ബെഡ്റോക്കിനുള്ള വിജ്ഞാന അടിത്തറ, പ്ലാൻ്റ് തൊഴിലാളികൾക്ക് കൂടുതൽ കൃത്യമായ അപാകത മൂലകാരണ വിശകലനം നൽകുന്നതിന് നിങ്ങൾക്ക് RAG വികസന പ്രക്രിയ ലളിതമാക്കാം. ഞങ്ങളുടെ പോസ്റ്റ് ആമസോൺ ബെഡ്റോക്ക് നൽകുന്ന വ്യാവസായിക ഉപയോഗ കേസുകൾക്കായുള്ള ഒരു ഇൻ്റലിജൻ്റ് അസിസ്റ്റൻ്റിനെ കാണിക്കുന്നു, NLQ വെല്ലുവിളികളെ അഭിസംബോധന ചെയ്യുന്നു, ചിത്രങ്ങളിൽ നിന്ന് ഭാഗങ്ങളുടെ സംഗ്രഹങ്ങൾ സൃഷ്ടിക്കുന്നു, കൂടാതെ RAG സമീപനത്തിലൂടെ ഉപകരണ രോഗനിർണയത്തിനുള്ള എഫ്എം പ്രതികരണങ്ങൾ വർദ്ധിപ്പിക്കുന്നു.
പരിഹാര അവലോകനം
ഇനിപ്പറയുന്ന വാക്യം പരിഹാര വാസ്തുവിദ്യയെ വ്യക്തമാക്കുന്നു.

വർക്ക്ഫ്ലോയിൽ മൂന്ന് വ്യത്യസ്ത ഉപയോഗ കേസുകൾ ഉൾപ്പെടുന്നു:
കേസ് 1 ഉപയോഗിക്കുക: സമയ ശ്രേണി ഡാറ്റയ്ക്കൊപ്പം NLQ
സമയ ശ്രേണി ഡാറ്റയോടുകൂടിയ NLQ-നുള്ള വർക്ക്ഫ്ലോ ഇനിപ്പറയുന്ന ഘട്ടങ്ങൾ ഉൾക്കൊള്ളുന്നു:
- അനോമലി കണ്ടെത്തലിനായി ഞങ്ങൾ ML കഴിവുകളുള്ള ഒരു അവസ്ഥ നിരീക്ഷണ സംവിധാനം ഉപയോഗിക്കുന്നു ആമസോൺ മോണിട്രോൺ, വ്യവസായ ഉപകരണങ്ങളുടെ ആരോഗ്യം നിരീക്ഷിക്കാൻ. ആമസോൺ മോണിട്രോണിന് ഉപകരണങ്ങളുടെ വൈബ്രേഷൻ, താപനില അളവുകൾ എന്നിവയിൽ നിന്ന് സാധ്യമായ ഉപകരണ പരാജയങ്ങൾ കണ്ടെത്താൻ കഴിയും.
- പ്രോസസ്സിംഗ് വഴി ഞങ്ങൾ സമയ ശ്രേണി ഡാറ്റ ശേഖരിക്കുന്നു ആമസോൺ മോണിട്രോൺ ഡാറ്റ വഴി ആമസോൺ കൈനസിസ് ഡാറ്റ സ്ട്രീമുകൾ ഒപ്പം ആമസോൺ ഡാറ്റ ഫയർഹോസ്, ഇത് ഒരു ടാബ്ലർ CSV ഫോർമാറ്റിലേക്ക് പരിവർത്തനം ചെയ്യുകയും ഒരു എന്നതിൽ സംരക്ഷിക്കുകയും ചെയ്യുന്നു ആമസോൺ ലളിതമായ സംഭരണ സേവനം (Amazon S3) ബക്കറ്റ്.
- സ്ട്രീംലിറ്റ് ആപ്പിലേക്ക് ഒരു സ്വാഭാവിക ഭാഷാ അന്വേഷണം അയച്ചുകൊണ്ട് അന്തിമ ഉപയോക്താവിന് ആമസോൺ എസ് 3-ലെ അവരുടെ സമയ ശ്രേണി ഡാറ്റയുമായി ചാറ്റ് ചെയ്യാൻ കഴിയും.
- സ്ട്രീംലിറ്റ് ആപ്പ് ഉപയോക്തൃ ചോദ്യങ്ങൾ ഇതിലേക്ക് കൈമാറുന്നു ആമസോൺ ബെഡ്റോക്ക് ടൈറ്റൻ ടെക്സ്റ്റ് എംബെഡിംഗ് മോഡൽ ഈ ചോദ്യം ഉൾച്ചേർക്കാൻ, ഒരു സാമ്യത തിരയൽ നടത്തുന്നു ആമസോൺ ഓപ്പൺ സെർച്ച് സേവനം മുൻ NLQ-കളും ഉദാഹരണ കോഡുകളും അടങ്ങുന്ന സൂചിക.
- സമാനത തിരയലിന് ശേഷം, NLQ ചോദ്യങ്ങൾ, ഡാറ്റാ സ്കീമ, പൈത്തൺ കോഡുകൾ എന്നിവയുൾപ്പെടെയുള്ള സമാന ഉദാഹരണങ്ങൾ ഒരു ഇഷ്ടാനുസൃത പ്രോംപ്റ്റിൽ ചേർക്കുന്നു.
- ആമസോൺ ബെഡ്റോക്ക് ക്ലോഡ് v2 മോഡലിലേക്ക് PandasAI ഈ ഇഷ്ടാനുസൃത നിർദ്ദേശം അയയ്ക്കുന്നു.
- ആമസോൺ ബെഡ്റോക്ക് ക്ലോഡ് v2 മോഡലുമായി സംവദിക്കാൻ ആപ്പ് PandasAI ഏജൻ്റിനെ ഉപയോഗിക്കുന്നു, Amazon Monitron ഡാറ്റാ വിശകലനത്തിനും NLQ പ്രതികരണങ്ങൾക്കുമായി പൈത്തൺ കോഡ് സൃഷ്ടിക്കുന്നു.
- ആമസോൺ ബെഡ്റോക്ക് ക്ലോഡ് v2 മോഡൽ പൈത്തൺ കോഡ് തിരികെ നൽകിയതിന് ശേഷം, ആപ്പിൽ നിന്ന് അപ്ലോഡ് ചെയ്ത Amazon Monitron ഡാറ്റയിൽ PandasAI പൈത്തൺ അന്വേഷണം പ്രവർത്തിപ്പിക്കുകയും കോഡ് ഔട്ട്പുട്ടുകൾ ശേഖരിക്കുകയും പരാജയപ്പെട്ട റണ്ണുകൾക്ക് ആവശ്യമായ എല്ലാ ശ്രമങ്ങളും പരിഹരിക്കുകയും ചെയ്യുന്നു.
- Streamlit ആപ്പ് PandasAI വഴി പ്രതികരണം ശേഖരിക്കുകയും ഉപയോക്താക്കൾക്ക് ഔട്ട്പുട്ട് നൽകുകയും ചെയ്യുന്നു. ഔട്ട്പുട്ട് തൃപ്തികരമാണെങ്കിൽ, ഓപ്പൺ സെർച്ച് സേവനത്തിൽ NLQ, ക്ലോഡ് സൃഷ്ടിച്ച പൈത്തൺ കോഡ് എന്നിവ സംരക്ഷിച്ച് ഉപയോക്താവിന് ഇത് സഹായകരമാണെന്ന് അടയാളപ്പെടുത്താനാകും.
കേസ് 2 ഉപയോഗിക്കുക: തകരാറുള്ള ഭാഗങ്ങളുടെ സംഗ്രഹം
ഞങ്ങളുടെ സംഗ്രഹ ജനറേഷൻ ഉപയോഗ കേസിൽ ഇനിപ്പറയുന്ന ഘട്ടങ്ങൾ അടങ്ങിയിരിക്കുന്നു:
- ഏത് വ്യാവസായിക ആസ്തിയാണ് അസാധാരണമായ പെരുമാറ്റം കാണിക്കുന്നതെന്ന് ഉപയോക്താവിന് അറിഞ്ഞ ശേഷം, അതിൻ്റെ സാങ്കേതിക സവിശേഷതകളും പ്രവർത്തന അവസ്ഥയും അനുസരിച്ച് ഈ ഭാഗത്ത് ശാരീരികമായി എന്തെങ്കിലും കുഴപ്പമുണ്ടോ എന്ന് തിരിച്ചറിയാൻ അവർക്ക് തകരാറുള്ള ഭാഗത്തിൻ്റെ ചിത്രങ്ങൾ അപ്ലോഡ് ചെയ്യാൻ കഴിയും.
- ഉപയോക്താവിന് ഉപയോഗിക്കാം Amazon Recognition DetectText API ഈ ചിത്രങ്ങളിൽ നിന്ന് ടെക്സ്റ്റ് ഡാറ്റ എക്സ്ട്രാക്റ്റ് ചെയ്യാൻ.
- എക്സ്ട്രാക്റ്റ് ചെയ്ത ടെക്സ്റ്റ് ഡാറ്റ ആമസോൺ ബെഡ്റോക്ക് ക്ലോഡ് v2 മോഡലിൻ്റെ പ്രോംപ്റ്റിൽ ഉൾപ്പെടുത്തിയിട്ടുണ്ട്, ഇത് തെറ്റായി പ്രവർത്തിക്കുന്ന ഭാഗത്തിൻ്റെ 200-വാക്കുകളുടെ സംഗ്രഹം സൃഷ്ടിക്കാൻ മോഡലിനെ പ്രാപ്തമാക്കുന്നു. ഭാഗത്തിൻ്റെ കൂടുതൽ പരിശോധന നടത്താൻ ഉപയോക്താവിന് ഈ വിവരങ്ങൾ ഉപയോഗിക്കാം.
കേസ് 3 ഉപയോഗിക്കുക: മൂലകാരണ രോഗനിർണയം
ഞങ്ങളുടെ മൂലകാരണ രോഗനിർണ്ണയ ഉപയോഗ കേസിൽ ഇനിപ്പറയുന്ന ഘട്ടങ്ങൾ അടങ്ങിയിരിക്കുന്നു:
- തെറ്റായ പ്രവർത്തന അസറ്റുകളുമായി ബന്ധപ്പെട്ട വിവിധ ഡോക്യുമെൻ്റ് ഫോർമാറ്റുകളിൽ (PDF, TXT, മുതലായവ) എൻ്റർപ്രൈസ് ഡാറ്റ ഉപയോക്താവ് നേടുകയും അവ ഒരു S3 ബക്കറ്റിലേക്ക് അപ്ലോഡ് ചെയ്യുകയും ചെയ്യുന്നു.
- ആമസോൺ ബെഡ്റോക്കിൽ ടൈറ്റൻ ടെക്സ്റ്റ് എംബെഡ്ഡിംഗ് മോഡലും ഡിഫോൾട്ട് ഓപ്പൺസെർച്ച് സർവീസ് വെക്റ്റർ സ്റ്റോറും ഉപയോഗിച്ച് ഈ ഫയലുകളുടെ ഒരു വിജ്ഞാന അടിത്തറ ജനറേറ്റുചെയ്യുന്നു.
- തെറ്റായ ഉപകരണങ്ങളുടെ മൂലകാരണ രോഗനിർണ്ണയവുമായി ബന്ധപ്പെട്ട ചോദ്യങ്ങൾ ഉപയോക്താവ് ഉന്നയിക്കുന്നു. RAG സമീപനത്തോടെ ആമസോൺ ബെഡ്റോക്ക് വിജ്ഞാന അടിത്തറയിലൂടെ ഉത്തരങ്ങൾ സൃഷ്ടിക്കപ്പെടുന്നു.
മുൻവ്യവസ്ഥകൾ
ഈ പോസ്റ്റിനൊപ്പം പിന്തുടരുന്നതിന്, നിങ്ങൾ ഇനിപ്പറയുന്ന മുൻവ്യവസ്ഥകൾ പാലിക്കണം:
സൊല്യൂഷൻ ഇൻഫ്രാസ്ട്രക്ചർ വിന്യസിക്കുക
നിങ്ങളുടെ പരിഹാര ഉറവിടങ്ങൾ സജ്ജീകരിക്കുന്നതിന്, ഇനിപ്പറയുന്ന ഘട്ടങ്ങൾ പൂർത്തിയാക്കുക:
- വിന്യസിക്കുക AWS ക്ലൗഡ്ഫോർമേഷൻ ടെംപ്ലേറ്റ് opensearchsagemaker.yml, ഇത് ഒരു ഓപ്പൺ സെർച്ച് സേവന ശേഖരണവും സൂചികയും സൃഷ്ടിക്കുന്നു, ആമസോൺ സേജ് മേക്കർ നോട്ട്ബുക്ക് ഉദാഹരണവും S3 ബക്കറ്റും. നിങ്ങൾക്ക് ഈ AWS ക്ലൗഡ് ഫോർമേഷൻ സ്റ്റാക്കിനെ ഇങ്ങനെ പേരിടാം:
genai-sagemaker. - JupyterLab-ൽ SageMaker നോട്ട്ബുക്ക് ഇൻസ്റ്റൻസ് തുറക്കുക. ഇനിപ്പറയുന്നവ നിങ്ങൾ കണ്ടെത്തും ഗിറ്റ്ഹബ് റെപ്പോ ഈ സന്ദർഭത്തിൽ ഇതിനകം ഡൗൺലോഡ് ചെയ്തു: വ്യാവസായിക പ്രവർത്തനങ്ങളിൽ ജനറേറ്റീവ്-ഐ-ഇൻ-ഓപ്പറേഷനുകളുടെ സാധ്യതകൾ അൺലോക്ക് ചെയ്യുന്നു.
- ഈ ശേഖരത്തിലെ ഇനിപ്പറയുന്ന ഡയറക്ടറിയിൽ നിന്ന് നോട്ട്ബുക്ക് പ്രവർത്തിപ്പിക്കുക: അൺലോക്കിംഗ്-ദി-പൊട്ടൻഷ്യൽ-ഓഫ്-ജനറേറ്റീവ്-എഐ-ഇൻ-ഇൻഡസ്ട്രിയൽ-ഓപ്പറേഷൻസ്/SagemakerNotebook/nlq-vector-rag-embedding.ipynb. ഈ നോട്ട്ബുക്ക് SageMaker നോട്ട്ബുക്ക് ഉപയോഗിച്ച് OpenSearch സേവന സൂചിക ലോഡ് ചെയ്യും. നിലവിലുള്ള 23 NLQ ഉദാഹരണങ്ങൾ.
- ഡാറ്റ ഫോൾഡറിൽ നിന്ന് പ്രമാണങ്ങൾ അപ്ലോഡ് ചെയ്യുക അസറ്റ്പാർട്ട്ഡോക് GitHub റിപ്പോസിറ്ററിയിൽ, CloudFormation സ്റ്റാക്ക് ഔട്ട്പുട്ടുകളിൽ ലിസ്റ്റ് ചെയ്തിരിക്കുന്ന S3 ബക്കറ്റിലേക്ക്.

അടുത്തതായി, നിങ്ങൾ ആമസോൺ എസ് 3-ൽ ഡോക്യുമെൻ്റുകൾക്കായി വിജ്ഞാന അടിത്തറ സൃഷ്ടിക്കുന്നു.
- Amazon Bedrock കൺസോളിൽ, തിരഞ്ഞെടുക്കുക നോളജ് ബേസ് നാവിഗേഷൻ പാളിയിൽ.
- തിരഞ്ഞെടുക്കുക വിജ്ഞാന അടിത്തറ ഉണ്ടാക്കുക.
- വേണ്ടി അറിവിൻ്റെ അടിസ്ഥാന നാമം, ഒരു പേര് നൽകുക.
- വേണ്ടി റൺടൈം റോൾ, തിരഞ്ഞെടുക്കുക ഒരു പുതിയ സേവന റോൾ സൃഷ്ടിച്ച് ഉപയോഗിക്കുക.
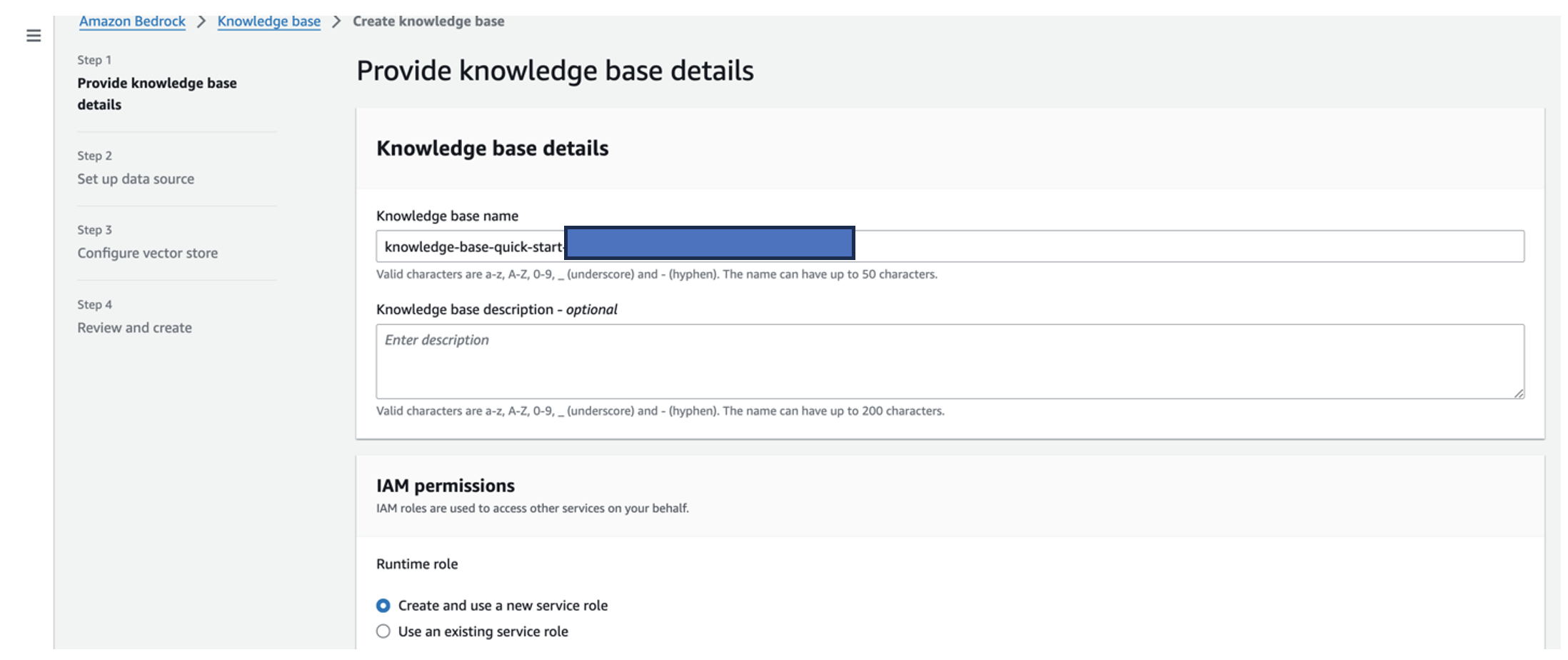
- വേണ്ടി ഡാറ്റ ഉറവിട നാമം, നിങ്ങളുടെ ഡാറ്റ ഉറവിടത്തിൻ്റെ പേര് നൽകുക.
- വേണ്ടി S3 URI, നിങ്ങൾ മൂലകാരണ രേഖകൾ അപ്ലോഡ് ചെയ്ത ബക്കറ്റിൻ്റെ S3 പാത നൽകുക.
- തിരഞ്ഞെടുക്കുക അടുത്തത്.
 ടൈറ്റൻ എംബെഡിംഗ്സ് മോഡൽ സ്വയമേവ തിരഞ്ഞെടുക്കപ്പെടുന്നു.
ടൈറ്റൻ എംബെഡിംഗ്സ് മോഡൽ സ്വയമേവ തിരഞ്ഞെടുക്കപ്പെടുന്നു. - തെരഞ്ഞെടുക്കുക ഒരു പുതിയ വെക്റ്റർ സ്റ്റോർ വേഗത്തിൽ സൃഷ്ടിക്കുക.
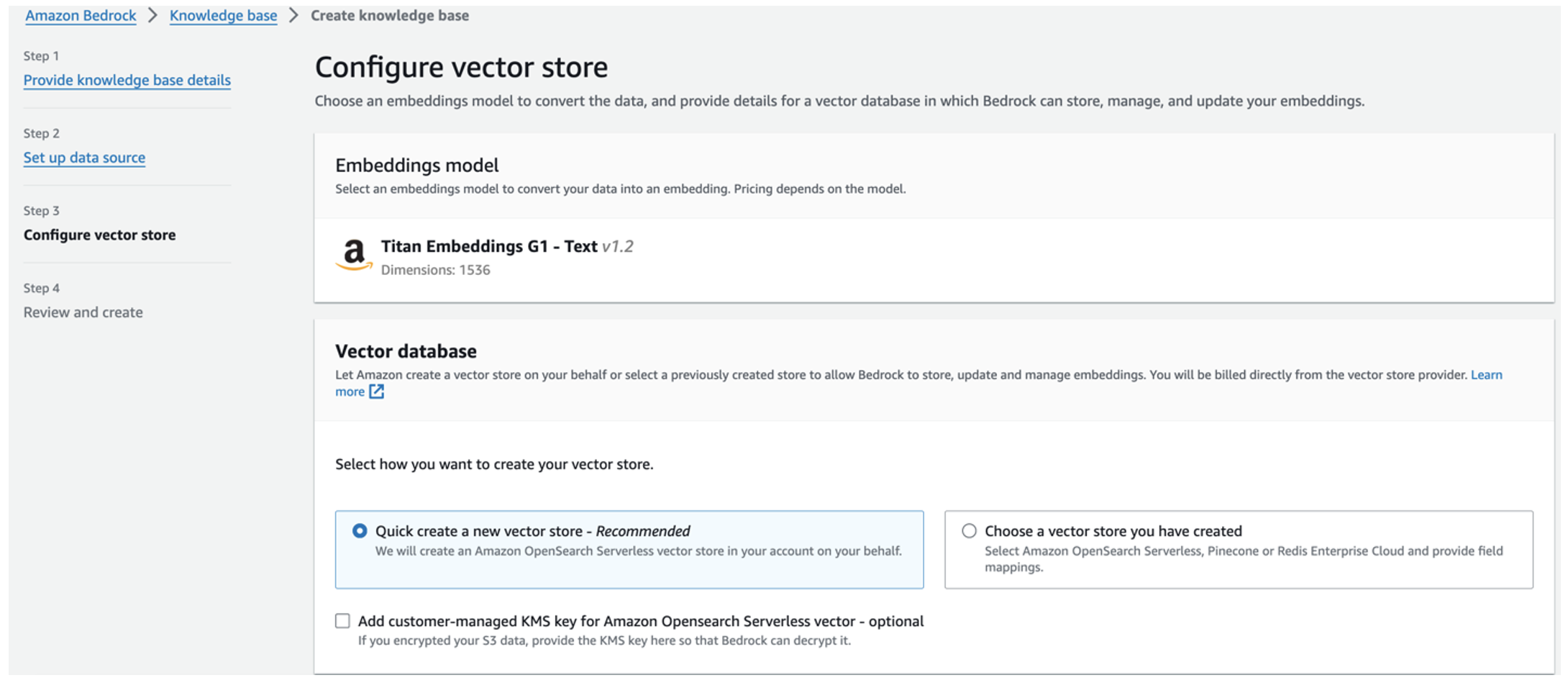
- തിരഞ്ഞെടുക്കുന്നതിലൂടെ നിങ്ങളുടെ ക്രമീകരണങ്ങൾ അവലോകനം ചെയ്ത് വിജ്ഞാന അടിത്തറ സൃഷ്ടിക്കുക വിജ്ഞാന അടിത്തറ ഉണ്ടാക്കുക.
- വിജ്ഞാന അടിത്തറ വിജയകരമായി സൃഷ്ടിച്ച ശേഷം, തിരഞ്ഞെടുക്കുക സമന്വയം വിജ്ഞാന അടിത്തറയുമായി S3 ബക്കറ്റ് സമന്വയിപ്പിക്കാൻ.

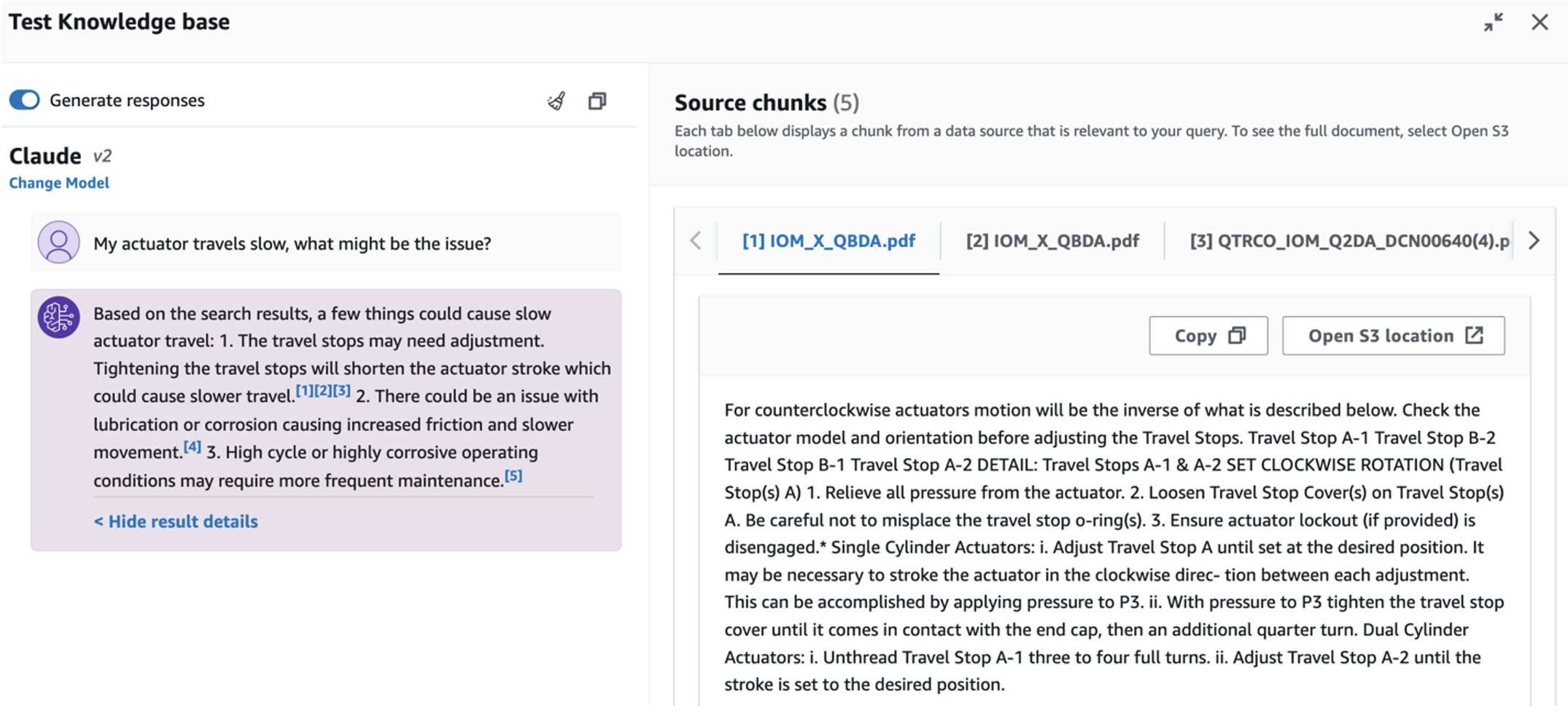
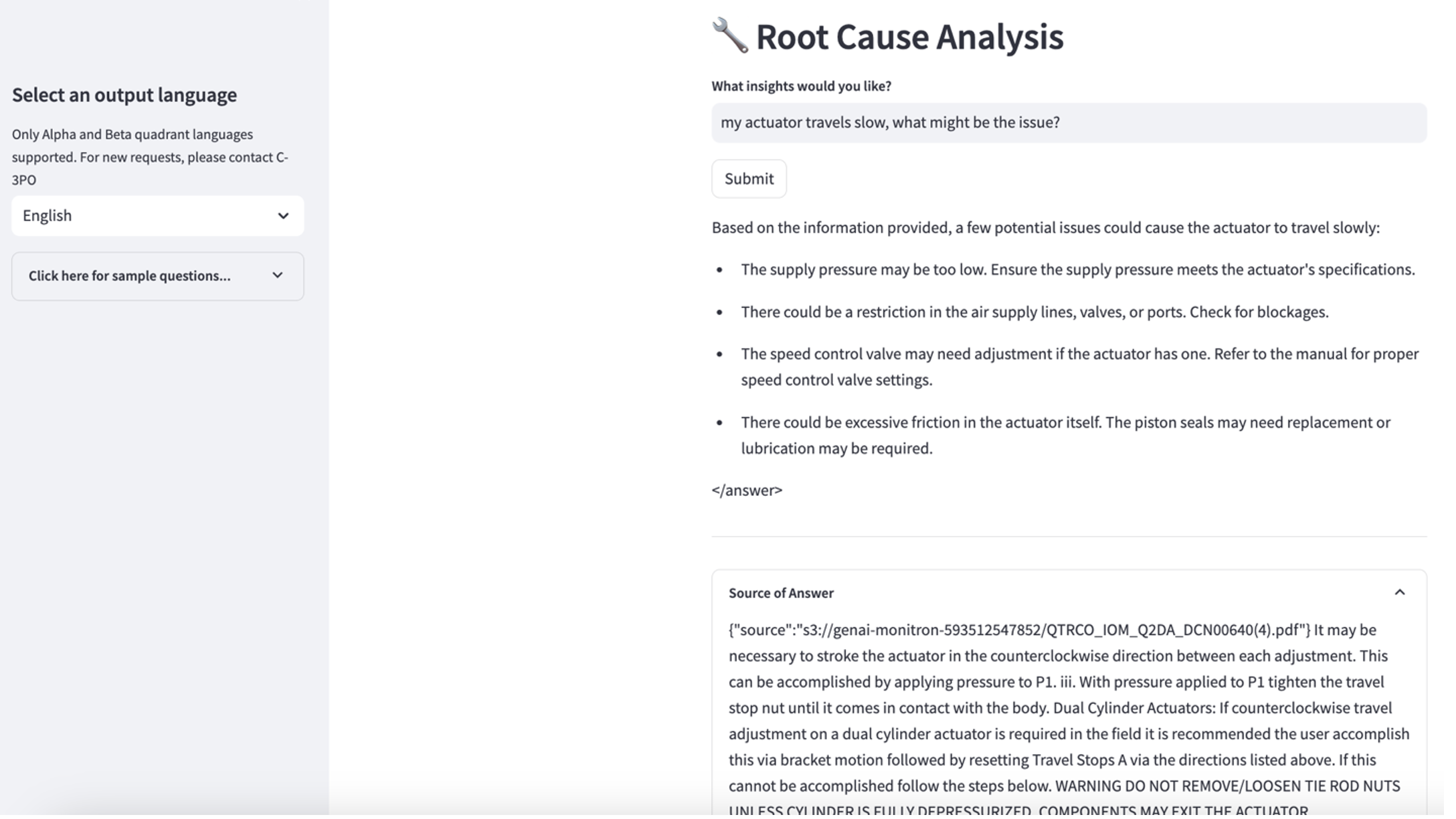
- നിങ്ങൾ വിജ്ഞാന അടിത്തറ സജ്ജീകരിച്ച ശേഷം, "എൻ്റെ ആക്യുവേറ്റർ പതുക്കെ സഞ്ചരിക്കുന്നു, എന്തായിരിക്കാം പ്രശ്നം?" എന്നതുപോലുള്ള ചോദ്യങ്ങൾ ചോദിച്ച് മൂലകാരണ രോഗനിർണ്ണയത്തിനുള്ള RAG സമീപനം നിങ്ങൾക്ക് പരിശോധിക്കാം.
നിങ്ങളുടെ പിസിയിലോ EC2 ഇൻസ്റ്റൻസിലോ (ഉബുണ്ടു സെർവർ 22.04 LTS) ആവശ്യമായ ലൈബ്രറി പാക്കേജുകൾ ഉപയോഗിച്ച് ആപ്പ് വിന്യസിക്കുക എന്നതാണ് അടുത്ത ഘട്ടം.
- നിങ്ങളുടെ AWS ക്രെഡൻഷ്യലുകൾ സജ്ജീകരിക്കുക നിങ്ങളുടെ പ്രാദേശിക പിസിയിൽ AWS CLI ഉപയോഗിച്ച്. ലാളിത്യത്തിനായി, ക്ലൗഡ് ഫോർമേഷൻ സ്റ്റാക്ക് വിന്യസിക്കാൻ നിങ്ങൾ ഉപയോഗിച്ച അതേ അഡ്മിൻ റോൾ നിങ്ങൾക്ക് ഉപയോഗിക്കാം. നിങ്ങൾ Amazon EC2 ഉപയോഗിക്കുകയാണെങ്കിൽ, ഉദാഹരണത്തിലേക്ക് അനുയോജ്യമായ ഒരു IAM റോൾ അറ്റാച്ചുചെയ്യുക.
- ക്ലോൺ ഗിറ്റ്ഹബ് റെപ്പോ:
- എന്നതിലേക്ക് ഡയറക്ടറി മാറ്റുക
unlocking-the-potential-of-generative-ai-in-industrial-operations/srcഒപ്പം പ്രവർത്തിപ്പിക്കുകsetup.shLangChain, PandasAI എന്നിവയുൾപ്പെടെ ആവശ്യമായ പാക്കേജുകൾ ഇൻസ്റ്റാൾ ചെയ്യാൻ ഈ ഫോൾഡറിൽ സ്ക്രിപ്റ്റ് ചെയ്യുക:cd unlocking-the-potential-of-generative-ai-in-industrial-operations/src chmod +x ./setup.sh ./setup.sh - ഇനിപ്പറയുന്ന കമാൻഡ് ഉപയോഗിച്ച് സ്ട്രീംലിറ്റ് അപ്ലിക്കേഷൻ പ്രവർത്തിപ്പിക്കുക:
source monitron-genai/bin/activate python3 -m streamlit run app_bedrock.py <REPLACE WITH YOUR BEDROCK KNOWLEDGEBASE ARN>
മുമ്പത്തെ ഘട്ടത്തിൽ നിന്ന് ആമസോൺ ബെഡ്റോക്കിൽ നിങ്ങൾ സൃഷ്ടിച്ച OpenSearch സേവന ശേഖരം ARN നൽകുക.
നിങ്ങളുടെ അസറ്റ് ഹെൽത്ത് അസിസ്റ്റൻ്റുമായി ചാറ്റ് ചെയ്യുക
നിങ്ങൾ എൻഡ്-ടു-എൻഡ് വിന്യാസം പൂർത്തിയാക്കിയ ശേഷം, പോർട്ട് 8501-ലെ ലോക്കൽ ഹോസ്റ്റ് വഴി നിങ്ങൾക്ക് ആപ്പ് ആക്സസ് ചെയ്യാൻ കഴിയും, അത് വെബ് ഇൻ്റർഫേസുള്ള ഒരു ബ്രൗസർ വിൻഡോ തുറക്കുന്നു. നിങ്ങൾ ഒരു EC2 ഉദാഹരണത്തിൽ ആപ്പ് വിന്യസിച്ചിട്ടുണ്ടെങ്കിൽ, സുരക്ഷാ ഗ്രൂപ്പ് ഇൻബൗണ്ട് റൂൾ വഴി പോർട്ട് 8501 ആക്സസ് അനുവദിക്കുക. വിവിധ ഉപയോഗ കേസുകൾക്കായി നിങ്ങൾക്ക് വ്യത്യസ്ത ടാബുകളിലേക്ക് നാവിഗേറ്റ് ചെയ്യാം.
ഉപയോഗ കേസ് 1 പര്യവേക്ഷണം ചെയ്യുക
ആദ്യ ഉപയോഗ കേസ് പര്യവേക്ഷണം ചെയ്യാൻ, തിരഞ്ഞെടുക്കുക ഡാറ്റ ഇൻസൈറ്റും ചാർട്ടും. നിങ്ങളുടെ സമയ ശ്രേണി ഡാറ്റ അപ്ലോഡ് ചെയ്തുകൊണ്ട് ആരംഭിക്കുക. നിങ്ങൾക്ക് ഉപയോഗിക്കുന്നതിന് നിലവിൽ ഒരു സമയ ശ്രേണി ഡാറ്റ ഫയൽ ഇല്ലെങ്കിൽ, നിങ്ങൾക്ക് ഇനിപ്പറയുന്നവ അപ്ലോഡ് ചെയ്യാം സാമ്പിൾ CSV ഫയൽ അജ്ഞാത ആമസോൺ മോണിട്രോൺ പ്രോജക്റ്റ് ഡാറ്റയോടൊപ്പം. നിങ്ങൾക്ക് ഇതിനകം ഒരു ആമസോൺ മോണിട്രോൺ പ്രോജക്റ്റ് ഉണ്ടെങ്കിൽ, റഫർ ചെയ്യുക ആമസോൺ മോണിട്രോൺ, ആമസോൺ കൈനിസിസ് എന്നിവ ഉപയോഗിച്ച് പ്രവചനാത്മക പരിപാലന മാനേജ്മെന്റിനായി പ്രവർത്തനക്ഷമമായ സ്ഥിതിവിവരക്കണക്കുകൾ സൃഷ്ടിക്കുക നിങ്ങളുടെ ആമസോൺ മോണിട്രോൺ ഡാറ്റ ആമസോൺ എസ് 3-ലേക്ക് സ്ട്രീം ചെയ്യാനും ഈ ആപ്ലിക്കേഷനിൽ നിങ്ങളുടെ ഡാറ്റ ഉപയോഗിക്കാനും.
അപ്ലോഡ് പൂർത്തിയാകുമ്പോൾ, നിങ്ങളുടെ ഡാറ്റയുമായി ഒരു സംഭാഷണം ആരംഭിക്കാൻ ഒരു ചോദ്യം നൽകുക. ഇടത് സൈഡ്ബാർ നിങ്ങളുടെ സൗകര്യത്തിനായി നിരവധി ഉദാഹരണ ചോദ്യങ്ങൾ വാഗ്ദാനം ചെയ്യുന്നു. ഇനിപ്പറയുന്ന സ്ക്രീൻഷോട്ടുകൾ, “യഥാക്രമം മുന്നറിയിപ്പ് അല്ലെങ്കിൽ അലാറമായി കാണിച്ചിരിക്കുന്ന ഓരോ സൈറ്റിനും തനതായ സെൻസറുകളുടെ എണ്ണം പറയൂ?” പോലുള്ള ഒരു ചോദ്യം ഇൻപുട്ട് ചെയ്യുമ്പോൾ FM സൃഷ്ടിച്ച പ്രതികരണവും പൈത്തൺ കോഡും വ്യക്തമാക്കുന്നു. (ഒരു ഹാർഡ്-ലെവൽ ചോദ്യം) അല്ലെങ്കിൽ "ആരോഗ്യകരമല്ലാത്ത താപനില സിഗ്നൽ കാണിക്കുന്ന സെൻസറുകൾക്ക്, അസാധാരണമായ വൈബ്രേഷൻ സിഗ്നൽ കാണിക്കുന്ന ഓരോ സെൻസറിനും ദിവസങ്ങളിൽ സമയദൈർഘ്യം കണക്കാക്കാമോ?" (ഒരു വെല്ലുവിളി തലത്തിലുള്ള ചോദ്യം). ആപ്പ് നിങ്ങളുടെ ചോദ്യത്തിന് ഉത്തരം നൽകും, കൂടാതെ അത്തരം ഫലങ്ങൾ സൃഷ്ടിക്കുന്നതിന് അത് നടത്തിയ ഡാറ്റ വിശകലനത്തിൻ്റെ പൈത്തൺ സ്ക്രിപ്റ്റും കാണിക്കും.


ഉത്തരത്തിൽ നിങ്ങൾ തൃപ്തനാണെങ്കിൽ, നിങ്ങൾക്കത് ഇതായി അടയാളപ്പെടുത്താം സഹായകമായ, ഒരു ഓപ്പൺ സെർച്ച് സേവന സൂചികയിലേക്ക് NLQ, ക്ലോഡ് സൃഷ്ടിച്ച പൈത്തൺ കോഡ് സംരക്ഷിക്കുന്നു.

ഉപയോഗ കേസ് 2 പര്യവേക്ഷണം ചെയ്യുക
രണ്ടാമത്തെ ഉപയോഗ കേസ് പര്യവേക്ഷണം ചെയ്യാൻ, തിരഞ്ഞെടുക്കുക പകർത്തിയ ചിത്ര സംഗ്രഹം സ്ട്രീംലിറ്റ് ആപ്പിലെ ടാബ്. നിങ്ങളുടെ വ്യാവസായിക അസറ്റിൻ്റെ ഒരു ചിത്രം നിങ്ങൾക്ക് അപ്ലോഡ് ചെയ്യാൻ കഴിയും, കൂടാതെ ഇമേജ് വിവരങ്ങളെ അടിസ്ഥാനമാക്കി ആപ്ലിക്കേഷൻ അതിൻ്റെ സാങ്കേതിക സവിശേഷതയുടെയും പ്രവർത്തന അവസ്ഥയുടെയും 200-വാക്കുകളുടെ സംഗ്രഹം സൃഷ്ടിക്കും. താഴെയുള്ള സ്ക്രീൻഷോട്ട് ഒരു ബെൽറ്റ് മോട്ടോർ ഡ്രൈവിൻ്റെ ഇമേജിൽ നിന്ന് സൃഷ്ടിച്ച സംഗ്രഹം കാണിക്കുന്നു. ഈ സവിശേഷത പരിശോധിക്കുന്നതിന്, നിങ്ങൾക്ക് അനുയോജ്യമായ ഒരു ഇമേജ് ഇല്ലെങ്കിൽ, നിങ്ങൾക്ക് ഇനിപ്പറയുന്നവ ഉപയോഗിക്കാം ഉദാഹരണ ചിത്രം.
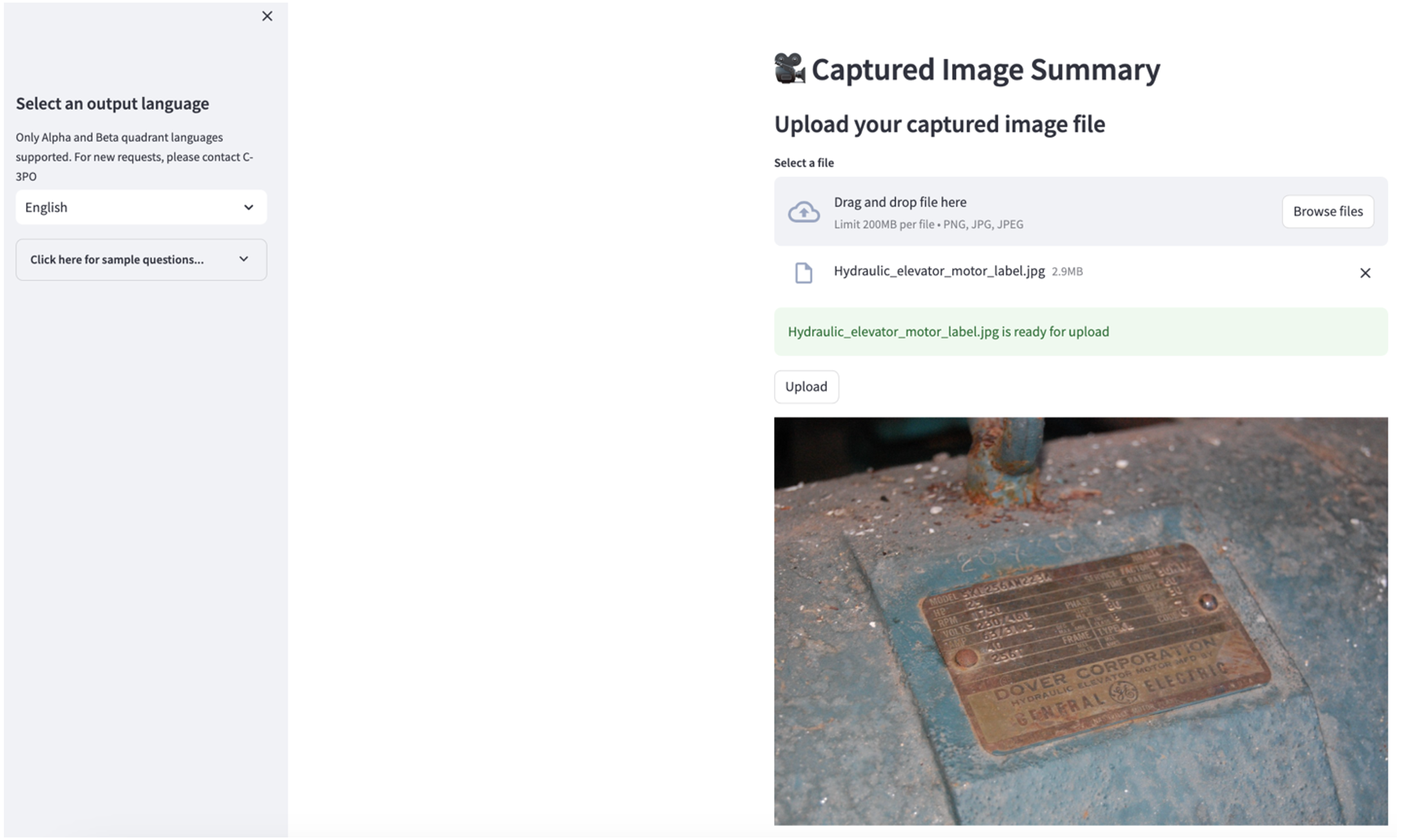
ഹൈഡ്രോളിക് എലിവേറ്റർ മോട്ടോർ ലേബൽ"ക്ലാരൻസ് റിഷറിൻ്റെ കീഴിൽ ലൈസൻസ് ഉണ്ട് ബൈ-എസ്.എ ക്സനുമ്ക്സ.

ഉപയോഗ കേസ് 3 പര്യവേക്ഷണം ചെയ്യുക
മൂന്നാമത്തെ ഉപയോഗ കേസ് പര്യവേക്ഷണം ചെയ്യാൻ, തിരഞ്ഞെടുക്കുക മൂലകാരണ രോഗനിർണയം ടാബ്. നിങ്ങളുടെ തകർന്ന വ്യാവസായിക അസറ്റുമായി ബന്ധപ്പെട്ട ഒരു ചോദ്യം നൽകുക, ഉദാഹരണത്തിന്, "എൻ്റെ ആക്യുവേറ്റർ പതുക്കെ സഞ്ചരിക്കുന്നു, എന്തായിരിക്കാം പ്രശ്നം?" ഇനിപ്പറയുന്ന സ്ക്രീൻഷോട്ടിൽ ചിത്രീകരിച്ചിരിക്കുന്നതുപോലെ, ഉത്തരം സൃഷ്ടിക്കാൻ ഉപയോഗിക്കുന്ന ഉറവിട ഡോക്യുമെൻ്റ് ഉദ്ധരണിക്കൊപ്പം ആപ്ലിക്കേഷൻ ഒരു പ്രതികരണം നൽകുന്നു.
കേസ് 1 ഉപയോഗിക്കുക: ഡിസൈൻ വിശദാംശങ്ങൾ
ഈ വിഭാഗത്തിൽ, ആദ്യ ഉപയോഗ കേസിനായുള്ള ആപ്ലിക്കേഷൻ വർക്ക്ഫ്ലോയുടെ ഡിസൈൻ വിശദാംശങ്ങൾ ഞങ്ങൾ ചർച്ച ചെയ്യുന്നു.
കസ്റ്റം പ്രോംപ്റ്റ് കെട്ടിടം
ഉപയോക്താവിൻ്റെ സ്വാഭാവിക ഭാഷാ അന്വേഷണത്തിന് വ്യത്യസ്ത ബുദ്ധിമുട്ടുള്ള തലങ്ങളുണ്ട്: എളുപ്പവും കഠിനവും വെല്ലുവിളിയും.
നേരായ ചോദ്യങ്ങളിൽ ഇനിപ്പറയുന്ന അഭ്യർത്ഥനകൾ ഉൾപ്പെട്ടേക്കാം:
- അദ്വിതീയ മൂല്യങ്ങൾ തിരഞ്ഞെടുക്കുക
- മൊത്തം സംഖ്യകൾ എണ്ണുക
- മൂല്യങ്ങൾ അടുക്കുക
ഈ ചോദ്യങ്ങൾക്ക്, പ്രോസസ്സിംഗിനായി പൈത്തൺ സ്ക്രിപ്റ്റുകൾ സൃഷ്ടിക്കുന്നതിന് PandasAI-ക്ക് FM-മായി നേരിട്ട് സംവദിക്കാൻ കഴിയും.
കഠിനമായ ചോദ്യങ്ങൾക്ക് അടിസ്ഥാന അഗ്രഗേഷൻ ഓപ്പറേഷൻ അല്ലെങ്കിൽ ടൈം സീരീസ് വിശകലനം ആവശ്യമാണ്, ഇനിപ്പറയുന്നവ:
- ആദ്യം മൂല്യം തിരഞ്ഞെടുക്കുക, ശ്രേണിയിൽ ഫലങ്ങൾ ഗ്രൂപ്പ് ചെയ്യുക
- പ്രാരംഭ റെക്കോർഡ് തിരഞ്ഞെടുപ്പിന് ശേഷം സ്ഥിതിവിവരക്കണക്കുകൾ നടത്തുക
- ടൈംസ്റ്റാമ്പ് എണ്ണം (ഉദാഹരണത്തിന്, മിനിറ്റും പരമാവധി)
കഠിനമായ ചോദ്യങ്ങൾക്ക്, കൃത്യമായ പ്രതികരണങ്ങൾ നൽകുന്നതിന് വിശദമായ ഘട്ടം ഘട്ടമായുള്ള നിർദ്ദേശങ്ങളുള്ള ഒരു പ്രോംപ്റ്റ് ടെംപ്ലേറ്റ് FM-കളെ സഹായിക്കുന്നു.
ചലഞ്ച്-ലെവൽ ചോദ്യങ്ങൾക്ക് ഇനിപ്പറയുന്നവ പോലുള്ള വിപുലമായ ഗണിത കണക്കുകൂട്ടലും സമയ ശ്രേണി പ്രോസസ്സിംഗും ആവശ്യമാണ്:
- ഓരോ സെൻസറിനും അനോമലി ദൈർഘ്യം കണക്കാക്കുക
- സൈറ്റിനായുള്ള അനോമലി സെൻസറുകൾ പ്രതിമാസ അടിസ്ഥാനത്തിൽ കണക്കാക്കുക
- സാധാരണ പ്രവർത്തനത്തിലും അസാധാരണ സാഹചര്യങ്ങളിലും സെൻസർ റീഡിംഗുകൾ താരതമ്യം ചെയ്യുക
ഈ ചോദ്യങ്ങൾക്ക്, പ്രതികരണ കൃത്യത വർദ്ധിപ്പിക്കുന്നതിന് നിങ്ങൾക്ക് ഇഷ്ടാനുസൃത പ്രോംപ്റ്റിൽ മൾട്ടി-ഷോട്ടുകൾ ഉപയോഗിക്കാം. അത്തരം മൾട്ടി-ഷോട്ടുകൾ അഡ്വാൻസ്ഡ് ടൈം സീരീസ് പ്രോസസ്സിംഗിൻ്റെയും ഗണിത കണക്കുകൂട്ടലിൻ്റെയും ഉദാഹരണങ്ങൾ കാണിക്കുന്നു, കൂടാതെ സമാനമായ വിശകലനത്തിൽ പ്രസക്തമായ അനുമാനം നടത്താൻ FM-ന് സന്ദർഭം നൽകും. ഒരു NLQ ചോദ്യ ബാങ്കിൽ നിന്നുള്ള ഏറ്റവും പ്രസക്തമായ ഉദാഹരണങ്ങൾ പ്രോംപ്റ്റിലേക്ക് ചലനാത്മകമായി ചേർക്കുന്നത് ഒരു വെല്ലുവിളിയാണ്. നിലവിലുള്ള NLQ ചോദ്യ സാമ്പിളുകളിൽ നിന്ന് ഉൾച്ചേർക്കലുകൾ നിർമ്മിക്കുകയും OpenSearch Service പോലെയുള്ള ഒരു വെക്റ്റർ സ്റ്റോറിൽ ഈ എംബെഡ്ഡിംഗുകൾ സംരക്ഷിക്കുകയും ചെയ്യുക എന്നതാണ് ഒരു പരിഹാരം. സ്ട്രീംലിറ്റ് ആപ്പിലേക്ക് ഒരു ചോദ്യം അയയ്ക്കുമ്പോൾ, ചോദ്യം വെക്ടറൈസ് ചെയ്യപ്പെടും ബെഡ്റോക്ക് എംബെഡിംഗുകൾ. ആ ചോദ്യത്തിന് ഏറ്റവും പ്രസക്തമായ എൻ-ബെഡ്ഡിംഗുകൾ ഉപയോഗിച്ചാണ് വീണ്ടെടുക്കുന്നത് opensearch_vector_search.similarity_search ഒരു മൾട്ടി-ഷോട്ട് പ്രോംപ്റ്റ് ആയി പ്രോംപ്റ്റ് ടെംപ്ലേറ്റിൽ ചേർത്തു.
ഇനിപ്പറയുന്ന ഡയഗ്രം ഈ വർക്ക്ഫ്ലോ വ്യക്തമാക്കുന്നു.
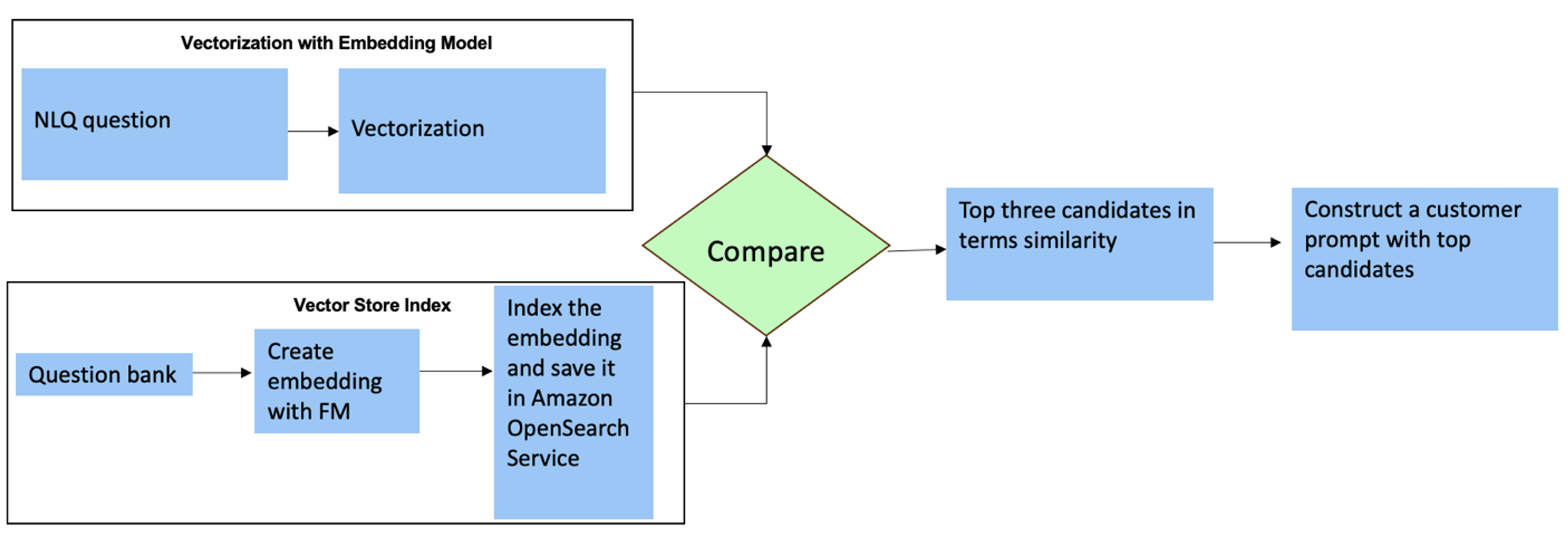
മൂന്ന് പ്രധാന ഉപകരണങ്ങൾ ഉപയോഗിച്ചാണ് ഉൾച്ചേർക്കൽ പാളി നിർമ്മിച്ചിരിക്കുന്നത്:
- ഉൾച്ചേർക്കൽ മോഡൽ - ഞങ്ങൾ ആമസോൺ ബെഡ്റോക്കിലൂടെ ലഭ്യമായ ആമസോൺ ടൈറ്റൻ എംബഡ്ഡിംഗുകൾ ഉപയോഗിക്കുന്നു (amazon.titan-embed-text-v1) വാചക പ്രമാണങ്ങളുടെ സംഖ്യാ പ്രാതിനിധ്യം സൃഷ്ടിക്കുന്നതിന്.
- വെക്റ്റർ സ്റ്റോർ - ഞങ്ങളുടെ വെക്റ്റർ സ്റ്റോറിനായി, ഈ നോട്ട്ബുക്കിലെ NLQ ഉദാഹരണങ്ങളിൽ നിന്ന് ജനറേറ്റുചെയ്ത എംബെഡിംഗുകളുടെ സംഭരണം കാര്യക്ഷമമാക്കിക്കൊണ്ട്, LangChain ചട്ടക്കൂട് വഴി ഞങ്ങൾ OpenSearch സേവനം ഉപയോഗിക്കുന്നു.
- സൂചിക – ഇൻപുട്ട് എംബെഡിംഗുകളെ ഡോക്യുമെൻ്റ് എംബെഡിംഗുകളുമായി താരതമ്യപ്പെടുത്തുന്നതിലും പ്രസക്തമായ ഡോക്യുമെൻ്റുകൾ വീണ്ടെടുക്കുന്നതിലും ഓപ്പൺസെർച്ച് സേവന സൂചിക ഒരു പ്രധാന പങ്ക് വഹിക്കുന്നു. പൈത്തൺ ഉദാഹരണ കോഡുകൾ ഒരു JSON ഫയലായി സംരക്ഷിച്ചതിനാൽ, അവ ഓപ്പൺ സെർച്ച് സേവനത്തിൽ വെക്റ്ററുകളായി സൂചികയിലാക്കി OpenSearchVevtorSearch.fromtexts API കോൾ.
സ്ട്രീംലിറ്റ് വഴി മനുഷ്യൻ ഓഡിറ്റ് ചെയ്ത ഉദാഹരണങ്ങളുടെ തുടർച്ചയായ ശേഖരണം
ആപ്പ് ഡെവലപ്മെൻ്റിൻ്റെ തുടക്കത്തിൽ, എംബെഡിംഗുകളായി ഓപ്പൺ സെർച്ച് സേവന സൂചികയിൽ സംരക്ഷിച്ച 23 ഉദാഹരണങ്ങൾ മാത്രം ഉപയോഗിച്ചാണ് ഞങ്ങൾ ആരംഭിച്ചത്. ആപ്പ് ഫീൽഡിൽ സജീവമാകുമ്പോൾ, ഉപയോക്താക്കൾ അവരുടെ NLQ-കൾ ആപ്പ് വഴി ഇൻപുട്ട് ചെയ്യാൻ തുടങ്ങുന്നു. എന്നിരുന്നാലും, ടെംപ്ലേറ്റിൽ ലഭ്യമായ പരിമിതമായ ഉദാഹരണങ്ങൾ കാരണം, ചില NLQ-കൾ സമാനമായ നിർദ്ദേശങ്ങൾ കണ്ടെത്തിയേക്കില്ല. ഈ ഉൾച്ചേർക്കലുകൾ തുടർച്ചയായി സമ്പുഷ്ടമാക്കാനും കൂടുതൽ പ്രസക്തമായ ഉപയോക്തൃ നിർദ്ദേശങ്ങൾ നൽകാനും, മനുഷ്യൻ ഓഡിറ്റ് ചെയ്ത ഉദാഹരണങ്ങൾ ശേഖരിക്കുന്നതിന് നിങ്ങൾക്ക് സ്ട്രീംലിറ്റ് ആപ്പ് ഉപയോഗിക്കാം.
ആപ്പിനുള്ളിൽ, ഇനിപ്പറയുന്ന ഫംഗ്ഷൻ ഈ ആവശ്യത്തിനായി പ്രവർത്തിക്കുന്നു. അന്തിമ ഉപയോക്താക്കൾക്ക് ഔട്ട്പുട്ട് സഹായകരമാണെന്ന് കണ്ടെത്തി തിരഞ്ഞെടുക്കുക സഹായകമായ, ആപ്ലിക്കേഷൻ ഈ ഘട്ടങ്ങൾ പാലിക്കുന്നു:
- പൈത്തൺ സ്ക്രിപ്റ്റ് ശേഖരിക്കാൻ PandasAI-ൽ നിന്നുള്ള കോൾബാക്ക് രീതി ഉപയോഗിക്കുക.
- പൈത്തൺ സ്ക്രിപ്റ്റ്, ഇൻപുട്ട് ചോദ്യം, CSV മെറ്റാഡാറ്റ എന്നിവ ഒരു സ്ട്രിംഗിലേക്ക് റീഫോർമാറ്റ് ചെയ്യുക.
- നിലവിലുള്ള OpenSearch സേവന സൂചികയിൽ ഈ NLQ ഉദാഹരണം നിലവിലുണ്ടോയെന്ന് പരിശോധിക്കുക opensearch_vector_search.simarity_search_with_score.
- സമാനമായ ഉദാഹരണം ഇല്ലെങ്കിൽ, ഈ NLQ ഉപയോഗിച്ച് OpenSearch സേവന സൂചികയിലേക്ക് ചേർക്കും opensearch_vector_search.add_texts.
ഒരു ഉപയോക്താവ് തിരഞ്ഞെടുക്കുന്ന സാഹചര്യത്തിൽ സഹായകരമല്ല, ഒരു നടപടിയും എടുക്കുന്നില്ല. ഉപയോക്താക്കൾ സംഭാവന ചെയ്ത ഉദാഹരണങ്ങൾ ഉൾപ്പെടുത്തി സിസ്റ്റം തുടർച്ചയായി മെച്ചപ്പെടുത്തുന്നുവെന്ന് ഈ ആവർത്തന പ്രക്രിയ ഉറപ്പാക്കുന്നു.
def addtext_opensearch(input_question, generated_chat_code, df_column_metadata, opensearch_vector_search,similarity_threshold,kexamples, indexname):
#######build the input_question and generated code the same format as existing opensearch index##########
reconstructed_json = {}
reconstructed_json["question"]=input_question
reconstructed_json["python_code"]=str(generated_chat_code)
reconstructed_json["column_info"]=df_column_metadata
json_str = ''
for key,value in reconstructed_json.items():
json_str += key + ':' + value
reconstructed_raw_text =[]
reconstructed_raw_text.append(json_str)
results = opensearch_vector_search.similarity_search_with_score(str(reconstructed_raw_text[0]), k=kexamples) # our search query # return 3 most relevant docs
if (dumpd(results[0][1])<similarity_threshold): ###No similar embedding exist, then add text to embedding
response = opensearch_vector_search.add_texts(texts=reconstructed_raw_text, engine="faiss", index_name=indexname)
else:
response = "A similar embedding is already exist, no action."
return response
ഹ്യൂമൻ ഓഡിറ്റിംഗ് സംയോജിപ്പിക്കുന്നതിലൂടെ, ആപ്പ് ഉപയോഗം വർദ്ധിക്കുന്നതിനനുസരിച്ച്, ഓപ്പൺ സെർച്ച് സേവനത്തിലെ ഉദാഹരണങ്ങളുടെ അളവ് വേഗത്തിൽ ഉൾച്ചേർക്കുന്നതിന് ലഭ്യമാണ്. ഈ വിപുലീകരിച്ച എംബെഡിംഗ് ഡാറ്റാസെറ്റ് കാലക്രമേണ മെച്ചപ്പെടുത്തിയ തിരയൽ കൃത്യതയിൽ കലാശിക്കുന്നു. പ്രത്യേകിച്ചും, NLQ-കളെ വെല്ലുവിളിക്കുന്നതിന്, ഓരോ NLQ ചോദ്യത്തിനും ഇഷ്ടാനുസൃത നിർദ്ദേശങ്ങൾ നിർമ്മിക്കുന്നതിന് സമാനമായ ഉദാഹരണങ്ങൾ ചലനാത്മകമായി ചേർക്കുമ്പോൾ FM-ൻ്റെ പ്രതികരണ കൃത്യത ഏകദേശം 90% വരെ എത്തുന്നു. മൾട്ടി-ഷോട്ട് പ്രോംപ്റ്റുകളില്ലാത്ത സാഹചര്യങ്ങളുമായി താരതമ്യപ്പെടുത്തുമ്പോൾ ഇത് ശ്രദ്ധേയമായ 28% വർദ്ധനവിനെ പ്രതിനിധീകരിക്കുന്നു.
കേസ് 2 ഉപയോഗിക്കുക: ഡിസൈൻ വിശദാംശങ്ങൾ
സ്ട്രീംലിറ്റ് ആപ്പിൽ പകർത്തിയ ചിത്ര സംഗ്രഹം ടാബ്, നിങ്ങൾക്ക് നേരിട്ട് ഒരു ഇമേജ് ഫയൽ അപ്ലോഡ് ചെയ്യാൻ കഴിയും. ഇത് ആമസോൺ റെക്കഗ്നിഷൻ API ആരംഭിക്കുന്നു (ഡിറ്റെക്സ്റ്റ്_ടെക്സ്റ്റ് API), മെഷീൻ സ്പെസിഫിക്കേഷനുകൾ വിശദമാക്കുന്ന ഇമേജ് ലേബലിൽ നിന്ന് ടെക്സ്റ്റ് എക്സ്ട്രാക്റ്റുചെയ്യുന്നു. തുടർന്ന്, എക്സ്ട്രാക്റ്റ് ചെയ്ത ടെക്സ്റ്റ് ഡാറ്റ ഒരു പ്രോംപ്റ്റിൻ്റെ സന്ദർഭമായി ആമസോൺ ബെഡ്റോക്ക് ക്ലോഡ് മോഡലിലേക്ക് അയയ്ക്കുന്നു, അതിൻ്റെ ഫലമായി 200-വാക്കുകളുടെ സംഗ്രഹം ലഭിക്കും.
ഒരു ഉപയോക്തൃ അനുഭവ വീക്ഷണകോണിൽ, ഒരു ടെക്സ്റ്റ് സംഗ്രഹം ടാസ്ക്കിനായി സ്ട്രീമിംഗ് പ്രവർത്തനക്ഷമത പ്രാപ്തമാക്കുന്നത് പരമപ്രധാനമാണ്, മുഴുവൻ ഔട്ട്പുട്ടിനായി കാത്തിരിക്കുന്നതിനുപകരം FM സൃഷ്ടിച്ച സംഗ്രഹം ചെറിയ ഭാഗങ്ങളായി വായിക്കാൻ ഉപയോക്താക്കളെ അനുവദിക്കുന്നു. ആമസോൺ ബെഡ്റോക്ക് അതിൻ്റെ API വഴി സ്ട്രീമിംഗ് സുഗമമാക്കുന്നു (bedrock_runtime.invoke_model_with_response_stream).
കേസ് 3 ഉപയോഗിക്കുക: ഡിസൈൻ വിശദാംശങ്ങൾ
ഈ സാഹചര്യത്തിൽ, RAG സമീപനം ഉപയോഗിച്ച്, മൂലകാരണ വിശകലനത്തിൽ ശ്രദ്ധ കേന്ദ്രീകരിച്ച് ഞങ്ങൾ ഒരു ചാറ്റ്ബോട്ട് ആപ്ലിക്കേഷൻ വികസിപ്പിച്ചിട്ടുണ്ട്. മൂലകാരണ വിശകലനം സുഗമമാക്കുന്നതിന് ബെയറിംഗ് ഉപകരണങ്ങളുമായി ബന്ധപ്പെട്ട ഒന്നിലധികം രേഖകളിൽ നിന്ന് ഈ ചാറ്റ്ബോട്ട് എടുക്കുന്നു. ഈ RAG-അധിഷ്ഠിത മൂലകാരണ വിശകലന ചാറ്റ്ബോട്ട് വെക്റ്റർ ടെക്സ്റ്റ് പ്രാതിനിധ്യം അല്ലെങ്കിൽ ഉൾച്ചേർക്കലുകൾ സൃഷ്ടിക്കുന്നതിന് വിജ്ഞാന അടിത്തറകൾ ഉപയോഗിക്കുന്നു. ആമസോൺ ബെഡ്റോക്കിനായുള്ള നോളജ് ബേസുകൾ, ഡാറ്റാ ഉറവിടങ്ങളിലേക്ക് ഇഷ്ടാനുസൃത സംയോജനങ്ങൾ നിർമ്മിക്കുകയോ ഡാറ്റാ ഫ്ലോകളും RAG നടപ്പിലാക്കൽ വിശദാംശങ്ങളും നിയന്ത്രിക്കുകയോ ചെയ്യാതെ, മുഴുവനായും RAG വർക്ക്ഫ്ലോ നടപ്പിലാക്കാൻ നിങ്ങളെ സഹായിക്കുന്ന, ഉൾപ്പെടുത്തൽ മുതൽ വീണ്ടെടുക്കൽ, പ്രോംപ്റ്റ് ഓഗ്മെൻ്റേഷൻ എന്നിവ നടപ്പിലാക്കാൻ നിങ്ങളെ സഹായിക്കുന്നു.
ആമസോൺ ബെഡ്റോക്കിൽ നിന്നുള്ള നോളജ് ബേസ് പ്രതികരണത്തിൽ നിങ്ങൾ തൃപ്തനാകുമ്പോൾ, വിജ്ഞാന അടിത്തറയിൽ നിന്ന് സ്ട്രീംലിറ്റ് ആപ്പിലേക്ക് നിങ്ങൾക്ക് മൂലകാരണ പ്രതികരണം സമന്വയിപ്പിക്കാനാകും.
ക്ലീനപ്പ്
ചെലവ് ലാഭിക്കാൻ, ഈ പോസ്റ്റിൽ നിങ്ങൾ സൃഷ്ടിച്ച ഉറവിടങ്ങൾ ഇല്ലാതാക്കുക:
- ആമസോൺ ബെഡ്റോക്കിൽ നിന്ന് വിജ്ഞാന അടിത്തറ ഇല്ലാതാക്കുക.
- OpenSearch സേവന സൂചിക ഇല്ലാതാക്കുക.
- genai-sagemaker CloudFormation സ്റ്റാക്ക് ഇല്ലാതാക്കുക.
- സ്ട്രീംലിറ്റ് ആപ്പ് പ്രവർത്തിപ്പിക്കാൻ നിങ്ങൾ ഒരു EC2 ഇൻസ്റ്റൻസ് ഉപയോഗിച്ചിട്ടുണ്ടെങ്കിൽ EC2 ഇൻസ്റ്റൻസ് നിർത്തുക.
തീരുമാനം
ജനറേറ്റീവ് AI ആപ്ലിക്കേഷനുകൾ ഇതിനകം തന്നെ വിവിധ ബിസിനസ്സ് പ്രക്രിയകളെ രൂപാന്തരപ്പെടുത്തിയിട്ടുണ്ട്, തൊഴിലാളികളുടെ ഉൽപ്പാദനക്ഷമതയും വൈദഗ്ധ്യവും വർദ്ധിപ്പിക്കുന്നു. എന്നിരുന്നാലും, സമയ ശ്രേണി ഡാറ്റ വിശകലനം കൈകാര്യം ചെയ്യുന്നതിലെ എഫ്എമ്മുകളുടെ പരിമിതികൾ വ്യാവസായിക ക്ലയൻ്റുകളുടെ പൂർണ്ണമായ ഉപയോഗത്തിന് തടസ്സമായി. ദിവസേന പ്രോസസ്സ് ചെയ്യുന്ന പ്രധാന ഡാറ്റാ തരത്തിലേക്ക് ജനറേറ്റീവ് AI യുടെ പ്രയോഗത്തെ ഈ നിയന്ത്രണം തടസ്സപ്പെടുത്തിയിരിക്കുന്നു.
ഈ പോസ്റ്റിൽ, വ്യാവസായിക ഉപയോക്താക്കൾക്കുള്ള ഈ വെല്ലുവിളി ലഘൂകരിക്കാൻ രൂപകൽപ്പന ചെയ്ത ഒരു ജനറേറ്റീവ് AI ആപ്ലിക്കേഷൻ സൊല്യൂഷൻ ഞങ്ങൾ അവതരിപ്പിച്ചു. ഒരു എഫ്എമ്മിൻ്റെ ടൈം സീരീസ് വിശകലന ശേഷി ശക്തിപ്പെടുത്തുന്നതിന് ഈ ആപ്ലിക്കേഷൻ ഒരു ഓപ്പൺ സോഴ്സ് ഏജൻ്റ്, പാണ്ടസ്എഐ ഉപയോഗിക്കുന്നു. സമയ ശ്രേണി ഡാറ്റ നേരിട്ട് എഫ്എമ്മുകളിലേക്ക് അയയ്ക്കുന്നതിനുപകരം, ഘടനാരഹിതമായ സമയ ശ്രേണി ഡാറ്റയുടെ വിശകലനത്തിനായി പൈത്തൺ കോഡ് സൃഷ്ടിക്കാൻ ആപ്പ് പാണ്ടസായിയെ ഉപയോഗിക്കുന്നു. പൈത്തൺ കോഡ് ജനറേഷൻ്റെ കൃത്യത വർദ്ധിപ്പിക്കുന്നതിന്, ഹ്യൂമൻ ഓഡിറ്റിംഗ് ഉള്ള ഒരു കസ്റ്റം പ്രോംപ്റ്റ് ജനറേഷൻ വർക്ക്ഫ്ലോ നടപ്പിലാക്കിയിട്ടുണ്ട്.
അവരുടെ ആസ്തി ആരോഗ്യത്തെക്കുറിച്ചുള്ള ഉൾക്കാഴ്ചകളാൽ ശാക്തീകരിക്കപ്പെട്ട, വ്യാവസായിക തൊഴിലാളികൾക്ക് മൂലകാരണ രോഗനിർണയവും ഭാഗങ്ങൾ മാറ്റിസ്ഥാപിക്കുന്നതിനുള്ള ആസൂത്രണവും ഉൾപ്പെടെ വിവിധ ഉപയോഗ കേസുകളിലുടനീളം ജനറേറ്റീവ് AI യുടെ സാധ്യതകൾ പൂർണ്ണമായും പ്രയോജനപ്പെടുത്താൻ കഴിയും. ആമസോൺ ബെഡ്റോക്കിനായുള്ള നോളജ് ബേസുകൾ ഉപയോഗിച്ച്, ഡെവലപ്പർമാർക്ക് നിർമ്മിക്കാനും നിയന്ത്രിക്കാനും RAG പരിഹാരം ലളിതമാണ്.
എൻ്റർപ്രൈസ് ഡാറ്റ മാനേജ്മെൻ്റിൻ്റെയും പ്രവർത്തനങ്ങളുടെയും പാത, പ്രവർത്തനപരമായ ആരോഗ്യത്തെക്കുറിച്ചുള്ള സമഗ്രമായ ഉൾക്കാഴ്ചകൾക്കായി ജനറേറ്റീവ് AI-യുമായി ആഴത്തിലുള്ള സംയോജനത്തിലേക്ക് നീങ്ങുന്നു. ആമസോൺ ബെഡ്റോക്ക് നേതൃത്വം നൽകുന്ന ഈ മാറ്റം, LLM-കളുടെ വർദ്ധിച്ചുവരുന്ന കരുത്തും സാധ്യതയും കൊണ്ട് ഗണ്യമായി വർദ്ധിപ്പിക്കുന്നു. ആമസോൺ ബെഡ്റോക്ക് ക്ലോഡ് 3 പരിഹാരങ്ങൾ കൂടുതൽ ഉയർത്താൻ. കൂടുതലറിയാൻ, സന്ദർശിക്കുക ആമസോൺ ബെഡ്റോക്ക് ഡോക്യുമെൻ്റേഷൻ, എന്നിവയുമായി കൈകോർക്കുക ആമസോൺ ബെഡ്റോക്ക് വർക്ക്ഷോപ്പ്.
രചയിതാക്കളെക്കുറിച്ച്
 ജൂലിയ ഹു ആമസോൺ വെബ് സേവനങ്ങളിലെ സീനിയർ AI/ML സൊല്യൂഷൻസ് ആർക്കിടെക്റ്റാണ്. അവർ ജനറേറ്റീവ് AI, അപ്ലൈഡ് ഡാറ്റ സയൻസ്, IoT ആർക്കിടെക്ചർ എന്നിവയിൽ വൈദഗ്ദ്ധ്യം നേടിയിട്ടുണ്ട്. നിലവിൽ അവൾ ആമസോൺ ക്യൂ ടീമിൻ്റെ ഭാഗമാണ്, കൂടാതെ മെഷീൻ ലേണിംഗ് ടെക്നിക്കൽ ഫീൽഡ് കമ്മ്യൂണിറ്റിയിലെ സജീവ അംഗം/ഉപദേശകയുമാണ്. AWSome ജനറേറ്റീവ് AI സൊല്യൂഷനുകൾ വികസിപ്പിക്കുന്നതിന്, സ്റ്റാർട്ട്-അപ്പുകൾ മുതൽ സംരംഭങ്ങൾ വരെയുള്ള ഉപഭോക്താക്കളുമായി അവൾ പ്രവർത്തിക്കുന്നു. നൂതന ഡാറ്റ അനലിറ്റിക്സിനായി വലിയ ഭാഷാ മോഡലുകൾ പ്രയോജനപ്പെടുത്തുന്നതിലും യഥാർത്ഥ ലോക വെല്ലുവിളികളെ അഭിമുഖീകരിക്കുന്ന പ്രായോഗിക ആപ്ലിക്കേഷനുകൾ പര്യവേക്ഷണം ചെയ്യുന്നതിലും അവൾക്ക് പ്രത്യേക താൽപ്പര്യമുണ്ട്.
ജൂലിയ ഹു ആമസോൺ വെബ് സേവനങ്ങളിലെ സീനിയർ AI/ML സൊല്യൂഷൻസ് ആർക്കിടെക്റ്റാണ്. അവർ ജനറേറ്റീവ് AI, അപ്ലൈഡ് ഡാറ്റ സയൻസ്, IoT ആർക്കിടെക്ചർ എന്നിവയിൽ വൈദഗ്ദ്ധ്യം നേടിയിട്ടുണ്ട്. നിലവിൽ അവൾ ആമസോൺ ക്യൂ ടീമിൻ്റെ ഭാഗമാണ്, കൂടാതെ മെഷീൻ ലേണിംഗ് ടെക്നിക്കൽ ഫീൽഡ് കമ്മ്യൂണിറ്റിയിലെ സജീവ അംഗം/ഉപദേശകയുമാണ്. AWSome ജനറേറ്റീവ് AI സൊല്യൂഷനുകൾ വികസിപ്പിക്കുന്നതിന്, സ്റ്റാർട്ട്-അപ്പുകൾ മുതൽ സംരംഭങ്ങൾ വരെയുള്ള ഉപഭോക്താക്കളുമായി അവൾ പ്രവർത്തിക്കുന്നു. നൂതന ഡാറ്റ അനലിറ്റിക്സിനായി വലിയ ഭാഷാ മോഡലുകൾ പ്രയോജനപ്പെടുത്തുന്നതിലും യഥാർത്ഥ ലോക വെല്ലുവിളികളെ അഭിമുഖീകരിക്കുന്ന പ്രായോഗിക ആപ്ലിക്കേഷനുകൾ പര്യവേക്ഷണം ചെയ്യുന്നതിലും അവൾക്ക് പ്രത്യേക താൽപ്പര്യമുണ്ട്.
 സുധീഷ് ശശിധരൻ എനർജി ടീമിലെ AWS-ലെ സീനിയർ സൊല്യൂഷൻ ആർക്കിടെക്റ്റാണ്. സങ്കീർണ്ണമായ ബിസിനസ്സ് വെല്ലുവിളികൾ പരിഹരിക്കുന്ന നൂതനമായ സൊല്യൂഷനുകൾ നിർമ്മിക്കാനും പുതിയ സാങ്കേതികവിദ്യകൾ പരീക്ഷിക്കാനും സുധീഷ് ഇഷ്ടപ്പെടുന്നു. അവൻ സൊല്യൂഷനുകൾ രൂപകല്പന ചെയ്യുകയോ ഏറ്റവും പുതിയ സാങ്കേതിക വിദ്യകൾ ഉപയോഗിക്കാതിരിക്കുകയോ ചെയ്യുമ്പോൾ, ടെന്നീസ് കോർട്ടിൽ അവൻ്റെ ബാക്ക്ഹാൻഡിൽ പ്രവർത്തിക്കുന്നുണ്ടെന്ന് നിങ്ങൾക്ക് കണ്ടെത്താനാകും.
സുധീഷ് ശശിധരൻ എനർജി ടീമിലെ AWS-ലെ സീനിയർ സൊല്യൂഷൻ ആർക്കിടെക്റ്റാണ്. സങ്കീർണ്ണമായ ബിസിനസ്സ് വെല്ലുവിളികൾ പരിഹരിക്കുന്ന നൂതനമായ സൊല്യൂഷനുകൾ നിർമ്മിക്കാനും പുതിയ സാങ്കേതികവിദ്യകൾ പരീക്ഷിക്കാനും സുധീഷ് ഇഷ്ടപ്പെടുന്നു. അവൻ സൊല്യൂഷനുകൾ രൂപകല്പന ചെയ്യുകയോ ഏറ്റവും പുതിയ സാങ്കേതിക വിദ്യകൾ ഉപയോഗിക്കാതിരിക്കുകയോ ചെയ്യുമ്പോൾ, ടെന്നീസ് കോർട്ടിൽ അവൻ്റെ ബാക്ക്ഹാൻഡിൽ പ്രവർത്തിക്കുന്നുണ്ടെന്ന് നിങ്ങൾക്ക് കണ്ടെത്താനാകും.
 നീൽ ദേശായി ആർട്ടിഫിഷ്യൽ ഇൻ്റലിജൻസ് (AI), ഡാറ്റാ സയൻസ്, സോഫ്റ്റ്വെയർ എഞ്ചിനീയറിംഗ്, എൻ്റർപ്രൈസ് ആർക്കിടെക്ചർ എന്നിവയിൽ 20 വർഷത്തിലേറെ പരിചയമുള്ള ഒരു ടെക്നോളജി എക്സിക്യൂട്ടീവാണ്. AWS-ൽ, നൂതന ജനറേറ്റീവ് AI- പവർ സൊല്യൂഷനുകൾ നിർമ്മിക്കാനും ഉപഭോക്താക്കളുമായി മികച്ച സമ്പ്രദായങ്ങൾ പങ്കിടാനും ഉൽപ്പന്ന റോഡ്മാപ്പ് ഡ്രൈവ് ചെയ്യാനും ഉപഭോക്താക്കളെ സഹായിക്കുന്ന വേൾഡ് വൈഡ് AI സേവന സ്പെഷ്യലിസ്റ്റ് സൊല്യൂഷൻ ആർക്കിടെക്റ്റുകളുടെ ഒരു ടീമിനെ അദ്ദേഹം നയിക്കുന്നു. വെസ്റ്റാസ്, ഹണിവെൽ, ക്വസ്റ്റ് ഡയഗ്നോസ്റ്റിക്സ് എന്നിവയിലെ തൻ്റെ മുൻ റോളുകളിൽ, കമ്പനികളുടെ പ്രവർത്തനങ്ങൾ മെച്ചപ്പെടുത്തുന്നതിനും ചെലവ് കുറയ്ക്കുന്നതിനും വരുമാനം വർദ്ധിപ്പിക്കുന്നതിനും സഹായിക്കുന്ന നൂതന ഉൽപ്പന്നങ്ങളും സേവനങ്ങളും വികസിപ്പിക്കുന്നതിലും സമാരംഭിക്കുന്നതിലും നീൽ നേതൃത്വപരമായ റോളുകൾ വഹിച്ചിട്ടുണ്ട്. യഥാർത്ഥ ലോക പ്രശ്നങ്ങൾ പരിഹരിക്കാൻ സാങ്കേതികവിദ്യ ഉപയോഗിക്കുന്നതിൽ അദ്ദേഹം ആവേശഭരിതനാണ്, കൂടാതെ വിജയത്തിൻ്റെ തെളിയിക്കപ്പെട്ട ട്രാക്ക് റെക്കോർഡുള്ള തന്ത്രപരമായ ചിന്തകനുമാണ്.
നീൽ ദേശായി ആർട്ടിഫിഷ്യൽ ഇൻ്റലിജൻസ് (AI), ഡാറ്റാ സയൻസ്, സോഫ്റ്റ്വെയർ എഞ്ചിനീയറിംഗ്, എൻ്റർപ്രൈസ് ആർക്കിടെക്ചർ എന്നിവയിൽ 20 വർഷത്തിലേറെ പരിചയമുള്ള ഒരു ടെക്നോളജി എക്സിക്യൂട്ടീവാണ്. AWS-ൽ, നൂതന ജനറേറ്റീവ് AI- പവർ സൊല്യൂഷനുകൾ നിർമ്മിക്കാനും ഉപഭോക്താക്കളുമായി മികച്ച സമ്പ്രദായങ്ങൾ പങ്കിടാനും ഉൽപ്പന്ന റോഡ്മാപ്പ് ഡ്രൈവ് ചെയ്യാനും ഉപഭോക്താക്കളെ സഹായിക്കുന്ന വേൾഡ് വൈഡ് AI സേവന സ്പെഷ്യലിസ്റ്റ് സൊല്യൂഷൻ ആർക്കിടെക്റ്റുകളുടെ ഒരു ടീമിനെ അദ്ദേഹം നയിക്കുന്നു. വെസ്റ്റാസ്, ഹണിവെൽ, ക്വസ്റ്റ് ഡയഗ്നോസ്റ്റിക്സ് എന്നിവയിലെ തൻ്റെ മുൻ റോളുകളിൽ, കമ്പനികളുടെ പ്രവർത്തനങ്ങൾ മെച്ചപ്പെടുത്തുന്നതിനും ചെലവ് കുറയ്ക്കുന്നതിനും വരുമാനം വർദ്ധിപ്പിക്കുന്നതിനും സഹായിക്കുന്ന നൂതന ഉൽപ്പന്നങ്ങളും സേവനങ്ങളും വികസിപ്പിക്കുന്നതിലും സമാരംഭിക്കുന്നതിലും നീൽ നേതൃത്വപരമായ റോളുകൾ വഹിച്ചിട്ടുണ്ട്. യഥാർത്ഥ ലോക പ്രശ്നങ്ങൾ പരിഹരിക്കാൻ സാങ്കേതികവിദ്യ ഉപയോഗിക്കുന്നതിൽ അദ്ദേഹം ആവേശഭരിതനാണ്, കൂടാതെ വിജയത്തിൻ്റെ തെളിയിക്കപ്പെട്ട ട്രാക്ക് റെക്കോർഡുള്ള തന്ത്രപരമായ ചിന്തകനുമാണ്.
- SEO പവർ ചെയ്ത ഉള്ളടക്കവും PR വിതരണവും. ഇന്ന് ആംപ്ലിഫൈഡ് നേടുക.
- PlatoData.Network ലംബ ജനറേറ്റീവ് Ai. സ്വയം ശാക്തീകരിക്കുക. ഇവിടെ പ്രവേശിക്കുക.
- PlatoAiStream. Web3 ഇന്റലിജൻസ്. വിജ്ഞാനം വർധിപ്പിച്ചു. ഇവിടെ പ്രവേശിക്കുക.
- പ്ലേറ്റോഇഎസ്ജി. കാർബൺ, ക്ലീൻ ടെക്, ഊർജ്ജം, പരിസ്ഥിതി, സോളാർ, മാലിന്യ സംസ്കരണം. ഇവിടെ പ്രവേശിക്കുക.
- പ്ലേറ്റോ ഹെൽത്ത്. ബയോടെക് ആൻഡ് ക്ലിനിക്കൽ ട്രയൽസ് ഇന്റലിജൻസ്. ഇവിടെ പ്രവേശിക്കുക.
- അവലംബം: https://aws.amazon.com/blogs/machine-learning/unlock-the-potential-of-generative-ai-in-industrial-operations/

