
ചിത്രം രചയിതാവ്
ലോകത്തിലെ മുൻനിര AI ഗവേഷണ കമ്പനികളിലൊന്നായ Mistral AI അടുത്തിടെയാണ് അടിസ്ഥാന മോഡൽ പുറത്തിറക്കിയത് Mistral 7B v0.2.
ഈ ഓപ്പൺ സോഴ്സ് ഭാഷാ മോഡൽ 23 മാർച്ച് 2024-ന് കമ്പനിയുടെ ഹാക്കത്തോൺ ഇവൻ്റിനിടെ അനാച്ഛാദനം ചെയ്തു.
Mistral 7B മോഡലുകൾക്ക് 7.3 ബില്ല്യൺ പാരാമീറ്ററുകൾ ഉണ്ട്, അവ വളരെ ശക്തമാണ്. ലാമ 2 13 ബി, ലാമ 1 34 ബി എന്നിവയെ മിക്കവാറും എല്ലാ മാനദണ്ഡങ്ങളിലും അവർ മറികടക്കുന്നു. ഏറ്റവും പുതിയ V0.2 മോഡൽ മറ്റ് പുരോഗതികൾക്കൊപ്പം 32k സന്ദർഭ വിൻഡോ അവതരിപ്പിക്കുന്നു, ഇത് ടെക്സ്റ്റ് പ്രോസസ്സ് ചെയ്യാനും ജനറേറ്റുചെയ്യാനുമുള്ള അതിൻ്റെ കഴിവ് വർദ്ധിപ്പിക്കുന്നു.
കൂടാതെ, ഈയിടെ പ്രഖ്യാപിച്ച പതിപ്പ്, കഴിഞ്ഞ വർഷം ആദ്യം പുറത്തിറക്കിയ "Mistral-7B-Instruct-V0.2" എന്ന നിർദ്ദേശ-ട്യൂൺ വേരിയൻ്റിൻ്റെ അടിസ്ഥാന മോഡലാണ്.
ഈ ട്യൂട്ടോറിയലിൽ, ഹഗ്ഗിംഗ് ഫേസിൽ ഈ ഭാഷാ മോഡൽ എങ്ങനെ ആക്സസ് ചെയ്യാമെന്നും ഫൈൻ ട്യൂൺ ചെയ്യാമെന്നും ഞാൻ കാണിച്ചുതരാം.
ഹഗ്ഗിംഗ് ഫേസിൻ്റെ ഓട്ടോട്രെയിൻ പ്രവർത്തനക്ഷമത ഉപയോഗിച്ച് ഞങ്ങൾ Mistral 7B-v0.2 ബേസ് മോഡൽ നന്നായി ക്രമീകരിക്കും.
ആലിംഗനം ചെയ്യുന്ന മുഖം മെഷീൻ ലേണിംഗ് മോഡലുകളിലേക്കുള്ള പ്രവേശനം ജനാധിപത്യവൽക്കരിക്കുന്നതിന് പേരുകേട്ടതാണ്, ഇത് ദൈനംദിന ഉപയോക്താക്കളെ വിപുലമായ AI പരിഹാരങ്ങൾ വികസിപ്പിക്കാൻ അനുവദിക്കുന്നു.
ഹഗ്ഗിംഗ് ഫെയ്സിൻ്റെ സവിശേഷതയായ ഓട്ടോട്രെയിൻ, മോഡൽ പരിശീലന പ്രക്രിയയെ സ്വയമേവയാക്കുന്നു, ഇത് ആക്സസ് ചെയ്യാവുന്നതും കാര്യക്ഷമവുമാക്കുന്നു.
മോഡലുകൾ മികച്ച രീതിയിൽ ട്യൂൺ ചെയ്യുമ്പോൾ മികച്ച പാരാമീറ്ററുകളും പരിശീലന സാങ്കേതിക വിദ്യകളും തിരഞ്ഞെടുക്കാൻ ഇത് ഉപയോക്താക്കളെ സഹായിക്കുന്നു, അല്ലാത്തപക്ഷം ബുദ്ധിമുട്ടുള്ളതും സമയമെടുക്കുന്നതുമായ ഒരു ജോലിയാണിത്.
നിങ്ങളുടെ Mistral-5B മോഡൽ മികച്ചതാക്കുന്നതിനുള്ള 7 ഘട്ടങ്ങൾ ഇതാ:
1. പരിസ്ഥിതി സജ്ജീകരിക്കുന്നു
നിങ്ങൾ ആദ്യം ഹഗ്ഗിംഗ് ഫേസ് ഉപയോഗിച്ച് ഒരു അക്കൗണ്ട് സൃഷ്ടിക്കണം, തുടർന്ന് ഒരു മോഡൽ ശേഖരം സൃഷ്ടിക്കുക.
ഇത് നേടുന്നതിന്, ഇതിൽ നൽകിയിരിക്കുന്ന ഘട്ടങ്ങൾ പിന്തുടരുക ബന്ധം ഈ ട്യൂട്ടോറിയലിലേക്ക് മടങ്ങുക.
ഞങ്ങൾ പൈത്തണിൽ മോഡലിനെ പരിശീലിപ്പിക്കും. പരിശീലനത്തിനായി ഒരു നോട്ട്ബുക്ക് പരിതസ്ഥിതി തിരഞ്ഞെടുക്കുമ്പോൾ, നിങ്ങൾക്ക് ഉപയോഗിക്കാം കാഗിൾ നോട്ട്ബുക്കുകൾ or Google കൊളാബ്, ഇവ രണ്ടും GPU-കളിലേക്ക് സൗജന്യ ആക്സസ് നൽകുന്നു.
പരിശീലന പ്രക്രിയയ്ക്ക് കൂടുതൽ സമയമെടുക്കുകയാണെങ്കിൽ, AWS Sagemaker അല്ലെങ്കിൽ Azure ML പോലുള്ള ക്ലൗഡ് പ്ലാറ്റ്ഫോമിലേക്ക് മാറാൻ നിങ്ങൾ ആഗ്രഹിച്ചേക്കാം.
അവസാനമായി, ഈ ട്യൂട്ടോറിയലിലേക്ക് കോഡിംഗ് ആരംഭിക്കുന്നതിന് മുമ്പ് ഇനിപ്പറയുന്ന പൈപ്പ് ഇൻസ്റ്റാളുകൾ നടത്തുക:
!pip install -U autotrain-advanced
!pip install datasets transformers2. നിങ്ങളുടെ ഡാറ്റാസെറ്റ് തയ്യാറാക്കുന്നു
ഈ ട്യൂട്ടോറിയലിൽ, ഞങ്ങൾ ഉപയോഗിക്കും അൽപാക്ക ഡാറ്റാസെറ്റ് കെട്ടിപ്പിടിക്കുന്ന മുഖത്ത്, ഇതുപോലെ കാണപ്പെടുന്നു:
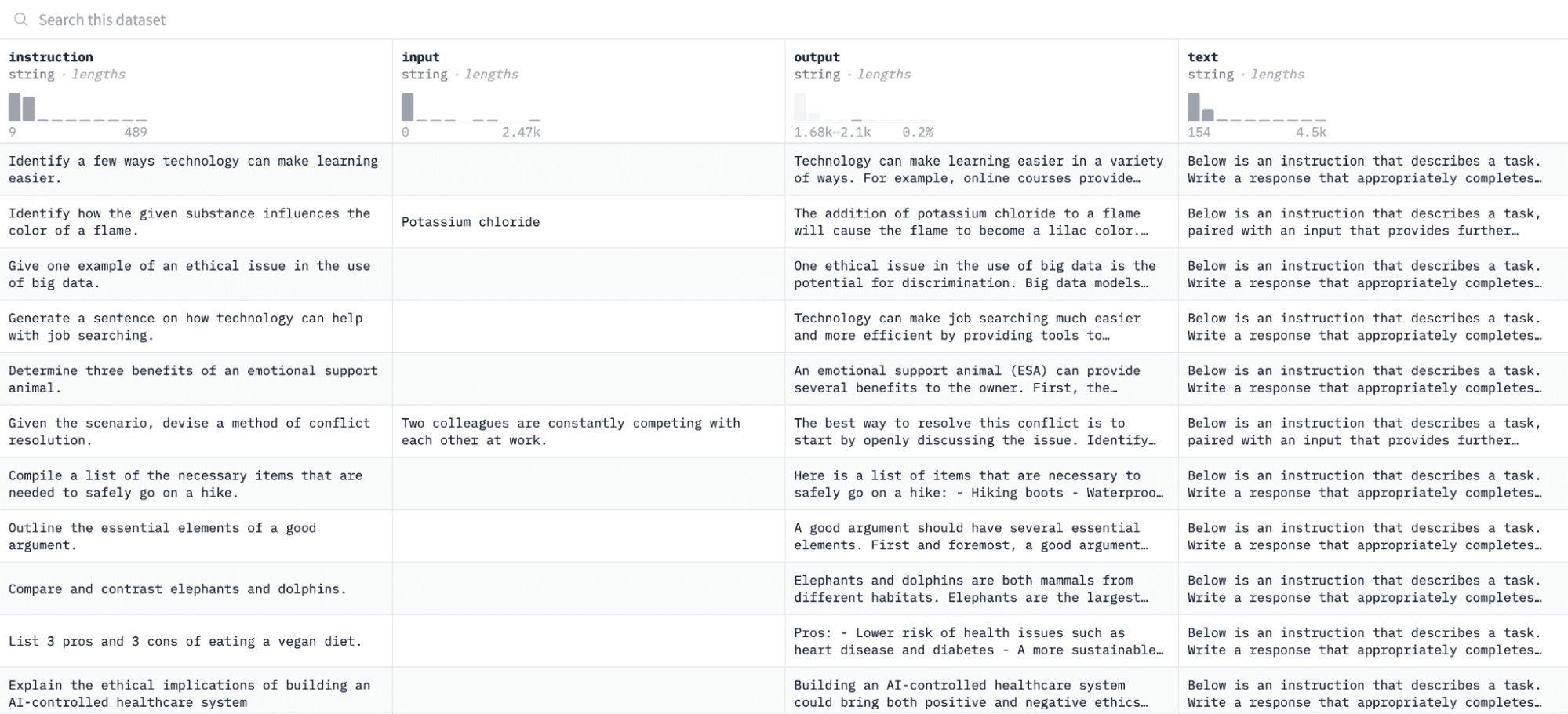
ജോഡി നിർദ്ദേശങ്ങളിലും ഔട്ട്പുട്ടുകളിലും ഞങ്ങൾ മോഡൽ നന്നായി ട്യൂൺ ചെയ്യുകയും മൂല്യനിർണ്ണയ പ്രക്രിയയിൽ നൽകിയിരിക്കുന്ന നിർദ്ദേശങ്ങളോട് പ്രതികരിക്കാനുള്ള അതിൻ്റെ കഴിവ് വിലയിരുത്തുകയും ചെയ്യും.
ഈ ഡാറ്റാസെറ്റ് ആക്സസ് ചെയ്യാനും തയ്യാറാക്കാനും, ഇനിപ്പറയുന്ന കോഡ് ലൈനുകൾ പ്രവർത്തിപ്പിക്കുക:
import pandas as pd
from datasets import load_dataset
# Load and preprocess dataset
def preprocess_dataset(dataset_name, split_ratio='train[:10%]', input_col='input', output_col='output'):
dataset = load_dataset(dataset_name, split=split_ratio)
df = pd.DataFrame(dataset)
chat_df = df[df[input_col] == ''].reset_index(drop=True)
return chat_df
# Formatting according to AutoTrain requirements
def format_interaction(row):
formatted_text = f"[Begin] {row['instruction']} [End] {row['output']} [Close]"
return formatted_text
# Process and save the dataset
if __name__ == "__main__":
dataset_name = "tatsu-lab/alpaca"
processed_data = preprocess_dataset(dataset_name)
processed_data['formatted_text'] = processed_data.apply(format_interaction, axis=1)
save_path = 'formatted_data/training_dataset'
os.makedirs(save_path, exist_ok=True)
file_path = os.path.join(save_path, 'formatted_train.csv')
processed_data[['formatted_text']].to_csv(file_path, index=False)
print("Dataset formatted and saved.")ആദ്യ ഫംഗ്ഷൻ "ഡാറ്റസെറ്റുകൾ" ലൈബ്രറി ഉപയോഗിച്ച് അൽപാക്ക ഡാറ്റാസെറ്റ് ലോഡ് ചെയ്യുകയും ഞങ്ങൾ ശൂന്യമായ നിർദ്ദേശങ്ങളൊന്നും ഉൾപ്പെടുത്തിയിട്ടില്ലെന്ന് ഉറപ്പാക്കുകയും ചെയ്യും. രണ്ടാമത്തെ ഫംഗ്ഷൻ നിങ്ങളുടെ ഡാറ്റയെ AutoTrain മനസ്സിലാക്കാൻ കഴിയുന്ന ഒരു ഫോർമാറ്റിൽ ക്രമീകരിക്കുന്നു.
മുകളിലെ കോഡ് പ്രവർത്തിപ്പിച്ചതിന് ശേഷം, ഡാറ്റാസെറ്റ് ലോഡ് ചെയ്യുകയും ഫോർമാറ്റ് ചെയ്യുകയും നിർദ്ദിഷ്ട പാതയിൽ സംരക്ഷിക്കുകയും ചെയ്യും. നിങ്ങളുടെ ഫോർമാറ്റ് ചെയ്ത ഡാറ്റാസെറ്റ് തുറക്കുമ്പോൾ, "formatted_text" എന്ന് ലേബൽ ചെയ്തിരിക്കുന്ന ഒരു കോളം നിങ്ങൾ കാണും.
3. നിങ്ങളുടെ പരിശീലന അന്തരീക്ഷം സജ്ജീകരിക്കുക
ഇപ്പോൾ നിങ്ങൾ ഡാറ്റാസെറ്റ് വിജയകരമായി തയ്യാറാക്കിയിരിക്കുന്നു, നിങ്ങളുടെ മാതൃകാ പരിശീലന പരിതസ്ഥിതി സജ്ജീകരിക്കാൻ നമുക്ക് മുന്നോട്ട് പോകാം.
ഇത് ചെയ്യുന്നതിന്, നിങ്ങൾ ഇനിപ്പറയുന്ന പാരാമീറ്ററുകൾ നിർവചിക്കേണ്ടതുണ്ട്:
project_name = 'mistralai'
model_name = 'alpindale/Mistral-7B-v0.2-hf'
push_to_hub = True
hf_token = 'your_token_here'
repo_id = 'your_repo_here.'മുകളിലുള്ള സവിശേഷതകളുടെ ഒരു തകർച്ച ഇതാ:
- നിങ്ങൾക്ക് ഏത് വേണമെങ്കിലും വ്യക്തമാക്കാം പദ്ധതിയുടെ പേര്. നിങ്ങളുടെ എല്ലാ പ്രോജക്റ്റുകളും പരിശീലന ഫയലുകളും ഇവിടെയാണ് സംഭരിക്കപ്പെടുന്നത്.
- ദി മോഡൽ_നാമം പാരാമീറ്റർ നിങ്ങൾ നന്നായി ക്രമീകരിക്കാൻ ആഗ്രഹിക്കുന്ന മോഡലാണ്. ഈ സാഹചര്യത്തിൽ, ഇതിലേക്കുള്ള ഒരു പാത ഞാൻ വ്യക്തമാക്കിയിട്ടുണ്ട് Mistral-7B v0.2 അടിസ്ഥാന മോഡൽ ഹഗ്ഗിംഗ് ഫേസിൽ.
- ദി hf_ടോക്കൺ നിങ്ങളുടെ ഹഗ്ഗിംഗ് ഫേസ് ടോക്കണിലേക്ക് വേരിയബിൾ സജ്ജീകരിച്ചിരിക്കണം, ഇത് നാവിഗേറ്റ് ചെയ്യുന്നതിലൂടെ ലഭിക്കും ഈ ലിങ്ക്.
- നിങ്ങളുടെ repo_id ഈ ട്യൂട്ടോറിയലിൻ്റെ ആദ്യ ഘട്ടത്തിൽ നിങ്ങൾ സൃഷ്ടിച്ച ഹഗ്ഗിംഗ് ഫേസ് മോഡൽ റിപ്പോസിറ്ററിയിലേക്ക് സജ്ജീകരിച്ചിരിക്കണം. ഉദാഹരണത്തിന്, എൻ്റെ റിപ്പോസിറ്ററി ഐഡി NatasshaS/Model2.
4. മോഡൽ പാരാമീറ്ററുകൾ ക്രമീകരിക്കുന്നു
ഞങ്ങളുടെ മോഡൽ ഫൈൻ-ട്യൂൺ ചെയ്യുന്നതിന് മുമ്പ്, പരിശീലന കാലയളവും ക്രമപ്പെടുത്തലും പോലുള്ള മോഡൽ പെരുമാറ്റത്തിൻ്റെ വശങ്ങളെ നിയന്ത്രിക്കുന്ന പരിശീലന പാരാമീറ്ററുകൾ ഞങ്ങൾ നിർവചിക്കേണ്ടതുണ്ട്.
ഈ പാരാമീറ്ററുകൾ മോഡൽ എത്ര സമയം പരിശീലിപ്പിക്കുന്നു, ഡാറ്റയിൽ നിന്ന് എങ്ങനെ പഠിക്കുന്നു, അത് എങ്ങനെ ഓവർഫിറ്റിംഗ് ഒഴിവാക്കുന്നു തുടങ്ങിയ പ്രധാന വശങ്ങളെ സ്വാധീനിക്കുന്നു.
നിങ്ങളുടെ മോഡലിന് ഇനിപ്പറയുന്ന പാരാമീറ്ററുകൾ സജ്ജമാക്കാൻ കഴിയും:
use_fp16 = True
use_peft = True
use_int4 = True
learning_rate = 1e-4
num_epochs = 3
batch_size = 4
block_size = 512
warmup_ratio = 0.05
weight_decay = 0.005
lora_r = 8
lora_alpha = 16
lora_dropout = 0.015. പരിസ്ഥിതി വേരിയബിളുകൾ ക്രമീകരിക്കുന്നു
ചില പരിസ്ഥിതി വേരിയബിളുകൾ സജ്ജീകരിച്ച് നമുക്ക് പരിശീലന അന്തരീക്ഷം തയ്യാറാക്കാം.
ഞങ്ങളുടെ പ്രോജക്റ്റ് പേരും പരിശീലന മുൻഗണനകളും പോലുള്ള മോഡൽ മികച്ചതാക്കാൻ AutoTrain സവിശേഷത ആവശ്യമുള്ള ക്രമീകരണങ്ങൾ ഉപയോഗിക്കുന്നുവെന്ന് ഈ ഘട്ടം ഉറപ്പാക്കുന്നു:
os.environ["PROJECT_NAME"] = project_name
os.environ["MODEL_NAME"] = model_name
os.environ["LEARNING_RATE"] = str(learning_rate)
os.environ["NUM_EPOCHS"] = str(num_epochs)
os.environ["BATCH_SIZE"] = str(batch_size)
os.environ["BLOCK_SIZE"] = str(block_size)
os.environ["WARMUP_RATIO"] = str(warmup_ratio)
os.environ["WEIGHT_DECAY"] = str(weight_decay)
os.environ["USE_FP16"] = str(use_fp16)
os.environ["LORA_R"] = str(lora_r)
os.environ["LORA_ALPHA"] = str(lora_alpha)
os.environ["LORA_DROPOUT"] = str(lora_dropout)6. മാതൃകാ പരിശീലനം ആരംഭിക്കുക
അവസാനമായി, നമുക്ക് മോഡൽ ഉപയോഗിച്ച് പരിശീലനം ആരംഭിക്കാം ഓട്ടോട്രെയിൻ കമാൻഡ്. ചുവടെ പ്രദർശിപ്പിച്ചിരിക്കുന്നതുപോലെ നിങ്ങളുടെ മോഡൽ, ഡാറ്റാസെറ്റ്, പരിശീലന കോൺഫിഗറേഷനുകൾ എന്നിവ വ്യക്തമാക്കുന്നത് ഈ ഘട്ടത്തിൽ ഉൾപ്പെടുന്നു:
!autotrain llm
--train
--model "${MODEL_NAME}"
--project-name "${PROJECT_NAME}"
--data-path "formatted_data/training_dataset/"
--text-column "formatted_text"
--lr "${LEARNING_RATE}"
--batch-size "${BATCH_SIZE}"
--epochs "${NUM_EPOCHS}"
--block-size "${BLOCK_SIZE}"
--warmup-ratio "${WARMUP_RATIO}"
--lora-r "${LORA_R}"
--lora-alpha "${LORA_ALPHA}"
--lora-dropout "${LORA_DROPOUT}"
--weight-decay "${WEIGHT_DECAY}"
$( [[ "$USE_FP16" == "True" ]] && echo "--mixed-precision fp16" )
$( [[ "$USE_PEFT" == "True" ]] && echo "--use-peft" )
$( [[ "$USE_INT4" == "True" ]] && echo "--quantization int4" )
$( [[ "$PUSH_TO_HUB" == "True" ]] && echo "--push-to-hub --token ${HF_TOKEN} --repo-id ${REPO_ID}" )മാറ്റുന്നത് ഉറപ്പാക്കുക ഡാറ്റ-പാത്ത് നിങ്ങളുടെ പരിശീലന ഡാറ്റാസെറ്റ് എവിടെയാണ് സ്ഥിതി ചെയ്യുന്നത്.
7. മോഡൽ വിലയിരുത്തുന്നു
നിങ്ങളുടെ മോഡൽ പരിശീലനം പൂർത്തിയാക്കിക്കഴിഞ്ഞാൽ, നിങ്ങളുടെ പ്രൊജക്റ്റ് പേരിൻ്റെ അതേ ശീർഷകത്തിൽ ഒരു ഫോൾഡർ നിങ്ങളുടെ ഡയറക്ടറിയിൽ ദൃശ്യമാകുന്നത് നിങ്ങൾ കാണും.
എൻ്റെ കാര്യത്തിൽ, ഈ ഫോൾഡറിൻ്റെ തലക്കെട്ട് "മിസ്ട്രാലൈ" ചുവടെയുള്ള ചിത്രത്തിൽ കാണുന്നത് പോലെ:
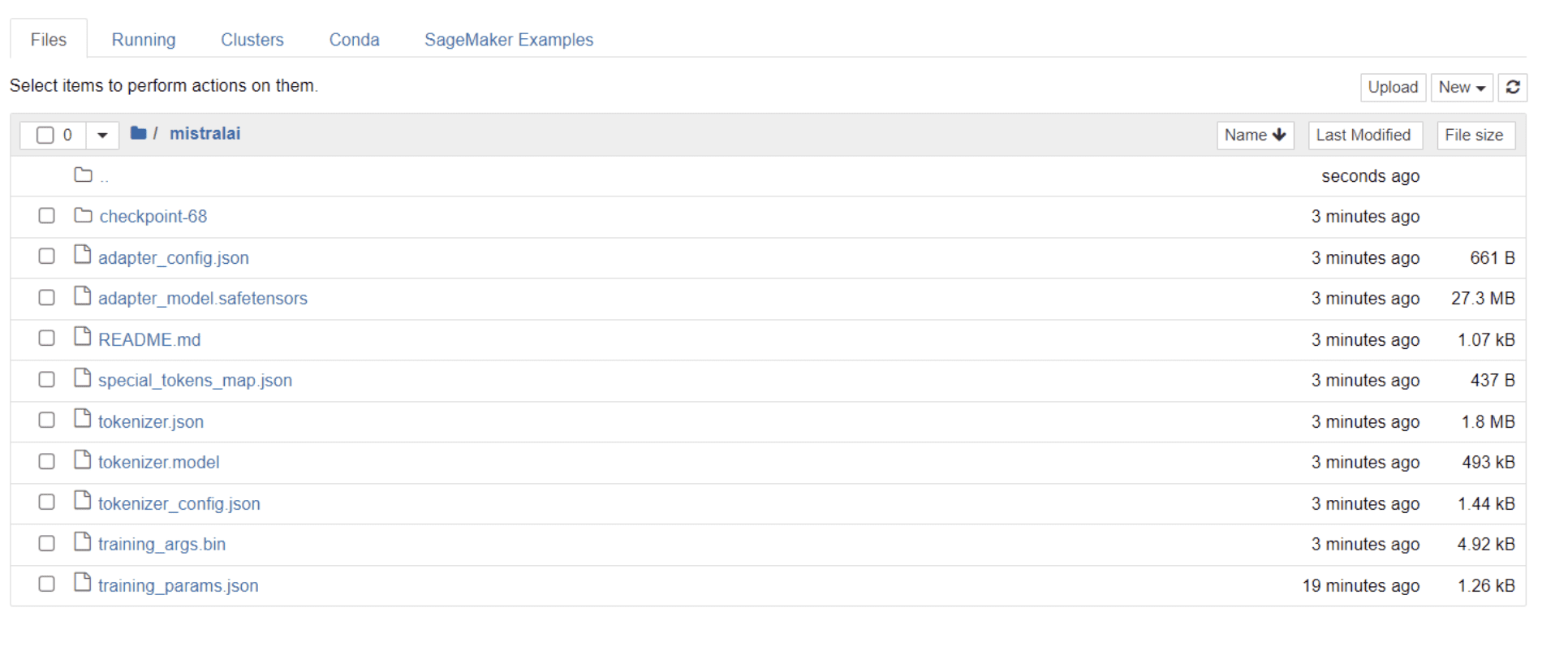
ഈ ഫോൾഡറിനുള്ളിൽ, നിങ്ങളുടെ മോഡൽ ഭാരം, ഹൈപ്പർപാരാമീറ്ററുകൾ, ആർക്കിടെക്ചർ വിശദാംശങ്ങൾ എന്നിവ ഉൾക്കൊള്ളുന്ന ഫയലുകൾ നിങ്ങൾക്ക് കണ്ടെത്താനാകും.
നമ്മുടെ ഡാറ്റാസെറ്റിലെ ഒരു ചോദ്യത്തോട് കൃത്യമായി പ്രതികരിക്കാൻ ഈ ഫൈൻ-ട്യൂൺ ചെയ്ത മോഡലിന് കഴിയുമോ എന്ന് ഇപ്പോൾ പരിശോധിക്കാം. ഇത് നേടുന്നതിന്, ഞങ്ങളുടെ ഡാറ്റാസെറ്റിൽ നിന്ന് 5 സാമ്പിൾ ഇൻപുട്ടുകളും ഔട്ട്പുട്ടുകളും സൃഷ്ടിക്കുന്നതിന് ഞങ്ങൾ ആദ്യം ഇനിപ്പറയുന്ന കോഡ് ലൈനുകൾ പ്രവർത്തിപ്പിക്കേണ്ടതുണ്ട്:
# Print out 5 sample inputs and outputs from our dataset
for i, example in enumerate(dataset):
if i >= 5:
break
print(f"Instruction: {example['instruction']}")
print(f"Output: {example['output']}n---")5 സാമ്പിൾ ഡാറ്റ പോയിൻ്റുകൾ പ്രദർശിപ്പിക്കുന്ന, ഇതുപോലെയുള്ള ഒരു പ്രതികരണം നിങ്ങൾ കാണും:
Instruction: Give three tips for staying healthy.
Output: 1.Eat a balanced diet and make sure to include plenty of fruits and vegetables.
2. Exercise regularly to keep your body active and strong.
3. Get enough sleep and maintain a consistent sleep schedule.
---
Instruction: What are the three primary colors?
Output: The three primary colors are red, blue, and yellow.
---
Instruction: Describe the structure of an atom.
Output: An atom is made up of a nucleus, which contains protons and neutrons, surrounded by electrons that travel in orbits around the nucleus. The protons and neutrons have a positive charge, while the electrons have a negative charge, resulting in an overall neutral atom. The number of each particle determines the atomic number and the type of atom.
---
Instruction: How can we reduce air pollution?
Output: There are a number of ways to reduce air pollution, such as shifting to renewable energy sources, encouraging the use of public transportation, prohibiting the burning of fossil fuels, implementing policies to reduce emissions from industrial sources, and implementing vehicle emissions standards. Additionally, individuals can do their part to reduce air pollution by reducing car use, avoiding burning materials such as wood, and changing to energy efficient appliances.
---
Instruction: Describe a time when you had to make a difficult decision.
Output: I had to make a difficult decision when I was working as a project manager at a construction company. I was in charge of a project that needed to be completed by a certain date in order to meet the client's expectations. However, due to unexpected delays, we were not able to meet the deadline and so I had to make a difficult decision. I decided to extend the deadline, but I had to stretch the team's resources even further and increase the budget. Although it was a risky decision, I ultimately decided to go ahead with it to ensure that the project was completed on time and that the client's expectations were met. The project was eventually successfully completed and this was seen as a testament to my leadership and decision-making abilities.ഞങ്ങൾ മുകളിലെ നിർദ്ദേശങ്ങളിൽ ഒന്ന് മോഡലിൽ ടൈപ്പ് ചെയ്യുകയും അത് കൃത്യമായ ഔട്ട്പുട്ട് സൃഷ്ടിക്കുന്നുണ്ടോയെന്ന് പരിശോധിക്കുകയും ചെയ്യും. മോഡലിന് ഒരു നിർദ്ദേശം നൽകുന്നതിനും അതിൽ നിന്ന് ഒരു പ്രതികരണം നേടുന്നതിനുമുള്ള ഒരു ഫംഗ്ഷൻ ഇതാ:
# Function to provide an instruction
def ask(model, tokenizer, question, max_length=128):
inputs = tokenizer.encode(question, return_tensors='pt')
outputs = model.generate(inputs, max_length=max_length, num_return_sequences=1)
answer = tokenizer.decode(outputs[0], skip_special_tokens=True)
return answerഅവസാനമായി, ചുവടെ പ്രദർശിപ്പിച്ചിരിക്കുന്നതുപോലെ ഈ ഫംഗ്ഷനിലേക്ക് ഒരു ചോദ്യം നൽകുക:
question = "Describe a time when you had to make a difficult decision."
answer = ask(model, tokenizer, question)
print(answer)താഴെ പ്രദർശിപ്പിച്ചിരിക്കുന്നതുപോലെ, പരിശീലന ഡാറ്റാസെറ്റിലെ അതിൻ്റെ അനുബന്ധ ഔട്ട്പുട്ടിന് സമാനമായ ഒരു പ്രതികരണം നിങ്ങളുടെ മോഡൽ സൃഷ്ടിക്കണം:
Describe a time when you had to make a difficult decision.
What did you do? How did it turn out?
[/INST] I remember a time when I had to make a difficult decision about
my career. I had been working in the same job for several years and had
grown tired of it. I knew that I needed to make a change, but I was unsure of what to do. I weighed my options carefully and eventually decided to take a leap of faith and start my own business. It was a risky move, but it paid off in the end. I am now the owner of a successful business andഞങ്ങൾ വ്യക്തമാക്കിയ ടോക്കണുകളുടെ എണ്ണം കാരണം പ്രതികരണം അപൂർണ്ണമായോ അല്ലെങ്കിൽ വെട്ടിച്ചുരുക്കിയതായോ തോന്നാം എന്നത് ശ്രദ്ധിക്കുക. കൂടുതൽ വിപുലമായ പ്രതികരണം അനുവദിക്കുന്നതിന് "max_length" മൂല്യം ക്രമീകരിക്കാൻ മടിക്കേണ്ടതില്ല.
നിങ്ങൾ ഇത്രയും ദൂരം എത്തിയെങ്കിൽ, അഭിനന്ദനങ്ങൾ!
ഹഗ്ഗിംഗ് ഫേസിൻ്റെ കഴിവുകൾക്കൊപ്പം Mistral 7B v-0.2 ൻ്റെ ശക്തിയും പ്രയോജനപ്പെടുത്തി, അത്യാധുനിക ഭാഷാ മോഡൽ നിങ്ങൾ വിജയകരമായി മികച്ച രീതിയിൽ ട്യൂൺ ചെയ്തു.
എന്നാൽ യാത്ര ഇവിടെ അവസാനിക്കുന്നില്ല.
അടുത്ത ഘട്ടമെന്ന നിലയിൽ, മോഡൽ പെർഫോമൻസ് ഒപ്റ്റിമൈസ് ചെയ്യുന്നതിന് വ്യത്യസ്ത ഡാറ്റാസെറ്റുകളിൽ പരീക്ഷണം നടത്താനോ ചില പരിശീലന പാരാമീറ്ററുകൾ ട്വീക്ക് ചെയ്യാനോ ഞാൻ ശുപാർശ ചെയ്യുന്നു. വലിയ തോതിലുള്ള ഫൈൻ-ട്യൂണിംഗ് മോഡലുകൾ അവയുടെ ഉപയോഗക്ഷമത വർദ്ധിപ്പിക്കും, അതിനാൽ വലിയ ഡാറ്റാസെറ്റുകൾ അല്ലെങ്കിൽ PDF-കളും ടെക്സ്റ്റ് ഫയലുകളും പോലുള്ള വ്യത്യസ്ത ഫോർമാറ്റുകൾ പരീക്ഷിച്ചുനോക്കൂ.
ഓർഗനൈസേഷനുകളിൽ യഥാർത്ഥ ലോക ഡാറ്റയുമായി പ്രവർത്തിക്കുമ്പോൾ അത്തരം അനുഭവം വിലമതിക്കാനാവാത്തതാണ്, അത് പലപ്പോഴും കുഴപ്പവും ഘടനാരഹിതവുമാണ്.
നതാഷ സെൽവരാജ് എഴുത്തിനോടുള്ള അഭിനിവേശമുള്ള സ്വയം പഠിപ്പിച്ച ഡാറ്റ ശാസ്ത്രജ്ഞനാണ്. ഡാറ്റാ സയൻസുമായി ബന്ധപ്പെട്ട എല്ലാ കാര്യങ്ങളിലും നതാഷ എഴുതുന്നു, എല്ലാ ഡാറ്റാ വിഷയങ്ങളുടെയും യഥാർത്ഥ മാസ്റ്റർ. നിങ്ങൾക്ക് അവളുമായി ബന്ധപ്പെടാം ലിങ്ക്ഡ് അല്ലെങ്കിൽ അവളെ പരിശോധിക്കുക YouTube ചാനൽ.
- SEO പവർ ചെയ്ത ഉള്ളടക്കവും PR വിതരണവും. ഇന്ന് ആംപ്ലിഫൈഡ് നേടുക.
- PlatoData.Network ലംബ ജനറേറ്റീവ് Ai. സ്വയം ശാക്തീകരിക്കുക. ഇവിടെ പ്രവേശിക്കുക.
- PlatoAiStream. Web3 ഇന്റലിജൻസ്. വിജ്ഞാനം വർധിപ്പിച്ചു. ഇവിടെ പ്രവേശിക്കുക.
- പ്ലേറ്റോഇഎസ്ജി. കാർബൺ, ക്ലീൻ ടെക്, ഊർജ്ജം, പരിസ്ഥിതി, സോളാർ, മാലിന്യ സംസ്കരണം. ഇവിടെ പ്രവേശിക്കുക.
- പ്ലേറ്റോ ഹെൽത്ത്. ബയോടെക് ആൻഡ് ക്ലിനിക്കൽ ട്രയൽസ് ഇന്റലിജൻസ്. ഇവിടെ പ്രവേശിക്കുക.
- അവലംബം: https://www.kdnuggets.com/mistral-7b-v02-fine-tuning-mistral-new-open-source-llm-with-hugging-face?utm_source=rss&utm_medium=rss&utm_campaign=mistral-7b-v0-2-fine-tuning-mistrals-new-open-source-llm-with-hugging-face

