NFL(National Football League)은 미국에서 가장 인기 있는 스포츠 리그 중 하나이며, 세계에서 가장 가치 있는 스포츠 리그. NFL, BioCore 및 AWS는 보다 안전한 축구 경기를 만들기 위해 스포츠 관련 부상의 진단, 예방 및 치료에 대한 인간의 이해를 발전시키기 위해 노력하고 있습니다. NFL 선수 건강 및 안전 노력에 대한 자세한 내용은 다음에서 확인할 수 있습니다. NFL 웹사이트.
AWS 전문 서비스 팀은 NFL 및 Biocore와 협력하여 컴퓨터 비전(CV) 기술을 사용하여 게임 영상에서 헬멧 영향을 식별하기 위한 기계 학습(ML) 기반 솔루션을 제공합니다. 각 게임에서 여러 카메라 보기를 사용할 수 있으므로 이러한 각 보기에서 헬멧 충격을 식별하고 헬멧 충격 결과를 병합하는 솔루션을 개발했습니다.
여러 카메라 뷰를 활용하는 동기는 하나의 뷰로만 충격 이벤트를 캡처할 때 정보의 한계에서 비롯됩니다. 하나의 관점만 사용하면 일부 플레이어가 서로를 가리거나 필드의 다른 개체에 의해 차단될 수 있습니다. 따라서 더 많은 관점을 추가하면 ML 시스템이 단일 보기에서 볼 수 없는 더 많은 영향을 식별할 수 있습니다. 퓨전 프로세스의 결과와 팀이 시각화 도구를 사용하여 모델 성능을 평가하는 방법을 보여주기 위해 다중 뷰 감지 결과를 시각적으로 오버레이하는 코드베이스를 개발했습니다. 이 프로세스는 여러 보기에서 감지된 중복 영향을 제거하여 개별 플레이어가 경험하는 실제 영향 수를 식별하는 데 도움이 됩니다.
이 게시물에서는 공개적으로 사용 가능한 데이터 세트를 사용합니다. NFL – 충격 감지 Kaggle 대회 두 보기를 병합한 결과를 표시합니다. 데이터 세트에는 모든 프레임의 헬멧 경계 상자와 각 비디오에서 발견된 충격 레이블이 포함됩니다. 특히 ID로 동영상을 중복 제거하고 시각화하는 데 중점을 둡니다. 57583_000082 엔드존 및 사이드라인 보기에서. 당신은 다운로드 할 수 있습니다 엔드존 및 사이드라인 비디오, 그리고 또한 실측 레이블.
사전 조건
솔루션에는 다음이 필요합니다.
SageMaker Studio Lab 시작 및 필요한 패키지 설치
에서 노트북을 실행할 수 있습니다. GitHub의 리포지토리 또는 SageMaker Studio Lab에서. 이 게시물에서는 SageMaker Studio Lab 환경에서 노트북을 실행합니다. 우리가 SageMaker Studio Lab을 선택하는 이유는 무료이고 강력한 CPU 및 GPU 사용자 세션과 환경을 자동으로 저장하는 15GB의 영구 스토리지를 제공하여 작업을 중단한 부분부터 계속할 수 있기 때문입니다. SageMaker Studio Lab을 사용하려면 새 계정 요청 및 설정. 계정이 승인되면 다음 단계를 완료하십시오.
- 를 방문 aws 샘플 GitHub 리포지토리.
- .
README섹션 선택 오픈 스튜디오 랩.
이렇게 하면 SageMaker Studio Lab 환경으로 리디렉션됩니다.
- CPU 컴퓨팅 유형을 선택한 다음 런타임 시작.
- 런타임이 시작된 후 프로젝트에 복사, Jupyter Lab 환경으로 새 창이 열립니다.
이제 노트북을 사용할 준비가 되었습니다!
- 엽니다
fuse_and_visualize_multiview_impacts.ipynb노트북의 지침을 따릅니다.
노트북의 첫 번째 셀은 pandas 및 OpenCV와 같은 필수 Python 패키지를 설치합니다.
%pip install pandas
%pip install opencv-contrib-python-headless더 나은 시각화 경험을 위해 필요한 모든 Python 패키지를 가져오고 pandas 옵션을 설정합니다.
import os
import cv2
import pandas as pd
import numpy as np
pd.set_option('mode.chained_assignment', None)주석이 달린 헬멧 경계 상자와 영향이 있는 CSV 파일을 통해 수집하고 구문 분석하기 위해 pandas를 사용합니다. 우리는 주로 배열과 행렬을 조작하기 위해 NumPy를 사용합니다. Python에서 이미지 데이터를 읽고 쓰고 조작하기 위해 OpenCV를 사용합니다.
두 가지 보기의 결과를 융합하여 데이터 준비
두 가지 관점을 융합하기 위해 우리는 다음을 사용합니다. train_labels.csv 예를 들어 Kaggle 경쟁에서 endzone과 sideline 모두의 ground truth 영향을 포함하기 때문입니다. 다음 함수는 입력 데이터 세트를 가져와 입력 데이터 세트의 모든 재생에 대해 중복 제거된 융합 데이터 프레임을 출력합니다.
def prep_data(df): df['game_play'] = df['gameKey'].astype('str') + '_' + df['playID'].astype('str').str.zfill(6) return df def dedup_view(df, windows): # define view df = df.sort_values(by='frame') view_columns = ['frame', 'left', 'width', 'top', 'height', 'video'] common_columns = ['game_play', 'label', 'view', 'impactType'] label_cleaned = df[view_columns + common_columns] # rename columns sideline_column_rename = {col: 'Sideline_' + col for col in view_columns} endzone_column_rename = {col: 'Endzone_' + col for col in view_columns} sideline_columns = list(sideline_column_rename.values()) # create two dataframes, one for sideline, one for endzone label_endzone = label_cleaned.query('view == "Endzone"') label_endzone.rename(columns=endzone_column_rename, inplace=True) label_sideline = label_cleaned.query('view == "Sideline"') label_sideline.rename(columns=sideline_column_rename, inplace=True) # prepare sideline labels label_sideline['is_dup'] = False for columns in sideline_columns: label_endzone[columns] = np.nan label_endzone['is_dup'] = False # iterrate endzone rows to find matches and dedup for index, row in label_endzone.iterrows(): player = row['label'] frame = row['Endzone_frame'] impact_type = row['impactType'] sideline_row = label_sideline[(label_sideline['label'] == player) & ((label_sideline['Sideline_frame'] >= frame - windows // 2) & (label_sideline['Sideline_frame'] <= frame + windows // 2 + 1)) & (label_sideline['is_dup'] == False) & (label_sideline['impactType'] == impact_type)] if len(sideline_row) > 0: sideline_index = sideline_row.index[0] label_sideline['is_dup'].loc[sideline_index] = True for col in sideline_columns: label_endzone[col].loc[index] = sideline_row.iloc[0][col] label_endzone['is_dup'].loc[index] = True # calculate overlap perc not_dup_sideline = label_sideline[label_sideline['is_dup'] == False] final_output = pd.concat([not_dup_sideline, label_endzone]) return final_output def fuse_df(raw_df, windows): outputs = [] all_game_play = raw_df['game_play'].unique() for game_play in all_game_play: df = raw_df.query('game_play ==@game_play') output = dedup_view(df, windows) outputs.append(output) output_df = pd.concat(outputs) output_df['gameKey'] = output_df['game_play'].apply(lambda x: x.split('_')[0]).map(int) output_df['playID'] = output_df['game_play'].apply(lambda x: x.split('_')[1]).map(int) return output_df함수를 실행하기 위해 다음 코드 블록을 실행하여 train_labels.csv 그런 다음 데이터 준비를 수행하여 추가 열을 추가하고 영향 행만 추출합니다. 함수를 실행한 후 출력을 데이터 프레임 변수에 저장합니다. fused_df.
# read the annotated impact data from train_labels.csv
ground_truth = pd.read_csv('train_labels.csv') # prepare game_play column using pipe(prep_data) function in pandas then filter the dataframe for just rows with impacts
ground_truth = ground_truth.pipe(prep_data).query('impact == 1') # loop over all the unique game_plays and deduplicate the impact results from sideline and endzone
fused_df = fuse_df(ground_truth, windows=30)
다음 스크린샷은 실측 정보를 보여줍니다.

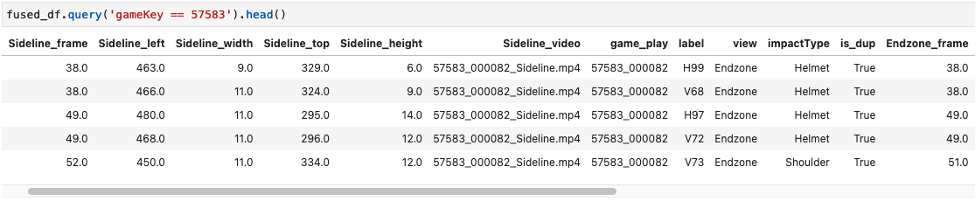
다음 스크린샷은 융합된 데이터 프레임 예제를 보여줍니다.
그래프 및 비디오 코드
충격 결과를 융합한 후 생성된 fused_df 결과를 엔드존 및 사이드라인 비디오에 오버레이하고 두 보기를 병합합니다. 이를 위해 다음 함수를 사용하며 필요한 입력은 endzone video, sideline video, fused_df 데이터 프레임 및 새로 생성된 비디오의 최종 출력 경로. 이 섹션에서 사용되는 기능은 SageMaker Studio Lab에서 사용되는 노트북의 마크다운 섹션에 설명되어 있습니다.
def get_video_and_metadata(vid_path): vid = cv2.VideoCapture(vid_path) total_frame_number = vid.get(cv2.CAP_PROP_FRAME_COUNT) width = int(vid.get(cv2.CAP_PROP_FRAME_WIDTH)) height = int(vid.get(cv2.CAP_PROP_FRAME_HEIGHT)) fps = vid.get(cv2.CAP_PROP_FPS) return vid, total_frame_number, width, height, fps def overlay_impacts(frame, fused_df, game_key, play_id, frame_cnt, h1): # look for duplicates duplicates = fused_df.query(f"gameKey == {int(game_key)} and playID == {int(play_id)} and is_dup == True and Sideline_frame == @frame_cnt") frame_has_impact = False if len(duplicates) > 0: for duplicate in duplicates.itertuples(index=False): if frame_cnt == duplicate.Sideline_frame: frame_has_impact = True if frame_has_impact: cv2.rectangle(frame, #frame to be edited (int(duplicate.Sideline_left), int(duplicate.Sideline_top)), #(x,y) of top left corner (int(duplicate.Sideline_left) + int(duplicate.Sideline_width), int(duplicate.Sideline_top) + int(duplicate.Sideline_height)), #(x,y) of bottom right corner (0,0,255), #RED boxes thickness=3) cv2.rectangle(frame, #frame to be edited (int(duplicate.Endzone_left), int(duplicate.Endzone_top)+ h1), #(x,y) of top left corner (int(duplicate.Endzone_left) + int(duplicate.Endzone_width), int(duplicate.Endzone_top) + int(duplicate.Endzone_height) + h1), #(x,y) of bottom right corner (0,0,255), #RED boxes thickness=3) cv2.line(frame, #frame to be edited (int(duplicate.Sideline_left), int(duplicate.Sideline_top)), #(x,y) of point 1 in a line (int(duplicate.Endzone_left), int(duplicate.Endzone_top) + h1), #(x,y) of point 2 in a line (255, 255, 255), # WHITE lines thickness=4) else: # if no duplicates, look for sideline then endzone and add to the view sl_impacts = fused_df.query(f"gameKey == {int(game_key)} and playID == {int(play_id)} and is_dup == False and view == 'Sideline' and Sideline_frame == @frame_cnt") if len(sl_impacts) > 0: for impact in sl_impacts.itertuples(index=False): if frame_cnt == impact.Sideline_frame: frame_has_impact = True if frame_has_impact: cv2.rectangle(frame, #frame to be edited (int(impact.Sideline_left), int(impact.Sideline_top)), #(x,y) of top left corner (int(impact.Sideline_left) + int(impact.Sideline_width), int(impact.Sideline_top) + int(impact.Sideline_height)), #(x,y) of bottom right corner (0, 255, 255), #YELLOW BOXES thickness=3) ez_impacts = fused_df.query(f"gameKey == {int(game_key)} and playID == {int(play_id)} and is_dup == False and view == 'Endzone' and Endzone_frame == @frame_cnt") if len(ez_impacts) > 0: for impact in ez_impacts.itertuples(index=False): if frame_cnt == impact.Endzone_frame: frame_has_impact = True if frame_has_impact: cv2.rectangle(frame, #frame to be edited (int(impact.Endzone_left), int(impact.Endzone_top)+ h1), #(x,y) of top left corner (int(impact.Endzone_left) + int(impact.Endzone_width), int(impact.Endzone_top) + int(impact.Endzone_height) + h1 ), #(x,y) of bottom right corner (0, 255, 255), #YELLOW BOXES thickness=3) return frame, frame_has_impact def generate_impact_video(ez_vid_path:str, sl_vid_path:str, fused_df:pd.DataFrame, output_path:str, freeze_impacts=True): #define video codec to be used for VIDEO_CODEC = "MP4V" # parse game_key and play_id information from the name of the files game_key = os.path.basename(ez_vid_path).split('_')[0] # parse game_key play_id = os.path.basename(ez_vid_path).split('_')[1] # parse play_id # get metadata such as total frame number, width, height and frames per second (FPS) from endzone (ez) and sideline (sl) videos ez_vid, ez_total_frame_number, ez_width, ez_height, ez_fps = get_video_and_metadata(ez_vid_path) sl_vid, sl_total_frame_number, sl_width, sl_height, sl_fps = get_video_and_metadata(sl_vid_path) # define a video writer for the output video output_video = cv2.VideoWriter(output_path, #output file name cv2.VideoWriter_fourcc(*VIDEO_CODEC), #Video codec ez_fps, #frames per second in the output video (ez_width, ez_height+sl_height)) # frame size with stacking video vertically # find shorter video and use the total frame number from the shorter video for the output video total_frame_number = int(min(ez_total_frame_number, sl_total_frame_number)) # iterate through each frame from endzone and sideline for frame_cnt in range(total_frame_number): frame_has_impact = False frame_near_impact = False # reading frames from both endzone and sideline ez_ret, ez_frame = ez_vid.read() sl_ret, sl_frame = sl_vid.read() # creating strings to be added to the output frames img_name = f"Game key: {game_key}, Play ID: {play_id}, Frame: {frame_cnt}" video_frame = f'{game_key}_{play_id}_{frame_cnt}' if ez_ret == True and sl_ret == True: h, w, c = ez_frame.shape h1,w1,c1 = sl_frame.shape if h != h1 or w != w1: # resize images if they're different ez_frame = cv2.resize(ez_frame,(w1,h1)) frame = np.concatenate((sl_frame, ez_frame), axis=0) # stack the frames vertically frame, frame_has_impact = overlay_impacts(frame, fused_df, game_key, play_id, frame_cnt, h1) cv2.putText(frame, #image frame to be modified img_name, #string to be inserted (30, 30), #(x,y) location of the string cv2.FONT_HERSHEY_SIMPLEX, #font 1, #scale (255, 255, 255), #WHITE letters thickness=2) cv2.putText(frame, #image frame to be modified str(frame_cnt), #frame count string to be inserted (w1-75, h1-20), #(x,y) location of the string in the top view cv2.FONT_HERSHEY_SIMPLEX, #font 1, #scale (255, 255, 255), # WHITE letters thickness=2) cv2.putText(frame, #image frame to be modified str(frame_cnt), #frame count string to be inserted (w1-75, h1+h-20), #(x,y) location of the string in the bottom view cv2.FONT_HERSHEY_SIMPLEX, #font 1, #scale (255, 255, 255), # WHITE letters thickness=2) output_video.write(frame) # Freeze for 60 frames on impacts if frame_has_impact and freeze_impacts: for _ in range(60): output_video.write(frame) else: break frame_cnt += 1 output_video.release() return이러한 기능을 실행하기 위해 다음 코드와 같이 입력을 제공할 수 있습니다. output.mp4:
generate_impact_video('57583_000082_Endzone.mp4', '57583_000082_Sideline.mp4', fused_df, 'output.mp4')이렇게 하면 다음 예와 같이 비디오가 생성됩니다. 여기서 빨간색 경계 상자는 엔드존과 사이드라인 보기 모두에서 발견되는 임팩트이고 노란색 경계 상자는 엔드존 또는 사이드라인에서 하나의 보기에서만 발견되는 임팩트입니다.
결론
이 게시물에서는 NFL, Biocore 및 AWS ProServe 팀이 여러 보기의 결과를 융합하여 충격 감지를 개선하기 위해 어떻게 협력하고 있는지 시연했습니다. 이를 통해 팀은 모델이 정성적으로 수행되는 방식을 디버깅하고 시각화할 수 있습니다. 이 프로세스는 XNUMX개 이상의 보기로 쉽게 확장할 수 있습니다. 프로젝트에서 최대 XNUMX개의 서로 다른 보기를 활용했습니다. 하나의 뷰에서만 비디오를 시청하여 헬멧 충격을 감지하는 것은 뷰 방해로 인해 어려울 수 있지만 여러 뷰에서 충격을 감지하고 결과를 융합하면 모델 성능을 향상시킬 수 있습니다.
이 솔루션을 실험하려면 다음을 방문하십시오. aws 샘플 GitHub 리포지토리 및 참조 퓨즈_and_visualize_multiview_impacts.ipynb 공책. 유사한 기술을 제조, 소매 및 보안과 같은 다른 산업에도 적용할 수 있습니다. 여기서 여러 보기를 사용하면 ML 시스템이 보다 포괄적인 보기로 대상을 더 잘 식별하는 데 도움이 됩니다.
NFL 선수 건강 및 안전에 대한 자세한 내용은 다음을 방문하십시오. NFL 웹사이트 과 NFL 설명: 선수 건강 및 안전의 혁신.
저자 소개
 크리스 붐 하워 AWS Professional Services의 기계 학습 엔지니어입니다. Chris는 다양한 산업 분야에서 지도 및 비지도 머신 러닝 솔루션을 개발한 6년 이상의 경험을 가지고 있습니다. 현재 그는 스포츠, 의료 및 농업 산업의 고객이 확장 가능한 엔드 투 엔드 머신 러닝 솔루션을 설계하고 구축하는 데 대부분의 시간을 할애하고 있습니다.
크리스 붐 하워 AWS Professional Services의 기계 학습 엔지니어입니다. Chris는 다양한 산업 분야에서 지도 및 비지도 머신 러닝 솔루션을 개발한 6년 이상의 경험을 가지고 있습니다. 현재 그는 스포츠, 의료 및 농업 산업의 고객이 확장 가능한 엔드 투 엔드 머신 러닝 솔루션을 설계하고 구축하는 데 대부분의 시간을 할애하고 있습니다.
 벤 펜커 AWS Professional Services의 선임 데이터 과학자이며 고객이 스포츠에서 의료, 제조에 이르기까지 다양한 산업에서 ML 솔루션을 구축하고 배포하는 데 도움을 주었습니다. 그는 박사 학위를 가지고 있습니다. Texas A&M University에서 물리학을 전공하고 6년의 업계 경험을 쌓았습니다. Ben은 야구, 독서, 자녀 양육을 즐깁니다.
벤 펜커 AWS Professional Services의 선임 데이터 과학자이며 고객이 스포츠에서 의료, 제조에 이르기까지 다양한 산업에서 ML 솔루션을 구축하고 배포하는 데 도움을 주었습니다. 그는 박사 학위를 가지고 있습니다. Texas A&M University에서 물리학을 전공하고 6년의 업계 경험을 쌓았습니다. Ben은 야구, 독서, 자녀 양육을 즐깁니다.
 샘 허들 스턴 NFL의 Digital Athlete 프로그램의 기술 책임자인 Biocore LLC의 수석 데이터 과학자입니다. Biocore는 버지니아 주 Charlottesville에 기반을 둔 세계적 수준의 엔지니어 팀으로 부상의 이해와 감소에 전념하는 고객에게 연구, 테스트, 생체 역학 전문 지식, 모델링 및 기타 엔지니어링 서비스를 제공합니다.
샘 허들 스턴 NFL의 Digital Athlete 프로그램의 기술 책임자인 Biocore LLC의 수석 데이터 과학자입니다. Biocore는 버지니아 주 Charlottesville에 기반을 둔 세계적 수준의 엔지니어 팀으로 부상의 이해와 감소에 전념하는 고객에게 연구, 테스트, 생체 역학 전문 지식, 모델링 및 기타 엔지니어링 서비스를 제공합니다.
 자비스 리 AWS Professional Services의 선임 데이터 과학자입니다. 그는 AWS에서 XNUMX년 이상 근무하면서 기계 학습 및 컴퓨터 비전 문제에 대해 고객과 협력했습니다. 업무 외에는 자전거 타기를 즐깁니다.
자비스 리 AWS Professional Services의 선임 데이터 과학자입니다. 그는 AWS에서 XNUMX년 이상 근무하면서 기계 학습 및 컴퓨터 비전 문제에 대해 고객과 협력했습니다. 업무 외에는 자전거 타기를 즐깁니다.
 타일러 멀렌바흐 AWS Professional Services에서 ML의 글로벌 실무 책임자입니다. 그는 전문 서비스용 ML의 전략적 방향을 주도하고 고객이 ML 기술 채택을 통해 혁신적인 비즈니스 성과를 실현하도록 보장하는 일을 담당하고 있습니다.
타일러 멀렌바흐 AWS Professional Services에서 ML의 글로벌 실무 책임자입니다. 그는 전문 서비스용 ML의 전략적 방향을 주도하고 고객이 ML 기술 채택을 통해 혁신적인 비즈니스 성과를 실현하도록 보장하는 일을 담당하고 있습니다.
 케빈 송 AWS Professional Services의 데이터 과학자입니다. 그는 생물 물리학 박사 학위를 보유하고 있으며 컴퓨터 비전 및 기계 학습 솔루션 구축 분야에서 5년 이상의 업계 경험을 가지고 있습니다.
케빈 송 AWS Professional Services의 데이터 과학자입니다. 그는 생물 물리학 박사 학위를 보유하고 있으며 컴퓨터 비전 및 기계 학습 솔루션 구축 분야에서 5년 이상의 업계 경험을 가지고 있습니다.
 베티 장 데이터 및 기술 분야에서 10년의 경력을 가진 데이터 과학자입니다. 그녀의 열정은 혁신적인 기계 학습 솔루션을 구축하여 회사의 변혁적 변화를 주도하는 것입니다. 여가 시간에는 여행, 독서, 신기술 학습을 즐깁니다.
베티 장 데이터 및 기술 분야에서 10년의 경력을 가진 데이터 과학자입니다. 그녀의 열정은 혁신적인 기계 학습 솔루션을 구축하여 회사의 변혁적 변화를 주도하는 것입니다. 여가 시간에는 여행, 독서, 신기술 학습을 즐깁니다.
- SEO 기반 콘텐츠 및 PR 배포. 오늘 증폭하십시오.
- 플라토 블록체인. Web3 메타버스 인텔리전스. 지식 증폭. 여기에서 액세스하십시오.
- 출처: https://aws.amazon.com/blogs/machine-learning/analyze-and-visualize-multi-camera-events-using-amazon-sagemaker-studio-lab/

