강력하고 재사용 가능한 머신 러닝(ML) 파이프라인을 만드는 것은 복잡하고 시간이 많이 소요되는 프로세스일 수 있습니다. 개발자는 일반적으로 처리 및 교육 스크립트를 로컬에서 테스트하지만 파이프라인 자체는 일반적으로 클라우드에서 테스트합니다. 실험 중에 전체 파이프라인을 만들고 실행하면 개발 수명 주기에 원치 않는 오버헤드와 비용이 추가됩니다. 이 게시물에서는 사용 방법에 대해 자세히 설명합니다. Amazon SageMaker 파이프라인 로컬 모드 ML 파이프라인을 로컬에서 실행하여 파이프라인 개발과 실행 시간을 모두 줄이는 동시에 비용을 절감합니다. 파이프라인이 로컬에서 완전히 테스트된 후 다음을 사용하여 쉽게 다시 실행할 수 있습니다. 아마존 세이지 메이커 몇 줄의 코드 변경만으로 관리되는 리소스.
ML 수명 주기 개요
ML의 새로운 혁신과 애플리케이션의 주요 동인 중 하나는 더 저렴한 컴퓨팅 옵션과 함께 데이터의 가용성과 양입니다. 여러 영역에서 ML은 기존의 빅 데이터 및 분석 기술로 이전에 해결할 수 없었던 문제를 해결할 수 있음이 입증되었으며 데이터 과학 및 ML 실무자에 대한 수요가 꾸준히 증가하고 있습니다. 매우 높은 수준에서 ML 수명 주기는 다양한 부분으로 구성되지만 ML 모델 구축은 일반적으로 다음과 같은 일반적인 단계로 구성됩니다.
- 데이터 정리 및 준비(기능 엔지니어링)
- 모델 교육 및 조정
- 모델 평가
- 모델 배포(또는 일괄 변환)
데이터 준비 단계에서 데이터가 로드되고, 마사지되고, ML 모델이 예상하는 입력 유형 또는 기능으로 변환됩니다. 데이터 변환을 위한 스크립트 작성은 일반적으로 반복적인 프로세스이며, 여기서 빠른 피드백 루프는 개발 속도를 높이는 데 중요합니다. 일반적으로 기능 엔지니어링 스크립트를 테스트할 때 전체 데이터 세트를 사용할 필요가 없으므로 다음을 사용할 수 있습니다. 로컬 모드 기능 SageMaker 처리의. 이를 통해 로컬에서 실행하고 더 작은 데이터 세트를 사용하여 반복적으로 코드를 업데이트할 수 있습니다. 최종 코드가 준비되면 완전한 데이터 세트를 사용하고 SageMaker 관리형 인스턴스에서 실행되는 원격 처리 작업에 제출됩니다.
개발 프로세스는 모델 교육 및 모델 평가 단계 모두에 대한 데이터 준비 단계와 유사합니다. 데이터 과학자는 다음을 사용합니다. 로컬 모드 기능 ML 최적화 인스턴스의 SageMaker 관리 클러스터에서 모든 데이터를 사용하기 전에 로컬에서 더 작은 데이터 세트로 빠르게 반복하기 위해 SageMaker Training의. 이는 개발 프로세스의 속도를 높이고 실험하는 동안 SageMaker에서 관리하는 ML 인스턴스를 실행하는 비용을 제거합니다.
조직의 ML 성숙도가 증가함에 따라 다음을 사용할 수 있습니다. Amazon SageMaker 파이프 라인 이러한 단계를 연결하는 ML 파이프라인을 생성하여 ML 모델을 처리, 교육 및 평가하는 더 복잡한 ML 워크플로를 생성합니다. SageMaker Pipelines는 데이터 로드, 데이터 변환, 모델 교육 및 조정, 모델 배포를 포함하여 ML 워크플로의 다양한 단계를 자동화하기 위한 완전 관리형 서비스입니다. 최근까지 로컬에서 스크립트를 개발하고 테스트할 수 있었지만 클라우드에서 ML 파이프라인을 테스트해야 했습니다. 이로 인해 ML 파이프라인의 흐름과 형태를 반복하는 과정이 느리고 비용이 많이 듭니다. 이제 SageMaker Pipelines의 추가된 로컬 모드 기능을 사용하여 처리 및 교육 스크립트에서 테스트 및 반복하는 방법과 유사하게 ML 파이프라인을 반복 및 테스트할 수 있습니다. 소규모 데이터 하위 집합을 사용하여 파이프라인 구문 및 기능을 검증하여 로컬 머신에서 파이프라인을 실행하고 테스트할 수 있습니다.
SageMaker 파이프 라인
SageMaker Pipelines는 단순하거나 복잡한 ML 워크플로를 실행하는 완전히 자동화된 방법을 제공합니다. SageMaker Pipelines를 사용하면 사용하기 쉬운 Python SDK로 ML 워크플로를 만든 다음 다음을 사용하여 워크플로를 시각화하고 관리할 수 있습니다. 아마존 세이지 메이커 스튜디오. 데이터 과학 팀은 SageMaker Pipelines에서 생성한 워크플로 단계를 저장하고 재사용하여 보다 효율적이고 빠르게 확장할 수 있습니다. 인프라 및 리포지토리 생성을 자동화하는 사전 구축된 템플릿을 사용하여 ML 환경 내에서 모델을 구축, 테스트, 등록 및 배포할 수도 있습니다. 이러한 템플릿은 조직에서 자동으로 사용할 수 있으며 다음을 사용하여 프로비저닝됩니다. AWS 서비스 카탈로그 제품보기.
SageMaker Pipelines는 개발 및 프로덕션 환경 간의 패리티 유지, 버전 제어, 주문형 테스트 및 종단 간 자동화와 같은 ML에 지속적인 통합 및 연속 배포(CI/CD) 사례를 제공하여 전체 ML을 확장하는 데 도움이 됩니다. 조직. DevOps 실무자는 CI/CD 기술 사용의 주요 이점 중 일부에 재사용 가능한 구성 요소를 통한 생산성 향상 및 자동화된 테스트를 통한 품질 향상이 포함되어 비즈니스 목표에 대한 더 빠른 ROI로 이어진다는 것을 알고 있습니다. 이러한 이점은 이제 SageMaker Pipelines를 사용하여 ML 모델의 교육, 테스트 및 배포를 자동화함으로써 MLOps 실무자가 사용할 수 있습니다. 로컬 모드를 사용하면 파이프라인에서 사용할 스크립트를 개발하는 동안 훨씬 더 빠르게 반복할 수 있습니다. 로컬 파이프라인 인스턴스는 Studio IDE 내에서 보거나 실행할 수 없습니다. 그러나 로컬 파이프라인에 대한 추가 보기 옵션이 곧 제공될 예정입니다.
SageMaker SDK는 범용 로컬 모드 구성 이를 통해 개발자는 로컬 환경에서 지원되는 프로세서 및 추정기를 실행하고 테스트할 수 있습니다. 여러 AWS 지원 프레임워크 이미지(TensorFlow, MXNet, Chainer, PyTorch 및 Scikit-Learn)와 직접 제공한 이미지로 로컬 모드 교육을 사용할 수 있습니다.
오케스트레이션된 워크플로 단계의 DAG(Directed Acyclic Graph)를 구축하는 SageMaker Pipelines는 ML 수명 주기의 일부인 많은 활동을 지원합니다. 로컬 모드에서는 다음 단계가 지원됩니다.
- 작업 단계 처리 – 기능 엔지니어링, 데이터 유효성 검사, 모델 평가 및 모델 해석과 같은 데이터 처리 워크로드를 실행하기 위한 SageMaker의 간소화된 관리 환경
- 교육 작업 단계 – 훈련 데이터 세트의 예를 제시하여 모델이 예측을 하도록 가르치는 반복 프로세스
- 초매개변수 조정 작업 – 가장 정확한 모델을 생성하는 하이퍼파라미터를 평가하고 선택하는 자동화된 방법
- 조건부 실행 단계 – 파이프라인에서 분기의 조건부 실행을 제공하는 단계
- 모델 단계 – CreateModel 인수를 사용하여 이 단계는 변환 단계에서 사용하거나 나중에 엔드포인트로 배포할 모델을 생성할 수 있습니다.
- 작업 단계 변환 – 대규모 데이터 세트에서 예측을 생성하고 영구 엔드포인트가 필요하지 않을 때 추론을 실행하는 일괄 변환 작업
- 실패 단계 – 파이프라인 실행을 중지하고 실행을 실패로 표시하는 단계
솔루션 개요
우리의 솔루션은 로컬 모드에서 SageMaker 파이프라인을 생성하고 실행하기 위한 필수 단계를 보여줍니다. 즉, 로컬 CPU, RAM 및 디스크 리소스를 사용하여 워크플로 단계를 로드하고 실행합니다. 로컬 환경은 VSCode 또는 PyCharm과 같은 널리 사용되는 IDE를 사용하여 랩톱에서 실행되거나 클래식 노트북 인스턴스를 사용하여 SageMaker에서 호스팅될 수 있습니다.
로컬 모드를 사용하면 데이터 과학자가 처리, 교육 및 평가 작업을 포함할 수 있는 단계를 결합하고 전체 워크플로를 로컬에서 실행할 수 있습니다. 로컬에서 테스트를 완료하면 SageMaker 관리 환경에서 파이프라인을 교체하여 파이프라인을 다시 실행할 수 있습니다. LocalPipelineSession ~을 가진 대상 PipelineSession, ML 수명 주기에 일관성을 제공합니다.
이 노트북 샘플에서는 공개적으로 사용 가능한 표준 데이터 세트를 사용합니다. UCI 기계 학습 전복 데이터 세트. 목표는 물리적 측정에서 전복 달팽이의 나이를 결정하도록 ML 모델을 훈련시키는 것입니다. 핵심은 회귀 문제입니다.
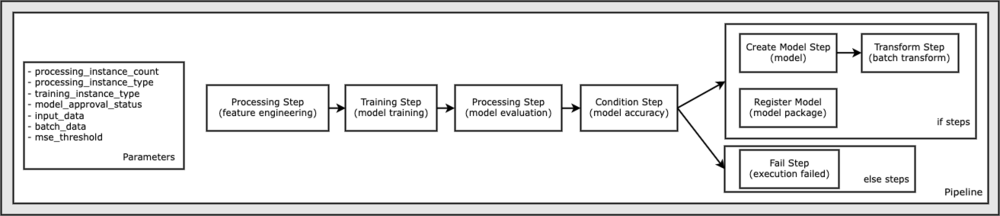
이 노트북 샘플을 실행하는 데 필요한 모든 코드는 GitHub의 amazon-sagemaker-예제 저장소. 이 노트북 샘플에서 각 파이프라인 워크플로 단계는 독립적으로 생성된 다음 파이프라인을 생성하기 위해 함께 연결됩니다. 다음 단계를 생성합니다.
- 처리 단계(특징 엔지니어링)
- 훈련 단계(모델 훈련)
- 처리 단계(모델 평가)
- 조건 단계(모델 정확도)
- 모델 생성 단계(모델)
- 변환 단계(일괄 변환)
- 모델 단계 등록(모델 패키지)
- 실패 단계(실행 실패)
다음 다이어그램은 파이프라인을 보여줍니다.
사전 조건
이 게시물을 따라 하려면 다음이 필요합니다.
이러한 전제 조건이 갖추어지면 다음 섹션에 설명된 대로 샘플 노트북을 실행할 수 있습니다.
파이프라인 구축
이 노트북 샘플에서는 다음을 사용합니다. SageMaker 스크립트 모드 이는 대부분의 ML 프로세스에서 활동을 수행하고 이 코드에 대한 참조를 전달하기 위한 실제 Python 코드(스크립트)를 제공한다는 것을 의미합니다. 스크립트 모드는 XGBoost 또는 Scikit-Learn과 같은 SageMaker 사전 구축 컨테이너를 계속 활용하면서 코드를 사용자 지정할 수 있도록 하여 SageMaker 처리 내에서 동작을 제어할 수 있는 뛰어난 유연성을 제공합니다. 사용자 지정 코드는 magic 명령으로 시작하는 셀을 사용하여 Python 스크립트 파일에 작성됩니다. %%writefile, 다음과 같이:
%%writefile code/evaluation.py
로컬 모드의 기본 Enabler는 LocalPipelineSession Python SDK에서 인스턴스화된 개체입니다. 다음 코드 세그먼트는 로컬 모드에서 SageMaker 파이프라인을 생성하는 방법을 보여줍니다. 많은 로컬 파이프라인 단계에 대해 로컬 데이터 경로를 구성할 수 있지만 Amazon S3는 변환에 의한 데이터 출력을 저장하는 기본 위치입니다. 새로운 LocalPipelineSession 객체는 이 게시물에 설명된 많은 SageMaker 워크플로 API 호출에서 Python SDK로 전달됩니다. 사용할 수 있습니다. local_pipeline_session 변수를 사용하여 S3 기본 버킷 및 현재 리전 이름에 대한 참조를 검색합니다.
개별 파이프라인 단계를 생성하기 전에 파이프라인에서 사용하는 몇 가지 매개변수를 설정합니다. 이러한 매개변수 중 일부는 문자열 리터럴인 반면 다른 매개변수는 SDK에서 제공하는 특수 열거 유형으로 생성됩니다. 열거형 입력은 유효한 설정이 파이프라인에 제공되도록 합니다(예: 파이프라인에 전달됨). ConditionLessThanOrEqualTo 더 아래로:
mse_threshold = ParameterFloat(name="MseThreshold", default_value=7.0)
여기에서 기능 엔지니어링을 수행하는 데 사용되는 데이터 처리 단계를 생성하기 위해 다음을 사용합니다. SKLearnProcessor 데이터 세트를 로드하고 변환합니다. 우리는 통과 local_pipeline_session 워크플로 단계가 로컬 모드에서 실행되도록 지시하는 클래스 생성자에 대한 변수:
다음으로 첫 번째 실제 파이프라인 단계를 생성합니다. ProcessingStep SageMaker SDK에서 가져온 개체. 프로세서 인수는 호출에서 반환됩니다. SKLearnProcessor run() 메서드. 이 워크플로 단계는 노트북 끝으로 향하는 다른 단계와 결합되어 파이프라인 내 작업 순서를 나타냅니다.
다음으로 SageMaker SDK를 사용하여 표준 추정기를 먼저 인스턴스화하여 교육 단계를 설정하는 코드를 제공합니다. 우리는 같은 것을 통과 local_pipeline_session xgb_train이라는 추정기에 대한 변수는 sagemaker_session 논쟁. XGBoost 모델을 훈련시키려면 프레임워크 및 여러 버전 매개변수를 포함하여 다음 매개변수를 지정하여 유효한 이미지 URI를 생성해야 합니다.
선택적으로 추가 추정기 메서드를 호출할 수 있습니다. 예를 들어 set_hyperparameters(), 훈련 작업에 대한 초매개변수 설정을 제공합니다. 이제 추정기가 구성되었으므로 실제 훈련 단계를 생성할 준비가 되었습니다. 다시 한 번, 우리는 수입 TrainingStep SageMaker SDK 라이브러리의 클래스:
다음으로, 모델 평가를 수행하기 위한 또 다른 처리 단계를 구축합니다. 이것은 생성하여 수행됩니다. ScriptProcessor 인스턴스 및 전달 local_pipeline_session 매개변수로 객체:
훈련된 모델의 배포를 활성화하려면 SageMaker 실시간 끝점 또는 일괄 변환에 대해 Model 모델 아티팩트, 적절한 이미지 URI 및 선택적으로 사용자 정의 추론 코드를 전달하여 객체를 생성합니다. 우리는 다음 이것을 통과 Model 에 반대 ModelStep, 로컬 파이프라인에 추가됩니다. 다음 코드를 참조하십시오.
다음으로, 특징 벡터 세트를 제출하고 추론을 수행하는 일괄 변환 단계를 생성합니다. 먼저 생성해야 합니다. Transformer 이의를 제기하고 통과 local_pipeline_session 매개변수. 그런 다음 우리는 TransformStep, 필수 인수를 전달하고 이를 파이프라인 정의에 추가합니다.
마지막으로 모델 평가 결과가 기준을 충족하는 경우에만 일괄 변환을 실행하도록 워크플로에 분기 조건을 추가하려고 합니다. 다음을 추가하여 이 조건부를 나타낼 수 있습니다. ConditionStep 다음과 같은 특정 조건 유형을 사용하여 ConditionLessThanOrEqualTo. 그런 다음 기본적으로 파이프라인의 if/else 또는 true/false 분기를 정의하여 두 분기에 대한 단계를 열거합니다. 에 제공된 if_steps ConditionStep (step_create_model, step_transform)는 조건이 다음과 같이 평가될 때마다 실행됩니다. True.
다음 다이어그램은 이 조건부 분기 및 연결된 if/else 단계를 보여줍니다. 조건 단계에서 비교한 모델 평가 단계의 결과에 따라 하나의 분기만 실행됩니다.
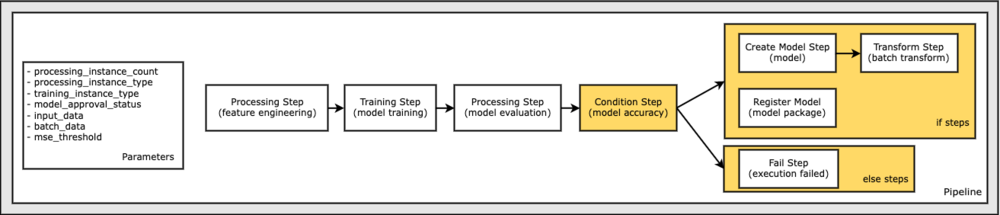
이제 모든 단계가 정의되고 기본 클래스 인스턴스가 생성되었으므로 이를 파이프라인으로 결합할 수 있습니다. 우리는 몇 가지 매개변수를 제공하고 단순히 원하는 순서로 단계를 나열하여 작업 순서를 결정적으로 정의합니다. 참고로 TransformStep 조건부 단계의 대상이기 때문에 여기에 표시되지 않으며 단계 인수로 제공되었습니다. ConditionalStep 일찍이.
파이프라인을 실행하려면 두 가지 메서드를 호출해야 합니다. pipeline.upsert()기본 서비스에 파이프라인을 업로드하는 , pipeline.start(), 파이프라인 실행을 시작합니다. 다양한 다른 방법을 사용하여 실행 상태를 조사하고 파이프라인 단계를 나열하는 등의 작업을 수행할 수 있습니다. 로컬 모드 파이프라인 세션을 사용했기 때문에 이러한 단계는 모두 프로세서에서 로컬로 실행됩니다. start 메소드 아래의 셀 출력은 파이프라인의 출력을 보여줍니다.
셀 출력 하단에 다음과 유사한 메시지가 표시되어야 합니다.
Pipeline execution d8c3e172-089e-4e7a-ad6d-6d76caf987b7 SUCCEEDED
관리 리소스로 되돌리기
파이프라인이 오류 없이 실행되고 파이프라인의 흐름과 형식에 만족하고 나면 SageMaker 관리 리소스를 사용하여 파이프라인을 다시 생성하고 다시 실행할 수 있습니다. 필요한 유일한 변경 사항은 PipelineSession 대신 개체 LocalPipelineSession:
에 sagemaker.workflow.pipeline_context 가져오기 LocalPipelineSessionfrom sagemaker.workflow.pipeline_context import PipelineSession
local_pipeline_session=LocalPipelineSession()pipeline_session = PipelineSession()
이는 SageMaker 관리 리소스에서 이 세션 개체를 참조하는 각 단계를 실행하도록 서비스에 알립니다. 작은 변경 사항이 주어지면 다음 코드 셀에서 필요한 코드 변경 사항만 설명하지만 동일한 변경 사항을 사용하여 각 셀에서 구현해야 합니다. local_pipeline_session 물체. 그러나 변경 사항은 모든 셀에서 동일합니다. local_pipeline_session 개체 pipeline_session 목적.
로컬 세션 개체가 모든 곳에서 교체된 후 파이프라인을 다시 만들고 SageMaker 관리 리소스로 실행합니다.
정리
Studio 환경을 깔끔하게 유지하려면 다음 방법을 사용하여 SageMaker 파이프라인 및 모델을 삭제할 수 있습니다. 전체 코드는 샘플에서 찾을 수 있습니다. 수첩.
결론
최근까지 SageMaker Processing 및 SageMaker Training의 로컬 모드 기능을 사용하여 SageMaker 관리 리소스로 모든 데이터에서 실행하기 전에 로컬에서 처리 및 교육 스크립트를 반복할 수 있었습니다. SageMaker Pipelines의 새로운 로컬 모드 기능을 통해 ML 실무자는 이제 ML 파이프라인을 반복할 때 동일한 방법을 적용하여 서로 다른 ML 워크플로를 결합할 수 있습니다. 파이프라인이 프로덕션 준비가 되면 SageMaker 관리 리소스로 파이프라인을 실행하려면 몇 줄의 코드 변경만 있으면 됩니다. 이는 개발 중 파이프라인 실행 시간을 줄여 더 빠른 개발 주기로 파이프라인을 더 빠르게 개발하는 동시에 SageMaker 관리 리소스 비용을 줄입니다.
더, 방문 내용 Amazon SageMaker 파이프 라인 or SageMaker 파이프라인을 사용하여 로컬에서 작업 실행.
저자 소개
 폴 하기스 AWS, Amazon, Hortonworks를 비롯한 여러 회사에서 기계 학습에 집중했습니다. 그는 기술 솔루션을 구축하고 사람들에게 이를 최대한 활용하는 방법을 가르치는 것을 즐깁니다. AWS에서 근무하기 전에는 Amazon Exports and Expansions의 수석 설계자로서 amazon.com이 해외 쇼핑객을 위한 경험을 개선하도록 도왔습니다. Paul은 고객이 실제 문제를 해결하기 위해 기계 학습 이니셔티브를 확장하도록 돕는 것을 좋아합니다.
폴 하기스 AWS, Amazon, Hortonworks를 비롯한 여러 회사에서 기계 학습에 집중했습니다. 그는 기술 솔루션을 구축하고 사람들에게 이를 최대한 활용하는 방법을 가르치는 것을 즐깁니다. AWS에서 근무하기 전에는 Amazon Exports and Expansions의 수석 설계자로서 amazon.com이 해외 쇼핑객을 위한 경험을 개선하도록 도왔습니다. Paul은 고객이 실제 문제를 해결하기 위해 기계 학습 이니셔티브를 확장하도록 돕는 것을 좋아합니다.
 니클라스 팜 스웨덴 스톡홀름에있는 AWS의 솔루션 설계자로서 북유럽 전역의 고객이 클라우드에서 성공할 수 있도록 지원합니다. 그는 IoT 및 머신 러닝과 함께 서버리스 기술에 특히 열정적입니다. 일 외에 Niklas는 열렬한 크로스 컨트리 스키어이자 스노 보더이자 마스터 에그 보일러입니다.
니클라스 팜 스웨덴 스톡홀름에있는 AWS의 솔루션 설계자로서 북유럽 전역의 고객이 클라우드에서 성공할 수 있도록 지원합니다. 그는 IoT 및 머신 러닝과 함께 서버리스 기술에 특히 열정적입니다. 일 외에 Niklas는 열렬한 크로스 컨트리 스키어이자 스노 보더이자 마스터 에그 보일러입니다.
 키릿 타다카 SageMaker 서비스 SA 팀에서 일하는 ML 솔루션 설계자입니다. AWS에 합류하기 전에 Kirit는 초기 단계의 AI 스타트업에서 근무한 후 AI 연구, MLOps 및 기술 리더십 분야에서 다양한 역할을 컨설팅했습니다.
키릿 타다카 SageMaker 서비스 SA 팀에서 일하는 ML 솔루션 설계자입니다. AWS에 합류하기 전에 Kirit는 초기 단계의 AI 스타트업에서 근무한 후 AI 연구, MLOps 및 기술 리더십 분야에서 다양한 역할을 컨설팅했습니다.

