개요
단 XNUMX개월 만에 OpenAI의 ChatGPT는 우리 삶의 필수적인 부분이 되었습니다. 더 이상 기술에만 국한되지 않습니다. 학생에서 작가에 이르기까지 모든 연령대와 직업의 사람들이 광범위하게 사용하고 있습니다. 이러한 채팅 모델은 정확성, 속도 및 사람과 같은 대화에서 탁월합니다. 기술뿐만 아니라 다양한 분야에서 중요한 역할을 할 태세다.
AutoGPT, BabyAGI 및 Langchain과 같은 오픈 소스 도구가 등장하여 언어 모델의 힘을 활용합니다. 프롬프트로 프로그래밍 작업을 자동화하고, 언어 모델을 데이터 소스에 연결하고, 그 어느 때보다 빠르게 AI 애플리케이션을 생성하세요. Langchain은 PDF용 ChatGPT 지원 Q&A 도구로, AI 애플리케이션 구축을 위한 원스톱 상점입니다.
학습 목표
- Gradio를 사용하여 챗봇 인터페이스 구축
- PDF에서 텍스트 추출 및 임베딩 생성
- Chroma 벡터 데이터베이스에 임베딩 저장
- 백엔드에 쿼리 보내기(Langchain 체인)
- 텍스트에 대한 시맨틱 검색을 수행하여 관련 데이터 소스 찾기
- LLM(ChatGPT)에 데이터를 보내고 챗봇에서 답변 받기
Langchain을 사용하면 몇 줄의 코드로 이러한 모든 단계를 쉽게 수행할 수 있습니다. 포함 모델, 채팅 모델 및 벡터 데이터베이스를 비롯한 여러 서비스에 대한 래퍼가 있습니다.
이 기사는 데이터 과학 블로그.
차례
랭체인이란?
Langchain은 외부 데이터를 대규모 언어 모델에 연결하는 데 도움이 되는 Python으로 작성된 오픈 소스 도구입니다. GPT-4 또는 GPT-3.5와 같은 채팅 모델을 보다 에이전트적이고 데이터 인식하게 만듭니다. 그래서 어떤 면에서 Langchain은 훈련되지 않은 새로운 데이터를 LLM에 제공하는 방법을 제공합니다. Langchain은 언어 모델과 상호 작용할 때 복잡성을 추상화하는 많은 체인을 제공합니다. 또한 벡터 임베딩을 생성하기 위한 모델 및 벡터를 저장하기 위한 벡터 데이터베이스와 같은 몇 가지 다른 도구가 필요합니다. 더 진행하기 전에 텍스트 임베딩을 간단히 살펴보겠습니다. 이것들은 무엇이고 왜 중요한가요?
텍스트 임베딩
텍스트 임베딩은 대규모 언어 작업의 핵심입니다. 기술적으로는 자연어로 언어 모델을 사용할 수 있지만 자연어를 저장하고 검색하는 것은 매우 비효율적입니다. 예를 들어 이 프로젝트에서는 대량의 데이터에 대해 고속 검색 작업을 수행해야 합니다. 자연어 데이터에 대해 이러한 작업을 수행하는 것은 불가능합니다.
더 효율적으로 만들려면 텍스트 데이터를 벡터 형식으로 변환해야 합니다. 텍스트에서 임베딩을 생성하기 위한 전용 ML 모델이 있습니다. 텍스트는 다차원 벡터로 변환됩니다. 포함되면 이러한 데이터에 대해 그룹화, 정렬, 검색 등을 수행할 수 있습니다. 두 문장 사이의 거리를 계산하여 두 문장이 얼마나 밀접하게 관련되어 있는지 알 수 있습니다. 그리고 가장 중요한 부분은 이러한 작업이 기존 데이터베이스 검색과 같은 키워드에만 국한되지 않고 오히려 두 문장의 의미론적 근접성을 캡처한다는 것입니다. 이것은 기계 학습 덕분에 훨씬 더 강력해졌습니다.
랭체인 도구
Langchain에는 Chroma, Redis, Pinecone, Alpine db 등과 같은 모든 주요 벡터 데이터베이스에 대한 래퍼가 있습니다. 그리고 OpeanAI 모델과 함께 LLM도 마찬가지이며 Cohere의 모델인 GPT4ALL(GPT 모델의 오픈 소스 대안)도 지원합니다. 임베딩의 경우 OpenAI, Cohere 및 HuggingFace 임베딩에 대한 래퍼를 제공합니다. 커스텀 임베딩 모델도 사용할 수 있습니다.
즉, 간단히 말해서 Langchain은 기본 기술과 상호 작용하는 많은 복잡성을 추상화하여 누구나 AI 애플리케이션을 빠르게 구축할 수 있도록 하는 메타 도구입니다.
이 기사에서는 다음을 사용합니다. OpenAI 임베딩 임베딩 생성을 위한 모델. 최종 사용자를 위해 AI 앱을 배포하려면 Huggingface 모델 또는 Google의 범용 문장 인코더와 같은 오픈 소스 모델을 사용하는 것이 좋습니다.
벡터를 저장하려면 다음을 사용합니다. 크로마DB, 오픈 소스 벡터 저장소 데이터베이스입니다. Alpine, Pinecone 및 Redis와 같은 다른 데이터베이스를 자유롭게 탐색하십시오. Langchain에는 이러한 모든 벡터 저장소에 대한 래퍼가 있습니다.
Langchain 체인을 생성하려면 다음을 사용합니다. 대화 검색 체인(), 히스토리가 있는 채팅 모델과의 대화에 이상적입니다(대화의 컨텍스트를 유지하기 위해). 확인하십시오 공식 문서 다른 LLM 체인에 대해.
개발 환경 설정
우리가 사용할 라이브러리가 꽤 많이 있습니다. 따라서 미리 설치하십시오. 매끄럽고 깔끔한 개발 환경을 만들려면 다음을 사용하십시오. 가상 환경 or 도커.
gradio = "^3.27.0"
openai = "^0.27.4"
langchain = "^0.0.148"
chromadb = "^0.3.21"
tiktoken = "^0.3.3"
pypdf = "^3.8.1"
pymupdf = "^1.22.2"이제 이 라이브러리를 가져옵니다.
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import Image채팅 인터페이스 구축
응용 프로그램의 인터페이스에는 두 가지 주요 기능이 있습니다. 하나는 채팅 인터페이스이고 다른 하나는 PDF의 관련 페이지를 이미지로 렌더링합니다. 이 외에도 최종 사용자로부터 OpenAI API 키를 수락하기 위한 텍스트 상자입니다. 에 대한 기사를 살펴보는 것이 좋습니다. Gradio로 GPT 챗봇 구축 기스로부터. 이 기사에서는 Gradio의 기본적인 측면에 대해 설명합니다. 이 기사에서 많은 것을 빌릴 것입니다.
Gradio Blocks 클래스를 사용하면 웹 앱을 만들 수 있습니다. 행 및 열 클래스를 사용하면 웹 앱에서 여러 구성 요소를 정렬할 수 있습니다. 이를 사용하여 웹 인터페이스를 사용자 정의합니다.
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style()
인터페이스는 몇 가지 구성 요소로 간단합니다.
그것은있다 :
- PDF와 통신하기 위한 채팅 인터페이스.
- 관련 PDF 페이지를 렌더링하기 위한 구성 요소입니다.
- API 키를 수락하기 위한 텍스트 상자와 키 변경 버튼.
- 질문을 위한 텍스트 상자와 제출 버튼.
- 파일 업로드 버튼입니다.
다음은 웹 UI의 스냅샷입니다.
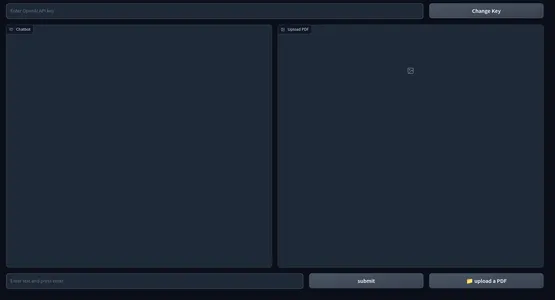
애플리케이션의 프런트엔드 부분이 완성되었습니다. 백엔드로 넘어갑시다.
백엔드
먼저, 처리할 프로세스를 간략하게 설명하겠습니다.
- 업로드된 PDF 및 OpenAI API 키 처리
- PDF에서 텍스트를 추출하고 OpenAI 임베딩을 사용하여 PDF에서 텍스트 임베딩을 생성합니다.
- ChromaDB 벡터 저장소에 벡터 임베딩을 저장합니다.
- Langchain으로 대화형 검색 체인을 만듭니다.
- 쿼리된 텍스트의 포함을 만들고 포함된 문서에 대한 유사성 검색을 수행합니다.
- 관련 문서를 OpenAI 채팅 모델(gpt-3.5-turbo)로 보냅니다.
- 답변을 가져와 채팅 UI에서 스트리밍합니다.
- 웹 UI에서 관련 PDF 페이지를 렌더링합니다.
이것은 우리 응용 프로그램의 개요입니다. 그것을 구축 시작하자.
그라디오 이벤트
웹 UI에서 특정 작업이 수행되면 이러한 이벤트가 트리거됩니다. 따라서 이벤트는 웹 앱을 대화형 및 동적으로 만듭니다. Gradio를 사용하면 Python 코드로 이벤트를 정의할 수 있습니다.
Gradio 이벤트는 백엔드와 통신하기 위해 이전에 정의한 구성 요소 변수를 사용합니다. 애플리케이션에 필요한 몇 가지 이벤트를 정의합니다. 이것들은
- API 키 이벤트 제출: API 키를 붙여넣은 후 엔터를 누르면 이벤트가 발생합니다.
- 키 변경: 이렇게 하면 새 API 키를 제공할 수 있습니다.
- 쿼리 입력: 챗봇에 텍스트 쿼리 제출
- 파일 업로드: 이렇게 하면 최종 사용자가 PDF 파일을 업로드할 수 있습니다.
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )지금까지 우리는 위의 이벤트 핸들러 내부에서 호출되는 함수를 정의하지 않았습니다. 다음으로 기능적인 웹 앱을 만들기 위해 이러한 모든 기능을 정의합니다.
API 키 처리
전체가 BYOK(Bring Your Own Key) 원칙에 따라 실행되므로 사용자의 API 키를 처리하는 것이 중요합니다. 사용자가 키를 제출할 때마다 텍스트 상자는 키가 설정되었음을 제안하는 프롬프트와 함께 변경할 수 없게 되어야 합니다. 그리고 "키 변경" 이벤트가 트리거되면 상자가 입력을 받을 수 있어야 합니다.
이렇게 하려면 두 개의 전역 변수를 정의합니다.
enable_box = gr.Textbox.update(value=None,placeholder= 'Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value = 'OpenAI API key is Set',interactive=False)기능 정의
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box def enable_api_box(): return enable_boxset_apikey 함수는 문자열 입력을 받아 disable_box 변수를 반환하여 실행 후 텍스트 상자를 변경할 수 없게 만듭니다. Gradio Events 섹션에서 set_apikey 함수를 호출하는 api_key 제출 이벤트를 정의했습니다. OS 라이브러리를 사용하여 API 키를 환경 변수로 설정합니다.
API 키 변경 버튼을 클릭하면 텍스트 상자의 가변성을 다시 활성화하는 enable_box 변수가 반환됩니다.
체인 만들기
이것은 가장 중요한 단계입니다. 이 단계에는 텍스트를 추출하고 임베딩을 생성하여 벡터 저장소에 저장하는 작업이 포함됩니다. 여러 서비스에 대한 래퍼를 제공하여 작업을 더 쉽게 해주는 Langchain 덕분입니다. 그럼 함수를 정의해 봅시다.
def process_file(file): # raise an error if API key is not provided if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') # Load the PDF file using PyPDFLoader loader = PyPDFLoader(file.name) documents = loader.load() # Initialize OpenAIEmbeddings for text embeddings embeddings = OpenAIEmbeddings() # Create a ConversationalRetrievalChain with ChatOpenAI language model # and PDF search retriever pdfsearch = Chroma.from_documents(documents, embeddings,) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever= pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True,) return chain- API 키가 설정되어 있는지 확인을 생성했습니다. 키가 설정되지 않은 경우 프런트 엔드에서 오류가 발생합니다.
- PyPDFLoader를 사용하여 PDF 파일 로드
- OpenAIEmbeddings로 정의된 임베딩 기능.
- 포함 기능을 사용하여 PDF의 텍스트 목록에서 벡터 저장소를 만들었습니다.
- 기본 검색기(유사성 검색 사용)인 chatOpenAI(기본적으로 ChatOpenAI는 gpt-3.5-turbo 사용)로 체인을 정의했습니다.
응답 생성
체인이 생성되면 체인을 호출하고 쿼리를 보냅니다. 쿼리와 함께 채팅 기록을 보내 대화의 컨텍스트를 유지하고 채팅 인터페이스에 대한 응답을 스트리밍합니다. 함수를 정의해 봅시다.
def generate_response(history, query, btn): global COUNT, N, chat_history # Check if a PDF file is uploaded if not btn: raise gr.Error(message='Upload a PDF') # Initialize the conversation chain only once if COUNT == 0: chain = process_file(btn) COUNT += 1 # Generate a response using the conversation chain result = chain({"question": query, 'chat_history':chat_history}, return_only_outputs=True) # Update the chat history with the query and its corresponding answer chat_history += [(query, result["answer"])] # Retrieve the page number from the source document N = list(result['source_documents'][0])[1][1]['page'] # Append each character of the answer to the last message in the history for char in result['answer']: history[-1][-1] += char # Yield the updated history and an empty string yield history, ''
- 업로드된 PDF가 없으면 오류가 발생합니다.
- process_file 함수를 한 번만 호출합니다.
- 쿼리 및 채팅 기록을 체인으로 보냅니다.
- 가장 관련성이 높은 답변의 페이지 번호를 검색합니다.
- 프런트 엔드에 대한 응답을 양보하십시오.
PDF 파일의 렌더링 이미지
마지막 단계는 가장 관련성이 높은 답변으로 PDF 파일의 이미지를 렌더링하는 것입니다. PyMuPdf 및 PIL 라이브러리를 사용하여 문서의 이미지를 렌더링할 수 있습니다.
def render_file(file): global N # Open the PDF document using fitz doc = fitz.open(file.name) # Get the specific page to render page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) # Create an Image object from the rendered pixel data image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) # Return the rendered image return image
- PyMuPdf의 Fitz로 파일을 엽니다.
- 관련 페이지를 가져옵니다.
- 페이지에 대한 pix 맵을 가져옵니다.
- PIL의 Image 클래스에서 이미지를 만듭니다.
이것은 모든 PDF와 채팅하기 위한 기능적인 웹 앱에 필요한 모든 것입니다.
모든 것을 합치다
#import csv
import gradio as gr
from langchain.embeddings.openai import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import Chroma from langchain.chains import ConversationalRetrievalChain
from langchain.chat_models import ChatOpenAI from langchain.document_loaders import PyPDFLoader
import os import fitz
from PIL import Image # Global variables
COUNT, N = 0, 0
chat_history = []
chain = ''
enable_box = gr.Textbox.update(value=None, placeholder='Upload your OpenAI API key', interactive=True)
disable_box = gr.Textbox.update(value='OpenAI API key is Set', interactive=False) # Function to set the OpenAI API key
def set_apikey(api_key): os.environ['OPENAI_API_KEY'] = api_key return disable_box # Function to enable the API key input box
def enable_api_box(): return enable_box # Function to add text to the chat history
def add_text(history, text): if not text: raise gr.Error('Enter text') history = history + [(text, '')] return history # Function to process the PDF file and create a conversation chain
def process_file(file): if 'OPENAI_API_KEY' not in os.environ: raise gr.Error('Upload your OpenAI API key') loader = PyPDFLoader(file.name) documents = loader.load() embeddings = OpenAIEmbeddings() pdfsearch = Chroma.from_documents(documents, embeddings) chain = ConversationalRetrievalChain.from_llm(ChatOpenAI(temperature=0.3), retriever=pdfsearch.as_retriever(search_kwargs={"k": 1}), return_source_documents=True) return chain # Function to generate a response based on the chat history and query
def generate_response(history, query, btn): global COUNT, N, chat_history, chain if not btn: raise gr.Error(message='Upload a PDF') if COUNT == 0: chain = process_file(btn) COUNT += 1 result = chain({"question": query, 'chat_history': chat_history}, return_only_outputs=True) chat_history += [(query, result["answer"])] N = list(result['source_documents'][0])[1][1]['page'] for char in result['answer']: history[-1][-1] += char yield history, '' # Function to render a specific page of a PDF file as an image
def render_file(file): global N doc = fitz.open(file.name) page = doc[N] # Render the page as a PNG image with a resolution of 300 DPI pix = page.get_pixmap(matrix=fitz.Matrix(300/72, 300/72)) image = Image.frombytes('RGB', [pix.width, pix.height], pix.samples) return image # Gradio application setup
with gr.Blocks() as demo: # Create a Gradio block with gr.Column(): with gr.Row(): with gr.Column(scale=0.8): api_key = gr.Textbox( placeholder='Enter OpenAI API key', show_label=False, interactive=True ).style(container=False) with gr.Column(scale=0.2): change_api_key = gr.Button('Change Key') with gr.Row(): chatbot = gr.Chatbot(value=[], elem_id='chatbot').style(height=650) show_img = gr.Image(label='Upload PDF', tool='select').style(height=680) with gr.Row(): with gr.Column(scale=0.70): txt = gr.Textbox( show_label=False, placeholder="Enter text and press enter" ).style(container=False) with gr.Column(scale=0.15): submit_btn = gr.Button('Submit') with gr.Column(scale=0.15): btn = gr.UploadButton("📁 Upload a PDF", file_types=[".pdf"]).style() # Set up event handlers # Event handler for submitting the OpenAI API key api_key.submit(fn=set_apikey, inputs=[api_key], outputs=[api_key]) # Event handler for changing the API key change_api_key.click(fn=enable_api_box, outputs=[api_key]) # Event handler for uploading a PDF btn.upload(fn=render_first, inputs=[btn], outputs=[show_img]) # Event handler for submitting text and generating response submit_btn.click( fn=add_text, inputs=[chatbot, txt], outputs=[chatbot], queue=False ).success( fn=generate_response, inputs=[chatbot, txt, btn], outputs=[chatbot, txt] ).success( fn=render_file, inputs=[btn], outputs=[show_img] )
demo.queue()
if __name__ == "__main__": demo.launch()이제 모든 것을 구성했으므로 애플리케이션을 시작하겠습니다.
다음 명령을 사용하여 디버그 모드에서 애플리케이션을 시작할 수 있습니다.
그래디오 app.py
그렇지 않으면 Python 명령을 사용하여 응용 프로그램을 간단히 실행할 수도 있습니다. 아래는 최종 제품의 스냅샷입니다. 의 GitHub 저장소 코드.
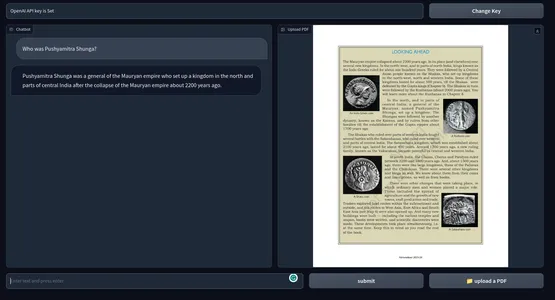
[포함 된 콘텐츠]
가능한 개선
현재 응용 프로그램은 훌륭하게 작동합니다. 하지만 이를 개선하기 위해 할 수 있는 일이 몇 가지 있습니다.
- 이것은 장기적으로 비쌀 수 있는 OpenAI 임베딩을 사용합니다. 프로덕션 준비 앱의 경우 모든 오프라인 임베딩 모델이 더 적합할 수 있습니다.
- 프로토타이핑을 위한 Gradio는 괜찮지만 실제 세계에서는 Next Js 또는 Svelte와 같은 최신 자바스크립트 프레임워크가 있는 앱이 성능과 미학 측면에서 훨씬 더 나을 것입니다.
- 관련 텍스트를 찾기 위해 코사인 유사성을 사용했습니다. 일부 조건에서는 KNN 접근 방식이 더 나을 수 있습니다.
- 조밀한 텍스트 콘텐츠가 포함된 PDF의 경우 더 작은 텍스트 청크를 만드는 것이 더 나을 수 있습니다.
- 모델이 좋을수록 성능도 좋아집니다. 다른 LLM과 실험하고 결과를 비교하십시오.
실제 사용 사례
교육에서 법률, 학계 또는 사람이 엄청난 텍스트를 검토해야 하는 상상할 수 있는 모든 분야에 걸쳐 여러 분야에서 도구를 사용하십시오. PDF용 ChatGPT의 실제 사용 사례 중 일부는 다음과 같습니다.
- 교육 기관: 학생들은 교과서, 학습 자료 및 과제를 업로드할 수 있으며 도구는 질문에 답변하고 특정 섹션을 설명할 수 있습니다. 이것은 학생들에게 전반적인 학습 과정을 덜 힘들게 만들 수 있습니다.
- 이용약관: 로펌은 PDF 형식의 수많은 법률 문서를 처리해야 합니다. 이 도구를 사용하여 사건 문서, 법적 계약 및 법령에서 관련 정보를 편리하게 추출할 수 있습니다. 변호사가 조항, 판례 및 기타 정보를 더 빨리 찾는 데 도움이 될 수 있습니다.
- 학원: 연구학자들은 종종 연구논문과 기술문서를 다룬다. 문헌을 요약하고 문서에서 답을 분석하고 제공할 수 있는 도구는 전체 시간을 절약하고 생산성을 향상시킬 수 있습니다.
- 관리 : 정부 사무실 및 기타 관리 부서에서는 매일 방대한 양의 양식, 신청서 및 보고서를 처리합니다. 문서에 응답하는 챗봇을 사용하면 관리 프로세스를 간소화하여 모든 사람의 시간과 비용을 절약할 수 있습니다.
- 재무: 재무 보고서를 분석하고 몇 번이고 다시 확인하는 것이 지루합니다. 챗봇을 사용하면 더 쉽게 만들 수 있습니다. 본질적으로 인턴.
- 미디어 : 저널리스트와 분석가는 chatGPT 지원 PDF 질문 답변 도구를 사용하여 대용량 텍스트 코퍼스를 쿼리하여 신속하게 답변을 찾을 수 있습니다.
chatGPT 지원 PDF Q&A 도구는 수많은 PDF 텍스트에서 더 빠르게 정보를 수집할 수 있습니다. 텍스트 데이터 검색 엔진과 같습니다. PDF뿐만 아니라 이 도구를 약간의 코드 조작으로 텍스트 데이터가 있는 모든 것으로 확장할 수 있습니다.
결론
그래서 이것은 ChatGPT로 모든 PDF 파일과 대화할 수 있는 챗봇을 구축하는 것이었습니다. Langchain 덕분에 AI 애플리케이션 구축이 훨씬 쉬워졌습니다. 이 기사의 주요 내용은 다음과 같습니다.
- Gradio는 AI 애플리케이션 프로토타이핑을 위한 오픈 소스 도구입니다. 우리는 Gradio로 애플리케이션의 프런트 엔드를 만들었습니다.
- Langchain은 AI 애플리케이션을 구축할 수 있는 또 다른 오픈 소스 도구입니다. 인기 있는 LLM 및 벡터 데이터 저장소에 대한 래퍼가 있어 기본 서비스와 쉽게 상호 작용할 수 있습니다.
- 우리는 애플리케이션의 백엔드 시스템을 구축하기 위해 Langchain을 사용했습니다.
- OpenAI 모델은 우리 앱에 전반적으로 중요했습니다. OpenAI 임베딩 및 GPT 3.5 엔진을 사용하여 PDF와 채팅했습니다.
- PDF 및 기타 텍스트 데이터용 ChatGPT 지원 Q&A 도구는 지식 작업을 간소화하는 데 큰 도움이 될 수 있습니다.
이 기사에 표시된 미디어는 Analytics Vidhya의 소유가 아니며 작성자의 재량에 따라 사용됩니다.
관련
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- PlatoAiStream. Web3 데이터 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 미래 만들기 w Adryenn Ashley. 여기에서 액세스하십시오.
- PREIPO®로 PRE-IPO 회사의 주식을 사고 팔 수 있습니다. 여기에서 액세스하십시오.
- 출처: https://www.analyticsvidhya.com/blog/2023/05/build-a-chatgpt-for-pdfs-with-langchain/

