ലേബൽ ചെയ്യാത്തതും സാമാന്യവൽക്കരിച്ചതുമായ ഡാറ്റാസെറ്റുകളുടെ വിശാലമായ സ്പെക്ട്രത്തിൽ പരിശീലിപ്പിച്ച വലിയ മെഷീൻ ലേണിംഗ് (ML) മോഡലുകളാണ് ഫൗണ്ടേഷൻ മോഡലുകൾ (FMs). FM-കൾ, പേര് സൂചിപ്പിക്കുന്നത് പോലെ, കൂടുതൽ സ്പെഷ്യലൈസ്ഡ് ഡൗൺസ്ട്രീം ആപ്ലിക്കേഷനുകൾ നിർമ്മിക്കുന്നതിനുള്ള അടിത്തറ നൽകുന്നു, മാത്രമല്ല അവയുടെ അഡാപ്റ്റബിലിറ്റിയിൽ അതുല്യവുമാണ്. സ്വാഭാവിക ഭാഷാ സംസ്കരണം, ഇമേജുകൾ തരംതിരിക്കുക, ട്രെൻഡുകൾ പ്രവചിക്കുക, വികാരം വിശകലനം ചെയ്യുക, ചോദ്യങ്ങൾക്ക് ഉത്തരം നൽകുക എന്നിങ്ങനെ വിവിധങ്ങളായ വിവിധ ജോലികൾ ചെയ്യാൻ അവർക്ക് കഴിയും. പരമ്പരാഗത ML മോഡലുകളിൽ നിന്ന് FM-കളെ വ്യത്യസ്തമാക്കുന്നത് ഈ സ്കെയിലും പൊതു-ഉദ്ദേശ്യ അഡാപ്റ്റബിലിറ്റിയുമാണ്. FM-കൾ മൾട്ടിമോഡൽ ആണ്; ടെക്സ്റ്റ്, വീഡിയോ, ഓഡിയോ, ഇമേജുകൾ എന്നിവ പോലുള്ള വ്യത്യസ്ത ഡാറ്റ തരങ്ങളുമായി അവ പ്രവർത്തിക്കുന്നു. വലിയ ഭാഷാ മോഡലുകൾ (LLMs) ഒരു തരം FM ആണ്, അവ വലിയ അളവിലുള്ള ടെക്സ്റ്റ് ഡാറ്റയിൽ മുൻകൂട്ടി പരിശീലിപ്പിച്ചവയാണ്, കൂടാതെ സാധാരണയായി ടെക്സ്റ്റ് സൃഷ്ടിക്കൽ, ഇൻ്റലിജൻ്റ് ചാറ്റ്ബോട്ടുകൾ അല്ലെങ്കിൽ സംഗ്രഹം എന്നിവ പോലുള്ള ആപ്ലിക്കേഷൻ ഉപയോഗങ്ങളുണ്ട്.
സ്ട്രീമിംഗ് ഡാറ്റ വൈവിധ്യമാർന്നതും കാലികവുമായ വിവരങ്ങളുടെ നിരന്തരമായ ഒഴുക്ക് സുഗമമാക്കുന്നു, കൂടുതൽ കൃത്യവും സാന്ദർഭികമായി പ്രസക്തവുമായ ഔട്ട്പുട്ടുകൾ പൊരുത്തപ്പെടുത്താനും സൃഷ്ടിക്കാനുമുള്ള മോഡലുകളുടെ കഴിവ് വർദ്ധിപ്പിക്കുന്നു. സ്ട്രീമിംഗ് ഡാറ്റയുടെ ഈ ഡൈനാമിക് ഇൻ്റഗ്രേഷൻ പ്രാപ്തമാക്കുന്നു ജനറേറ്റീവ് AI മാറിക്കൊണ്ടിരിക്കുന്ന അവസ്ഥകളോട് ഉടനടി പ്രതികരിക്കുന്നതിനും അവയുടെ പൊരുത്തപ്പെടുത്തൽ മെച്ചപ്പെടുത്തുന്നതിനും വിവിധ ജോലികളിലെ മൊത്തത്തിലുള്ള പ്രകടനത്തിനും ആപ്ലിക്കേഷനുകൾ.
ഇത് നന്നായി മനസ്സിലാക്കാൻ, യാത്രക്കാർക്ക് അവരുടെ യാത്ര ബുക്ക് ചെയ്യാൻ സഹായിക്കുന്ന ഒരു ചാറ്റ്ബോട്ട് സങ്കൽപ്പിക്കുക. ഈ സാഹചര്യത്തിൽ, ചാറ്റ്ബോട്ടിന് എയർലൈൻ ഇൻവെൻ്ററി, ഫ്ലൈറ്റ് സ്റ്റാറ്റസ്, ഹോട്ടൽ ഇൻവെൻ്ററി, ഏറ്റവും പുതിയ വില മാറ്റങ്ങൾ എന്നിവയിലേക്കും മറ്റും തത്സമയ ആക്സസ് ആവശ്യമാണ്. ഈ ഡാറ്റ സാധാരണയായി മൂന്നാം കക്ഷികളിൽ നിന്നാണ് വരുന്നത്, ഡെവലപ്പർമാർ ഈ ഡാറ്റ ഉൾപ്പെടുത്താനും ഡാറ്റ മാറ്റങ്ങൾ സംഭവിക്കുമ്പോൾ അവ പ്രോസസ്സ് ചെയ്യാനും ഒരു വഴി കണ്ടെത്തേണ്ടതുണ്ട്.
ഈ സാഹചര്യത്തിൽ ബാച്ച് പ്രോസസ്സിംഗ് ഏറ്റവും അനുയോജ്യമല്ല. ഡാറ്റ അതിവേഗം മാറുമ്പോൾ, ഒരു ബാച്ചിൽ പ്രോസസ്സ് ചെയ്യുന്നത്, ചാറ്റ്ബോട്ട് ഉപയോഗിക്കുന്ന പഴകിയ ഡാറ്റയ്ക്ക് കാരണമായേക്കാം, ഇത് ഉപഭോക്താവിന് കൃത്യമല്ലാത്ത വിവരങ്ങൾ നൽകുന്നു, ഇത് മൊത്തത്തിലുള്ള ഉപഭോക്തൃ അനുഭവത്തെ ബാധിക്കുന്നു. എന്നിരുന്നാലും, സ്ട്രീം പ്രോസസ്സിംഗിന്, തത്സമയ ഡാറ്റ ആക്സസ് ചെയ്യാനും ലഭ്യതയിലും വിലയിലും ഉള്ള മാറ്റങ്ങളുമായി പൊരുത്തപ്പെടാനും ചാറ്റ്ബോട്ടിനെ പ്രാപ്തമാക്കാനും ഉപഭോക്താവിന് മികച്ച മാർഗ്ഗനിർദ്ദേശം നൽകാനും ഉപഭോക്തൃ അനുഭവം വർദ്ധിപ്പിക്കാനും കഴിയും.
ഒരു സിസ്റ്റത്തിൻ്റെ തത്സമയ ഇൻ്റേണൽ മെട്രിക്സ് നിരീക്ഷിക്കുകയും അലേർട്ടുകൾ നിർമ്മിക്കുകയും ചെയ്യുന്ന എഫ്എം-കൾ AI- നയിക്കുന്ന നിരീക്ഷണ, നിരീക്ഷണ സൊല്യൂഷനാണ് മറ്റൊരു ഉദാഹരണം. മോഡൽ അസാധാരണമോ അസാധാരണമോ ആയ മെട്രിക് മൂല്യം കണ്ടെത്തുമ്പോൾ, അത് ഉടനടി ഒരു മുന്നറിയിപ്പ് നൽകുകയും ഓപ്പറേറ്ററെ അറിയിക്കുകയും വേണം. എന്നിരുന്നാലും, അത്തരം പ്രധാനപ്പെട്ട ഡാറ്റയുടെ മൂല്യം കാലക്രമേണ ഗണ്യമായി കുറയുന്നു. ഈ അറിയിപ്പുകൾ നിമിഷങ്ങൾക്കകം അല്ലെങ്കിൽ അത് സംഭവിക്കുമ്പോൾ പോലും ലഭിക്കണം. ഈ അറിയിപ്പുകൾ സംഭവിച്ച് മിനിറ്റുകൾക്കോ മണിക്കൂറുകൾക്കോ ഓപ്പറേറ്റർമാർക്ക് ലഭിക്കുകയാണെങ്കിൽ, അത്തരമൊരു ഉൾക്കാഴ്ച പ്രവർത്തനക്ഷമമല്ല, മാത്രമല്ല അതിൻ്റെ മൂല്യം നഷ്ടപ്പെടാനും സാധ്യതയുണ്ട്. റീട്ടെയിൽ, കാർ നിർമ്മാണം, ഊർജ്ജം, സാമ്പത്തിക വ്യവസായം തുടങ്ങിയ മറ്റ് വ്യവസായങ്ങളിലും സമാനമായ ഉപയോഗ കേസുകൾ നിങ്ങൾക്ക് കണ്ടെത്താനാകും.
ഈ പോസ്റ്റിൽ, ഡാറ്റ സ്ട്രീമിംഗ് അതിൻ്റെ തത്സമയ സ്വഭാവം കാരണം ജനറേറ്റീവ് AI ആപ്ലിക്കേഷനുകളുടെ നിർണായക ഘടകമായിരിക്കുന്നത് എന്തുകൊണ്ടാണെന്ന് ഞങ്ങൾ ചർച്ച ചെയ്യുന്നു. പോലുള്ള AWS ഡാറ്റ സ്ട്രീമിംഗ് സേവനങ്ങളുടെ മൂല്യം ഞങ്ങൾ ചർച്ച ചെയ്യുന്നു അപ്പാച്ചെ കാഫ്കയ്ക്കായി ആമസോൺ സ്ട്രീമിംഗ് നിയന്ത്രിച്ചു (ആമസോൺ MSK), ആമസോൺ കൈനസിസ് ഡാറ്റ സ്ട്രീമുകൾ, Apache Flink-നുള്ള ആമസോൺ നിയന്ത്രിത സേവനം, ഒപ്പം ആമസോൺ കിനിസിസ് ഡാറ്റ ഫയർഹോസ് ജനറേറ്റീവ് AI ആപ്ലിക്കേഷനുകൾ നിർമ്മിക്കുന്നതിൽ.
പശ്ചാത്തലത്തിലുള്ള പഠനം
LLM-കൾ പോയിൻ്റ്-ഇൻ-ടൈം ഡാറ്റ ഉപയോഗിച്ച് പരിശീലിപ്പിക്കപ്പെടുന്നു, കൂടാതെ അനുമാന സമയത്ത് പുതിയ ഡാറ്റ ആക്സസ് ചെയ്യാനുള്ള അന്തർലീനമായ കഴിവില്ല. പുതിയ ഡാറ്റ ദൃശ്യമാകുമ്പോൾ, നിങ്ങൾ തുടർച്ചയായി മോഡൽ മികച്ചതാക്കുകയോ കൂടുതൽ പരിശീലിപ്പിക്കുകയോ ചെയ്യേണ്ടിവരും. ഇത് ചെലവേറിയ പ്രവർത്തനം മാത്രമല്ല, പ്രായോഗികമായി വളരെ പരിമിതപ്പെടുത്തുന്നു, കാരണം പുതിയ ഡാറ്റാ ജനറേഷൻ നിരക്ക് മികച്ച ട്യൂണിംഗിൻ്റെ വേഗതയെ മറികടക്കുന്നു. കൂടാതെ, LLM-കൾക്ക് സന്ദർഭോചിതമായ ധാരണ ഇല്ല, മാത്രമല്ല അവരുടെ പരിശീലന ഡാറ്റയെ മാത്രം ആശ്രയിക്കുകയും ചെയ്യുന്നു, അതിനാൽ ഭ്രമാത്മകതയ്ക്ക് സാധ്യതയുണ്ട്. ഇതിനർത്ഥം അവർക്ക് ഒഴുക്കുള്ളതും യോജിപ്പുള്ളതും വാക്യഘടനാപരമായി ശബ്ദമുള്ളതും എന്നാൽ വസ്തുതാപരമായി തെറ്റായതുമായ പ്രതികരണം സൃഷ്ടിക്കാൻ കഴിയും. അവയ്ക്ക് പ്രസക്തിയും വ്യക്തിവൽക്കരണവും സന്ദർഭവും ഇല്ല.
എന്നിരുന്നാലും, മോഡൽ വെയ്റ്റുകളിൽ മാറ്റം വരുത്താതെ കൂടുതൽ കൃത്യമായി പ്രതികരിക്കുന്നതിന് സന്ദർഭത്തിൽ നിന്ന് ലഭിക്കുന്ന ഡാറ്റയിൽ നിന്ന് പഠിക്കാനുള്ള ശേഷി LLM-കൾക്ക് ഉണ്ട്. ഇതിനെ വിളിക്കുന്നു പശ്ചാത്തലത്തിലുള്ള പഠനം, കൂടാതെ വ്യക്തിപരമാക്കിയ ഉത്തരങ്ങൾ നിർമ്മിക്കുന്നതിനോ ഓർഗനൈസേഷൻ നയങ്ങളുടെ പശ്ചാത്തലത്തിൽ കൃത്യമായ പ്രതികരണം നൽകുന്നതിനോ ഉപയോഗിക്കാം.
ഉദാഹരണത്തിന്, ഒരു ചാറ്റ്ബോട്ടിൽ, ഡാറ്റാ ഇവൻ്റുകൾ ഫ്ലൈറ്റുകൾ, ഹോട്ടലുകൾ എന്നിവയുടെ ഒരു ഇൻവെൻ്ററി അല്ലെങ്കിൽ സ്ട്രീമിംഗ് സ്റ്റോറേജ് എഞ്ചിനിലേക്ക് നിരന്തരം ഉൾപ്പെടുത്തുന്ന വിലയിലെ മാറ്റങ്ങളുമായി ബന്ധപ്പെട്ടിരിക്കുന്നു. കൂടാതെ, ഒരു സ്ട്രീം പ്രോസസർ ഉപയോഗിച്ച് ഡാറ്റ ഇവൻ്റുകൾ ഫിൽട്ടർ ചെയ്യുകയും സമ്പുഷ്ടമാക്കുകയും ഉപഭോഗ ഫോർമാറ്റിലേക്ക് മാറ്റുകയും ചെയ്യുന്നു. ഏറ്റവും പുതിയ സ്നാപ്പ്ഷോട്ട് അന്വേഷിച്ച് ഫലം അപ്ലിക്കേഷന് ലഭ്യമാക്കുന്നു. സ്ട്രീം പ്രോസസ്സിംഗിലൂടെ സ്നാപ്പ്ഷോട്ട് നിരന്തരം അപ്ഡേറ്റ് ചെയ്യുന്നു; അതിനാൽ, മോഡലിലേക്കുള്ള ഒരു ഉപയോക്താവിൻ്റെ പ്രോംപ്റ്റിൻ്റെ പശ്ചാത്തലത്തിലാണ് കാലികമായ ഡാറ്റ നൽകിയിരിക്കുന്നത്. വിലയിലും ലഭ്യതയിലും ഏറ്റവും പുതിയ മാറ്റങ്ങളുമായി പൊരുത്തപ്പെടാൻ ഇത് മോഡലിനെ അനുവദിക്കുന്നു. ഇനിപ്പറയുന്ന ഡയഗ്രം ഒരു അടിസ്ഥാന ഇൻ-കണ്ടെക്സ്റ്റ് ലേണിംഗ് വർക്ക്ഫ്ലോ ചിത്രീകരിക്കുന്നു.
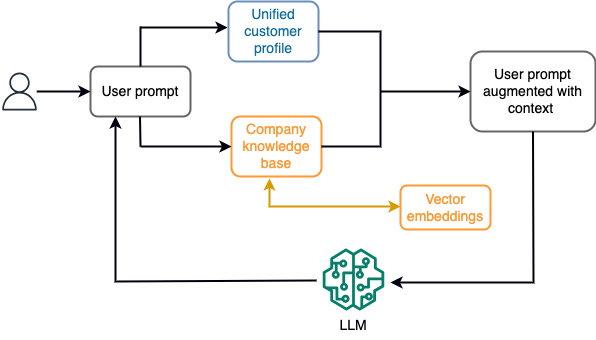
Retrieval Augmented Generation (RAG) എന്ന സാങ്കേതിക വിദ്യയാണ് സാധാരണയായി ഉപയോഗിക്കുന്ന ഇൻ-കണ്ടെക്സ്റ്റ് ലേണിംഗ് സമീപനം. RAG-ൽ, ഏറ്റവും പ്രസക്തമായ നയവും ഉപഭോക്തൃ രേഖകളും പോലെയുള്ള പ്രസക്തമായ വിവരങ്ങളും ഉപയോക്തൃ ചോദ്യത്തോടൊപ്പം പ്രോംപ്റ്റിലേക്ക് നിങ്ങൾ നൽകുന്നു. ഈ രീതിയിൽ, സന്ദർഭമായി നൽകിയിരിക്കുന്ന അധിക വിവരങ്ങൾ ഉപയോഗിച്ച് ഉപയോക്തൃ ചോദ്യത്തിനുള്ള ഉത്തരം LLM സൃഷ്ടിക്കുന്നു. RAG നെ കുറിച്ച് കൂടുതലറിയാൻ, റഫർ ചെയ്യുക ആമസോൺ സേജ് മേക്കർ ജമ്പ്സ്റ്റാർട്ടിലെ അടിസ്ഥാന മോഡലുകൾക്കൊപ്പം റിട്രീവൽ ഓഗ്മെന്റഡ് ജനറേഷൻ ഉപയോഗിച്ച് ചോദ്യത്തിന് ഉത്തരം നൽകുന്നു.
ഒരു RAG-അധിഷ്ഠിത ജനറേറ്റീവ് AI ആപ്ലിക്കേഷന് അതിൻ്റെ പരിശീലന ഡാറ്റയെയും വിജ്ഞാന അടിത്തറയിലെ പ്രസക്തമായ രേഖകളെയും അടിസ്ഥാനമാക്കി മാത്രമേ പൊതുവായ പ്രതികരണങ്ങൾ സൃഷ്ടിക്കാൻ കഴിയൂ. ആപ്ലിക്കേഷനിൽ നിന്ന് തത്സമയ വ്യക്തിഗത പ്രതികരണം പ്രതീക്ഷിക്കുമ്പോൾ ഈ പരിഹാരം കുറയുന്നു. ഉദാഹരണത്തിന്, ഒരു യാത്രാ ചാറ്റ്ബോട്ട് ഉപയോക്താവിൻ്റെ നിലവിലെ ബുക്കിംഗുകൾ, ലഭ്യമായ ഹോട്ടൽ, ഫ്ലൈറ്റ് ഇൻവെൻ്ററി എന്നിവയും മറ്റും പരിഗണിക്കുമെന്ന് പ്രതീക്ഷിക്കുന്നു. മാത്രമല്ല, പ്രസക്തമായ ഉപഭോക്തൃ വ്യക്തിഗത ഡാറ്റ (സാധാരണയായി അറിയപ്പെടുന്നത് ഏകീകൃത ഉപഭോക്തൃ പ്രൊഫൈൽ) സാധാരണയായി മാറ്റത്തിന് വിധേയമാണ്. ജനറേറ്റീവ് AI-യുടെ ഉപയോക്തൃ പ്രൊഫൈൽ ഡാറ്റാബേസ് അപ്ഡേറ്റ് ചെയ്യാൻ ഒരു ബാച്ച് പ്രോസസ്സ് ഉപയോഗിക്കുന്നുവെങ്കിൽ, പഴയ ഡാറ്റയെ അടിസ്ഥാനമാക്കി ഉപഭോക്താവിന് അതൃപ്തികരമായ പ്രതികരണങ്ങൾ ലഭിച്ചേക്കാം.
ഈ പോസ്റ്റിൽ, ഏകീകൃത ഉപഭോക്തൃ പ്രൊഫൈലുകളിലേക്കും ഓർഗനൈസേഷണൽ വിജ്ഞാന അടിത്തറയിലേക്കും തത്സമയ ആക്സസ്സിൽ നിന്ന് സന്ദർഭം ഉപയോഗിച്ച് ചോദ്യത്തിന് ഉത്തരം നൽകുന്ന ഏജൻ്റുമാരെ നിർമ്മിക്കുന്നതിന് ഉപയോഗിക്കുന്ന ഒരു RAG സൊല്യൂഷൻ മെച്ചപ്പെടുത്തുന്നതിനുള്ള സ്ട്രീം പ്രോസസ്സിംഗിൻ്റെ പ്രയോഗത്തെ ഞങ്ങൾ ചർച്ച ചെയ്യുന്നു.
തത്സമയ ഉപഭോക്തൃ പ്രൊഫൈൽ അപ്ഡേറ്റുകൾ
ഉപഭോക്തൃ രേഖകൾ സാധാരണയായി ഒരു ഓർഗനൈസേഷനിലെ ഡാറ്റ സ്റ്റോറുകളിൽ വിതരണം ചെയ്യപ്പെടുന്നു. പ്രസക്തവും കൃത്യവും കാലികവുമായ ഒരു ഉപഭോക്തൃ പ്രൊഫൈൽ നൽകുന്നതിന് നിങ്ങളുടെ ജനറേറ്റീവ് AI ആപ്ലിക്കേഷന്, വിതരണം ചെയ്ത ഡാറ്റ സ്റ്റോറുകളിൽ ഉടനീളം ഐഡൻ്റിറ്റി റെസല്യൂഷനും പ്രൊഫൈൽ അഗ്രഗേഷനും നടത്താൻ കഴിയുന്ന സ്ട്രീമിംഗ് ഡാറ്റ പൈപ്പ്ലൈനുകൾ നിർമ്മിക്കുന്നത് അത്യന്താപേക്ഷിതമാണ്. സ്ട്രീമിംഗ് ജോലികൾ സിസ്റ്റങ്ങളിൽ ഉടനീളം സമന്വയിപ്പിക്കുന്നതിന് പുതിയ ഡാറ്റ നിരന്തരം ഉൾക്കൊള്ളുന്നു, കൂടാതെ സമയത്തിൻ്റെ ജാലകങ്ങളിൽ കൂടുതൽ കാര്യക്ഷമമായി സമ്പുഷ്ടമാക്കൽ, പരിവർത്തനങ്ങൾ, ചേരലുകൾ, കൂട്ടിച്ചേർക്കലുകൾ എന്നിവ നടത്താനാകും. മാറ്റ ഡാറ്റ ക്യാപ്ചർ (CDC) ഇവൻ്റിൽ ഉറവിട റെക്കോർഡ്, അപ്ഡേറ്റുകൾ, സമയം, ഉറവിടം, വർഗ്ഗീകരണം (ഇൻസേർട്ട്, അപ്ഡേറ്റ് അല്ലെങ്കിൽ ഡിലീറ്റ്), മാറ്റത്തിൻ്റെ തുടക്കക്കാരൻ തുടങ്ങിയ മെറ്റാഡാറ്റയെ കുറിച്ചുള്ള വിവരങ്ങൾ അടങ്ങിയിരിക്കുന്നു.
ഏകീകൃത ഉപഭോക്തൃ പ്രൊഫൈലുകൾക്കായുള്ള CDC സ്ട്രീമിംഗ് ഉൾപ്പെടുത്തലിനും പ്രോസസ്സിംഗിനുമുള്ള ഒരു ഉദാഹരണ വർക്ക്ഫ്ലോ ഇനിപ്പറയുന്ന ഡയഗ്രം വ്യക്തമാക്കുന്നു.

ഈ വിഭാഗത്തിൽ, RAG അടിസ്ഥാനമാക്കിയുള്ള ജനറേറ്റീവ് AI ആപ്ലിക്കേഷനുകളെ പിന്തുണയ്ക്കുന്നതിന് ആവശ്യമായ CDC സ്ട്രീമിംഗ് പാറ്റേണിൻ്റെ പ്രധാന ഘടകങ്ങളെ ഞങ്ങൾ ചർച്ച ചെയ്യുന്നു.
CDC സ്ട്രീമിംഗ് ഉൾപ്പെടുത്തൽ
ഒരു ഉറവിട സിസ്റ്റത്തിൽ നിന്ന് (സാധാരണയായി ഇടപാട് ലോഗുകളോ ബിൻലോഗുകളോ വായിച്ചുകൊണ്ട്) ഡാറ്റാ മാറ്റങ്ങൾ ശേഖരിക്കുകയും ഒരു സ്ട്രീമിംഗ് ഡാറ്റാ സ്ട്രീമിലോ വിഷയത്തിലോ സംഭവിച്ച അതേ ക്രമത്തിൽ CDC ഇവൻ്റുകൾ എഴുതുകയും ചെയ്യുന്ന ഒരു പ്രക്രിയയാണ് CDC റെപ്ലിക്കേറ്റർ. പോലുള്ള ഉപകരണങ്ങൾ ഉപയോഗിച്ച് ഒരു ലോഗ് അധിഷ്ഠിത ക്യാപ്ചർ ഇതിൽ ഉൾപ്പെടുന്നു AWS ഡാറ്റാബേസ് മൈഗ്രേഷൻ സേവനം (AWS DMS) അല്ലെങ്കിൽ അപ്പാച്ചെ കാഫ്ക കണക്റ്റിനായി Debezium പോലുള്ള ഓപ്പൺ സോഴ്സ് കണക്ടറുകൾ. അപ്പാച്ചെ കാഫ്ക എൻവയോൺമെൻ്റിൻ്റെ ഭാഗമാണ് അപ്പാച്ചെ കാഫ്ക കണക്ട്, വിവിധ സ്രോതസ്സുകളിൽ നിന്ന് ഡാറ്റ ഉൾപ്പെടുത്താനും വിവിധ ലക്ഷ്യസ്ഥാനങ്ങളിലേക്ക് എത്തിക്കാനും ഇത് അനുവദിക്കുന്നു. നിങ്ങളുടെ അപ്പാച്ചെ കാഫ്ക കണക്റ്റർ പ്രവർത്തിപ്പിക്കാൻ കഴിയും ആമസോൺ MSK കണക്ട് ഒരു അപ്പാച്ചെ കാഫ്ക ക്ലസ്റ്ററിൻ്റെ കോൺഫിഗറേഷൻ, സജ്ജീകരണം, പ്രവർത്തിപ്പിക്കൽ എന്നിവയെക്കുറിച്ച് ആകുലപ്പെടാതെ മിനിറ്റുകൾക്കുള്ളിൽ. നിങ്ങളുടെ കണക്ടറിൻ്റെ കംപൈൽ ചെയ്ത കോഡ് അപ്ലോഡ് ചെയ്യേണ്ടതുണ്ട് ആമസോൺ ലളിതമായ സംഭരണ സേവനം (Amazon S3) കൂടാതെ നിങ്ങളുടെ ജോലിഭാരത്തിൻ്റെ നിർദ്ദിഷ്ട കോൺഫിഗറേഷൻ ഉപയോഗിച്ച് നിങ്ങളുടെ കണക്റ്റർ സജ്ജീകരിക്കുക.
ഡാറ്റ മാറ്റങ്ങൾ ക്യാപ്ചർ ചെയ്യുന്നതിനുള്ള മറ്റ് രീതികളും ഉണ്ട്. ഉദാഹരണത്തിന്, ആമസോൺ ഡൈനാമോഡിബി CDC ഡാറ്റ സ്ട്രീം ചെയ്യുന്നതിനുള്ള ഒരു സവിശേഷത നൽകുന്നു ആമസോൺ ഡൈനാമോഡിബി സ്ട്രീമുകൾ അല്ലെങ്കിൽ Kinesis ഡാറ്റ സ്ട്രീമുകൾ. ആമസോൺ എസ്3 ഒരു ട്രിഗർ നൽകുന്നു AWS Lambda ഒരു പുതിയ പ്രമാണം സംഭരിക്കുമ്പോൾ പ്രവർത്തനം.
സ്ട്രീമിംഗ് സംഭരണം
CDC ഇവൻ്റുകൾ പ്രോസസ്സ് ചെയ്യപ്പെടുന്നതിന് മുമ്പ് സംഭരിക്കുന്നതിനുള്ള ഒരു ഇൻ്റർമീഡിയറ്റ് ബഫറായി സ്ട്രീമിംഗ് സ്റ്റോറേജ് പ്രവർത്തിക്കുന്നു. സ്ട്രീമിംഗ് ഡാറ്റ സ്ട്രീമിംഗ് സ്റ്റോറേജ് വിശ്വസനീയമായ സംഭരണം നൽകുന്നു. രൂപകൽപ്പന പ്രകാരം, ഇത് വളരെ ലഭ്യവും ഹാർഡ്വെയർ അല്ലെങ്കിൽ നോഡ് പരാജയങ്ങളെ പ്രതിരോധിക്കുന്നതുമാണ് കൂടാതെ ഇവൻ്റുകൾ എഴുതിയിരിക്കുന്നതുപോലെ ക്രമം നിലനിർത്തുകയും ചെയ്യുന്നു. സ്ട്രീമിംഗ് സ്റ്റോറേജ് ഡാറ്റ ഇവൻ്റുകൾ സ്ഥിരമായി അല്ലെങ്കിൽ ഒരു നിശ്ചിത സമയത്തേക്ക് സംഭരിക്കാൻ കഴിയും. ഒരു തകരാർ അല്ലെങ്കിൽ വീണ്ടും പ്രോസസ്സിംഗ് ആവശ്യമുണ്ടെങ്കിൽ സ്ട്രീമിൻ്റെ ഒരു ഭാഗത്ത് നിന്ന് റീഡ് ചെയ്യാൻ ഇത് സ്ട്രീം പ്രോസസറുകളെ അനുവദിക്കുന്നു. Kinesis ഡാറ്റ സ്ട്രീമുകൾ ഒരു സെർവർലെസ് സ്ട്രീമിംഗ് ഡാറ്റാ സേവനമാണ്, അത് ഡാറ്റ സ്ട്രീമുകൾ സ്കെയിലിൽ പിടിച്ചെടുക്കാനും പ്രോസസ്സ് ചെയ്യാനും സംഭരിക്കാനും എളുപ്പമാക്കുന്നു. Apache Kafka പ്രവർത്തിപ്പിക്കുന്നതിനായി AWS നൽകുന്ന പൂർണ്ണമായി കൈകാര്യം ചെയ്യപ്പെടുന്നതും വളരെ ലഭ്യവും സുരക്ഷിതവുമായ സേവനമാണ് Amazon MSK.
സ്ട്രീം പ്രോസസ്സിംഗ്
ഉയർന്ന ഡാറ്റ ത്രൂപുട്ട് കൈകാര്യം ചെയ്യുന്നതിനായി സ്ട്രീം പ്രോസസ്സിംഗ് സിസ്റ്റങ്ങൾ സമാന്തരമായി രൂപകൽപ്പന ചെയ്തിരിക്കണം. ഒന്നിലധികം കമ്പ്യൂട്ട് നോഡുകളിൽ പ്രവർത്തിക്കുന്ന ഒന്നിലധികം ജോലികൾക്കിടയിൽ അവർ ഇൻപുട്ട് സ്ട്രീം വിഭജിക്കണം. ഒരു പ്രവർത്തനത്തിൻ്റെ ഫലം അടുത്തതിലേക്ക് നെറ്റ്വർക്കിലൂടെ അയയ്ക്കാൻ ടാസ്ക്കുകൾക്ക് കഴിയണം, ജോയിൻ ചെയ്യൽ, ഫിൽട്ടറിംഗ്, സമ്പുഷ്ടമാക്കൽ, അഗ്രഗേഷൻ തുടങ്ങിയ പ്രവർത്തനങ്ങൾ നടത്തുമ്പോൾ സമാന്തരമായി ഡാറ്റ പ്രോസസ്സ് ചെയ്യുന്നത് സാധ്യമാക്കുന്നു. സ്ട്രീം പ്രോസസ്സിംഗ് ആപ്ലിക്കേഷനുകൾക്ക് ഇവൻ്റുകൾ വൈകിയെത്തിയതോ ശരിയായ കണക്കുകൂട്ടൽ സിസ്റ്റം സമയത്തേക്കാൾ ഇവൻ്റുകൾ സംഭവിക്കുന്ന സമയത്തെ ആശ്രയിച്ചിരിക്കുന്നതോ ആയ ഉപയോഗ കേസുകൾക്കായുള്ള ഇവൻ്റ് സമയവുമായി ബന്ധപ്പെട്ട് ഇവൻ്റുകൾ പ്രോസസ്സ് ചെയ്യാൻ കഴിയണം. കൂടുതൽ വിവരങ്ങൾക്ക്, റഫർ ചെയ്യുക സമയത്തെക്കുറിച്ചുള്ള ആശയങ്ങൾ: ഇവൻ്റ് സമയവും പ്രോസസ്സിംഗ് സമയവും.
ഒരു ടാർഗെറ്റ് സിസ്റ്റത്തിലേക്ക് ഔട്ട്പുട്ട് ചെയ്യേണ്ട ഡാറ്റ ഇവൻ്റുകളുടെ രൂപത്തിൽ സ്ട്രീം പ്രക്രിയകൾ തുടർച്ചയായി ഫലങ്ങൾ നൽകുന്നു. ഒരു ടാർഗെറ്റ് സിസ്റ്റം എന്നത് പ്രോസസുമായി നേരിട്ട് സംയോജിപ്പിക്കാൻ കഴിയുന്ന അല്ലെങ്കിൽ ഇടനിലക്കാരിൽ പോലെ സ്ട്രീമിംഗ് സ്റ്റോറേജ് വഴി സംയോജിപ്പിക്കാൻ കഴിയുന്ന ഏതൊരു സിസ്റ്റവും ആകാം. സ്ട്രീം പ്രോസസ്സിംഗിനായി നിങ്ങൾ തിരഞ്ഞെടുക്കുന്ന ചട്ടക്കൂടിനെ ആശ്രയിച്ച്, ലഭ്യമായ സിങ്ക് കണക്ടറുകൾ അനുസരിച്ച് ടാർഗെറ്റ് സിസ്റ്റങ്ങൾക്കായി നിങ്ങൾക്ക് വ്യത്യസ്ത ഓപ്ഷനുകൾ ഉണ്ടായിരിക്കും. ഒരു ഇടനില സ്ട്രീമിംഗ് സ്റ്റോറേജിലേക്ക് ഫലങ്ങൾ എഴുതാൻ നിങ്ങൾ തീരുമാനിക്കുകയാണെങ്കിൽ, ഒരു അപ്പാച്ചെ കാഫ്ക സിങ്ക് കണക്റ്റർ പ്രവർത്തിപ്പിക്കുന്നത് പോലെയുള്ള ഇവൻ്റുകൾ വായിക്കുകയും ടാർഗെറ്റ് സിസ്റ്റത്തിൽ മാറ്റങ്ങൾ പ്രയോഗിക്കുകയും ചെയ്യുന്ന ഒരു പ്രത്യേക പ്രോസസ്സ് നിങ്ങൾക്ക് നിർമ്മിക്കാൻ കഴിയും. നിങ്ങൾ തിരഞ്ഞെടുക്കുന്ന ഓപ്ഷൻ പരിഗണിക്കാതെ തന്നെ, CDC ഡാറ്റയ്ക്ക് അതിൻ്റെ സ്വഭാവം കാരണം അധിക കൈകാര്യം ചെയ്യൽ ആവശ്യമാണ്. CDC ഇവൻ്റുകൾ അപ്ഡേറ്റുകളെക്കുറിച്ചോ ഇല്ലാതാക്കുന്നതിനെക്കുറിച്ചോ ഉള്ള വിവരങ്ങൾ വഹിക്കുന്നതിനാൽ, അവ ശരിയായ ക്രമത്തിൽ ടാർഗെറ്റ് സിസ്റ്റത്തിൽ ലയിപ്പിക്കേണ്ടത് പ്രധാനമാണ്. തെറ്റായ ക്രമത്തിലാണ് മാറ്റങ്ങൾ പ്രയോഗിച്ചതെങ്കിൽ, ടാർഗെറ്റ് സിസ്റ്റം അതിൻ്റെ ഉറവിടവുമായി സമന്വയിപ്പിക്കില്ല.
അപ്പാച്ചെ ഫ്ലിങ്ക് കുറഞ്ഞ ലേറ്റൻസിക്കും ഉയർന്ന ത്രൂപുട്ട് കഴിവുകൾക്കും പേരുകേട്ട ശക്തമായ സ്ട്രീം പ്രോസസ്സിംഗ് ചട്ടക്കൂടാണ്. ഇത് ഇവൻ്റ് ടൈം പ്രോസസ്സിംഗ്, കൃത്യമായി ഒരിക്കൽ പ്രോസസ്സിംഗ് സെമാൻ്റിക്സ്, ഉയർന്ന തെറ്റ് സഹിഷ്ണുത എന്നിവ പിന്തുണയ്ക്കുന്നു. കൂടാതെ, വിളിക്കപ്പെടുന്ന ഒരു പ്രത്യേക ഘടന വഴി സിഡിസി ഡാറ്റയ്ക്ക് നേറ്റീവ് പിന്തുണ നൽകുന്നു ചലനാത്മക പട്ടികകൾ. ഡൈനാമിക് ടേബിളുകൾ സോഴ്സ് ഡാറ്റാബേസ് ടേബിളുകളെ അനുകരിക്കുകയും സ്ട്രീമിംഗ് ഡാറ്റയുടെ കോളം പ്രാതിനിധ്യം നൽകുകയും ചെയ്യുന്നു. പ്രോസസ്സ് ചെയ്യുന്ന ഓരോ ഇവൻ്റിലും ഡൈനാമിക് ടേബിളുകളിലെ ഡാറ്റ മാറുന്നു. പുതിയ റെക്കോർഡുകൾ എപ്പോൾ വേണമെങ്കിലും കൂട്ടിച്ചേർക്കുകയോ അപ്ഡേറ്റ് ചെയ്യുകയോ ഇല്ലാതാക്കുകയോ ചെയ്യാം. ഡൈനാമിക് ടേബിളുകൾ ഓരോ റെക്കോർഡ് ഓപ്പറേഷനും (ഇൻസേർട്ട് ചെയ്യുക, അപ്ഡേറ്റ് ചെയ്യുക, ഡിലീറ്റ് ചെയ്യുക) പ്രത്യേകമായി നടപ്പിലാക്കേണ്ട അധിക ലോജിക്കിനെ അമൂർത്തമാക്കുന്നു. കൂടുതൽ വിവരങ്ങൾക്ക്, റഫർ ചെയ്യുക ഡൈനാമിക് ടേബിളുകൾ.
കൂടെ Apache Flink-നുള്ള ആമസോൺ നിയന്ത്രിത സേവനം, നിങ്ങൾക്ക് Apache Flink ജോലികൾ പ്രവർത്തിപ്പിക്കാനും മറ്റ് AWS സേവനങ്ങളുമായി സംയോജിപ്പിക്കാനും കഴിയും. നിയന്ത്രിക്കാൻ സെർവറുകളും ക്ലസ്റ്ററുകളും ഇല്ല, കൂടാതെ സജ്ജീകരിക്കാൻ കംപ്യൂട്ടും സ്റ്റോറേജ് ഇൻഫ്രാസ്ട്രക്ചറും ഇല്ല.
AWS പശ പൂർണ്ണമായി കൈകാര്യം ചെയ്യപ്പെടുന്ന എക്സ്ട്രാക്റ്റ്, ട്രാൻസ്ഫോം, ലോഡ് (ഇടിഎൽ) സേവനമാണ്, അതായത് നിങ്ങൾക്കുള്ള ഇൻഫ്രാസ്ട്രക്ചർ പ്രൊവിഷനിംഗ്, സ്കെയിലിംഗ്, മെയിൻ്റനൻസ് എന്നിവ AWS കൈകാര്യം ചെയ്യുന്നു. ഇത് പ്രാഥമികമായി ETL കഴിവുകൾക്ക് പേരുകേട്ടതാണെങ്കിലും, AWS ഗ്ലൂ സ്പാർക്ക് സ്ട്രീമിംഗ് ആപ്ലിക്കേഷനുകൾക്കും ഉപയോഗിക്കാം. സിഡിസി ഡാറ്റ പ്രോസസ്സ് ചെയ്യുന്നതിനും പരിവർത്തനം ചെയ്യുന്നതിനും AWS Glue-ന് Kinesis Data Streams, Amazon MSK എന്നിവ പോലുള്ള സ്ട്രീമിംഗ് ഡാറ്റ സേവനങ്ങളുമായി സംവദിക്കാൻ കഴിയും. AWS Glue-ന് Lambda പോലുള്ള മറ്റ് AWS സേവനങ്ങളുമായി പരിധികളില്ലാതെ സംയോജിപ്പിക്കാൻ കഴിയും, AWS സ്റ്റെപ്പ് ഫംഗ്ഷനുകൾ, കൂടാതെ DynamoDB, ഡാറ്റ പ്രോസസ്സിംഗ് പൈപ്പ് ലൈനുകൾ നിർമ്മിക്കുന്നതിനും നിയന്ത്രിക്കുന്നതിനുമുള്ള ഒരു സമഗ്രമായ ആവാസവ്യവസ്ഥ നിങ്ങൾക്ക് നൽകുന്നു.
ഏകീകൃത ഉപഭോക്തൃ പ്രൊഫൈൽ
വിവിധ സോഴ്സ് സിസ്റ്റങ്ങളിൽ ഉടനീളമുള്ള ഉപഭോക്തൃ പ്രൊഫൈലിൻ്റെ ഏകീകരണം മറികടക്കാൻ ശക്തമായ ഡാറ്റ പൈപ്പ് ലൈനുകളുടെ വികസനം ആവശ്യമാണ്. എല്ലാ റെക്കോർഡുകളും ഒരു ഡാറ്റ സ്റ്റോറിലേക്ക് കൊണ്ടുവരാനും സമന്വയിപ്പിക്കാനും കഴിയുന്ന ഡാറ്റ പൈപ്പ് ലൈനുകൾ നിങ്ങൾക്ക് ആവശ്യമാണ്. RAG അടിസ്ഥാനമാക്കിയുള്ള ജനറേറ്റീവ് AI ആപ്ലിക്കേഷനുകളുടെ പ്രവർത്തന കാര്യക്ഷമതയ്ക്ക് ആവശ്യമായ സമഗ്രമായ ഉപഭോക്തൃ റെക്കോർഡ് കാഴ്ച ഈ ഡാറ്റ സ്റ്റോർ നിങ്ങളുടെ സ്ഥാപനത്തിന് നൽകുന്നു. അത്തരമൊരു ഡാറ്റ സ്റ്റോർ നിർമ്മിക്കുന്നതിന്, ഘടനയില്ലാത്ത ഡാറ്റ സ്റ്റോർ മികച്ചതാണ്.
ഒരു ഐഡൻ്റിറ്റി ഗ്രാഫ് ഒരു ഏകീകൃത ഉപഭോക്തൃ പ്രൊഫൈൽ സൃഷ്ടിക്കുന്നതിനുള്ള ഒരു ഉപയോഗപ്രദമായ ഘടനയാണ്, കാരണം അത് വിവിധ സ്രോതസ്സുകളിൽ നിന്നുള്ള ഉപഭോക്തൃ ഡാറ്റ ഏകീകരിക്കുകയും സംയോജിപ്പിക്കുകയും ചെയ്യുന്നു, ഡാറ്റ കൃത്യതയും ഡ്യൂപ്ലിക്കേഷനും ഉറപ്പാക്കുന്നു, തത്സമയ അപ്ഡേറ്റുകൾ വാഗ്ദാനം ചെയ്യുന്നു, ക്രോസ്-സിസ്റ്റം സ്ഥിതിവിവരക്കണക്കുകൾ ബന്ധിപ്പിക്കുന്നു, വ്യക്തിഗതമാക്കൽ പ്രാപ്തമാക്കുന്നു, ഉപഭോക്തൃ അനുഭവം മെച്ചപ്പെടുത്തുന്നു. റെഗുലേറ്ററി കംപ്ലയിൻസിനെ പിന്തുണയ്ക്കുന്നു. ഈ ഏകീകൃത ഉപഭോക്തൃ പ്രൊഫൈൽ, ഉപഭോക്താക്കളെ ഫലപ്രദമായി മനസ്സിലാക്കുന്നതിനും അവരുമായി ഇടപഴകുന്നതിനും ഡാറ്റാ സ്വകാര്യതാ നിയന്ത്രണങ്ങൾ പാലിക്കുന്നതിനും ആത്യന്തികമായി ഉപഭോക്തൃ അനുഭവങ്ങൾ മെച്ചപ്പെടുത്തുന്നതിനും ബിസിനസ്സ് വളർച്ചയെ നയിക്കുന്നതിനും ജനറേറ്റീവ് AI ആപ്ലിക്കേഷനെ പ്രാപ്തരാക്കുന്നു. നിങ്ങളുടെ ഐഡൻ്റിറ്റി ഗ്രാഫ് സൊല്യൂഷൻ ഉപയോഗിച്ച് നിങ്ങൾക്ക് നിർമ്മിക്കാം ആമസോൺ നെപ്റ്റ്യൂൺ, വേഗതയേറിയതും വിശ്വസനീയവും പൂർണ്ണമായി കൈകാര്യം ചെയ്യുന്നതുമായ ഗ്രാഫ് ഡാറ്റാബേസ് സേവനം.
ഘടനാരഹിതമായ കീ-മൂല്യം ഒബ്ജക്റ്റുകൾക്കായി AWS മറ്റ് ചില നിയന്ത്രിതവും സെർവർരഹിതവുമായ NoSQL സംഭരണ സേവന ഓഫറുകൾ നൽകുന്നു. ആമസോൺ ഡോക്യുമെന്റ് ഡിബി (MongoDB അനുയോജ്യതയോടെ) വേഗതയേറിയതും അളക്കാവുന്നതും വളരെ ലഭ്യവും പൂർണ്ണമായി കൈകാര്യം ചെയ്യുന്നതുമായ ഒരു സംരംഭമാണ് പ്രമാണ ഡാറ്റാബേസ് നേറ്റീവ് JSON വർക്ക്ലോഡുകളെ പിന്തുണയ്ക്കുന്ന സേവനം. DynamoDB എന്നത് പൂർണ്ണമായി കൈകാര്യം ചെയ്യപ്പെടുന്ന NoSQL ഡാറ്റാബേസ് സേവനമാണ്, അത് തടസ്സമില്ലാത്ത സ്കേലബിളിറ്റിയോടെ വേഗതയേറിയതും പ്രവചിക്കാവുന്നതുമായ പ്രകടനം നൽകുന്നു.
തത്സമയ സ്ഥാപന വിജ്ഞാന അടിസ്ഥാന അപ്ഡേറ്റുകൾ
ഉപഭോക്തൃ റെക്കോർഡുകൾക്ക് സമാനമായി, കമ്പനി നയങ്ങളും ഓർഗനൈസേഷണൽ ഡോക്യുമെൻ്റുകളും പോലുള്ള ആന്തരിക വിജ്ഞാന ശേഖരണങ്ങൾ സ്റ്റോറേജ് സിസ്റ്റങ്ങളിൽ ഉടനീളം നിശബ്ദമാണ്. ഇത് സാധാരണയായി ഘടനാരഹിതമായ ഡാറ്റയാണ്, ഇത് ഒരു നോൺ-ഇൻക്രിമെൻ്റൽ ഫാഷനിൽ അപ്ഡേറ്റ് ചെയ്യപ്പെടുന്നു. AI ആപ്ലിക്കേഷനുകൾക്കായി ഘടനാരഹിതമായ ഡാറ്റ ഉപയോഗിക്കുന്നത് വെക്റ്റർ എംബെഡിംഗുകൾ ഉപയോഗിച്ച് ഫലപ്രദമാണ്, ഇത് ടെക്സ്റ്റ് ഫയലുകൾ, ഇമേജുകൾ, ഓഡിയോ ഫയലുകൾ എന്നിവ പോലുള്ള ഉയർന്ന അളവിലുള്ള ഡാറ്റയെ മൾട്ടി-ഡൈമൻഷണൽ ന്യൂമറിക് ആയി പ്രതിനിധീകരിക്കുന്നതിനുള്ള ഒരു സാങ്കേതികതയാണ്.
AWS നിരവധി നൽകുന്നു വെക്റ്റർ എഞ്ചിൻ സേവനങ്ങൾ, അതുപോലെ Amazon OpenSearch Serverless, ആമസോൺ കേന്ദ്ര, ഒപ്പം ആമസോൺ അറോറ PostgreSQL-അനുയോജ്യമായ പതിപ്പ് വെക്റ്റർ എംബെഡിംഗുകൾ സംഭരിക്കുന്നതിനുള്ള pgvector വിപുലീകരണത്തോടൊപ്പം. ജനറേറ്റീവ് AI ആപ്ലിക്കേഷനുകൾക്ക് ഉപയോക്തൃ പ്രോംപ്റ്റിനെ ഒരു വെക്ടറാക്കി മാറ്റുന്നതിലൂടെ ഉപയോക്തൃ അനുഭവം മെച്ചപ്പെടുത്താനും സാന്ദർഭികമായി പ്രസക്തമായ വിവരങ്ങൾ വീണ്ടെടുക്കുന്നതിന് വെക്റ്റർ എഞ്ചിൻ അന്വേഷിക്കാനും ഇത് ഉപയോഗിക്കാനും കഴിയും. വീണ്ടെടുക്കപ്പെട്ട പ്രോംപ്റ്റും വെക്റ്റർ ഡാറ്റയും കൂടുതൽ കൃത്യവും വ്യക്തിഗതവുമായ പ്രതികരണം ലഭിക്കുന്നതിന് LLM-ന് കൈമാറുന്നു.
വെക്റ്റർ എംബെഡിംഗുകൾക്കായുള്ള സ്ട്രീം-പ്രോസസ്സിംഗ് വർക്ക്ഫ്ലോയുടെ ഉദാഹരണം ഇനിപ്പറയുന്ന ഡയഗ്രം വ്യക്തമാക്കുന്നു.
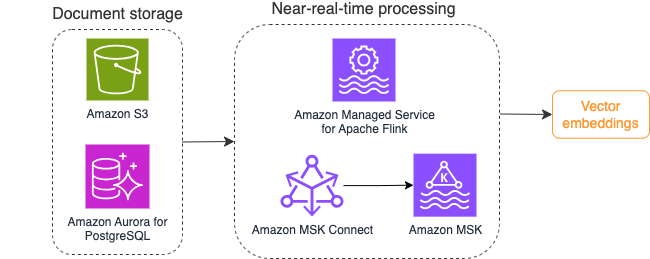
വെക്റ്റർ ഡാറ്റ സ്റ്റോറിലേക്ക് എഴുതുന്നതിന് മുമ്പ് നോളജ് ബേസ് ഉള്ളടക്കങ്ങൾ വെക്റ്റർ എംബെഡിംഗുകളിലേക്ക് പരിവർത്തനം ചെയ്യേണ്ടതുണ്ട്. ആമസോൺ ബെഡ്റോക്ക് or ആമസോൺ സേജ് മേക്കർ നിങ്ങൾ തിരഞ്ഞെടുത്ത മോഡൽ ആക്സസ് ചെയ്യാനും ഈ പരിവർത്തനത്തിനായി ഒരു സ്വകാര്യ എൻഡ്പോയിൻ്റ് വെളിപ്പെടുത്താനും നിങ്ങളെ സഹായിക്കും. കൂടാതെ, ഈ എൻഡ് പോയിൻ്റുകളുമായി സംയോജിപ്പിക്കാൻ നിങ്ങൾക്ക് LangChain പോലുള്ള ലൈബ്രറികൾ ഉപയോഗിക്കാം. ഒരു ബാച്ച് പ്രോസസ്സ് നിർമ്മിക്കുന്നത് നിങ്ങളുടെ വിജ്ഞാന അടിസ്ഥാന ഉള്ളടക്കത്തെ വെക്റ്റർ ഡാറ്റയിലേക്ക് പരിവർത്തനം ചെയ്യാനും തുടക്കത്തിൽ ഒരു വെക്റ്റർ ഡാറ്റാബേസിൽ സംഭരിക്കാനും സഹായിക്കും. എന്നിരുന്നാലും, നിങ്ങളുടെ വിജ്ഞാന അടിസ്ഥാന ഉള്ളടക്കത്തിലെ മാറ്റങ്ങളുമായി നിങ്ങളുടെ വെക്റ്റർ ഡാറ്റാബേസ് സമന്വയിപ്പിക്കുന്നതിന് ഡോക്യുമെൻ്റുകൾ വീണ്ടും പ്രോസസ്സ് ചെയ്യുന്നതിന് നിങ്ങൾ ഒരു ഇടവേളയെ ആശ്രയിക്കേണ്ടതുണ്ട്. ധാരാളം പ്രമാണങ്ങൾ ഉള്ളതിനാൽ, ഈ പ്രക്രിയ കാര്യക്ഷമമല്ല. ഈ ഇടവേളകൾക്കിടയിൽ, നിങ്ങളുടെ ജനറേറ്റീവ് AI ആപ്ലിക്കേഷൻ ഉപയോക്താക്കൾക്ക് പഴയ ഉള്ളടക്കം അനുസരിച്ച് ഉത്തരങ്ങൾ ലഭിക്കും, അല്ലെങ്കിൽ പുതിയ ഉള്ളടക്കം ഇതുവരെ വെക്ടറൈസ് ചെയ്യാത്തതിനാൽ കൃത്യമല്ലാത്ത ഉത്തരം ലഭിക്കും.
സ്ട്രീം പ്രോസസ്സിംഗ് ഈ വെല്ലുവിളികൾക്ക് അനുയോജ്യമായ ഒരു പരിഹാരമാണ്. ഇത് തുടക്കത്തിൽ നിലവിലുള്ള ഡോക്യുമെൻ്റുകൾ പ്രകാരം ഇവൻ്റുകൾ നിർമ്മിക്കുകയും സോഴ്സ് സിസ്റ്റം കൂടുതൽ നിരീക്ഷിക്കുകയും അവ സംഭവിക്കുമ്പോൾ തന്നെ ഒരു ഡോക്യുമെൻ്റ് മാറ്റ പരിപാടി സൃഷ്ടിക്കുകയും ചെയ്യുന്നു. ഈ ഇവൻ്റുകൾ സ്ട്രീമിംഗ് സ്റ്റോറേജിൽ സംഭരിക്കാനും സ്ട്രീമിംഗ് ജോലിയിലൂടെ പ്രോസസ്സ് ചെയ്യാൻ കാത്തിരിക്കാനും കഴിയും. ഒരു സ്ട്രീമിംഗ് ജോലി ഈ ഇവൻ്റുകൾ വായിക്കുകയും ഡോക്യുമെൻ്റിൻ്റെ ഉള്ളടക്കം ലോഡുചെയ്യുകയും പദങ്ങളുടെ അനുബന്ധ ടോക്കണുകളുടെ ഒരു നിരയിലേക്ക് ഉള്ളടക്കത്തെ മാറ്റുകയും ചെയ്യുന്നു. ഓരോ ടോക്കണും ഒരു എംബെഡിംഗ് FM-ലേക്കുള്ള API കോൾ വഴി വെക്റ്റർ ഡാറ്റയായി രൂപാന്തരപ്പെടുന്നു. ഒരു സിങ്ക് ഓപ്പറേറ്റർ വഴി വെക്റ്റർ സ്റ്റോറേജിലേക്ക് സംഭരണത്തിനായി ഫലങ്ങൾ അയയ്ക്കുന്നു.
നിങ്ങളുടെ പ്രമാണങ്ങൾ സംഭരിക്കുന്നതിന് നിങ്ങൾ Amazon S3 ഉപയോഗിക്കുകയാണെങ്കിൽ, ലാംഡയ്ക്കായുള്ള S3 ഒബ്ജക്റ്റ് മാറ്റ ട്രിഗറുകൾ അടിസ്ഥാനമാക്കി നിങ്ങൾക്ക് ഒരു ഇവൻ്റ്-സോഴ്സ് ആർക്കിടെക്ചർ നിർമ്മിക്കാൻ കഴിയും. ഒരു ലാംഡ ഫംഗ്ഷന് ആവശ്യമുള്ള ഫോർമാറ്റിൽ ഒരു ഇവൻ്റ് സൃഷ്ടിക്കാനും അത് നിങ്ങളുടെ സ്ട്രീമിംഗ് സ്റ്റോറേജിലേക്ക് എഴുതാനും കഴിയും.
ഒരു സ്ട്രീമിംഗ് ജോലിയായി പ്രവർത്തിക്കാൻ നിങ്ങൾക്ക് Apache Flink ഉപയോഗിക്കാനും കഴിയും. അപ്പാച്ചെ ഫ്ലിങ്ക് നേറ്റീവ് ഫയൽസിസ്റ്റം സോഴ്സ് കണക്ടർ നൽകുന്നു, അതിന് നിലവിലുള്ള ഫയലുകൾ കണ്ടെത്താനും അവയുടെ ഉള്ളടക്കങ്ങൾ തുടക്കത്തിൽ വായിക്കാനും കഴിയും. അതിനുശേഷം, പുതിയ ഫയലുകൾക്കായി നിങ്ങളുടെ ഫയൽ സിസ്റ്റം തുടർച്ചയായി നിരീക്ഷിക്കാനും അവയുടെ ഉള്ളടക്കം പിടിച്ചെടുക്കാനും ഇതിന് കഴിയും. പ്ലെയിൻ ടെക്സ്റ്റ്, അവ്റോ, സിഎസ്വി, പാർക്ക്വെറ്റ് എന്നിവയും അതിലേറെയും ഉള്ള ഫോർമാറ്റ് ഉപയോഗിച്ച് ആമസോൺ എസ് 3 അല്ലെങ്കിൽ എച്ച്ഡിഎഫ്എസ് പോലുള്ള വിതരണം ചെയ്ത ഫയൽ സിസ്റ്റങ്ങളിൽ നിന്നുള്ള ഒരു കൂട്ടം ഫയലുകൾ വായിക്കുന്നതിനെ കണക്റ്റർ പിന്തുണയ്ക്കുകയും സ്ട്രീമിംഗ് റെക്കോർഡ് സൃഷ്ടിക്കുകയും ചെയ്യുന്നു. പൂർണ്ണമായി നിയന്ത്രിത സേവനം എന്ന നിലയിൽ, അപ്പാച്ചെ ഫ്ലിങ്കിനുള്ള നിയന്ത്രിത സേവനം ഫ്ലിങ്ക് ജോലികൾ വിന്യസിക്കുന്നതിനും പരിപാലിക്കുന്നതിനുമുള്ള പ്രവർത്തന ഓവർഹെഡ് നീക്കം ചെയ്യുന്നു, ഇത് നിങ്ങളുടെ സ്ട്രീമിംഗ് ആപ്ലിക്കേഷനുകൾ നിർമ്മിക്കുന്നതിലും സ്കെയിൽ ചെയ്യുന്നതിലും ശ്രദ്ധ കേന്ദ്രീകരിക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു. ആമസോൺ MSK അല്ലെങ്കിൽ Kinesis ഡാറ്റ സ്ട്രീമുകൾ പോലെയുള്ള AWS സ്ട്രീമിംഗ് സേവനങ്ങളിലേക്കുള്ള തടസ്സങ്ങളില്ലാത്ത സംയോജനത്തോടെ, തത്സമയ സ്ട്രീമിംഗ് ഡാറ്റ കൈകാര്യം ചെയ്യുന്നതിനായി വിശ്വസനീയവും കാര്യക്ഷമവുമായ ഫ്ലിങ്ക് ആപ്ലിക്കേഷനുകൾ പ്രദാനം ചെയ്യുന്ന ഓട്ടോമാറ്റിക് സ്കെയിലിംഗ്, സുരക്ഷ, പ്രതിരോധശേഷി എന്നിവ പോലുള്ള സവിശേഷതകൾ ഇത് നൽകുന്നു.
നിങ്ങളുടെ DevOps മുൻഗണനയെ അടിസ്ഥാനമാക്കി, സ്ട്രീമിംഗ് റെക്കോർഡുകൾ സംഭരിക്കുന്നതിന് Kinesis ഡാറ്റ സ്ട്രീമുകൾ അല്ലെങ്കിൽ Amazon MSK എന്നിവയിൽ നിന്ന് നിങ്ങൾക്ക് തിരഞ്ഞെടുക്കാം. Kinesis ഡാറ്റ സ്ട്രീമുകൾ ഇഷ്ടാനുസൃത സ്ട്രീമിംഗ് ഡാറ്റ ആപ്ലിക്കേഷനുകൾ നിർമ്മിക്കുന്നതിലും കൈകാര്യം ചെയ്യുന്നതിലും ഉള്ള സങ്കീർണ്ണതകളെ ലളിതമാക്കുന്നു, ഇത് ഇൻഫ്രാസ്ട്രക്ചർ മെയിൻ്റനൻസിനേക്കാൾ നിങ്ങളുടെ ഡാറ്റയിൽ നിന്നുള്ള സ്ഥിതിവിവരക്കണക്കുകൾ നേടുന്നതിൽ ശ്രദ്ധ കേന്ദ്രീകരിക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു. അപ്പാച്ചെ കാഫ്ക ഉപയോഗിക്കുന്ന ഉപഭോക്താക്കൾ പലപ്പോഴും ആമസോൺ എംഎസ്കെ തിരഞ്ഞെടുക്കുന്നത് അതിൻ്റെ നേർരേഖയും സ്കേലബിളിറ്റിയും AWS പരിതസ്ഥിതിയിലുള്ള അപ്പാച്ചെ കാഫ്ക ക്ലസ്റ്ററുകൾക്ക് മേൽനോട്ടം വഹിക്കാനുള്ള വിശ്വാസ്യതയുമാണ്. പൂർണ്ണമായും കൈകാര്യം ചെയ്യപ്പെടുന്ന ഒരു സേവനമെന്ന നിലയിൽ, നിങ്ങളുടെ സ്ട്രീമിംഗ് ആപ്ലിക്കേഷനുകൾ നിർമ്മിക്കുന്നതിലും വിപുലീകരിക്കുന്നതിലും ശ്രദ്ധ കേന്ദ്രീകരിക്കാൻ നിങ്ങളെ പ്രാപ്തരാക്കുന്ന അപ്പാച്ചെ കാഫ്ക ക്ലസ്റ്ററുകൾ വിന്യസിക്കുന്നതും പരിപാലിക്കുന്നതുമായി ബന്ധപ്പെട്ട പ്രവർത്തന സങ്കീർണ്ണതകൾ Amazon MSK ഏറ്റെടുക്കുന്നു.
ഒരു RESTful API സംയോജനം ഈ പ്രക്രിയയുടെ സ്വഭാവത്തിന് അനുയോജ്യമായതിനാൽ, പരാജയങ്ങൾ ട്രാക്ക് ചെയ്യാനും പരാജയപ്പെട്ട അഭ്യർത്ഥനയ്ക്കായി വീണ്ടും ശ്രമിക്കാനും RESTful API കോളുകൾ വഴിയുള്ള ഒരു സംസ്ഥാന സമ്പുഷ്ടീകരണ പാറ്റേൺ പിന്തുണയ്ക്കുന്ന ഒരു ചട്ടക്കൂട് നിങ്ങൾക്ക് ആവശ്യമാണ്. അപ്പാച്ചെ ഫ്ലിങ്ക് വീണ്ടും മെമ്മറി വേഗതയിൽ സ്റ്റേറ്റ്ഫുൾ പ്രവർത്തനങ്ങൾ ചെയ്യാൻ കഴിയുന്ന ഒരു ചട്ടക്കൂടാണ്. Apache Flink വഴി API കോളുകൾ വിളിക്കാനുള്ള മികച്ച വഴികൾ മനസിലാക്കാൻ, റഫർ ചെയ്യുക Apache Flink-നുള്ള ആമസോൺ Kinesis ഡാറ്റാ അനലിറ്റിക്സിലെ പൊതുവായ സ്ട്രീമിംഗ് ഡാറ്റാ സമ്പുഷ്ടീകരണ പാറ്റേണുകൾ.
Pgvector അല്ലെങ്കിൽ PostgreSQL-നുള്ള ആമസോൺ അറോറ പോലുള്ള വെക്റ്റർ ഡാറ്റാസ്റ്റോറുകളിലേക്ക് ഡാറ്റ എഴുതുന്നതിന് അപ്പാച്ചെ ഫ്ലിങ്ക് നേറ്റീവ് സിങ്ക് കണക്ടറുകൾ നൽകുന്നു. ആമസോൺ ഓപ്പൺ സെർച്ച് സേവനം VectorDB ഉപയോഗിച്ച്. പകരമായി, നിങ്ങൾക്ക് ഒരു MSK വിഷയത്തിലോ കൈനസിസ് ഡാറ്റ സ്ട്രീമിലോ ഫ്ലിങ്ക് ജോലിയുടെ ഔട്ട്പുട്ട് (വെക്ടറൈസ്ഡ് ഡാറ്റ) സ്റ്റേജ് ചെയ്യാം. Kinesis ഡാറ്റ സ്ട്രീമുകളിൽ നിന്നോ MSK വിഷയങ്ങളിൽ നിന്നോ ഉള്ള നേറ്റീവ് ഉൾപ്പെടുത്തലിനുള്ള പിന്തുണ OpenSearch സേവനം നൽകുന്നു. കൂടുതൽ വിവരങ്ങൾക്ക്, റഫർ ചെയ്യുക ആമസോൺ ഓപ്പൺ സെർച്ച് ഇൻജഷൻ്റെ ഉറവിടമായി ആമസോൺ MSK അവതരിപ്പിക്കുന്നു ഒപ്പം Amazon Kinesis ഡാറ്റ സ്ട്രീമുകളിൽ നിന്ന് സ്ട്രീമിംഗ് ഡാറ്റ ലോഡുചെയ്യുന്നു.
ഫീഡ്ബാക്ക് അനലിറ്റിക്സും മികച്ച ട്യൂണിംഗും
ഡാറ്റാ ഓപ്പറേഷൻ മാനേജർമാർക്കും AI/ML ഡവലപ്പർമാർക്കും ജനറേറ്റീവ് AI ആപ്ലിക്കേഷൻ്റെ പ്രകടനത്തെക്കുറിച്ചും ഉപയോഗത്തിലുള്ള FM-കളെക്കുറിച്ചും ഉൾക്കാഴ്ച നേടേണ്ടത് പ്രധാനമാണ്. അത് നേടുന്നതിന്, ഉപയോക്തൃ ഫീഡ്ബാക്കും വൈവിധ്യമാർന്ന ആപ്ലിക്കേഷൻ ലോഗുകളും മെട്രിക്സും അടിസ്ഥാനമാക്കി പ്രധാനപ്പെട്ട കീ പെർഫോമൻസ് ഇൻഡിക്കേറ്റർ (കെപിഐ) ഡാറ്റ കണക്കാക്കുന്ന ഡാറ്റാ പൈപ്പ്ലൈനുകൾ നിങ്ങൾ നിർമ്മിക്കേണ്ടതുണ്ട്. എഫ്എം, ആപ്ലിക്കേഷൻ്റെ പ്രകടനം, നിങ്ങളുടെ ആപ്ലിക്കേഷനിൽ നിന്ന് ലഭിക്കുന്ന പിന്തുണയുടെ ഗുണനിലവാരത്തെക്കുറിച്ചുള്ള മൊത്തത്തിലുള്ള ഉപയോക്തൃ സംതൃപ്തി എന്നിവയെക്കുറിച്ച് തത്സമയ ഉൾക്കാഴ്ച നേടുന്നതിന് ഈ വിവരങ്ങൾ പങ്കാളികൾക്ക് ഉപയോഗപ്രദമാണ്. ഡൊമെയ്ൻ-നിർദ്ദിഷ്ട ടാസ്ക്കുകൾ ചെയ്യുന്നതിനുള്ള കഴിവ് മെച്ചപ്പെടുത്തുന്നതിന് നിങ്ങളുടെ എഫ്എമ്മുകളെ കൂടുതൽ മികച്ച രീതിയിൽ ട്യൂൺ ചെയ്യുന്നതിനായി നിങ്ങൾ സംഭാഷണ ചരിത്രം ശേഖരിക്കുകയും സംഭരിക്കുകയും ചെയ്യേണ്ടതുണ്ട്.
സ്ട്രീമിംഗ് അനലിറ്റിക്സ് ഡൊമെയ്നിൽ ഈ ഉപയോഗ കേസ് നന്നായി യോജിക്കുന്നു. നിങ്ങളുടെ ആപ്ലിക്കേഷൻ ഓരോ സംഭാഷണവും സ്ട്രീമിംഗ് സ്റ്റോറേജിൽ സൂക്ഷിക്കണം. ഓരോ ഉത്തരത്തിൻ്റെയും കൃത്യതയുടെയും അവരുടെ മൊത്തത്തിലുള്ള സംതൃപ്തിയുടെയും റേറ്റിംഗിനെക്കുറിച്ച് നിങ്ങളുടെ ആപ്ലിക്കേഷന് ഉപയോക്താക്കളോട് ആവശ്യപ്പെടാൻ കഴിയും. ഈ ഡാറ്റ ഒരു ബൈനറി ചോയ്സിൻ്റെ ഫോർമാറ്റിലോ ഒരു സ്വതന്ത്ര ഫോം ടെക്സ്റ്റിലോ ആകാം. ഈ ഡാറ്റ ഒരു Kinesis ഡാറ്റ സ്ട്രീമിലോ MSK വിഷയത്തിലോ സംഭരിക്കാനും തത്സമയം KPI-കൾ സൃഷ്ടിക്കുന്നതിന് പ്രോസസ്സ് ചെയ്യാനും കഴിയും. ഉപയോക്താക്കളുടെ വികാര വിശകലനത്തിനായി നിങ്ങൾക്ക് FM-കൾ പ്രവർത്തിക്കാൻ കഴിയും. FM-കൾക്ക് ഓരോ ഉത്തരവും വിശകലനം ചെയ്യാനും ഉപയോക്തൃ സംതൃപ്തിയുടെ ഒരു വിഭാഗം നൽകാനും കഴിയും.
അപ്പാച്ചെ ഫ്ലിങ്കിൻ്റെ ആർക്കിടെക്ചർ സമയത്തിൻ്റെ ജാലകങ്ങളിൽ സങ്കീർണ്ണമായ ഡാറ്റ സംഗ്രഹം അനുവദിക്കുന്നു. ഡാറ്റ ഇവൻ്റുകളുടെ സ്ട്രീമിലൂടെ SQL അന്വേഷിക്കുന്നതിനുള്ള പിന്തുണയും ഇത് നൽകുന്നു. അതിനാൽ, Apache Flink ഉപയോഗിക്കുന്നതിലൂടെ, നിങ്ങൾക്ക് റോ യൂസർ ഇൻപുട്ടുകൾ വേഗത്തിൽ വിശകലനം ചെയ്യാനും പരിചിതമായ SQL അന്വേഷണങ്ങൾ എഴുതി തത്സമയം KPI-കൾ സൃഷ്ടിക്കാനും കഴിയും. കൂടുതൽ വിവരങ്ങൾക്ക്, റഫർ ചെയ്യുക പട്ടിക API & SQL.
കൂടെ അപ്പാച്ചെ ഫ്ലിങ്ക് സ്റ്റുഡിയോയ്ക്കായി ആമസോൺ നിയന്ത്രിത സേവനം, നിങ്ങൾക്ക് ഒരു ഇൻ്ററാക്ടീവ് നോട്ട്ബുക്കിൽ സ്റ്റാൻഡേർഡ് SQL, Python, Scala എന്നിവ ഉപയോഗിച്ച് Apache Flink സ്ട്രീം പ്രോസസ്സിംഗ് ആപ്ലിക്കേഷനുകൾ നിർമ്മിക്കാനും പ്രവർത്തിപ്പിക്കാനും കഴിയും. സ്റ്റുഡിയോ നോട്ട്ബുക്കുകൾ അപ്പാച്ചെ സെപ്പെലിൻ ആണ് നൽകുന്നത് കൂടാതെ സ്ട്രീം പ്രോസസ്സിംഗ് എഞ്ചിനായി അപ്പാച്ചെ ഫ്ലിങ്ക് ഉപയോഗിക്കുന്നു. സ്റ്റുഡിയോ നോട്ട്ബുക്കുകൾ ഈ സാങ്കേതികവിദ്യകളെ തടസ്സങ്ങളില്ലാതെ സംയോജിപ്പിച്ച് എല്ലാ നൈപുണ്യ സെറ്റുകളുടെയും ഡെവലപ്പർമാർക്ക് ആക്സസ് ചെയ്യാൻ കഴിയുന്ന ഡാറ്റ സ്ട്രീമുകളിലെ വിപുലമായ അനലിറ്റിക്സ് ഉണ്ടാക്കുന്നു. ഉപയോക്തൃ-നിർവചിച്ച ഫംഗ്ഷനുകൾക്കുള്ള (യുഡിഎഫ്) പിന്തുണയോടെ, വികാര വിശകലനം പോലുള്ള സങ്കീർണ്ണമായ ജോലികൾ ചെയ്യുന്നതിന് എഫ്എമ്മുകൾ പോലുള്ള ബാഹ്യ ഉറവിടങ്ങളുമായി സംയോജിപ്പിക്കുന്നതിന് ഇഷ്ടാനുസൃത ഓപ്പറേറ്റർമാരെ നിർമ്മിക്കുന്നതിന് അപ്പാച്ചെ ഫ്ലിങ്ക് അനുവദിക്കുന്നു. വിവിധ അളവുകൾ കണക്കാക്കുന്നതിനോ ഉപയോക്തൃ വികാരം പോലുള്ള അധിക സ്ഥിതിവിവരക്കണക്കുകൾ ഉപയോഗിച്ച് ഉപയോക്തൃ ഫീഡ്ബാക്ക് റോ ഡാറ്റയെ സമ്പന്നമാക്കുന്നതിനോ നിങ്ങൾക്ക് UDF-കൾ ഉപയോഗിക്കാം. ഈ പാറ്റേണിനെക്കുറിച്ച് കൂടുതലറിയാൻ, റഫർ ചെയ്യുക GenAI, Flink, Apache Kafka, Kinesis എന്നിവ ഉപയോഗിച്ച് തത്സമയം ഉപഭോക്തൃ ആശങ്കകൾ മുൻകൂട്ടി അഭിസംബോധന ചെയ്യുന്നു.
അപ്പാച്ചെ ഫ്ലിങ്ക് സ്റ്റുഡിയോയ്ക്കായുള്ള നിയന്ത്രിത സേവനം ഉപയോഗിച്ച്, ഒറ്റ ക്ലിക്കിലൂടെ നിങ്ങളുടെ സ്റ്റുഡിയോ നോട്ട്ബുക്ക് സ്ട്രീമിംഗ് ജോലിയായി വിന്യസിക്കാനാകും. നിങ്ങൾക്ക് ഇഷ്ടമുള്ള സ്റ്റോറേജിലേക്ക് ഔട്ട്പുട്ട് അയയ്ക്കാനോ കിനിസിസ് ഡാറ്റ സ്ട്രീമിലോ എംഎസ്കെ വിഷയത്തിലോ സ്റ്റേജ് ചെയ്യാനോ അപ്പാച്ചെ ഫ്ലിങ്ക് നൽകുന്ന നേറ്റീവ് സിങ്ക് കണക്ടറുകൾ ഉപയോഗിക്കാം. ആമസോൺ റെഡ്ഷിഫ്റ്റ് ഓപ്പൺ സെർച്ച് സേവനവും അനലിറ്റിക്കൽ ഡാറ്റ സംഭരിക്കുന്നതിന് അനുയോജ്യമാണ്. രണ്ട് എഞ്ചിനുകളും കൈനസിസ് ഡാറ്റ സ്ട്രീമുകളിൽ നിന്നും ആമസോൺ എംഎസ്കെയിൽ നിന്നും ഒരു പ്രത്യേക സ്ട്രീമിംഗ് പൈപ്പ്ലൈൻ വഴി ഒരു ഡാറ്റ തടാകത്തിലേക്കോ വിശകലനത്തിനായി ഡാറ്റ വെയർഹൗസിലേക്കോ നേറ്റീവ് ഇൻജക്ഷൻ പിന്തുണ നൽകുന്നു.
AWS-രൂപകൽപ്പന ചെയ്ത ഹാർഡ്വെയറും മെഷീൻ ലേണിംഗും ഉപയോഗിച്ച് ഡാറ്റാ വെയർഹൗസുകളിലും ഡാറ്റാ തടാകങ്ങളിലും ഉടനീളം ഘടനാപരമായതും അർദ്ധ-ഘടനാപരമായതുമായ ഡാറ്റ വിശകലനം ചെയ്യാൻ Amazon Redshift SQL ഉപയോഗിക്കുന്നു. ഓപ്പൺ സെർച്ച് ഡാഷ്ബോർഡുകളും കിബാനയും (1.5 മുതൽ 7.10 വരെ പതിപ്പുകൾ) നൽകുന്ന വിഷ്വലൈസേഷൻ കഴിവുകൾ ഓപ്പൺ സെർച്ച് സേവനം നൽകുന്നു.
ആവശ്യമുള്ളപ്പോൾ എഫ്എം ഫൈൻ-ട്യൂൺ ചെയ്യുന്നതിന് ഉപയോക്തൃ പ്രോംപ്റ്റ് ഡാറ്റയുമായി സംയോജിപ്പിച്ച് അത്തരം വിശകലനത്തിൻ്റെ ഫലം നിങ്ങൾക്ക് ഉപയോഗിക്കാം. നിങ്ങളുടെ FM-കൾ മികച്ചതാക്കാനുള്ള ഏറ്റവും ലളിതമായ മാർഗമാണ് SageMaker. SageMaker-നൊപ്പം Amazon S3 ഉപയോഗിക്കുന്നത് നിങ്ങളുടെ മോഡലുകളെ മികച്ച രീതിയിൽ ക്രമീകരിക്കുന്നതിന് ശക്തവും തടസ്സമില്ലാത്തതുമായ സംയോജനം നൽകുന്നു. വലിയ ഡാറ്റാസെറ്റുകൾ, പരിശീലന ഡാറ്റ, മോഡൽ ആർട്ടിഫാക്റ്റുകൾ എന്നിവയുടെ നേരിട്ടുള്ള സംഭരണവും വീണ്ടെടുക്കലും പ്രാപ്തമാക്കുന്ന, സ്കേലബിൾ, ഡ്യൂറബിൾ ഒബ്ജക്റ്റ് സ്റ്റോറേജ് സൊല്യൂഷനായി Amazon S3 പ്രവർത്തിക്കുന്നു. മുഴുവൻ ML ജീവിതചക്രത്തെയും ലളിതമാക്കുന്ന പൂർണ്ണമായി മാനേജ് ചെയ്യപ്പെടുന്ന ML സേവനമാണ് SageMaker. SageMaker-ൻ്റെ സ്റ്റോറേജ് ബാക്കെൻഡായി Amazon S3 ഉപയോഗിക്കുന്നതിലൂടെ, ആമസോൺ S3-ൻ്റെ സ്കേലബിളിറ്റി, വിശ്വാസ്യത, ചെലവ്-ഫലപ്രാപ്തി എന്നിവയിൽ നിന്ന് നിങ്ങൾക്ക് പ്രയോജനം നേടാം, അതേസമയം SageMaker പരിശീലനവും വിന്യാസ ശേഷികളുമായി ഇത് തടസ്സമില്ലാതെ സമന്വയിപ്പിക്കുന്നു. ഈ കോമ്പിനേഷൻ കാര്യക്ഷമമായ ഡാറ്റ മാനേജുമെൻ്റ് പ്രാപ്തമാക്കുന്നു, സഹകരണ മോഡൽ വികസനം സുഗമമാക്കുന്നു, കൂടാതെ ML വർക്ക്ഫ്ലോകൾ കാര്യക്ഷമവും അളക്കാവുന്നതുമാണെന്ന് ഉറപ്പാക്കുന്നു, ആത്യന്തികമായി ML പ്രക്രിയയുടെ മൊത്തത്തിലുള്ള ചടുലതയും പ്രകടനവും വർദ്ധിപ്പിക്കുന്നു. കൂടുതൽ വിവരങ്ങൾക്ക്, റഫർ ചെയ്യുക @remote decorator ഉപയോഗിച്ച് Amazon SageMaker-ലെ Falcon 7B-യും മറ്റ് LLM-കളും മികച്ചതാക്കുക.
ഒരു ഫയൽ സിസ്റ്റം സിങ്ക് കണക്ടർ ഉപയോഗിച്ച്, Apache Flink ജോലികൾക്ക് ആമസോൺ S3-ലേക്ക് ഓപ്പൺ ഫോർമാറ്റിൽ (JSON, Avro, Parquet എന്നിവയും അതിലേറെയും) ഫയലുകൾ ഡാറ്റാ ഒബ്ജക്റ്റുകളായി നൽകാനാകും. ഒരു ഇടപാട് ഡാറ്റാ തടാക ചട്ടക്കൂട് (അപ്പാച്ചെ ഹുഡി, അപ്പാച്ചെ ഐസ്ബർഗ് അല്ലെങ്കിൽ ഡെൽറ്റ തടാകം പോലുള്ളവ) ഉപയോഗിച്ച് നിങ്ങളുടെ ഡാറ്റാ തടാകം നിയന്ത്രിക്കാൻ നിങ്ങൾ ആഗ്രഹിക്കുന്നുവെങ്കിൽ, ഈ ചട്ടക്കൂടുകളെല്ലാം അപ്പാച്ചെ ഫ്ലിങ്കിനായി ഒരു ഇഷ്ടാനുസൃത കണക്റ്റർ നൽകുന്നു. കൂടുതൽ വിവരങ്ങൾക്ക്, റഫർ ചെയ്യുക Amazon MSK കണക്ട്, അപ്പാച്ചെ ഫ്ലിങ്ക്, അപ്പാച്ചെ ഹുഡി എന്നിവ ഉപയോഗിച്ച് ലോ-ലേറ്റൻസി സോഴ്സ്-ടു-ഡേറ്റ ലേക് പൈപ്പ്ലൈൻ സൃഷ്ടിക്കുക.
ചുരുക്കം
ഒരു RAG മോഡലിനെ അടിസ്ഥാനമാക്കിയുള്ള ഒരു ജനറേറ്റീവ് AI ആപ്ലിക്കേഷനായി, നിങ്ങൾ രണ്ട് ഡാറ്റ സ്റ്റോറേജ് സിസ്റ്റങ്ങൾ നിർമ്മിക്കുന്നത് പരിഗണിക്കേണ്ടതുണ്ട്, കൂടാതെ എല്ലാ ഉറവിട സിസ്റ്റങ്ങളുമായി കാലികമായി നിലനിർത്തുന്ന ഡാറ്റാ ഓപ്പറേഷനുകൾ നിങ്ങൾ നിർമ്മിക്കേണ്ടതുണ്ട്. നിങ്ങളുടെ ജനറേറ്റീവ് AI ആപ്ലിക്കേഷനുമായി സംയോജിപ്പിക്കേണ്ട ഡാറ്റയുടെ വലുപ്പവും വൈവിധ്യവും പ്രോസസ്സ് ചെയ്യുന്നതിന് പരമ്പരാഗത ബാച്ച് ജോലികൾ പര്യാപ്തമല്ല. ഉറവിട സിസ്റ്റങ്ങളിലെ മാറ്റങ്ങൾ പ്രോസസ്സ് ചെയ്യുന്നതിലെ കാലതാമസം കൃത്യമല്ലാത്ത പ്രതികരണത്തിന് കാരണമാകുകയും നിങ്ങളുടെ ജനറേറ്റീവ് AI ആപ്ലിക്കേഷൻ്റെ കാര്യക്ഷമത കുറയ്ക്കുകയും ചെയ്യുന്നു. വിവിധ സിസ്റ്റങ്ങളിൽ ഉടനീളമുള്ള വിവിധ ഡാറ്റാബേസുകളിൽ നിന്നുള്ള ഡാറ്റ ഉൾക്കൊള്ളാൻ ഡാറ്റ സ്ട്രീമിംഗ് നിങ്ങളെ പ്രാപ്തരാക്കുന്നു. തൽസമയത്ത് കാര്യക്ഷമമായി നിരവധി ഉറവിടങ്ങളിലുടനീളം ഡാറ്റ രൂപാന്തരപ്പെടുത്താനും സമ്പന്നമാക്കാനും ചേരാനും സമാഹരിക്കാനും ഇത് നിങ്ങളെ അനുവദിക്കുന്നു. ഡാറ്റാ സ്ട്രീമിംഗ് ഉപയോക്താക്കളുടെ തത്സമയ പ്രതികരണങ്ങൾ അല്ലെങ്കിൽ ആപ്ലിക്കേഷൻ പ്രതികരണങ്ങളെക്കുറിച്ചുള്ള അഭിപ്രായങ്ങൾ ശേഖരിക്കുന്നതിനും രൂപാന്തരപ്പെടുത്തുന്നതിനും ലളിതമായ ഒരു ഡാറ്റ ആർക്കിടെക്ചർ നൽകുന്നു, മോഡൽ ഫൈൻ ട്യൂണിംഗിനായി ഒരു ഡാറ്റ തടാകത്തിൽ ഫലങ്ങൾ നൽകാനും സംഭരിക്കാനും നിങ്ങളെ സഹായിക്കുന്നു. മാറ്റ ഇവൻ്റുകൾ മാത്രം പ്രോസസ്സ് ചെയ്തുകൊണ്ട് ഡാറ്റാ പൈപ്പ്ലൈനുകൾ ഒപ്റ്റിമൈസ് ചെയ്യാനും ഡാറ്റ സ്ട്രീമിംഗ് നിങ്ങളെ സഹായിക്കുന്നു, ഡാറ്റ മാറ്റങ്ങളോട് കൂടുതൽ വേഗത്തിലും കാര്യക്ഷമമായും പ്രതികരിക്കാൻ നിങ്ങളെ അനുവദിക്കുന്നു.
കൂടുതൽ അറിയുക AWS ഡാറ്റ സ്ട്രീമിംഗ് സേവനങ്ങൾ നിങ്ങളുടെ സ്വന്തം ഡാറ്റ സ്ട്രീമിംഗ് പരിഹാരം നിർമ്മിക്കാൻ ആരംഭിക്കുക.
രചയിതാക്കളെക്കുറിച്ച്
 അലി അലെമി AWS-ലെ സ്ട്രീമിംഗ് സ്പെഷ്യലിസ്റ്റ് സൊല്യൂഷൻസ് ആർക്കിടെക്റ്റാണ്. വാസ്തുവിദ്യാപരമായ മികച്ച രീതികളുള്ള AWS ഉപഭോക്താക്കളെ അലി ഉപദേശിക്കുകയും വിശ്വസനീയവും സുരക്ഷിതവും കാര്യക്ഷമവും ചെലവ് കുറഞ്ഞതുമായ തത്സമയ അനലിറ്റിക്സ് ഡാറ്റാ സിസ്റ്റങ്ങൾ രൂപകൽപ്പന ചെയ്യാൻ അവരെ സഹായിക്കുകയും ചെയ്യുന്നു. അവൻ ഉപഭോക്താവിൻ്റെ ഉപയോഗ കേസുകളിൽ നിന്ന് പിന്നോട്ട് പ്രവർത്തിക്കുകയും അവരുടെ ബിസിനസ്സ് പ്രശ്നങ്ങൾ പരിഹരിക്കുന്നതിന് ഡാറ്റ പരിഹാരങ്ങൾ രൂപകൽപ്പന ചെയ്യുകയും ചെയ്യുന്നു. AWS-ൽ ചേരുന്നതിന് മുമ്പ്, അലി നിരവധി പൊതുമേഖലാ ഉപഭോക്താക്കളെയും AWS കൺസൾട്ടിംഗ് പങ്കാളികളെയും അവരുടെ ആപ്ലിക്കേഷൻ നവീകരണ യാത്രയിലും ക്ലൗഡിലേക്കുള്ള മൈഗ്രേഷനിലും പിന്തുണച്ചിരുന്നു.
അലി അലെമി AWS-ലെ സ്ട്രീമിംഗ് സ്പെഷ്യലിസ്റ്റ് സൊല്യൂഷൻസ് ആർക്കിടെക്റ്റാണ്. വാസ്തുവിദ്യാപരമായ മികച്ച രീതികളുള്ള AWS ഉപഭോക്താക്കളെ അലി ഉപദേശിക്കുകയും വിശ്വസനീയവും സുരക്ഷിതവും കാര്യക്ഷമവും ചെലവ് കുറഞ്ഞതുമായ തത്സമയ അനലിറ്റിക്സ് ഡാറ്റാ സിസ്റ്റങ്ങൾ രൂപകൽപ്പന ചെയ്യാൻ അവരെ സഹായിക്കുകയും ചെയ്യുന്നു. അവൻ ഉപഭോക്താവിൻ്റെ ഉപയോഗ കേസുകളിൽ നിന്ന് പിന്നോട്ട് പ്രവർത്തിക്കുകയും അവരുടെ ബിസിനസ്സ് പ്രശ്നങ്ങൾ പരിഹരിക്കുന്നതിന് ഡാറ്റ പരിഹാരങ്ങൾ രൂപകൽപ്പന ചെയ്യുകയും ചെയ്യുന്നു. AWS-ൽ ചേരുന്നതിന് മുമ്പ്, അലി നിരവധി പൊതുമേഖലാ ഉപഭോക്താക്കളെയും AWS കൺസൾട്ടിംഗ് പങ്കാളികളെയും അവരുടെ ആപ്ലിക്കേഷൻ നവീകരണ യാത്രയിലും ക്ലൗഡിലേക്കുള്ള മൈഗ്രേഷനിലും പിന്തുണച്ചിരുന്നു.
 ഇംതിയാസ് (താസ്) സെയ്ദ് AWS-ലെ അനലിറ്റിക്സിൻ്റെ വേൾഡ് വൈഡ് ടെക് ലീഡറാണ്. എല്ലാ കാര്യങ്ങളിലും ഡാറ്റയിലും അനലിറ്റിക്സിലും കമ്മ്യൂണിറ്റിയുമായി ഇടപഴകുന്നത് അവൻ ആസ്വദിക്കുന്നു. വഴി അവനെ എത്തിച്ചേരാം ലിങ്ക്ഡ്.
ഇംതിയാസ് (താസ്) സെയ്ദ് AWS-ലെ അനലിറ്റിക്സിൻ്റെ വേൾഡ് വൈഡ് ടെക് ലീഡറാണ്. എല്ലാ കാര്യങ്ങളിലും ഡാറ്റയിലും അനലിറ്റിക്സിലും കമ്മ്യൂണിറ്റിയുമായി ഇടപഴകുന്നത് അവൻ ആസ്വദിക്കുന്നു. വഴി അവനെ എത്തിച്ചേരാം ലിങ്ക്ഡ്.
- SEO പവർ ചെയ്ത ഉള്ളടക്കവും PR വിതരണവും. ഇന്ന് ആംപ്ലിഫൈഡ് നേടുക.
- PlatoData.Network ലംബ ജനറേറ്റീവ് Ai. സ്വയം ശാക്തീകരിക്കുക. ഇവിടെ പ്രവേശിക്കുക.
- PlatoAiStream. Web3 ഇന്റലിജൻസ്. വിജ്ഞാനം വർധിപ്പിച്ചു. ഇവിടെ പ്രവേശിക്കുക.
- പ്ലേറ്റോഇഎസ്ജി. കാർബൺ, ക്ലീൻ ടെക്, ഊർജ്ജം, പരിസ്ഥിതി, സോളാർ, മാലിന്യ സംസ്കരണം. ഇവിടെ പ്രവേശിക്കുക.
- പ്ലേറ്റോ ഹെൽത്ത്. ബയോടെക് ആൻഡ് ക്ലിനിക്കൽ ട്രയൽസ് ഇന്റലിജൻസ്. ഇവിടെ പ്രവേശിക്കുക.
- അവലംബം: https://aws.amazon.com/blogs/big-data/exploring-real-time-streaming-for-generative-ai-applications/

